
Obsah
1. Programování v assembleru mikroprocesorů AArch64
3. Složitější příklad: programová smyčka a výpis textu na standardní výstup
4. Překlad a slinkování programu s ladicími symboly i bez ladicích symbolů
5. Překlad se současným výpisem vygenerovaného kódu
6. Informace o spustitelném souboru vypsané nástrojem objdump
9. Spuštění a krokování programu, nastavení breakpointu
10. Zobrazení základních informací o laděném procesu
11. Použití příkazu display a print
12. Použití příkazu examine pro prohlížení obsahu paměti
15. Specifikace příkazů vykonaných při vstupu na breakpoint
16. Vzdálené ladění přes gdbserver
17. TUI – textové uživatelské rozhraní GNU debuggeru
18. Použití nadstavby nad GNU debuggerem nazvané cgdb
1. Programování v assembleru mikroprocesorů AArch64
V dnešní části seriálu o architekturách počítačů volně navážeme na konec předchozího článku, v němž jsme si ukázali velmi jednoduchou aplikaci naprogramovanou v assembleru 64bitových mikroprocesorů AArch64. Dnes si popíšeme, jak lze trasovat a ladit poněkud složitější aplikaci, což mimochodem znamená, že navážeme na starší miniseriál, ve kterém jsme se věnovali podobnému tématu, ovšem nikoli s ohledem na AArch64. Poznámka: budeme sice používat nástroje GNU Assembler, GNU Linker, GNU Debugger a taktéž doplňkové nástroje gdbserver a cgdb, což však v žádném případě neznamená, že pro AArch64 neexistují komerční varianty.
2. GNU Debugger
Kromě komerčních nástrojů je možné i pro 64bitové mikroprocesory AArch64 použít GNU Debugger neboli GDB, jehož první verze vznikla již v roce 1986, takže se po více než třiceti letech kontinuálního vývoje jedná o velmi vyzrálý produkt v typickém unixovém stylu – rozsáhlá funkcionalita je skryta za zpočátku těžko ovladatelné uživatelské rozhraní. GNU Debugger byl v průběhu svého vývoje portován jak na mnoho operačních systémů (většinou na různé komerční i nekomerční varianty Unixu, ovšem nalezneme ho například i v systému DOS), tak i na nepřeberné množství procesorových a mikroprocesorových architektur, z nichž jmenujme především řadu x86, x86_64, ARM (prakticky všechny 32bitové CPU i nová 64bitová jádra – což je ostatně přesně téma, které nás dnes zajímá), Motorola 68HC11, MIPS či PowerPC.
Tento debugger podporuje všechny překladače z rodiny GNU, což mj. znamená, že dokáže zobrazit a pracovat se zdrojovými kódy v jazycích Ada, C, C++, Go, Objective-C, D, Fortran, Modula-2, Pascal a Java (ovšem jen v případě překladu Javy do nativního kódu). Na základě jazyka, v němž je laděný program napsán, se upravují i zprávy GNU Debuggeru, takže se například používá správný formát hexadecimálních čísel, struktur záznamů atd. Taktéž assemblery používané na Linuxu GNU Debugger přímo podporují (jedná se jak o as, tak i o NASM – druhý jmenovaný assembler však pro AArch64 neexistuje). Ladicí nástroj GNU Debugger primárně používá ke komunikaci s uživatelem příkazový řádek, alternativně lze použít i protokol pro nepřímé ovládání debuggeru (tuto technologii používají různé nadstavby nad debuggerem) a v případě potřeby je možné k laděné aplikaci přidat relativně krátký „stub“ sloužící pro přímé ladění takové aplikace. Podporováno je i vzdálené ladění.
Většina často používaných příkazů má i svoji zkrácenou podobu (bt=backtrace, c=continue, f=frame) a navíc je možné používat klávesu [Tab] pro automatické doplnění celého jména příkazu. Pokud je správně nastavený terminál, bude fungovat i historie příkazového řádku, a to stejným způsobem, jaký známe ze shellu. Alternativně je možné využít gdbtui s celoobrazovkovým výstupem a přiblížit se tak (i když jen částečně) možnostem debuggerů s plnohodnotným grafickým uživatelským rozhraním. Pokud se GNU Debugger používá pro trasování, lze do kódu vkládat takzvané tracepoints. Ty slouží pro zjištění stavu programu v nějakém specifikovaném bodu, ovšem bez (po)zastavení programu. Samotné pozastavení programu totiž může v některých případech způsobit jeho chybnou činnost či naopak zastínit některé chyby vyplývající ze špatně implementované synchronizace vláken či při přístupu ke sdíleným prostředkům. Podpora tracepointů však prozatím pro AArch64 není implementována.
Všechny příkazy GNU Debuggeru jsou popsány v rozsáhlé nápovědě dostupné přímo z příkazového řádku:
(gdb) help List of classes of commands: aliases -- Aliases of other commands breakpoints -- Making program stop at certain points data -- Examining data files -- Specifying and examining files internals -- Maintenance commands obscure -- Obscure features running -- Running the program stack -- Examining the stack status -- Status inquiries support -- Support facilities tracepoints -- Tracing of program execution without stopping the program user-defined -- User-defined commands Type "help" followed by a class name for a list of commands in that class. Type "help all" for the list of all commands. Type "help" followed by command name for full documentation. Type "apropos word" to search for commands related to "word". Command name abbreviations are allowed if unambiguous.
V seznamu zobrazeném pod tímto odstavcem jsou zmíněny vybrané základní operace, které je možné v GNU Debuggeru provádět:
- Ladění přeloženého programu (spuštění procesu přímo z debuggeru), připojení debuggeru k běžícímu procesu, analýza core dumpu.
- Spuštění (run), pozastavení a znovuspuštění laděného programu (continue). Prakticky tytéž operace je možné provádět s jednotlivými vlákny.
- Krokování programu, přičemž se vývojář může rozhodnout, jestli se mají volané funkce provést v jednom kroku (step over) či zda se naopak má přejít i dovnitř těchto funkcí (step into).
- Nastavení breakpointů i breakpointů s podmínkou, tj. breakpointů, které začnou být aktivní až ve chvíli, kdy dojde ke splnění zadané podmínky (vhodné například při sledování chování programových smyček či rekurzivních algoritmů).
