
V našem seriálu nehodláme nijak podrobně rozebírat problematiku databází obecně ani konkrétně vytvářet nějaký nový návod pro využití PG. Na druhou stranu je ale logické, že spojení databáze (resp. jejího obsahu = dat) s nějakou aplikací je naprosto logické a velmi časté. Proto je také jasné, že se tímto úkolem naše série zabývat musí a bude.
Obecně se dá konstatovat, že aplikace do databází data ukládají, čtou je z nich a zobrazují, aktualizují je a mění a také je z databáze odstraňují. Veškerá tato činnost je zahrnuta pod anglickou zkratku CRUD (Create – Read – Update – Delete), která vše velmi jednoduše vystihuje. My si postupně ukážeme všechny čtyři tyto činnosti v různých formách a podobách.
Druhů a typů databází je dnes k dispozici velmi slušné množství a je tedy třeba před výběrem pro konkrétní aplikaci provést analýzu potřeb a najít odpovídající řešení. Pro zjednodušení uvedeme základní rozdělení databází na dvě velké skupiny:
- relační (RDBMS, SQL)
- dokumentově orientované (NoSQL)
První skupina představuje většinou věkem a praxí ověřené databáze pro ukládání tzv. strukturovaných dat (k tomuto pojmu se vrátíme v dalším textu tohoto dílu). Mezi jejich zástupce patří opravdu mocné nástroje jako je Oracle IBM DB2, Informix nebo další zástupci, např. MySQL, MSSql, PostgreSQL. Do této skupiny můžeme zařadit i velmi jednoduše použitelné databáze, které ke svému běhu nepotřebují žádný „server“. K nim můžeme zařadit třeba Sqlite a podobné nástroje, kterým stačí pouze jeden nebo více souborů, kde jsou data uložená.
Druhou skupinu tvoří poměrně novější a v dnešní době bouřlivě se rozvíjející nástroje, ve kterých je docela těžké se orientovat. Obecně se dá říct, že jsou určené pro různé typy dat hlavně tam, kde data nemají „žádnou“ nebo „volnější“ strukturu. Mezi nimi můžeme najít nástroje, které jsou konkrétněji zaměřené na ukládání specifických typů dat. Zde je několik příkladů rozdělených podle datového modelu:
- sloupcové – Accumulo, Cassandra
- dokumentové – MongoDB, Apache CouchDB
- klíč-hodnota – Oracle NoSQL, Redis
- grafické – Allegro, Neo4J
- multimodelové – OrientDB, FoundationDB
Příkladů by se mohlo uvádět ještě mnohem víc, ale není to nutné. Navíc se tyto nástroje poměrně složitě někam zařazují, protože se jejich zaměření a datové modely mohou překrývat. My se jimi už dále nebudeme zabývat a zaměříme se na první skupinu relačních databází. Z nich se pro účely našeho seriálu vybral jeden zástupce – PG. Jedná se o stále vyvíjenou databázi, která má smíšený vývoj v tom smyslu, že ji vyvíjí jak komunita, tak komerční firma a oba směry vývoje se vzájemně doplňují a prolínají. Proti třeba velmi známé databázi MySQL má určitě výhodu v jednotném a jediném vývojovém směru (viz forky MySQL – MariaDB a Percona + vlastní MySQL). Jenom krátce uvedeme několik výhod PG:
- je k dispozici volná i placená verze pro každý model využití
- vývoj je trvalý, ale předvídatelný
- existují nástroje pro administraci jak volné, tak komerční
- PG má velmi dobrou kompatibilitu s Oracle DB a často se využívá jako její náhrada
- v poslední verzi byl přidán systém pro NoSQL data
- instalace, zprovoznění i administrace nejsou nijak složité
- jsou k dispozici ovladače pro všechny možné programovací jazyky včetně Javy
- je možné najít slušné množství doplňků a utilit pro rozšíření možností
To by obecně o databázích a konkrétně o PG mohlo stačit a my se můžeme pustit do dalšího kroku. Je asi jasné, že když chceme s nějakými daty manipulovat, tak je v první řadě musíme mít k dispozici a co víc – musíme je mít v příslušné databázi. Pro náš první ukázkový příklad využije dostupný seznam obcí a měst, který vydává a aktualizuje Ministerstvo vnitra. My si tento seznam na jedné straně zúžíme (je v něm něco přes 6 000 záznamů, my použijeme data pouze z Prahy, JČ. SČ a JM kraje, celkem asi 1 500 záznamů). Naopak si z určitých důvodů rozšíříme zobrazované údaje. Konkrétně budou mít data následující strukturu:
- unikátní identifikační označení obce
- číslo kraje (vyšší územně-správní celek)
- název kraje
- číslo okresu (obce s rozšířenou působností)
- název okresu
- název obce
Na základě tohoto schématu je možné pomocí SQL vytvořit samotnou tabulku, ve které budou data uložená (nebudeme zde rozebírat SQL, proto budeme uvádět jenom konkrétní příkazy):
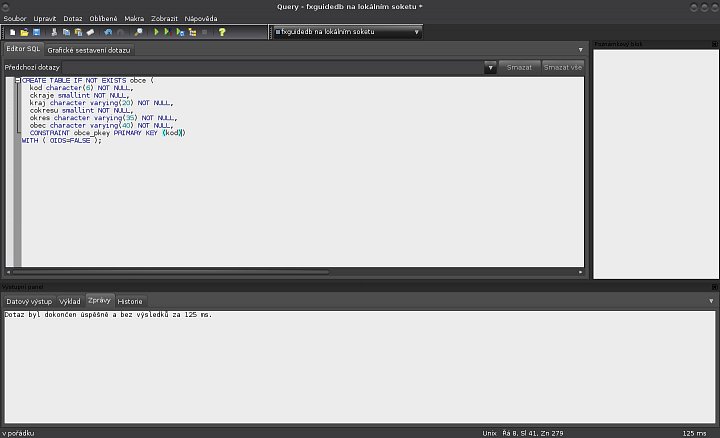
CREATE TABLE IF NOT EXISTS obce ( kod character(6) NOT NULL, ckraje smallint NOT NULL, kraj character varying(20) NOT NULL, cokresu smallint NOT NULL, okres character varying(35) NOT NULL, obec character varying(40) NOT NULL, CONSTRAINT obce_pkey PRIMARY KEY (kod)) WITH ( OIDS=FALSE );
Pro vytvoření tabulky můžeme použít uvedený SQL příkaz, který se vloží do příslušného SQL Editoru v aplikaci pgAdmin. Pak už stačí jen spustit a výsledek je vidět na prvním obrázku první galerie. Je také samozřejmě možné použít menu Upravit → Nový objekt → Nová tabulka a využít grafické nástroje v pgAdmin. Blíže je to zřejmé z dalších šesti obrázků v první galerii. Osmý obrázek první galerie pak ukazuje, jak se změnila struktura databáze, ve které se po provedení příkazu objevila nová tabulka. Ve spodní části je zobrazen SQL příkaz, který je možné kopírovat a opakovaně využívat dle potřeby. Tabulka je tedy vytvořená a nám nezbývá, než ji naplnit daty. Do přílohy je dávat nebudeme a na jejich vložení použijeme klasický SQL příkaz:
INSERT INTO obce VALUES
('554782', 1, 'Hlavní město Praha', 1, 'Praha (1 až 22)', 'Praha'),
(...),
...
(...);
Poslední obrázek první galerie pak ukazuje, jak vypadá část příkazu pro vložení dat a jeho výsledek. Pokud by měl někdo zájem, může použít pravé tlačítko myši na názvu tabulky (obce) a vybrat položku Prohlížet data → Zobrazit všechny řádky, popř. Zobrazit prvních 100 řádků. Tímto příkazem se otevře nové okno s tabulkovým přehledem dat. Ten zde nebudeme nijak rozebírat a pokročíme k dalšímu kroku. Máme tedy vytvořenou tabulku, která je naplněna vzorkem dat. V první zkušební úloze nás čekají ještě další dva úkoly – z aplikace JavaFX se připojit a přihlásit do databáze a zobrazit data, která jsou uložena ve vybrané tabulce.
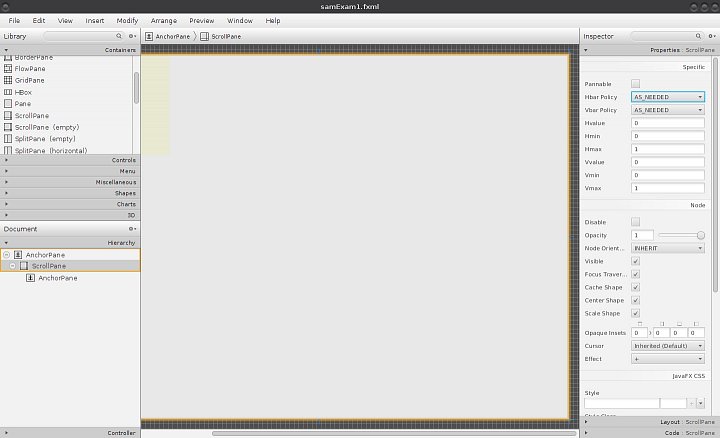
Práci zahájíme opět v JFXSB, kde si upravíme náš jednoduchý formulář tak, aby bylo možné v něm zadaná data zobrazit. Nebudeme se zde zabývat dalšími akcemi, a proto bude na celém formuláři pouze plocha s daty (žádná tlačítka ani další widgety nebudeme vkládat a využívat). Když si prohlédneme seznam dostupných widgetů, tak zjistíme, že ve skupině Controls jsou dva, které by nás mohly zajímat – TableColumn a TableView. Než je ale využijeme, je nutné se zamyslet nad jednou skutečností: v tabulce máme k dispozici cca 1 500 řádků a je jasné, že se nám do formuláře všechny nevejdou. Řešení je dvojí – nějakým způsobem implementovat stránkování (pro naše začátky zbytečně složité) a nebo se poohlédnout po jednodušší možnosti. Tou je widget ScrollPane ze skupiny Containers. Ten tedy do našeho formuláře vložíme jako první – výsledek po zvětšení na celou plochu ukazuje první obrázek druhé galerie. Zde si také můžeme všimnout dvou zajímavých vlastností tohoto widgetu – Hbar Policy a Vbar Policy. Jak je z obrázku patrné, u obou je nastavena volba AS_NEEDED (dle potřeby). K dispozici jsou ještě další dvě možnosti – NEVER (nikdy) a ALWAYS (vždy). Pomocí těchto voleb si můžeme nastavit, kdy se nám mají zobrazit horizontální a vertikální skrolovací lišty.
My ponecháme přednastavenou hodnotu a do widgetu přidáme TableView a opět ho maximálně zvětšíme. V záložce Code nastavíme název tabulky na hodnotu table_Obce. Výsledek nám ukazuje druhý obrázek ve druhé galerii. Z něj je patrné, že okamžitě po vložení widgetu tabulky máme k dispozici dva sloupce. My jich ale budeme potřebovat šest, takže použijeme naši známou funkci Duplicate na druhém sloupci a výsledek vidíme na třetím obrázku druhé galerie. Na prvním sloupci ukážeme podrobněji, co je třeba dál nastavit:
- na záložce Properties změníme hodnotu položky text na požadovaný nadpis sloupce
- na záložce Layout nastavíme položku Min Width na USE_PREF_SIZE a Pref Width na nějakou číselnou hodnotu (šířka sloupce)
- na záložce Code nastavíme název fx:id na hodnotu col_ID
Obdobným způsobem nastavíme hodnoty u všech ostatních sloupců (je třeba brát v úvahu předpokládaný rozsah šířky jednotlivých sloupců i celé tabulky). Konečný výsledek je vidět na čtvrtém obrázku ve druhé galerii. Na pátém obrázku druhé galerie je pak vidět kostra kontroléru, která byla vygenerována po našem kompletním zadání s volbou Full. Kód zkopírujeme a vložíme do příslušné třídy naší aplikace. Jak ukazuje šestý obrázek ve druhé galerii, IJI nehlásí žádnou chybu. Můžeme tedy zkusit překlad, spuštění aplikace a otevření nového formuláře. Výsledek je vidět na sedmém obrázku druhé galerie.
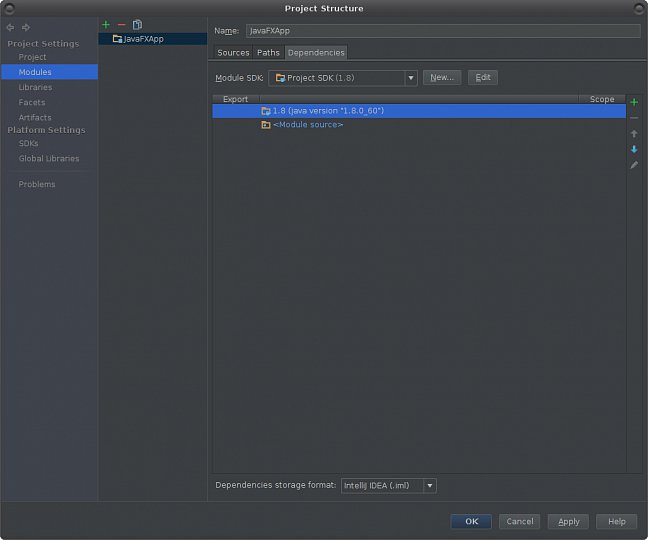
Tímto úkonem již máme připraveno vše ve formuláři a můžeme přistoupit k dalšímu kroku. Ten bude spočívat v tom, že se musíme připojit k databázi a přihlásit se jako oprávněný uživatel dané tabulky. My si k tomu ještě připojíme funkci, která nám ověří, že se připojení a přihlášení zdařilo. Abychom se vůbec mohli pokusit o nějaké připojení k databázi, budeme k tomu potřebovat nějaký nástroj. Podobným nástrojům se obecně říká konektory a pro PG jsou k dispozici k většině běžných programovacích jazyků včetně Javy. Pro implementaci konektoru musíme udělat dvě věci. Jako první si připravíme prostředí IJI. Ve struktuře projektu klikneme pravou myší a vybereme položku New → Directory. Do formuláře zadáme název nového adresáře, jak je to vidět na osmém obrázku ve druhé galerii. Změnu uložíme a adresář se nám objeví v přehledu. Dále použijeme ikonu Project Structure a nový adresář libs zařadíme mezi zdrojové dříve popsaným způsobem. Konečnou úpravu ukazuje poslední obrázek druhé galerie.
Nyní můžeme přejít na příslušnou webovou stránku PG Connector a stáhnout potřebný (prioritně nejnovější, pouze ve výjimečných případech starší) soubor s konektorem. Konkrétní konektor patří do „rodiny“ podobných nástrojů pro jazyk Java, které se obecně nazývají JDBC. Nebudeme zde dále rozebírat a odkážeme pouze na další podrobnosti zde: JDBC. V našem případě se konkrétně jedná o javovskou knihovnu postgresql-9.4–1201.jdbc41.jar, kterou uložíme do adresáře libs. To samo o sobě ještě nestačí a tak musíme spustit menu Project Structure a přejít do oddílu Modules a záložky Dependencies. První obrázek třetí galerie nám ukazuje, jak zde vypadá situace. My musíme použít zelené znaménko + , kde se nabízejí tři možnosti. My si vybereme tu první – JARs or directories…. Otevře se nový formulář s adresářovou strukturou našeho projektu. My si vybereme adresář libs (viz druhý obrázek ve třetí galerii) a pak klikneme na OK. Konečný výsledek je vidět na třetím obrázku třetí galerie. Okno Project Structure opět zavřeme tlačítkem OK. Tím máme konektor připravený k akci a můžeme se pokusit ho aktivovat v aplikaci. V JavaFX je k dispozici pro tyto účely příslušná funkce. Na čtvrtém obrázku ve třetí galerii je vidět, jaké možnosti jsou po zadání části kódu k dispozici. My volíme typ (java.sql), který automaticky importuje knihovnu java.sql.Connection. Je zřejmé, že pro přihlášení do databáze a tabulky budeme potřebovat nějaké přihlašovací údaje, takže si je rovnou zadáme do funkce jako parametry. Základ funkce pak bude vypadat následovně:
private Connection connDB (final String jmeno, final String heslo) {
}
Dále si zadáme privátní pomocné proměnné:
private Connection CONN = null; private String host = "jdbc:postgresql://127.0.0.1:5432/"+dbname;
V první proměnné definujeme společný typ, stejný jako u deklarace předchozí funkce. Ve druhé se pak definuje „cesta“ k databázi. První část se odkazuje na typ JDBC konektoru a definuje tak použitou databázi. Druhá část deklaruje lokalizaci databázového serveru (ten náš běží na lokálním stroji a na defaultním portu) a třetí část pak definuje název databáze, ke které se chceme přihlašovat. Tyto údaje budou pro celou aplikaci stejné (v našem případě), a tak si můžeme dovolit globální deklaraci. Pak se musíme nějak odkázat na konkrétní konektor, což se provádí příkazem:
Class.forName("org.postgresql.Driver");
