Názory k článku Interní reprezentace numerických hodnot: od skutečného počítačového pravěku po IEEE 754–2008
-

K tomuto tématu může být zajímavý i datový typ Numeric v Postgresu https://www.postgresql.org/docs/9.3/static/datatype-numeric.html
-
atarist (neregistrovaný)
hele mas pravdu, protoze BASIC nikdy nelze:
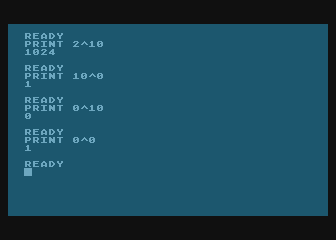
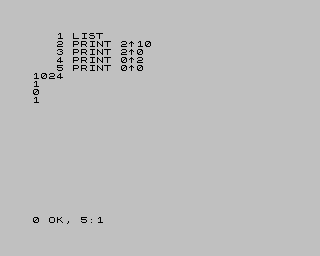
https://mojefedora.cz/wp-content/uploads/2017/09/atari000.png
https://mojefedora.cz/wp-content/uploads/2017/09/speccy.png -
 Pavel TišnovskýZlatý podporovatel
Pavel TišnovskýZlatý podporovatelProtože ve skutečnosti IEEE 754-2008 (https://www.csee.umbc.edu/%7Etsimo1/CMSC455/IEEE-754-2008.pdf) specifikuje *tři* různé funkce pro výpočet x^y: pow(), pown() a powr().
Funkce pown(x, 0) přitom vrací 1 pro každé x, klidně i pro 0, NaN nebo nekonečno, přitom by tato funkce měla akceptovat jen celočíselné exponenty (ostatně právě pown asi myslel Knuth, když psal, že 0^0 by mělo být 1)
Funkce pow(x, 0) v tomto případě bude pracovat podobně, zato powr(0, 0), powr(-0, 0), powr(0, -0) i powr(-0, -0) bude signalizovat neplatnou operaci.
Na druhou stranu céčkovské pow(3), powf(3), powl(3) odpovídají "nepřesné" funkci pow() podle normy.
-
karna48 (neregistrovaný)
Je to definováno hlavně z praktických důvodů pro konzistenci např. binomické věty
https://cs.wikipedia.org/wiki/Umoc%C5%88ov%C3%A1n%C3%AD#Nula_na_nultou
-
Pavel (neregistrovaný)
Ale zase je spousta případů, kdy nepotřebuju, aby 0^0 = 1, například i v tom článku zmíněná funkce a^x, když chci, aby byla spojitá i pro a = 0 a x -> 0.
Co jsem viděl binomickou větu (naříklad), tak tam vždy bylo uvedeno, že platí pro a,b != 0, a ještě že pro účely této věty 0! = 1, i když to je mnohem šířeji akceptováno, než že 0^0 = 1 (protože zatímco to první je speciální případ dobře definované Gamma funkce, to druhé prostě pravda není).
-
atarist (neregistrovaný)
K tomu atárku jen dodám, že ty originální FP rutiny jsou skutečně hodně pomalé. Používaly se i v dalších jazycích, ale výjimkou byl BASIC XE, který měl vlastní rutiny a byl rychlejší, a to podstatně (https://atariage.com/forums/topic/269132-bench-marking-fp-routines-with-fractal-zoom/ https://en.wikipedia.org/wiki/Optimized_Systems_Software#BASIC_XE).
Dá se to říct i jinak - pokud někdo pracoval na programu s mnoha FP výpočty, bylo lepší použít BASIC XE než se snažit o assembler se starými FP rutinami (přesný opak tvorby her :-)
-
Pavel (neregistrovaný)
IBM z/Architecture používá i dekadický floating point formát, ve kterém ukládá 3 dekadické cifry do 10 bitů.
Možná někomu může připadat takový formát obskurní a zbytečný, ale je nutné si uvědomit, že pro učetnictví jsou uzákoněny přesné postupy výpočtů včetně zaokrouhlování, a to pro dekadická čísla. S binární reprezentací čísel je velmi obtížné tyto zákonem dané postupy implementovat. Proto je dekadická vnitřní implementace důležitá.
-
TK (neregistrovaný)
Pro serializaci doporucuji Google protocol buffers (https://developers.google.com/protocol-buffers/docs/overview), interne pouzivane v Googlu, multiplatformni, bindingy do ruznych jazyku.
Pripadne jako datovy format (napr. pro maticova data) jsme na skole kdysi davno pouzivali NetCDF (https://en.wikipedia.org/wiki/NetCDF) pripadne muzete zkusit HDF5 (https://en.wikipedia.org/wiki/Hierarchical_Data_Format). -
armabeton (neregistrovaný)
Tak textový formát nemusí být marný, pokud těch dat nejsou megabajty, navíc máš jistotu, že i po letech to +- někdo přeluští, i když například dnešní platformy budou v muzeu :-) Měl by sis jen pohlídat konverze, aby se neztrácela přesnost při printf/scanf (nebo ekvivalentech v jiných jazycích). Někdy dokonce textový formát zabere míň než binární serializace doublů, ale hodně záleží na tom, o jaké hodnoty se jedná.
-
Petr M (neregistrovaný)
Pamatuješ na ten nedávný problém s šachovým programem, kde se na serveru ukládaly partie jako číslo, appka je brala jako číslo, přenos jako text a stejně to nefungovalo? Na jedné straně to byl INT32, na druhé INT64 a těch partií už bylo moc... Text spolehlivě zabil typovou kontrolu.
-
armabeton (neregistrovaný)
bylo by to horsi, protoze upravou binarniho protokolu by se muselo sahnout na vsechny appky, ktere to API mohly vyuzivat a zmenit vsechno NARAZ. Takto se opravi jen ta jedna, ktera tam mela int32, navic mozna ani neni nutny prepisovat dokumentaci, protoze 'textovy int' se muze natahovat na jakykoli pocet cifer, kdezto u binarniho protokolu je to mega problem.
-
j (neregistrovaný)
Jo, ale z pohledu uzivatele by vysledek byl tentyz - proste by to nefungovalo pripadne delalo psi kusy. Jinak samozrejme kazdej blbec vi ze soucasti kazdyho api nebo protokolu ma byt verze a proto prakticky nikdy neni. Presne z toho duvodu, kdyz potrebujes neco nekde zmenit, tak proste umoznis nejakou dobu soubeh verzi(nebo minimalne appce reknes, ze tu jeji verzi uz nepodporujes).
-
Ňuf (neregistrovaný)
ad V minulosti se však používaly i jiné báze, například 8, 16 nebo i 10, s nimi se však již dnes prakticky nesetkáme
Báze 10 se používá poměrně často, třeba v .NETu ji používá typ decimal. Používá se všude tam, kde je nutné desetinné číslo v desítkové soustavě reprezentovat přesně, bez zaokrouhlení. Takže třeba všude tam, kde se počítá s penězi. Za program, kde by hodnota bankovního účtu byla reprezentovaná typem IEEE 754 by vás banka rozhodně nepochválila.
-
Pavel TišnovskýZlatý podporovatel
To je pravda, ta věta vyzněla špatně, opravím to. Mimochodem o Decimal a podobných formátech (včetně rational) něco napíšu příště, právě proto, jaké zaručují výsledky oproti single/double.
-
vandrovnik (neregistrovaný)
Dnešní "potomek" Turbo Pascalu - Delphi - má kvůli kompatibilitě stále ještě i typ Real48.
Jinak za zmínku tam stojí i typ currency - pro čísla s pevnou desetinnou čárkou, interně je to vlastně int 64, desetinná čárka je posunuta "o 4 místa", takže hodnota 1,23 se uloží jako 12300 (což programátora normálně moc nezajímá, špinavou práci odvede překladač). -
vandrovnik (neregistrovaný)
Myslím, že převedou na double, výpočet provedou na FPU a pak převedou zpět na fixed point. Zkusím sem dát asi ne moc přehlednou ukázku (jsou proložené řádky zdrojáku s assemblerem, který vytvoří překladač):
Main.pas.29: a:=1.2345;
005CDF48 C745F039300000 mov [ebp-$10],$00003039
005CDF4F 33C0 xor eax,eax
005CDF51 8945F4 mov [ebp-$0c],eax
Main.pas.30: b:=6.7891;
005CDF54 C745E833090100 mov [ebp-$18],$00010933
005CDF5B 33C0 xor eax,eax
005CDF5D 8945EC mov [ebp-$14],eax
Main.pas.31: c:=a+b;
005CDF60 DF6DF0 fild qword ptr [ebp-$10]
005CDF63 DF6DE8 fild qword ptr [ebp-$18]
005CDF66 DEC1 faddp st(1)
005CDF68 DF7DE0 fistp qword ptr [ebp-$20]
005CDF6B 9B wait
Main.pas.32: c:=a/b;
005CDF6C DF6DF0 fild qword ptr [ebp-$10]
005CDF6F DF6DE8 fild qword ptr [ebp-$18]
005CDF72 DEF9 fdivp st(1)
005CDF74 D80D84DF5C00 fmul dword ptr [$005cdf84]
005CDF7A DF7DE0 fistp qword ptr [ebp-$20]
005CDF7D 9B wait -

Ja to resil taky ted. Norma pro polske plynare format real48. Nakonec jsem udelal funkce co se mi i libili:
https://stackoverflow.com/a/45921700/5507237 -

skvely format je DECIMAL64 a DECIMAL128
(uz je tady nekdo letmo zminil)
3 decimalni cislice se ukladaji do 10 bitu, takze plytvani bitama je minimalni (na rozdil od BCD) a je zarucena presnost vypoctu
Pouziva je napriklad moje oblibena kalkulacka WP34S
decimal64 ma 16 platnych decimalnich cislic a (dekadicky) exponent -383 az +384
decimal128 ma 34 platnych decimalnich cislic a rozsah exponentu -6143 az +6144
viz https://en.wikipedia.org/wiki/Decimal128_floating-point_format
decimalni cislice jsou kodovany systemem DPD - densely packed decimal
viz https://en.wikipedia.org/wiki/Densely_packed_decimal -
Pavel TišnovskýZlatý podporovatel
Jj, mezitím jsem to nachystal do druhé části článku. K tomu DPD - elegantnější je https://en.wikipedia.org/wiki/Chen%E2%80%93Ho_encoding

{kind=link}
{kind=link}