
Obsah
1. Posílání zpráv v aplikacích založených na mikroslužbách
2. Dvě klíčové součásti návrhu mikroslužeb: databáze a komunikace
3. Zajištění nezávislosti mikroslužeb aneb koncept tlačítka STOP
5. Tři důvody, proč poslat zprávu
6. Zpráva požadující provedení úlohy – COMMAND
7. Směrování používané při posílání příkazů (COMMAND)
8. Zpráva poslaná ve chvíli, kdy došlo k nějaké události – EVENT
9. Směrování používané při vzniku události (EVENT)
10. Zpráva pro získání nějaké informace – QUERY
11. Směrování používané při dotazech (QUERY)
12. Vzájemné propojení mezi komponentami
13. Škálování aplikace ve chvíli, kdy je vytvořen „distribuovaný monolit“
14. Jediný centralizovaný message broker
16. Další dělení hierarchického modelu
1. Posílání zpráv v aplikacích založených na mikroslužbách
„It's hard to get messaging right“
V předchozí části seriálu o mikroslužbách jsme se věnovali velmi důležitému tématu – návrhem databáze resp. přesněji řečeno namodelováním reprezentace stavu celé aplikace, pochopitelně včetně způsobů změny tohoto stavu. Připomeňme si, že bylo důležité rozdělit databázi takovým způsobem, aby každá komponenta měla k dispozici právě tu část databáze, kterou pro svoji činnost nutně potřebuje. Právě rozdělení databáze pro jednotlivé komponenty je kritickou částí návrhu, která odlišuje takzvaný „distribuovaný monolit“ od skutečné aplikace založené na mikroslužbách. Kromě klasického rozdělení databáze na jednotlivé části jsme si minule popsali i takzvanou architekturu kappa, v níž je ústředním prvkem systém NATS Streaming Server či Apache Kafka, který obsahuje neměnitelné záznamy (log) se všemi změnami stavu celé aplikace. Jednotlivé komponenty tyto změny postupně aplikují na svoje lokální databáze a přibližují se tak postupně okamžitému a pravdivému stavu, který je uložen formou neměnitelných záznamů se změnami.

Obrázek 1: Příklad aplikace používající architekturu kappa.
Výsledkem návrhu by měla být architektura, ve které si každá služba autonomně řídí svůj stav a taktéž případnou změnu svého stavu (ideální je pochopitelně mít co nejvíce komponent bezstavových – stateless, pokud je to možné). Požadavky na autonomnost služeb jsou ve skutečnosti ještě větší. Kromě toho, že služba má svoji databázi, neměla by (kromě svého API) sdílet svůj stav a už vůbec ne svůj interní (vnitřní) stav. Což ale nejsou příliš překvapující požadavky, protože podobné požadavky existují i v objektově orientovaném programování a nazýváme je zapouzdření (encapsulation). Dále je nutné, aby služby pro komunikaci používaly vždy své API a nikoli nějaké postranní kanály.

Obrázek 2: Jednotlivé mikroslužby mezi sebou mohou komunikovat například s využitím protokolu HTTP (REST API), STOMP atd. Ovšem důležité je, že každá mikroslužba má svoji databázi.
2. Dvě klíčové součásti návrhu mikroslužeb: databáze a komunikace
„Monolith components are large components that contain a lot of functionality“
Návrh databáze je skutečně primární částí naplánování modelu celé architektury aplikace (a měl by být proveden už na začátku, ideálně možná ještě před založením repositáře se zdrojovými kódy :-), ovšem pochopitelně se nejedná o jedinou součást návrhu, kterou je nutné vyřešit. Dalším důležitým architektonickým rozhodnutím je určení, jakým způsobem vlastně budou mezi sebou jednotlivé komponenty komunikovat. A podobně jako bylo možné (mnohdy nutné) pro každou komponentu zvolit odlišnou databázi (SQL či nějakou NoSQL, ať již dokumentovou, objektovou nebo grafovou atd.), i způsoby vzájemné komunikace služeb – posílání zpráv – je nutné navrhnout podle toho, o jakou komunikaci se jedná. V praxi to znamená, že se většinou použije větší množství protokolů a většinou i několik instancí message brokerů, popř. se klasičtí message brokeři zkombinují se streamingem záznamů/událostí. A v neposlední řadě je nutné určit, zda spolu budou jednotlivé komponenty komunikovat přímo či zda se vytvoří centrální popř. hierarchicky umístěné uzly, k nimž se jednotlivé komponenty budou připojovat.

Obrázek 3: Monolitická služba, která je sice naškálována, ale sdílí společnou databázi.
3. Zajištění nezávislosti mikroslužeb aneb koncept tlačítka STOP
„As a fan of microservices, I fear enterprises are blindly charging forward and could be left disappointed with a microservices-based strategy if the technology is not appropriately applied.“
Sinclair Schuller
Jak se vlastně pozná dobrý návrh architektury aplikace založené na mikroslužbách? Samozřejmě je k dispozici velké množství kritérií, například propustnost, maximální počet současně obsluhovaných klientů, škálovatelnost, systémové nároky atd. atd. Existuje ovšem ještě jedno zajímavé kritérium, které osobně označuji termínem „tlačítko STOP“. Celá aplikace by totiž měla být – pochopitelně v ideálním světě – schopna do jisté míry fungovat i tehdy, pokud nějakou z komponent (mikroslužeb atd.) vypneme. A i když aplikace přestane nabízet některé služby, měla by být schopna se automaticky vrátit k běžné činnosti ihned poté, co se zastavená komponenta opět restartuje. Právě toto chování totiž vyžadujeme – schopnost aplikace se „vzpamatovat“ i po částečném výpadku, a to bez toho, aby se musela celá aplikace vypnout s postupným zapínáním služeb podle nějakého návodu (toto chování ponechme monolitním aplikacím).

Obrázek 4: Jedna z nejjednodušších forem testování mikroslužeb – tlačítko STOP u každé mikroslužby.

