
V minulém díle jsme si řekli, co je to HPL a k čemu se používá. Nyní si jej konečně sami zkompilujeme. Pokud jste ještě nekompilovali, tak budete potřebovat balíček build-essential (Debian, Ubuntu), nebo @development-tools (Fedora, Red Hat)
$ sudo apt install build-essential
nebo
$ sudo dnf install @development-tools
Dále bude návod jen pro Debian a Ubuntu. Pro Fedoru a Red Hat to však bude podobné, jen se mohou lišit názvy balíčků.
Nainstalujeme jednu ze dvou možných MPI knihoven (OpenMPI, nebo MPICH) ve vývojářské variantě. Výběr je na vás a nemá velký vliv na výsledný výkon.
$ sudo apt install libopenmpi-dev
nebo
$ sudo apt install libmpich-dev
Nyní už budeme kompilovat knihovnu BLAS, kterou si vybereme. Jak už jsme říkali, tak právě na knihovně BLAS nejvíce záleží výkon naměřený HPL. Můžete samozřejmě zkusit více knihoven a potom výkon porovnat. Pokud nevíte, nebo chcete prostě něčím začít, doporučuji OpenBLAS.
OpenBLAS
Vezmeme zdrojové kódy aktuální verze 0.3.24 z GitHubu.
wget https://github.com/xianyi/OpenBLAS/archive/refs/tags/v0.3.24.tar.gz tar xvf v0.3.24.tar.gz cd OpenBLAS-0.3.24
Nyní je potřeba správně nakonfigurovat procesor pomocí proměnné TARGET=. Možné hodnoty naleznete v souboru TargetList.txt. Pro arm64 se nám mohou hodit ARMV8, CORTEXA53, CORTEXA57, CORTEXA72, CORTEXA73 a CORTEXX1 (domnívám se, že by to mohlo být optimální pro CORTEX-A76, 77 a 78). Ve výsledku se ukáže, že výsledná binárka HPL pro CORTEXA53 a CORTEXA55 je stejná (pro OpenBLAS-0.3.25 již ne). To také platí pro CORTEXA57 a CORTEXA72. A to i když samotné soubory knihovny libopenblas_*.a stejné nejsou. Je to tím, že HPL použije jen pár funkcí z knihovny (nejvíc záleží na dgemm (double precision general matrix multiply) a pak ještě daxpy, dcopy, dgemv, dger, dscal, dswap, dtrsm, dtrsv a idamax) a ty jsou stejné.
Pro amd64 jsou tu volby pro CPU Intel od P2 do SAPPHIRERAPIDS, ale opět se ukáže, že výsledné binárky HPL jsou pro některé TARGETy stejné. Můžeme je rozdělit podle instrukcí SSE4.2 ( NEHALEM), AVX ( SANDYBRIDGE), AVX2 ( HASWELL) a AVX512 ( SKYLAKEX).
Mimochodem, v x86 binárkách se můžeme přímo podívat, jaké tam jsou instrukce. Hodí se k tomu například nástroj elfx86exts napsaný v Rustu. Pokud jej nemáte v repozitářích, stačí cargo install elf86exts. V případě dynamické architektury se vám objeví všechny možné instrukce, ale za běhu se samozřejmě nepoužijí. Pro ARM takový nástroj pokud vím bohužel neexistuje. Jde použít ruční disassembler objdump -d a pak ve výstupu hledat instrukce NEON. V případě HPL půjde patrně o instrukci fmla (ASIMD FP multiply accumulate). Například se můžeme přesvědčit, jaké instrukce jsou v binárce pro SandyBridge (AVX)
$ elfx86exts xhpl-openblas0.3.22.sandybridge File format and CPU architecture: Elf, X86_64 MODE64 (call) SSE2 (movsd) CMOV (cmove) SSE1 (movaps) AVX (vmovsd) NOVLX (vxorps) SSE3 (movddup) Instruction set extensions used: AVX, CMOV, MODE64, NOVLX, SSE1, SSE2, SSE3 CPU Generation: Unknown
V univerzální binárce pak najdeme AVX, AVX2, AVX512 i například zastaralé 3DNow.
$ elfx86exts xhpl-openblas0.3.22.universal-from-sandybrydge File format and CPU architecture: Elf, X86_64 MODE64 (call) SSE2 (movsd) CMOV (cmove) SSE1 (movaps) SSE3 (haddpd) 3DNow (prefetch) MMX (emms) AVX (vbroadcastsd) NOVLX (vmovups) FMA4 (vfmaddpd) AVX2 (vpand) AVX512 (vmovapd) BWI (kmovq) BMI2 (sarx) VLX (vbroadcastsd) DQI (kmovb) Instruction set extensions used: 3DNow, AVX, AVX2, AVX512, BMI2, BWI, CMOV, DQI, FMA4, MMX, MODE64, NOVLX, SSE1, SSE2, SSE3, VLX CPU Generation: Unknown
V případě ARM můžeme třeba spočítat počet instrukcí fmla.
$ objdump -d xhpl-openblas0.3.21.a53 | grep fmla | wc
357 2142 16895
Když si budete kompilovat knihovnu pro procesor s instrukcemi, které váš nemá, tak dostanete při testu chybu. Ale knihovna jde nainstalovat a slinkovat s HPL. Samozřejmě že program pak pustíte jen na procesoru, co už tyto instrukce umí. Můžete si tedy vše zkompilovat na jednom počítači a pak testovat počítačů více.
