
Architektura
Co se dozvíte v článku
Základem Pingory je server, který obsluhuje jednu nebo více služeb. Služba může být přímo odpovědná za zpracování příchozích požadavků, ale může také řešit pomocné úlohy mimo hlavní zpracování požadavku — například aktualizaci pravidel WAF, objevování upstreamových serverů a podobně. Samozřejmě může jít i o kombinaci obojího.
Pojďme si připomenout funkci main() z příkladu uvedeného v minulém díle:
use async_trait::async_trait;
use pingora::prelude::*;
use pingora_load_balancing::LoadBalancer;
use pingora_load_balancing::prelude::RoundRobin;
use pingora_proxy::{ ProxyHttp, Session, http_proxy_service};
use std::sync::Arc;
pub struct LB(Arc<LoadBalancer<RoundRobin>>);
fn main() {
// Bootstrap pingora serveru
let mut my_server = Server::new(None).unwrap();
my_server.bootstrap();
// Definice upstreamu pro naši http proxy službu
let upstreams = match LoadBalancer::<RoundRobin>::try_from_iter(["127.0.0.1:8080"]) {
Ok(upstreams) => Arc::new(upstreams),
Err(e) => {
eprintln!("Failed to create load balancer: {e}");
return;
}
};
// Samotné vytvoření služby
let mut lb = http_proxy_service(&my_server.configuration, LB(Arc::clone(&upstreams)));
lb.add_tcp("127.0.0.1:8000");
// a její přidání do našeho serveru
my_server.add_service(lb);
// spuštění serveru
my_server.run_forever();
}
Nejprve vytvoříme server my_server a provedeme jeho inicializaci pomocí funkce bootstrap(). Následně přidáme službu lb, která bude zodpovědná za zpracování HTTP požadavků.
Ta potřebuje dvě věci:
- globální konfiguraci serveru,
- upstream, na který se budou požadavky přeposílat.
Posledním krokem je registrace služby do serveru a spuštění hlavní runtimové smyčky serveru pomocí funkce run_forever(), která převezme řízení hlavního vlákna a běží, dokud není server korektně ukončen.
Možná vás při čtení kódu napadne, proč při inicializaci služby používáme:
let mut lb = http_proxy_service(&my_server.configuration, LB(Arc::clone(&upstreams)));
a nestačí jednodušší zápis:
let mut lb = http_proxy_service(&my_server.configuration, Arc::clone(&upstreams));
Důvod je jednoduchý. Funkce http_proxy_service() je definována následovně:
pub fn http_proxy_service<SV>(conf: &Arc<ServerConf>, inner: SV) -> Service<HttpProxy<SV, ()>>
where
SV: ProxyHttp
Jinými slovy — potřebujeme typ, který splňuje trait ProxyHttp.
Běžný Arc><...> tento trait samozřejmě neimplementuje a my jej navíc nemůžeme doplnit přímo, protože Arc pochází ze standardní knihovny a nevlastníme jej — Rust neumožňuje přidávat cizí trait na cizí typ (tzv. orphan rule).
Proto si vytvoříme vlastní wrapper:
pub struct LB(...)
Nad tímto typem následně doplníme trait ProxyHttp. Wrapper LB tak bude reprezentovat chování proxy služby v rámci životního cyklu požadavku.
Další věcí, které si pravděpodobně všimnou ostřílení rustoví vývojáři, je absence jakékoliv inicializace async frameworku Tokio, i když jsme ho v rámci řešení závislostí balíčků (viz minulý díl) instalovali. Většinou totiž v podobných typech aplikací můžeme vidět v úvodní main.rs něco jako:
#[tokio::main]
async fn main() -> Result<(), std::io::Error> {
.
.
}
Pingora typicky inicializuje Tokio runtime interně, takže běžná aplikace nepotřebuje explicitní #[tokio::main].
Životní cyklus HTTP požadavku
Jak jsme si naznačili v předchozí kapitole, životní cyklus požadavku je v Pingoře modelován pomocí traitu ProxyHttp. Ten musíme navázat na konkrétní typ, který bude reprezentovat chování naší proxy služby.
V našem případě jsme zvolili jednoduchý wrapper:
pub struct LB(Arc<LoadBalancer<RoundRobin>>);
Jde o takzvanou tuple struct, která obsahuje jedinou položku — sdílený odkaz (Arc) na load balancer.
Typ Arc zde používáme proto, že stejná instance load balanceru může být současně sdílena mezi paralelně obsluhovanými požadavky / tasky.
Rust přitom už při kompilaci kontroluje pravidla vlastnictví, sdílení a přístupu k datům. Programátor tak musí explicitně řešit životnost a bezpečné sdílení hodnot mezi jednotlivými částmi aplikace.
Trait ProxyHttp je definován přibližně takto:
pub trait ProxyHttp {
type CTX;
// Required methods
fn new_ctx(&self) -> Self::CTX;
async fn upstream_peer(
&self,
session: &mut Session,
ctx: &mut Self::CTX,
) -> Result<Box<HttpPeer>>;
.
.
fn init_downstream_modules(&self, modules: &mut HttpModules) {
.
Pro svou proxy potřebujeme přidat pouze dvě povinné metody:
new_ctx()— vytvoří request-local context pro konkrétní HTTP požadavek,upstream_peer()— asynchronně vybere a vrátí upstreamový server, na který bude požadavek směrován.
Mnoho callbacků má výchozí implementaci a přepisujeme jen ty, které potřebujeme. Na rozdíl od mnoha moderních web frameworků totiž Pingora nepoužívá klasický middleware chain, ale spíše model založený na callback fázích podobný Nginxu.
Jednotlivé fáze zpracování tak reprezentují callbacky, které framework volá v konkrétních okamžicích životního cyklu požadavku.
V našem případě vypadal trait ProxyHttp následovně:
#[async_trait]
impl ProxyHttp for LB {
type CTX = ();
fn new_ctx(&self) -> Self::CTX {
()
}
async fn upstream_peer( &self, _session: &mut Session, _ctx: &mut Self::CTX) -> Result<Box<HttpPeer>> {
let upstream = match self.0.select(b"", 256) {
Some(upstream) => upstream,
None => return Err(Error::new(ErrorType::HTTPStatus(504)))
};
println!("upstream peer is: {upstream:?}");
let peer = Box::new(HttpPeer::new(upstream, false, "".to_string()));
Ok(peer)
}
}
Kontext CTX představuje stav vytvořený pro konkrétní HTTP požadavek, který je následně předáván jednotlivým fázím během jeho životního cyklu. Naše proxy pouze přeposílá požadavky na upstreamový server, takže si vystačíme s prázdným obsahem:
type CTX = ();
fn new_ctx(&self) -> Self::CTX {
()
}
Funkce upstream_peer() má k dispozici odkaz na naši proxy službu ( &self), aktuální Session a mutable referenci na request-local kontext CTX. Session reprezentuje downstreamové HTTP spojení a aktuálně zpracovávaný request context. Přes ni se můžeme dostat k požadavku, hlavičkám, URI, tělu požadavku a dalším informacím, které mohou ovlivnit výběr upstreamu.
V našem jednoduchém příkladu žádná data z požadavku nepotřebujeme. Z load balanceru pouze vybereme (jeden) upstream:
let upstream = match self.0.select(b"", 256) {
Some(upstream) => upstream,
None => return Err(Error::new(ErrorType::HTTPStatus(504)))
};
Použijeme metodu select(), kde pro jednoduchost používáme prázdný hash key. Druhý parametr je počet iterací, který se používá u některých algoritmů pro loadbalancer a pro tento příklad ho můžeme opomenout. Metoda select() vrací Option, protože teoreticky nemusí být žádný backend k dispozici. V takovém případě vrátíme klientovi chybu s HTTP kódem 504.
Pokud upstream najdeme, vytvoříme z něj objekt typu HttpPeer. Ten neobsahuje odpověď klientovi, ale popis cíle, kam má Pingora požadavek přeposlat — tedy adresu upstreamu, informaci o TLS a případné SNI. Framework zároveň interně řeší pooling a znovupoužití upstreamu, takže vytvoření HttpPeer neznamená nutně otevření nového TCP spojení.
let peer = Box::new(HttpPeer::new(upstream, false, "".to_string()));
Ok(peer)
Kontext
Několikrát jsme se tu zmínili, že Pingora se v návrhu životního cyklu požadavku inspirovala modelem známým z Nginxu/OpenResty. Máme fáze zpracování, které reprezentují jednotlivé callbacky a jejichž implementace je ve většině případů nepovinná. Často ale potřebujeme držet stav, který inicializujeme hned na začátku zpracování a který je pak k dispozici pro každou jednotlivou fázi. Ty ho mohou číst, měnit nebo se dle něj rozhodovat — a můžeme v něm držet třeba informace týkající se naší infrastruktury, požadavku samotného, případně flow.
Pingora proto používá tzv. per-request context, který inicializujeme v povinné metodě new_ctx() traitu ProxyHttp. Mutable referenci na tento kontext pak dostává každý callback v celém zpracování požadavku. Kontext existuje pouze po dobu zpracování konkrétního požadavku a po dokončení je zahozen.
Všimněme si také, že kontext není součástí relace nebo typu LB, ale je to svébytný objekt. Z hlediska architektury jsou tak oddělené stavy transportní vrstvy, samotné proxy a aplikačního stavu konkrétního požadavku.
U jednoduché proxy může být kontext prázdný (jako v našem úvodním příkladu):
type CTX = ();
U pokročilejší služby ale může jít o vlastní strukturu s více poli.
Příklad: základní klasifikace provozu dle klientské IP
Pojďme se teď podívat na konkrétní využití kontextu v praxi a rozšiřme si proxy o další funkce. Demonstrujeme si na krátkém příkladě, jak se kontext chová, a také rozšíříme naši proxy o další dva callbacky. Celé zpracování požadavku v krátkosti shrnuje následující diagram. Pro jednoduchost budeme veškerý kód opět psát přímo do main.rs.
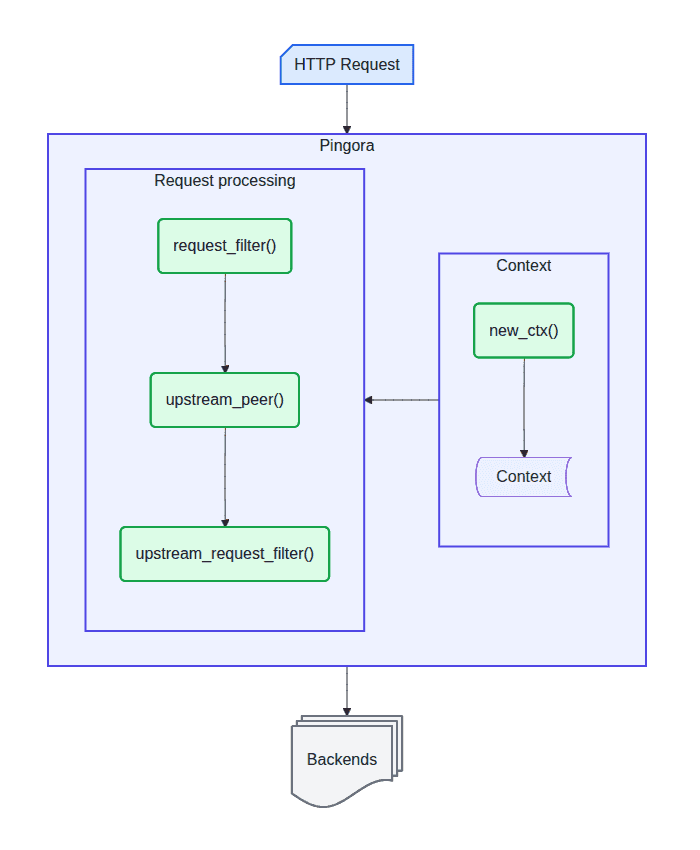
Poznámka: Náš diagram pro jednoduchost zobrazuje pouze tři fáze které používáme plus inicializaci kontextu. Pingora jich nabízí mnohem více, odkaz na kompletní flow je v sekci odkazů.
Představme si, že bychom rádi klasifikovali každý HTTP požadavek na základě IP adresy klienta a dle této klasifikace mohli dále aplikovat různé filtry, rate-limiting apod. V našem případě se spokojíme s vytvořením nové hlavičky X-Zone a přeposláním na klienta. Pro zjednodušení budeme uvažovat pouze o IPv4 klientech, IPv6 klienti budou klasifikováni výchozí hodnotou.
Požadavky dle IP rozdělíme do zón dle následujících kritérií:
- localhost: klienti přicházející z loopbacku
- private: klienti kteří volají API z privátních rozsahů
- podnet: klienti nebo služby, kteří naši proxy volají z definované Kubernetes sítě (definujeme si jeden rozsah reprezentující virtuální síť podů v rámci Kubernetes)
- public: klienti volající naši proxy z veřejných rozsahů (z internetu)
- unknown: výchozí hodnota, klient nebyl nijak klasifikován
Teoreticky bychom si mohli vytvořit pomocnou funkci, která převede IP na zónu a kterou voláme pokaždé, kdy to potřebujeme. Vhodnější ale bude určit zónu pouze na začátku zpracování a uložit ji právě do kontextu.
Definice zón
Zóny bude nejlépe reprezentovat výčtový typ (enum), který hned definujeme:
#[derive(Debug)]
pub enum Zone {
Localhost,
Private,
Public,
PodNet,
Unknown
}
Unknown reprezentuje iniciální hodnotu nezařazeného HTTP požadavku, případně takový požadavek, který nebyl poslán v rámci protokolu IPv4. Typ Zone také obalíme makrem Debug, abychom mohli jednoduše logovat jeho hodnoty.
Dále potřebujeme typ, který bude reprezentovat celý náš kontext. Prozatím půjde o jednoduchou strukturu s jediným polem zone, kterou můžeme později snadno rozšířit.
#[derive(Debug)]
pub struct Context {
zone: Zone,
}
Všimněme si, že naši strukturu Context nikde neobalujeme typem Arc případně Mutex, tak jako to bylo v případě typu LB! Důvod je prostý: kontext není sdílen mezi paralelně běžícími požadavky. V rámci jednoho zpracování je předáván jednotlivým callbackům jako mutable reference. Typový systém Rustu zajišťuje, že mutable reference ke kontextu nemůže být současně použita z více míst.
Klasifikace v rámci ProxyHttp workflow
Nyní máme všechny základní typy připravené a můžeme svůj kontext inicializovat. Nejprve změníme asociovaný typ traitu z prázdné hodnoty na naši strukturu Context. Dále v rámci implementace povinné funkce traitu new_ctx() vytvoříme jeho novou instanci a zone naplníme hodnotou Zone::Unknown.
#[async_trait]
impl ProxyHttp for LB {
type CTX = Context;
fn new_ctx(&self) -> Self::CTX {
Context { zone: Zone::Unknown }
}
.
.
Pingora tedy před vlastním spuštěním zpracování požadavku zavolá v rámci traitu metodu new_ctx() a vytvoří novou instanci struktury Context. V callbackových funkcích pak můžeme psát například:
async fn request_filter(&self, session: &mut Session, ctx: &mut Self::CTX) -> Result {
.
.
ctx.zone = Zone::from(client_ip);
.
Poznámka: Zone::from zde není definovaný — implementaci si ukážeme v dalším díle. Slouží jen jako ukázka, jak se dostat k obsahu kontextu.

V dnešním díle jsme si důkladně prošli příklad z minulého dílu a vysvětlili si některá specifika návrhu a idiomatické vzory jazyka Rust — od orphan rule přes absenci #[tokio::main] až po roli wrapperu LB.
Ukázali jsme si také, jak Pingora modeluje životní cyklus požadavku pomocí traitu ProxyHttp a jak do tohoto modelu zapadá per-request kontext. Na závěr jsme si připravili půdu pro praktický příklad: definovali jsme typy Zone a Context a naznačili, jak kontext inicializovat a předávat jednotlivým fázím zpracování. V příštím díle klasifikaci dokončíme — ukážeme si implementaci request_filter(), konverzi IP adresy na zónu a celý příklad si zkompilujeme a otestujeme.


