
Zobrazení dat v tabulce máme za sebou a je otázka, kam se vrhnout dále. Bylo by samozřejmě možné pokračovat v dalších krocích CRUD, ale nemělo by to valný smysl. Použití JOOQ jsme již předvedli a tím pádem bychom se nedozvěděli nic nového. Proto se pustíme trochu jinou cestou a jak už mnohým napověděly texty tlačítek v ukázkové úloze, bude to směrem k manipulaci s CSV soubory. Tento jednoduchý typ souborů (Comma-separated values, hodnoty oddělené čárkami) se používá hlavně pro ukládání a výměnu tabulkových dat. I když je už velmi letitý, můžeme se s ním docela často potkat i dnes. Proto se určitě vyplatí se na něj podívat trochu podrobněji a ukázat si, co všechno je s ním možné provádět. H2 nám pokusy docela slušně usnadní, protože má k dispozici dvě speciální funkce – CSVREAD a CSVWRITE. Jak již samotné názvy funkcí napovídají, jedná se o čtení a zápis CSV souborů. Více podrobností můžeme najít v PDF dokumentaci na stranách 27 –28.
My si na úvod ukážeme několik jednoduchých variant a možností pomocí H2 administrační konzole. Proto si jí spustíme a zadáme velmi jednoduchý SQL příkaz:
call csvwrite ('zkusebni.csv', 'SELECT * FROM zkusebni');
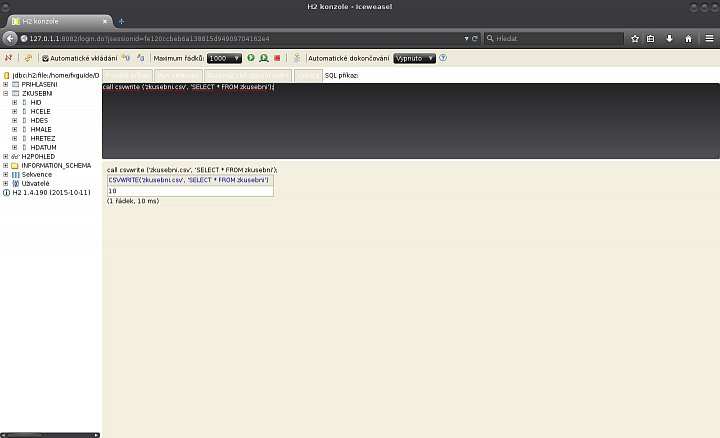
Příkaz má dva parametry – prvním je název CSV souboru, který chceme vytvořit (včetně případné kompletní cesty) a druhý pak slouží pro získání nějakých dat pro uložení do souboru. V našem konkrétním případě použijeme jako zdroj dat tabulku zkusebni. Pokud příkaz spustíme, stane se několik věcí:
- na prvním obrázku v první galerii vidíme, že byl příkaz v pořádku a také to, že se dotýkal celkem 10 záznamů
- na druhém obrázku první galerie pak vidíme, že se automaticky vytvořil požadovaný soubor v domovském adresáři
- třetí obrázek v první galerii nám dokazuje, že se nejen vytvořil, ale jsou v něm i příslušná data
To nakonec ověříme velmi jednoduchým příkazem, který nám nově vytvořený soubor načte do konzole:
SELECT * FROM CSVREAD ('zkusebni.csv');
Čtvrtý obrázek první galerie nám ukazuje, že se načtení povedlo, že data jsou k dispozici a po bližším zkoumání můžeme potvrdit, že se opravdu jedná o obsah uvedené tabulky. Než si ukážeme další možnost práce s CSV soubory, tak si v oblíbeném textovém editoru otevřeme soubor zkusebni.csv a k hodnotám ve sloupci HID přidáme jedničku (tím vznikne řada 21,41,61,81,101,91,71,51,31 a 11). Pak použijeme další příkaz:
INSERT INTO zkusebni SELECT * FROM CSVREAD ('zkusebni.csv');
Pátý obrázek v první galerii ukazuje úspěšnou akci, která obsahovala 10 záznamů. Tímto příkazem jsme vlastně vložili data z CSV souboru do vybrané tabulky. Proto zkusíme ověřit, jestli se to povedlo. Šestý obrázek první galerie jasně dokazuje, že se to opravdu povedlo a v tabulce je celkem 20 záznamů. Další možností je použít uložený CSV soubor a pomocí v něm obsažených dat vytvořit tabulku:
CREATE TABLE csvpokus AS SELECT * FROM CSVREAD ('zkusebni.csv');
Sedmý obrázek v první galerii ukazuje, že příkaz proběhl řádně a že se v seznamu tabulek skutečně objevila ta námi požadovaná. Její obsah ověříme jednoduchým dotazem a na posledním obrázku první galerii vidíme, že je správný a odpovídající. Tím bychom uzavřeli pokusy v administrační konzole a přesuneme se do naší aplikace. Zde si ukážeme trochu praktičtější využití CSV souborů. Jak již bylo výše uvedeno, tento typ souborů se pořád poměrně hojně využívá. My jako důkaz tohoto tvrzení použijeme web ČNB. Kromě jiného se zde nacházejí dvě pro nás použitelné informace: Kurzy devizového trhu a Kódy bank. V následují kapitole si ukážeme, jak je možné s těmito informacemi nakládat v rámci naší ukázkové aplikace. Seznam devizových kurzů je možné stáhnout přímo ze stránek ČNB ve formě textového souboru: Denní kurz. Jeho struktura vypadá následovně:
16.12.2015 #242 země|měna|množství|kód|kurz Austrálie|dolar|1|AUD|17,806
Seznam kódů bank je možné stáhnout ve formátu PDF a CSV, který je pro nás samozřejmě mnohem zajímavější. Jeho struktura je následující:
Kód platebního styku;Poskytovatel platebních služeb;BIC kód (SWIFT);Systém CERTIS 0100;Komerční banka, a.s.;KOMBCZPP;A 0300;Československá obchodní banka, a.s.;CEKOCZPP;A
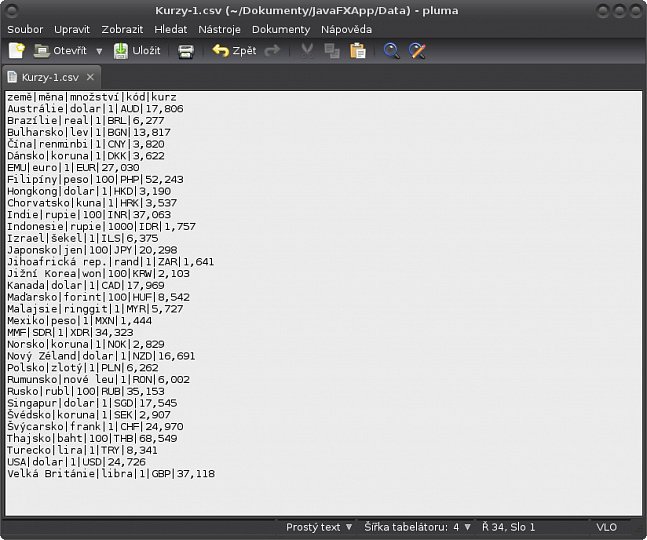
Jak je možné si z částečných výpisů všimnout, ani jeden z uvedených souborů nemá požadovanou strukturu – ani jeden totiž neobsahuje hodnoty oddělené čárkou! Máme tedy dvě možnosti: buď upravit samotné soubory tak, aby byly „opravdově“ CSV (to je docela pracné zvláště tam, kde jsou použity čárky i jinde, než v oddělení hodnot), nebo nějak „přesvědčit“ H2 funkce, aby se s tím vyrovnaly. Je asi jasné, že se pustíme druhou cestou. Ještě než začneme, tak si připravíme půdu:
- z příslušné stránky si otevřeme textový soubor s denním kurzem a obsah zkopírujeme bez prvního řádku do souboru – viz první obrázek ve druhé galerii
- z textu vynecháme první řádek s hlavičkou sloupců a uložíme do dalšího souboru – viz druhý obrázek druhé galerie
- z příslušné stránky stáhneme CSV soubor s kódy bank a uložíme – viz třetí obrázek ve druhé galerii
- z textu opět vypustíme řádek s hlavičkou a uložíme pod jiným jménem – viz čtvrtý obrázek druhé galerie
Pátý obrázek ve druhé galerii nám ukazuje, že jsme vytvořili celkem 4 soubory (Kurzy-1.csv, Kurzy-2.csv, Banky-1.csv, Banky-2.csv) a uložili je do domovského adresáře. Také je všechny uložíme do aplikačního adresáře Data, jak je patrné z posledního obrázku druhé galerie. Možná se to zdá trochu zbytečné, ale za chvíli uvidíme, že využijeme všechny vytvořené CSV soubory. Abychom zbytečně nekomplikovali situaci, nebudeme vytvářet žádnou extra tabulku pro uložení údajů a použijeme čistě a jenom uložené soubory. Jako první si ukážeme načtení souboru Banky-1.csv. Vytvoříme si novou proceduru, do které vložíme zatím pouze jeden příkaz podle vzoru z PDF dokumentace k H2 na straně 28:
private void readCSV1() {
ResultSet resultSet = new Csv().read("/home/fxguide/Banky-1.csv",null,null);
}
Při komentáři k zadanému příkazu budeme vycházet z popisu funkce na straně 156 v PDF dokumentaci. Příkaz má tři parametry:
- povinná cesta k požadovanému CSV souboru (fileNameString). Je nutné uvádět kompletní cestu a celý název souboru
- nepovinný seznam názvů sloupců/položek (columnsString). V našem případě zadána hodnota null, což znamená použití defaultní hodnoty. Více si objasníme v dalším příkladu
- nepovinné nastavení parametrů CSV souboru (csvOptions). Těch může být hned několik a jejich přehled najdeme v PDF dokumentaci na straně 123–124. Opět je použita defaultní hodnota, což celkem nepřekvapivě znamená použití znaku čárky jako oddělovače jednotlivých sloupců
Abychom mohli nově vytvořenou proceduru vyzkoušet, tak musíme prvně odstranit IJI avizovanou chybu a příkaz uzavřít do smyčky pro zachycení výjimek. Pak už stačí jenom přidat volání procedury do akce příslušného tlačítka a spustit aplikaci. Dobrým výsledkem by v tuto chvíli mělo být to, že systém nehlásí žádnou chybu či výjimku. Pokud to tak je, můžeme přidat podle vzoru v dokumentaci další příkazy pro zobrazení obsahu načteného souboru v konzole. Celá procedura pak bude mít asi takový formát:
private void readCSV1() {
try (ResultSet resultSet = new Csv().read("/home/fxguide/Banky-1.csv", null, null)) {
ResultSetMetaData metaData = resultSet.getMetaData();
while (resultSet.next()) {
for (int i = 1; i <= metaData.getColumnCount(); i++) {
System.out.println(
metaData.getColumnLabel(i) + ": " +
resultSet.getString(i));
}
System.out.println();
}
} catch (SQLException e) {
e.printStackTrace();
}
}
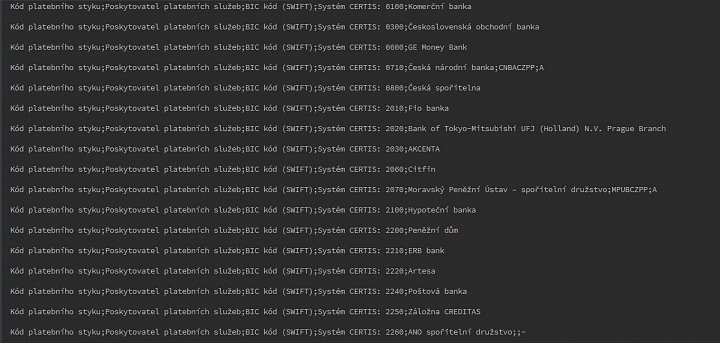

Pokud provedeme zkoušku znovu, tak už uvidíme nějaký výsledek. Jak se ale můžeme přesvědčit na prvním obrázku ve třetí galerii, není to výsledek zrovna ideální. Pokud se na něj zaměříme podrobněji, tak zjistíme dva závažné problémy:
- každý řádek začíná kompletním seznamem názvu sloupců (tedy prvním řádkem celého souboru)
- některé řádky jsou přečtené celé, některých je jenom část
- neúplně přečtené jsou ty řádky, kde se v názvu poskytovatele nachází řetězec , a.s. nebo obecně nějaký jiný, který obsahuje čárku
Je to asi celkem pochopitelný výsledek, protože jsme předpokládali defaultní hodnoty parametrů a tím je pro CSV samozřejmě oddělení položek čárkou. My ale máme soubor, kde jsou sloupce oddělené středníkem. A z tohoto rozporu vychází všechny problémy, které jsme výše popisovali. Proto se pokusíme vše napravit a použijeme trochu odlišný začátek procedury a nové volání výkonného příkazu:
Csv csvReader = new Csv();
csvReader.setFieldSeparatorRead(';');
try {
ResultSet resultSet = csvReader.read("/home/fxguide/Banky-1.csv",null,null);
...}
Rozdíl je pouze v tom, že jsme pro dříve použitou knihovnu nastavili námi požadovaný oddělovač sloupců (velmi vřele doporučujeme si na straně 124 PDF dokumentace podrobně přečíst, jaké jsou rozdíly mezi možnostmi nastavení CSV parametrů fieldDelimiter, fieldSeparator, rowSeparator a lineSeparator). Tímto postupem jsme nastavili novou defaultní hodnotu pro oddělovač sloupců a nemusí tak měnit hodnoty parametrů výkonné funkce. Výsledek spuštění nové verze procedury je vidět na druhém obrázku třetí galerii. Z letmého pohledu na obrázek je naprosto jasné, že výsledek vypadá mnohem čitelněji a přehledněji. Pokud se podíváme podrobněji, tak zjistíme následující:
- jednotlivé řádky jsou od sebe jednoznačně a správně oddělené
- na začátku každého sloupce/položky je jeho hlavička/nadpis
- ke každé položce je přiřazena správná hodnota ze sloupce
- položky s názvem poskytovatele jsou načtené kompletní, bez ohledu na to, jestli obsahují čárky či nikoliv
Je asi jasné, že takový výsledek je pro nás uspokojivý a můžeme přikročit k dalšímu pokusu. Aby se nám to nepletlo, tak si naší proceduru zkopíruje s novým názvem a zkusíme si zobrazit soubor Banky-2.csv (kód pro zobrazení hodnot v konzole zůstane beze změny):
private void readCSV2() {
Csv csvReader = new Csv();
csvReader.setFieldSeparatorRead(';');
try (ResultSet resultSet = csvReader.read("/home/fxguide/Banky-2.csv", null, null)) {
...
Znovu nastavíme volání nové procedury v akci tlačítka a spustíme aplikaci. Pokud se podíváme na třetí obrázek ve třetí galerii, tak vypadá opticky velmi podobně jako minulý výpis. Pokud se ale zaměříme na zobrazená data, už to taková sláva není! Nebudeme to nijak rozebírat, protože důvod je jasný:
- první řádek souboru není ve výpisu vůbec zobrazen
- hodnoty z prvního řádku jsou použity jako nadpisy sloupců
- uložené soubory se liší pouze tím, že první varianta má v prvním řádku nadpisy sloupců, kdežto druhá začíná rovnou daty
- defaultní nastavení druhého parametru výkonné funkce znamená právě to, že se první řádek čteného souboru použije jako nadpisy sloupců
Pomoc naštěstí existuje a je poměrně jednoduchá: definujeme si názvy sloupců sami a přidáme jejich seznam do parametru výkonné procedury:
String[] columnNames = { "Kod", "Poskytovatel", "BIC", "CERTIS" };
Csv csvReader = new Csv();
csvReader.setFieldSeparatorRead(';');
try (ResultSet resultSet = csvReader.read("/home/fxguide/Banky-2.csv", columnNames, null)) {
Jak je patrné z čtvrtého obrázku třetí galerie, jsou výsledky také správné a přehledné. Máme tak možnost zpracovat CSV soubory jak s použitím názvu sloupců přímo v souboru nebo definovaných jako aplikační parametr. Už je asi také jasnější, proč jsme prováděli zdánlivě nadbytečné ukládání souborů velmi podobného formátu. Zbývá nám ještě vyzkoušet zobrazení údajů o denních kurzech devizového trhu. Za tímto účelem si vytvoříme opět extra proceduru a uděláme v ní vlastně jenom tři změny:
private void readCSV3() {
String curDir = new File("").getAbsolutePath();
Csv csvReader = new Csv();
csvReader.setFieldSeparatorRead('|');
try(ResultSet resultSet = csvReader.read(curDir+"/Data/Kurzy-1.csv",null,null)) {
...
První změnou je použití souboru, který je uložený v aplikačním adresáři Data. Toho bylo dosaženo využitím proměnné, která předává kompletní cestu k aktuálnímu adresáři. S její pomocí už pak není odkaz na daný soubor problém. Druhou změnou je pak nový znak pro oddělení sloupců a poslední samozřejmě změna čteného souboru. Pokud novou verzi vyzkoušíme, dostaneme výsledek jako na pátém obrázku ve třetí galerii. Můžeme také samozřejmě použít druhý soubor s kurzy a nastavit názvy sloupců:
...
String[] cols = new String[] {"Země", "Měna","Množství", "Kód", "Kurz"};
try {
ResultSet resultSet = csvReader.read(curDir+"/Data/Kurzy-2.csv",cols,null);
...
Výsledek spuštění je viditelný na šestém obrázku třetí galerie. Tímto příkladem bychom mohli ukončit ukázky čtení CSV souborů a přesunout se k jejich vytváření. V dokumentaci je také k dispozici jednoduchá ukázka, ale my zkusíme jinou variantu. Načteme jeden soubor do příslušné proměnné, pomocí této proměnné vytvoříme nový CSV soubor a jeho obsah zobrazíme v konzole:
private void writeCSV() {
String curDir = new File("").getAbsolutePath();
Csv csvReader = new Csv();
csvReader.setFieldSeparatorRead(';');
try(ResultSet banky1ResultSet = csvReader.read(curDir + "/Data/Banky-1.csv", null, null)) {
Integer res = new Csv().write(curDir + "/Data/Banky-3.csv", banky1ResultSet, null);
System.out.println("Počet řádků souboru: " + res.toString());
System.out.println("----------------");
} catch (SQLException e) {
System.err.println("Vstupno/výstupní chyba pri zpracovávaní CSV");
e.printStackTrace();
return;
}
try(ResultSet resultSet = new Csv().read(curDir + "/Data/Banky-3.csv", null, null)) {
...
V proceduře opět využíváme proměnnou pro aktuální adresář a pro čtení nastavujeme jako oddělovač středník. Vybraný soubor načítáme s uloženými názvy sloupců do proměnné příslušného typu. Při zápisu souboru používáme proměnnou, která obsahuje počet záznamů do souboru uložených. Vlastnosti zapisovaného souboru necháváme na přednastavených hodnotách. Formát nově vytvořeného souboru si můžeme prohlédnout na sedmém obrázku ve třetí galerii. Z něj je patrné, že oddělovačem jednotlivých sloupců je čárka a všechny hodnoty jsou uzavřené v uvozovkách. Proto se při čtení nově uloženého souboru nemusíme zabývat žádným nastavením a provést ho v té nejjednodušší formě. Výsledek našeho snažení je pak vidět na osmém obrázku třetí galerie. Na dalších čtyřech obrázcích ve třetí galerii jsou pak vidět výsledky stejných příkazů, které byly zadány pomocí H2 administrační konzole:

- SELECT * FROM CSVREAD (‚Banky-1.csv‘, null, null);
- SELECT * FROM CSVREAD (‚Banky-1.csv‘, null, ‚fieldSeparator=;‘);
- SELECT * FROM CSVREAD (‚Banky-2.csv‘, ‚Kod;Poskytovatel;BIC;CERTIS‘, ‚fieldSeparator=;‘);
- SELECT * FROM CSVREAD (‚Kurzy-1.csv‘, null, ‚fieldSeparator=|‘);
Jako úplně poslední věc dnešního dílu dáváme do přílohy kompletní kód příslušné procedury: samexam7.java.
V dnešním dílu jsme ukončili kapitolu o H2 databázi. Ukázali jsme si možnosti manipulace s CSV soubory včetně praktických příkladů použití na zajímavých datech. V příštím dílu se zaměříme na ukázku možností zabezpečení dat v H2 i PG databázích za pomoci nativních nástrojů a frameworku Apache Shiro. Tím také vlastně zakončíme naší poměrně dlouhou sérii článků a propojení JavaFX aplikací s databázemi.