Já si tedy vyberu pro Raspberry Pi 4 TARGET=CORTEXA72 a pustím kompilaci. Pokud TARGET nespecifikujete, dojde k autodetekci.
export NO_SHARED=1
export TARGET=CORTEXA72
NO_FORTRAN=1 NUM_THREADS=8 USE_OPENMP=1 make -j$(nproc)
make PREFIX=${HOME}/openblas install
Proměnná NO_SHARED nám zajistí statickou knihovnu. Výsledná binárka HPL bude tak staticky slinkovaná a nebude k ní potřeba složitě přikládat dynamický so soubor knihovny. To je zase pro případ, že kompilujeme na jednom počítači a spouštíme na jiném. NO_FORTRAN je jasné, NUM_THREADS nastavte na maximum jader, co chcete pomocí OpenMP obsloužit. Pokud nenastavíte, samo se detekuje počet jader na stroji, kde kompilujete.
Pokud použijete místo toho MPI, nebo vás zajímá výkon jen jednoho jádra, tak je možné OpenMP vypnout a výsledek bude rychlejší ( USE_OPENMP=0 USE_THREAD=0). Pro testování stability však pro jednoduchost OpenMP použijeme.
Na Raspberry Pi 4 se OpenBLAS kompiluje asi 16 minut, na SandyBridge 4×2,5 GHz asi 7 minut. Takto si můžete nakompilovat statické knihovny OpenBLAS pro více TARGETů i více verzí. Výsledek bude vypadat například takto
$ ls -l ${HOME}/openblas/lib/
total 695296
drwxrwxr-x 3 rock rock 4096 Oct 5 12:48 cmake
-rw-r--r-- 1 rock rock 44943532 Oct 5 13:51 libopenblas-r0.3.24.a
lrwxrwxrwx 1 rock rock 27 Oct 7 13:21 libopenblas.a -> libopenblas_armv8-r0.3.24.a
-rw-r--r-- 1 rock rock 24790982 Oct 6 22:13 libopenblas_armv8-r0.3.24.a
-rw-r--r-- 1 rock rock 26828348 Oct 6 21:56 libopenblas_armv8p-r0.3.24.a
-rw-r--r-- 1 rock rock 24720786 Oct 5 15:33 libopenblas_cortexa53-r0.3.24.a
-rw-r--r-- 1 rock rock 26752584 Oct 5 15:40 libopenblas_cortexa53p-r0.3.24.a
-rw-r--r-- 1 rock rock 24720786 Oct 5 13:59 libopenblas_cortexa55-r0.3.24.a
-rw-r--r-- 1 rock rock 26750384 Oct 6 16:10 libopenblas_cortexa55p-r0.3.24.a
-rw-r--r-- 1 rock rock 24794166 Oct 5 15:27 libopenblas_cortexa57-r0.3.24.a
-rw-r--r-- 1 rock rock 26835276 Oct 5 15:22 libopenblas_cortexa57p-r0.3.24.a
-rw-r--r-- 1 rock rock 24794214 Oct 5 15:02 libopenblas_cortexa72-r0.3.24.a
-rw-r--r-- 1 rock rock 26835324 Oct 5 14:57 libopenblas_cortexa72p-r0.3.24.a
-rw-r--r-- 1 rock rock 24793222 Oct 5 15:09 libopenblas_cortexa73-r0.3.24.a
-rw-r--r-- 1 rock rock 26834076 Oct 5 15:16 libopenblas_cortexa73p-r0.3.24.a
-rw-r--r-- 1 rock rock 24801798 Oct 6 16:38 libopenblas_cortexx1-r0.3.24.a
-rw-r--r-- 1 rock rock 26838212 Oct 6 16:57 libopenblas_cortexx1p-r0.3.24.a
-rw-r--r-- 1 rock rock 24818390 Oct 5 15:55 libopenblas_neoversen1-r0.3.24.a
-rw-r--r-- 1 rock rock 26890652 Oct 5 15:48 libopenblas_neoversen1p-r0.3.24.a
-rw-r--r-- 1 rock rock 24818558 Oct 6 17:14 libopenblas_neoversen2-r0.3.24.a
-rw-r--r-- 1 rock rock 26890612 Oct 6 17:20 libopenblas_neoversen2p-r0.3.24.a
-rw-r--r-- 1 rock rock 24532944 Oct 5 16:05 libopenblas_neoversev1-r0.3.24.a
-rw-r--r-- 1 rock rock 26605590 Oct 5 16:17 libopenblas_neoversev1p-r0.3.24.a
-rw-r--r-- 1 rock rock 24311744 Oct 6 17:09 libopenblas_thunderx-r0.3.24.a
-rw-r--r-- 1 rock rock 26356294 Oct 6 17:04 libopenblas_thunderxp-r0.3.24.a
-rw-r--r-- 1 rock rock 47222354 Oct 5 12:49 libopenblasp-r0.3.24.a
drwxrwxr-x 2 rock rock 4096 Oct 5 12:48 pkgconfig
V názvu hned vidíme TARGET, verzi OpenBLAS a také, jestli je knihovna zkompilovaná s vlákny (p), nebo bez (nic). Dynamická architektura (viz níže) pak prostě nemá žádný TARGET. Knihovna, která se použije při linkování s HPL je pak ta, na kterou ukazuje symbolický link libopenblas.a.
Kromě toho můžeme využít dynamickou architekturu, tedy zkompilovat víc TARGETů do jedné knihovny. Při běhu se použije ta optimální pro daný procesor. Na první pohled to funguje docela dobře, není tedy důvod to nepoužít. Důvodem proti může být velikost a někdy špatná detekce (obzvlášť u big.LITTLE). I když vlastní knihovna s dynamickou architekturou je asi jen dvakrát větší (jak na amd64 tak i na arm64), tak výsledná binárka HPL je větší asi padesátkrát (11,7 MB místo 0,2 MB). Zřejmě se nešikovně linkuje stále stejný kód knihovny několikrát dokola.
Další nevýhodou autodetekce je, že na big.LITTLE architektuře vybere vždy to horší jádro (možná se kouká jen na jádro 0, což bývá zpravidla to LITTLE?). Ke špatné autodetekci dojde jak při kompilaci bez specifikace TARGETu, tak i při spuštění univerzálního kódu. Mám to vyzkoušené na Rockchip RK3588 (Rock 5B, 4× Cortex-A76 + 4× Cortex-A55), Rockchip 3399 (Orange Pi 4, 2× Cortex-A72 + 4× Cortex-A53) a Amlogic A311D (Khadas VIM3, 4× Cortex-A73 + 2× Cortex-A52). Autodetekce při spuštění u OpenBLAS jde obejít nastavením proměnné například OPENBLAS_CORETYPE=CORTEXA72.
Pokud byste měli podezření, že HPL nejede optimálně, můžete se vrátit k jednotlivým TARGETům. V případě dynamické architektury kompilujeme takto
export NO_SHARED=1
export TARGET=ARMV8
export DYNAMIC_ARCH=1
NO_FORTRAN=1 NUM_THREADS=8 USE_OPENMP=1 make -j$(nproc)
make PREFIX=${HOME}/openblas install
Zde TARGET je vlastně nejnižší procesor, na kterém by knihovna ještě měla jet. Pokud ho nespecifikujete, tak se opět uplatní autodetekce. Ale tím pádem bychom na Raspberry Pi 4 neměli třeba CORTEX-A53. Kompilace na Raspberry Pi 4 zabere asi 43 minut (asi 2,6× déle, než jeden TARGET) a na SandyBridge 4×2,5 GHz asi 19 minut (asi 2,7× déle, než jeden TARGET).
BLIS
Alternativně můžeme použít knihovnu BLIS, kterou v aktuální verzi 0.9.0 stáhneme také z GitHubu.
wget https://github.com/flame/blis/archive/refs/tags/0.9.0.tar.gz tar xvf 0.9.0.tar.gz cd blis-0.9.0
Kompilujeme pomocí
./configure -p ${HOME}/blis --disable-shared -t openmp auto
make -j${nproc}
make -j${nproc} check
make install
ln -s ${HOME}/blis/lib/libblis.a ${HOME}/blis/lib/libopenblas.a
Zde opět použijeme OpenMP. Při použití MPI můžeme vypnout (vynechá se -t openmp, nebo dáte -t no). Parametr auto zajistí autodetekci. Pokud chcete specifikovat CPU, stačí zadat jeho název. Všechny názvy nalezneme pomocí ls config.
~/blis-0.9.0 $ ls -l config/ total 140 drwxr-xr-x 2 pi pi 4096 Apr 1 2022 a64fx drwxr-xr-x 2 pi pi 4096 Apr 1 2022 amd64 drwxr-xr-x 2 pi pi 4096 Apr 1 2022 amd64_legacy drwxr-xr-x 2 pi pi 4096 Apr 1 2022 arm32 drwxr-xr-x 2 pi pi 4096 Apr 1 2022 arm64 drwxr-xr-x 2 pi pi 4096 Apr 1 2022 armsve drwxr-xr-x 2 pi pi 4096 Apr 1 2022 bgq drwxr-xr-x 2 pi pi 4096 Apr 1 2022 bulldozer drwxr-xr-x 2 pi pi 4096 Apr 1 2022 cortexa15 drwxr-xr-x 2 pi pi 4096 Apr 1 2022 cortexa53 drwxr-xr-x 2 pi pi 4096 Apr 1 2022 cortexa57 drwxr-xr-x 2 pi pi 4096 Apr 1 2022 cortexa9 drwxr-xr-x 2 pi pi 4096 Apr 1 2022 excavator drwxr-xr-x 2 pi pi 4096 Apr 1 2022 firestorm drwxr-xr-x 2 pi pi 4096 Apr 1 2022 generic drwxr-xr-x 2 pi pi 4096 Apr 1 2022 haswell drwxr-xr-x 2 pi pi 4096 Apr 1 2022 intel64 drwxr-xr-x 2 pi pi 4096 Apr 1 2022 knc drwxr-xr-x 2 pi pi 4096 Apr 1 2022 knl drwxr-xr-x 8 pi pi 4096 Apr 1 2022 old drwxr-xr-x 2 pi pi 4096 Apr 1 2022 penryn drwxr-xr-x 2 pi pi 4096 Apr 1 2022 piledriver drwxr-xr-x 2 pi pi 4096 Apr 1 2022 power10 drwxr-xr-x 2 pi pi 4096 Apr 1 2022 power7 drwxr-xr-x 2 pi pi 4096 Apr 1 2022 power9 -rw-r--r-- 1 pi pi 823 Apr 1 2022 README.md drwxr-xr-x 2 pi pi 4096 Apr 1 2022 sandybridge drwxr-xr-x 2 pi pi 4096 Apr 1 2022 skx drwxr-xr-x 2 pi pi 4096 Apr 1 2022 steamroller drwxr-xr-x 3 pi pi 4096 Apr 1 2022 template drwxr-xr-x 2 pi pi 4096 Apr 1 2022 thunderx2 drwxr-xr-x 2 pi pi 4096 Apr 1 2022 x86_64 drwxr-xr-x 3 pi pi 4096 Apr 1 2022 zen drwxr-xr-x 2 pi pi 4096 Apr 1 2022 zen2 drwxr-xr-x 2 pi pi 4096 Apr 1 2022 zen3
Pro arm64 jsou relevantní cortexa53, cortexa57, firestorm (Apple A14, M1), thunderx2 (Neoverse N1), armsve a generic. Dále je možné také použít dynamickou architekturu, čehož jsem si doposud nevšiml. BLIS to nazývá rodina konfigurací (configuration family). V tom případě použijte název arm64.
Pro x86 je to složitější, protože tu máte amd64, což se může zdát jako název architektury. Ale ve skutečnosti to jsou jen nové procesory AMD (od Zen). Starší procesory AMD jsou v amd64_legacy a procesory Intel v intel64. Dohromady amd64, intel64 a amd64_legacy jsou v x86_64. Popsáno je to v soubory config_registry.
V případě BLIS je potřeba ještě ručně udělat link třeba na libopenblas.a, protože HPL libblis.a nezná. BLIS na rozdíl od OpenBLAS nedělá sám kontrolu výsledné knihovny, proto přidáme make -j${nproc} check. To je jen pár testů, jestli chcete testů více, je tu ještě make -j${nproc} test. Ale to asi není pro náš účel potřeba, protože samotná aplikace HPL stejně výsledky sama kontroluje.
U BLIS se nám nevytváří hezká jména knihoven podle procesoru, pro který je přeložena, ale udělá se jen soubor libblis.a. Pokud budete kompilovat knihovnu vícekrát, je potřeba si to pojmenovat ručně.
Doba kompilace BLIS je kratší, než OpenBLAS. Na RPi4 to je asi 2 minuty + 1 minuta check v případě kompilace pro jeden procesor a 5 minut + 1 minuta pro celou rodinu procesorů ( arm64). Na SandyBridge 4×2,5 GHz je to asi 30 sekund + 10 sekund check v případě kompilace pro jeden procesor a 2,5 minuty + 10 sekund pro celou rodinu procesorů ( x86_64).
HPL
Máme tedy zkompilovanou alespoň jednu nebo i více knihoven BLAS. Tím je většina práce hotova. Nyní zkompilujeme vlastní HPL, ale to již trvá daleko kratší dobu. HPL vezmeme v aktuální verzi 2.3 ze stránek netlib.org.
wget https://www.netlib.org/benchmark/hpl/hpl-2.3.tar.gz tar xvf hpl-2.3.tar.gz cd hpl-2.3
Při použití OpenBLAS kompilujeme takto
LDFLAGS=-L${HOME}/openblas/lib CFLAGS="-pthread -fopenmp" ./configure
make -j$(nproc)
Při použití BLIS jen změníme cestu ke knihovně
LDFLAGS=-L${HOME}/blis/lib CFLAGS="-pthread -fopenmp" ./configure
make -j$(nproc)
Výsledná binárka pak je ~/hpl-2.3/testing/xhpl. Pokud nepotřebujeme debugovat, tak na ní můžete spustit strip, protože ve výchozím stavu se HPL kompiluje s přepínačem -g.
Výsledné stripované binárky vypadají například takto
-rwxrwxr-x 1 rock rock 12530616 Oct 7 10:33 xhpl-r0.3.24 -rwxrwxr-x 1 rock rock 231600 Oct 7 13:22 xhpl_armv8-r0.3.24 -rwxrwxr-x 1 rock rock 207024 Oct 7 13:21 xhpl_cortexa53-r0.3.24 -rwxrwxr-x 1 rock rock 207024 Oct 7 12:58 xhpl_cortexa55-r0.3.24 -rwxrwxr-x 1 rock rock 231600 Oct 7 13:19 xhpl_cortexa57-r0.3.24 -rwxrwxr-x 1 rock rock 231600 Oct 7 13:13 xhpl_cortexa72-r0.3.24 -rwxrwxr-x 1 rock rock 231600 Oct 7 12:07 xhpl_cortexa73-r0.3.24 -rwxrwxr-x 1 rock rock 235696 Oct 7 12:26 xhpl_cortexx1-r0.3.24 -rwxrwxr-x 1 rock rock 235696 Oct 7 12:35 xhpl_neoversen1-r0.3.24 -rwxrwxr-x 1 rock rock 235696 Oct 7 12:44 xhpl_neoversen2-r0.3.24 -rwxrwxr-x 1 rock rock 231600 Oct 7 12:43 xhpl_neoversev1-r0.3.24 -rwxrwxr-x 1 rock rock 190640 Oct 7 12:52 xhpl_thunderx-r0.3.24 -rwxrwxr-x 1 rock rock 3529960 Oct 8 16:31 xhpl-blis0.9.0-arm64-no -rwxrwxr-x 1 rock rock 1178856 Oct 8 21:28 xhpl-blis0.9.0-cortexa53-no -rwxrwxr-x 1 rock rock 1174760 Oct 8 16:30 xhpl-blis0.9.0-cortexa57-no -rwxrwxr-x 1 rock rock 1158376 Oct 8 21:27 xhpl-blis0.9.0-generic-no -rwxrwxr-x 1 rock rock 1486056 Oct 8 16:29 xhpl-blis0.9.0-thunderx2-no -rwxr-xr-x 1 rock rock 1154968 Jul 17 20:25 xhpl-blis0.9.0.a53 -rwxr-xr-x 1 rock rock 1142680 Jul 17 20:33 xhpl-blis0.9.0.a57 -rwxr-xr-x 1 rock rock 1142680 Jul 17 20:37 xhpl-blis0.9.0.firestorm -rwxr-xr-x 1 rock rock 1142680 Jul 17 20:34 xhpl-blis0.9.0.generic -rwxr-xr-x 1 rock rock 1474448 Jul 17 20:38 xhpl-blis0.9.0.thunderx2 -rwxr-xr-x 1 rock rock 3506088 Jul 13 21:45 xhpl-blis0.9.0.u -rwxr-xr-x 1 rock rock 3497864 Jul 13 21:41 xhpl-blis0.9.0.u-single
Je vidět, že u knihovny BLIS univerzální binárka není až tak velká, jako u OpenBLAS. Má jen 3,4 MB, zato pro jeden procesor je BLIS o něco větší, má 1,1 MB. Pro OpenBLAS je to 11,7 MB a 0,2 MB. Taky je možné se podívat, které binárky jsou shodné. Jak jsme již říkali, tak OpenBLAS Cortex-A53 a Cortex-A55 jsou stejné (pro OpenBLAS-0.3.25 již ne) a pak Cortex-A57 a Cortex-A72 jsou stejné.
$ sha256sum xhpl* | sort 99bdc4ee089bf50b04f5bbb142e439c4b7bf9dd471fe9b1b2015572616a7adec xhpl_cortexa53-r0.3.24 99bdc4ee089bf50b04f5bbb142e439c4b7bf9dd471fe9b1b2015572616a7adec xhpl_cortexa55-r0.3.24 edb6113ff7da97b5c2bcf1c7069b05689b86e4ede85def818b68056dadab995b xhpl_cortexa57-r0.3.24 edb6113ff7da97b5c2bcf1c7069b05689b86e4ede85def818b68056dadab995b xhpl_cortexa72-r0.3.24
Předkompilované binárky pro aarch64
Pokud se vám nechce kompilovat knihovny a HPL, tak mám předkompilované binárky HPL pro Linux na aarch64 (arm64) na GitHubu. Jsou tam také výsledky některých ARM SBC včetně spotřeby a teploty.
Schválně jsem to dal až na konec, abych vás nepřipravil o radost z kompilování. Pokud chcete použít předkompilované binárky, stačí vám nainstalovat knihovny OpenMPI a to je všechno
$ sudo apt install openmpi-bin
Pokud budete mít výsledek na ARM64 jiné desky, nebo stejné desky jako mám na GitHubu, ale lepší, tak se o něj prosím podělte. Rád ho tam přidám.
HPL.dat
Ke spuštění HPL potřebujeme binárku (máme) a soubor HPL.dat. Ten definuje, co se bude počítat. Můžeme použít například tento
HPLinpack benchmark input file Innovative Computing Laboratory, University of Tennessee HPL.out output file name (if any) 6 device out (6=stdout,7=stderr,file) 1 # of problems sizes (N) 28000 Ns 20 # of NBs 96 104 112 120 128 136 144 152 160 168 176 184 192 200 208 216 224 232 240 248 NBs 0 PMAP process mapping (0=Row-,1=Column-major) 1 # of process grids (P x Q) 1 Ps 1 Qs 16.0 threshold 1 # of panel fact 1 PFACTs (0=left, 1=Crout, 2=Right) 1 # of recursive stopping criterium 4 NBMINs (>= 1) 1 # of panels in recursion 2 NDIVs 1 # of recursive panel fact. 2 RFACTs (0=left, 1=Crout, 2=Right) 1 # of broadcast 2 BCASTs (0=1rg,1=1rM,2=2rg,3=2rM,4=Lng,5=LnM) 1 # of lookahead depth 0 DEPTHs (>=0) 2 SWAP (0=bin-exch,1=long,2=mix) 8 swapping threshold 0 L1 in (0=transposed,1=no-transposed) form 0 U in (0=transposed,1=no-transposed) form 1 Equilibration (0=no,1=yes) 8 memory alignment in double
Většina parametrů může mít více hodnot, v jednom řádku máte například # of problems sizes (N), tedy kolik různých N má očekávat na následujícím řádku. Počet parametrů je omezen na 20. Občas by se hodilo i více, ale to bysme museli zasahovat do zdrojáku HPL. Druhá možnost je udělat více HPL.dat souborů a pustit si je postupně.
Hlavní parametr je Ns, tedy rozměr matice Ns × Ns se kterou se pracuje. Optimální je zvolit co nejvyšší Ns tak, aby se ještě vše vlezlo do RAM. Nezapomeneme přitom na nějakou spotřebu samotného operačního systému. Připomínáme, že paměťovou náročnost můžeme odhadnout jako místo zabrané maticí A, tedy 8 byte × Ns2 a k tomu přidáme rezervu zhruba okolo 20 %. Pozor však na dobu výpočtu, která roste jako 2/3 x Ns3-2Ns2. Pokud tedy budeme ze začátku ladit parametry, tak raději nejdříve s nižšími Ns, aby výpočet dlouho netrval.
Takže pro 4 GB RAM můžeme použít Ns=20 000, pro 8 GB RAM 28 000, pro 16 GB RAM 40 000. Viz tabulka, ve které už je s určitou režií OS počítáno
| RAM [GB] | Ns |
| 0,5 | 7000 |
| 1 | 10000 |
| 2 | 14000 |
| 4 | 20000 |
| 8 | 28000 |
| 16 | 40000 |
| 32 | 57000 |
| 64 | 80000 |
Takže nahradíme Ns v našem souboru HPL.dat podle toho, kolik máte volné RAM. A nyní už konečně program pustíme.
Spouštění a výsledky
Pokud máme OpenBLAS s OpenMP, tak je stiuace jednoduchá a spustíme prostě ./xhpl. Automaticky se využije plný počet jader. To však někdy není úplně žádoucí. Příkladem je x86 s HT jádry. Ta je pro větší Flop/s lépe vypnout, nebo nepoužívat. Pokud tedy chcete pustit HPL například na 4 jádrech, uděláme OMP_NUM_THREADS=4 ./xhpl. Je dobré nenastavovat OMP_NUM_THREADS úplně globálně, protože tuto proměnou používají všechny OpenMP programy a člověk může zapomenout, co kde nastavil a pak se nestačí divit (vlastní zkušenost™).
V případě BLIS s OpenMP nejde program spustit bez nastavené proměnné OMP_NUM_THREADS, protože bez ní se spustí jen na jednom jádře. Takže v tomto případě pouštíme OMP_NUM_THREADS=4 ./xhpl. Malá poznámka: ono se to tedy spouští stejně, jako OpenBLAS, ale vývojáři BLIS varují, že se proměnná OMP_NUM_THREADS používat nemá, protože může být v nějakém budoucím vydání odstraněna. Má se místo toho používat BLIS_NUM_THREADS.
Je dobré zkontrolovat pomocí top či htop, jestli pracuje tolik jader, kolik jsme chtěli. Chceme, aby pracovala všechna jádra, ale bez HT. Malá poznámka: na začátku výpočtu, kdy se plní paměť maticí a na konci výpočtu, kdy se kontroluje správnost používá OpenMP jen jedno vlákno. Tato část výpočtu může být i dost dlouhá, záleží na Ns. Ale ve vlastním výpočtu by měli jet jádra všechna.
V případě big.LITTLE je to složitější stejně jako u nových procesorů Intel, kde máte zároveň rychlá a pomalá jádra. HPL s tím nepočítá a rychlá jádra sice budou mít výpočet dřív, ale budou čekat na pomalá, protože práce je rozdělena mezi jádra rovnoměrně. Jedna z možností je pustit HPL dvakrát s různými parametry, jednou jen na rychlých jádrech a zároveň i na pomalých. Přitom je potřeba správně vybrat parametry tak, aby oba výpočty trvaly zhruba stejnou dobu. Příště si ukážeme, jak na to.
Když už koukáte do top/htop, tak se podívejte, jestli jste nepřehnali Ns a neplní se vám swap. V tom případě bude výpočet řádově pomalejší a nebude tak fungovat ani jako test stability. Možná tak jako test stability zařízení swap.
Samozřejmě na počítači nemáme pokud možno spuštěno nic jiného. Jednak by to zabíralo paměť a také obtěžovalo CPU a vyrovnávací paměť. Pokud to jde, tak nastartujeme i bez grafického rozhraní.
Pokud chcete testovat pouze stabilitu, tak máme v podstatě hotovo. Předpřipravený HPL.dat soubor spustí 20 testů s různou velikostí bloků Nb. Pokud všechny dopadnou dobře, tak váš počítač je z velkou pravděpodobností stabilní.
Výsledek pak vypadá například takto (zkráceno, ukazujeme jen první z 20 výsledků):
================================================================================ HPLinpack 2.3 -- High-Performance Linpack benchmark -- December 2, 2018 Written by A. Petitet and R. Clint Whaley, Innovative Computing Laboratory, UTK Modified by Piotr Luszczek, Innovative Computing Laboratory, UTK Modified by Julien Langou, University of Colorado Denver ================================================================================ An explanation of the input/output parameters follows: T/V : Wall time / encoded variant. N : The order of the coefficient matrix A. NB : The partitioning blocking factor. P : The number of process rows. Q : The number of process columns. Time : Time in seconds to solve the linear system. Gflops : Rate of execution for solving the linear system. The following parameter values will be used: N : 20000 NB : 104 112 120 128 136 144 152 160 168 176 184 192 200 208 216 224 232 240 248 256 PMAP : Row-major process mapping P : 1 Q : 4 PFACT : Crout NBMIN : 4 NDIV : 2 RFACT : Right BCAST : 1ring DEPTH : 0 SWAP : Mix (threshold = 8) L1 : transposed form U : transposed form EQUIL : yes ALIGN : 8 double precision words -------------------------------------------------------------------------------- - The matrix A is randomly generated for each test. - The following scaled residual check will be computed: ||Ax-b||_oo / ( eps * ( || x ||_oo * || A ||_oo + || b ||_oo ) * N ) - The relative machine precision (eps) is taken to be 1.110223e-16 - Computational tests pass if scaled residuals are less than 16.0 ================================================================================ T/V N NB P Q Time Gflops -------------------------------------------------------------------------------- WR00R2C4 20000 104 1 4 93.31 5.7164e+01 HPL_pdgesv() start time Tue Oct 31 14:56:12 2023 HPL_pdgesv() end time Tue Oct 31 14:57:45 2023 -------------------------------------------------------------------------------- ||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 3.47090776e-03 ...... PASSED ================================================================================
Duležité je PASSED a pak výkon v GFlop/s, zde asi 57,2 GFlop/s. Na samém konci se objeví ještě shrnutí, tedy že všech 20 testů dopadlo dobře.
================================================================================ Finished 20 tests with the following results: 20 tests completed and passed residual checks, 0 tests completed and failed residual checks, 0 tests skipped because of illegal input values. -------------------------------------------------------------------------------- End of Tests. ================================================================================
Tady máme příklad výsledku, kdy byla detekovaná chyba (FAILED). Pokud počítač zatuhne nebo se restartuje tak to je potřeba také brát jako negativní výsledek:
================================================================================ T/V N NB P Q Time Gflops -------------------------------------------------------------------------------- WR00R2C4 20000 64 1 1 367.00 1.4534e+01 HPL_pdgesv() start time Mon Jun 13 06:53:23 2022 HPL_pdgesv() end time Mon Jun 13 06:59:30 2022 -------------------------------------------------------------------------------- ||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 6.20248109e+07 ...... FAILED ||Ax-b||_oo . . . . . . . . . . . . . . . . . = 14.699328 ||A||_oo . . . . . . . . . . . . . . . . . . . = 5077.970709 ||A||_1 . . . . . . . . . . . . . . . . . . . = 5073.290150 ||x||_oo . . . . . . . . . . . . . . . . . . . = 21.018396 ||x||_1 . . . . . . . . . . . . . . . . . . . = 86900.973187 ||b||_oo . . . . . . . . . . . . . . . . . . . = 0.499989 ================================================================================
Dobré je se podívat, jestli výsledné Flop/s zhruba odpovídají počtu jader a frekvenci. Menší výkon může znamenat thermal-throttling nebo jiný problém. Vezmeme například SandyBridge 4×3,2 GHz (bez HT). Podle tabulky na Wikipedii má jedno jádro SandyBridge ve FP64 na takt 8 operací. Dostáváme tedy teoreticky 8×4×3,2 GFlop/s a to je asi 102 GFlop/s. Ve skutečnosti na 4 jádrech dosáhneme asi 91 GFlops/s, to je dobré. Pokud chybně pustíme xhpl na všech 8 jádrech včetně HT, bude výkon nižší asi 84 GFlop/s.
Na Raspberry Pi 4 s 8 GB RAM (4× Cortex-A72 1,8 GHz) trvá jeden test zhruba 15 minut. Pokud používáte OpenMP, tak před testem se navíc jedním jádrem plní paměť maticí (asi 4 minuty) a po skončení testu se opět jedním jádrem kontroluje správnost (asi 5 minut). Dohromady tedy 20 testů poběží asi 8 hodin. Nejlepší výkon jsem zatím dostal asi 18,4 GFlop/s. To je asi 2,6 FP64 operací na takt a jádro (Wikipedie po opravě pro Cortex-A72 říká 4). Jeff Geerling pro Raspberry Pi 4 s 8 GB RAM naměřil v HPL 11,8 GFlop/s, ale on to pouští automaticky a nijak zvlášť neoptimalizuje.
Radaxa Rock 5B s 16 GB RAM, který má stejný SoC jako Orange Pi 5 (RK3588, 4× Cortex-A76 2,4 GHz + 4× Cortex-A55 1,8 GHz), mi dává jen na 4 velkých jádrech nejlepší výkon asi 66,0 GFlops/s. To je asi 6,9 FP64 operací na takt a jádro (Wikipedie pro Cortex-A76 říká 8). Zde jeden test trvá podobnou dobu kolem 15 minut. V příštím díle zkusíme zkombinovat velká jádra s malými, která samostatně dávají asi 18,4 GFlop/s. Výsledek očekáváme o něco nižší, než 66,0+18,4, protože některé zdroje počítače (například RAM) budou sdílené.
Jeff pro stejnou desku na všech jádrech, ale s 4 GB RAM naměřil 51,4 GFlop/s. Zajímavé je, že Orange Pi 5 také se 4 GB RAM je podle Jeffa rychlejší s 53,3 GFlop/s. Kromě toho je rychlejší i v Geekbench 5 a 6. Rozdíl je v DMC (Dynamic Memory Interface) v RK3588, který umí snižovat takt RAM z 2112 MHz až na 528 MHz. V jádře Orange Pi 5 DMC není aktivní a RAM jede stále na plný výkon. V Rock 5B se frekvence snižuje, čímž se ušetří v klidu asi 0,5–0,6 W. Ale zvyšování frekvence je příliš konzervativní a testy tím trpí. Řešením je povolit v DMC rychlejší zvyšování frekvence echo 25 >/sys/devices/platform/dmc/devfreq/dmc/upthreshold místo výchozích 40. Vypadá to, že v posledních jádrech od Radaxy to je již takhle opravené.
Kromě toho mají obě desky s RK3588 zvláštní jádro označené například 5.10.110–8, ale to nemá s oficiálním jádrem 5.10 mnoho společného. Jde o jádro z Android BSP (Board Support Package). Na podpoře v oficiálním jádře se pracuje.
Raspberry Pi 5, na kterou ještě čekám (měla by dorazit příští týden?), má podle Jeffa 30,2 GFlop/s.
Mimochodem, v tabulce na Wikipedii byla chyba u ARM Cortex-A53, A55, A72, A73, A75 chybně uvedeno jen 2 FP64 operace na takt. Opravil jsem to na 4 jako u Cortex-A57.
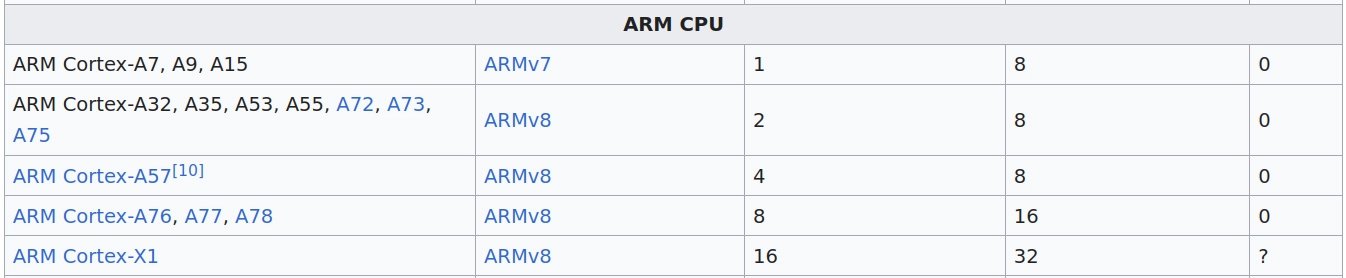
Chyba na Wikipedii

Po opravě
Zároveň je potřeba si uvědomit, že Cortex-A53 (třeba Raspberry Pi 3) a Cortex-A55 (třeba Odroid M1, nebo malé jádra v Orange Pi 5) jsou in-order (instrukce se nepřeskupují) a bude tedy težké dosáhnout 4 FP64 operace za takt. Naproti tomu Cortex-A57, A72 (Raspberry Pi 4), A73 a A75 jsou již out-of-order (instrukce se automaticky za běhu přeskupují pro optimální výkon), kde dosažení 4 FP64 bude již snazší.
Na Raspberry Pi je možné se přesvědčit, jestli došlo ke snižování frekvence kvůli teplotě i nezávisle pomocí vcgencmd get_throttled. Výsledek by měl být po testu throttled=0x0. Zároveň hlídá i pokles napájecího napětí. Jinde je možné sledovat frekvenci i teplotu CPU během výpočtu třeba právě v htop.

Optimalizace Flop/s
Takže máme ověřeno, že náš počítač či SBC je stabilní, nesnižuje frekvenci, případné přetaktování je stabilní, zdroj stačí dodávat proud i extrémně zatíženému procesoru, paměť je v pořádku (pokud jsme naplnili téměř celou paměť) a CPU počítá správné výsledky. Co dále? Můžeme zkusit dosáhnout co největšího výkonu Flop/s. K tomu bude potřeba experimentovat se souborem HPL.dat a také se způsobem, jak HPL spustit na více procesorech. To si detailně ukážeme v dalším díle.
Dopředu vám prozradím, že největší vliv má parametr Nb v HPL.dat. To je velikost bloků, do kterých se matice rozloží. Optimální hodnota závisí na velikosti vyrovnávací paměti, na počtu jader a bohužel na Ns. Dopředu se nedá moc říci, jaké Nb bude optimální. Je potřeba je vyzkoušet. Tak je ostatně i náš HPL.dat napsán. Ostatní parametry v souboru HPL.dat jsou myslím již docela optimální. Jejich popis najdete na oficiálních stránkách netlib.org a také v oficiálním FAQ.


































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU