
Obsah
1. Indexování a fulltextové vyhledávání v dokumentech s využitím nástroje Elasticsearch
2. Lokální instalace nástroje Elasticsearch
3. Instalace pluginu určeného pro indexování příloh (dokumentů) v různých formátech
4. Základní nastavení mapování
5. Přidání dokumentů do fulltextové databáze
6. Vyhledávání dokumentů na základě hledané fráze
7. První vylepšení indexování: uložení metadat dokumentů
8. Vyhledávání v dokumentech se zobrazením základních metadat
9. Druhé vylepšení indexování: uživatelsky definovaná metadata
10. Vyhledávání v dokumentech se zobrazením uživatelských metadat
11. Omezení počtu vyhledaných dokumentů i počtu zobrazených řetězců se zvýrazněním
12. Jednoduché GUI k vyhledávacímu Engine naprogramované v jazyce Clojure
1. Indexování a fulltextové vyhledávání v dokumentech s využitím nástroje Elasticsearch
Mezi jeden z nejznámějších a pravděpodobně i nejrozšířenějších nástrojů určených pro fulltextové vyhledávání patří fulltextový vyhledávač nazvaný Elasticsearch. Ten je, společně s podpůrnými knihovnami a některými pluginy, naprogramovaný kompletně v Javě, což mj. znamená možnost jeho snadné instalace na různých platformách a operačních systémech; vzácností nejsou ani heterogenní clustery složené z různých platforem. Mezi přednosti Elasticsearche patří velmi dobrá škálovatelnost (tou se však dnes nebudeme zabývat), vysoká dostupnost spočívající v automatickém sledování a řízení jednotlivých uzlů v clusteru (taktéž se jedná o téma přesahující rozsah tohoto článku) a v neposlední řadě i vysoká rychlost vyhledávání, která může ty uživatele, kteří jsou zklamáni z výkonu Javy například u některých desktopových aplikací, velmi příjemně překvapit.
Elasticsearch dokáže indexovat čistě textová data, popř. strukturované údaje složené opět z textových dat. To je sice pěkné, ovšem v reálném světě se v mnoha případech setkáme s dokumenty uloženými do formátu PDF, Open/Libre Office, MS Office, s knihami ve formátu Epub a samozřejmě i s dokumenty používajícími značkovací jazyky HTML a XML. I pro indexaci a vyhledávání v takových dokumentech je možné Elasticsearch použít, ovšem je nutné tento nástroj doplnit o vhodný zásuvný modul (plugin), který dokáže se soubory různých typů více či méně úspěšně pracovat a parsovat je. Tento plugin skutečně existuje a jmenuje se mapper-attachment. Interně se pro rozpoznání formátu dokumentů a pro jejich indexaci používá knihovna nazvaná Apache Tika. Na stránce http://tika.apache.org/1.13/formats.html jsou dostupné informace o podporovaných formátech; užitečná je jak podpora formátů používaných v balíčcích „office“, tak i podpora pro zmíněný PDF a Epub.
V dalším textu se ve stručnosti seznámíme s:
- Lokální instalací nástroje Elasticsearch
- Instalací pluginu mapper-attachment
- Konfigurací mapování a indexací dokumentů
- Vyhledávání v dokumentech se zvýrazněním vyhledaných výrazů
- Použitím automaticky zjišťovaných metadat
- Použitím uživatelsky nastavených metadat
- Jednoduchou aplikací s webovým GUI, která komunikuje s Elasticsearchem pomocí RESTful API
Tip: naučte se ELK na našich školeních ELK Stack školení a Kurz ELK stack – instalace a provoz
2. Lokální instalace nástroje Elasticsearch
Lokální instalace Elasticsearche je velmi jednoduchá a vyžaduje vlastně pouze dva kroky. Předpokladem je, že máte v systému JVM alespoň verze 7. Pokud je JVM nainstalována (lze zkontrolovat například přes java -version), postačuje si do pracovního adresáře stáhnout archiv s verzí 2.4.0 a rozbalit ho:
wget https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/zip/elasticsearch/2.4.0/elasticsearch-2.4.0.zip unzip elasticsearch-2.4.0.zip
Můžeme si zkusit Elasticsearch pustit, prozatím bez dat:
cd elasticsearch-2.4.0/bin ./elasticsrach
Na standardní výstup by se měly vypsat přibližně následující zprávy (jen se nelekněte, že jméno vlákna je zvoleno náhodně):
[2016-09-25 21:30:56,815][INFO ][node ] [Alexander Goodwin Pierce] version[2.4.0], pid[4826], build[ce9f0c7/2016-08-29T09:14:17Z]
[2016-09-25 21:30:56,816][INFO ][node ] [Alexander Goodwin Pierce] initializing ...
[2016-09-25 21:30:57,393][INFO ][plugins ] [Alexander Goodwin Pierce] modules [lang-groovy, reindex, lang-expression], plugins [], sites []
[2016-09-25 21:30:57,443][INFO ][env ] [Alexander Goodwin Pierce] using [1] data paths, mounts [[/ (/dev/sda1)]], net usable_space [98.5gb], net total_space [113.5gb], spins? [no], types [ext4]
[2016-09-25 21:30:57,443][INFO ][env ] [Alexander Goodwin Pierce] heap size [990.7mb], compressed ordinary object pointers [true]
[2016-09-25 21:30:57,443][WARN ][env ] [Alexander Goodwin Pierce] max file descriptors [4096] for elasticsearch process likely too low, consider increasing to at least [65536]
[2016-09-25 21:30:59,367][INFO ][node ] [Alexander Goodwin Pierce] initialized
[2016-09-25 21:30:59,367][INFO ][node ] [Alexander Goodwin Pierce] starting ...
[2016-09-25 21:30:59,441][INFO ][transport ] [Alexander Goodwin Pierce] publish_address {127.0.0.1:9300}, bound_addresses {127.0.0.1:9300}, {[::1]:9300}
[2016-09-25 21:30:59,446][INFO ][discovery ] [Alexander Goodwin Pierce] elasticsearch/uQfXGZ70QNah5K387Oqu-g
[2016-09-25 21:31:02,522][INFO ][cluster.service ] [Alexander Goodwin Pierce] new_master {Alexander Goodwin Pierce}{uQfXGZ70QNah5K387Oqu-g}{127.0.0.1}{127.0.0.1:9300}, reason: zen-disco-join(elected_as_master, [0] joins received)
[2016-09-25 21:31:02,538][INFO ][http ] [Alexander Goodwin Pierce] publish_address {127.0.0.1:9200}, bound_addresses {127.0.0.1:9200}, {[::1]:9200}
[2016-09-25 21:31:02,538][INFO ][node ] [Alexander Goodwin Pierce] started
[2016-09-25 21:31:02,579][INFO ][gateway ] [Alexander Goodwin Pierce] recovered [0] indices into cluster_state
Ve zprávách je mj. uvedeno, že na URL 127.0.0.1:9200 nebo též localhost:9200 je možné s Elasticsearchem komunikovat přes RESTful API. Ostatně můžeme si to vyzkoušet:
$ curl localhost:9200
{
"name" : "Alexander Goodwin Pierce",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "2.4.0",
"build_hash" : "ce9f0c7394dee074091dd1bc4e9469251181fc55",
"build_timestamp" : "2016-08-29T09:14:17Z",
"build_snapshot" : false,
"lucene_version" : "5.5.2"
},
"tagline" : "You Know, for Search"
}
Poznámka: opět platí, že jméno (zde „Alexander Goodwin Pierce“) se s velkou pravděpodobností bude na vašem počítači lišit.
3. Instalace pluginu určeného pro indexování příloh (dokumentů) v různých formátech
Druhým důležitým krokem je instalace pluginu, který se bude starat o parsování a indexování dokumentů uložených v různých formátech. Nejprve pro jistotu běžící Elasticsearch ukončíme (Ctrl+C) a nainstalujeme plugin k tomu připraveným skriptem:
cd elasticsearch-2.4.0/bin ./plugin install mapper-attachments
Po chvíli by se měla zobrazit zpráva o úspěšné (doufejme!) instalaci pluginu. Pokud se nyní pokusíme Elasticsearch znovu spustit, objeví se ve zprávách nový řádek, který je v následujícím výpisu zvýrazněn:
./elasticsrach
[2016-09-26 20:17:39,804][INFO ][node ] [Anti-Phoenix Force] version[2.4.0], pid[9150], build[ce9f0c7/2016-08-29T09:14:17Z]
[2016-09-26 20:17:39,804][INFO ][node ] [Anti-Phoenix Force] initializing ...
[2016-09-26 20:17:40,572][INFO ][plugins ] [Anti-Phoenix Force] modules [lang-groovy, reindex, lang-expression], plugins [mapper-attachments], sites []
[2016-09-26 20:17:40,604][INFO ][env ] [Anti-Phoenix Force] using [1] data paths, mounts [[/ (/dev/sda1)]], net usable_space [98.5gb], net total_space [113.5gb], spins? [no], types [ext4]
[2016-09-26 20:17:40,604][INFO ][env ] [Anti-Phoenix Force] heap size [990.7mb], compressed ordinary object pointers [true]
[2016-09-26 20:17:40,605][WARN ][env ] [Anti-Phoenix Force] max file descriptors [4096] for elasticsearch process likely too low, consider increasing to at least [65536]
[2016-09-26 20:17:42,479][INFO ][node ] [Anti-Phoenix Force] initialized
[2016-09-26 20:17:42,479][INFO ][node ] [Anti-Phoenix Force] starting ...
[2016-09-26 20:17:42,540][INFO ][transport ] [Anti-Phoenix Force] publish_address {127.0.0.1:9300}, bound_addresses {127.0.0.1:9300}, {[::1]:9300}
[2016-09-26 20:17:42,546][INFO ][discovery ] [Anti-Phoenix Force] elasticsearch/rcWn1VueQpaPlnGDpCO8xg
[2016-09-26 20:17:45,606][INFO ][cluster.service ] [Anti-Phoenix Force] new_master {Anti-Phoenix Force}{rcWn1VueQpaPlnGDpCO8xg}{127.0.0.1}{127.0.0.1:9300}, reason: zen-disco-join(elected_as_master, [0] joins received)
[2016-09-26 20:17:45,622][INFO ][http ] [Anti-Phoenix Force] publish_address {127.0.0.1:9200}, bound_addresses {127.0.0.1:9200}, {[::1]:9200}
[2016-09-26 20:17:45,622][INFO ][node ] [Anti-Phoenix Force] started
[2016-09-26 20:17:45,768][INFO ][gateway ] [Anti-Phoenix Force] recovered [0] indices into cluster_state
Poznámka: pokud se zvýrazněný řádek neobjeví, nebudou dále popisované příklady fungovat a je nutné zjistit, proč instalace selhala. Zejména u starších verzí Elasticsearchu se to v některých případech stávalo, takže je kontrola důležitá.
4. Základní nastavení mapování
Před vlastním parsováním a indexací dokumentů je nutné Elasticsearch nakonfigurovat a nastavit mapování. Veškerá komunikace s Elasticsearchem probíhá přes RESTful API, což mj. znamená, že si vystačíme s nástrojem curl. Existují sice i nadstavby pro webové prohlížeče či integrovaná vývojová prostředí, které mohou práci s RESTful API zjednodušit, nicméně prozatím si skutečně vystačíme s velmi flexibilní příkazovou řádkou. Nastavení mapování provedeme následujícím způsobem:
curl -XPUT "localhost:9200/docs/" curl -XPUT "localhost:9200/docs/document/_mapping" -d @create_mapping.json
Poznámka: zkontrolujte, zda Elasticsearch odpověděl stylem {acknowledged a nikoli chybovým hlášením.
Druhé volání REST API do Elasticsearche přenáší obsah JSON souboru nazvaného create_mapping.json. V tomto souboru je definováno, že se mají indexovat přílohy (zpracovávané pluginem mapper-attachment) a při indexování se má interně vytvořit datová struktura umožňující rychlé hledání slov a sousloví v parsovaných dokumentech:
{
"document" : {
"properties" : {
"file" : {
"type" : "attachment",
"fields" : {
"content" : { "type":"string","term_vector":"with_positions_offsets", "store":"yes" }
}
}
}
}
}
Interně se zpracovávané soubory nejdříve převedou do textové podoby:

A následně se pro jednotlivá slova vytvoří (přibližně) následující struktura, která je interně uložena efektivním způsobem umožňujícím rychlé vyhledávání a současně i poměrně malé nároky na diskový prostor:

Více informací se můžete v případě zájmu dozvědět na http://blog.jpountz.net/post/41301889664/putting-term-vectors-on-a-diet, pro samotné provozování Elasticsearche to však není nutné.
