
Obsah
1. Automatická analýza a recenze zdrojových kódů s využitím nástroje CodeRabbit
2. Integrace CodeRabbita s repositářem
3. Knihovna naprogramovaná v jazyku C
4. Analýza a recenze zdrojového kódu knihovny
5. Vygenerování komentářů k analyzovanému zdrojovému kódu
6. Odvození sekvenčního diagramu z analyzovaného zdrojového kódu
7. Podpora programovacích jazyků, které nepatří do mainstreamu
8. Program pro smazání obrazovky na ZX Spectru
9. Programová smyčka realizovaná instrukcí DJNZ
10. Program vytvořený v assembleru mikroprocesorů Intel 8086 pro IBM PC+DOS
11. Výpočet největšího společného dělitele v BBC BASICu
13. Oficiální demonstrační příklad pro jazyk C3
14. Analýza a recenze příkladu
15. Rekurzivní výpočet naprogramovaný v jazyce Standard ML
16. Analýza a recenze příkladu
17. Rekurzivní výpočet naprogramovaný v jazyce OCaml
18. Analýza a recenze příkladu
19. Nepatrně složitější příklad naprogramovaný v jazyce OCaml
20. Analýza a recenze příkladu
1. Automatická analýza a recenze zdrojových kódů s využitím nástroje CodeRabbit
„AI doesn’t invent. It recycles. It’s trained on other people’s ideas, imitates patterns, and doesn’t jump the curve.“
Jak již bylo napsáno v perexu dnešního článku, s aplikacemi a nástroji, které do nějaké míry využívají umělou inteligenci, se v posledních několika letech doslova roztrhl pytel. V oblasti vývojářských nástrojů se můžeme setkat s mnoha doplňky umožňujícími tvorbu programového kódu (vibe coding), se všemi pozitivními ale i mnoha negativními důsledky, které tato technologie přináší. Ovšem prozatím ponechme programování na lidech a zaměřme se na jinou oblast. Konkrétně se bude jednat o nástroje, které umožňují analyzovat změny prováděné ve zdrojových kódech (pull request, change request), hledat v těchto změnách nedostatky, navrhovat vylepšení popř. opravovat zjevné chyby nebo dokonce navrhovat vylepšení implementovaných algoritmů. Takové nástroje mohou být velmi užitečné a tím, že se soustředí pouze na analýzu změn, je je možné využít i na CI.
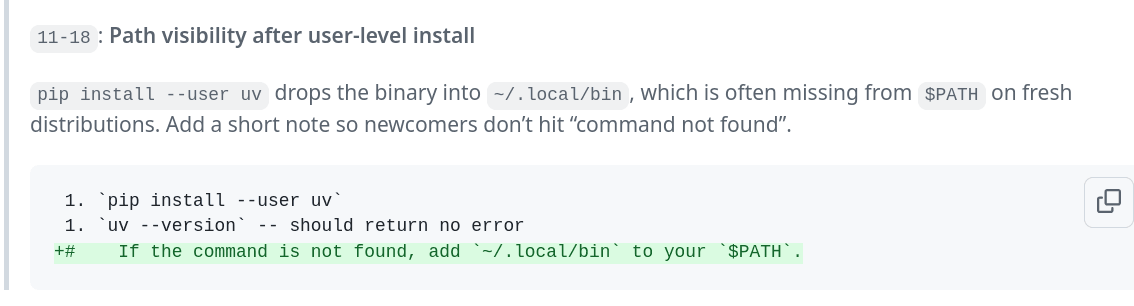
Obrázek 1: CodeRabbit dokáže navrhovat i vylepšení dokumentace.
V dnešním článku se seznámíme s nástrojem CodeRabbit, který lze velmi dobře integrovat s GitHubem a GitLabem. Tento nástroj podporuje velké množství programovacích jazyků, pochopitelně zejména těch mainstreamových. Ovšem navíc dokáže provádět analýzu toku dat, kontroluje konfigurační soubory, definiční soubory, specifikace API atd. A navíc je jeho použití pro veřejně dostupné repositáře zdarma, takže integraci CodeRabbita vlastně nic nestojí v cestě [*].

Obrázek 2: Další návrhy na úpravu dokumentace provedenou nástrojem CodeRabbit.
2. Integrace CodeRabbita s repositářem
CodeRabbit dokáže analyzovat každý pull request do repositáře, ovšem pochopitelně je nutné jeho propojení se zvoleným repositářem nebo repositáři. To je snadné, ovšem za předpokladu, že máte práva ke konfiguraci repositáře. Nejdříve je nutné se přihlásit na stránce https://app.coderabbit.ai/login. Předpokládejme, že přihlášení bude provedeno přes GitHub. V takovém případě CodeRabbit automaticky nabídne seznam repositářů, do kterých se může přidat. Přitom vyžaduje práva pro čtení a současně i zápis, což sice zní divně, ovšem většinou to znamená práva pro vytvoření pull requestů (typicky je totiž hlavní větev zamčená pro přímé zápisy – pokud není, je nejvyšší čas ji zamčít :-). CodeRabbit se následně v nastavení repositáře objeví v sekci GitHub Apps pod označením coderabbitai Developed by coderabbitai.
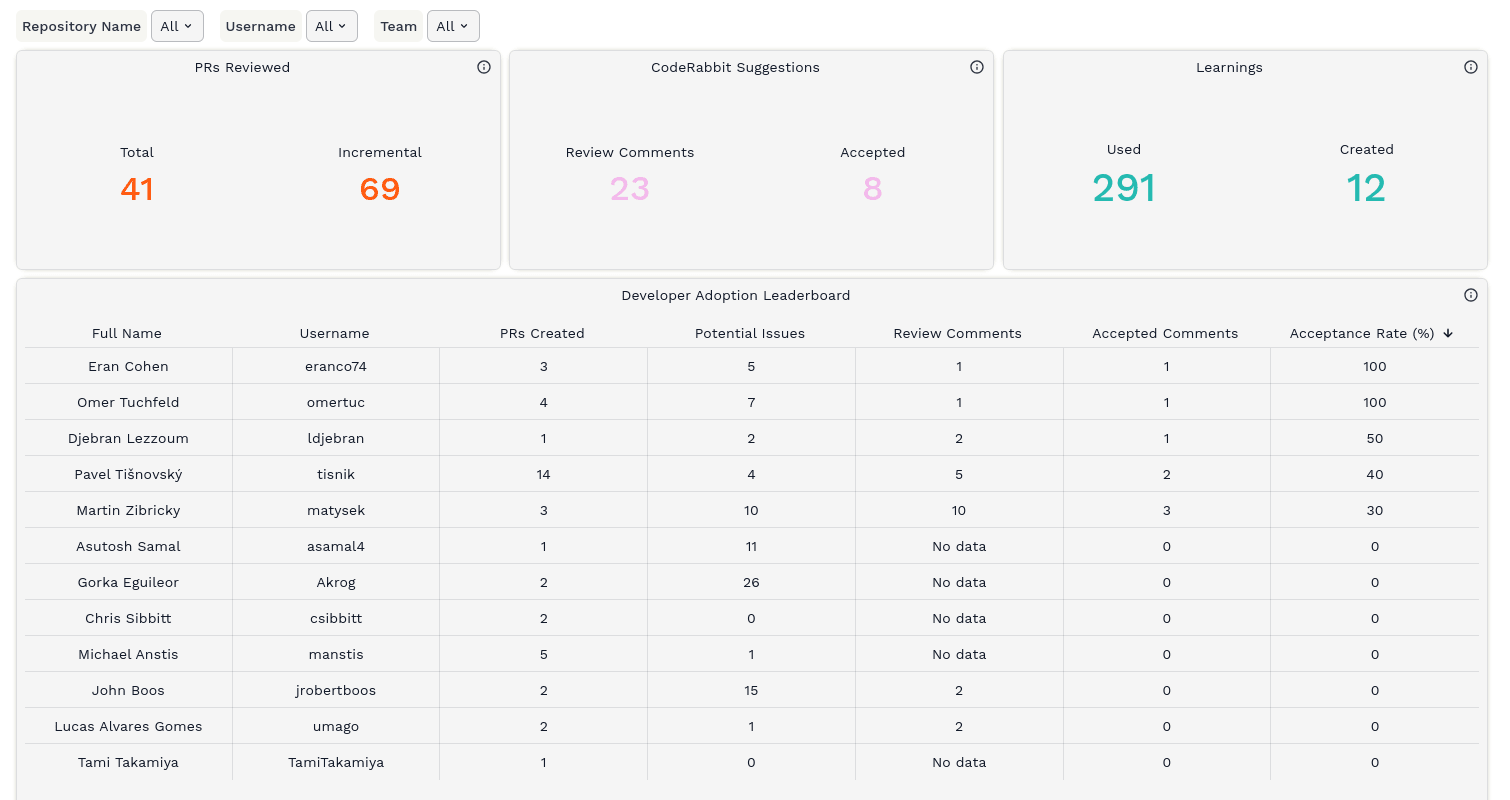
Obrázek 3: Přehledová tabulka s informacemi o tom, kolik změn bylo analyzováno a kolik navrhovaných úprav bylo akceptováno.
Nyní bude pro každý nový pull request provedena jeho analýza, což je činnost, která může nějakou dobu trvat (řádově minuty). Posléze jsou zobrazeny výsledky analýzy i s navrhovanými změnami, například:

Obrázek 4: Navrhované úpravy kódu provedené CodeRabbitem
3. Knihovna naprogramovaná v jazyku C
Abychom si otestovali některé základní možnosti nabízené nástrojem CodeRabbit, byla vytvořena jednoduchá knihovna napsaná v céčku. Zdrojový kód této knihovny byl poslán do repositáře v jediném pull requestu (což je trik, jak si zajistit analýzu celého zdrojového kódu). Zdrojový kód této knihovny vypadá následovně (nejedná se o uměle vytvořený kód, protože je na něm založen reálný projekt):
/*
build as shared library: gcc -shared -Wl,-soname,testlib -o testlib.so -fPIC
testlib.c build as executable:
*/
#include <stdio.h>
#include <stdlib.h>
void render_test_rgb_image(unsigned int width, unsigned int height,
unsigned char *pixels, unsigned char green) {
unsigned int i, j;
unsigned char *p = pixels;
for (j = 0; j < height; j++) {
for (i = 0; i < width; i++) {
*p++ = i;
*p++ = green;
*p++ = j;
p++;
}
}
}
void ppm_write_ascii_to_stream(unsigned int width, unsigned int height,
unsigned char *pixels, FILE *fout) {
int x, y;
unsigned char r, g, b;
unsigned char *p = pixels;
/* header */
fprintf(fout, "P3 %d %d 255\n", width, height);
/* pixel array */
for (y = height - 1; y >= 0; y--) {
for (x = 0; x < width; x++) {
r = *p++;
g = *p++;
b = *p++;
p++;
fprintf(fout, "%d %d %d\n", r, g, b);
}
}
}
int ppm_write_ascii(unsigned int width, unsigned int height,
unsigned char *pixels, const char *file_name) {
FILE *fout;
fout = fopen(file_name, "wb");
if (!fout) {
return -1;
}
ppm_write_ascii_to_stream(width, height, pixels, fout);
if (fclose(fout) == EOF) {
return -1;
}
return 0;
}
int main(void) {
#define WIDTH 256
#define HEIGHT 256
unsigned char *pixels = (unsigned char *)malloc(WIDTH * HEIGHT * 4);
render_test_rgb_image(WIDTH, HEIGHT, pixels, 0);
ppm_write_ascii(WIDTH, HEIGHT, pixels, "test_rgb_1.ppm");
return 0;
}
4. Analýza a recenze zdrojového kódu knihovny
Podívejme se nyní na to, jakým způsobem byl zdrojový kód knihovny uvedené ve druhé kapitole analyzován a jakou recenzi CodeRabbit vytvořil.
Nejdříve se vytvoří text s popisem provedené změny, která je v tomto případě poměrně příhodná:
A new C source file was added that provides functions to generate a simple RGB test image and write it in PPM ASCII format. The code includes image rendering, PPM writing utilities, and a main function that generates a 256x256 image and saves it to disk. Build instructions are included in comments.
Některé navrhované změny ponechám v článku zobrazeny v textové podobě, například nekonzistenci v pojmenování knihovny:
1-4: Fix inconsistencies in build instructions.
The build instructions contain several issues:
Line 3 references "testlib.c" but the actual filename is "render_image_1.c"
The shared library build command uses "testlib" names that don't match the file
The executable build instruction is incomplete
Apply this diff to correct the build instructions:
Navrhovaná změna je zobrazena formou patche:
/* -build as shared library: gcc -shared -Wl,-soname,testlib -o testlib.so -fPIC -testlib.c build as executable: +build as shared library: gcc -shared -Wl,-soname,render_image_1 -o render_image_1.so -fPIC render_image_1.c +build as executable: gcc -o render_image_1 render_image_1.c */
Další navrhované změny a problémy si již zobrazíme formou screenshotů:
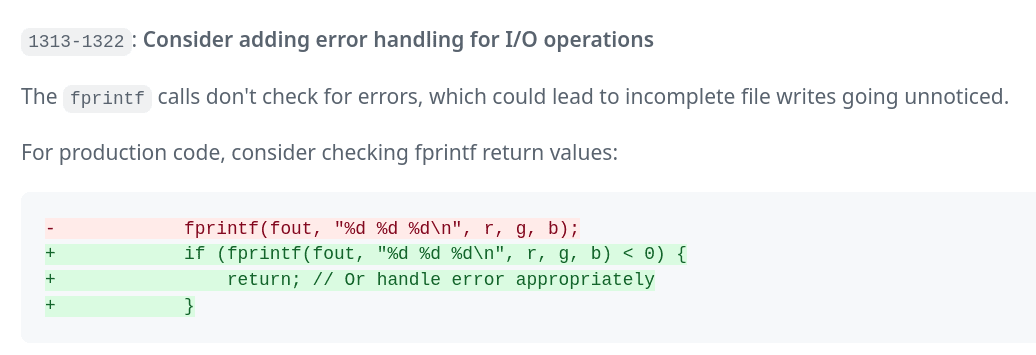
Obrázek 5: V novém kódu jsem zapomněl na kontrolu návratového kódu funkce fprintf, která může skončit s chybou.
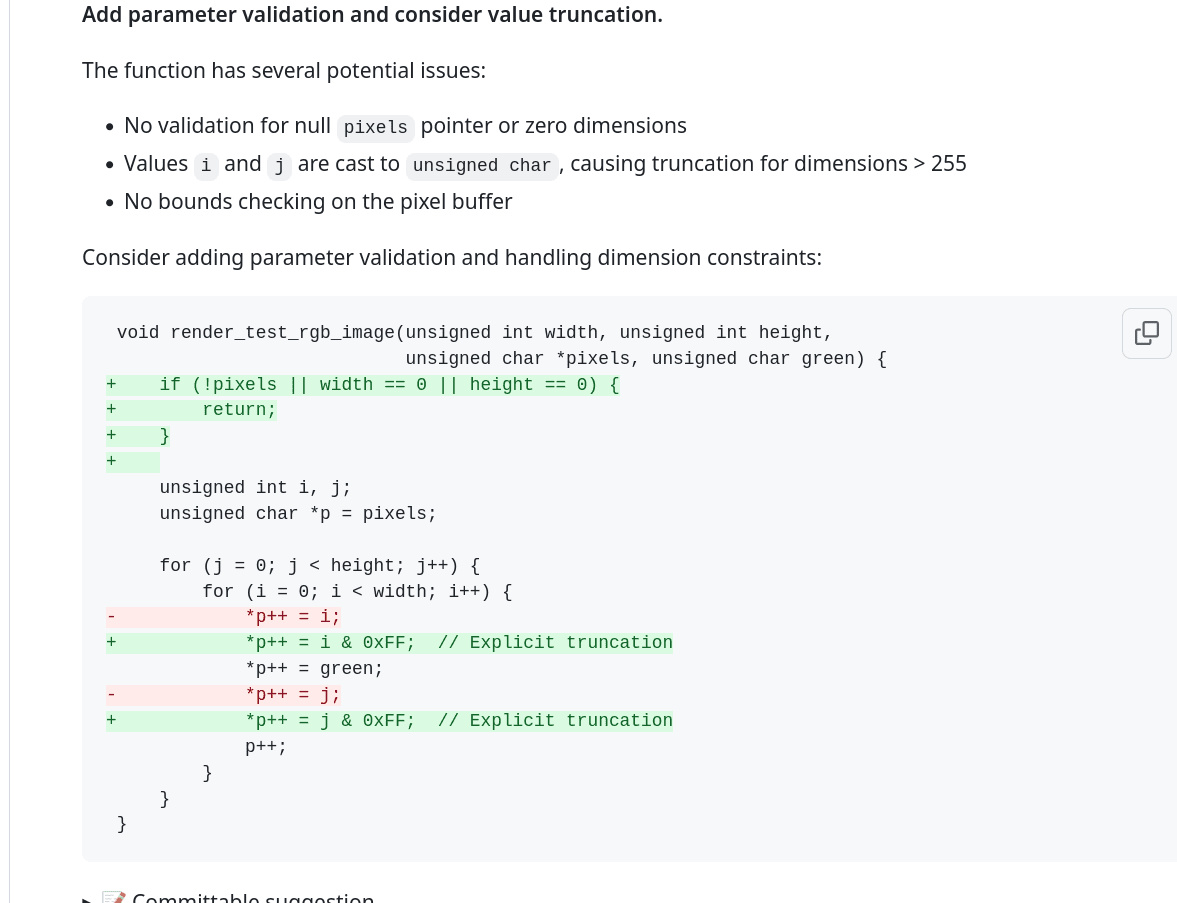
Obrázek 6: Důležitá je i kontrola vstupních parametrů funkce, zejména ukazatelů. A navíc CodeRabbit navrhuje i explicitní omezení zapisovaných hodnot na rozsah jednoho bajtu (což mi popravdě připadne až moc „profesorské“, ale budiž)
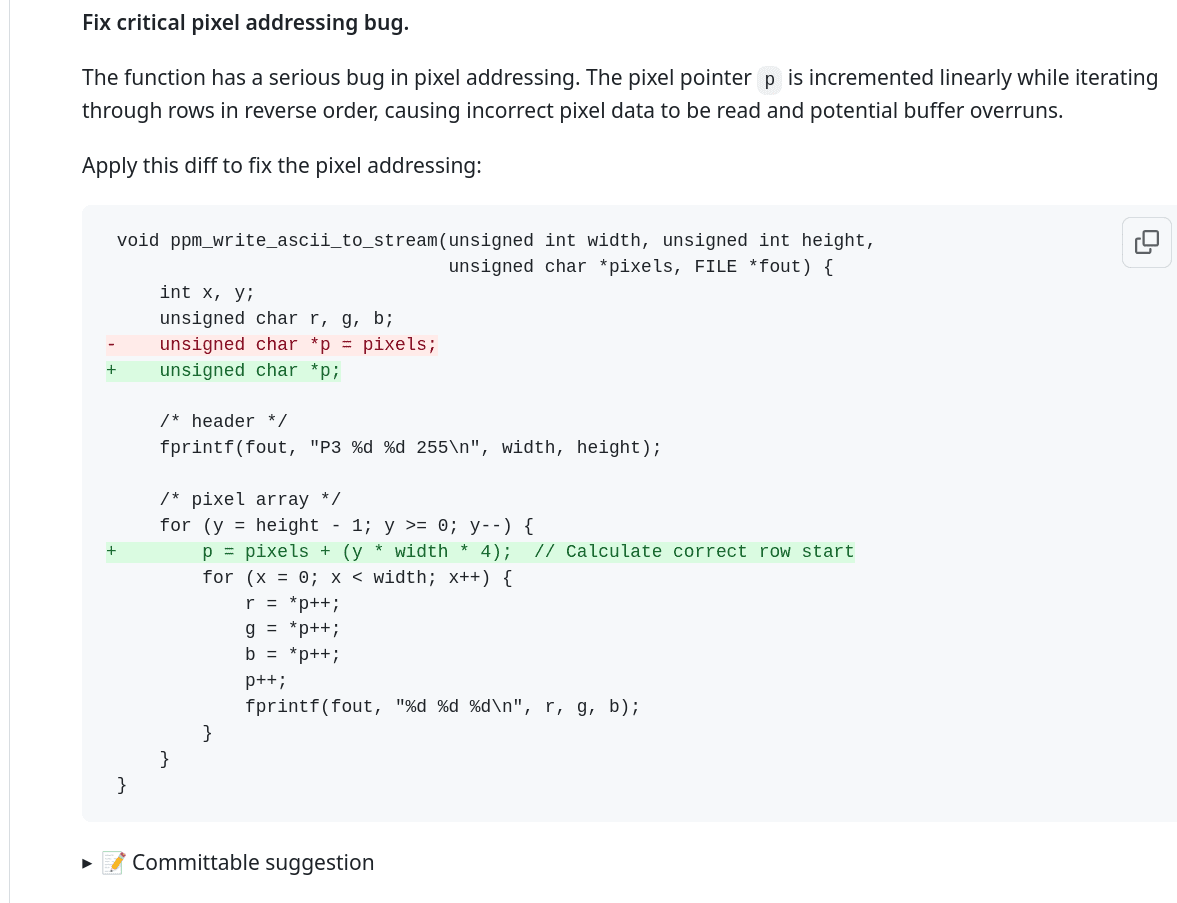
Obrázek 7: Toto je zajímavá potenciální chyba, která mě popravdě při psaní kódu ani nenapadla, takže je dobré, že na ni CodeRabbit upozornil
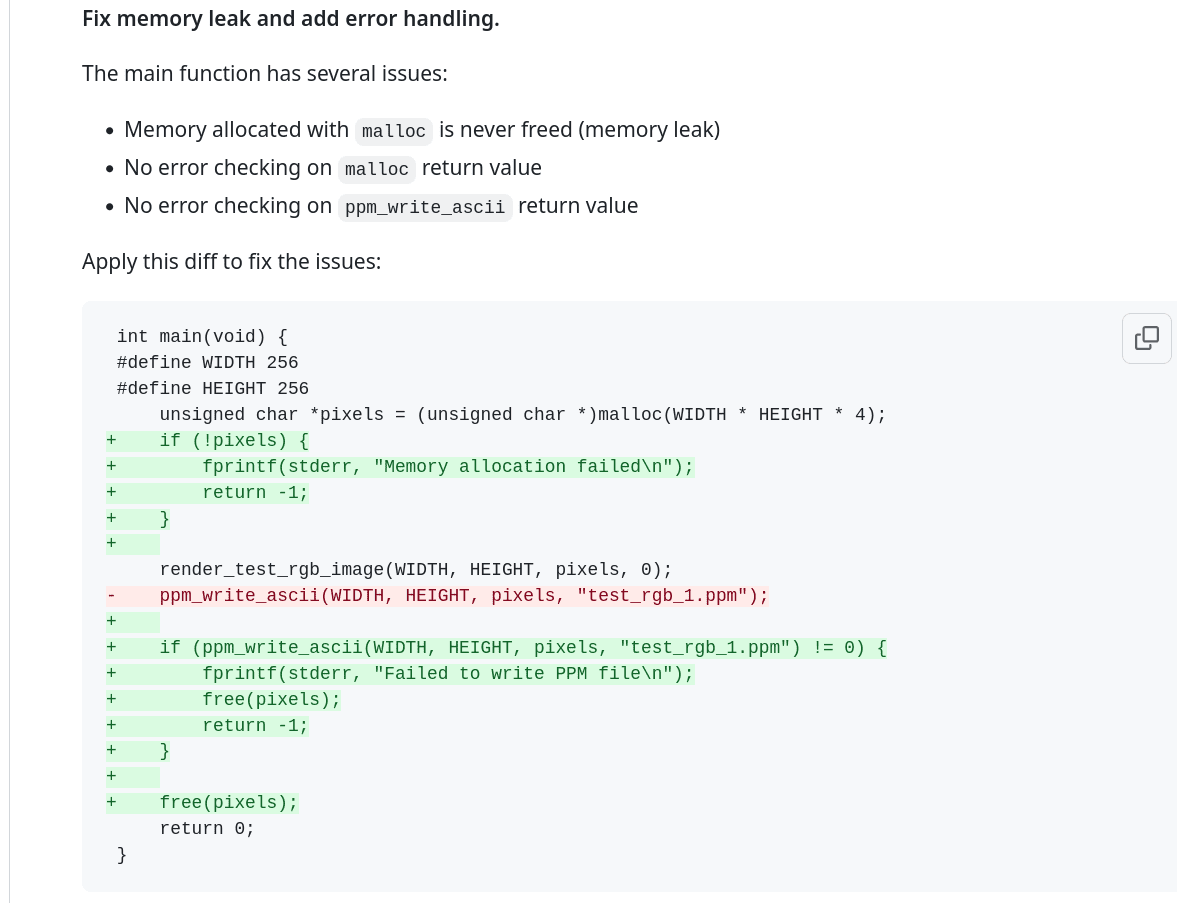
Obrázek 8: Jazyk C je nakonec snadno použitelný, když všechny potřebné kontroly doplňují boti
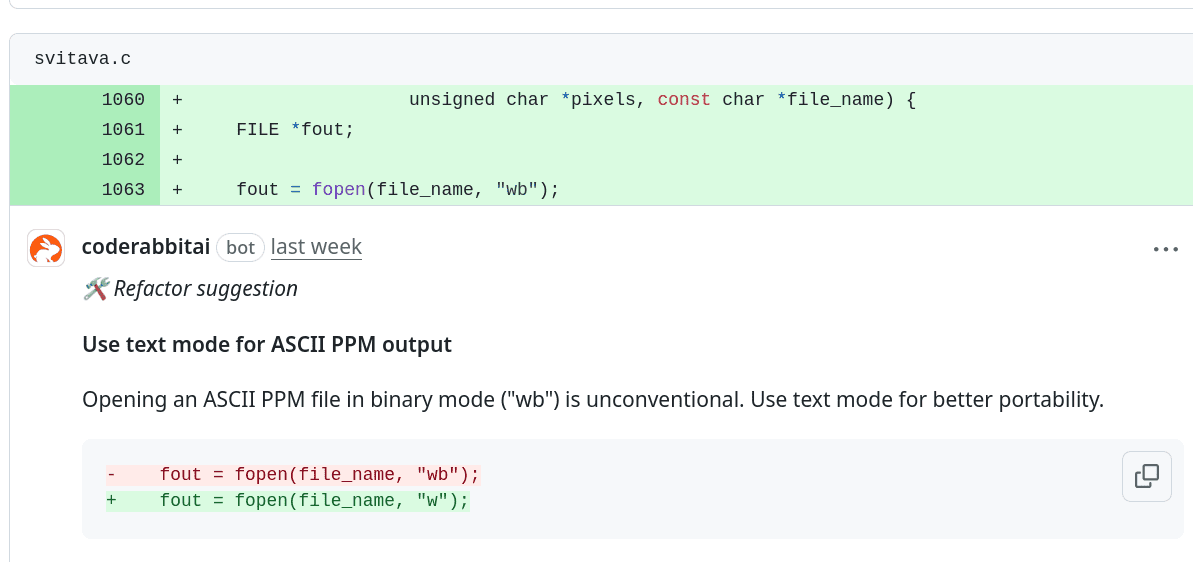
Obrázek 9: Tato změna mě popravdě překvapila, protože jsem neočekával, že CodeRabbit kódu porozumí až do takové míry, že odhalí typ vytvářeného souboru (a pochopitelně po změně typu souboru na binární PPM toto upozornění zmizí)
5. Vygenerování komentářů k analyzovanému zdrojovému kódu
Další potenciálně užitečnou funkcí CodeRabbita je jeho schopnost vygenerovat komentáře k analyzovanému zdrojovému kódu. Někdy jsou tyto komentáře až moc detailní, ovšem samozřejmě se jedná pouze o doporučení. Komentáře se vytvoří ve vlastním pull requestu vytvořeného CodeRabbitem, který pochopitelně musí být schválen a zařazen do repositáře.
Pro zajímavost si změnu provedenou CodeRabbitem zobrazíme formou patche, který by měl být pro vývojáře snadno čitelný:
From c5d1b1090d5b2519ee2c1154f332f673fd24a581 Mon Sep 17 00:00:00 2001
From: "coderabbitai[bot]"
<136622811+coderabbitai[bot]@users.noreply.github.com>
Date: Wed, 16 Jul 2025 19:14:12 +0000
Subject: [PATCH] =?UTF-8?q?=F0=9F=93=9D=20Add=20docstrings=20to=20`render?=
=?UTF-8?q?=5Fimage=5F1.c`?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
Docstrings generation was requested by @tisnik.
* https://github.com/tisnik/test-dependabot-no-devs/pull/1055#issuecomment-3079893992
The following files were modified:
* `render_image_1.c`
---
render_image_1.c | 30 ++++++++++++++++++++++++++++++
1 file changed, 30 insertions(+)
diff --git a/render_image_1.c b/render_image_1.c
index 9d845a65..35f8a681 100644
--- a/render_image_1.c
+++ b/render_image_1.c
@@ -6,6 +6,16 @@ testlib.c build as executable:
#include <stdio.h>
#include <stdlib.h>
+/**
+ * Fills a pixel buffer with a test RGBA image pattern.
+ *
+ * Sets each pixel's red channel to its x-coordinate, green channel to the specified value, blue channel to its y-coordinate, and leaves the alpha channel unused.
+ * The buffer must be preallocated with at least width * height * 4 bytes.
+ * @param width Image width in pixels.
+ * @param height Image height in pixels.
+ * @param pixels Pointer to the RGBA pixel buffer to fill.
+ * @param green Value to assign to the green channel for all pixels.
+ */
void render_test_rgb_image(unsigned int width, unsigned int height,
unsigned char *pixels, unsigned char green) {
unsigned int i, j;
@@ -21,6 +31,11 @@ void render_test_rgb_image(unsigned int width, unsigned int height,
}
}
+/**
+ * Writes pixel data to a file stream in ASCII PPM (P3) format.
