
Oprava k předchozímu dílu — na Linuxu 2.6 se low-memory deadlock nevyskytuje, pokud swapujeme do souboru na lokálním disku. Jádro v takovém případě zjistí umístění bloků souboru na jeho blokovém zařízení a swapuje jako na blokové zařízení s nesouvislým umístěním bloků. Při samotném swapování se funkce filesystému nevolají. Jádro 2.4 toto obcházení filesystému nemá a low-memory deadlock se v tomhle případě vyskytnout může.
Síť
V této kapitole se budeme zabývat implementací síťového stacku. Je třeba, aby operační systém podporoval více protokolů. Mezi ovladači těchto protokolů se předávají packety, přičemž každý protokol přidá nebo odebere svoji hlavičku. Packet může putovat mezi rozličnými ovladači protokolů— například Ethernet—IP—TCP, Ethernet—IP—UDP, PPP—IP—TCP, Ethernet—IPX a jiné. Je třeba najít obecný formát, v jakém se packety mezi protokoly předávají.
Socket buffery na Linuxu
Linux používá k předávání packetů socket buffery. Socket buffer má hlavu a datovou oblast. Hlava je popsána strukturou struct sk_buff, obsahuje pointery head a end, které ukazují na začátek a konec alokované datové oblasti, dále obsahuje pointery data a tail, které ukazují do oblasti určené head a end na data aktuální protokolové vrstvy. Socket buffer se alokuje pomocí funkce skb_alloc. V souboru skbuff.h je spousta dalších inlinovaných funkcí pro manipulaci s pointery nebo kopírování bufferu.
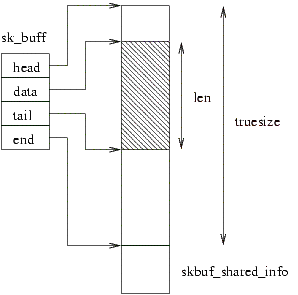
Socket buffer na Linuxu
Když je socket buffer vytvářen, rezervuje se na začátku dostatečné množství bytů pro hlavičky všech protokolů, pak se nakopírují vlastní data (na pointer data) a na konec se ukáže pointerem tail. Poté si jednotlivé vrstvy (např. TCP, IP, Ethernet) postupně posouvají data k nižším adresám a vkládají tam svoje hlavičky. Nakonec se socket buffer dostane k příslušnému ovladači síťové karty, a ten odešle všechny byty mezi pointery data a tail. Při posouvání data směrem dolů je třeba zajistit, aby tento pointer nikdy nebyl menší než pointer head. Pokud k tomu dojde, jádro spadne na panic (může k tomu dojít jen tehdy, pokud někdo napsal nekorektní ovladač protokolu, který alokuje příliš mnoho hlaviček).
Pokud Linux přijímá packet, alokuje ovladač karty socket buffer o dostatečné velikosti, umístí do něj celý packet a nastaví data na začátek packetu a tail na konec packetu. Poté je packet předán síťové vrstvě pomocí funkce netif_rx. Tato funkce rozhodne, ke kterému protokolu packet patří. Příslušný protokol si přečte svou hlavičku, posune data za konec hlavičky a předá packet dalšímu protokolu. Až packet projde všemi protokoly, zbudou mezi pointery data a tail jen samotná data, která se předají uživatelskému programu.
Socket buffery je možno klonovat. Klonování je potřeba tehdy, pokud je nutno jedna data přijatá ze síťové vrstvy předat dvěma nebo více odlišným protokolovým stackům. Typickým případem, kdy se klonování používá, je prohlížení sítě pomocí programu tcpdump — tehdy je třeba příchozí packet předat protokolové vrstvě, které náleží, k dalšímu zpracování a RAW socketu, pomocí kterého tcpdump sleduje tok na síti. Při klonování se vytvoří několik struktur struct sk_buff, které ukazují na tatáž data. Za pointerem end je umístěna struktura struct skbuf_shared_info (je možno se na ni dostat pomocí makra skb_shinfo) obsahující informace. Nejdůležitější je počítadlo, kolik sk_buf se na tuto oblast odkazuje. Při smazání posledního klonu toto počítadlo dosáhne nuly a datová oblast je uvolněna.
Mbuf na FreeBSD
FreeBSD používá k popisu packetu struktury struct mbuf. Jeden packet je popsán řetězcem těchto struktur. Každá struct mbuf má pointer m_next na další část packetu. Pokud je tento pointer NULL, jedná se o poslední kus packetu. První mbuf má navíc strukturu struct pkthdr, která obsahuje obecné informace o packetu. Data se mohou nacházet buď rovnou ve struktuře mbuf, nebo v externí oblasti definované strukturou struct m_ext, která je součástí mbuf. m_ext obsahuje pointer na začátek dat, délku a funkce pro uvolnění a klonování. Každý mbuf má pevnou velikost 256 bytů (je možno nastavit v konfiguračním souboru při kompilaci jádra). Pokud se do něj data vejdou, uloží se tam za konec struktur, jinak se alokuje externí oblast. S mbufy je možno manipulovat pomocí maker v souboru mbuf.h.
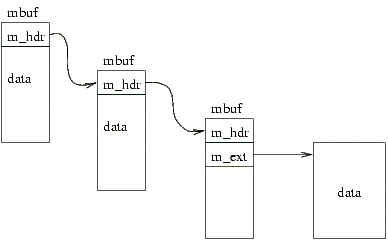
Packet popsaný pomocí tří zřetězených struktur mbuf
Když je vytvářen mbuf s packetem k odeslání, vyrobí se mbuf obsahující pouze hlavičky protokolů IP a TCP. Tyto hlavičky jsou vyplněny a k tomuto mbufu je připojen nový mbuf obsahující ukazatele na data do fronty příslušného socketu. Pokud je dat málo, jsou nakopírována rovnou do původního mbufu za hlavičky.
Při přijetí packetu síťový ovladač sám alokuje a vyplní mbuf. Pokud je packet dlouhý, musí mbuf obsahovat pointer na externí data. Ovladač může specifikovat funkce pro uvolnění nebo zvětšení počítadla referencí pro tuto externí oblast.
Mbufy je možno klonovat podobně jako na Linuxu — struct mbuf se prostě zkopírují, a pokud mbuf obsahuje nějaká externí data, zavolá se na tato data speciální funkce, která zvětší počítadlo referencí.
Zero-copy TCP
Síťové servery zpravidla posílají veliké množství dat ze souborů do sítě. Značného zrychlení docílíme, pokud budeme data posílat rovnou z page cache do síťové karty pomocí DMA bez jakéhokoli kopírování dat do síťových bufferů. Potřebujeme k tomu síťovou kartu, která umí tzv. scatter-gather DMA. Při scatter-gather DMA jsou ovladači síťové karty předány ukazatele na začátky jednotlivých fragmentů, které tvoří packet, a jejich délky. Síťová karta sama přečte z paměti jednotlivé fragmenty, poskládá packet a pošle ho na síť. Většina moderních PCI síťových karet scatter-gather DMA umí (zde musím varovat před velmi rozšířenými kartami Realtek RTL8139 — tyto karty nejenže neumí sg-DMA, ale navíc vyžadují zcela nevhodné zarovnání packetů pro DMA, proto se u nich celý packet musí kopírovat na správné místo, než může být odeslán. Ve vytížených serverech je použití takové karty zcela nevhodné).
Program může pro zero-copy TCP použít syscall sendfile. Syscall pošle daný soubor na daný socket. Syntax syscallu se na Linuxu a na FreeBSD liší — na FreeBSD je možno pomocí syscallu navíc ještě připojit nějaká data před nebo za soubor.
Zero-copy TCP existovalo dlouho pouze na FreeBSD — velmi snadno se implementuje pomocí řetězu mbufů (vyrobíme jeden mbuf obsahující TCP/IP hlavičky a druhý mbuf obsahující ukazatel na externí data do page-cache a tyto dva mbufy zřetězíme), ale nelze je implementovat pomocí socket bufferů obsahujících data packetu v jedné lineární oblasti na Linuxu. Posledních několik verzí Linuxu 2.4 má také zero-copy — seznam externích fragmentů se ukládá na konec datové oblasti socket bufferu do struktury struct skbuf_shared_info. Poněvadž se na Linuxu jedná o novou vlastnost, nepodporují ji ještě všechny ovladače síťových karet. I když samotná karta scatter-gather DMA umí, není jisté, že někdo přepsal ovladač, aby uměl tyto fragmenty do scatter-gather seznamu karty ukládat.
Zero-copy s sebou přináší další problém, a tím je počítání kontrolních součtů packetů. Každý TCP a UDP packet má mít kontrolní součet datové oblasti. Dokud zero-copy neexistovalo, součet se počítal při kopírování dat do fronty na socketu. Počítání součtu při kopírování dat nezpomaluje téměř vůbec. Aby data mohla být při zero-copy posílána rovnou z paměti na kartu a nemusela procházet pomalou sběrnicí mezi pamětí a procesorem, musí síťová karta být schopna spočítat kontrolní součet. Většina moderních síťových karet kontrolní součty počítat umí. Některé mají v sobě napevno zadrátované počítání kontrolních součtů pro IP, některé umí počítat součty libovolné oblasti, takže jsou použitelné i pro IPv6 nebo jiné protokoly. FreeBSD i novější verze Linuxu 2.4 umějí počítání kontrolních součtů na kartě využít. Před nákupem karty do serveru je však třeba si ověřit, že karta i ovladač v daném systému počítání kontrolních součtů podporují — jinak přijde celé zero-copy TCP nazmar a data se stejně budou muset kvůli spočítání součtu kopírovat do procesoru.

V experimentálním FreeBSD 5 bylo zavedeno zero-copy i při syscallu write (zero-copy při write funguje již velmi dlouho na operačním systému NetBSD, je nutno to povolit volbou ZERO_COPY_SOCKETS při kompilaci jádra). Pokud program zavolá write, zapisovaná stránka je označena v tabulce stránek jako read-only a vyrobí se mbuf, jehož externí data ukazují rovnou na tuto stránku. Takový mbuf se dále předá TCP/IP stacku, který před něj přidá mbuf s hlavičkami a odešle packet na síťovou kartu. Karta pak rovnou pomocí DMA čte data ze stránky náležící uživatelskému adresnímu prostoru. Pokud program mezitím do stránky zapíše, vyrobí se copy-on-write kopie stránky a původní stránka zůstane netknutá. Zero-copy se provádí pouze, pokud množství zapsaných dat je větší než stránka. Pokud je množství zapsaných dat malé, je rychlejší data zkopírovat než provádět manipulaci s tabulkami stránek. Zero-copy při write může v určitých situacích přinést zrychlení síťové komunikace, nicméně ve většině případů k tomu nedojde — je dost práce s manipulací s tabulkami stránek a navíc, aby to správně rychle fungovalo, program nesmí do oblasti paměti, kterou předal syscallu write, zapsat, dokud data nebudou odeslána a potvrzena. Většina programátorů ihned po zápisu bufferu pomocí write tento buffer uvolní nebo použije na něco jiného, což způsobí kopírování stránek při pokusu o zápis do read-only stránky a celou věc to ještě více zpomalí.
Schopnosti TCP/IP stacku
Od původního standardu TCP/IP z roku 1981 (RFC 791, 792, 793) uplynulo mnoho let a tento standard byl rozšiřován. Navzdory tomu je dosud udržována kompatibilita — TCP z roku 1981 by stále mohlo komunikovat se současnými implementacemi.
- Path MTU discovery — RFC1191 z roku 1990— toto rozšíření umožňuje zjistit Maximum transmission unit (neboli maximální velikost packetu) na cestě mezi dvěma spojenými počítači. Díky tomuto rozšíření může TCP posílat packety potřebné velikosti a není třeba je pak fragmentovat na routerech. Funguje to tak, že packety jsou posílány s příznakem, že nesmějí být fragmentovány; pokud je někde po cestě menší MTU, než je velikost packetu, je packet zahozen a odesilateli je poslána ICMP zpráva o přílišné velikosti packetu. Odesilatel poté začne posílat menší packety. Linux i FreeBSD toto rozšíření podporují.
- Window scaling — RFC1323 z roku 1992. Původní TCP umožňovalo maximální velikost okna (t.j. dat, jež byla odeslána, ale ještě nebyla potvrzena) 65535. Toto rozšíření umožňuje tuto velikost libovolně zvyšovat. Linux i FreeBSD je podporují, nicméně pro použití je třeba na socketu pomocí syscallu
setsockoptnastavit větší příchozí buffer. Implicitní hodnota bufferu je menší než 65536, aby nedošlo k zaplnění paměti, pokud je otevřeno mnoho socketů. - Timestamps — také RFC1323. Ke každému packetu je přiřazen čas, kdy byl odeslán. Tento čas je možno použít k přesnému měření, jak dlouho trvá round-trip (t.j. čas od odeslání packetu do jeho přijetí). Dále tento čas funguje jako ochrana proti přetečení seq čísla — na gigabitovém Ethernetu dojde k přetečení za 34 sekund. Packet může však v síti držet až 4 1/4 minuty. Teoreticky by tedy mohlo docházet k tomu, že se staré packety budou míchat do současného spojení. V praxi je toto témeř nemožné, neboť packety se nikde po dobu 34 sekund nedrží. Podle nejnovějších standardů je možno tento čas použít i k rozpoznání, zda došlo k předčasnému znovuposlání packetu, na sítích, které mají velmi proměnlivý round-trip. Timestampy podporuje Linux i FreeBSD.
- T/TCP — Transakční TCP, RFC1644 z roku 1994 — umožňuje obejít standardní třípacketovou výměnu při navazování spojení, neboť ta je moc pomalá. Pomocí T/TCP je možno data poslat už v původním SYN packetu a přijmout odpověď v SYN/ACK packetu. V packetech je možno nastavit i bit FIN, čímž se způsobí, že nebudou žádné další packety potřeba na ukončení spojení; v takovém případě je možno uskutečnit celé spojení pouze pomocí dvou packetů — jednoho poslaného klientem a druhého poslaného serverem. Nové TCP optiony v onom RFC řeší problémy se ztracenými a přeposlanými packety —je třeba zajistit, aby se jedno spojení tvářilo stále jako jedno spojení, i když dojde ke ztrátě packetu. T/TCP podporuje pouze FreeBSD, Linux ne. Ve FreeBSD je implicitně vypnuté a je třeba ho povolit pomocí sysctl
net.inet.tcp.rfc1644. T/TCP na klientovi nelze použít pomocí standardních syscallůconnectawrite; je třeba po vytvoření socketu pomocísocketprovést současné připojení i poslání dat pomocí syscallusendto(více informací vizman ttcp). Bohužel programátoři o T/TCP moc nevědí a většina programů ho nepoužívá. - Selective acknowledgement — RFC2018 z roku 1996. V TCP příjemce tradičně informuje odesilatele o přijatých packetech pomocí ACK čísla — říká, že přijal všechna data se SEQ číslem menším, než je jeho odeslané ACK číslo. Pomocí selective acknowledgement může příjemce informovat odesilatele i o nesouvislých blocích přijatých dat. Selective acknowledgement je implementován jako TCP option, ve kterém mohou být až čtyři intervaly přijatých dat. Selective acknowledgement podporuje Linux, ale nikoli FreeBSD.
- Explicit congestion notification (ECN) —RFC3168 z roku 2001. Původní implementace TCP řešila zahlcení pomocí ICMP zprávy „Source quench” — zahlcený router odeslal tuto zprávu odesilateli, ten při přijetí snížil rychlost odesílání. Nebylo nijak specifikováno, jak moc má odesilatel omezit rychlost vysílání. Takové řešení moc nefungovalo a v osmdesátých letech docházelo často ke kolapsu internetu kvůli zahlcení. Van Jacobson tento problém vyřešil definováním nového standardu, podle něhož TCP zmenší velikost vysílacího okna na polovinu pokaždé, když dojde ke ztrátě a přeposlání packetu. Source quench zprávy již není třeba generovat ani na ně reagovat. Takovéto řešení se ukázalo velmi dobré a každé současné TCP je musí dodržovat. Zjistilo se, že na routerech není vhodné zahazovat packety až ve chvíli, kdy jim dojde fronta; mnohem efektivnější je zahazovat je náhodně, kde pravděpodobnost zahození packetu je úměrná velikosti fronty — takové řešení se nazývá Random early detection. Tím budou TCP spojení přiškrcována rovnoměrně. Explicit congestion notification je nové rozšíření, které znamená, že router packet místo zahození označí, příjemce informuje ve svém ACKu odesilatele, že dostal označený packet, a odesilatel při přijetí této informace sníží velikost odesílacího okna, jako by došlo ke ztrátě packetu. K žádné ztrátě packetu a znovuposlání však nedochází, proto je toto řešení efektivnější. ECN podporuje pouze Linux, FreeBSD ne. ECN je třeba zapnout při kompilaci jádra a povolit v
/proc/sys/net/ipv4/tcp_ecn. Některé staré firewally bohužel packety s nastavenými ECN bity zahazují nebo na ně odpovídají RST packetem, proto je po zapnutí této featury možno očekávat problémy s připojováním na určitá místa. Nicméně takových míst rychle ubývá.






















 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU