
Obsah
1. Podmínka účinnosti vyrovnávací paměti: lokalita dat či programového kódu
2. Struktura údajů uložených ve vyrovnávací paměti
3. Asociativita vyrovnávací paměti
4. Přímo mapovaná vyrovnávací paměť
5. Plně asociativní vyrovnávací paměť
6. Dvoucestná či čtyřcestná asociativní vyrovnávací paměť
7. Strategie přidělování bloků
8. Literatura a odkazy na Internetu
9. Obsah dalšího pokračování seriálu
1. Podmínka účinnosti vyrovnávací paměti: lokalita dat či programového kódu
V předchozí části tohoto seriálu jsme si popsali hierarchii paměti (pyramidovou strukturu) i základní způsob zapojení vyrovnávacích pamětí první a druhé úrovně (L1 cache, L2 cache) do paměťového subsystému počítačů. Vyrovnávací paměti jsou obecně velmi rychlé, ovšem jejich kapacita je poměrně malá, typicky dosahuje pouhého jednoho promile až jednoho procenta kapacity operační paměti (ta je založena na relativně pomalé, ovšem levné DRAM, která se mj. vyznačuje velkou integrací). Cena, přesněji řečeno časové zpoždění, které zaplatíme za operaci čtení či zápisu z adresy, jež se nenachází ve vyrovnávací paměti (cache miss) může být docela vysoká, proto se tvůrci architektury vyrovnávacích pamětí snaží, aby byla vyrovnávací paměť i přes svoji malou kapacitu použita pro co největší množství čtecích i zápisových operací, tj. aby se minimalizoval počet „výpadků “ (cache miss) a naopak maximalizoval počet cache hits, tj. situací, kdy se požadovaná data nachází ve vyrovnávací paměti.
Nejlépe si tuto snahu vysvětlíme na údajích z praxe. Například u typické konfigurace počítače založeného na procesoru Intel Pentium M (používaného v noteboocích) či Celeron se uvádí následující údaje; vše v počtu taktů (cyklů procesoru):
| Čtení či zápis z/do | Počet cyklů |
|---|---|
| Pracovní registr | 1 či méně v případě úspěšného zřetězení instrukcí |
| Vyrovnávací paměť první úrovně | cca 3 |
| Vyrovnávací paměť druhé úrovně | cca 14 |
| Operační paměť | cca 240 |
Pokud nějaký program má na této konfiguraci přečíst 1000000 adres (a něco s jejich obsahem udělat, například provést jejich součet s uložením výsledku do pracovního registru) a efektivita vyrovnávací paměti je rovna 95 procentům, stráví mikroprocesor čtením adres celkem:
1000000×0,95×3=2850000 taktů při čtení z L1 cache a
1000000×(1–0,95)×240=12000000 taktů při čtení z operační paměti,
celkem tedy: 14850000 taktů (příklad je velmi zjednodušený, nepočítá například s vyrovnávací pamětí druhé úrovně, blokovým čtením s DRAM apod., omezené kapacitě vyrovnávací paměti atd.).
Vliv efektivity vyrovnávací paměti (poměru cache hit vůči všem operacím), je patrný i z následující tabulky, opět platné pro předchozí konfiguraci:
| Efektivita | L1 cache (taktů) | DRAM (taktů) | Celkem |
|---|---|---|---|
| 0% | 0 | 240000000 | 240000000 |
| 5% | 150000 | 228000000 | 228150000 |
| 10% | 300000 | 216000000 | 216300000 |
| 15% | 450000 | 204000000 | 204450000 |
| 20% | 600000 | 192000000 | 192600000 |
| 25% | 750000 | 180000000 | 180750000 |
| 30% | 900000 | 168000000 | 168900000 |
| 35% | 1050000 | 156000000 | 157050000 |
| 40% | 1200000 | 144000000 | 145200000 |
| 45% | 1350000 | 132000000 | 133350000 |
| 50% | 1500000 | 120000000 | 121500000 |
| 55% | 1650000 | 108000000 | 109650000 |
| 60% | 1800000 | 96000000 | 97800000 |
| 65% | 1950000 | 84000000 | 85950000 |
| 70% | 2100000 | 72000000 | 74100000 |
| 75% | 2250000 | 60000000 | 62250000 |
| 80% | 2400000 | 48000000 | 50400000 |
| 85% | 2550000 | 36000000 | 38550000 |
| 90% | 2700000 | 24000000 | 26700000 |
| 95% | 2850000 | 12000000 | 14850000 |
| 100% | 3000000 | 0 | 3000000 |

Závislost celkového počtu taktů nutných pro přečtení jednoho milionu adres na efektivitě vyrovnávací paměti první úrovně (zjednodušený příklad)
Jednou z podmínek pro dosažení co největší efektivity vyrovnávacích pamětí je lokalita dat (pro datové cache) či lokalita programového kódu (pro instrukční cache). Této žádoucí vlastnosti lze dosáhnout vhodným naprogramováním aplikace, většinou však vyplývá už ze samotné podstaty řešeného problému – programy obsahují vložené (někdy ne explicitně zapsané) programové smyčky, které po překladu přímo vedou k lokalitě programového kódu a ve velkém množství případů se zpracovávají neustále ta stejná data, která se v ideálním případě mohou celá vložit do datové vyrovnávací paměti a tím značným způsobem urychlit běh programu díky sníženému množství přenosů z operační paměti do vyrovnávací paměti a zpět. Vlastnost lokality se v literatuře označuje jako pravidlo 80–20, popř. pravidlo 90–10, které lze vyjádřit i slovně: 80 % času stráví program pouze ve 20 % kódu. Pokud by tato pravidla nebyla platná (například by byly jednotlivé instrukce programu v operační paměti „rozházeny“ zcela náhodně), ztrácelo by použití vyrovnávacích pamětí svůj význam.
2. Struktura údajů uložených ve vyrovnávací paměti
Již minule jsme si řekli, že data jsou ve vyrovnávací paměti uložena po blocích pevné délky. Tyto bloky se nazývají lines, popř. cache lines. Každý blok má kapacitu dosahující většinou 32 nebo 64 bytů (tj. 256 nebo 512 bitů). Například vyrovnávací paměť o kapacitě 512 kB a velikosti bloku 32 bytů obsahuje celkem 16384 bloků. Ke každému bloku je přidána další informační struktura (tj. paměťové buňky) obsahující index tohoto bloku v hlavní paměti (jedná se o adresu bez nižších n bitů, kde n odpovídá velikosti bloku a šířce zpracovávaného slova), popř. i další informace, například o tom, kolikrát byl tento blok použit při čtení či zápisu dat, zda se jedná o „špinavý“ (dirty) blok, jehož obsah musí být v budoucnu uložen do hlavní paměti atd. Tyto doplňující informace se označují jako tag a jejich délka je různá podle konkrétní architektury vyrovnávací paměti (typicky se jedná o hodnotu 32 bitů, ale může být i odlišná).
Nutnost uložení doplňujících informací ke každému bloku ve vyrovnávací paměti je jeden z hlavních důvodů, proč se ve vyrovnávacích pamětech používají bloky o kapacitě větší než jedno adresovatelné slovo – i pro samotný tag je totiž nutné vyhradit část kapacity vyrovnávací paměti a kdyby byly bloky příliš malé, zabraly by jejich tagy zbytečně mnoho drahého místa v paměťových buňkách, nehledě na to, že spolu se snižující se velikostí bloků stoupá počet bitů nutných pro uložení jeho indexu (adresy) v operační paměti (tím se zvětšuje počet bitů nutných pro uložení každého tagu). Současné paměti DDR a DDR2 navíc obsahují ve svém přenosovém protokolu příkazy, kterými je možné provést blokový přesun (burst read, burst write), jehož délka v ideálním případě odpovídá právě velikosti bloku vyrovnávací paměti. Při tomto přesunu se zdrojová či cílová adresa přenáší pouze jedenkrát, což samozřejmě celý přenos urychluje. Pokud je šířka datové sběrnice 64 bitů (DDR), je pro přesun celého bloku o délce 64 bytů zapotřebí vykonat 64×8/64=8 čtecích či zápisových operací.
3. Asociativita vyrovnávací paměti
Asociativita vyrovnávací paměti zjednodušeně řečeno určuje, jakým způsobem mohou být mapovány bloky z operační paměti do bloků v paměti vyrovnávací. Obecně totiž neplatí, že jakýkoli blok z operační paměti může být uložen kdekoli v paměti vyrovnávací – tuto na první pohled užitečnou vlastnost je sice možné zaručit, ovšem za cenu zpomalení práce vyrovnávací paměti a zvýšené složitosti logických obvodů, které práci vyrovnávacích pamětí řídí. Již minule jsme si uváděli jednoduchý příklad konfigurace počítače s 64 MB operační paměti, 512 kB vyrovnávací paměti a velikosti bloku 32 bytů: vyrovnávací paměť může pojmout 16384 bloků (512×210/32), operační paměť je rozdělena do 2097152 bloků (64×220/32). Pro rozlišení oněch 2097152 bloků je zapotřebí 21 bitů, protože platí 221=2097152 (nebo také se znalostí výpočtu logaritmu o libovolném základu log(2097152)/log(2)=ln(2097152)/ln(2)=21), což je také minimální teoretická šířka tagu každého bloku (pro jednoduchost předpokládejme, že tagy jsou uloženy mimo oněch 512 kB vyrovnávací paměti, což je mnohdy pravda.
Existují různé míry asociativity vyrovnávací paměti, z nichž ty nejtypičtější jsou popsány v následujících kapitolách.
4. Přímo mapovaná vyrovnávací paměť
V případě přímo mapované vyrovnávací paměti (direct mapped cache) se jedná o implementačně nejjednodušší strukturu vyrovnávacích pamětí, ve které se již přímo z indexu bloku (tj. nejvyšších bitů adresy) určuje, ve kterém místě se blok může nacházet ve vyrovnávací paměti – konkrétně se jedná o jedno jediné místo vypočtené pomocí vztahu index modulo n, kde n je celkový počet bloků, které vyrovnávací paměť obsahuje. Výše uvedený vztah se samozřejmě v praxi nemusí počítat, protože počet bloků ve vyrovnávací paměti je roven celočíselné mocnině dvou, takže nejnižších x bitů indexu bloku v operační paměti přímo určuje umístění bloku v paměti vyrovnávací (samozřejmě platí 2x=n). Takto zkonstruovaná vyrovnávací paměť je při výběru bloků velmi rychlá, ovšem omezení daná způsobem mapování bloků jsou největší: dva bloky, jejichž indexy se liší o celočíselný násobek n nemohou být současně ve vyrovnávací paměti umístěny, což může vést k relativně vysoké míře cache miss a tím pádem i k nižší celkové efektivitě.
5. Plně asociativní vyrovnávací paměť
Plně asociativní vyrovnávací paměť (fully associative cache ) je ve své podstatě pravým opakem přímo mapované vyrovnávací paměti. Zatímco u předchozí konstrukce byla pozice bloku pevně dána jeho indexem, u plně asociativní paměti prakticky neexistuje žádné omezení, co se týče mapování bloků (jediným omezením je, aby se blok ve vyrovnávací paměti nacházel pouze v jedné kopii, což je logické jak kvůli koherenci dat, tak i z hlediska co nejlepšího využití kapacity této paměti). Vzhledem k minimálnímu omezení mapování bloků (a tím i největším možnostem, které má alokátor bloků) se u tohoto typu konstrukce vyrovnávací paměti dosahuje nejnižší míry cache miss, takže by se zdálo, že se tato konstrukce používá nejčastěji. Ve skutečnosti tomu tak vždy není, protože v takto vytvořené vyrovnávací paměti je nutné implementovat rychlý mechanismus mapování a hledání bloků, což většinou vede na nutnost použití nějakého typu CAM (Content Addressable Memory), tj. paměti adresované obsahem (zde je obsahem myšlen index bloku). Tyto obvody jsou drahé a také relativně pomalé, proto plně asociativní vyrovnávací paměť není obecně tak rychlá, jako přímo mapovaná paměť.
6. Dvoucestná či čtyřcestná asociativní vyrovnávací paměť
Tak, jak je už v IT i jiných disciplínách skoro pravidlem, je v praxi výhodnější nepoužívat žádnou z výše uvedených limitních případů asociativity (přímé mapování, tj. nultá míra asociativity versus plná asociativita), ale spíše nějaký vhodně navržený kompromis. Ten je představován dvoucestnou asociativní vyrovnávací pamětí (2-way set associative cache) popř. čtyřcestnou asociativní vyrovnávací pamětí (4-way set associative cache). Název těchto konstrukcí již naznačuje jejich základní vlastnosti. U dvoucestné asociativní vyrovnávací paměti je možné každý blok z operační paměti mapovat do dvou míst v paměti vyrovnávací; čtyřcestná asociativní vyrovnávací paměť naproti tomu umožňuje jeden blok mapovat do čtyř míst (samozřejmě ne do všech současně, alokátor si musí vybrat na základě zvolené strategie). Na první pohled je výběr pouhých dvou či čtyř míst oproti místu jednomu (jak tomu bylo v případě přímo mapované paměti) bezvýznamný, v praxi se však ukazuje, že se výrazně snižuje míra cache miss. Ani konstrukce těchto pamětí není složitá (původní CAM se redukuje na relativně jednoduchý rozhodovací obvod), proto se tyto paměti používají poměrně často.
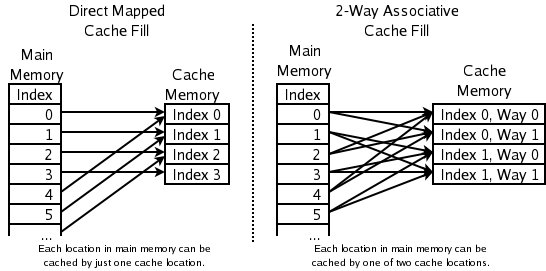
Přímo mapovaná a dvoucestná vyrovnávací paměť
7. Strategie přidělování bloků
Ve chvíli, kdy mikroprocesor potřebuje provést čtení či zápis dat do bloku X, který se nenachází ve vyrovnávací paměti (jinými slovy nastane cache miss), použije se takzvaný alokátor bloků, což je logický obvod, který na základě několika kritérií rozhodne, jakým způsobem se požadovaný blok X do vyrovnávací paměti dostane. Nejjednodušší práci má alokátor v případě, že vyrovnávací paměť je přímo mapovaná – index bloku X v tomto případě přímo určuje, na které místo ve vyrovnávací paměti se blok X má načíst. Původní blok Y je (v případě, že byl změněn, tj. byl u něj nastaven příznakový bit dirty) uložen zpět do operační paměti (provádí se burst write neboli blokový zápis do operační paměti) a poté je do stejného místa vyrovnávací paměti načten požadovaný blok X (provádí se burst read neboli blokové čtení z operační paměti). Toto řešení je nejrychlejší z hlediska práce alokátoru, ovšem počet blokových přenosů z a do operační paměti je poměrně velký – viz čtvrtá kapitola.
Poněkud více práce čeká na alokátor bloků v případě, že je použita dvoucestná, čtyřcestná či dokonce plně asociativní vyrovnávací paměť. Celou činnost si vysvětlíme na dvoucestné asociativní vyrovnávací paměti, problém je však stejný i v ostatních případech. U dvoucestné paměti musí alokátor rozhodnout, který z bloků Y1 či Y2 bude uložen zpět do operační paměti, aby na stejné místo mohl být načten požadovaný blok X. Rozhodnutí mezi blokem Y1 a Y2 je provedeno na základě strategie přidělování bloků, která dosti podstatným způsobem ovlivňuje efektivitu vyrovnávací paměti (nejvíce je to patrné u plně asociativní paměti). Pravděpodobně nejvíce známá je strategie, při které je „zahozen“ ten blok Yn, který byl používán méně často, než ostatní kandidáti na „zahození“ („zahození“ v tomto případě může znamenat i uložení do operační paměti v případě, že byl obsah bloku změněn). Tato strategie se označuje zkratkou LRU (Least Recently Used) a vyžaduje, aby se u každého bloku uloženého ve vyrovnávací paměti udržovaly i informace o posledním použití tohoto bloku (jedná se o celé číslo).
Podobnou strategií je strategie nazvaná LFU (Least Frequently Used), u níž se ke každému bloku pamatuje informace o tom, jak často byl blok požadován. Možné jsou i kombinace, například u Adaptive Replacement Cache (ARC), ve které se vhodným způsobem kombinuje strategie LRU a LFU s tím cílem, aby se efektivita využití vyrovnávací paměti co nejvíce zvýšila i v případě dat, u nichž jednotlivé predikce nepracují optimálně (LRU i LFU jsou totiž ve skutečnosti jednoduché prediktory, které se snaží odhadnout, které bloky budou v budoucnost použity méně častěji a které častěji).

8. Literatura a odkazy na Internetu
- Pavel Valášek, Roman Loskot: Polovodičové paměti,
BEN – Technická literatura, Praha 1998, ISBN-80–86056–18-X - Budínský J.: Polovodičové paměti a jejich použití,
SNTL, Praha 1977 - Budínský J.: Polovodičové paměti – Názvosloví a definice,
TESLA VÚST, Praha 1980 - Janů K.: Paměti a řadiče – část I.,
ČSVTS, Knižnice mikroprocesorová technika, Praha 1982 - Great Microprocessors of the Past and Present (V 13.0.0)
- Cache Mapping and Associativity (http://www.pcguide.com/ref/mbsys/cache/funcMapping-c.html)
- Wikipedia: Cache (http://en.wikipedia.org/wiki/Cache)
- Wikipedia: CPU cache (http://en.wikipedia.org/wiki/CPU_cache)
- Wikipedia: Cache algorithms (http://en.wikipedia.org/wiki/Cache_algorithms)
- Memory part 2: CPU caches (http://lwn.net/Articles/252125/)
- Cache Performance for SPEC CPU2000 Benchmarks (http://www.cs.wisc.edu/multifacet/misc/spec2000cache-data/)
- Fully Associative Cache (http://www.cs.umd.edu/class/spring2003/cmsc311/Notes/Memory/fully.html)
9. Obsah dalšího pokračování seriálu
V následující části tohoto seriálu si popíšeme práci vyrovnávacích pamětí v systémech, které obsahují více relativně samostatně pracujících procesorových jednotek nebo větší množství procesorových jader (dual core, quad core). Na těchto systémech je použití vyrovnávacích pamětí takřka nezbytné, protože jinak by byl celý výpočetní výkon ztracen při přístupu do operační paměti. Také se budeme zabývat tím, jakým způsobem se vyrovnávací paměti a fronty instrukcí musí zkonstruovat v případě, že je povolena modifikace spustitelného kódu (self-modyfying code, code morphing), tj. programový zásah do sekvence operačních kódů. Jedná se o poměrně aktuální téma, zejména při použití dnes velmi často používaných programovacích jazyků, jejichž virtuální stroje obsahují JIT (Just in Time) překladač. Jedná se jak o Javu či platformu .NET, tak i o některé implementace Lispu.