+ *
+ * Outputs the image header and RGB values for each pixel, reading from the provided buffer in bottom-to-top row order. The alpha channel in the buffer is ignored.
+ */
void ppm_write_ascii_to_stream(unsigned int width, unsigned int height,
unsigned char *pixels, FILE *fout) {
int x, y;
@@ -42,6 +57,17 @@ void ppm_write_ascii_to_stream(unsigned int width, unsigned int height,
}
}
+/**
+ * Writes pixel data to a file in ASCII PPM (P3) format.
+ *
+ * Opens the specified file for writing, writes the image data in ASCII PPM format using the provided pixel buffer, and closes the file.
+ * Returns 0 on success, or -1 if the file cannot be opened or closed.
+ * @param width Image width in pixels.
+ * @param height Image height in pixels.
+ * @param pixels Pointer to the RGBA pixel buffer (only RGB channels are written).
+ * @param file_name Name of the output file.
+ * @return 0 on success, -1 on failure.
+ */
int ppm_write_ascii(unsigned int width, unsigned int height,
unsigned char *pixels, const char *file_name) {
FILE *fout;
@@ -59,6 +85,10 @@ int ppm_write_ascii(unsigned int width, unsigned int height,
return 0;
}
+/**
+ * Generates a 256x256 test RGB image and writes it to "test_rgb_1.ppm" in ASCII PPM format.
+ * @returns 0 on successful completion.
+ */
int main(void) {
#define WIDTH 256
#define HEIGHT 256
6. Odvození sekvenčního diagramu z analyzovaného zdrojového kódu
Program resp. možná přesněji řečeno implementovaný algoritmus, je možné do určité míry popsat i graficky, tedy vhodným diagramem. K tomuto účelu se využívají například stavové diagramy. Ty dokážou názorně popsat stavy systému i možné přechody mezi jednotlivými stavy, ovšem v mnoha případech vzniká potřeba podrobněji popsat i interakci mezi popisovaným systémem a jeho okolím, interakci mezi dvěma nebo více moduly systému či (na té nejpodrobnější úrovni) interakci probíhající mezi jednotlivými objekty, z nichž se systém skládá. Pro tento účel slouží takzvané sekvenční diagramy (sequence diagrams), v nichž lze velmi názorným způsobem naznačit časovou posloupnost posílání zpráv mezi různými typy objektů, popř. k zobrazené posloupnosti zpráv přidat další komentáře a značky. Jeden z typických a poměrně často v praxi používaných příkladů použití sekvenčních diagramů je popis komunikace s využitím síťových i jiných protokolů.
CodeRabbit dokáže tyto diagramy relativně dobře odvodit, což je patrné z následujících screenshotů:
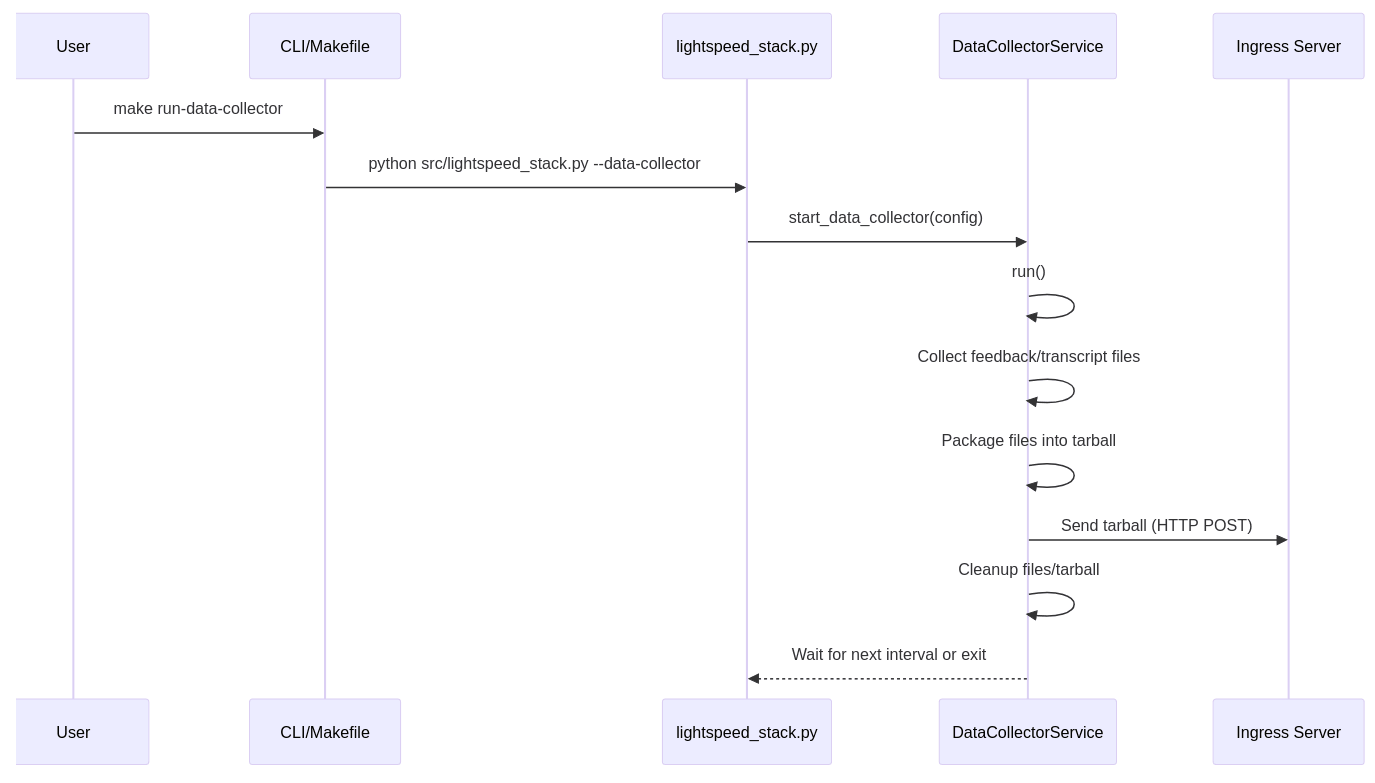
Obrázek 10: Sekvenční diagram odvozený z kódu naprogramovaného v Pythonu
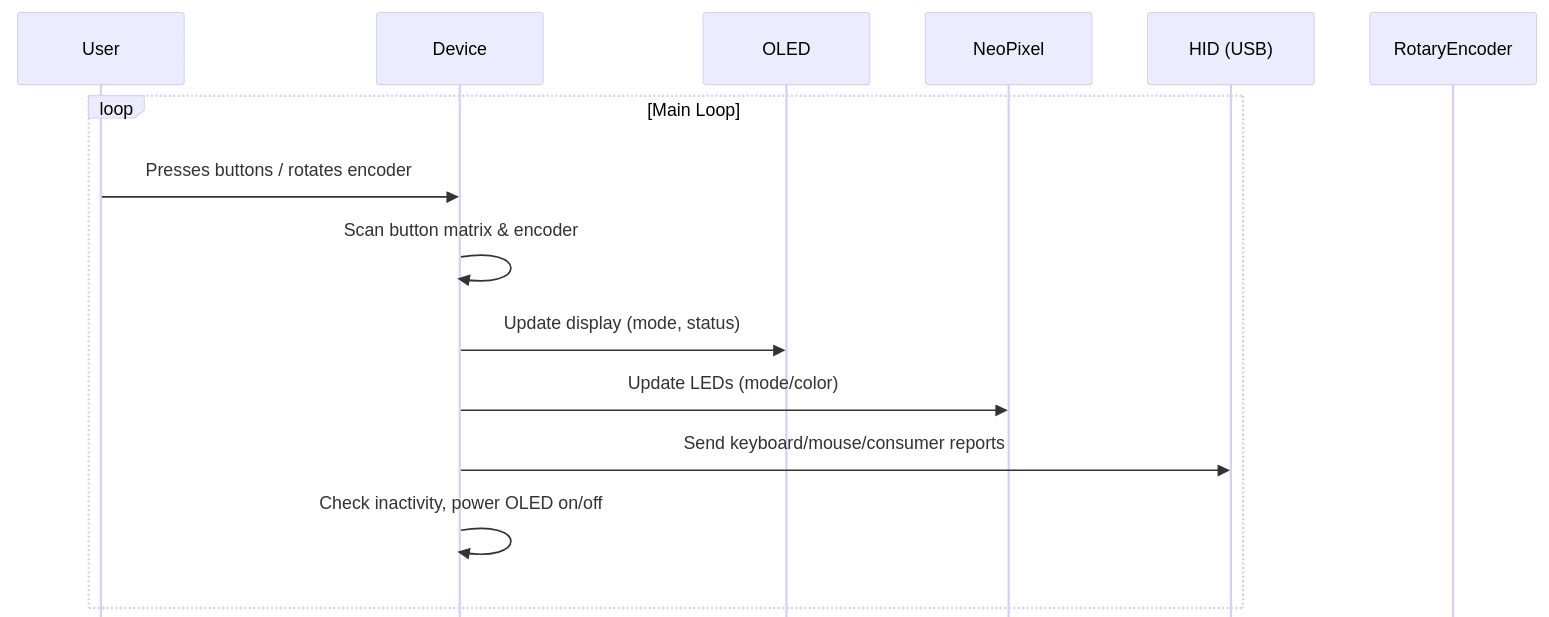
Obrázek 11: Sekvenční diagram odvozený z kódu naprogramovaného v Pythonu
7. Podpora programovacích jazyků, které nepatří do mainstreamu
Od nástrojů postavených mj. na moderních jazykových modelech můžeme očekávat velmi dobrou podporu mainstreamových programovacích jazyků, mezi něž patří především Python, který je následovaný jazyky C, C++, Javou, C# a pochopitelně taktéž JavaScriptem, TypeScriptem, Go a Rustem. Velmi dobrá podpora těchto programovacích jazyků by neměla být nijak překvapující, ovšem zajímavé bude zjistit, jak a zda vůbec dokáže CodeRabbit zpracovávat a hodnotit zdrojové kódy vytvořené v programovacích jazycích, které nepatří (a pravděpodobně ani nikdy nebudou patřit) mezi mainstream. V navazujících kapitolách proto některé tyto jazyky otestujeme. Bude se jednat jak o historické jazyky a assemblery (a proč nezačít rovnou s legendárním ZX Spectrem a assemblerem mikroprocesoru Zilog Z80?), tak i o jazyky používané v současnosti, které ovšem nepatří mezi (alespoň co se týče používanosti, nikoli nutně kvalit) absolutní špičku.

Obrázek 12: Rekapitulace trojice zdrojových kódů naprogramovaných v různých assemblerech
8. Program pro smazání obrazovky na ZX Spectru
První program zapsaný v assembleru bude provádět jedinou operaci – zavolá službu resp. subrutinu neboli podprogram, jenž je uložený v paměti ROM ZX Spectra a je tedy programátorům snadno dostupný a navíc i velmi dobře zdokumentovaný. Tento podprogram zajistí smazání obrazovky a otevření kanálu číslo 2 (což je zařízení typu „obrazovka“ neboli screen). Podprogram ROM_CLS (popř. jen CLS, viz například tento popis) je v paměti ROM ZX Spectra umístěn na adrese 0×0DAF a nevyžaduje žádné parametry, které by se jinak předávaly buď v pracovních registrech nebo s využitím speciálním zásobníku numerických hodnot typu float.
Zavolání podprogramu zajišťuje u mikroprocesorů Zilog Z80 (a i na mnoha dalších mikroprocesorových architekturách) instrukce CALL, která uloží návratovou adresu na zásobník a následně provede skok. Náš program se tedy bude skládat ze dvou instrukcí CALL + RET:
ENTRY_POINT equ $8000
ROM_CLS equ $0DAF
org ENTRY_POINT
start:
call ROM_CLS ; smazání obrazovky a otevření kanálu číslo 2 (screen)
ld A, 42 ; kód znaku '*' pro tisk
call 0x10 ; zavolání rutiny v ROM
ret ; návrat z programu do BASICu
end ENTRY_POINT
Analýza a recenze dopadne poměrně uspokojujícím způsobem – program byl zanalyzován korektně:
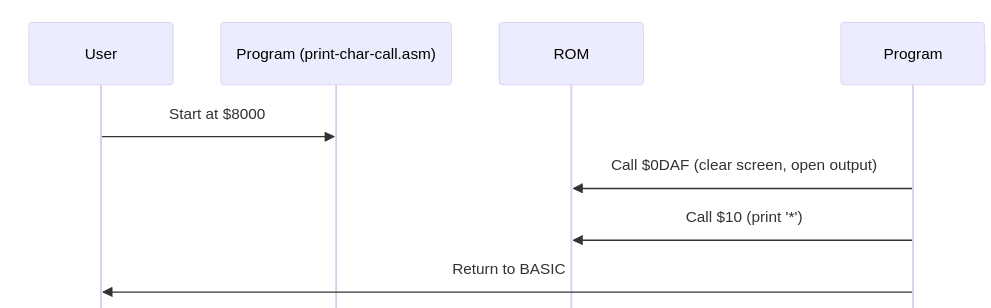
Obrázek 13: Vygenerovaný sekvenční diagram, povšimněte si, že je doplněn i popisek volané služby

Obrázek 14: Našel se pouze jeden problém – nekontrolujeme, jestli zavolaná služba operačního systému nevrátila informaci o chybě
9. Programová smyčka realizovaná instrukcí DJNZ
Ve druhém programu napsaném v assembleru mikroprocesoru Zilog Z80 pro ZX Spectrum je vytvořena programová smyčka realizovaná instrukcí DJNZ. Program provede 256 zápisů do atributové paměti ZX Spectra a změní tedy barvy v horní části obrazovky:
ATTRIBUTE_ADR equ $5800
ENTRY_POINT equ $8000
org ENTRY_POINT
start:
ld hl, ATTRIBUTE_ADR ; adresa pro zápis
ld b, l ; zapisovaná hodnota + počitadlo smyčky
loop:
ld (hl),l ; zápis hodnoty na adresu (HL)
inc l ; zvýšení adresy i zapisované hodnoty
djnz loop ; kombinace dec b + jp NZ, loop
; snížení hodnoty počitadla
; skok pokud se ještě nedosáhlo nuly
ret
end ENTRY_POINT
V tomto případě je nalezena potenciální chyba, která spočívá v tom, že v programové smyčce modifikujeme pouze hodnotu osmibitového registru L a nikoli zdvojeného šestnáctibitového registru HL, což je ovšem ve skutečnosti přesně požadované chování (analýza by si mohla všimnout toho, že počitadlo je osmibitové).
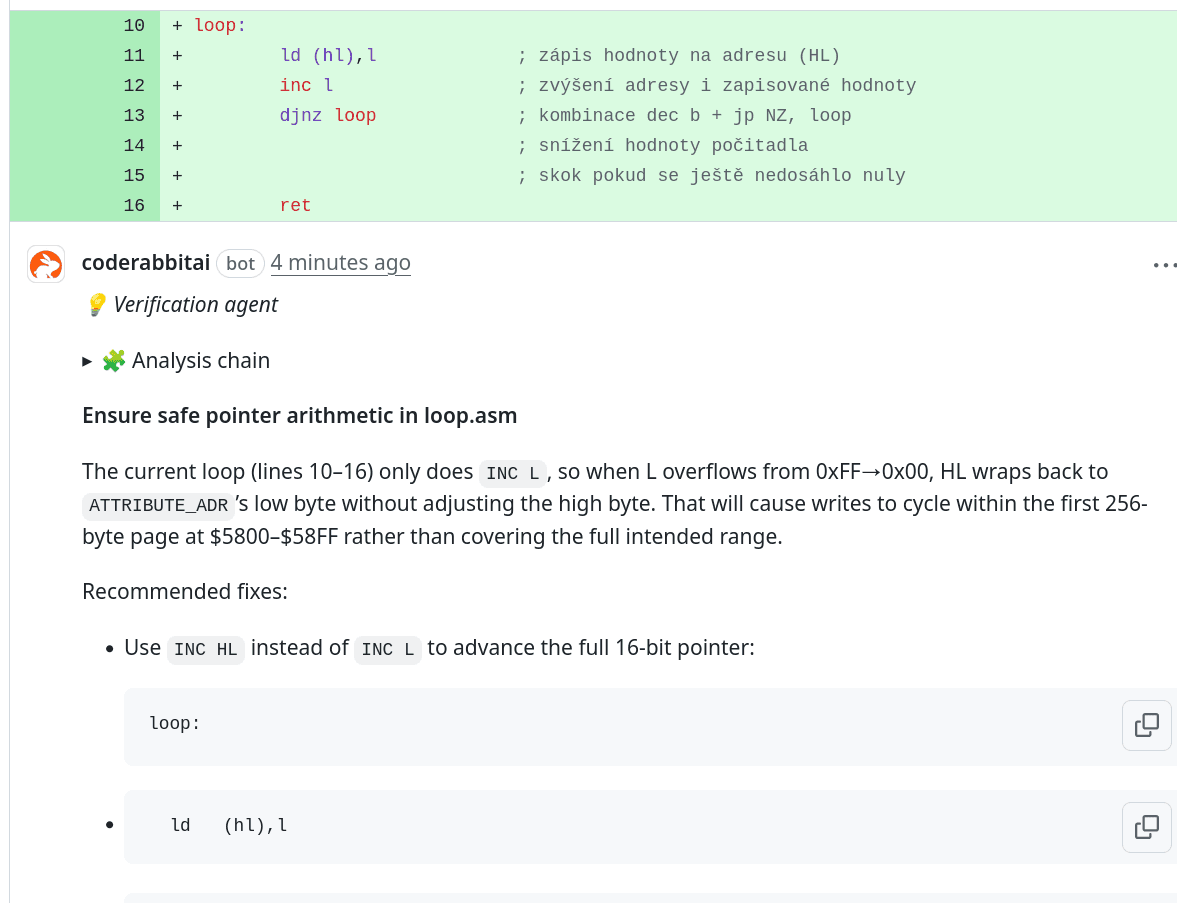
Obrázek 15: Analýza programu s počítanou programovou smyčkou realizovanou instrukcí DJNZ
10. Program vytvořený v assembleru mikroprocesorů Intel 8086 pro IBM PC+DOS
Třetí a současně i poslední program vytvořený v assembleru je pro změnu určen pro počítače IBM PC vybavené (minimálně) mikroprocesorem Intel 8086. V tomto programu je implementována subrutina (podprogram) určená pro vykreslení pixelu zadanou barvou v grafickém režimu karty VGA s rozlišením 320×200 pixelů a s 256 barvami. Subrutina je navržena právě pro původní čip 8086 resp. 8088:
;-----------------------------------------------------------------------------
BITS 16 ; 16bitovy vystup pro DOS
CPU 8086 ; specifikace pouziteho instrukcniho souboru
;-----------------------------------------------------------------------------
; ukonceni procesu a navrat do DOSu
%macro exit 0
mov ah, 0x4c
int 0x21
%endmacro
; vyprazdneni bufferu klavesnice a cekani na klavesu
%macro wait_key 0
xor ax, ax
int 0x16
%endmacro
; nastaveni grafickeho rezimu
%macro gfx_mode 1
mov ah, 0
mov al, %1
int 0x10
%endmacro
;-----------------------------------------------------------------------------
org 0x100 ; zacatek kodu pro programy typu COM (vzdy se zacina na 256)
start:
gfx_mode 0x13 ; nastaveni rezimu 320x200 s 256 barvami
mov ax, 0xa000 ; video RAM v textovem rezimu
mov es, ax
xor di, di ; nyni ES:DI obsahuje adresu prvniho pixelu ve video RAM
mov ax, 0
opak:
mov bx, ax ; y-ová souřadnice
push ax
mov cl, al ; barva
call putpixel ; vykreslení pixelu
pop ax
push ax
mov cl, al ; barva
add ax, 10 ; horizontalni posun useky
call putpixel ; vykreslení pixelu
pop ax
push ax
mov cl, al ; barva
add ax, 20 ; horizontalni posun useky
call putpixel ; vykreslení pixelu
pop ax
inc ax ; pusun x+=1, y+=1
cmp ax, 200 ; hranice obrazovky?
jne opak ; ne-opakujeme
wait_key ; cekani na klavesu
exit ; navrat do DOSu
; Vykresleni pixelu
; AX - x-ova souradnice
; BX - y-ova souradnice (staci len BL)
; CL - barva
putpixel:
mov dx, 0xa000 ; zacatek stranky video RAM
mov es, dx ; nyni obsahuje ES stranku video RAM
mov di, ax ; horizontalni posun pocitany v bajtech
mov ax, bx ; y-ova souradnice
shl ax, 1 ; y*2
shl ax, 1 ; y*4
shl ax, 1 ; y*8
shl ax, 1 ; y*16
shl ax, 1 ; y*32
shl ax, 1 ; y*64
add di, ax ; pricist cast y-oveho posunu
shl ax, 1 ; y*128
shl ax, 1 ; y*256
add di, ax ; pricist zbytek y-oveho posunu
; -> y*64 + y*256 = y*320
mov [es:di], cl ; vlastni vykresleni pixelu
ret
CodeRabbit korektně odvodí sekvenční diagram popisující činnosti programu:
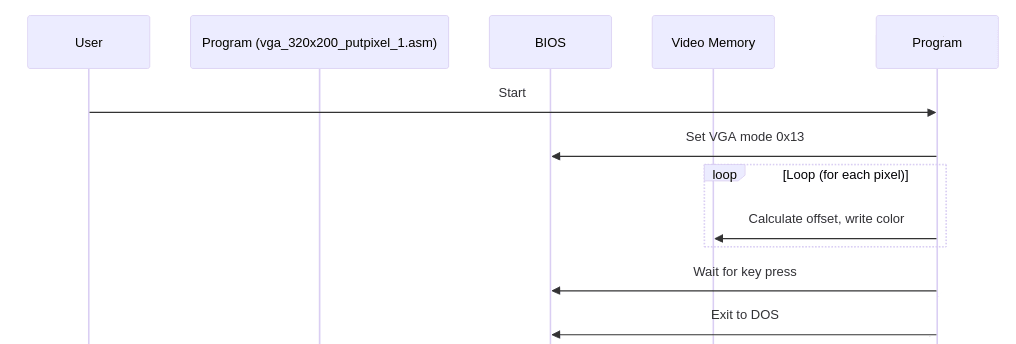
Obrázek 16: Sekvenční diagram popisující činnosti programu.
Následně je nabídnuta možnost optimalizace programu, která spočívá v lepším využití pracovních registrů, což je ovšem nekorektní, protože volaná subrutina „ničí“ jak obsah registru AX, tak i DX. Aplikací této úpravy se můžeme snadno přesvědčit, že program již nebude funkční:

Obrázek 17: Nabídnutá možnost optimalizace využití pracovních registrů
Nakonec je nabídnuta ještě jedna úprava, a to náhrada sekvence instrukcí SHL AX, 1 za SHL AX, jiná_hodnota. Toto řešení není striktně řečeno korektní, protože jsme vyžadovali překlad pro mikroprocesor Intel 8086/8088, který tyto instrukce nepodporuje:
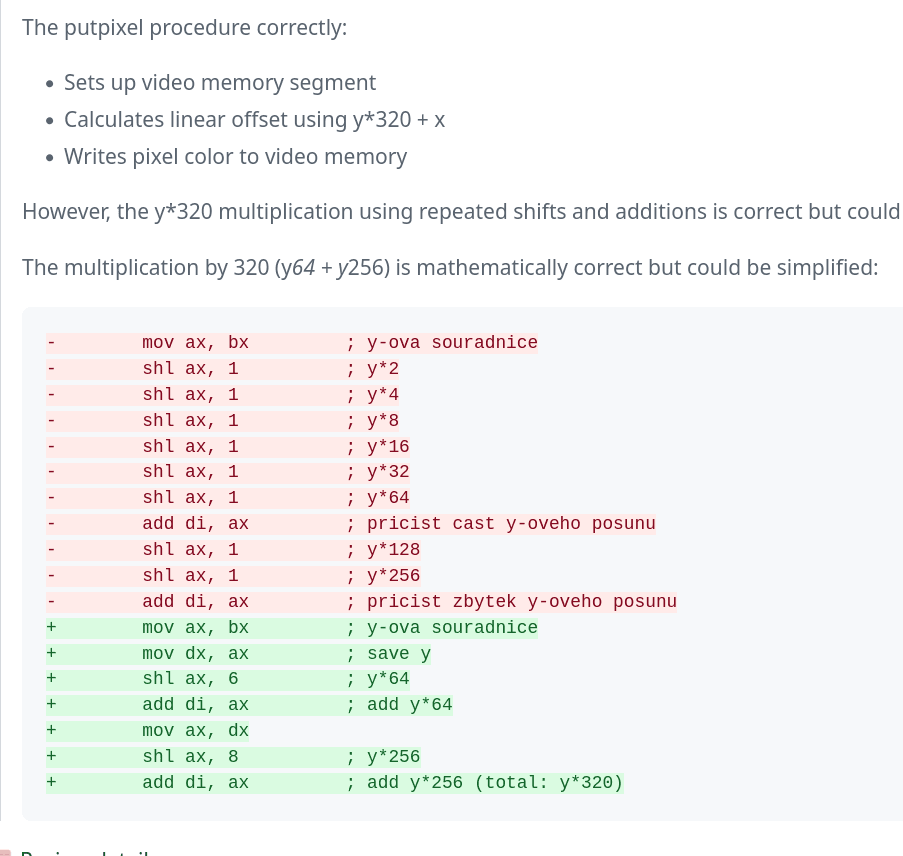
Obrázek 18: Nabídka úpravy a optimalizace instrukcí pro bitové posuny
11. Výpočet největšího společného dělitele v BBC BASICu
V dalším kroku se pokusíme o analýzu typického „školního“ algoritmu z osmdesátých let. Jedná se o algoritmus určený pro výpočet největšího společného dělitele, který je realizován ve slavném BBC BASICu, ovšem ve skutečnosti ho bude možné bez větších úprav použít i v dalších interpretrech BASICů (Atari BASIC atd.). Program postupně provádí rozdíl mezivýsledků až do stavu, kdy budou oba mezivýsledky totožné. Zcela jsme tudíž odstranili operaci podílu resp. výpočtu zbytku po dělení:
1 REM ***************************** 2 REM Vypocet nejvetsiho spolecneho 3 REM delitele. 4 REM 5 REM Uprava pro BBC BASIC 6 REM 7 REM ***************************** 8 REM 9 REM 10 PRINT "X="; 20 INPUT X 30 PRINT "Y="; 40 INPUT Y 50 IF X=Y THEN PRINT "GCD: ";X:END 60 IF X>Y THEN X=X-Y:GOTO 50 70 IF X<Y THEN Y=Y-X:GOTO 50 998 REM finito 999 STOP
12. Analýza a recenze výpočtu
Opět se podívejme, jakým způsobem byl tento zdrojový kód analyzován:
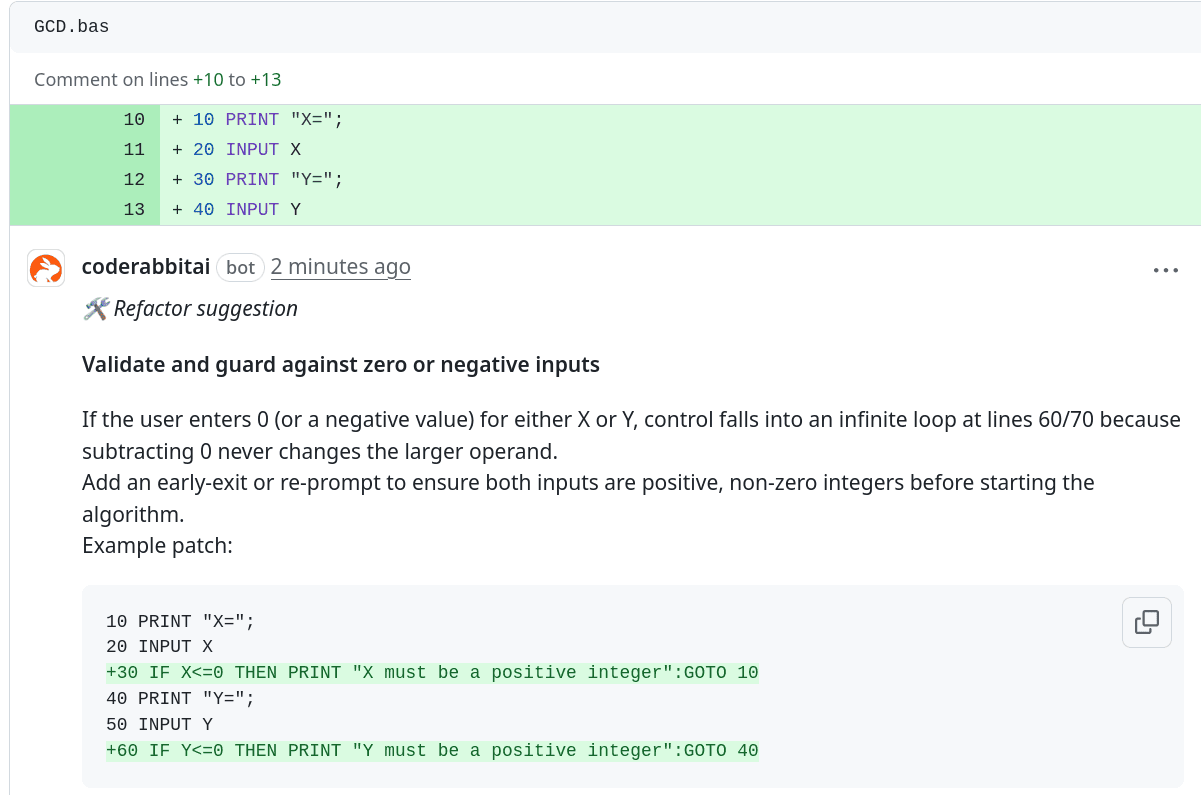
Obrázek 19: CodeRabbit nás zcela jasně upozorní na chybějící podmínky a dokonce doplní kód pro otestování vstupů

Obrázek 20: Ve druhém případě jsme upozorněni na to, že algoritmus není efektivní a je nabídnuta jeho úprava (model evidentně tento algoritmus velmi dobře „zná“
13. Oficiální demonstrační příklad pro jazyk C3
Dále si vyzkoušíme, jakým způsobem dokáže CodeRabbit pracovat s relativně novým programovacím jazykem nazvaným C3, který je popsán na stránkách https://c3-lang.org/. Jedná se o jazyk odvozený od klasického céčka, ovšem s několika poměrně praktickými vylepšeními. Pro otestování jsem zvolil příklad, který je dostupný přímo na oficiálních stránkách tohoto jazyka. Jedná se o ukázku použití výčtového datového typu. Tento příklad jsem ovšem „rozbil“: z výčtového typu byl odstraněn jeden prvek s identifikátorem MEDIUM, takže je zdrojový kód nekorektní:
enum Height : uint
{
LOW,
HIGH,
}
fn void demo_enum(Height h)
{
switch (h)
{
case LOW:
case MEDIUM:
io::printn("Not high");
// Implicit break.
case HIGH:
io::printn("High");
}
// This also works
switch (h)
{
case LOW:
case MEDIUM:
io::printn("Not high");
// Implicit break.
case Height.HIGH:
io::printn("High");
}
// Completely empty cases are not allowed.
switch (h)
{
case LOW:
break; // Explicit break required, since switches can't be empty.
case MEDIUM:
io::printn("Medium");
case HIGH:
break;
}
// special checking of switching on enum types
switch (h)
{
case LOW:
case MEDIUM:
case HIGH:
break;
default: // warning: default label in switch which covers all enumeration value
break;
}
// Using "nextcase" will fallthrough to the next case statement,
// and each case statement starts its own scope.
switch (h)
{
case LOW:
int a = 1;
io::printn("A");
nextcase;
case MEDIUM:
int a = 2;
io::printn("B");
nextcase;
case HIGH:
// a is not defined here
io::printn("C");
}
}
14. Analýza a recenze příkladu
V tomto konkrétním případě CodeRabbit velmi přesně zjistil, že chybí jeden z prvků výčtového datového typu a navrhl příslušnou změnu (dokonce i na správném místě ve zdrojovém kódu):
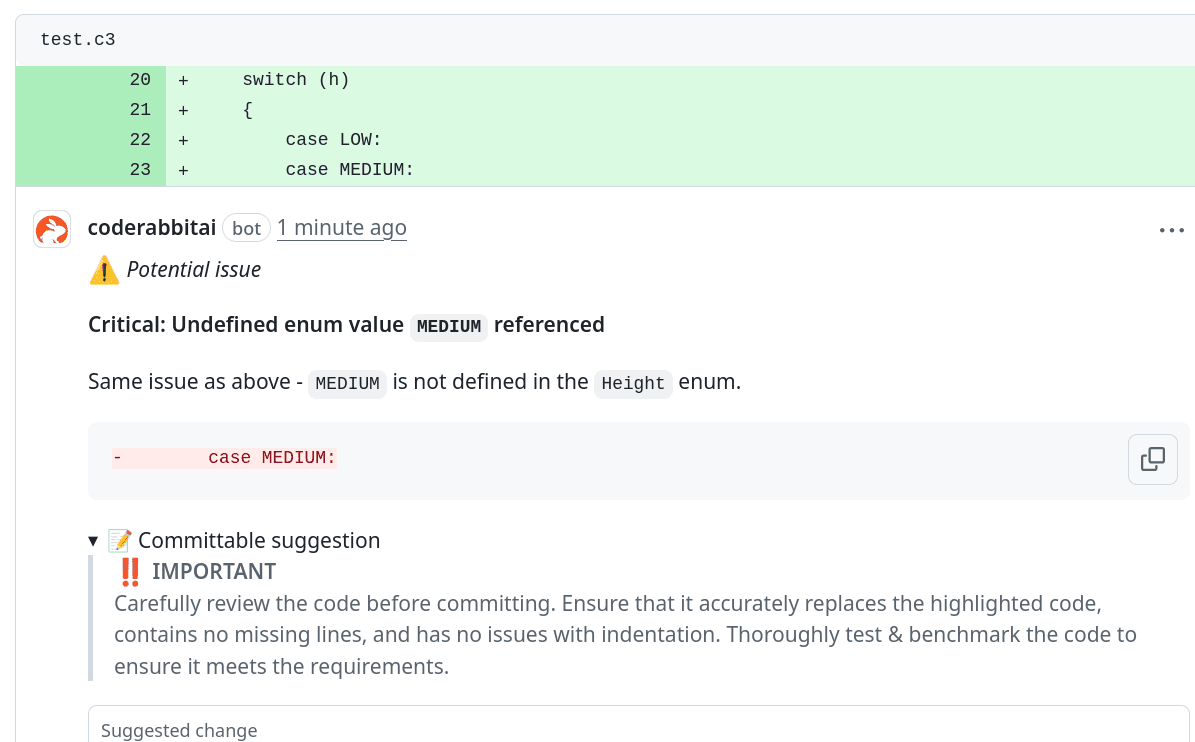
Obrázek 21: Návrh na změnu zdrojového kódu napsaného v jazyku C3 takovým způsobem, aby ho bylo možné korektně přeložit
15. Rekurzivní výpočet naprogramovaný v jazyce Standard ML
Ve zbylých kapitolách si vyzkoušíme, jakým způsobem dokáže CoreRabbitAI rozpoznat a zpracovat zdrojové kódy naprogramované v některém z programovacích jazyků odvozených od ML (což jsou jazyky s pokročilou typovou inferencí). Jedná se o jazyky Standard ML, OCaml a v neposlední řadě taktéž o jazyk F#. Začneme zdrojovým kódem napsaným ve Standard ML. Jedná se o naprosto typický „školní“ příklad výpočtu Fibonacciho posloupnosti s využitím rekurze (a tedy bez dalších optimalizací):
(* Implementace výpočtu Fibonacciho posloupnosti s využitím pattern matchingu *) fun fib 0 = 0 | fib 1 = 1 | fib n = fib (n - 1) + fib (n - 2);
16. Analýza a recenze příkladu
V tomto případě dokázal CodeRabbit ne zcela korektně navrhnout, aby došlo k přepisu zdrojového kódu do programovacího jazyka OCaml, který je od Standard ML odvozen. Pravděpodobně bot došel k tomuto závěru na základě koncovky zdrojového kódu, protože v případě Standard ML se může použít i koncovka .sml a nikoli .ml (dejte si tedy pozor na korektní koncovky, aby nebyly jazykové modely „zmateny“):
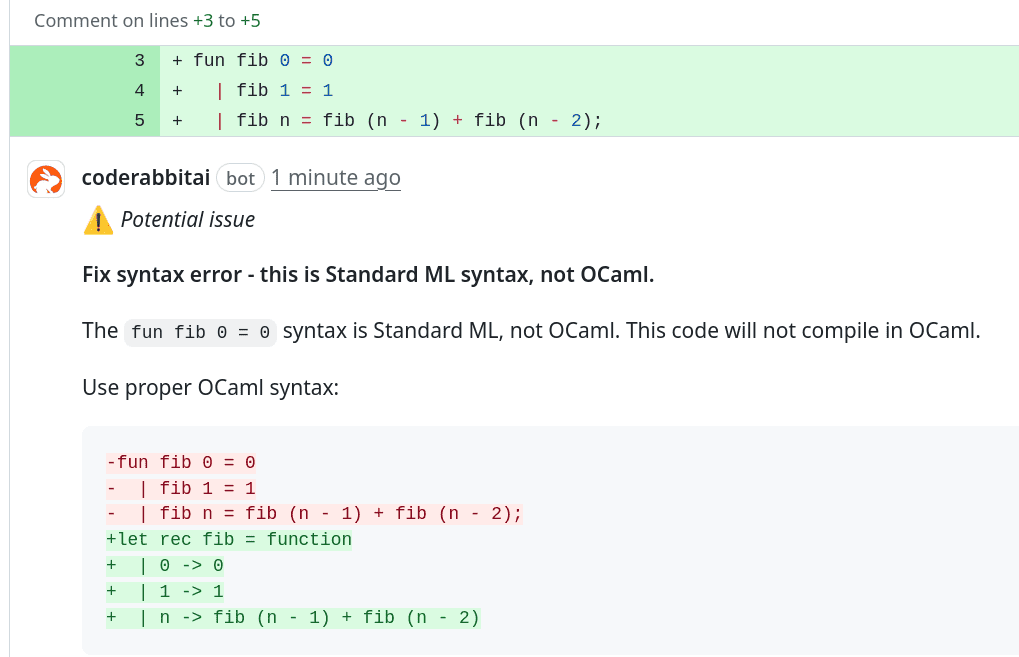
Obrázek 22: Výsledek analýzy programu vytvořeného v jazyce Standard ML
17. Rekurzivní výpočet naprogramovaný v jazyce OCaml
V dalším kroku přejdeme z jazyka Standard ML na jazyk OCaml, což je programovací jazyk patřící do stejné rodiny programovacích jazyků, je ovšem novější, podporuje objektově orientované programování a taktéž je v porovnání se Standard ML poněkud komplikovanější (syntaxe i sémantika). Výpočet Fibonacciho posloupnosti se v tomto jazyku zapisuje sice syntakticky odlišně, ovšem sémantika je prakticky totožná (až na to, že nyní musíme explicitně specifikovat, že definujeme rekurzivní funkci):
let rec fib = function
0 -> 0
| 1 -> 1
| n -> fib (n-1) + fib (n-2)
fib 10
18. Analýza a recenze příkladu
Nyní nastala mnohem zajímavější situace, protože CodeRabbit navrhl, aby se neefektivní algoritmus s přímou rekurzí přepsal do podoby, ve které je možné využít koncové rekurze. A v komentáři dokonce navrhl ještě lepší řešení založené na paměti (mezi)výsledků:

Obrázek 23: Výsledek analýzy programu vytvořeného v jazyce OCaml
19. Nepatrně složitější příklad naprogramovaný v jazyce OCaml
Poslední zdrojový kód, který si necháme okomentovat nástrojem CodeRabbit, je opět naprogramován v jazyce OCaml. Jedná se o implementaci nového datového typu color, přičemž barvy mohou být reprezentovány různými hodnotami (různé barvové modely, smíchání dvou barev s využitím alfa kanálu atd.):

type color = | BasicColor of basic_color * brightness | Gray of int | RGB of int * int * int | HSV of float * float * float | Mix of float * color * color ;;
Navíc jsou doprogramovány i funkce určené pro konverzi mezi různými reprezentacemi barev:
let scale_component x =
int_of_float (255.*.x)
;;
let scale_rgb r g b =
(scale_component r,
scale_component g,
scale_component b)
;;
let hsv_to_rgb_ h s v =
let h =
match h with
| 1.0 -> 0.0
| _ -> h
in
let i = int_of_float (h*.6.0) in
let f = h *. 6.0 -. (float i) in
let w = v *. (1.0 -. s) in
let q = v *. (1.0 -. s*.f) in
let t = v *. (1.0 -. s*.(1.0 -. f)) in
match i with
| 0 -> scale_rgb v t w
| 1 -> scale_rgb q v w
| 2 -> scale_rgb w v t
| 3 -> scale_rgb w q v
| 4 -> scale_rgb t w v
| 5 -> scale_rgb v w q
| _ -> (0, 0, 0)
;;
let hsv_to_rgb h s v =
match s with
| 0.0 -> (scale_rgb v v v)
| _ -> (hsv_to_rgb_ h s v)
;;
type basic_color =
| Black
| Red
| Green
| Yellow
| Blue
| Magenta
| Cyan
| White
;;
type brightness =
| Dark
| Bright
;;
type color =
| BasicColor of basic_color * brightness
| Gray of int
| RGB of int * int * int
| HSV of float * float * float
| Mix of float * color * color
;;
let basic_color_to_rgb = function
| Black -> (0, 0, 0)
| Red -> (255, 0,0)
| Green -> (0, 255, 0)
| Yellow -> (255, 255, 0)
| Blue -> (0, 0, 255)
| Magenta -> (255, 0, 255)
| Cyan -> (0, 255, 255)
| White -> (255, 255, 255)
;;
let darker = function
| (r, g, b) -> (r/2, g/2, b/2)
;;
let brightness rgb brightess =
match brightess with
| Dark -> darker rgb
| Bright -> rgb
;;
20. Analýza a recenze příkladu
Popravdě jsem při analýze výše uvedeného příkladu očekával, že CodeRabbit navrhne sofistikovanější řešení založené na OOP atd., ovšem ve skutečnosti byl nalezen pouze jeden nedostatek – špatné jméno parametru funkce brightness (což je dobře, protože takové přepisy dělám poměrně často):
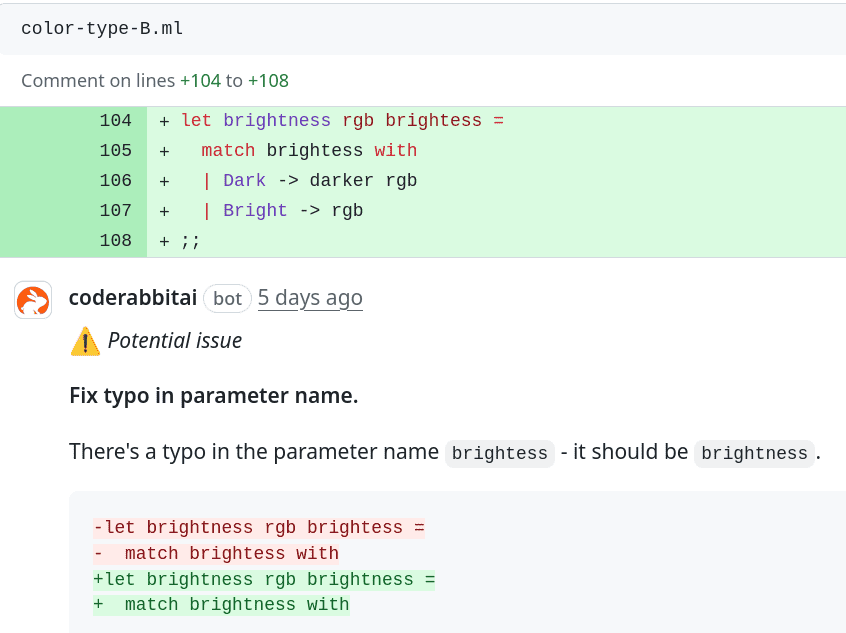
Obrázek 24: Výsledek analýzy programu vytvořeného v jazyce OCaml
21. Odkazy na Internetu
- Code Rabbit home page
https://www.coderabbit.ai/ - Nástroje pro tvorbu UML diagramů:
http://www.root.cz/clanky/nastroje-pro-tvorbu-uml-diagramu/ - Unified Modeling Language
https://en.wikipedia.org/wiki/Unified_Modeling_Language - UML basics: The sequence diagram
http://www.ibm.com/developerworks/rational/library/3101.html - UML 2 State Machine Diagrams: An Agile Introduction
http://www.agilemodeling.com/artifacts/stateMachineDiagram.htm - PlantUML (home page)
http://plantuml.sourceforge.net/ - PlantUML (download page)
http://sourceforge.net/projects/plantuml/files/plantuml.jar/download - PlantUML (Language Reference Guide)
http://plantuml.sourceforge.net/PlantUML_Language_Reference_Guide.pdf - Plain-text diagrams take shape in Asciidoctor!
http://asciidoctor.org/news/2014/02/18/plain-text-diagrams-in-asciidoctor/ - Graphviz – Graph Visualization Software
http://www.graphviz.org/ - graphviz (Manual Page)
http://www.root.cz/man/7/graphviz/ - dot (Manual page)
http://www.root.cz/man/1/dot/ - Ditaa home page
http://ditaa.sourceforge.net/ - Ditaa introduction
http://ditaa.sourceforge.net/#intro - Ditaa usage
http://ditaa.sourceforge.net/#usage - Node, Edge and Graph Attributes
http://www.graphviz.org/doc/info/attrs.html - Graphviz (Wikipedia)
http://en.wikipedia.org/wiki/Graphviz - z80 standalone assembler
https://www.asm80.com/onepage/asmz80.html - Z80 Assembly programming for the ZX Spectrum
https://www.chibiakumas.com/z80/ZXSpectrum.php - 8-BIT SMACKDOWN! 65C02 vs. Z80: slithy VLOGS #6
https://www.youtube.com/watch?v=P1paVoFEvyc - Instrukce mikroprocesoru Z80
https://clrhome.org/table/ - Z80 instructions: adresní režimy atd.
https://jnz.dk/z80/instructions.html - Z80 Instruction Groups
https://jnz.dk/z80/instgroups.html - R. T. RUSSELL: The home of BBC BASIC
http://www.rtrussell.co.uk/ - R. T. RUSSELL: A History of BBC BASIC
http://www.cix.co.uk/~rrussell/bbcbasic/history.html - General-Purpose, Industrial-Strength, Expressive, and Safe
https://ocaml.org/ - OCaml playground
https://ocaml.org/play - Online Ocaml Compiler IDE
https://www.jdoodle.com/compile-ocaml-online/ - Get Started – OCaml
https://www.ocaml.org/docs - Get Up and Running With OCaml
https://www.ocaml.org/docs/up-and-running - Better OCaml (Online prostředí)
https://betterocaml.ml/?version=4.14.0 - Learn X in Y minutes Where X=Standard ML
https://learnxinyminutes.com/docs/standard-ml/ - CSE307 Online – Summer 2018: Principles of Programing Languages course
https://www3.cs.stonybrook.edu/~pfodor/courses/summer/cse307.html - CSE307 Principles of Programming Languages course: SML part 1
https://www.youtube.com/watch?v=p1n0_PsM6hw - CSE 307 – Principles of Programming Languages – SML
https://www3.cs.stonybrook.edu/~pfodor/courses/summer/CSE307/L01_SML.pdf - SML, Some Basic Examples
https://cs.fit.edu/~ryan/sml/intro.html - History of programming languages
https://devskiller.com/history-of-programming-languages/ - History of programming languages (Wikipedia)
https://en.wikipedia.org/wiki/History_of_programming_languages - The F# Survival Guide
https://web.archive.org/web/20110715231625/http://www.ctocorner.com/fsharp/book/default.aspx - Object-Oriented Programming — The Trillion Dollar Disaster
https://betterprogramming.pub/object-oriented-programming-the-trillion-dollar-disaster-92a4b666c7c7 - Goodbye, Object Oriented Programming
https://cscalfani.medium.com/goodbye-object-oriented-programming-a59cda4c0e53 - So You Want to be a Functional Programmer (Part 1)
https://cscalfani.medium.com/so-you-want-to-be-a-functional-programmer-part-1–1f15e387e536 - So You Want to be a Functional Programmer (Part 2)
https://cscalfani.medium.com/so-you-want-to-be-a-functional-programmer-part-2–7005682cec4a - So You Want to be a Functional Programmer (Part 3)
https://cscalfani.medium.com/so-you-want-to-be-a-functional-programmer-part-3–1b0fd14eb1a7 - So You Want to be a Functional Programmer (Part 4)
https://cscalfani.medium.com/so-you-want-to-be-a-functional-programmer-part-4–18fbe3ea9e49 - So You Want to be a Functional Programmer (Part 5)
https://cscalfani.medium.com/so-you-want-to-be-a-functional-programmer-part-5-c70adc9cf56a - So You Want to be a Functional Programmer (Part 6)
https://cscalfani.medium.com/so-you-want-to-be-a-functional-programmer-part-6-db502830403






























 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU