
Decentralizované vyhledávání
Myšlenka decentralizovaného vyhledávače není tak nereálná, jak by se mohla na první pohled zdát. V historii několik pokusů už bylo, projekty často zanikly, nenápadná řádka v logu webserveru mne ale nasměrovala na jeden, který se drží už 17 let a stále se rozvíjí. Jmenuje se YaCy.



YaCy je decentralizovaný vyhledávač na principu peer-to-peer sítě. Svoji instanci si může rozjet každý a používat ji jako klienta s využitím decentralizovaného vyhledávacího indexu. Ti, kteří k tomu mají ještě veřejnou IP adresu, mohou své indexy sdílet s ostatními.
Systém rozlišuje „senior peery“, kteří indexy sdílejí, a pasivní peery označované jako „junior“, přístup k vyhledávání však mají všichni stejný.
Veřejné demo na yacy.searchlab.eu je velmi pomalé, vyplatí se tedy si rozjet vlastní instanci a vyzkoušet možnosti.
Aktivních peerů jsou v současnosti řádově stovky a z indexů je vidět, že velká většina uživatelů žije v sousedním Německu, které je i místem vzniku YaCy a kde je citlivost k otázkám soukromí tradičně vysoká a hackerská scéna rozvinutá (jako vyhledávač používá YaCy i Chaos Communication Camp). Podle mapy peerů funguje jejich poměrně velká skupina ve Francii, kde jsou státní omezení internetu silnější než u nás, další velkou skupinou je ruská jazyková oblast, která obsahuje hlavně pirátské stránky a poloilegální knihovny elektronických knih.
K čemu YaCy použít
České weby jsou zatím zaindexované mizerně, ale přesto se i nám nabízí hned několik slibných možností použití. Můžeme prohledávat fulltextově lokální úložiště a indexovat například elektronickou knihovničku či archív textů stažených z internetu – říkají tomu Robinsonův režim. Podobně lze snadno indexovat firemní intranet.

Náš soukromý vyhledávač na localhostu. YaCy nabízí mnoho šablon vzhledu, vyhovuje mi tenhle tmavý, co v noci nesvítí do očí.
Nebo si vyrobíme fulltextový vyhledávač pro vlastní veřejné weby a index budeme sdílet s komunitou – současně tak zařídíme, že náš web bude kompletně (ne selektivně, jako to dělá Google) zaindexovaný v decentralizovaném vyhledávači a indexy se přes DHT nakopírují na ostatní peery.
Můžu zaindexovat celé weby, které mě zajímají, nebo v kterých často hledám a přispět sdíleným indexem komunitě. Když už člověk oblíbeným webům plácá pásmo na indexaci, ať to někomu k něčemu je. Nebo můžu vyrobit oborový index dokumentů, které sice jsou veřejně přístupné, ale špatně se prohledávají. Jeden ze současných peerů YaCy například indexuje právní dokumenty Evropské unie, v minulosti se objevily pokusy s vyhledáváním nad biologickými daty.
Nebo si můžeme zaindexovat weby, které Google z nějakého důvodu vyřadil z indexu (DMCA, ochrana soukromí, nevhodný obsah, zásahy států). Šlo by i indexovat weby skryté za Torem (je to natvrdo zakázané v kódu, ale ten je otevřený a svobodný).
Mohu též použít jako zdroj adres html se seznamem záložek vyexportovaných z prohlížeče a moci tak hledat ve webech, které jsem už navštívil (opatrným nastavením hloubky crawleru na jinou než 0 se dostaneme na poměrně vysoká čísla, ale současně do indexu dostaneme stránky, které jsme nečetli, ale mohli bychom chtít). Případně použít YaCy jako reverzní proxy a indexovat všechno, na co se koukám – to má sice implikace pro soukromí, ale nemusím svoji instanci veřejně sdílet (tato funkcionalita je omezená kvůli současnému rozšíření HTTPS, nicméně uživatelé na jejím zachování trvali). Nebo zkusím nakrmit YaCy RSSky oblíbených zdrojů a budu moci vyhledávat ve zprávách dříve, než je objeví Google.

