
Máte-li pochybnosti o tom, co si v programátorské praxi představit pod pojmem „strom“, přečtěte si nejprve předcházející kapitolu tohoto seriálu nazvanou Binární stromy.
Jestliže (nám už dobře známé) binární stromy byly spíše jednoúčelové a sloužily k rychlému vyhledávání dat, mnohonásobné stromy implementují obecný datový typ „strom“ se vším, co k tomu patří. Proto také mají rozhodně širší použití.
Typ mnohonásobný strom (N-ary tree) je vystavěn kolem struktury GNode velkým množstvím funkcí. Samotný datový záznam GNode reprezentuje jeden prvek (uzel) stromu.
struct GNode
{
gpointer data;
GNode *next;
GNode *prev;
GNode *parent;
GNode *children;
};
Pointer data je obecný ukazatel na data, která chcete ve stromu shromažďovat. Položky next a prev jsou pointery na následujícího a předcházejícího sourozence daného uzlu. (Sourozencem chápejte všechny uzly, které mají stejného rodiče). Položka parent pak je pointer na rodiče uzlu nebo NULL, pokud daný GNode je kořenem stromu. Položka children ukazuje na prvního potomka uzlu. Ostatní potomci jsou dosahováni použitím pointerů next a prev.
Na strom tedy můžeme pohlížet jako na jakýsi vícerozměrný či vnořený seznam. V jednom směru jsou prvky zřetězeny dvojicemi parent a children a ve druhých směrech pak pointery next a prev (viz obrázek).
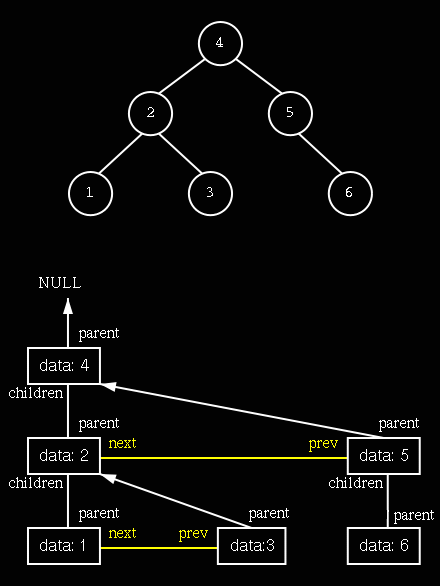
Obrázek 1 – Ukázka stromu a jeho realizace v paměti prostřednictvím uzlů GNode (kde chybí ukazatel, např. uzlu 6 chybí next, prev i children, znamená to, že je stejně NULLový)
Příklad:
Tak například, máme-li v paměti strom jako na obrázku 1, uchováváme pouze pointer root na kořen (uzel 4) a chceme získat adresu uzlu 2, napíšeme něco jako:
root->children Kdybychom chtěli adresu uzlu 5, napíšeme:
root->children->next a pro uzel 6 stačí použít kód:
root->children->next->children Nové uzly stokrát jinak
GNode* g_node_new(gpointer data); …vytvoří nový uzel GNode, který bude uchovávat zadaná data. Funkce se obvykle používá k vytvoření kořene stromu. Vrácená hodnota je pointer na nově alokovanou strukturu GNode.
Vkládání již vytvořených uzlů do stromu
Funkce, které budou následovat, slouží k připojení již vytvořeného uzlu na nějaké místo existujícího stromu. Vkládaný uzel může být i kořenem dalšího stromu. Smíte tedy vkládat jednotlivé uzly i spojovat dva stromy dohromady. Návratovou hodnotou je vždy vkládaný uzel.
GNode* g_node_insert(GNode *parent, gint position, GNode *node); …do daného stromu vloží GNode node jako position-tého potomka uzlu parent. Je-li position větší nebo rovno nule, node se vloží jako position-tý potomek uzlu parent (ostatní sourozenci se posunou). Index sourozenců začíná on nuly, takže první potomek odpovídá indexu 0, druhý 1 apod. Chcete-li tedy, aby node byl do seznamu potomků uložen na první pozici, zvolte position rovno 0. Je-li position menší než nula, uzel node se vloží na konec seznamu potomků.
GNode* g_node_insert_before(GNode *parent, GNode *sibling, GNode *node); …do stromu přidá GNode node jako potomka uzlu parent tak, aby se v seznamu potomků nacházel před sourozencem sibling. Je-li sibling roven NULL, node se vloží jako poslední potomek uzlu parent.
#define g_node_append(parent, node) …makro pro přidání uzlu node na pozici posledního potomka uzlu parent.
A konečně, funkce
GNode* g_node_prepend(GNode *parent, GNode *node); …přidá uzel node na pozici prvního potomka uzlu parent.
Vytvoření nového uzlu a jeho vložení do stromu
Každý programátor je od nátury lenoch a tvůrci knihovny GLib to dobře vědí. Proto pro náš komfort připravili následující čtveřici maker:
#define g_node_insert_data(parent, position, data)
#define g_node_insert_data_before(parent, sibling, data)
#define g_node_append_data(parent, data)
#define g_node_prepend_data(parent, data) Tyto makra (světe div se), dělají skoro přesně totéž, co funkce podobného jména, které jsem popsal výše. Jediné, co vykonají navíc, je, že vkládaný uzel nově alokují funkcí g_node_new() a uloží do něj data. Vrácená hodnota makra je pointer na nový uzel.
Tedy, g_node_insert_data() vloží nový uzel s daty data jako position-tého potomka uzlu parent, g_node_insert_data_before() jej vloží na pozici před sourozence sibling, g_node_append_data() na konec a g_node_prepend_data() na začátek seznamu potomků uzlu parent.
Příklad:
Stejného účinku jako volání makra
g_node_append_data(nejaky_uzel, nejaka_data); byste dosáhli napsáním
g_node_append(nejaky_uzel, g_node_new(nejaka_data)); nebo
g_node_insert_before(nejaky_uzel, NULL, g_node_new(nejaka_data)); do čehož se makro g_node_append_data() ve skutečnosti rozvine.
Rozdělování stromů
void g_node_unlink(GNode *node); Tato funkce rozdělí strom, jehož součástí je i uzel node, na dva stromy tak, že kořenem nového stromu bude právě uzel node.
Uvolnění stromu z paměti
Jako obvykle, na tomto místě nás čeká klasická funkce na uvolnění datové struktury z paměti.

void g_node_destroy(GNode *root); …uvolní z paměti uzel root a všechny jeho následovníky. Není-li root kořenem stromu, dojde nejprve k odpojení podstromu voláním g_node_unlink(root) a následné dealokaci tohoto nového stromu. Uchovává-li strom nějaká dynamicky alokovaná data, musíte sami dealokovat nejprve je.
Pokračování příště.

