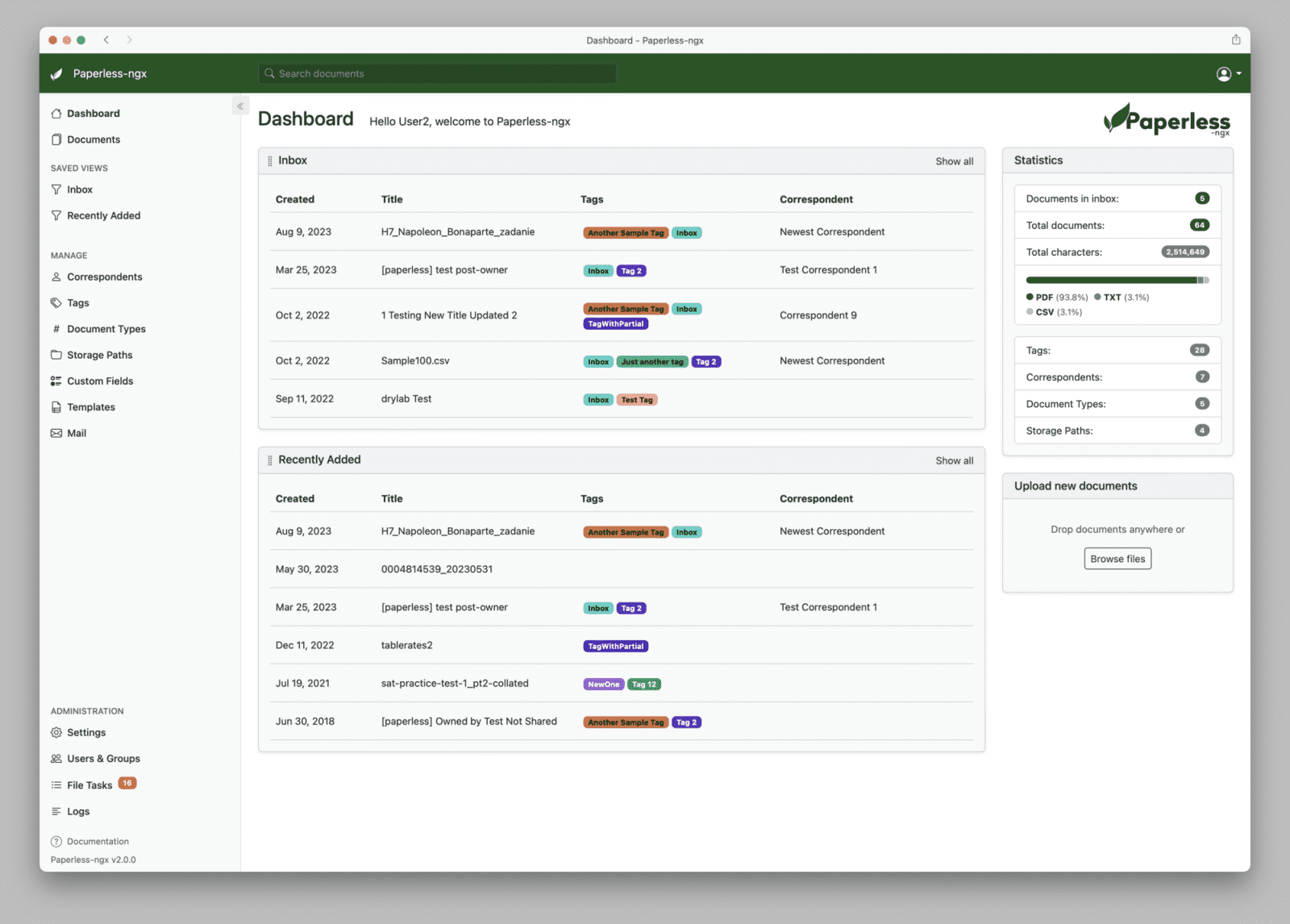
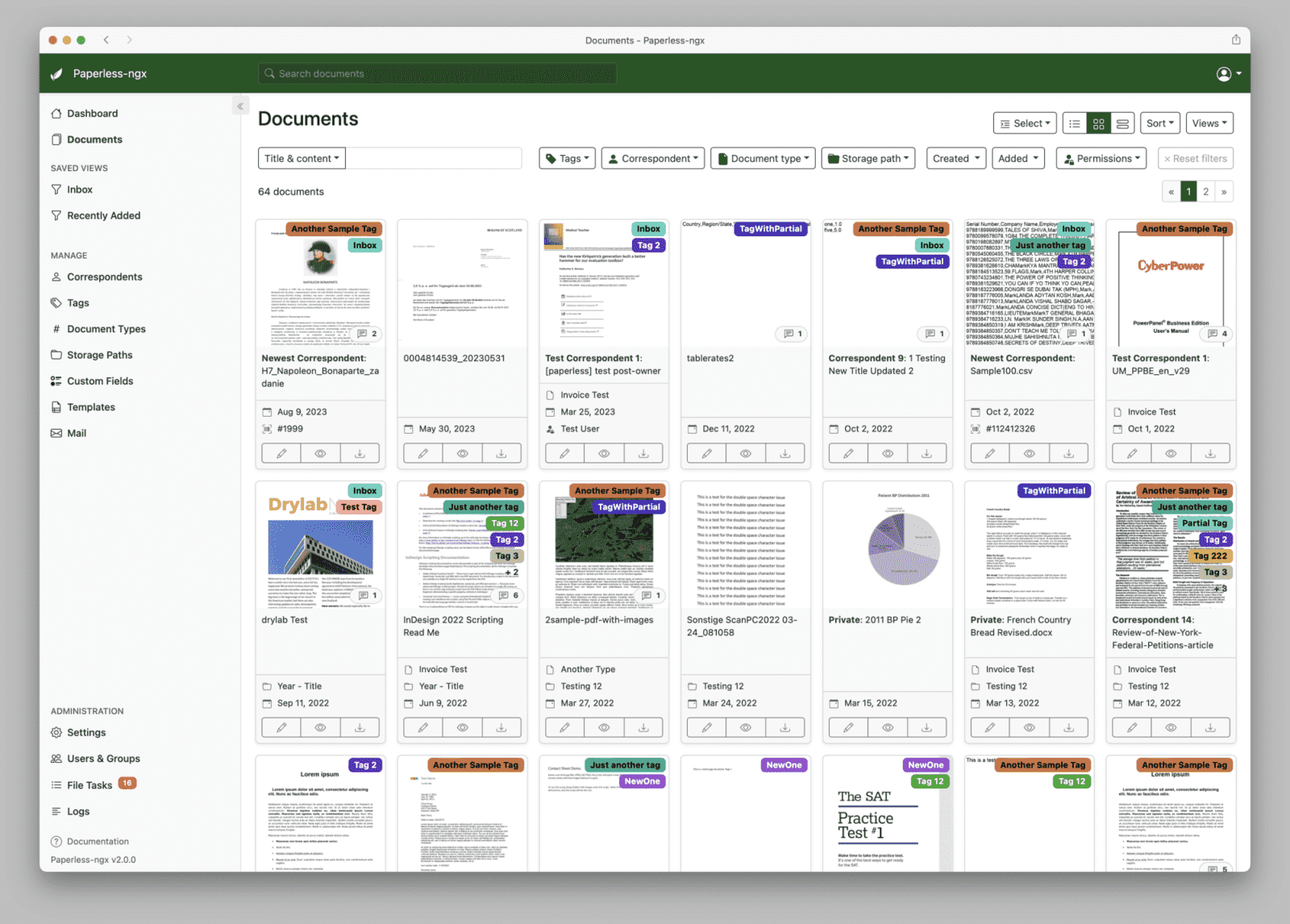
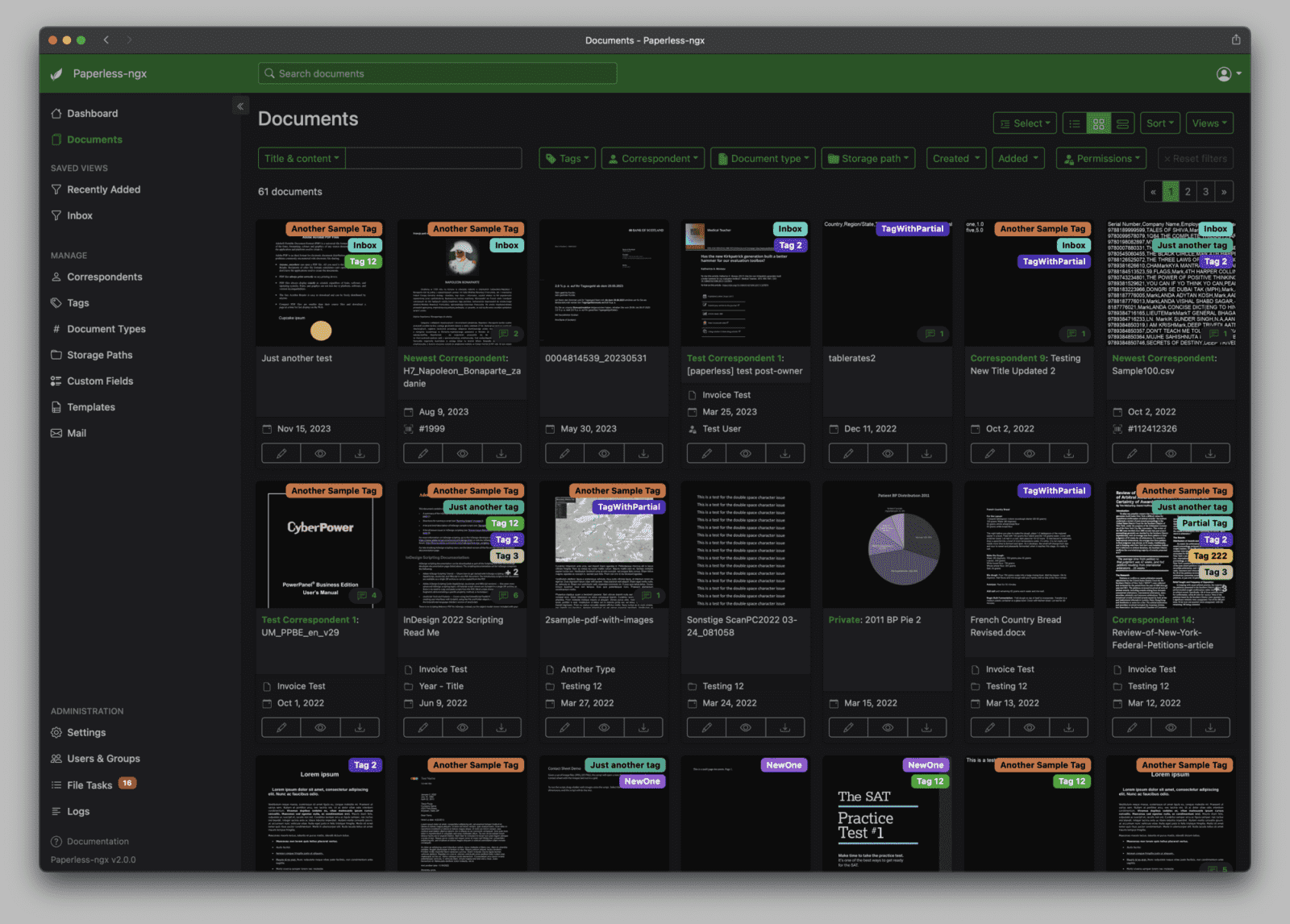
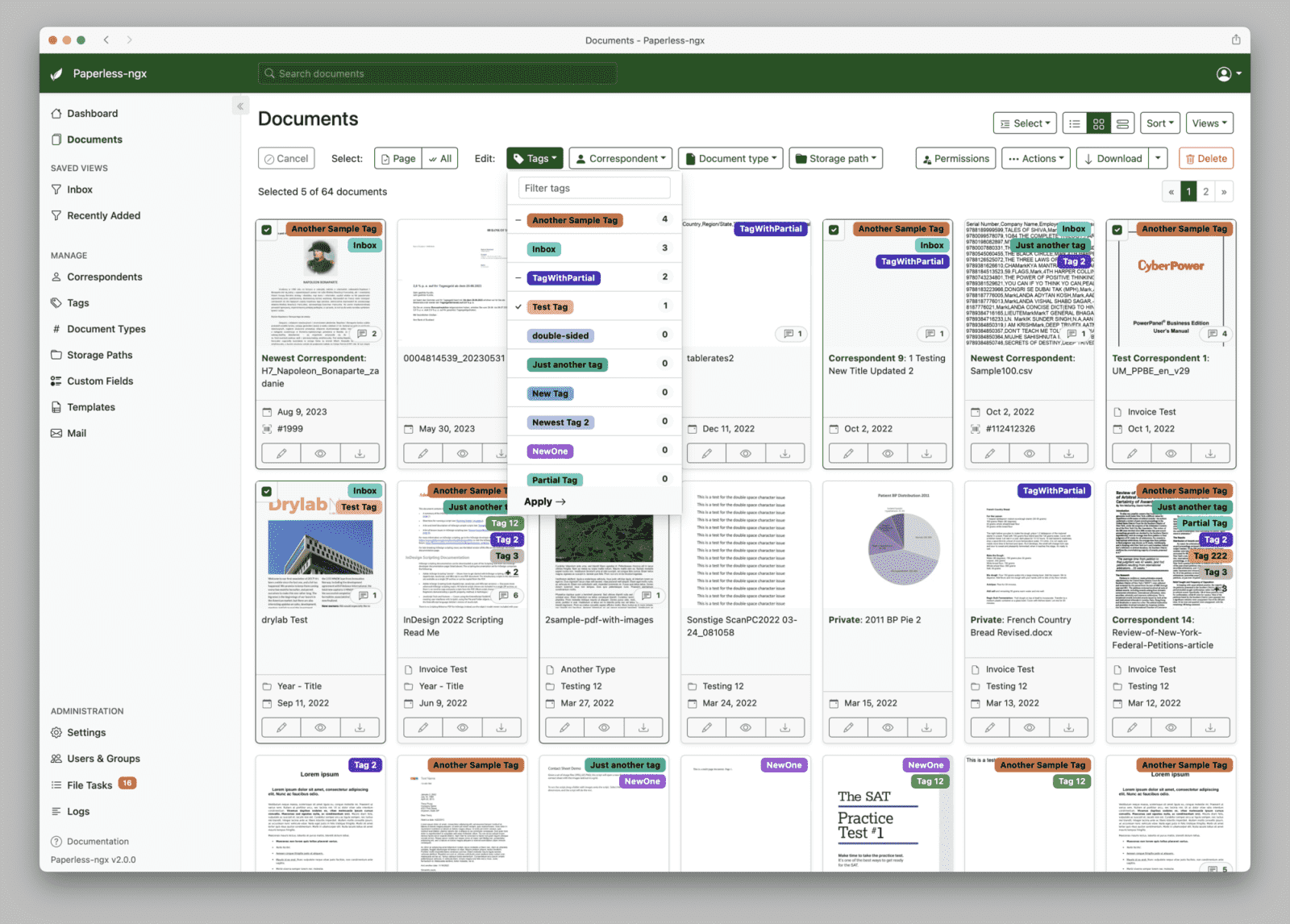
Domácí archiv často vznikne bez plánu. Nejdřív několik faktur z e-mailu, potom sken smlouvy, potvrzení ze školy, pojistka, bankovní dokument a po pár letech adresář, ve kterém se hledá podle paměti. Někdo drží názvy souborů ve tvaru rok, firma a téma. Někdo spoléhá na hledání v cizí službě. Paperless-ngx nabízí jiný postup: dokumenty zůstanou doma, ale nehledají se jen podle názvu souboru.
Co se dozvíte v článku
- Paperless není vyhledávač nad adresářem
- Stabilní řada 2.x a výhled 3.0
- Adresář consume je vstupní fronta, ne archiv
- Čeština v OCR potřebuje vlastní jazykový balík
- Metadata mají nahradit zvyk na adresáře
- ASN propojí elektronický archiv s papírovým pořadačem
- Docker Compose, PostgreSQL a Redis jako základ
- Lokální provoz není automaticky bezpečný provoz
- Záloha musí zahrnout soubory i databázi
- Sken účetního dokladu není právní jistota
- Kdy Paperless-ngx dává smysl
Paperless-ngx není grafická nadstavba nad existujícím adresářem. Je to systém pro příjem, zpracování, uložení a vyhledávání dokumentů. Podle oficiální dokumentace Paperless-ngx převezme soubor ze vstupního adresáře, provede OCR, uloží originál i archivní verzi a k dokumentu vede metadata. Na nich záleží, jestli bude archiv za rok použitelný, nebo se z něj stane jen další místo s hromadou PDF.
Paperless není vyhledávač nad adresářem
Kdo čeká něco jako pdfgrep s webovým rozhraním, bude překvapený. Paperless dokumenty nepřipojí pasivně k existující stromové struktuře. Soubory převezme, zpracuje a uloží do vlastní struktury. Ze vstupního adresáře po úspěšném zpracování zmizí. Slouží jen jako vstupní fronta; archiv vzniká až po zpracování v Paperlessu.
Tím se Paperless liší od samotného OCRmyPDF, který umí přidat do naskenovaného PDF textovou vrstvu, takže v něm lze hledat. Pro malý archiv to může stačit: skener, skript, dobře pojmenované soubory a záloha. Paperless přidává nad tuto logiku korespondenty, typy dokumentů, štítky, oprávnění, historii změn, odkazy na fyzické originály a export celého archivu.
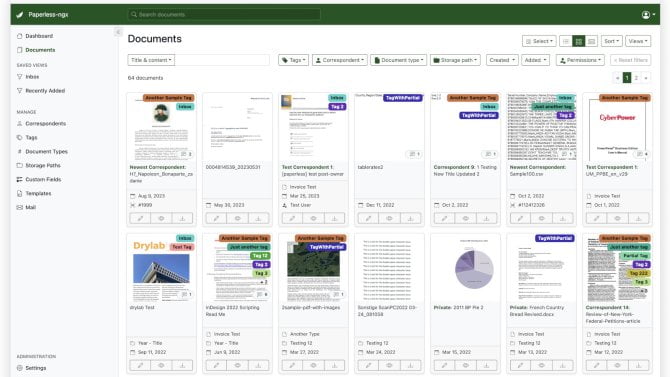
Tím ale roste složitost. Paperless už není jen sada souborů v adresáři. Hodnota archivu leží v souborech, databázi, vyhledávacím rejstříku a nastavení. Kdo si chce zachovat úplnou kontrolu nad ručně udržovaným stromem adresářů, měl by to vědět předem. Strukturu souborů na disku lze ovlivnit, ale hlavní práce má probíhat přes webové rozhraní, metadata a hledání.
Stabilní řada 2.x a výhled 3.0
Projekt je na GitHubu pod licencí GNU GPL 3.0 a navazuje na původní Paperless a Paperless-ng. V době psaní, 13. května 2026, je stabilní řadou verze 2.x; vydání Paperless-ngx 2.20.15 z 27. dubna 2026 opravuje bezpečnostní problém a projekt ho doporučuje všem uživatelům.
Vedle toho už je k dispozici veřejné předběžné vydání Paperless-ngx 3.0.0-beta.rc1, které ukazuje směr budoucí řady 3.0. Patří do něj Paperless AI, vzdálené OCR přes Azure AI, verze souborů dokumentů, rámec doplňků pro načítání dokumentů a přechod vyhledávání z Whoosh na tantivy. Pro domácí archiv je rozumnější zůstat u stabilní řady 2.x a funkce 3.0 brát zatím jako výhled.
U článku o lokálním archivu je to důležitá poznámka. Lokální provoz může přestat být čistě lokální, pokud dokumenty nebo jejich text odešlete do externí služby kvůli OCR, umělé inteligenci nebo jinému strojovému zpracování. Paperless tomu sám nebrání; rozhoduje konkrétní nastavení a použitá funkce.
Adresář consume je vstupní fronta, ne archiv
Primární cesta dokumentů do Paperlessu vede přes adresář consume. Skener, telefon, e-mailové pravidlo nebo uživatel do něj uloží PDF či obrázek, Paperless soubor najde, zpracuje a po úspěšném uložení ho ze vstupu odstraní. Pro uživatele zvyklé na běžné adresáře je to první nezvyk: ve vstupním adresáři nemá po zpracování nic zůstávat.
Prakticky to znamená, že skener může ukládat dokumenty do sdíleného adresáře nebo na server, který je zpřístupní například přes Sambu, FTP nebo jiný mechanismus. Paperless pak čte až výsledný soubor v připojeném adresáři consume. Nespravuje skenovací protokol jako takový, ale sleduje adresář, do kterého dokument doputoval. Uživatelsky udržovaný seznam skenerů pro Paperless-ngx je proto užitečný spíš jako orientační zdroj než jako nákupní doporučení.
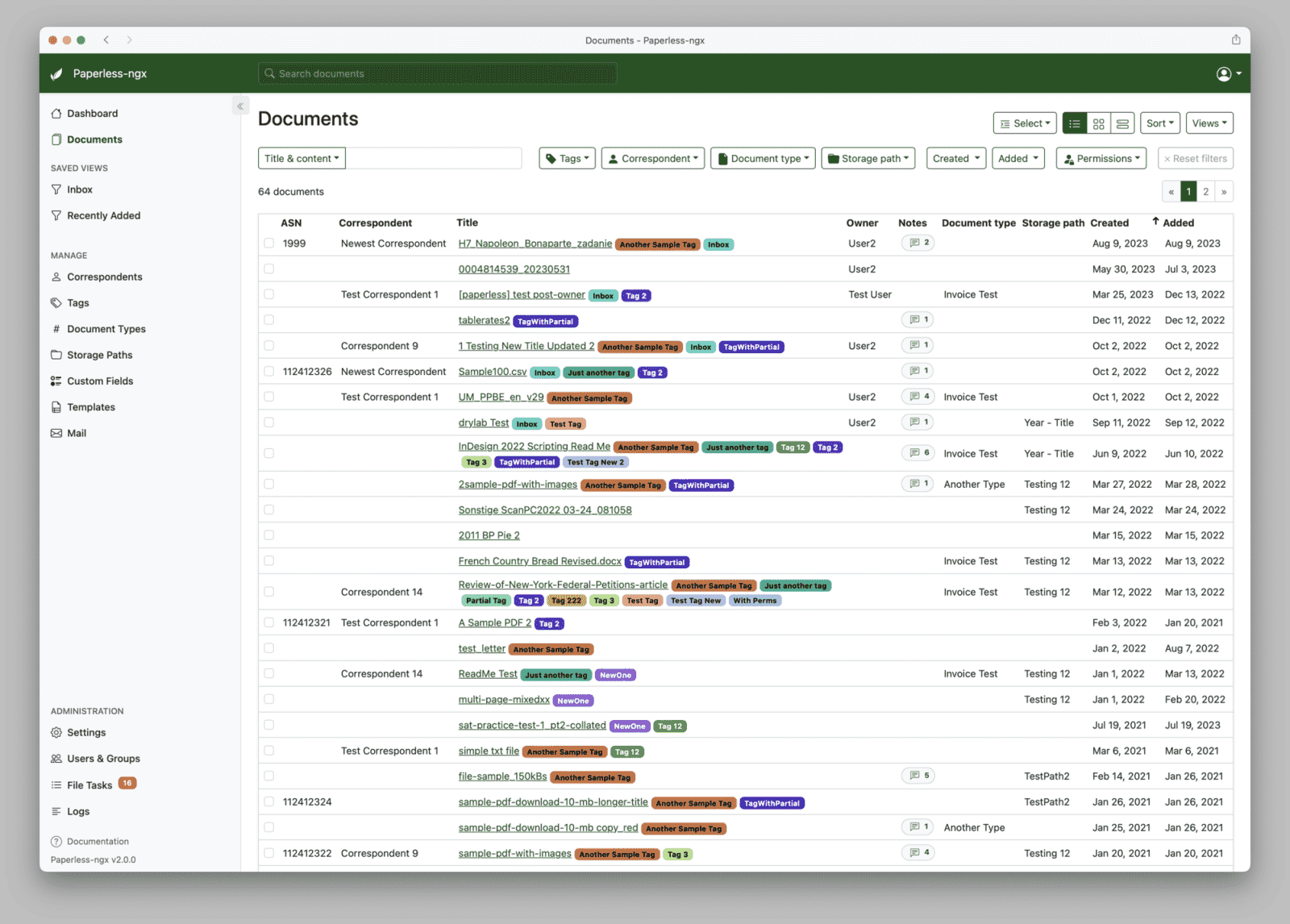
U síťových sdílení se může objevit nenápadný problém. Některé souborové systémy nebo jejich síťové implementace se nechovají dobře s inotify, takže Paperless nezaznamená nový soubor. V takovém případě pomáhá volba PAPERLESS_CONSUMER_POLLING, které nechá Paperless adresář pravidelně kontrolovat. Při pomalém zápisu ze skeneru se může hodit také prodleva před zpracováním, aby aplikace nesáhla na soubor, který ještě není celý uložený. Tyto potíže řeší dokumentace k řešení problémů a konfigurační dokumentace.
Čeština v OCR potřebuje vlastní jazykový balík
Paperless používá OCRmyPDF a Tesseract. Výchozí jazyk OCR je angličtina ( eng), takže české dokumenty potřebují vlastní nastavení. V běžné instalaci v Dockeru se jazykové balíčky doplňují přes PAPERLESS_OCR_LANGUAGES a používaný jazyk se volí přes PAPERLESS_OCR_LANGUAGE. Dokumentace uvádí pro češtinu kód ces a připomíná, že použití více jazyků zvýší nároky na procesor.
Rozumný výchozí stav pro český domácí archiv může vypadat takto:
PAPERLESS_OCR_LANGUAGES=ces PAPERLESS_OCR_LANGUAGE=ces+eng PAPERLESS_OCR_MODE=skip PAPERLESS_OCR_OUTPUT_TYPE=pdfa PAPERLESS_TIME_ZONE=Europe/Prague
Volba PAPERLESS_OCR_LANGUAGES=ces v Dockeru doinstaluje češtinu; angličtina je v obrazu mezi výchozími jazyky. Pozor na kontejnery spouštěné bez práv roota: dokumentace k instalaci i konfigurační dokumentace upozorňují, že PAPERLESS_OCR_LANGUAGES se v takovém režimu nemá používat. Kdo chce Paperless provozovat tímto způsobem, měl by si instalaci jazykových balíků ověřit předem.
Režim skip dělá OCR jen tam, kde dokument nemá textovou vrstvu. To je bezpečná výchozí volba, protože digitální faktura z e-shopu nebo banky už text většinou obsahuje a Paperless jej jen použije. Režim redo může pomoci u skenů s nekvalitním OCR ze skeneru. Režim force je agresivnější, protože dokument převede na obraz a textovou vrstvu vytvoří znovu. Funguje univerzálněji, ale může zvětšit soubor a zhoršit ostrost textu při přiblížení.
Výstup pdfa vytváří archivní PDF/A a Paperless zároveň uchovává původní vstupní soubor. To je dobrý kompromis pro domácí archiv: aplikace pracuje s archivní verzí, ale uživatel se může vrátit k originálu. Podrobné volby OCR popisuje konfigurační dokumentace Paperless-ngx.
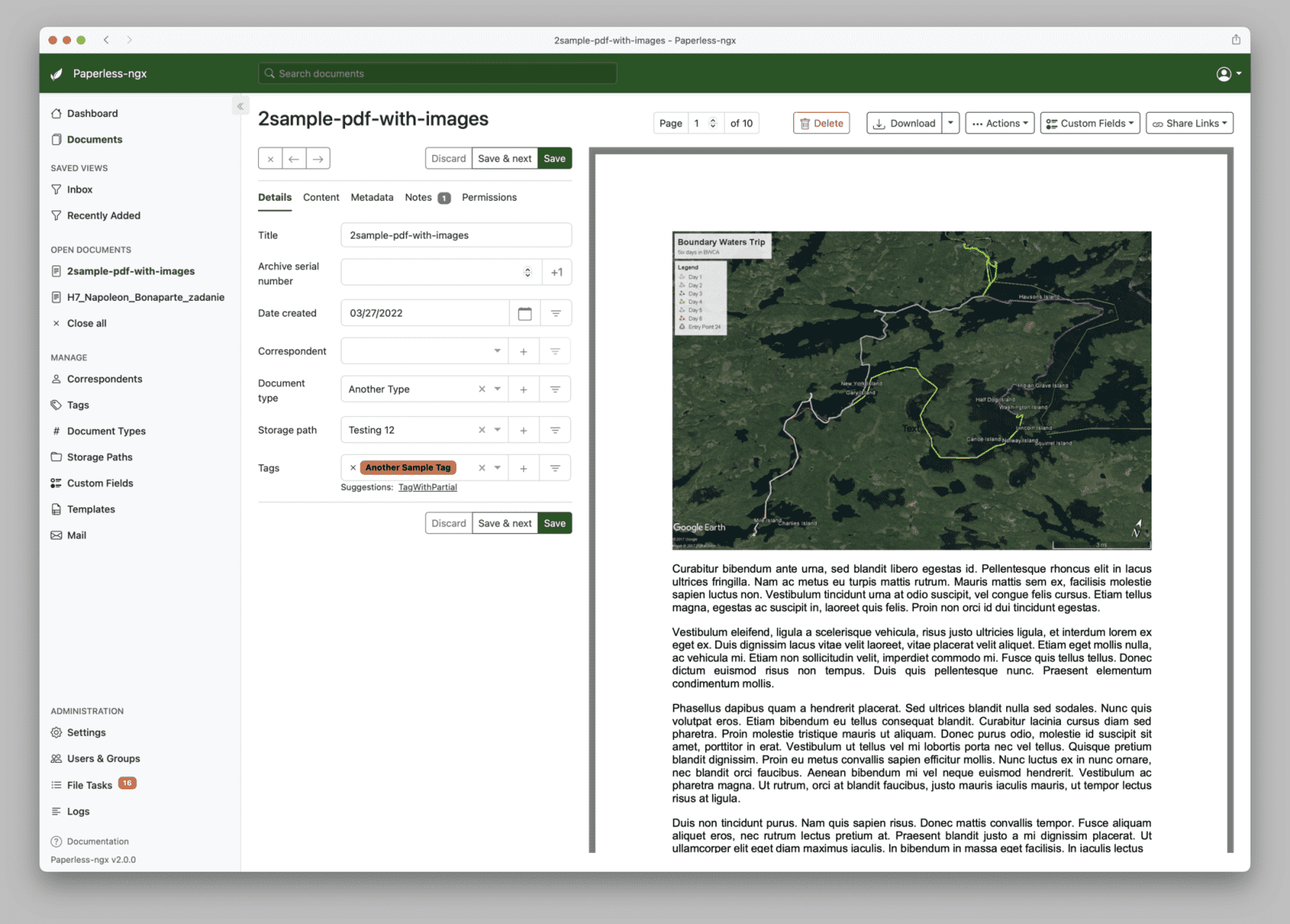
Na slabším hardwaru je potřeba počítat s tím, že OCR bude nejdražší část zpracování. Raspberry Pi nebo levný NAS mohou stačit na průběžné skenování menšího množství dokumentů, ale záleží na modelu, počtu stran, rozlišení, jazycích OCR a souběhu úloh. U větší jednorázové dávky dokumentů je lepší nastavit OCR konzervativně: například omezit PAPERLESS_OCR_PAGES, PAPERLESS_TASK_WORKERS a PAPERLESS_THREADS_PER_WORKER, případně dávku zpracovat mimo dobu, kdy server dělá něco dalšího. Součin počtu pracovních procesů a vláken by neměl překročit počet procesorových jader.
Metadata mají nahradit zvyk na adresáře
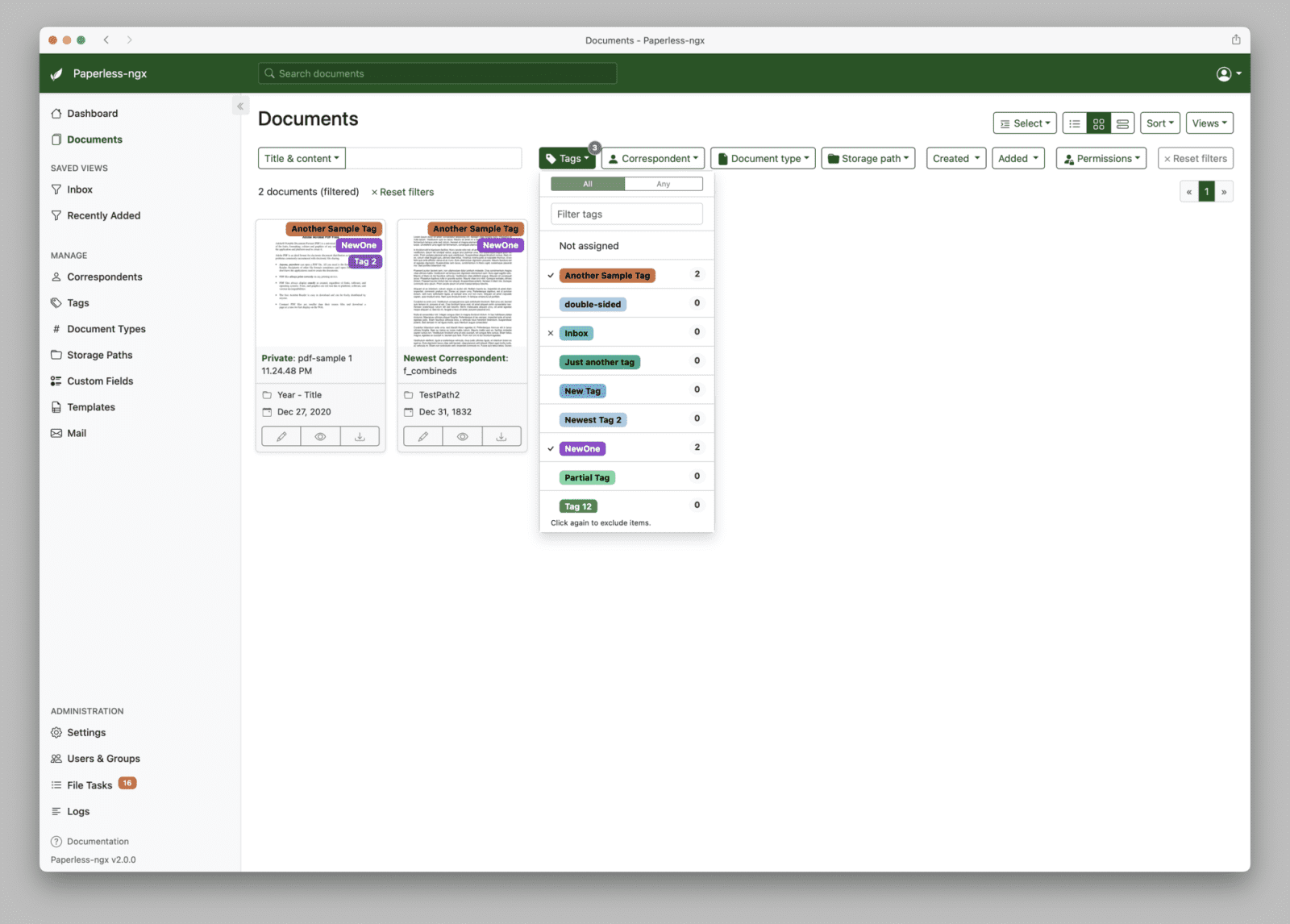
Paperless staví organizaci na metadatech. Korespondent označuje firmu, úřad nebo osobu, od níž dokument pochází nebo které byl určen. Typ dokumentu říká, jestli jde o fakturu, smlouvu, bankovní výpis nebo potvrzení. Štítek je volnější značka a jeden dokument jich může mít víc.
To je proti adresářům hlavní praktická výhoda. Faktura za pojištění auta může mít korespondenta pojišťovny, typ faktura a štítky auto, pojištění, daně a rodina. Ve stromu adresářů by ležela jen na jednom místě. V Paperlessu se najde podle firmy, částky, roku, štítku nebo slova z rozpoznaného textu.
Na začátku je dobré držet slovník metadat malý. Několik korespondentů, pár typů dokumentů a jeden dočasný štítek pro nové dokumenty stačí. Příliš podrobný slovník obvykle skončí tím, že ho uživatel přestane udržovat. Lepší je nechat pravidla růst podle skutečných dokumentů.
Paperless umí metadata přiřazovat automaticky podle textu dokumentu. Pokud se ve faktuře opakovaně objevuje název dodavatele energií nebo pojišťovny, lze nastavit pravidlo pro korespondenta. Funguje to dobře hlavně u opakujících se dokumentů, kde se mění částka a datum, ale zůstává podobné rozvržení a slovník. U smluv nebo jednorázových potvrzení bude lidská kontrola pořád potřeba.
ASN propojí elektronický archiv s papírovým pořadačem
Jedna z nejpraktičtějších funkcí Paperlessu se jmenuje ASN, archivní pořadové číslo. Každý důležitý papírový originál dostane průběžné číslo. Po naskenování se uloží do pořadače podle tohoto čísla. Když je později potřeba papír, dokument se najde v Paperlessu, přečte se ASN a fyzický originál se vytáhne z pořadače.
Tento postup je užitečný právě proto, že fyzický pořadač nemusí kopírovat logiku metadat. Papírový originál nepotřebuje ležet v adresáři pojištění, auto nebo daně. V papíru patří pod číslo, v Paperlessu může mít všechny potřebné štítky.
Pro české prostředí je to rozumnější doporučení než jednoduché „naskenujte a vyhoďte“. Běžné nedůležité papíry po skenu možná nemá smysl uchovávat. Smlouvy, pojistky, dokumenty s podpisy, pracovněprávní dokumenty, zdravotní zprávy a daňové podklady bych do koše neposílal jen proto, že OCR dopadlo dobře. Paperless zde slouží jako vyhledávač nad fyzickým archivem.
Docker Compose, PostgreSQL a Redis jako základ
Oficiální dokumentace nabízí instalační skript, šablony pro Docker Compose i instalaci přímo na systém. Pro většinu nových instalací doporučuje Docker a jako databázi PostgreSQL. SQLite je dostupná volba a u malého nasazení může fungovat, ale pro nový dlouhodobý archiv je PostgreSQL lepší výchozí varianta. Dokumentace zároveň u slabšího hardwaru připouští, že kdo chce šetřit prostředky, může u SQLite zůstat a případné zamykání řešit až v případě potíží.
Základní sestava je přehledná, ale ne bezúdržbová: Paperless, PostgreSQL, Redis, vstupní adresář a adresáře media, data a export. Redis se používá pro zpracování na pozadí a plánované úlohy. Volitelně lze přidat Tiku a Gotenberg, pokud mají do archivu chodit i kancelářské dokumenty a e-maily. Pro začátek se skeny a PDF bych je nepřidával, dokud pro ně není konkrétní důvod.
Minimální sada proměnných pro český domácí archiv může obsahovat například toto. Není to kompletní docker-compose.yml, jen ukázka důležitých voleb:
PAPERLESS_REDIS=redis://broker:6379 PAPERLESS_DBHOST=db PAPERLESS_SECRET_KEY=sem-patri-dlouhy-nahodny-retezec PAPERLESS_URL=https://paperless.example.lan PAPERLESS_OCR_LANGUAGES=ces PAPERLESS_OCR_LANGUAGE=ces+eng PAPERLESS_OCR_MODE=skip PAPERLESS_OCR_OUTPUT_TYPE=pdfa PAPERLESS_TIME_ZONE=Europe/Prague USERMAP_UID=1000 USERMAP_GID=1000
Volba PAPERLESS_SECRET_KEY musí být v reálné instalaci dlouhý náhodný řetězec, ne opsaná ukázka. Dokumentace zvlášť upozorňuje, že při vystavení služby na internet je nutné změnit výchozí hodnotu, protože je známá. Položky USERMAP_UID a USERMAP_GID mají odpovídat uživateli na hostitelském systému, aby kontejner i host mohly zapisovat do sdílených adresářů. Hodnoty se zjistí příkazy id -u a id -g. Špatně nastavená oprávnění jsou častý důvod, proč skener soubor uloží, ale Paperless ho nedokáže zpracovat nebo uložit výsledek.
Lokální provoz není automaticky bezpečný provoz
Dokumentace projektu říká přímo, že Paperless nemá běžet na nedůvěryhodném hostiteli, protože citlivé informace ukládá v čitelné podobě bez aplikačního šifrování. Nejbezpečnější variantou je podle projektu domácí server se zálohami. Pro domácí instalaci z toho plyne jednoduché pravidlo: server i zálohy musí být pod vaší kontrolou.
Starší šifrování dokumentů bylo odstraněno. Vývojáři v administrátorské dokumentaci vysvětlují, že nepřidávalo mnoho skutečné ochrany: heslo leželo v konfiguraci, text dokumentů byl stejně uložen v databázi a názvy souborů nebyly šifrované. Doporučení zní: použijte šifrovaný souborový systém, typicky například LUKS nebo šifrování v ZFS. To pomáhá při fyzické krádeži vypnutého stroje. Nechrání ale proti útočníkovi, který se dostane do běžící aplikace nebo k databázi.
Při přístupu z mobilu nebo mimo domácí síť bych Paperless nevystavoval přímo na internet. Konzervativnějším řešením je WireGuard na vlastním serveru, případně Tailscale nebo podobná síťová vrstva, pokud vám nevadí závislost na externím řízení přístupu. Dokumenty tím pořád nemusejí opustit domácí server. Pokud má služba běžet za reverzní proxy, je potřeba změnit výchozí PAPERLESS_SECRET_KEY, správně nastavit PAPERLESS_URL, povolené hosty a přihlášení. Dokumentace k hostování a bezpečnosti varuje mimo jiné před neopatrným použitím hlavičky Remote-User, která při špatném nastavení může obejít přihlášení.
Bezpečnostní aktualizace nejsou formalita. Řada 2.20 měla v roce 2026 několik vydání s bezpečnostními opravami a doporučením aktualizace. Kdo v Paperlessu uchovává smlouvy, faktury a zdravotní dokumenty, nemá provozovat roky starý kontejner jen proto, že „to pořád funguje“.
Záloha musí zahrnout soubory i databázi
Jen zkopírovaný adresář s PDF není plná záloha Paperlessu. Dokumenty sice zůstanou jako běžné soubory, ale bez databáze zmizí korespondenti, štítky, typy dokumentů, oprávnění, historie a další stav aplikace. Uživatel by se dostal k souborům, ne k původnímu archivu.
Paperless nabízí document_exporter, který vyváží dokumenty, náhledy, metadata a obsah databáze do exportního adresáře. Export lze spouštět opakovaně a kombinovat s nástroji jako rsync, Borg nebo Restic. Administrátorská dokumentace popisuje, že manifest obsahuje metadata z databáze včetně korespondentů a štítků.
Rozumný provozní model počítá se dvěma typy záloh. Jedna záloha má být pravidelný export a jeho kopie na jiné úložiště. Druhá má pokrýt databázi a adresář s dokumenty, ideálně jako součást běžné zálohy serveru. Jednou za čas má přijít test obnovy do čisté instalace stejné verze: otevřít několik dokumentů, zkontrolovat metadata a zkusit hledání.
Ověřená obnova je součást archivu, ne práce navíc. U Paperlessu to platí víc než u prostého adresáře s PDF, protože největší uživatelská hodnota neleží jen v dokumentech, ale v databázi, vyhledávacím rejstříku a pravidlech, která uživatel postupně nastavil.
Sken účetního dokladu není právní jistota
Článek o domácím archivu by neměl vyvolat dojem, že skenováním končí povinnosti kolem originálů. U soukromých dokumentů jde často o osobní toleranci k riziku. U účetních a daňových dokladů jde o zákonné požadavky.
Zákon o účetnictví v § 33 připouští účetní záznamy v listinné, technické nebo smíšené formě a převod mezi nimi. Účetní jednotka ale musí zajistit, že obsah nového záznamu odpovídá původnímu. Zákon o DPH v § 34 vyžaduje, aby byla u daňového dokladu od vystavení do konce doby uchování zajištěna věrohodnost původu, neporušenost obsahu a čitelnost.
Paperless může být výborný provozní archiv a vyhledávač. Sám o sobě ale neřeší právní průkaznost skenu ani rozhodnutí, zda lze zničit papírový originál. U podnikatelů a firem je rozumné postup konzultovat s účetní nebo právníkem podle typu dokumentu, hlavně u dokladů pro DPH, pracovněprávních dokumentů a smluv s podpisy. Pro domácnost platí jednodušší pravidlo: důležité originály nevyhazovat, ale uložit je podle ASN do pořadače.
Kdy Paperless-ngx dává smysl
Kdo chce jen prohledávat desítky PDF ročně, tomu může stačit dobře pojmenovaný adresář, OCRmyPDF a záloha. Paperless začíná dávat smysl ve chvíli, kdy dokumenty chodí pravidelně, z více zdrojů, část je skenovaná, část digitální, část e-mailem a po roce už nikdo neví, jestli má hledat podle banky, auta, daní nebo data.

Oproti komerční službě zůstávají dokumenty doma a projekt ukládá soubory běžným způsobem, takže nejste odkázáni jen na rozhraní poskytovatele. Oproti holému OCR nad adresářem získáte databázi, metadata, oprávnění, ASN a pohodlnější hledání. Lokální provoz znamená i správu aktualizací, záloh, obnovy a přístupových práv.
Paperless pomůže hlavně tam, kde je potřeba struktura, kterou obyčejný adresář s PDF nemá. Tím ale roste závislost na správě služby. Kdo ji nasadí, měl by vědět, kde jsou soubory, kde je databáze, jak se archiv obnovuje a zda některá nová funkce neposílá obsah dokumentů mimo domácí server.