Obrázek 5: Výpadek složité služby, který byl viditelný i zákazníkům.
4. Význam pojmů CQS a CQRS
„“…organizations which design systems … are constrained to produce designs which are copies of the communication structures of these organizations.”“
V souvislosti se zprávami i s celým návrhem architektury aplikace založené na mikroslužbách se často setkáme s termíny CQS a CQRS. Termín CQS znamená Command–query separation a CQRS je zkratkou vzniklou z Command-query responsibility segregation (nebo separation). CQS se používá při vývoji a znamená takový návrh aplikace (typicky založené na OOP, ale není to nutné), kdy každá funkce či metoda provádí buď nějaký příkaz (command) nebo slouží k získání dat (query); žádná z metod by neměla provádět obě akce. Zatímco se metodika CQS typicky aplikuje na jednotlivé třídy, tedy na relativně malou a izolovanou část aplikace, je druhá z metodik CQRS aplikována na celou architekturu služeb a mikroslužeb, přičemž command je ta část modelu aplikace, která slouží ke změně stavu a query druhá část modelu používaná pro agregaci dat.
Jak by mohlo vypadat aplikování metodiky CQRS v praxi? Představme si nějakou jednoduchou službu, jejímž úkolem je vést seznam uživatelů, samozřejmě včetně jejich metadat. Tato služba bude mít svoje API, jednoduchý model pro zápis nových uživatelů, dotaz, zda uživatel existuje, agregace uživatelů podle různých kritérií atd. A samozřejmě bude tato služba používat svoji databázi s tabulkou uživatelů a dalšími pomocnými tabulkami.
Partner seriálu o mikroslužbách
V IGNUM mají rádi technologie a staví na nich vlastní mikroslužby, díky kterým je registrace a správa domén, hostingů a e-mailů pro zákazníky hračka. Vymýšlet jednoduchá řešení pro obsluhu složitých systémů a uvádět je v život je výzva. Společnost IGNUM miluje mikroslužby a je proto hrdým partnerem tohoto seriálu.
Taková služba sice může dlouhou dobu pracovat bez problémů, ovšem při větší zátěži se mohou ukázat limity používané databáze. Zjednodušeně řečeno – pro zpracování dotazů (QUERY/SELECT) je nutné používat indexy, ovšem existence těchto indexů obecně zhoršuje a zpomaluje operace typu INSERT, UPDATE i DELETE. V praxi se tedy musí vyvažovat mezi větším množstvím indexů pro všechny používané dotazy a menším množstvím v případě, že se změny v databázi negativně projevují na celkové výkonnosti služby.
Alternativně můžeme aplikovat metodiku CQRS. Model aplikace se rozdělí na dvě části – změnu stavu (COMMAND) a dotazy pro získání agregovaných dat (QUERY).
Řešení je ovšem možné ještě dále upravit, a to rozdělením databáze na dvě části, z nichž jedna bude určena pro zápisy (těch bývá řádově menší množství) a druhá část bude určena pro dotazy. Obě databáze ovšem bude nutné synchronizovat.
V další iteraci může dojít k rozdělení celé služby na dvě části a dokonce i k odstranění jedné databáze. K dispozici zůstane jen databáze optimalizovaná na zápisy, kdežto namísto druhé databáze bude použita prostá cache, pochopitelně synchronizovaná s databází (a zde již záleží na tom, zda budeme potřebovat přesnou repliku či zda se spokojíme s tím, že záznamy nemusí být v daný okamžik naprosto totožné).
5. Tři důvody, proč poslat zprávu
„“Design the organisation you want, the architecture will follow (kicking and screaming).”“
Při návrhu komunikace mezi jednotlivými komponentami je dobré si uvědomit, proč spolu vlastně jednotlivé komponenty potřebují komunikovat. V naprosté většině případů se jedná o jednu ze tří možností vypsaných pod tímto odstavcem:
- Jedna komponenta vyžaduje, aby některá z dalších komponent provedla určitou činnost či určitý příkaz. Tento typ zprávy budeme označovat slovemCOMMAND a většinou znamená, že se změní stav aplikace (například záznam informace o novém uživateli). Podobnost s výše zmíněnou metodikou CQRS pochopitelně není náhodná.
- Komponenta oznamuje dalším komponentám, že došlo k nějaké události. Z tohoto důvodu budeme tento typ zprávy označovat slovemEVENT. Samotné oznámení o vzniku události nemusí nutně znamenat změnu stavu aplikace, ovšem na tuto zprávu mohou příjemci reagovat posláním jiné zprávy typu COMMAND.
- A konečně komponenta potřebuje získat nějaký údaj či údaje. Tento typ zprávy pojmenujeme QUERY a typicky by se jejím posláním neměl měnit stav aplikace (opět viz metodika CQRS). Z tohoto hlediska se většinou jedná o nejjednodušeji implementovatelné zprávy, ovšem jak uvidíme dále, i zde může dojít ke komplikacím v případě, že se o výsledku může hlasovat.
Tyto tři typy zpráv se odráží i v pojmenování některých technologií. Můžeme se například setkat se systémy, v nichž se používají tři navzájem nezávislé typy „sběrnic zpráv“ typicky pojmenované CommandBus, EventBus a QueryBus.
6. Zpráva požadující provedení úlohy: COMMAND
„Microservice – “small autonomous services modelled around business domain that work together““
Sam Newman, jeden z původních autorů myšlenky mikroslužeb
Na jednotlivé typy zpráv popsaných v předchozí kapitole se můžeme podívat podrobněji. Zaměřme se nejdříve na první typ zpráv, tj. na zprávy typu COMMAND. Tyto zprávy obecně slouží ke změně stavu aplikace a obecně tedy provádí nějaký side-effect, typicky modifikaci dat (kromě odpovědi se změní i nějaká další část aplikace, například se zapíše záznam do databáze atd.). Můžeme se ale setkat i s takovými zprávami typu COMMAND, které stav aplikace nezmění. Poměrně dobrým příkladem může být žádost o poslání e-mailu uživateli – zde se tedy mění spíše stav okolního systému (mailboxu příjemce).
Zprávy typu COMMAND jsou typické tím, že většinou existuje pouze jediná komponenta, která může daný příkaz provést. To, o kterou komponentu ve funkci příjemce zprávy se konkrétně jedná, však nemusí zdrojová komponenta (tj. komponenta, která příkaz posílá) řešit, resp. přesněji řečeno by to ani ve správně navržené aplikaci neměla řešit, protože by se jednalo o zbytečně těsné svázání obou komponent (mikroslužeb).
Většinou taktéž požadujeme, aby přijímající komponenta poslala odpověď na zprávu typu COMMAND. V naprosté většině případů se jedná o jednoduchou stavovou informaci typu OK/Not OK popř. ACK/NACK, jen výjimečně s dalšími daty (například s ID vytvořeného požadavku); v případě, že by v odpovědi byla další data, jednalo by se pravděpodobně o porušení CQRS. Tento typ odpovědi může být poslán synchronně či asynchronně – viz též navazující kapitolu.
7. Směrování používané při posílání příkazů (COMMAND)
„‚Service‘ does not imply…Docker, Stateless, Kubernetes, JSON, ESB, Cloud, NoSQL, …“
Clemens Vasters
Existuje několik způsobů směrování (routing) používaných pro zprávy typu COMMAND. Typicky je možné rozhodnout přímo na základě příslušného příkazu, která komponenta má příkaz zpracovat (příklady příkazů: create_new_user, send_notification_email atd.). V tom nejjednodušším případě se příkaz ihned přepošle cílové komponentě, ovšem většinou se setkáme s využitím front zpráv (message queue), které slouží jak pro zajištění persistence zpráv v případě, že přijímající komponenta není spuštěna či pokud je přetížena, tak i případně pro load balancin. Použitou komunikační strategií je tedy strategie PUSH-PULL.

Obrázek 6: Komunikační strategie typu PUSH-PULL bez použití fronty.
Samotné téma load balancingu pro zprávy typu COMMAND je dosti rozsáhlé, protože tyto zprávy mění stav aplikace. Nicméně cílová komponenta může být spuštěna několikrát a existuje hned několik strategií, jak zprávy/příkazy z fronty přeposílat. Nejjednodušší a pravděpodobně i nejpoužívanější řešení je založeno na tom, že se ta instance komponenty, která má volné prostředky (strojový čas) sama přihlásí o přiřazení příkazu (úkolu), což je zajištěno přes protokoly používané message brokery. Používají se však i další způsoby; jeden z nich je založen na SLA. V praxi to znamená, že příkazy související s „VIP uživateli“ jsou zpracovány na dedikovaných instancích popř. mají vyšší prioritu (a většina message brokerů dokáže nějakým způsobem pracovat s prioritou zpráv, popř. lze využít specializované prioritní fronty).

Obrázek 7: Komunikační strategie typu PUSH-PULL s větším počtem příjemců.
V předchozím textu jsme si řekli, že odpovědi na zprávy typu COMMAND bývají většinou pouze potvrzující, tj. komponenta získá informaci o tom, zda byl příkaz proveden či nikoli (popř. proč nebyl proveden). Odpovědi mohou být synchronní, ovšem častěji se setkáme s asynchronními odpověďmi, které umožňují, aby obě komponenty před potvrzením mohly provádět jinou činnost. Jak se však realizují asynchronní odpovědi? Jednou z možností je použití druhé fronty, do které bude zprávy posílat příjemce příkazu (COMMAND). V takové odpovědi bývá uvedeno jednoznačné ID příkazu. Alternativně se někdy můžeme setkat i s tím, že přímo součástí příkazu bývá jméno nové dočasné fronty, kterou příjemce příkazu vytvoří a která se posléze automaticky zruší (zde ovšem záleží na typu použitého message brokera, do jaké míry je flexibilní při vytváření a rušení front).

Obrázek 8: Složitější konfigurace nabízená například systémem RabbitMQ.
8. Zpráva poslaná ve chvíli, kdy došlo k nějaké události – EVENT
Druhý typ zpráv nazvaný EVENT je prakticky libovolnými komponentami posílán ve chvíli, kdy dojde k určité události, o nichž chce komponenta informovat okolní systém. Může se jednat o prakticky libovolnou událost (tedy nikoli pouze o událost na GUI). Příkladem může být detekce změny některých dat, zjištění, že došlo k překročení nějakého časového limitu, informace o přetížení určitého uzlu v clusteru, informace o překročení nastaveného limitu databáze, opakované pokusy o přihlášení atd. Můžeme sem řadit i komponenty/mikroslužby typu cron, které slouží právě k posílání informací o naplánovaných událostech, ať již periodických (zaslání e-mailu se žádostí o změnu hesla, pravidelná kontrola jiné služby přes její API), tak i neperiodických (ad-hoc události). Typicky komponenta pouze oznámí, že došlo k nějaké události a neočekává žádné odpovědi. Z implementačního hlediska je posílání a zpracování těchto zpráv nejjednodušší.
9. Směrování používané při vzniku události (EVENT)
Zprávy typu EVENT se většinou směrují odlišným způsobem, než zprávy typu COMMAND. Je tomu tak z toho důvodu, že na události může reagovat obecně větší množství komponent, nikoli jediný typ komponenty. Z tohoto důvodu se používá komunikační strategie PUBLISH-SUBSCRIBE neboli PUB-SUB, která je podporována většinou message brokerů. Ovšem můžeme se setkat i s dalšími konfiguracemi, například s takzvanými soupeřícími konzumenty (competing consumers) nebo s balanced consumers.
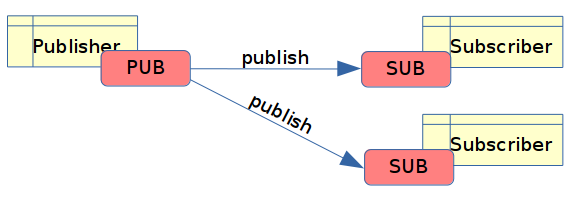
Obrázek 9: Komunikační strategie typu PUBLISH-SUBSCRIBE používaná při vzniku událostí.
10. Zpráva pro získání nějaké informace – QUERY
Posledním typem zprávy jsou zprávy označované QUERY. Jak již víme z předchozího textu, měly by tyto zprávy požadovat vrácení nějakých dat popř. agregaci dat, ovšem přitom by nemělo dojít ke změně stavu aplikace (side-effect). A opět platí – komponenta, která data vyžaduje, by ideálně nemusela a vlastně ani neměla vědět, která komponenta jí bude ve skutečnosti odpovídat. Jen tak je ostatně možné zaručit modularitu celého systému i možnost výměny některé komponenty za odlišnou službu (nebo dokonce jen za její mock).
Vzhledem k tomu, že tento typ zprávy vyžaduje odpověď, používá se zde buď synchronní protokol typu REQUEST-RESPONSE nebo asynchronní příprava dat – v tomto případě lze využít již zmíněné dvojice front, kde do jedné fronty budou chodit požadavky, tj. zprávy typu QUERY a do druhé fronty odpovědi s požadovanými daty.
11. Směrování používané při dotazech (QUERY)
Dotazy QUERY bývají zpracovány dvěma způsoby. V tom jednodušším případě odpověď připraví a pošle jediná komponenta, která je za poskytnutí odpovědi zodpovědná (tato komponenta ovšem může být load-balancovaná). Odpovědi tohoto typu se zpracovávají velmi jednoduše, protože pokud získáme jedinou odpověď, můžeme ji považovat za pravdivou.

Obrázek 10: Synchronní odpovědi lze získat klasickou komunikační strategií REQ-REP.
Existuje ovšem ještě jedna možnost používaná u rozsáhlých služeb. Někdy se setkáme s označením scatter-gather query a v podstatě se jedná o hlasování. Na samotný dotaz (QUERY) totiž může v nastaveném časovém intervalu odpovědět větší množství komponent a každá odpověď může být dokonce odlišná!

Obrázek 11: Jeden dotaz s několika různými odpověďmi.
Dobrým příkladem může být dotaz na cenu nějaké služby nebo výrobku. Na tento dotaz může odpovědět jedna komponenta, která zná obecné ceny, dále odpoví komponenta, která řeší přesnější ceny a slevy pro VIP zákazníky, další komponenta má k dispozici seznam slevových akcí atd. Nakonec záleží na tazateli, kterou odpověď si vybere a jak případně zahrne všechny odpovědi do své logiky.
12. Vzájemné propojení mezi komponentami
Dalším problémem, který je nutné při návrhu architektury aplikace uspokojivě vyřešit, je konfigurace vzájemného popojení jednotlivých komponent. Zde máme k dispozici hned několik možností, z nichž o některých již víme, že nejsou ideální, resp. mnohem přesněji to ví ti vývojáři, které tyto způsoby použili a narazili na jejich meze.
Mezi používané typy propojení patří:
- obecné propojení typu „každý s každým“
- využití magického centralizovaného message brokeru
- hierarchická struktura založená na tzv. clusterech
13. Škálování aplikace ve chvíli, kdy je vytvořen „distribuovaný monolit“
Jeden z obecně nejhorších způsobů spočívá v tom, že každá komponenta může přímo komunikovat s jinou komponentou na základě svého vlastního rozhodnutí, přesněji řečeno na základě rozhodnutí programátora, který danou komponentu navrhnul. Pravděpodobně vás již napadlo, že v tomto případě může dojít k mnoha nepříjemnostem. V první řadě bude celá struktura aplikace dosti chaotická, a to již ve chvíli, kdy bude aplikace obsahovat jednotky až desítky služeb. Dále se tato architektura pravděpodobně zcela automaticky nevzpamatuje při výpadku některého z uzlů (a pokud se vzpamatuje, znamená to, že se jedná o časově náročnou práci vývojářů jednotlivých komponent). Problematické až zcela nemožné je škálování jednotlivých komponent, konfigurace load balancingu na základě požadavků SLA, mechanismus, kterým se jednotlivé služby vyhledávají atd. atd.

Obrázek 12: Při malém množství komponent může být propojení typu „každý s každým“ zdánlivě snadno zvládnutelné.
Zajímavé a možná i typické a vlastně i pochopitelné je, že se tato architektura používá ve chvíli, kdy se nějaký tým rozhodne rozdělit původně monolitickou aplikaci na „mikroslužby“. Ovšem jedná se o ten druhý nejhorší možný způsob, který pouze vede k vytvoření „distribuovaného monolitu“ (prvním nejhorším způsobem je postavit komponenty nad jedinou databází).
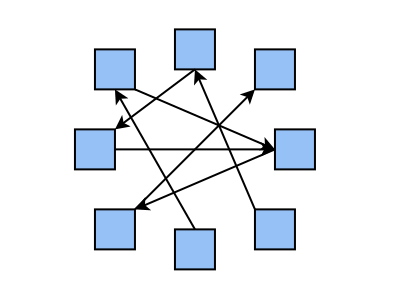
Obrázek 13: Při rostoucím množství komponent se velmi rychle ukazují limity této architektury.
14. Jediný centralizovaný message broker
Zatímco první způsob popsaný v předchozím textu představoval jeden extrém, můžeme se setkat i s opačným extrémem. Ten bývá založen (v tom lepším případě) na centrálním uzlu s message brokerem, přes který jednotlivé služby komunikují. Přitom je zaručeno, že žádné jiné komunikační cesty nebudou použity. Ve skutečnosti se nejedná o špatný návrh, ovšem musíme počítat s tím, že se při jeho důsledném dodržování zhorší škálovatelnost a i další růst aplikace o další komponenty/mikroslužby bude omezen výkonem a škálovatelností message brokera (musíme navíc uvažovat i o případných omezeních daných vrstvou a fyzickým oddělením jednotlivých komponent na různé stroje). Pro menší aplikace se však může jednat o dobrý přístup.

Obrázek 14: Při relativně malém množství komponent bývá použití centrálního message brokera dobrou volbou.

Obrázek 15: Pokud však počet komunikujících komponent překročí určitou mez, může se message broker stát úzkým hrdlem celé aplikace.
15. Hierarchický model
V případě ještě větších aplikací s mnoha desítkami či dokonce se stovkami komponent je však nutné způsob komunikace navrhnout ještě pečlivěji. Setkáme se například se sdružováním jednotlivých komponent do větších hierarchicky organizovaných celků (řekněme clusterů v původním významu tohoto slova), přičemž každý z těchto clusterů sdružuje služby, které k sobě logicky patří. V každém clusteru se typicky nachází centrální message broker a všechny služby v clusteru komunikují pouze s tímto uzlem. Jednotlivé clustery jsou spojeny dalším (tentokrát již centrálním) message brokerem, takže výsledkem může být poměrně snadno uchopitelná a elegantní rekurzivní struktura. Výkonnost tohoto řešení je založená na předpokladu, že logicky související služby spolu komunikují častěji, takže centrální message broker není přetěžován.

Obrázek 16: Hierarchický model aplikace se sdružením těch služeb, které k sobě patří buď logicky, nebo podle toho, jak intenzivně spolu komunikují.
16. Další dělení hierarchického modelu
Prakticky nic nám pochopitelně nebrání v tom, aby byl hierarchický model ještě více strukturovaný, což je naznačeno na následujícím obrázku:

Obrázek 17: Další dělení hierarchického modelu.

17. Obsah další části seriálu
Již mnohokrát jsme se v tomto seriálu setkali s nástrojem Apache Kafka. Jedná se o velmi často používaný (někdy i nadužívaný) nástroj, o jehož základních možnostech se zmíníme příště.

Obrázek 18: Logo nástroje Apache Kafka.
18. Odkazy na Internetu
- Microservices – Not a free lunch!
http://highscalability.com/blog/2014/4/8/microservices-not-a-free-lunch.html - Microservices, Monoliths, and NoOps
http://blog.arungupta.me/microservices-monoliths-noops/ - Microservice Design Patterns
http://blog.arungupta.me/microservice-design-patterns/ - Vision of a microservice revolution
https://www.jolie-lang.org/vision.html - Microservices: a definition of this new architectural term
https://martinfowler.com/articles/microservices.html - Mikroslužby
http://voho.eu/wiki/mikrosluzba/ - Microservice Prerequisites
https://martinfowler.com/bliki/MicroservicePrerequisites.html - Microservices in Practice, Part 1: Reality Check and Service Design (vyžaduje registraci)
https://ieeexplore.ieee.org/document/7819415 - Microservice Trade-Offs
https://www.martinfowler.com/articles/microservice-trade-offs.html - What is a microservice? (from a linguistic point of view)
http://claudioguidi.blogspot.com/2017/03/what-microservice-from-linguisitc.html - Microservices (Wikipedia)
https://en.wikipedia.org/wiki/Microservices - Fallacies of distributed computing (Wikipedia)
https://en.wikipedia.org/wiki/Fallacies_of_distributed_computing - Service (systems architecture)
https://en.wikipedia.org/wiki/Service_(systems_architecture) - Microservices in a Nutshell
https://www.thoughtworks.com/insights/blog/microservices-nutshell - What is Microservices?
https://smartbear.com/solutions/microservices/ - Mastering Chaos – A Netflix Guide to Microservices
https://www.youtube.com/watch?v=CZ3wIuvmHeM&t=17s - Messaging in Microservice Architecture
https://www.youtube.com/watch?v=MkQWQ5f-SEY - Pattern: Messaging
https://microservices.io/patterns/communication-style/messaging.html - Microservices Messaging: Why REST Isn’t Always the Best Choice
https://blog.codeship.com/microservices-messaging-rest-isnt-always-best-choice/ - Protocol buffers
https://developers.google.com/protocol-buffers/ - BSON
http://bsonspec.org/ - Apache Avro!
https://avro.apache.org/ - REST vs Messaging for Microservices – Which One is Best?
https://solace.com/blog/experience-awesomeness-event-driven-microservices/ - How did we end up here?
https://gotocon.com/dl/goto-chicago-2015/slides/MartinThompson_and_ToddMontgomery_HowDidWeEndUpHere.pdf - Scaling microservices with message queues to handle data bursts
https://read.acloud.guru/scaling-microservices-with-message-queue-2d389be5b139 - Microservices: What are smart endpoints and dumb pipes?
https://stackoverflow.com/questions/26616962/microservices-what-are-smart-endpoints-and-dumb-pipes - Common Object Request Broker Architecture
https://en.wikipedia.org/wiki/Common_Object_Request_Broker_Architecture - Enterprise service bus
https://en.wikipedia.org/wiki/Enterprise_service_bus - Microservices vs SOA : What’s the Difference
https://www.edureka.co/blog/microservices-vs-soa/ - Pravda o SOA
https://businessworld.cz/reseni-a-realizace/pravda-o-soa-2980 - Is it a good idea for Microservices to share a common database?
https://www.quora.com/Is-it-a-good-idea-for-Microservices-to-share-a-common-database - Pattern: Shared database
https://microservices.io/patterns/data/shared-database.html - Is a Shared Database in Microservices Actually an Anti-pattern?
https://hackernoon.com/is-shared-database-in-microservices-actually-anti-pattern-8cc2536adfe4 - Shared database in microservices is a problem, yep
https://ayende.com/blog/186914-A/shared-database-in-microservices-is-a-problem-yep - Microservices with shared database? using multiple ORM's?
https://stackoverflow.com/questions/43612866/microservices-with-shared-database-using-multiple-orms - Examples of microservice architecture
https://www.coursera.org/lecture/intro-ibm-microservices/examples-of-microservice-architecture-JXOFj - Microservices: The Rise Of Kafka
https://movio.co/blog/microservices-rise-kafka/ - Building a Microservices Ecosystem with Kafka Streams and KSQL
https://www.confluent.io/blog/building-a-microservices-ecosystem-with-kafka-streams-and-ksql/ - An introduction to Apache Kafka and microservices communication
https://medium.com/@ulymarins/an-introduction-to-apache-kafka-and-microservices-communication-bf0a0966d63 - ACID (computer science)
https://en.wikipedia.org/wiki/ACID_(computer_science) - Distributed transaction
https://en.wikipedia.org/wiki/Distributed_transaction - Two-phase commit protocol
https://en.wikipedia.org/wiki/Two-phase_commit_protocol - Why is 2-phase commit not suitable for a microservices architecture?
https://stackoverflow.com/questions/55249656/why-is-2-phase-commit-not-suitable-for-a-microservices-architecture - 4 reasons why microservices resonate
https://www.oreilly.com/ideas/4-reasons-why-microservices-resonate - Pattern: Microservice Architecture
https://microservices.io/patterns/microservices.html - Pattern: Monolithic Architecture
https://microservices.io/patterns/monolithic.html - Pattern: Saga
https://microservices.io/patterns/data/saga.html - Pattern: Database per service
https://microservices.io/patterns/data/database-per-service.html - Pattern: Access token
https://microservices.io/patterns/security/access-token.html - Databázová integrita
https://cs.wikipedia.org/wiki/Datab%C3%A1zov%C3%A1_integrita - Referenční integrita
https://cs.wikipedia.org/wiki/Referen%C4%8Dn%C3%AD_integrita - Introduction into Microservices
https://specify.io/concepts/microservices - Are Microservices ‘SOA Done Right’?
https://intellyx.com/2015/07/20/are-microservices-soa-done-right/ - The Hardest Part About Microservices: Your Data
https://blog.christianposta.com/microservices/the-hardest-part-about-microservices-data/ - From a monolith to microservices + REST
https://www.slideshare.net/InfoQ/from-a-monolith-to-microservices-rest-the-evolution-of-linkedins-service-architecture - DevOps and the Myth of Efficiency, Part I
https://blog.christianposta.com/devops/devops-and-the-myth-of-efficiency-part-i/ - DevOps and the Myth of Efficiency, Part II
https://blog.christianposta.com/devops/devops-and-the-myth-of-efficiency-part-ii/ - Standing on Distributed Shoulders of Giants: Farsighted Physicists of Yore Were Danged Smart!
https://queue.acm.org/detail.cfm?id=2953944 - Building DistributedLog: High-performance replicated log service
https://blog.twitter.com/engineering/en_us/topics/infrastructure/2015/building-distributedlog-twitter-s-high-performance-replicated-log-servic.html - Turning the database inside-out with Apache Samza
https://www.confluent.io/blog/turning-the-database-inside-out-with-apache-samza/ - Debezium: Stream changes from your databases.
https://debezium.io/ - Change data capture
https://en.wikipedia.org/wiki/Change_data_capture - Apache Samza (Wikipedia)
https://en.wikipedia.org/wiki/Apache_Samza - Storm (event processor)
https://en.wikipedia.org/wiki/Storm_(event_processor) - kappa-architecture.com
http://milinda.pathirage.org/kappa-architecture.com/ - Questioning the Lambda Architecture
https://www.oreilly.com/ideas/questioning-the-lambda-architecture - Lambda architecture
https://en.wikipedia.org/wiki/Lambda_architecture - Event stream processing
https://en.wikipedia.org/wiki/Event_stream_processing - How to beat the CAP theorem
http://nathanmarz.com/blog/how-to-beat-the-cap-theorem.html - Kappa Architecture Our Experience
https://events.static.linuxfound.org/sites/events/files/slides/ASPgems%20-%20Kappa%20Architecture.pdf - Messaging Patterns in Event Driven Microservice Architectures
https://www.youtube.com/watch?v=3×Dc4MEYuHI - Why monolithic apps are often better than microservices
https://gigaom.com/2015/11/06/why-monolithic-apps-are-often-better-than-microservices/ - How Enterprise PaaS Can Add Critical Value to Microservices
https://apprenda.com/blog/enterprise-paas-microservices/ - Common React Mistakes: Monolithic Components and a Lack of Abstraction
https://www.pmg.com/blog/common-react-mistakes-monolithic-components-lack-abstraction/ - From monolith to microservices – to migrate or not to migrate?
https://altkomsoftware.pl/en/blog/monolith-microservices/ - Command–query separation
https://en.wikipedia.org/wiki/Command%E2%80%93query_separation - GOTO 2016: Messaging and Microservices (Clemens Vasters)
https://www.youtube.com/watch?v=rXi5CLjIQ9kx - GOTO Amsterdam 2019
https://gotoams.nl/ - Lesson 2 – Kafka vs. Standard Messaging
https://www.youtube.com/watch?v=lwMjjTT1Q-Q - CommandQuerySeparation (Martin Fowler)
https://martinfowler.com/bliki/CommandQuerySeparation.html - Command–query separation
https://en.wikipedia.org/wiki/Command%E2%80%93query_separation - CQRS – Martin Fowler
https://martinfowler.com/bliki/CQRS.html - Lesson 12 – CQRS and Microservices
https://www.youtube.com/watch?v=pUGvXUBfvEE

























