
Obsah
1. Cesta k superpočítači CDC 6600
2. Poněkud neúspěšný projekt IBM 7030 (STRETCH)
3. Vliv IBM 7030 na další vývoj výpočetní techniky
4. CDC 6600 – nejvýkonnější superpočítač ve své éře
5. Výpočetní výkon superpočítače CDC 6600
6. Centrální procesorová jednotka a procesorové jednotky pro ovládání periferií
7. Procesorové jednotky určené pro přístup k operační paměti
8. Obsah následující části seriálu
1. Cesta k superpočítači CDC 6600
V předchozí části seriálu o historii vývoje výpočetní techniky jsme se seznámili s tím, jakým způsobem vznikla společnost CDC (Control Data Corporation). Tato společnost se zpočátku soustředila především na vývoj periferních zařízení k mainframům vyráběným ostatními výrobci počítačů, ale s příchodem Seymoura Craye do CDC se vše poměrně radikálním způsobem změnilo. Cray nejprve sestrojil relativně malý počítač nazvaný příznačně CDC Little Character, na jehož konstrukci si ověřil některé v té době nové technologie, především použití tranzistorů a modularizovaných plošných spojů jako základních elektronických součástek, z nichž se skládal řadič i aritmeticko-logická jednotka. Tyto technologie se na prototypu CDC Little Character osvědčily, proto byl zahájen nový projekt: přestavba staršího, ale populárního mainframu 1103 s využitím polovodičových tranzistorů. Výsledkem tohoto projektu byl sálový počítač CDC 1604, který se v roce 1959 stal prvním komerčně úspěšným mainframem založeným na tranzistorech (tento počítač jsme si popsali minule).

Obrázek 1: Konstruktéři superpočítačů v minulosti a vlastně i v současnosti nešetřili místem, jak je to ostatně patrné z této dobové fotografie.
Ve chvíli, kdy vedení firmy CDC vyžadovalo po Crayovi napsání podrobného plánu na další rok a současně na další pětiletku :-), Cray pouze lakonicky odpověděl, že do pěti let by chtěl sestrojit nejvýkonnější počítač na světě a jednoletým plánem je dosažení jedné pětiny tohoto cíle (podle většiny dobových pramenů Cray skutečně nesnášel byrokracii). Ovšem pod pojmem „nejvýkonnější počítač“ si Cray představoval stroj 50× (!) výkonnější, než byl už tak velmi rychlý mainframe CDC 1604. Pro dosažení tohoto cíle dokonce na zelené louce (a především v jiném městě, než ve kterém sídlilo vedení firmy) vznikly nové laboratoře, v nichž mohl probíhat vývoj nového počítače v relativním klidu a izolaci od okolních rušivých vlivů (dokonce se traduje, že ani ředitel společnosti CDC neměl do laboratoří bez předchozího schválení přístup). Superpočítač, který v těchto laboratořích v roce 1963 vznikl, se skutečně stal nejvýkonnějším počítačem na světě a toto prvenství si udržel po dlouhých pět let, tj. od roku 1964 (kdy začal být vyráběn) až do roku 1969, kdy byl překonán nikoli konkurenčním výrobkem, ale svým následovníkem CDC 7600.

