
Služby v distribuovaných systémech – řízení uzlů
V dalším pokračování o centrálních službách v distribuovaných systémech bych se chtěl zaměřit na problematiku řízení uzlů zapojených do sítě.
V distribuovaných systémech obvykle preferujeme nezávislou funkci jednotlivých uzlů a jejich vzájemnou kooperaci. Někdy se ovšem hodí, abychom byli schopni ovlivnit funkci uzlů z jednoho místa. Obvykle ale nejde o striktní řízení z jednoho centra, ale spíše o jistou formu orchestrace jednotlivých systémů pro zajištění lepší funkčnosti.
Příkladem může být opět síť automatizovaných meteorologických stanic. Ty mohou být nastaveny na automatizované měření meteorologických dat s intervalem jedna hodina. Pokud ovšem nastanou zajímavé meteorologické děje, mohli bychom požadovat častější měření. Pak by se nám jistě hodila možnost z jednoho místa požádat všechny zapojené stanice, aby provedly mimořádné měření. Na druhou stranu si toto měření ale nemůžeme vynutit, pokud se některá ze stanic rozhodne, že na tyto mimořádné žádosti reagovat nebude.
I v případě centrálního řízení platí, že centrální uzel nezná řízené uzly a jejich umístění. Pro komunikaci můžu tedy využít pouze předávání zpráv prostřednictvím témat (TOPIC). Řídící uzel odešle svůj požadavek na uzly do vybraného tématu. Zprávy z témat odebírají jednotlivé řízené uzly a podle svého nastavení na požadavek reagují. Je pochopitelně možné, že některé uzly budou požadavek ignorovat, nebo se k odebírání tématu vůbec nepřipojí. To ovšem centrální řídící uzel ovlivnit nemůže.
Nastavení času a požadavek na restart uzlu
Jako příklad centrálního řízení v distribuovaných systémech jsem si vybral dvě relativně jednoduché služby, na nichž bude ovšem princip fungování dostatečně zřejmý.
Komunikace v distribuovaných systémech prostřednictvím message brokeru je hodně citlivá na sladění systémového času u všech komunikujících uzlů a brokeru. Pokud nemají všechny stroje stejně nastavený systémový čas, pak TTL zprávy nastavené na jednom stroji může u příjemce vypadat jako zpráva s prošlou dobou platnosti. A obdobně je tomu u brokeru. Ten zprávy s prošlým TTL automaticky zahazuje, takže nám komunikace začne „záhadně“ drhnout.
Pokud můžeme všechny stroje synchronizovat pomocí NTP služby, pak máme vyhráno. Jsou ovšem případy, kdy se k dané službě z organizačních nebo technických důvodů dostat nemůžeme, a pak by nám mohla posloužit jako berlička distribuce času přes broker. Je zde pochopitelně problém v tom, že takto nemůžeme zajistit správné nastavení času na milisekundy, ale pro zajištění funkce komunikace to je řešení dostatečné.
Jako druhou ukázku jsem zařadil požadavek na restart uzlu. Dle situace to může být diskutabilní služba, ale berte ji prosím jako další ukázku.
Následující diagram zachycuje interakci mezi uzly (rolemi) s návazností na centrální řídící uzel:
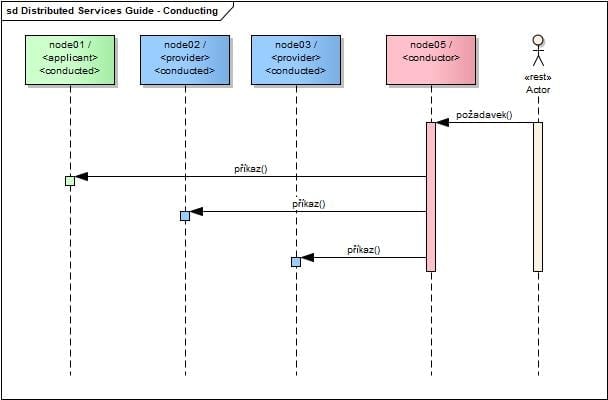
Řídícím uzlem je stroj s přidělenou rolí <conductor>. Ten odesílá požadavky do tématu topic:CONDUCT.
Řízené stroje mají přidělenou roli <conducted>. Ta zajišťuje napojení uzlu na téma topic:CONDUCT, vyzvednutí požadavku a patřičnou reakci na něj. Řídící uzel se zpětně nedozví, které uzly a jak na jeho požadavek reagovaly.
Pro předání požadavku na stroje jsem rozšířil definici entit o následující typy zpráv:
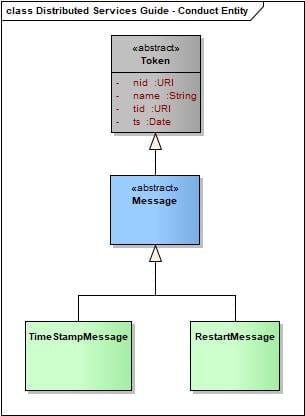
Jedná se zde o TimeStampMessage, který plní úlohu časové známky generované centrálním uzlem. Dále pak RestartMessage, což je požadavek na restart řízeného uzlu.
Role <conductor>
Tato role zajistí uzlu jeho řídící úlohu. V mém případě bude zajišťovat automatické odesílání časových známek. Dále bude možné přes aplikační rozhraní vyvolat požadavek na restart všech řízených uzlů.
Komunikace probíhá přes téma definované v hlavním konfiguračním souboru pod označením services.conduct.uri. Díky tomu toto URI zná jak role <conductor>, tak také role <conducted>.
Komunikační funkce
Komunikační funkce pro tuto roli jsou definovány ve třídě ConductorCamelRoutes:
@Component
@Profile(value = "conductor")
public class ConductorCamelRoutes extends RouteBuilder {
private static final Logger logger = LoggerFactory.getLogger(ConductorCamelRoutes.class);
@Autowired
TokenFactory factory;
@Override
public void configure() throws Exception {
from("timer://conductor-ts?fixedRate=true&delay=1000&period={{conduct.timestamp.period:30000}}&repeatCount=0").routeId("conductor-ts")
.process(exchange -> exchange.getMessage().setBody(factory.tokenInstance(TimeStampMessage.class)))
.to("{{services.conduct.uri}}");
from("direct:conductor-restart").routeId("conductor-restart")
.to("{{services.conduct.uri}}")
.choice()
.when(simple("${camelContext.hasEndpoint(direct:conductor-audit)} != null"))
.wireTap("direct:conductor-audit")
.end();
}
}
Ve třídě jsou definovány dvě cesty:
- conductor-ts
V pravidelných intervalech vytváří novou instanci entity TimeStampMessage a odesílá ji na URI definované parametrem v hlavním konfiguračním souboru services.conduct.uri (v mém případě se jedná o topic:CONDUCT).
Interval mezi generovanými časovými známkami je možné nastavit pomocí parametru conduct.timestamp.period, implicitně je to 30 sekund.
- conductor-restart
Tato cesta je velice jednoduchá. Zprávu, kterou dostane na svůj vstup, odešle do tématu dle parametru services.conduct.uri.
Navíc je zde opět ukázka „ocásku“ pro napojení na auditní systém, což vám ukážu v rámci ověřování funkce
Aplikační rozhraní
Požadavek na restart řízených uzlů chci vyvolávat prostřednictvím aplikačního rozhraní. Proto potřebuji jednu REST službu, a ta je v ConductorServiceController:
@RestController
@Profile(value = "conductor")
public class ConductorServiceController {
private static final Logger logger = LoggerFactory.getLogger(ConductorServiceController.class);
@Autowired
private ProducerTemplate producerTemplate;
@Autowired
TokenFactory factory;
@RequestMapping(value = "/conduct/restart")
public void claimRestart() throws Exception {
producerTemplate.sendBody("direct:conductor-restart", factory.tokenInstance(RestartMessage.class));
}
}
Jedná se o jednoduchou implementaci, kdy vytvořím entitu RestartMessage a odešlu jí do Camel cesty „direct:conductor-restart“. Žádnou odpověď neočekávám.
Role <conducted>
Uzel s touto rolí bude reagovat na řídící požadavky získané z tématu podle konfiguračního parametru services.conduct.uri. Dle své implementace se rozhodne, jak na ně bude reagovat.
Komunikační funkce
Všechny funkce implementující reakce na řídící požadavky jsou součástí ConductedCamelRoutes:
@Component
@Profile(value = "conducted")
public class ConductedCamelRoutes extends RouteBuilder {
private static final Logger logger = LoggerFactory.getLogger(ConductedCamelRoutes.class);
@Override
public void configure() throws Exception {
from("{{services.conduct.uri}}").routeId("conducted")
.choice()
.when(simple("${camelContext.hasEndpoint(direct:conducted-audit)} != null"))
.wireTap("direct:conducted-audit")
.endChoice()
.otherwise()
.end()
.choice()
.when(body().isInstanceOf(TimeStampMessage.class))
.process(exchange -> {
TimeStampMessage msg = exchange.getMessage().getBody(TimeStampMessage.class);
logger.info("Setting machine time to: {}", new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss.SSSXXX").format(msg.getTs()));
})
.when(body().isInstanceOf(RestartMessage.class))
.process(exchange -> {
logger.info("Restarting machine ...");
Application.restart();
})
.otherwise()
.process(exchange -> logger.warn("Conduct Command '{}' is not supported!", exchange.getMessage().getBody(Message.class).getClass().getCanonicalName()))
.end();
}
}
Nejdříve ověřuji, jestli nemám zapnutou auditní funkci, a pokud ano, pak požadavek odešlu do auditního systému. Udělám to dříve než začnu reagovat na řídící požadavek, abych předešel problémům s restartem aplikace.
Dále zjistím, jakého typu řídící požadavek je, a podle toho na něj reaguji:
- TimeStampMessage – v tomto případě pouze vypíšu hlášení do logu. Nemá smysl, abych se pokoušel nastavit čas na stejném stroji, na kterém testuji všechny uzly.
- RestartMessage – vyvolám metodu restart() hlavní třídy aplikace. Ta zajistí zastavení kontextu Spring a jeho opětovné nastartování.
Takto vypadá metoda pro restart aplikačního kontextu v třídě Application:
public static void restart() {
ApplicationArguments args = context.getBean(ApplicationArguments.class);
Thread thread = new Thread(() -> {
context.close();
context = SpringApplication.run(Application.class, args.getSourceArgs());
addContextListeners();
});
thread.setDaemon(false);
thread.start();
}
Nastal čas na vyzkoušení
Ukázka základní funkčnosti
Nejdříve si vyzkoušíme konfiguraci uzlů tak, jak jsem je naznačil v sekvenčním diagramu výše. Spustím tedy uzly s těmito rolemi:
- node01 – applicant, conducted
- node02 – provider, conducted
- node03 – provider, conducted
- node05 – conductor
Příkazy spustit každý v samostatném terminálu:
java -jar target/distributed-services-guide-1.0.jar --spring.profiles.active=node01,conducted java -jar target/distributed-services-guide-1.0.jar --spring.profiles.active=node02,conducted java -jar target/distributed-services-guide-1.0.jar --spring.profiles.active=node03,conducted java -jar target/distributed-services-guide-1.0.jar --spring.profiles.active=node05
V logu uzlů node01, node02 a node03 byste měli vidět hlášení o nastavení času uzlu, nějak takto:
2021-03-24 12:27:41.622 INFO 4182 --- [nsumer[CONDUCT]] c.d.d.route.ConductedCamelRoutes : Setting machine time to: 2021-03-24T12:27:41.598+01:00 2021-03-24 12:27:51.626 INFO 4182 --- [nsumer[CONDUCT]] c.d.d.route.ConductedCamelRoutes : Setting machine time to: 2021-03-24T12:27:51.596+01:00 2021-03-24 12:28:01.611 INFO 4182 --- [nsumer[CONDUCT]] c.d.d.route.ConductedCamelRoutes : Setting machine time to: 2021-03-24T12:28:01.590+01:00
Nyní si můžeme vyzkoušet, zda budou uzly reagovat na požadavek restartu; z nového terminálu vyvolám REST službu:
[raska@localhost ~]$ curl -s http://localhost:8085/conduct/restart
Všechny tři řízené uzly, tedy node01, node02 a node03, by se měly restartovat.
Uzel bez role řízeného
Můžeme si ještě vyzkoušet některý uzel bez role <conducted>. Ten by neměl reagovat na žádné požadavky z uzlu node05.
Zkuste si zastavit uzel node02 a spustit je opět bez role conducted takto:
java -jar target/distributed-services-guide-1.0.jar --spring.profiles.active=node02
V logu by se již neměly objevovat hlášení o nastavení systémového času. Uzel by také neměl reagovat na požadavek restartu.
Rozšíření auditního systému
V předchozím dílu jsem se prakticky zabýval ukázkou auditního systému pro uzly s rolí <applicant> a <provider>. Ono je ale dobré rozšířit auditní záznamy i na řídící funkce. Proto jsem do komunikačních funkcí role <audited> doplnil Camel cesty pro audit rolí <conductor> a <conducted>. Obě cesty zaznamenávají událost vyvolání a provedení restartu systému (událost nastavení systémového času jsem do auditních záznamů nezařadil).
Vyzkoušet si to můžeme tak, že spustíme uzly s rolemi:
- node01 – applicant, conducted, audited
- node02 – provider, conducted, audited
- node03 – provider, conducted, audited
- node04 – auditor
- node05 – conductor, audited
Příkazy spustit každý v samostatném terminálu:

java -jar target/distributed-services-guide-1.0.jar --spring.profiles.active=node01,conducted,audited java -jar target/distributed-services-guide-1.0.jar --spring.profiles.active=node02,conducted,audited java -jar target/distributed-services-guide-1.0.jar --spring.profiles.active=node03,conducted,audited java -jar target/distributed-services-guide-1.0.jar --spring.profiles.active=node04 java -jar target/distributed-services-guide-1.0.jar --spring.profiles.active=node05,audited
A následně si opět vyzkoušíme restart všech uzlů:
[raska@localhost ~]$ curl -s http://localhost:8085/conduct/restart
No a teď bychom měli vidět v auditní databázi záznamy o vyvolání a provedení restartu od všech auditovaných uzlů:
[raska@localhost ~]$ curl -s http://localhost:8084/audit | jq .
[
{
"nid": "local:node02",
"name": "node02",
"tid": "uuid:b2c34139-3ba4-4b7f-bcca-7c4bc3e49fb7",
"ts": "2021-03-24T11:48:02.930+00:00",
"event": "conducted.restarted",
"severity": "info",
"requestFrom": "local:node05"
},
{
"nid": "local:node03",
"name": "node03",
"tid": "uuid:b2c34139-3ba4-4b7f-bcca-7c4bc3e49fb7",
"ts": "2021-03-24T11:48:02.961+00:00",
"event": "conducted.restarted",
"severity": "info",
"requestFrom": "local:node05"
},
{
"nid": "local:node01",
"name": "node01",
"tid": "uuid:b2c34139-3ba4-4b7f-bcca-7c4bc3e49fb7",
"ts": "2021-03-24T11:48:02.944+00:00",
"event": "conducted.restarted",
"severity": "info",
"requestFrom": "local:node05"
},
{
"nid": "local:node05",
"name": "node05",
"tid": "uuid:b2c34139-3ba4-4b7f-bcca-7c4bc3e49fb7",
"ts": "2021-03-24T11:48:03.027+00:00",
"event": "conductor.restart",
"severity": "info"
}
]

