Obsah
1. Lokální sběrnice VESA Local Bus a univerzální sběrnice PCI
2. Lokální sběrnice VESA Local Bus
3. Univerzální sběrnice PCI se představuje
4. Přenosové rychlosti sběrnice PCI
5. Koncept Plug and Play
6. Komunikace mikroprocesoru s zařízením připojeným na PCI
7. Obsah další části tohoto seriálu
1. Lokální sběrnice VESA Local Bus a universální sběrnice PCI
V předchozí části tohoto seriálu byla popsána osmibitová i šestnáctibitová varianta univerzální sběrnice ISA (Industrial Standard Architecture). Tato sběrnice se v osobních počítačích kompatibilních s IBM PC používala po velmi dlouhou dobu, prakticky od samotného vzniku PC až do cca roku 2003. Dokonce i modernější základní desky, které již podporovaly některou z novějších sběrnic (EISA, VESA Local Bus či PCI), totiž – převážně z historických důvodů a pro zachování kompatibility se speciálními zařízeními – alespoň jeden konektor určený pro sběrnici ISA stále měly nainstalovaný, což samozřejmě znamenalo větší náklady na vývoj základní desky (mezi „rychlou“ sběrnicí a ISA musel být řadič, který zajišťoval mj. i řízení přerušení, DMA přenosy atd). V mnohých průmyslových počítačích založených na architektuře PC se se sběrnicí ISA dokonce můžeme setkat i dnes, mnoho měřicích desek či jednoúčelových řídicích desek je určeno právě pro ISA.
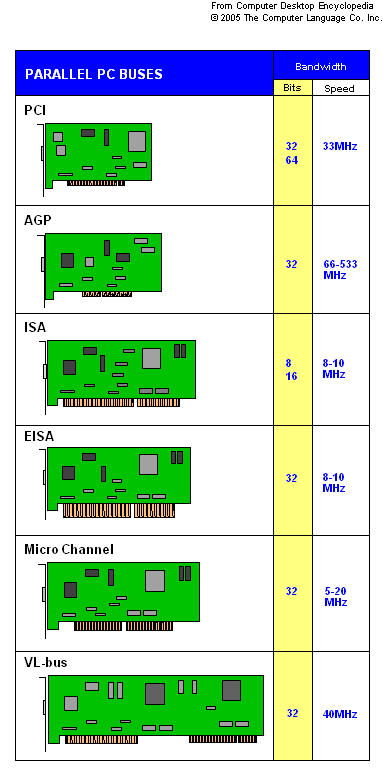
Obrázek 1: Schematické tvary přídavných karet upravených pro různé typy sběrnic, které se používaly či dodnes používají na desktopových PC
Při pohledu zpět do historie můžeme říci, že sběrnice ISA byla jednou z hlavních příčin velkého rozšíření počítačů kompatibilních s IBM PC, XT či AT – jednalo se o skutečný průmyslový standard, pro nějž mnoho výrobců vytvářelo různé typy přídavných karet, od řadičů sériových a paralelních portů přes síťové karty a specializované karty určené například pro skenery až po karty zvukové a grafické. Ovšem právě fakt, že se ke sběrnici musely připojovat i přídavné karty, které měly vysoké nároky na přenosové rychlosti (zejména se jednalo o grafické karty), vedl k tomu, že spolu s rostoucím výkonem mikroprocesorů i zvětšující se kapacitou operační paměti sběrnice ISA postupně zastarala.

Obrázek 2: Na tomto snímku je opravdová rarita – grafická karta kompatibilní s CGA, určená pro osmibitovou sběrnici ISA, která byla vyrobena v Bulharsku. Nutno podotknout, že originální CGA od firmy IBM obsahovala méně součástek o větší integraci. Některé integrované obvody na zobrazené kartě možná velmi dobře znáte.
Zatímco u prvních typů počítačů kompatibilních s IBM PC se poměrně běžně operační paměť, jejíž maximální kapacita byla 640 kB, doplňovala o takzvanou expandovanou paměť (expanded memory – EMS), jejíž paměťové čipy byly skutečně umístěny na rozšiřující kartě určené pro osmibitovou či šestnáctibitovou sběrnici ISA, stalo se toto ve své podstatě nouzové řešení již u počítačů s procesorem 80286 rychlostně neúnosné. Rychlostní omezení sběrnice ISA se negativně projevovalo i při připojení grafické karty na sběrnici. Pro starší grafické karty typu CGA, EGA a Hercules sice rychlost sběrnice ISA dostačovala (v textových i grafických režimech; například libovolný grafický režim u karty CGA vyžadoval pouze necelých 16 kB obrazové paměti), ovšem s příchodem populární grafické karty VGA a především jejích následovníků (SVGA) bylo pro přesuny obrazových dat zapotřebí mnohem širšího přenosového pásma, než jaké mohla sběrnice ISA poskytnout.