Výsledky vyhledávání v Peer-to-peer režimu. Filtrovat je můžeme podle různých parametrů: typu souboru, domény (Provider), názvu uživatelské kolekce, autora i jazyka.
V neposlední řadě můžeme experimentovat, zjišťovat, jak je vyhledávání složité, hrát si s váhami jednotlivých prvků stránek či slov, zkoušet vlastní funkce pro hodnocení relevance.
Kombinací více těchto strategií (indexy webů svých, kamarádů, bookmarků a několika rozsáhlejších webů, v nichž často vyhledávám) jsem se během prvních dní dostal na cca 66 000 zaindexovaných URL a velikost indexu 6,7GB, což není zrovna nic, kvůli čemu by si člověk kupoval nový disk.
Hrajeme si s YaCy
YaCy je napsané v Javě, v indexaci a vyhledávání spoléhá na Apache solr.
Na začátku budete muset nainstalovat JDK a Ant, stáhnout kódy z GitHubu a zkompilovat – nebo použít balíček pro Windows, Linux nebo macOS. Poté spustíme samotnou instanci YaCy. Funguje kupodivu i na FreeBSD a stačí mu oprávnění obyčejného uživatele – je bezpečnější mu vytvořit speciálního uživatele bez práv, nebo pustit instanci pod virtuálním strojem.
Vyhledávač
Po spuštění skriptem startYACY.sh se nám otevře webový server na localhostu a portu 8090. Na něm najdeme i svůj soukromý vyhledávač – klasické vyhledávací okénko jako na Googlu. Přístupné je i ve zbytku sítě, přístup můžeme samozřejmě omezit. Protože jsme zatím nezaindexovali žádné stránky, využijeme decentralizovaného vyhledávacího indexu.
Ve výsledcích vyhledávání můžeme filtrovat za pomoci mnoha parametrů (typ souboru, jazyk, doména, protokol, čas, geografické souřadnice), výsledky můžeme řadit pode skóre relevance nebo podle času. U každého výsledku se zobrazuje i jeho „citační index“, což je jeden z parametrů, podle kterých se posuzuje „skóre“ stránky. Podobně jako u ostatních vyhledávačů, čím je stránka odkazovanější, tím výše se ve výsledcích zobrazuje.

Výsledky vyhledávání v lokálním indexu. Stránky z německé Wikipedie přišly už dřív DHT transferem.
Každý výsledek vyhledávání má svůj RSS kanál podle specifikace OpenSearch, YaCy umožňuje se podle této specifikace ptát i různých jiných serverů, které OpenSearch podporují (rozhraní pro OpenSearch umí YaCy detekovat v už zaindexovaných webech). K dispozici jsou různá API i search extension pro Firefox.
Pokud už máme svůj vlastní index, můžeme si vybírat mezi režimem Stealth, který prohledává pouze jej a dotaz se nikam neposílá (u intranetu je tato možnost výchozí) nebo Peer-to-Peer, který se zeptá ostatních instancí YaCy, zobrazí výsledky z nich a sám je seřadí. Několik sekund trvá, než se výsledky z ostatních peerů načtou.
Pokud máte veřejnou IP adresu, nic nebrání tomu, abyste svůj vyhledávač vystavili do internetu, či přidali vyhledávací okénko na svoje webové stránky.
Relevance výsledků
Největší slabinou vyhledávače v češtině je špatné porozumění zadaným dotazům a hodnocení relevance. YaCy umožňuje používat thesaury, slovníky synonym, dostupné jsou pro angličtinu, němčinu a ruštinu. České thesaury se po internetu povalují taky, ale patrně by je někdo musel zkonvertovat do formátu použitého YaCy. Dalším problémem češtiny bude skloňování. Vzpomeneme si pak trochu na staré webové vyhledávače, kdy jsme dotazy formulovali pečlivěji a logičtěji.
Na druhou stranu se vyhledávač „nedomýšlí“, co asi hledáme, vzhledem k tomu, kde a kdo jsme, a nekazí nám čistotu dotazu žádnou „roztřepeností“, ze které geekové občas tečou. Máme zkrátka přístup k vyhledávání za pomoci přesně definovaných dotazů, s možností volby velkého množství parametrů, které dnes Googlu chybí. Což se hračičkům může hodit. Práce s češtinou by stála za pozornost vývojářů, kteří se již něčím takovým zabývali: i malé zlepšení by mohlo užitečnost YaCy v naší jazykové krajině výrazně zvýšit.
YaCy umožňuje i nastavovat si vlastní algoritmy hodnocení relevance (Boost funkce, v sekci Ranking and Heuristics) a například přiřazovat různé váhy různým elementům stránky, preferovat častěji aktualizované weby, penalizovat duplicity a podobně. Při indexování může stránky obohacovat i různými daty navíc – například ze seznamu geografických lokalit extrahovat místa, ke kterým se stránka pravděpodobně vztahuje a ty pak zobrazovat skrze OpenStreetMaps ve výsledcích vyhledávání.
Pavouci, rozběhněte se sítí
Administrační rozhraní je přístupné na stejném portu, ve výchozím stavu z localhostu bez omezení a hesla (doporučeno si nějaké hned nastavit). V záložce „Load Web Pages“ dostaneme možnost pustit první crawler – robot, který prochází web a sbírá stránky, které se později automaticky fulltextově indexují. Nastavíme URL, na níž chceme začít, a zvolíme si, zda se má procházet pouze zvolená část URL, nebo celá TLD. Pak proces spustíme a sledujeme průběh v Crawler Monitoru.
„Advanced Crawler“ pak nabízí další jemnější nastavení: do kolika úrovní chceme web procházet (s rozumem, viz šest stupňů odloučení, autor upozorňuje, že hloubka osm je už dost možná celý web), zda sledovat i odkazy na jiné domény, za pomoci regulérních výrazů filtrovat indexované stránky či stránky, na které crawler dále pokračuje, rozhodnout, co se stane se stránkami, které jsme již zaindexovali (indexovat znovu, nebo nechat být, pokud jsou starší než X dní) a zda chceme stránky kešovat a zobrazovat nakešovanou kopii ve výsledcích vyhledávání.
Process Scheduler nám umožní libovolnou crawlovací úlohu spustit opakovaně, v nastavený čas, nebo při události (start YaCy). Můžeme tedy kombinovat různé strategie: rozsáhlé weby zaindexovat jednorázově přes noc, často aktualizované procházet s menší hloubkou jednou týdně, a na agregátoor RSS pouštět crawler každou hodinu s instrukcí, aby ignoroval staré URL. Crawler samozřejmě respektuje robots.txt a parametry nofollow a noindex (tyto lze vypnout).
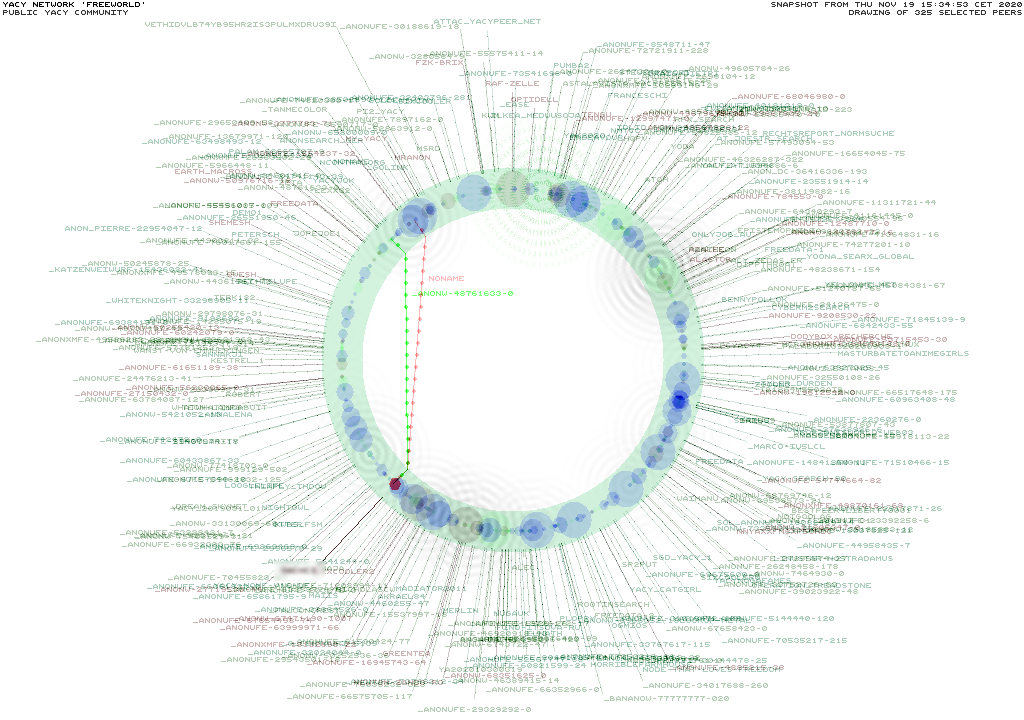
Mapa peer-to-peer sítě. Červená tečka jsem já. Červená čára je DHT přenos indexu ode mne na jiného peera. Zelená čára je přenos indexu ke mně. Peerové s vlnami kolem sebe právě indexují, peerové se svatozáří z čárek intenzivně vyhledávají.
Indexování větších webů (od tisíců položek víc) je poměrně náročné na RAM, zvlášť pokud si nadšeně pustíme více crawlů souběžně. I vlastní vyhledávání se pak zpomalí k nesnesitelnosti, je tedy lepší takové úlohy pouštět přes noc. Crawlování jde naštěstí „zapauzovat“ – pouze však globálně, nikoliv po jednotlivých úlohách. Pokud omylem přidáte doménu s příliš velkým množstvím stránek (třeba Wikipedii) a ukončíte její crawlování, můžete se při odstraňování desítek tisíc stránek z fronty taky docela načekat. YaCy má přednastavené limity na využitou paměť i místo na disku a když docházejí zdroje, omezí své funkce.
Skutečnou „killer feature“ je pak heuristika. Pokud zadáte vyhledávací dotaz, YaCy u stránek, které se zobrazily ve výsledcích vyhledávání, provede „mělký“ crawl na všechny jejich podstránky. Killer feature v tom smyslu, že po pár dotazech si indexováním svoji instanci slušně zahltíte a vyhledávání se výrazně zpomalí. Při výsledcích z peer-to-peer sítě navíc můžete crawlovat stránky, o které dvakrát nestojíte. Protože heuristika funguje na principu nabalující se sněhové koule, je vhodnější ji používat až ve chvíli, kdy máme slušnou databázi vlastních oindexovaných stránek a ty se zobrazují ve výsledcích výše.
Kdo by chtěl crawlování pojmout opravdu ve velkém, může v Advanced Crawleru využít funkci Network Scanner, která prochází celé síťové rozsahy, nebo velkolepý Autocrawl, který rozšíří kolekci o linky ze všech již zaindexovaných stránek do definované hloubky. YaCy podporuje i import dumpů ze systému MediaWiki či databáze diskusního fóra phpBB3. Dump všech hesel české Wikipedie s necelým miliónem stránek má zabalený jenom něco pod 900 MB.
P2P síť
Plnohodnotným peerem se staneme až ve chvíli, kdy vystavíme svoji instanci YaCy do veřejného internetu. Program si vystačí s jedním portem (8090), pokud jsme za NATem, můžeme ho nastavit na routeru jako DMZ. Případně si vypomůžeme SSH tunelem na stroj s veřejnou IP. Nezapomeňte, že na cílovém stroji musí být v sshd_config nastavena volba GatewayPorts yes.
$ ssh -f -R verejnystroj.cz:8090:localhost:8090 uzivatel@verejnystroj.cz -N
V System Administration → Server Access Settings → StaticIP je pak potřeba nastavit IP veřejného stroje.
Na grafu Peer-to-Peer Network pak můžeme sledovat, jak jsou velicí ostatní Peerové, kteří crawlují, kteří vyhledávají, jak k nám a od nás tečou data. Peeři mezi sebou sdílí DHT, decentralizovaný index, to znamená, že se již propočítané indexy z vaší instance ukládají na ostatní peery a ti zase ukládají části svých indexů k vám. Potenciál využití této vlastnosti spammery a „optimalizátory vyhledávání“ blokuje možnost celé domény z lokálního indexu mazat, případně je blacklistovat. To se vám bude líbit i v případě samotného indexování: nechcete už nikdy vidět výsledky z některého webu? Otravují vás srovnávače cen? Klik, blacklist a je to.
V sekci Peer-to-Peer Network naleznete i tabulku ostatních peerů, včetně množství zaindexovaných URL, jednotlivých slov v reverzním indexu a odkazu na vzdálenou instanci YaCy, kde můžete například prozkoumávat tamější seznamy zaindexovaných domén. Ve výchozím stavu je P2P nastaven na síť „freeworld“, je ale možné vytvářet i samostatné sítě s vlastní politikou, kdyby někdo chtěl být ještě osamělejší.

Přehled zaindexovaných URL na vzdáleném peerovi.
Experimentování s YaCy nabízí i zajímavý vhled do toho, jak vyhledávače fungují. Člověk si všimne, že některé redakční systémy plodí tisíce zbytečných podstránek. Zařekne se, že příště k tlačítku „poslat článek mailem“ přidá atribut „robots-nofollow“. Uvědomí si, jak linkovací farmy na legitimních serverech vystřelují nahoru neužitečný obsah. Zavrtí hlavou nad tím, jak rychle se jeho crawler nechá zavést třeba na blesk.cz. Prožije si velkými hráči dilema, zda chce z indexu mazat dezinformační weby a dělat, že neexistují, nebo si je tam pro zajímavost nechá, ale tím jim dá legitimitu. Dilema je to ovšem zbytečné, protože v decentralizovaném indexu je do své kolekce může zahrnout někdo jiný.
Hardwarová náročnost není zase tak příšerná, jak by člověk čekal – nejvíc se počítač zapotí u masivního crawlování a indexování. Kdo by chtěl něco takového podnikat ve větší míře, může mít více instancí na různých strojích a přes některé pouze indexovat a přes jiné jen vyhledávat. Pro nasazení ve skutečně masivním provozu není P2P princip patrně dostačující. Michael Christen, původní autor vyhledávače YaCY, chystá pro „obchodního partnera“ vyhledávací grid s modulární architekturou (postavený na Kubernetes, ElasticSearch, kibaně a RabbitMQ), který se po ukončení vývoje má stát novou generací opensource YaCy.
Slabiny a síla decentralizace
V politice vyhledávačů je obrovská moc. Rozhodují, jaké stránky zařadí do indexu, jak vysoko bude která ve výsledcích vyhledávání, tajemstvím jsou i samotné algoritmy. Decentralizovaný vyhledávač by mohl být nástrojem, jak tuto moc uchopit do svých rukou. Když zaindexuji a nasdílím jenom to, co mne zajímá, to stejné udělá pár dalších kamarádů, pokryjeme dohromady určitý výsek internetu.
Sice pořád bublinu, ale nebude bublinovatější než ta, do které nás zavírají dominantní vyhledávače s personalizovanými výsledky vyhledávání. Množství zaindexovaných stránek, jaké mají velké vyhledávače, snadno nedosáhneme. Seznam.cz má řádově miliardy, Google asi 55 miliard, YaCy je zatím na zhruba 1,5 miliardy.
Vyvážíme jej ale kurátorovaným výběrem, který možná bude zasahovat do koutů internetu, kam by jiné vyhledávače nedorazily, nebo by stránky mizely na dvacáté stránce výsledků vyhledávání. Výběr sestavený lidmi, kteří vědí, jaké zdroje potřebují prohledávat a co potřebují nalézat. Ti lidé jsme my.

Na běžném notebooku a s běžnou (ehm) domácí optikou mi crawler zaindexoval vyšší desetitisíce stránek denně. V češtině jsou počty stránek ve sdíleném indexu stále mizerné, ale u domén, které mne zajímají, jsem se dostal na vyšší proindexovanost než Google.
Podle statistik je z Root.cz zaindexovaných už 13 722 stránek, z webu abclinuxu.cz asi půl milionu, což trochu napovídá, kdo si už v české kotlině s YaCy hrál. I jednotliví uživatelé tak mohou český index YaCy výrazně ovlivnit. Zbývá otázka, kdo první zaindexuje celou českou Wikipedii. Třeba jenom ze zvědavosti, jak dlouho to bude trvat.