Obrázek 2: Fotografie superpočítače CDC 6600 s typickým řídicím panelem obsahujícím dvojici obrazovek.
2. Poněkud neúspěšný projekt IBM 7030 (Stretch)
Při našem povídání o první generaci superpočítačů musíme pro úplnost udělat malou odbočku a říci si základní informace i o konkurenčním superpočítači IBM 7030, který se taktéž nazýval STRETCH. Tento počítač vznikl na základě požadavků známého a vlivného Dr. Edwarda Tellera z Kalifornské university (konkrétně z Lawrence Livermore National Laboratory – LLNL), který poptával výkonný počítač vhodný pro provádění složitých výpočtů z oblasti hydrodynamiky. Osloveny byly dvě významné počítačové firmy, IBM a UNIVAC, přičemž bylo vyžadováno, aby nový počítač měl výpočetní výkon 1 až 2 MIPS a jeho cena by neměla přesahovat přibližně 2,5 milionu dolarů. Vzhledem k tomu, že počítač s ještě o něco vyšším výpočetním výkonem byl poptáván i (částečně konkurenční) národní laboratoří Los Alamos (viz známý projekt Manhattan, na němž mimochodem spolupracoval i výše zmíněný Edward Teller), rozhodla se firma IBM navrhnout takový počítač, jehož výpočetní výkon by byl stokrát větší, než výkon v té době známého a používaného mainframu IBM 704 (plánovaný výpočetní výkon nového stroje tedy zhruba odpovídal 4 MIPS).

Obrázek 3: Řídicí panel (konzole) superpočítače IBM 7030 (STRETCH).
Ovšem již v průběhu vývoje superpočítače IBM 7030 se začalo ukazovat, že slibovaného stonásobného nárůstu výpočetního výkonu nebude možné dosáhnout – konstruktéři tohoto stroje začali být omezováni jak použitou technologií polovodičových tranzistorů (musela se snížit hodinová frekvence), tak i možná poněkud nevhodně zvolenou architekturou (v IBM v té době evidentně chyběl člověk typu Seymoura Craye :-). V roce 1961 ukázaly benchmarky spuštěné na prototypu nového stroje, že výkon počítače IBM 7030 bude odpovídat pouze zhruba třicetinásobku výkonu IBM 704, což odpovídá přibližně 1,2 MIPS. Taktéž plánovaná prodejní cena tohoto superpočítače byla poměrně vysoká – 13,5 milionu dolarů. Poté, co se ukázalo, že výpočetní výkon není tak velký, jak se původně předpokládalo a jak IBM svým zákazníkům prezentovala, byla prodejní cena postupně snižována až na 7,78 milionu dolarů. To mj. ve svém důsledku znamenalo, že i když se firmě IBM skutečně podařilo sestrojit nejvýkonnější superpočítač na světě, nejednalo se ve skutečnosti o nijak výnosný projekt.

Obrázek 4: Detailní pohled na část řídicího panelu superpočítače IBM 7030 (STRETCH).
3. Vliv IBM 7030 na další vývoj výpočetní techniky
Projekt IBM 7030 (STRETCH) byl sice kvůli důvodům uvedeným v předchozí kapitole z komerčního hlediska neúspěšný a pro firmu, která by byla menší než IBM, by pravděpodobně mohl znamenat i existenční problémy, ale ve skutečnosti v rámci vývoje tohoto superpočítače vzniklo poměrně velké množství nových technologií, které mohla společnost IBM uplatnit u některých svých dalších produktů, takže se tento projekt nedá hodnotit zcela negativně a izolovaně od dalších produktů. Jednou z nově vyvinutých technologií, kterou bylo možné nalézt v poměrně velkém množství mainframů (včetně některých periferních zařízení pro IBM System/360), jsou i moduly SMS, neboli (IBM) Standard Modular System. Jednalo se o plošné spoje se standardizovanou velikostí 4,5×2,5 palce, které obsahovaly i unifikovaný konektor se šestnácti kontakty. Celý konektor byl vytvořen přímo na plošném spoji, podobně jako je tomu i u karet typu ISA, EISA, VLB, PCI, AGP atd. Tyto plošné spoje byly osazeny v té době běžnými diskrétními součástkami, tj. rezistory, kondenzátory, diodami i křemíkovými tranzistory.

Obrázek 5: Ve skutečnosti byl superpočítač IBM 7030 mnohem větší, než by se při pohledu na jeho řídicí panel mohlo zdát. Celková délka této chodbičky vedoucí mezi moduly IBM 7030 přesahovala 33 stop (cca deset metrů).
Tyto tvarově a částečně i signálově unifikované moduly se připojovaly do společných back-planů, na nichž bylo rozvedené napájecí napětí a všechny další potřebné řídicí i datové signály. S využitím podobného modulárního způsobu byly sestaveny mainframy řady IBM 7070 (tj. počítače určené především pro banky a podobné instituce), IBM 7080 (taktéž se jednalo o počítače specializované pro banky) či IBM 7090 (počítače určené pro náročné výpočty). Další technologií vyvinutou (či spíše vylepšenou) v rámci projektu IBM 7030 (STRETCH) byly paměťové jednotky obsahující nám již známé paměťové buňky sestavené z feritových jader; tyto paměti byly ovšem v případě projektu STRETCH uložené v klimatizované skříni, v níž se udržovala konstantní teplota. Původní paměťové moduly byly dokonce umístěny v oleji, který byl v případě potřeby zahříván či naopak ochlazován, později se používala „pouze“ vzduchová klimatizace. Právě stabilní teplota spolu se zmenšením průměru feritového toroidu každé jednobitové paměťové buňky umožnila inženýrům z firmy IBM postupně snížit dobu přístupu k datům na dvě mikrosekundy u modelu IBM 7094 a později dokonce na pouhé 1,4 mikrosekundy v modelu IBM 7094 II.

Obrázek 6: Jedno ze zařízení vyvinutých v rámci projektu IBM Stretch – paměť IBM 7302. Původně byly tyto paměti chlazeny olejem; v upraveném typu konstrukce pojmenovaném IBM 7302A se posléze používalo chlazení proudícím vzduchem.
4. CDC 6600 – nejvýkonnější superpočítač ve své éře
Vraťme se nyní zpět k firmě CDC, která začala na poli superpočítačů společnosti IBM poměrně významně konkurovat. Seymour Cray při návrhu superpočítače CDC 6600 zpočátku uvažoval o tom, že by pro jeho konstrukci použil stejný typ tranzistorů, jaké byly využity již v předchozím mainframu CDC 1604. Záhy se však ukázalo, že tehdejší germaniové tranzistory z CDC 1604 nebudou dostatečně rychlé pro přepínání binárního signálu na frekvencích dosahujících několika desítek MHz. Z tohoto důvodu se Cray rozhodl namísto toho použít nejnovější dobovou technologii – křemíkové tranzistory, které v té době na trh uvedla společnost Fairchild Semiconductor, o níž jsme se již zmínili v části věnované vývoji polovodičových prvků. Tyto tranzistory byly sice – alespoň zpočátku – dražší, než tranzistory germaniové, ovšem dalo se předpokládat (a historie tento předpoklad potvrdila), že spínací rychlost křemíkových tranzistorů bude poměrně rychle narůstat.

Obrázek 7: Pohled na řídicí panel superpočítače CDC 6600 s typickou dvojicí obrazovek.
Cray se díky tomuto rozhodnutí nedopustil takové chyby jako jeho konkurenti z firmy IBM, kteří pro svůj superpočítač IBM 7030 použili z mnoha důvodů nevyhovující hrotové tranzistory, zatímco křemíkové tranzistory firmy Fairchild Semiconductor byly vyráběny difúzní technologií, při níž se do destičky z čistého křemíku provádí difúze příměsi s vodivostí P nebo N. Díky použití křemíkových tranzistorů mohl Seymour Cray v superpočítači CDC 6600 použít hodinové signály o frekvenci 10 MHz, přičemž se díky existenci dvou fázově posunutých hodinových signálů, u nichž se pro synchronizaci využívala jak vzestupná, tak i sestupná hrana, jednotlivé prvky v systému přepínaly rychlostí až 40 MHz, což byla v polovině šedesátých let minulého století velmi vysoká pracovní frekvence, které ostatní počítače nedosahovaly (ostatně i o mnoho let později vzniklým mikroprocesorům trvalo celou jednu dekádu, než se jejich hodinová frekvence zvýšila na 40 MHz, a to vůbec neuvažujeme o tom, že mnoho mikroprocesorů pracujících na této frekvenci vůbec neobsahovalo matematický koprocesor).

Obrázek 8: Fragment manuálu k superpočítači CDC 6600.
5. Výpočetní výkon superpočítače CDC 6600
Superpočítač CDC 6600 byl, podobně jako i velká část dalších superpočítačů, které byly zkonstruovány v následujících letech, optimalizovaný na provádění operací s čísly reprezentovanými v systému plovoucí řádové čárky (floating point). Jednotlivé číselné hodnoty byly v případě CDC 6600 ukládány v registrech o šířce 60 bitů, což zhruba odpovídá v současnosti používanému datovému typu double (odvozenému od 64bitového formátu čísel s dvojitou přesností popsaného v normě IEEE 754). Vzhledem k tomu, že šířka slov ukládaných do operační paměti byla rovna dvanácti bitům, byla každá číselná hodnota uložena v pěti paměťových slovech. Operace násobení mohla být provedena v pouhých deseti strojových cyklech, dělení trvalo 29 strojových cyklů. Teoretický výpočetní výkon pro ručně optimalizované programy mohl dosáhnout až 3 MFLOPS, ovšem při použití překladačů FORTRANu (generujících optimalizovaný kód) se dosahovalo průměrného výkonu 1/2 MFLOPS, což však stále nebyla špatná hodnota.
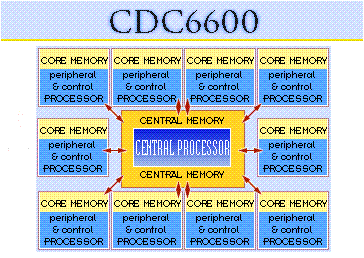
Obrázek 9: Modulová struktura superpočítače CDC 6600.
Pro malé porovnání: matematický koprocesor Intel 8087 dosahoval výpočetního výkonu přibližně 0,03 až 0,05 MFLOPS a jeho následovník Intel 80287 (1983) měl průměrný výpočetní výkon pouze nepatrně vyšší: 0,065 MFLOPS. V této chvíli vás možná napadne, proč se výpočetní výkon superpočítače IBM 7030 udával v jednotkách MIPS (tj. počtem operací s celými čísly provedenými za sekundu) a nikoli v jednotkách MFLOPS (počet operací s čísly reprezentovanými v systému plovoucí řádové čárky). Důvod je prozaický – měření výkonnosti (nejenom) superpočítačů vyjádřením počtu operací s FP hodnotami byl zaveden právě v souvislosti se vznikem superpočítače CDC 6600. Tuto jednotku, přesněji řečeno základní jednotku FLOPS, zavedl Frank H. McMahon z výše zmíněné Lawrence Livermore National Laboratory (LLNL), aby bylo možné porovnávat výkonnost (super)počítačů v oblasti, která souvisela s vysoce náročnými výpočty. Později byly naprogramovány standardizované benchmarky, zejména LINPACK benchmark založený, jak již jeho název napovídá, na Fortranovské knihovně LINPACK.

Obrázek 10: Pohled na spodní část plošného spoje jednoho z modulů počítače CDC 6600.
6. Centrální procesorová jednotka
Převážná většina mainframů a superpočítačů, které vznikaly v šedesátých letech minulého století i počátkem let sedmdesátých, byla založena na procesorové jednotce obsahující řadič, který zpracovával mnohdy i velmi složitou instrukční sadu s instrukcemi proměnné délky, mnoha adresními režimy, několika typy dat atd. Jak jsme si již řekli v paralelně běžícím seriálu o architekturách počítačů, byly procesory s komplexními instrukčními sadami zpočátku konstruovány z toho důvodu, aby se zmenšila takzvaná sémantická mezera mezi assemblerem (jazykem symbolických adres či též jazykem symbolických instrukcí) a vyššími programovacími jazyky, protože se věřilo, že je možné a především vhodné zkonstruovat procesor zpracovávající instrukce, které by se svým charakterem blížily prvkům použitým ve vyšších programovacích jazycích (určitou odezvu této dávné snahy můžeme najít i v instrukční sadě i386).

Obrázek 11: Paměť s feritovými jádry použitá v superpočítači CDC 6600.
Ovšem Seymour Cray se touto zdánlivě správnou cestou nevydal a namísto toho použil zcela odlišnou architekturu – místo jediného drahého procesoru zkonstruoval mnohem jednodušší procesor, který dokázal provádět aritmetické a logické operace, a to pouze s hodnotami uloženými v pracovních registrech, nikoli s hodnotami, které by bylo nutné načítat z operační paměti. Díky tomu, že tento procesor vůbec neobsahoval obvody pro přístup k operační paměti ani pro adresaci operandů, byla jeho interní struktura mnohem jednodušší a taktéž bylo možné použít takové obvodové zapojení, které dovolovalo využití vyšších hodinových frekvencí, než by tomu bylo v případě použití komplexního procesoru. Navíc se aritmetické a logické instrukce prováděly v menším počtu strojových cyklů, než tomu bylo na dalších v té době existujících počítačích, takže zdánlivě primitivnější procesor ve skutečnosti dosahoval vyššího výpočetního výkonu.

Obrázek 12: Další pohled na paměťový modul použitý v superpočítači CDC 6600.
7. Procesorové jednotky určené pro přístup k operační paměti
Použití jednoduchého typu procesoru, tj. architektury, která se později začala označovat zkratkou RISC, však nebylo jedinou novinkou, s níž Seymour Cray v případě superpočítače CDC 6600 přišel. Pro načítání a ukládání dat do operační paměti se totiž namísto CPU používal odlišný typ procesorů nazvaný peripheral processor (PP). Tyto procesory, které byly z obvodového hlediska taktéž poměrně jednoduché a tím pádem i rychlé, se staraly o komunikaci s operační pamětí a taktéž pro řízení samotného CPU, kterému posílaly operandy a instrukce, které se měly provést. Celá operační paměť byla rozdělena na deset regionů, ke kterým bylo možné přistupovat paralelně, což znamená, že v jednom okamžiku mohlo být načítáno či ukládáno až deset slov (každá z těchto operací byla prováděna jedním PP). Každému z těchto procesorů přitom byla přidělena operační paměť s organizací 4096×12 bitů a instrukce, kterými byly tyto procesory řízeny, umožňovaly přímou, nepřímou i relativní adresaci operandů (direct, indirect a relative addressing).

Obrázek 13: Unifikovaný modul počítače CDC 6600 – pohled na vrchní část modulu.
Vzhledem k tomu, že centrální procesorová jednotka superpočítače CDC 6600 byla díky své konstrukční jednoduchosti až desetkrát rychlejší, než kolik činila průměrná doba přístupu k datům uloženým v operační paměti (což bylo poměrně netypické), byl CPU, přesněji řečeno jeho aritmeticko-logická jednotka, neustále vytížena prováděním výpočtů, protože deset PP dokázalo CPU dokonale vytížit. Aby Seymour Cray ještě více zjednodušil celkový počet tranzistorů nutných pro konstrukci tohoto počítače, bylo všech deset PP uspořádáno do formy takzvaného bubnového procesoru (barrell processor), v němž byly některé informace, například obsah programového čítače či buffer načtených instrukcí, sdíleno mezi všemi deseti PP. Celý „buben“ rotoval, takže v jedné jeho otočce se načetla instrukce do všech PP, které si ve vlastních bufferech udržovaly výsledky předchozích operací. Další vlastností použitou Crayem na CDC 6600, která byla později použita i u procesorů s architekturou RISC je to, že některé časově složité operace byly ponechány na překladači, který musel sám kód přeorganizovat a optimalizovat takovým způsobem, aby jak CPU, tak i všech deset PP dokázaly spolupracovat bez zbytečných prodlev.

Obrázek 14: Unifikovaný modul počítače CDC 6600 – pohled na boční část modulu.
8. Obsah následující části seriálu
V následující části seriálu o historii vývoje výpočetní techniky dokončíme popis architektury superpočítače CDC 6600. Kromě podrobnějšího popisu konstrukce periferních procesorů si ukážeme především jeho instrukční sadu rozdělenou na instrukce určené pro CPU (a aritmeticko-logickou jednotku) a na odlišné instrukce zpracovávané periferními procesory.

Obrázek 15: Unifikovaný modul počítače CDC 6600 – pohled na spodní část modulu s plošným spojem.

Taktéž se zmíníme o jeho sice poměrně primitivním, ale stále v mnoha případech užitečném grafickém subsystému – ostatně řídicí panel s dvojicí kruhových obrazovek se stal poznávacím znakem tohoto stroje (ve skutečnosti však bylo nutné grafy a podobné grafické údaje, u nichž byla důležitá přesnost, tisknout s využitím velkoformátových plotterů, protože obrazovky byly určeny převážně pro zobrazení textů). Dále si v následující části tohoto seriálu popíšeme následovatele CDC 6600. Jedná se o superpočítač CDC 7600, který již obsahoval některé technologie použité o několik let později Seymourem Crayem již v jeho nově založené společnosti Cray Research.

Obrázek 16: Unifikovaný modul počítače CDC 6600 – další pohled na spodní část modulu s plošným spojem.
9. Odkazy na Internetu
- IBM 7302 Oil Core Memory
http://www.piercefuller.com/library/img00085.html?id=img00085 - IBM 7302 Air Core Memory
http://www.piercefuller.com/library/img00090.html?id=img00090 - Control Data Corporation (CDC) 6600: 1966–1977
http://www.cisl.ucar.edu/computers/gallery/cdc/6600.jsp - Control Data Corporation (CDC) 7600: 1971–1983
http://www.cisl.ucar.edu/computers/gallery/cdc/7600.jsp - John Mauchly
http://en.wikipedia.org/wiki/John_Mauchly - J. Presper Eckert
http://en.wikipedia.org/wiki/J._Presper_Eckert - BINAC
http://en.wikipedia.org/wiki/BINAC - Description of the BINAC
http://www.palosverdes.com/lasthurrah/binac-description.html - UNIVersal Automatic Computer (UNIVAC)
http://www.thocp.net/hardware/univac.htm - Control Data Corporation (CDC) 6600: 1966–1977
http://www.cisl.ucar.edu/computers/gallery/cdc/6600.jsp - Control Data Corporation (CDC) 7600: 1971–1983
http://www.cisl.ucar.edu/computers/gallery/cdc/7600.jsp - BUNCH
http://en.wikipedia.org/wiki/BUNCH - Mainframe computer
http://en.wikipedia.org/wiki/Mainframe_computer - Cray History
http://www.cray.com/About/History.aspx?404;http://www.cray.com:80/about_cray/history.html - Cray Historical Timeline
http://www.cray.com/Assets/PDF/about/CrayTimeline.pdf - Company: Cray Research, Inc. (Computer History)
http://www.computerhistory.org/brochures/companies.php?alpha=a-c&company=com-42b9d5d68b216 - General Electric GE-400
http://www.feb-patrimoine.com/PROJET/ge400/ge-400.htm - GE-400 Time-sharing information systems:
http://www.computerhistory.org/collections/accession/102646147 - GE 225 vs. IBM 1401
http://ed-thelen.org/GE225-IBM1401.html - A GE-225 is found
http://ed-thelen.org/comp-hist/GE225.html - G.E. 200 Series Computers
http://www.smecc.org/g_e__200_series_computers.htm - GE-200 series (Wikipedia)
http://en.wikipedia.org/wiki/GE-200_series - GE-400 series (Wikipedia)
http://en.wikipedia.org/wiki/GE-400_series - GE-600 series (Wikipedia)
http://en.wikipedia.org/wiki/GE-600_series - Mainframe – Introduction
http://www.thocp.net/hardware/mainframe.htm - Honeywell 800 (1958)
http://www.cs.clemson.edu/~mark/h800.html - Real Machines with 24-bit and 48-bit words
http://www.quadibloc.com/comp/cp0303.htm - Honeywell ARGUS
http://en.wikipedia.org/wiki/Honeywell_ARGUS - Honeywell Datamatic 1000
http://www.smecc.org/honeywell_datamatic_1000.htm - Honeywell
http://en.wikipedia.org/wiki/Honeywell - Whatever Happened to IBM and the Seven Dwarfs? Dwarf Four: Honeywell
http://www.dvorak.org/blog/ibm-and-the-seven-dwarfs-dwarf-four-honeywell/ - Datamatic 1000 by DATAmatic Corporation (1955)
http://www.computermuseum.li/Testpage/Datamatic-1000.html - Burroughs – Third Generation Computers
https://wiki.cc.gatech.edu/folklore/index.php/Burroughs_Third-Generation_Computers - Burroughs B5000, B5500 and B5700 (original) documentation
http://www.bitsavers.org/pdf/burroughs/B5000_5500_5700/ - Burroughs B6500 and B6700 (original) documentation
http://www.bitsavers.org/pdf/burroughs/B6500_6700/ - Burroughs B8500 (original) documentation
http://www.bitsavers.org/pdf/burroughs/B8500/ - ERA 1101 Documents
http://ed-thelen.org/comp-hist/ERA-1101-documents.html - Ukázkový program pro UNIVAC 1101/ERA 1101
https://wiki.cc.gatech.edu/folklore/index.php/Engineering_Research_Associates_and_the_Atlas_Computer_(UNIVAC_1101) - UNIVAC I Computer System
http://univac1.0catch.com/ - UNIVAC I Computer System
http://univac1.0catch.com/yellowpage.htm - UNIVAC (Wikipedia)
http://en.wikipedia.org/wiki/Univac - UNIVAC I (Wikipedia)
http://en.wikipedia.org/wiki/UNIVAC_I - UNIVAC II – Universal Automatic Computer Model II
http://ed-thelen.org/comp-hist/BRL61-u4.html - UNIVAC II (Wikipedia)
http://en.wikipedia.org/wiki/UNIVAC_II - UNIVAC III (Wikipedia)
http://en.wikipedia.org/wiki/UNIVAC_III - UNIVAC 1101 (Wikipedia)
http://en.wikipedia.org/wiki/UNIVAC_1101 - UNISYS History Newsletter
https://wiki.cc.gatech.edu/folklore/index.php/Main_Page - UNIVAC Solid State (Wikipedia)
http://en.wikipedia.org/wiki/UNIVAC_Solid_State - Bi-quinary coded decimal (Wikipedia)
http://en.wikipedia.org/wiki/Bi-quinary_coded_decimal - UNIVAC III Data Processing System
http://ed-thelen.org/comp-hist/BRL61-u4.html#UNIVAC-III - The UNIVAC III Computer
https://wiki.cc.gatech.edu/folklore/index.php/The_UNIVAC_III_Computer - UNIVAC III Photos
http://jwstephens.com/univac3/page01.htm - A History of Unisys Computers (kniha)
http://www.lulu.com/product/hardcover/a-history-of-unisys-computers/4627477 - UNIVAC III Instructions Reference Card
http://www.bitsavers.org/pdf/univac/univac3/UT-2455_UNIVACIII_RefCd61.pdf