Obrázek 3: Populární hra King's Quest zobrazená v grafickém režimu karty CGA, který umožňoval zobrazení celých čtyř barev v rozlišení 320×200 pixelů. Paměťové nároky na framebuffer dosahují 16 kB (přesněji 16000 bytů).
Řešení grafického subsystému formou vyměnitelné grafické karty, které bylo použito právě u osobních počítačů kompatibilních s IBM PC, má některé nesporné výhody, ale samozřejmě i nevýhody. Proto se v minulosti objevily (a s největší pravděpodobností i v budoucnosti budou objevovat) snahy o zajištění užší spolupráce mezi mikroprocesorem, operační pamětí a grafickou kartou. Mezi relativně úspěšná řešení patřilo použití lokálních sběrnic (například sběrnice VESA Local Bus) či portů vymezených pouze pro grafickou kartu (Advanced Graphics Port). Opačné snahy vedou k unifikaci přístupu ke všem zařízením, včetně grafické karty (viz již popsaná sběrnice ISA, níže popsaná sběrnice PCI či PCI Express).

Obrázek 4: Tatáž hra (King's Quest), zde ovšem zobrazená v grafickém režimu karty Tandy, jenž při stejném rozlišení 320×200 pixelů dokázal pracovat již se šestnácti současně zobrazitelnými barvami. Paměťové nároky na framebuffer byly dvojnásobné, tj. 32 kB.
Na tomto místě by bylo vhodné podotknout, že sběrnicová architektura je sice pro osobní počítače (stále založené na stařičkém návrhu od IBM) typická, ale není jediná možná. Například v grafických stanicích firmy SGI se již v dávné minulosti místo sběrnice používaly odlišné topologie, například mřížka, hierarchická mřížka, torus či „tlustý“ strom. Tyto topologie jsou sice na jednu stranu dražší, na stranu druhou je však možné dosáhnout mnohem vyšších toků dat (přenosy lze provádět paralelně a nezávisle na sobě). Bariéru lineární „sběrnicové“ topologie na PC částečně překračuje až PCI Express.

Obrázek 5: Jedna z výkonných grafických stanic od firmy SGI. Za několik let budeme mít podobný výpočetní výkon i v běžných noteboocích.
2. Lokální sběrnice VESA Local Bus
Sběrnice VESA Local Bus (zkráceně VLB) byla navržena sdružením VESA jako rychlejší doplněk k výkonnostně nedostatečné sběrnici ISA. Zatímco je sběrnice ISA určena pro prakticky libovolné zařízení, u sběrnice VESA Local Bus se předpokládalo její použití zejména pro grafické karty, řadiče rychlých pevných disků a síťové karty. Tato sběrnice byla používána pouze na osobních počítačích typu PC; podpora pro jiné výpočetní systémy prakticky neexistuje, protože architektura sběrnice je poměrně úzce svázána se strukturou a funkcí vývodů mikroprocesoru 486. Největší rozšíření této sběrnice bylo, jak se ostatně dá očekávat, v dobách osobních počítačů s procesory řady 486, u kterých rostla poptávka po rychlých grafických kartách a pevných discích s většími přenosovými rychlostmi. S dalším vývojem počítačů (zejména těch s procesory Intel Pentium, AMD K6 atd.) je zřetelný značný ústup v používání sběrnice VLB, naopak se začíná prosazovat perspektivní sběrnice PCI a v posledních letech i její nástupce PCI Express.

Obrázek 6: Grafická karta určená do sběrnice VESA Local Bus. Poměrně typické je přidružení i dalších funkcí na jednu kartu – zde sériových a paralelních portů, IDE rozhraní atd. Pokud se taková karta zapojila do základní desky, která již tyto obvody obsahovala, většinou došlo ke konfliktu a pomocí jumperů se musely přídavné funkce opět zakázat. Podobná obludná karta dodnes spolehlivě funguje v mém starém počítači s procesorem IBM Blue Lightning, což je jedna z variant procesoru 486.
Jak již název sběrnice VESA Local Bus napovídá, jedná se o sběrnici lokální, tj. sběrnici, která přímo sdílí datovou a adresovou částs mikroprocesorem počítače (z toho také vychází šířka datové části – 32 bitů). To má mimo jiné za následek omezení maximálního počtu připojených zařízení na dvě, maximálně až na tři, protože větší počet zařízení by příliš proudově a impedančně zatěžoval procesorovou sběrnici. Mohlo by docházet i k odrazům na adresových/datových vodičích, proto jsou konektory lokální sběrnice umístěny co nejblíže k mikroprocesoru. Také frekvence sběrnice je odvozena z vnější taktovací frekvence mikroprocesoru a může se pohybovat v hodnotách od 33 MHz až do 50 MHz (popravdě řečeno jsem však neviděl kartu určenou pro VLB, která by spolehlivě na 50 MHz pracovala, mezní frekvence spolehlivé funkce většinou byla 40 MHz, což odpovídá procesoru 486DX2 pracujícího na interní frekvenci 80 MHz či 486DX4, který pracuje až na 120 MHz).

Obrázek 7: Pohled do vzdálené minulosti – karty určené pro šestnáctibitovou sběrnici ISA (nahoře) a sběrnici EISA (dole).
Sběrnice VESA Local Bus podporovala takzvaný burst režim přenosu blokových dat. Jednalo se o zvláštní mód, ve kterém se přenesla vždy jedna adresa a po ní čtyři datová slova. Bylo tak možné jednoduše a rychle přenést 4×32 bitů pouze v pěti sběrnicových cyklech oproti osmi cyklům nutným pro přenos čtyř dvojic adresa-data. Jak se budete moci dočíst v dalších kapitolách, je možné u pokročilejších sběrnic použít vylepšenou variantu burst režimu, ve kterém se po zadání jedné adresy a počtu opakování může přenést mnohem více dat, což ve svém důsledku vede k vyšší přenosové rychlosti, neboť se ušetří cykly nutné pro přenos a dekódování adresy.
Prakticky jedinou výhodou sběrnice VESA Local Bus oproti dále popsané sběrnici PCI a PCI Express, je v některých případech vyšší přenosová rychlost, zejména v těch počítačích, kde je použita taktovací frekvence sběrnice 40 MHz a 50 MHz (při použití frekvence 40 MHz je možné na sběrnici připojit maximálně tři zařízení, na sběrnici VLB o frekvenci 50 MHz je však počet teoreticky připojitelných zařízení omezen na dvě, viz však poznámka v předchozích odstavcích). Převažují však nevýhody, mezi něž patří zejména: dnes již prakticky neexistující podpora jak u výrobců zařízení pro tuto sběrnici, tak u producentů čipových sad základních desek (dnes se sběrnice VLB vyskytuje prakticky pouze v malém množství v průmyslových počítačích, ale i tam se jedná spíše o raritu), možnost připojení omezeného množství zařízení a různorodá taktovací frekvence (která způsobuje komplikace návrhu přídavné karty). Po příchodu mikroprocesoru Intel Pentium na trh, s nímž Intel uvedl také sběrnici PCI, přestává být o VESA Local Bus zájem.
3. Univerzální sběrnice PCI se představuje
Sběrnice PCI je v současné době stále (i přes nástup výkonnějších typů sběrnic) nejpoužívanější sběrnicí jak na osobních počítačích typu IBM PC tak i na pracovních stanicích a serverech, které s IBM PC kompatibilní nejsou. Tato sběrnice byla navržena firmou Intel již v roce 1992 a od té doby se stala oficiálním průmyslovým standardem, který je podporovaný mnoha výrobci periferních zařízení i čipových sad základních desek počítačů. Název sběrnice PCI vznikl ze slovního spojení Peripheral Component Interface. Důvodem velké úspěšnosti PCI na platformě PC byly především nevyhovující parametry předchozích sběrnic: původní osmibitová i šestnáctibitová sběrnice ISA byla velmi pomalá s omezeným počtem přerušení a nevyhovujícím DMA, MCA byla proprietárním řešením od konkurenční a poměrně rigidní firmy IBM a VESA Local Bus byla pouze sběrnicí lokální (s možností připojení omezeného množství zařízení) a orientovanou především na mikroprocesory řady 486. Předností PCI je i podpora Plug and Play, tedy dynamické detekce a konfigurace zařízení po startu počítače.

Obrázek 8: Karty určené pro sběrnici PCI pravděpodobně není nutné podrobně představovat, setkal se s nimi prakticky každý uživatel počítače.
Tato sběrnice používá multiplexované adresové a datové vodiče, tj. podle momentálního stavu vybraných řídicích signálů se na jedněch vodičích střídavě vystavuje adresa a posílají data nebo příkazy pro připojená zařízení. Tento (pro některé účely poněkud diskutabilní) princip byl u PCI použit především kvůli zachování nižší ceny celého systému, jelikož vyšší počet vodičů by znamenal také nárůst komplikovanosti jak sběrnice, tak i připojených zařízení. Se zvětšujícím se počtem vodičů by samozřejmě souviselo i zvětšení konektorů a plošných obvodů zařízení, což by mohlo vést i k mechanickým problémům při připojování karet (viz VESA Local Bus, kde zastrčení karty do konektoru vyžadovalo velkou sílu a trpělivost, problémy někdy bývají i s kartami určenými do portu AGP, protože jeho konektor je více vzdálený od místa mechanického uchycení karty, než je tomu u PCI).
4. Přenosové rychlosti sběrnice PCI
Sběrnice PCI existuje v několika různých variantách, které se liší především úrovněmi logických signálů, taktovací frekvencí (tj. frekvencí hodinových pulsů sběrnice) a šířkou datové části sběrnice. Úroveň logických signálů (tj. napětí logické jedničky – logická nula se od tohoto napětí odvozuje) může nabývat hodnoty buď 5 V nebo 3,3 V. Taktovací frekvence a šířka datové sběrnice přímo určují maximální datový tok, jak je ostatně naznačeno v následující tabulce. Zde je nutné upozornit na fakt, že u osobních počítačů typu IBM PC se v naprosté většině případů vyskytuje nejpomalejší verze sběrnice PCI, která je taktovaná na 33 MHz s šířkou datové části sběrnice 32 bitů a datovým tokem rovným 33 MHz × 4B=132 MB.s-1 (pro mnoho aplikací je to velmi rozumná rychlost, a to i v případě, že se o ni dělí více zařízení). Rychlejší varianty sběrnice PCI našly své uplatnění ve specializovaných systémech, které jsou orientovány zejména na zpracování vysokých datových toků, například při práci s videem či komunikaci několika rychlých disků:
| Taktovací frekvence | Šířka datové části | Maximální datový tok |
|---|---|---|
| 33 MHz | 32 bitů | 132 MB.s-1 |
| 33 MHz | 64 bitů | 264 MB.s-1 |
| 66 MHz | 32 bitů | 264 MB.s-1 |
| 66 MHz | 64 bitů | 532 MB.s-1 |
| 133 MHz | 32 bitů | 532 MB.s-1 |
| 133 MHz | 64 bitů | 1066 MB.s-1 |
Sběrnice PCI tvoří spolu s rychlou adresovou a datovou lokální sběrnicí mikroprocesoru, popř. i se starší sběrnicí ISA, hierarchickou strukturu, ve které jsou jednotlivé sběrnice vzájemně uspořádány podle své rychlosti a vzdálenosti (ve smyslu řídicích, oddělovacích a budících obvodů) od centrální procesorové jednotky – CPU. Kombinace PCI+ISA se ve starších počítačích vyskytuje poměrně často, některé základní desky nabízí i trojkombinaci AGP+PCI+ISA, další kombinace (například PCI+VLB) se prakticky nevyskytují a ani nemají praktický význam.

Obrázek 9: Již dvakrát prezentované schéma typického počítače s hierarchicky uspořádanými sběrnicemi.
5. Koncept Plug and Play
Z hlediska uživatele počítače či programátora ovladačů je poměrně velmi důležitý také koncept nazvaný Plug and Play, který se začal ve velké míře využívat právě u PCI sběrnice (díky problémům s některými zařízeními, BIOSy i operačními systémy se tento koncept také nazýval Plug and Pray :-). Koncepce Plug and Play je založena na použití takzvaných konfiguračních registrů, jejichž obsah se při startu systému nastaví programově podle zjištěných typů a modifikací jednotlivých zařízení připojených na PCI sběrnici. Odpadá tak mnohdy velmi složité řešení konfliktů vzniklých použitím shodného přerušení či stejné adresy v adresovém prostoru zařízení – některé kombinace zařízení dokonce nešly na sběrnici ISA vyřešit (pamětníci se jistě podělí o zkušenosti). Pomocí konfiguračních registrů je také možné zjistit typ zařízení (zvukové zařízení, grafická karta, ovladač podřízené sběrnice, LAN adaptér apod., skupiny zařízení lze vyčíst ze specifikace) a kód výrobce zařízení – všechna zařízení jsou uspořádána do stromové struktury, která obsahuje například větve pro grafické karty, zvukové karty, síťová zařízení, řadiče periferních zařízení apod.
Kódy výrobců, které by (teoreticky) měly být certifikované, jsou specifikovány šestnáctibitovým číslem (Intel má například přidělené pěkné číslo 8086), které je, společně s číslem zařízení a přidělenými prostředky, zobrazené při inicializaci počítače (druhá obrazovka, která dnes bohužel pouze problikne, protože zavaděče moderních OS mají nepříjemnou vlastnost, že zobrazují vlastní menu). Svoji konfiguraci, tj. zařazení do stromu zařízení a rozsah adres či I/O prostoru, si zařízení uchovává buď v paměti ROM, EPROM či nejčastěji v EEROM či Flash paměti. Zajímavě je řešen rozsah adres, který dané zařízení pro svoji činnost potřebuje. Tento rozsah (či rozsahy) jsou taktéž uchovány v konfiguračních registrech (nazývaných BADRn, neboli Base Address n, n je typicky číslo od jedné do pěti), ale konkrétní adresu zařízení přidělí až BIOS případně operační systém. To mimo jiné znamená, že při každém startu počítače může být zařízení mapované do jiné oblasti či oblastí paměti. Pro samotné ovladače ani aplikace to nepředstavuje žádný problém, protože si mohou zjistit všechna zařízení připojená na sběrnici a z nich si podle kódu výrobce, identifikace zařízení a další jednobytové položky (odlišuje stejný typ zařízení, například dvě jinak zcela identické síťové karty) vybrat zařízení se kterým budou komunikovat.
6. Komunikace mikroprocesoru s zařízením připojeným na PCI
Mikroprocesor může k zařízením připojeným ke sběrnici PCI přistupovat pomocí několika technologií. Na první pohled je nejjednodušší přístup přes mapovanou paměť. Toto řešení má nevýhodu v tom, že se při nesprávně napsaném ovladači či nekorektně fungujícím zařízení může celá sběrnice „zaseknout“ a počítač pak přestane reagovat. Další možností je použití obousměrné fronty (FIFO) nebo takzvaných mailboxů, což jsou registry, do kterých lze z jedné strany (CPU či zařízení) informace zapisovat a z druhé strany tyto informace číst. K dispozici jsou samozřejmě příznaky čtení či zápisu do mailboxů, stejně tak jako řízení pomocí přerušení, jež může být generováno jak při práci s frontou FIFO, tak i při práci s mailboxy.
Nejrychlejším typem přenosu je busmaster přenos, při kterém řízení sběrnice převezme samo zařízení. Typicky se busmaster přenos na straně zařízení provádí přes obousměrné fronty a díky vyrovnávací paměti, kterou fronty představují (mohou mít kapacitu například šestnáct třicetidvoubitových slov) se reálná přenosová rychlost může přibližovat rychlosti teoretické. Na PCI kartách, pro které jsem vyvíjel ovládací programy, se tímto způsobem dosahovalo reálné dlouhodobé (průměrné) přenosové rychlosti cca 105 MB.s-1, což se přibližuje teoretické hranici (musíme vzít v úvahu to, že se zpracovávaná data přenášela do operační paměti, jejíž rychlost také není nekonečná, za sekundu proběhlo a bylo dříve či později zpracováno několik set různých přerušení, samotný ovladač také nebyl příliš optimálně napsaný atd.).

Obrázek 10: Porovnání velikostí konektorů různých moderních sběrnic a portu AGP.

7. Obsah další části tohoto seriálu
V následujícím pokračování seriálu o architekturách počítačů si popíšeme pokračovatele sběrnice PCI. Jedná se o sběrnici nazvanou PCI Express, u níž je možné dosáhnout ještě vyšších přenosových rychlostí než u sběrnice PCI. Také si popíšeme princip práce interního portu AGP, který slouží (či pro někoho, kdo již přešel na modernější technologii, už jen sloužil) k připojení grafických karet a grafických akcelerátorů. Řekneme si, jaké zvláštní režimy port AGP obsahuje – jedná se o režimy určené převážně pro „grafické“ účely, například efektivní přenos textur, sdílení grafických dat či práce s videem.
