Pokud ho ale do kódu přidáme, okamžitě vidíme, že IJI hlásí problém. Na pátém obrázku třetí galerie pak vidíme, že nám nabízí dvě varianty řešení. My si zvolíme řešení Surround with try/catch a výsledkem je poměrně složitý příkaz, který nám IJI vygenerovalo, viz šestý obrázek ve třetí galerii. K čemu to tedy vlastně došlo? Náš jednoduchý příkaz byl „obalen“ kódem pro zachycení výjimek, konkrétně pak šlo o možnou chybu při nenalezení odpovídající knihovny konektoru. Zatím nemáme důvod kód měnit ani doplňovat, takže přikročíme k dalšímu příkazu, který provede připojení a přihlášení k databázi:
CONN = DriverManager.getConnection (host, jmeno, heslo);
Znovu se opakuje upozornění na problém s výjimkou a my opět necháme vygenerovat příslušný kód. Mohlo by se zdát, že už je vše v pořádku, ale není. Ono není už od samého začátku naší snahy! IJI nás totiž upozorňuje, že jsme sice deklarovali funkci, ale nemáme vytvořenou žádnou návratovou hodnotu. Abychom se chybového hlášení zbavili, musíme jí zadat dokonce na dvě místa. Konečný výsledek vypadá tak, jak to ukazuje sedmý obrázek třetí galerie. Příkaz pro připojení k databázi máme hotový a můžeme zkusit vytvořit funkci pro ověření úspěšného přihlášení k databázi. Abychom se nemuseli v tuto chvíli zabývat nějakými tabulkami a daty, tak využijeme jeden drobný fígl. Ten nám umožní zjistit, jestli je databáze přístupná bez ohledu na to, jestli a jaká data jsou v ní uložená. Celá funkce je vidět na osmém obrázku ve třetí galerii. Náš fígl spočívá s tom, že zadáme do databáze obecný „dotaz“ SELECT 1;. Ten vypadá trochu nesmyslně (vždy vrátí hodnotu 1), ale funguje pouze tehdy, když je databáze přístupná!
Obě funkce již máme vytvořené a tak nezbývá, než je v aplikaci zavolat a použít. Problém je ale v tom, že nemáme k dispozici žádné tlačítko či podobný widget, který bychom mohli využít. To ale nevadí, protože si v tomto momentě ukážeme, jak zachytit a provést nějakou akci přímo při otevírání formuláře. Vrátíme se v kódu kousek nahoru a najdeme funkci, která se jmenuje @FXML void initialize() a vymažeme z ní všechny dosavadní příkazy. Místo nich vložíme jeden jediný a jednoduchý:
System.out.print(logOK());
Tento příkaz nám zajistí, že se při otevření formuláře aplikace přihlásí do databáze, vykoná příslušný SQL dotaz a vypíše jeho výsledek do konzole. Pak už nezbývá, než aplikaci přeložit, spustit a otevřít okno první úlohy. Při jeho otevření se v konzoli objeví text true, což je dobré znamení – podařilo se k databázi připojit. Po ukončení aplikace nám poslední obrázek třetí galerie ukazuje, že to tak opravdu je. Máme k dispozici funkci pro přihlášení do databáze a můžeme tím pádem přikročit k zobrazení dat z příslušné tabulky. V první úloze k tomu budeme využívat přímo SQL příkazů. Ještě než se do toho ale pustíme, tak upozorníme čtenáře a hlavně experimentátory na to, že dosavadní kompletní kód je v pěti přílohách: mainApp.java, mainForm.java, rootForm.fxml, samExam1.fxml a samexam1.java. V porovnání s Javou je v JavaFX situace docela odlišná a funkce či konkrétní příkazy pro zobrazení dat z tabulky nelze vzájemně zaměnit. Při snaze o řešení tohoto problému v JavaFX narazíme minimálně na čtyři problémy:
- jaký typ dat je vhodný pro funkci TableView.setItems
- jak zajistit zobrazení sloupců tabulky/dotazu ve widgetu TableView
- jak zobrazit různé typy dat
- jak nastavit vzhled tabulky při zobrazení
Řešení prvního problému se zdá jednoduché, ale úplně to tak není. Odkazy se sice dají najít, ale začátečník se asi bez metody pokus-omyl neobejde… Proto zde nebudeme situaci zbytečně komplikovat a uvedeme rovnou, že se bude používat datový typ
ObservableList<ObservableList> data = FXCollections.observableArrayList();
Druhý problém je také poměrně komplikovaný a příkaz pro jeho provedení je velmi nepřehledný. Vrátíme se k němu až v průběhu tvorby kódu. Třetí problém není nijak komplikovaný, ale při více sloupcích v tabulce může vést k většímu množství kódu. Poslední problém je možné rozdělit na dvě části – zarovnání dat ve sloupcích a vizuální parametry (barvy, fonty atd.). Postupně ale všechny problémy nějak vyřešíme a ukážeme i trochu sofistikovanější postupy, které celou problematiku mohou výrazně zjednodušit. Jako první samozřejmě začneme řešit funkci, která by načetla data z tabulky a uložila je do příslušného datového typu JavaFX. JDBC konektor má k dispozici funkce pro vykonání SQL příkazů a vytvoření sady výsledků. Ty nyní využijeme a vytvoříme odpovídající funkci:
private ObservableList<ObservableList> dataView (final String query) { //1
ObservableList<ObservableList> data = FXCollections.observableArrayList(); //2
PreparedStatement pStat = null; //3
CONN = connDB("fxguide", "fxguide"); //4
try { pStat = CONN.prepareStatement(query); //5
ResultSet rs = pStat.executeQuery(); //6
while (rs.next()) { //7
ObservableList<Object> row = FXCollections.observableArrayList(); //8
row.add(rs.getString(1)); //9
row.add(rs.getInt(2)); //10
row.add(rs.getString(3)); //11
row.add(rs.getInt(2)); //12
row.add(rs.getString(5)); //13
row.add(rs.getString(6)); //14
data.add(row); } //15
} catch (SQLException ex) { ex.getMessage(); } //16
finally { if (pStat!=null) { //17
try { pStat.close(); //18
} catch (SQLException ex) { ex.getMessage(); } //19
try { CONN.close(); //20
} catch (SQLException ex) { ex.getMessage(); } } } //21
return data; } //22
Kódu je docela dost, takže si k němu řekneme něco podrobněji:

- 1. – deklaruje funkce příslušného typu, kde parametrem je obecný SQL dotaz
- 2. – deklaruje lokální proměnnou pro uložení dat z tabulky
- 3. – deklaruje lokální proměnnou pro SQL příkaz. Je použit tento typ místo jednoduššího (Statement) – doporučuje se využívat přednostně navržené řešení
- 4. – do globální proměnné se ukládá výsledek připojení a přihlášení k databázi
- 5. – zahajuje se blok pro zachycení výjimky a připravuje volaný SQL dotaz
- 6. – vytváří se lokální proměnná pro sadu výsledků a do ní se ukládá výsledek dotazu
- 7. – zahajuje se smyčka procházení sadou výsledků
- 8. – deklaruje se lokální proměnná pro uložení výsledků pro jednotlivé řádky sady výsledků dotazu
- 9. – 14. – do jednoho řádku se ukládají všechny sloupce tabulky včetně jejich typu a pořadí v tabulce
- 15. – řádek s daty se ukládá do konečné sady dat, končí smyčka procházení sady výsledků
- 16. – zachycuje se případná výjimka v provádění SQL dotazu včetně chybového hlášení
- 17. – zahajuje se sekce pro řádné ukončení dotazu, kontroluje se jeho příprava
- 18. – pokud je dotaz správně připravený, tak se uzavírá
- 19. – zachycuje se případná výjimka v ukončení SQL dotazu včetně chybového hlášení
- 20. – ukončuje se připojení k databázi
- 21. – zachycuje se případná výjimka při ukončování připojení k databázi včetně chybového hlášení
- 22. – vrací se návratová hodnota funkce a ta se ukončuje
Jak ukazuje samotný kód i jeho stručné objasnění, je tato funkce poměrně složitá. Na druhou stranu je však i docela obecná a dává nám do budoucna možnost vytvoření libovolného dotazu (tedy ne úplně libovolného, musí obsahovat všechny sloupce tabulky) na tabulku obce a uložení příslušných výsledků do proměnné.
V dnešním dílu jsme se zaměřili na krátký úvod do problematiky databází a konkrétně PG, připravili jsme si data pro první ukázkový příklad a začali postupně tvořit potřebné GUI i výkonný kód. V příštím dílu budeme dál pokračovat v úpravě kódu tak, abychom mohli postupně zobrazit všechna data z vybrané tabulky.