- Nastavení takzvaných watchpointů. Jedná se o speciální případ breakpointů; program se zastaví ve chvíli, kdy dojde ke změně zadaného výrazu, v nejjednodušším případě ke změně hodnoty nějaké proměnné (popř. místa v paměti). Alternativně lze watchpoint nastavit pro detekci čtení z proměnné. To se samozřejmě týká i položek v záznamech (record) či prvků polí.
- Podpora tracepointů. Zjednodušeně řečeno je možné říci, že tracepointy slouží pro zjištění stavu programu v nějakém specifikovaném bodu, ovšem bez (po)zastavení programu. Samotné pozastavení programu totiž může v některých případech způsobit jeho chybnou činnost či naopak zastínit některé chyby vyplývající ze špatně implementované synchronizace vláken či při přístupu ke sdíleným prostředkům. Tracepointy však v současnosti nelze na Aarch64 použít.
- Výpis obsahu zásobníkových rámců (backtrace) a tím pádem i zjištění historie volaných funkcí (včetně informací o předaných parametrech).
- Prohlížení obsahu paměti, k čemuž slouží výkonný příkaz print a examine, jimž je možné zadat mnohdy i velmi komplikovaný výraz, jehož výsledek se vypíše na standardní výstup. Lze kombinovat s krokováním.
3. Složitější příklad: programová smyčka a výpis textu na standardní výstup
Při ladění aplikace pro AArch64 použijeme relativně jednoduchý demonstrační příklad, v němž se nejprve naplní řetězec (= vyhrazená oblast paměti) hvězdičkami, následně se tento řetězec vypíše systémovým voláním write na standardní výstup a nakonec se aplikace ukončí systémovým voláním exit. Opět si povšimněte, že se čísla syscallů zcela odlišují od hodnot, s nimiž jste se mohli setkat na platformě x86, x86–64 či ARM(32):
# Linux kernel system call table sys_exit = 93 sys_write = 64
Samotný výpis řetězce vypadá následovně. Je nutné znát délku řetězce, protože systémové volání write je určeno pro zápis sekvence bajtů do jakéhokoli souboru/zařízení, tudíž se zde nepracuje s řetězci ukončenými nulou:
mov x8, #sys_write // cislo syscallu pro funkci "write"
mov x0, #std_output // standardni vystup
ldr x1, =buffer // adresa retezce, ktery se ma vytisknout
mov x2, #rep_count // pocet znaku, ktere se maji vytisknout
svc 0 // volani Linuxoveho kernelu
V programové smyčce je použita instrukce CBNZ, tedy porovnání vybraného pracovního registru s nulou a skokem ve chvíli, kdy je registr nenulový. Taktéž si povšimněte, že při zápisu bajtu (znaku) do operační paměti instrukcí STRB (store byte) je nutné použít 32bitový registr w3 a nikoli 64bitový registrx3 (omezení instrukční sady, v praxi vlastně nijak významné). Do operační paměti se zapisuje samozřejmě pouze spodních osm bitů pracovního registru:
ldr x1, =buffer // zapis se bude provadet do tohoto bufferu
mov x2, #rep_count // pocet opakovani znaku
mov w3, #'*' // zapisovany znak
loop:
strb w3, [x1] // zapis znaku do bufferu
add x1, x1, #1 // uprava ukazatele do bufferu
sub x2, x2, #1 // zmenseni pocitadla a soucasne nastaveni priznaku
cbnz x2, loop // pokud jsme se nedostali k nule, skok na zacatek smycky
Poznámka: smyčka není žádným způsobem optimalizována, ostatně ani zápis po bajtech není pro 64bitovou architekturu nejlepším řešením.
Úplný zdrojový kód tohoto příkladu vypadá takto:
# asmsyntax=as
# Demonstracni priklad naprogramovany v assembleru GNU as
# - pocitana programova smycka realizovana instrukci CBNZ
# - uprava pro mikroprocesory s architekturou AArch64
#
# Autor: Pavel Tisnovsky
# Linux kernel system call table
sys_exit = 93
sys_write = 64
# List of syscalls for AArch64:
# https://github.com/torvalds/linux/blob/master/include/uapi/asm-generic/unistd.h
# Dalsi konstanty pouzite v programu - standardni streamy
std_input = 0
std_output = 1
# pocet opakovani znaku
rep_count = 40
#-----------------------------------------------------------------------------
.section .data
#-----------------------------------------------------------------------------
.section .bss
.lcomm buffer, rep_count // rezervace bufferu pro vystup
#-----------------------------------------------------------------------------
.section .text
.global _start // tento symbol ma byt dostupny i linkeru
_start:
ldr x1, =buffer // zapis se bude provadet do tohoto bufferu
mov x2, #rep_count // pocet opakovani znaku
mov w3, #'*' // zapisovany znak
loop:
strb w3, [x1] // zapis znaku do bufferu
add x1, x1, #1 // uprava ukazatele do bufferu
sub x2, x2, #1 // zmenseni pocitadla a soucasne nastaveni priznaku
cbnz x2, loop // pokud jsme se nedostali k nule, skok na zacatek smycky
mov x8, #sys_write // cislo syscallu pro funkci "write"
mov x0, #std_output // standardni vystup
ldr x1, =buffer // adresa retezce, ktery se ma vytisknout
mov x2, #rep_count // pocet znaku, ktere se maji vytisknout
svc 0 // volani Linuxoveho kernelu
mov x8, #sys_exit // cislo sycallu pro funkci "exit"
mov x0, #0 // exit code = 0
svc 0 // volani Linuxoveho kernelu
4. Překlad a slinkování programu s ladicími symboly i bez ladicích symbolů
Tato kapitola bude velmi stručná, protože si v ní jen řekneme, že pokud vyžadujeme překlad výsledné verze aplikace bez ladicích informací, postačuje zavolat as (GNU Assembler) pouze s parametrem -o a specifikací jména výsledného objektového souboru. Naproti tomu při volání linkeru použijeme parametr -s nebo jeho dlouhou variantu –strip-all, díky níž nebude výsledný spustitelný soubor obsahovat žádné informace o symbolech:
as loop-aarch64.s -o loop-aarch64.o ld -s loop-aarch64.o
Pokud je naopak nutné ladicí informace zachovat, například pro potřeby ladění, musí se při volání GNU Assembleru použít volba -g nebo její delší varianta –gen-debug. Taktéž nezapomeňte na odstranění přepínače -s při volání linkeru, protože v opačném případě by se všechny ladicí informace sice přidaly do objektového souboru, ale ve výsledném spustitelném souboru by již nebyly obsaženy:
as -g loop-aarch64.s -o loop-aarch64.o ld loop-aarch64.o
Poznámka: u všech dalších příkladů GNU Debuggeru předpokládám, že ladicí informace jsou zachovány.
5. Překlad se současným výpisem vygenerovaného kódu
Zejména při zápisu maker či při jejich volání může dojít k situaci, kdy se makro neexpanduje podle našich předpokladů a je nutné zjistit, kde nastal problém. GNU Assembler sice neexpanduje makra samostatným preprocesorem (jak je tomu v céčku a jeho preprocesoru nazvaném cpp), ovšem obsahuje možnost nechat si vygenerovat výpis původního zdrojového kódu kombinovaného s přeloženým objektovým kódem, přesněji řečeno s objektovým kódem zapsaným v hexadecimálním tvaru. Jedná se o mnohdy velmi užitečnou vlastnost, kterou nalezneme u mnoha assemblerů, a to i u některých starších nástrojů. Takový výpis se na historických mainframech bez obrazovky většinou posílal přímo na tiskárnu, takže obsahoval i vepsané chyby nalezené překladačem. A právě v tomto výpisu se mohou objevit expandovaná makra. Podívejme se, co se stane, pokud při překladu použijeme volbu -alm (resp. volbu -a s dalšími příznaky l a m) kombinovanou popř. s volbou -g:
as -alm loop-aarch64.s -o loop-aarch64.o AARCH64 GAS loop-aarch64.s page 1 1 # asmsyntax=as 2 3 # Demonstracni priklad naprogramovany v assembleru GNU as 4 # - pocitana programova smycka realizovana instrukci CBNZ 5 # - uprava pro mikroprocesory s architekturou AArch64 6 7 # Autor: Pavel Tisnovsky 8 9 10 11 # Linux kernel system call table 12 sys_exit = 93 13 sys_write = 64 14 15 # List of syscalls for AArch64: 16 # https://github.com/torvalds/linux/blob/master/include/uapi/asm-generic/unistd.h 17 18 # Dalsi konstanty pouzite v programu - standardni streamy 19 std_input = 0 20 std_output = 1 21 22 # pocet opakovani znaku 23 rep_count = 40 24 25 26 27 #----------------------------------------------------------------------------- 28 .section .data 29 30 31 32 #----------------------------------------------------------------------------- 33 .section .bss 34 .lcomm buffer, rep_count // rezervace bufferu pro vystup 35 36 37 38 #----------------------------------------------------------------------------- 39 .section .text 40 .global _start // tento symbol ma byt dostupny i linkeru 41 42 _start: 43 0000 01020058 ldr x1, =buffer // zapis se bude provadet do tohoto bufferu 44 0004 020580D2 mov x2, #rep_count // pocet opakovani znaku 45 0008 43058052 mov w3, #'*' // zapisovany znak 46 loop: 47 000c 23000039 strb w3, [x1] // zapis znaku do bufferu 48 0010 21040091 add x1, x1, #1 // uprava ukazatele do bufferu 49 0014 420400D1 sub x2, x2, #1 // zmenseni pocitadla a soucasne nastaveni priznaku 50 0018 A2FFFFB5 cbnz x2, loop // pokud jsme se nedostali k nule, skok na zacatek smycky 51 52 001c 080880D2 mov x8, #sys_write // cislo syscallu pro funkci "write" 53 0020 200080D2 mov x0, #std_output // standardni vystup 54 0024 E1000058 ldr x1, =buffer // adresa retezce, ktery se ma vytisknout 55 0028 020580D2 mov x2, #rep_count // pocet znaku, ktere se maji vytisknout 56 002c 010000D4 svc 0 // volani Linuxoveho kernelu 57 AARCH64 GAS loop-aarch64.s page 2 58 0030 A80B80D2 mov x8, #sys_exit // cislo sycallu pro funkci "exit" 59 0034 000080D2 mov x0, #0 // exit code = 0 60 0038 010000D4 svc 0 // volani Linuxoveho kernelu 61 003c 00000000 61 00000000 61 00000000
Tento výpis může být velmi užitečný při zkoumání vlastností instrukční sady.
6. Informace o spustitelném souboru vypsané nástrojem objdump
Rozdíl mezi překladem programu bez ladicích informací a s ladicími informacemi nám ozřejmí nástroj objdump. Možnosti tohoto nástroje jsou skutečně velké (může fungovat i jako disassembler atd.), nás však bude zajímat především přepínač -x, který vypíše i obsah tabulek symbolů. Pro program přeložený bez ladicích informací získáme stručný výsledek:
as loop-aarch64.s -o loop-aarch64.o
ld -s loop-aarch64.o
objdump -x a.out
a.out: file format elf64-littleaarch64
a.out
architecture: aarch64, flags 0x00000102:
EXEC_P, D_PAGED
start address 0x00000000004000b0
Program Header:
LOAD off 0x0000000000000000 vaddr 0x0000000000400000 paddr 0x0000000000400000 align 2**16
filesz 0x00000000000000f8 memsz 0x00000000000000f8 flags r-x
LOAD off 0x00000000000000f8 vaddr 0x00000000004100f8 paddr 0x00000000004100f8 align 2**16
filesz 0x0000000000000000 memsz 0x0000000000000028 flags rw-
private flags = 0:
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000048 00000000004000b0 00000000004000b0 000000b0 2**3
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .bss 00000028 00000000004100f8 00000000004100f8 000000f8 2**3
ALLOC
SYMBOL TABLE:
no symbols
Pokud je však program přeložen s ladicími informacemi, bude tabulka symbolů obsahovat mj. i všechny symboly, které nalezneme ve zdrojovém kódu (sys_exit, rep_count, buffer atd.):
as -g loop-aarch64.s -o loop-aarch64.o
ld loop-aarch64.o
objdump -x a.out
a.out: file format elf64-littleaarch64
a.out
architecture: aarch64, flags 0x00000112:
EXEC_P, HAS_SYMS, D_PAGED
start address 0x00000000004000b0
Program Header:
LOAD off 0x0000000000000000 vaddr 0x0000000000400000 paddr 0x0000000000400000 align 2**16
filesz 0x00000000000000f8 memsz 0x00000000000000f8 flags r-x
LOAD off 0x00000000000000f8 vaddr 0x00000000004100f8 paddr 0x00000000004100f8 align 2**16
filesz 0x0000000000000000 memsz 0x0000000000000028 flags rw-
private flags = 0:
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000048 00000000004000b0 00000000004000b0 000000b0 2**3
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .bss 00000028 00000000004100f8 00000000004100f8 000000f8 2**3
ALLOC
2 .debug_aranges 00000030 0000000000000000 0000000000000000 00000100 2**4
CONTENTS, READONLY, DEBUGGING
3 .debug_info 0000004a 0000000000000000 0000000000000000 00000130 2**0
CONTENTS, READONLY, DEBUGGING
4 .debug_abbrev 00000014 0000000000000000 0000000000000000 0000017a 2**0
CONTENTS, READONLY, DEBUGGING
5 .debug_line 00000050 0000000000000000 0000000000000000 0000018e 2**0
CONTENTS, READONLY, DEBUGGING
SYMBOL TABLE:
00000000004000b0 l d .text 0000000000000000 .text
00000000004100f8 l d .bss 0000000000000000 .bss
0000000000000000 l d .debug_aranges 0000000000000000 .debug_aranges
0000000000000000 l d .debug_info 0000000000000000 .debug_info
0000000000000000 l d .debug_abbrev 0000000000000000 .debug_abbrev
0000000000000000 l d .debug_line 0000000000000000 .debug_line
0000000000000000 l df *ABS* 0000000000000000 loop-aarch64.o
000000000000005d l *ABS* 0000000000000000 sys_exit
0000000000000040 l *ABS* 0000000000000000 sys_write
0000000000000000 l *ABS* 0000000000000000 std_input
0000000000000001 l *ABS* 0000000000000000 std_output
0000000000000028 l *ABS* 0000000000000000 rep_count
00000000004100f8 l O .bss 0000000000000028 buffer
00000000004000bc l .text 0000000000000000 loop
0000000000410120 g .bss 0000000000000000 _bss_end__
00000000004100f8 g .bss 0000000000000000 __bss_start__
0000000000410120 g .bss 0000000000000000 __bss_end__
00000000004000b0 g .text 0000000000000000 _start
00000000004100f8 g .bss 0000000000000000 __bss_start
0000000000410120 g .bss 0000000000000000 __end__
00000000004100f8 g .bss 0000000000000000 _edata
0000000000410120 g .bss 0000000000000000 _end
Poznámka: povšimněte si, že některé symboly jsou globální (g) a jiné lokální (l). Další možností jsou současně lokální i globální symboly (!), unikátní globální symboly (u) a kupodivu i symboly, které nejsou ani globální ani lokální ( ).
7. Použití nástroje strace
Užitečný nástroj strace jsme si již na serveru Root.cz popsali, takže se podívejme, jaká systémová volání vlastně náš miniaturní program v assembleru používá. Na rozdíl od céčkového programu postaveného nad glibc uvidíme pouze tři systémová volání, z nichž dvě jsou explicitně použity v aplikaci (sys_write a sys_exit) a první zavolá spouštěcí program ihned po fork:
strace ./a.out
execve("./a.out", ["./a.out"], [/* 50 vars */]) = 0
write(1, "********************************"..., 40****************************************) = 40
exit(0) = ?
+++ exited with 0 +++
8. Ladění v GNU Debuggeru
Informace získané nástrojem strace jsou sice užitečné a důležité, ovšem pro ladění většiny problémů nedostačující, takže nám nezbývá, než se obrátit na mnohem mocnější nástroj – GNU Debugger.
Pokud GNU Debugger spustíme s programem přeloženým BEZ ladicích informací, bude první vypsaná zpráva vypadat přibližně takto:
as loop-aarch64.s -o loop-aarch64.o ld -s loop-aarch64.o gdb a.out GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-94.el7 Copyright (C) 2013 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty" for details. This GDB was configured as "aarch64-redhat-linux-gnu". For bug reporting instructions, please see: >http://www.gnu.org/software/gdb/bugs/>... Reading symbols from work/a.out...(no debugging symbols found)...done.
Mnohem praktičtější je používat GNU Debugger pro aplikaci přeloženou se všemi ladicími informacemi. Poslední řádek první zprávy v takovém případě neobsahuje poznámku o nedostupných symbolech:
as -g loop-aarch64.s -o loop-aarch64.o ld loop-aarch64.o gdb a.out GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-94.el7 Copyright (C) 2013 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty" for details. This GDB was configured as "aarch64-redhat-linux-gnu". For bug reporting instructions, please see: >http://www.gnu.org/software/gdb/bugs/>... Reading symbols from work/a.out...done.
9. Spuštění a krokování programu, nastavení breakpointu
Program v GNU Debuggeru spustíme jednoduše příkazem run nebo jeho zkrácenou variantou r (ještě jsem ovšem neviděl, že by někdo psal plnou variantu tohoto příkazu :-). Celý program se vykoná, tj. vypíše řadu hvězdiček a je ukončen:
(gdb) r Starting program: work/a.out ****************************************[Inferior 1 (process 27777) exited normally] (gdb)
Pokud aplikaci upravíte tak, aby vracela kód 2, bude výsledek debuggeru odlišný, protože pouze kód 0 je považován za normální ukončení:
(gdb) r Starting program: /root/work/a.out ****************************************[Inferior 1 (process 28207) exited with code 02]
Důležitým příkazem je nastavení breakpointů pomocí break nebo jen b. Za tento příkaz je možné (při ladění programu naprogramovaného v debuggeru) uvést návěští nebo pouhé číslo řádku. Nastavení breakpointu na začátek naší rutiny tedy proběhne následovně:
(gdb) b _start Breakpoint 1 at 0x4000b0: file loop-aarch64.s, line 43.
Pokud nyní program spustíme, neproběhne celý, ale zastaví se na prvním nalezeném breakpointu. Současně se i vypíše instrukce, která se bude provádět:
(gdb) r Starting program: work/a.out Breakpoint 1, _start () at loop-aarch64.s:43 43 ldr x1, =buffer // zapis se bude provadet do tohoto bufferu (gdb)
Dalším důležitým příkazem je next neboli n pro přechod na další instrukci (klasické krokování):
(gdb) n 44 mov x2, #rep_count // pocet opakovani znaku
Posledním základním příkazem je continue neboli c, které běh programu znovu spustí od místa, které se právě krokuje (to ovšem neznamená, že program musí doběhnout – může se zastavit na dalším breakpointu):
(gdb) c Continuing. ****************************************[Inferior 1 (process 27783) exited normally]
10. Zobrazení základních informací o laděném procesu
V průběhu krokování je možné použít příkaz disassemble pro zobrazení instrukce, která se má provést a taktéž několika instrukcí následujících. Pro programy psané v assembleru to může znamenat, že se skutečně zobrazí vykonávané instrukce a nikoli například volání maker:
(gdb) disassemble Dump of assembler code for function _start: => 0x00000000004000b0 <+0>: ldr x1, 0x4000f0 <loop+52> 0x00000000004000b4 <+4>: mov x2, #0x28 // #40 0x00000000004000b8 <+8>: mov w3, #0x2a // #42 End of assembler dump. (gdb)
Další příkaz info frame zobrazí zásobníkové rámce. Pro naši assemblerovskou aplikaci to zatím není příliš důležité, ale pro programy psané ve vyšších programovacích jazycích již ano:
(gdb) info frame Stack level 0, frame at 0x3fffffff160: pc = 0x4000b4 in _start (loop-aarch64.s:44); saved pc 0x0 source language asm. Arglist at 0x3fffffff160, args: Locals at 0x3fffffff160, Previous frame's sp is 0x3fffffff160
Příkaz info registers zobrazí aktuální obsah všech pracovních, adresových a dalších registrů procesoru. Sada registrů je samozřejmě na různých architekturách CPU odlišná, takže následující výsledek platí jen pro AArch64. Povšimněte si, že x31 je zde pojmenován sp:
(gdb) info registers x0 0x0 0 x1 0x0 0 x2 0x0 0 x3 0x0 0 x4 0x0 0 x5 0x0 0 x6 0x0 0 x7 0x0 0 x8 0x0 0 x9 0x0 0 x10 0x0 0 x11 0x0 0 x12 0x0 0 x13 0x0 0 x14 0x0 0 x15 0x0 0 x16 0x0 0 x17 0x0 0 x18 0x0 0 x19 0x0 0 x20 0x0 0 x21 0x0 0 x22 0x0 0 x23 0x0 0 x24 0x0 0 x25 0x0 0 x26 0x0 0 x27 0x0 0 x28 0x0 0 x29 0x0 0 x30 0x0 0 sp 0x3fffffff160 0x3fffffff160 pc 0x4000b0 0x4000b0 <_start> cpsr 0x0 0 fpsr 0x0 0 fpcr 0x0 0
11. Použití příkazu display a print
Příkazem display lze specifikovat výrazy, jejichž výsledek se bude automaticky zobrazovat při krokování. Pokud si budeme chtít nechat zobrazovat hodnoty registrů x1 a x2, stačí napsat:
(gdb) display $x1 (gdb) display $x2
V praxi to může vypadat následovně:
(gdb) n x1 0x4100f8 4260088 x2 0x0 0
Pro ad-hoc zobrazení obsahu registru je možné použít velmi užitečný příkaz print, který ovšem dokáže vypsat i mnohem složitější výrazy (pokud je to nutné). Podívejme se nyní pouze na přepínače formátování – decimální výstup, hexadecimální výstup a zobrazení obsahu registru w3 jako znaku (pokud je to možné):
(gdb) print $w3 $1 = 42 (gdb) print/x $w3 $2 = 0x2a (gdb) print/c $w3 $3 = 42 '*'
12. Použití příkazu examine pro prohlížení obsahu paměti
Příkaz x (examine) byl popsán zde, takže si nyní ukažme jeho možnosti při sledování postupného naplňování bufferu hvězdičkami. Zobrazení s výchozím formátováním není příliš užitečné:
(gdb) x $x1 0x4100fa <buffer+2>: 0x00000000 (gdb) x $x1-2 0x4100f8 <buffer>: 0x00002a2a (gdb) x/b $x1-2
Můžeme přepnout režim zobrazení tak, aby se vypsalo deset bajtů (stále ještě hexadecimálně):
(gdb) x/10b $x1-2 0x4100f8 <buffer>: 0x2a 0x2a 0x00 0x00 0x00 0x00 0x00 0x00 0x410100 <buffer+8>: 0x00 0x00
Vidíme, že za již zapsanými bajty jsou uloženy nuly, takže můžeme buffer považovat za řetězec a použít speciální režim výpisu řetězců:
(gdb) x/bs $x1-2 0x4100f8 <buffer>: "**" (gdb) x/s $x1-2 0x4100f8 <buffer>: "**"
13. Watchpointy
Takzvané watchpointy umožňují automaticky sledovat hodnotu nějaké proměnné či registru a při každé změně vypsat jak původní hodnotu, tak i hodnotu novou (zapisovanou). Použití je snadné a do značné míry se podobá použití příkazu display. Ostatně podívejme se na příklad, v němž sledujeme změnu obsahu pracovního registru x2 (což je počitadlo smyčky):
(gdb) b _start Breakpoint 1 at 0x4000b0: file loop-aarch64.s, line 43. (gdb) r Starting program: work/a.out Breakpoint 1, _start () at loop-aarch64.s:43 43 ldr x1, =buffer // zapis se bude provadet do tohoto bufferu (gdb) watch $x2 Watchpoint 2: $x2 (gdb) n 44 mov x2, #rep_count // pocet opakovani znaku (gdb) n Watchpoint 2: $x2 Old value = 0 New value = 40 _start () at loop-aarch64.s:45 45 mov w3, #'*' // zapisovany znak
Vidíme, že watchpoint skutečně zareaguje až ve chvíli změny registru, na rozdíl od funkce příkazu display.
14. Breakpointy s podmínkou
U breakpointů je možné nastavit podmínku určující, kdy breakpoint skutečně zastaví provádění programu. Taktéž je možné určit, že se několik prvních průchodů breakpointem bude ignorovat. Ukažme se nejprve tuto možnost pro breakpoint nastavený na řádek 46 (smyčka):
(gdb) break 46 Breakpoint 1 at 0x4000c0: file loop-aarch64.s, line 46. (gdb) ignore 1 10 Will ignore next 10 crossings of breakpoint 1.
Při spuštění programu lze snadno zjistit, že se skutečně již nacházíme v desáté iteraci:
(gdb) r Starting program: work/./a.out Breakpoint 1, loop () at loop-aarch64.s:48 48 add x1, x1, #1 // uprava ukazatele do bufferu (gdb) print $x2 $2 = 30
Další možností je nastavení konkrétní podmínky příkazem condition. Podmínky mohou být i dosti složité, mohou obsahovat logické spojky atd:
(gdb) b 48 Breakpoint 1 at 0x4000c0: file loop-aarch64.s, line 48. (gdb) condition 1 $x2<10 (gdb) r Starting program: work/./a.out Breakpoint 1, loop () at loop-aarch64.s:48 48 add x1, x1, #1 // uprava ukazatele do bufferu (gdb) print $x2 $1 = 9
Vidíme, že jsme se skutečně dostali do situace, kdy už platí x2<10.
Další možnost nastavení breakpointu používá jeho definici s podmínkou na jediném řádku:
(gdb) b 48 if $x2<10 Breakpoint 1 at 0x4000c0: file loop-aarch64.s, line 48.
15. Specifikace příkazů vykonaných při vstupu na breakpoint
GNU Debugger umožňuje, aby se při zastavení programu na breakpointu vykonal libovolný uživatelem zvolený příkaz či sekvence příkazů. Pro jejich specifikaci se používá commands následované číslem breakpointu:
(gdb) commands 1 Type commands for breakpoint(s) 1, one per line. End with a line saying just "end". print $x2 end
Zajímavější je následující trik, kdy přímo v sekvenci příkazů použijeme continue, takže se program automaticky rozběhne. Výsledkem je, že breakpoint zde slouží ve funkci logování:
(gdb) b 48 if $x2<10 Breakpoint 1 at 0x4000c0: file loop-aarch64.s, line 48. (gdb) commands Type commands for breakpoint(s) 1, one per line. End with a line saying just "end". print $x2 cont end
Po spuštění se vypíše tato sekvence řádků (samozřejmě kromě řádku prvního):
(gdb) r Starting program: work/./a.out Breakpoint 1, loop () at loop-aarch64.s:48 48 add x1, x1, #1 // uprava ukazatele do bufferu $1 = 9 Breakpoint 1, loop () at loop-aarch64.s:48 48 add x1, x1, #1 // uprava ukazatele do bufferu $2 = 8 Breakpoint 1, loop () at loop-aarch64.s:48 48 add x1, x1, #1 // uprava ukazatele do bufferu $3 = 7 Breakpoint 1, loop () at loop-aarch64.s:48 48 add x1, x1, #1 // uprava ukazatele do bufferu $4 = 6 Breakpoint 1, loop () at loop-aarch64.s:48
Poznámka: zde asi začíná být jasné, že GUI nadstavby nad GNU Debuggerem to mají skutečně složité :-)
16. Vzdálené ladění přes gdbserver
V některých případech může být užitečné použít gdbserver umožňující vzdálené ladění. Program se spustí následovně:
gdbserver :0 ./a.out Process ./a.out created; pid = 27922 Listening on port 38253 Remote debugging from host 127.0.0.1
Ve skutečnosti se program nespustil (spustil se pouze stub), ale čeká na připojení GNU Debuggeru.
GNU Debugger spustíme ve druhém terminálu a jako první příkaz zadáme target remote :port, kde port je získán z předchozího výstupu:
gdb ./a.out Reading symbols from work/a.out...done. (gdb) target remote 38253 38253: No such file or directory. (gdb) target remote :38253 Remote debugging using :38253
Nyní je již možné nastavit breakpointy, tracepointy (pokud jsou podporovány) a provádět krokování, ladění atd. Jakmile se aplikace ukončí, dojde i k odpojení GNU Debuggeru od stubu.
17. TUI – textové uživatelské rozhraní GNU debuggeru
GNU Assembler byl sice původně nástrojem ovládaným čistě z příkazového řádku nebo vzdáleně pomocí síťového protokolu (RSP), ovšem později byl rozšířen o jednoduché textové uživatelské rozhraní (TUI). To se zapíná a konfiguruje příkazem layout:
(gdb) help layout
Change the layout of windows.
Usage: layout prev | next | <layout_name>
Layout names are:
src : Displays source and command windows.
asm : Displays disassembly and command windows.
split : Displays source, disassembly and command windows.
regs : Displays register window. If existing layout
is source/command or assembly/command, the
register window is displayed. If the
source/assembly/command (split) is displayed,
the register window is displayed with
the window that has current logical focus.
V TUI je možné část plochy obrazovky vyhradit pro zobrazení zdrojového kódu, disassemblovaného kódu, registrů atd. Například příkaz layout src rozdělí obrazovku na polovinu, přičemž v horní polovině bude zobrazen laděný zdrojový kód. Podobně příkazem layout regs přidáme další okno s obsahem pracovních registrů. Mezi uspořádáním oken je možné se přepínat pomocí layout prev a layout next. Žádné další složitější operace však podporovány nejsou.
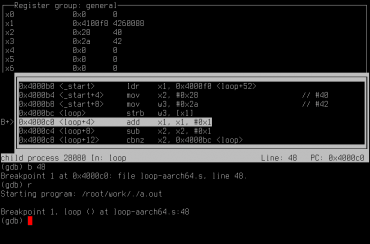
Obrázek 1: GDB s TUI spuštěný s naším demonstračním příkladem.
18. Použití nadstavby nad GNU debuggerem nazvané cgdb
Nástroj nazvaný cgdb, o němž jsem se podrobněji zmínil zde, je založený na knihovně curses resp. ncurses, tudíž ho je možné využít v terminálu, na stroji připojeném přes SSH atd. Ve svém základním nastavení nástroj cgdb rozděluje okno terminálu (konzole) na dvě části. V horní části je zobrazen zdrojový kód laděné aplikace a v části dolní pak rozhraní samotného GNU Debuggeru, které již známe z předchozích kapitol. Mezi oběma částmi je možné se s využitím několika klávesových zkratek přepínat, přičemž je nutné poznamenat, že většinu složitějších příkazů je možné zadávat jen v rozhraní GNU Debuggeru. Horní část slouží zejména pro dobrou orientaci v laděném programu, pro zobrazení nastavených breakpointů (v základním nastavení je použita červená barva) a taktéž pro zobrazení místa, v němž se právě nachází laděný program (v základním nastavení je tento řádek zobrazen zeleně, ale i toto nastavení je samozřejmě možné změnit).
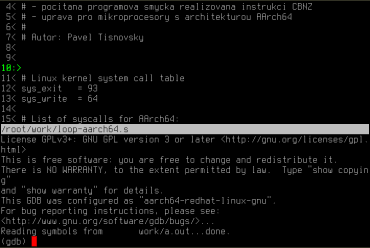
Obrázek 2: Nástroj cgdb spuštěný s naším demonstračním příkladem.
V nástroji cgdb se využívají klávesové zkratky známé především z textových editorů Vi a Vim, ovšem i ti uživatelé, kteří tyto editory nepoužívají (a tudíž dané zkratky neznají), nebudou ztraceni, protože se například ve zdrojovém textu mohou pro přesun kurzoru používat i kurzorové klávesy atd. cgdb obsahuje i vestavěnou nápovědu dostupnou po stisku klávesy F1.

Rozhraní cgdb při práci s našim příkladem vypadá následovně. V horní části vidíme část zdrojového kódu, v části dolní pak rozhraní GNU Debuggeru. Pro přepínání používejte vi-příkazy i a Esc:
4< # - pocitana programova smycka realizovana instrukci CBNZ 5< # - uprava pro mikroprocesory s architekturou AArch64 6< # 7< # Autor: Pavel Tisnovsky 8< 9< 10:> 11< # Linux kernel system call table 12< sys_exit = 93 13< sys_write = 64 14< 15< # List of syscalls for AArch64: /work/loop-aarch64.s License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl. html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copyin g" and "show warranty" for details. This GDB was configured as "aarch64-redhat-linux-gnu". For bug reporting instructions, please see: <http://www.gnu.org/software/gdb/bugs/>... Reading symbols from work/a.out...done. (gdb)
Takto vypadá rozhraní cgdb při ladění. Zdrojový kód se posunuje vždy na to místo, v němž se nachází právě „krokovaná“ instrukce:
39< .section .text 40< .global _start // tento symbol ma byt dostupny 41< 42< _start: 43< ldr x1, =buffer // zapis se bude provadet do to 44< mov x2, #rep_count // pocet opakovani znaku 45:> mov w3, #'*' // zapisovany znak 46< loop: 47< strb w3, [x1] // zapis znaku do bufferu 48< add x1, x1, #1 // uprava ukazatele do bufferu 49< sub x2, x2, #1 // zmenseni pocitadla a soucasn 50< cbnz x2, loop // pokud jsme se nedostali k nu work/loop-aarch64.s Breakpoint 1, _start () at loop-aarch64.s:43 (gdb) watch $x2 Watchpoint 2: $x2 (gdb) n (gdb) n Watchpoint 2: $x2 Old value = 0 New value = 40 _start () at loop-aarch64.s:45
19. Odkazy na Internetu
- Trasování a ladění nativních aplikací v Linuxu
https://www.root.cz/clanky/trasovani-a-ladeni-nativnich-aplikaci-v-linuxu/ - Trasování a ladění nativních aplikací v Linuxu: použití GDB a jeho nadstaveb
https://www.root.cz/clanky/trasovani-a-ladeni-nativnich-aplikaci-v-linuxu-pouziti-gdb-a-jeho-nadstaveb/ - Debuggery a jejich nadstavby v Linuxu (3): Nemiver
http://mojefedora.cz/debuggery-a-jejich-nadstavby-v-linuxu-3-nemiver/ - Debuggery a jejich nadstavby v Linuxu (4): KDbg
http://mojefedora.cz/debuggery-a-jejich-nadstavby-v-linuxu-4-kdbg/ - Debuggery a jejich nadstavby v Linuxu (5): ladění aplikací v editorech Emacs a Vim
http://mojefedora.cz/debuggery-a-jejich-nadstavby-v-linuxu-5-ladeni-aplikaci-v-editorech-emacs-a-vim/ - Tracing (software)
https://en.wikipedia.org/wiki/Tracing_%28software%29 - cgdb: the curses debugger
https://cgdb.github.io/ - cgdb: dokumentace
https://cgdb.github.io/docs/cgdb-split.html - strace(1) – Linux man page
http://linux.die.net/man/1/strace - strace (stránka projektu na SourceForge)
https://sourceforge.net/projects/strace/ - strace (Wikipedia)
https://en.wikipedia.org/wiki/Strace - GDB – Dokumentace
http://sourceware.org/gdb/current/onlinedocs/gdb/ - GDB – Supported Languages
http://sourceware.org/gdb/current/onlinedocs/gdb/Supported-Languages.html#Supported-Languages - GNU Debugger (Wikipedia)
https://en.wikipedia.org/wiki/GNU_Debugger - The LLDB Debugger
http://lldb.llvm.org/ - Debugger (Wikipedia)
https://en.wikipedia.org/wiki/Debugger - Comparison of ARMv8-A cores
https://en.wikipedia.org/wiki/Comparison_of_ARMv8-A_cores - A64 General Instructions
http://www.keil.com/support/man/docs/armclang_asm/armclang_asm_pge1427898258836.htm - ARMv8 (AArch64) Instruction Encoding
http://kitoslab-eng.blogspot.cz/2012/10/armv8-aarch64-instruction-encoding.html - Cortex-A32 Processor
https://www.arm.com/products/processors/cortex-a/cortex-a32-processor.php - Cortex-A35 Processor
https://www.arm.com/products/processors/cortex-a/cortex-a35-processor.php - Cortex-A53 Processor
https://www.arm.com/products/processors/cortex-a/cortex-a53-processor.php - Cortex-A57 Processor
https://www.arm.com/products/processors/cortex-a/cortex-a57-processor.php - Cortex-A72 Processor
https://www.arm.com/products/processors/cortex-a/cortex-a72-processor.php - Cortex-A73 Processor
https://www.arm.com/products/processors/cortex-a/cortex-a73-processor.php - Apple A7 (SoC založen na CPU Cyclone)
https://en.wikipedia.org/wiki/Apple_A7 - System cally pro AArch64 na Linuxu
https://github.com/torvalds/linux/blob/master/include/uapi/asm-generic/unistd.h - Architectures/AArch64 (FedoraProject.org)
https://fedoraproject.org/wiki/Architectures/AArch64 - SIG pro AArch64 (CentOS)
https://wiki.centos.org/SpecialInterestGroup/AltArch/AArch64 - The ARMv8 instruction sets
http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.den0024a/ch05s01.html - A64 Instruction Set
https://developer.arm.com/products/architecture/instruction-sets/a64-instruction-set - Switching between the instruction sets
http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.den0024a/ch05s01.html - The A64 instruction set
http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.den0024a/ch05s01.html - Introduction to ARMv8 64-bit Architecture
https://quequero.org/2014/04/introduction-to-arm-architecture/ - MCU market turns to 32-bits and ARM
http://www.eetimes.com/document.asp?doc_id=1280803 - Cortex-M0 Processor (ARM Holdings)
http://www.arm.com/products/processors/cortex-m/cortex-m0.php - Cortex-M0+ Processor (ARM Holdings)
http://www.arm.com/products/processors/cortex-m/cortex-m0plus.php - ARM Processors in a Mixed Signal World
http://www.eeweb.com/blog/arm/arm-processors-in-a-mixed-signal-world - ARM Architecture (Wikipedia)
https://en.wikipedia.org/wiki/ARM_architecture - DSP for Cortex-M
https://developer.arm.com/technologies/dsp/dsp-for-cortex-m - Cortex-M processors in DSP applications? Why not?!
https://community.arm.com/processors/b/blog/posts/cortex-m-processors-in-dsp-applications-why-not - White Paper – DSP capabilities of Cortex-M4 and Cortex-M7
https://community.arm.com/processors/b/blog/posts/white-paper-dsp-capabilities-of-cortex-m4-and-cortex-m7 - Q (number format)
https://en.wikipedia.org/wiki/Q_%28number_format%29 - TriCore Architecture & Core
http://www.infineon.com/cms/en/product/microcontroller/32-bit-tricore-tm-microcontroller/tricore-tm-architecture-and-core/channel.html?channel=ff80808112ab681d0112ab6b73d40837 - TriCoreTM V1.6 Instruction Set: 32-bit Unified Processor Core
http://www.infineon.com/dgdl/tc_v131_instructionset_v138.pdf?fileId=db3a304412b407950112b409b6dd0352 - TriCore v2.2 C Compiler, Assembler, Linker Reference Manual
http://tasking.com/support/tricore/tc_reference_guide_v2.2.pdf - Infineon TriCore (Wikipedia)
https://en.wikipedia.org/wiki/Infineon_TriCore - C166®S V2 Architecture & Core
http://www.infineon.com/cms/en/product/microcontroller/16-bit-c166-microcontroller/c166-s-v2-architecture-and-core/channel.html?channel=db3a304312bef5660112c3011c7d01ae - Comparing four 32-bit soft processor cores
http://www.eetimes.com/author.asp?section_id=14&doc_id=1286116 - RISC-V Instruction Set
http://riscv.org/download.html#spec_compressed_isa - RISC-V Spike (ISA Simulator)
http://riscv.org/download.html#isa-sim - RISC-V (Wikipedia)
https://en.wikipedia.org/wiki/RISC-V - David Patterson (Wikipedia)
https://en.wikipedia.org/wiki/David_Patterson_(computer_scientist) - OpenRISC (oficiální stránky projektu)
http://openrisc.io/ - OpenRISC architecture
http://openrisc.io/architecture.html - Emulátor OpenRISC CPU v JavaScriptu
http://s-macke.github.io/jor1k/demos/main.html - OpenRISC (Wikipedia)
https://en.wikipedia.org/wiki/OpenRISC - OpenRISC – instrukce
http://sourceware.org/cgen/gen-doc/openrisc-insn.html - OpenRISC – slajdy z přednášky o projektu
https://iis.ee.ethz.ch/~gmichi/asocd/lecturenotes/Lecture6.pdf - Berkeley RISC
http://en.wikipedia.org/wiki/Berkeley_RISC - Great moments in microprocessor history
http://www.ibm.com/developerworks/library/pa-microhist.html - Microprogram-Based Processors
http://research.microsoft.com/en-us/um/people/gbell/Computer_Structures_Principles_and_Examples/csp0167.htm - Great Microprocessors of the Past and Present
http://www.cpushack.com/CPU/cpu1.html - A Brief History of Microprogramming
http://www.cs.clemson.edu/~mark/uprog.html - What is RISC?
http://www-cs-faculty.stanford.edu/~eroberts/courses/soco/projects/2000–01/risc/whatis/ - RISC vs. CISC
http://www-cs-faculty.stanford.edu/~eroberts/courses/soco/projects/2000–01/risc/risccisc/ - RISC and CISC definitions:
http://www.cpushack.com/CPU/cpuAppendA.html - FPGA
https://cs.wikipedia.org/wiki/Programovateln%C3%A9_hradlov%C3%A9_pole - The Evolution of RISC
http://www.ibm.com/developerworks/library/pa-microhist.html#sidebar1