5. Přidání dokumentů do fulltextové databáze
Nyní nastává důležitý okamžik – začneme do fulltextové databáze přidávat dokumenty. Ty se musí přenášet přes RESTful API ve formátu JSON. To zdánlivě představuje problém, protože například PDF je binární formát, který může obsahovat všechny znaky (včetně znaku pro konec souboru, konec řetězce apod.). Aby se předešlo zmatkům, vyžaduje plugin mapper-attachment, aby se obsah všech souborů před přenosem zakódoval s použitím Base64. Předností je, že při použití Base64 se binární data převedou na sekvenci znaků A-Z, a-z, 0–9, + a / (navíc ještě =), takže se zde nevyskytují žádné potenciálně problematické znaky, které by mohly způsobit chybu při zpracování JSONu na straně Elasticsearche. Pro zjednodušení přidávání souborů do databáze lze použít následující skript nazvaný add_file.sh:
#!/bin/sh
coded=`cat $1 | perl -MMIME::Base64 -ne 'print encode_base64($_)'`
json="{\"file\":\"${coded}\"}"
echo "$json" > file.json
curl -X POST "localhost:9200/docs/document/" -d @file.json
Příklad použití:
./add_file.sh index.html ./add_file.sh TopSecret.odt ./add_file.sh InstallationGuide.pdf
Poznámka: skript na disku ponechá soubor file.json určený pro studijní účely.
6. Vyhledávání dokumentů na základě hledané fráze
I vyhledávání v dokumentech je zabezpečeno přes RESTful API, přičemž specifikace, co a jak se má vyhledat, je přenesena v JSON:
#!/bin/sh curl -XGET "http://localhost:9200/_search?pretty" -d @search.json
V souboru search.json je (pro testovací účely) ukázáno, jak hledat například slovo „network“:
{
"fields" : [],
"query" : {
"match" : {
"file.content" : "network"
}
},
"highlight" : {
"fields" : {
"file.content" : {}
}
}
}
Elasticsearch odpoví – jak jinak – taktéž strukturou reprezentovanou v JSONu:
{
"took" : 39,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.0817802,
"hits" : [ {
"_index" : "docs",
"_type" : "document",
"_id" : "AVdnaVFvU0d6k-GWgQp5",
"_score" : 0.0817802,
"highlight" : {
"file.content" : [
"configuration and administration of <em>network</em> interfaces, networks and <em>network</em> services in Red Hat Enterprise",
"NetworkManager\n\n\n\t1.5. <em>Network</em> Configuration Using a Text User Interface (nmtui)\n\t1.6. <em>Network</em> Configuration Using",
"Using NetworkManager's CLI (nmcli)\n\t1.7. <em>Network</em> Configuration Using the Command-Line Interface (CLI)",
"(CLI)\n\t1.8. NetworkManager and the <em>Network</em> Scripts\n\t1.9. <em>Network</em> Configuration Using sysconfig Files\n\t1.10",
"Interface Settings\n\t\t2.1.1. When to Use Static <em>Network</em> Interface Settings\n\t2.1.2. When to Use Dynamic" ]
}
}
}
Povšimněte si, že se vrátily jak informace o průběhu vyhledávání (čas v milisekundách atd.), tak i část indexovaného dokumentu, v němž je nalezený řetězec zvýrazněn značkou <em> (to lze ovšem změnit). Taktéž si všimněte, že se nalezlo celkem pět bloků v dokumentu s výskytem hledaného slova, takže pod klíčem file.content je uloženo pole, jehož obsah jsem pro jistotu zdůraznil přidáním konců řádků za jednotlivé řetězce (ty Elasticsearch kupodivu sám nepřidává).
7. První vylepšení indexování: uložení metadat dokumentů
K indexovaným dokumentům může plugin mapper-attachment přidat i některá automaticky zjištěná metadata, například typ souboru, délku dat, titulek (nemusí být dostupný vždy) či datum vytvoření (opět závisí na typu dokumentu). Pojďme si to vyzkoušet. Nejprve vytvoříme a nakonfigurujeme nové mapování. Povšimněte si použití docs2, aby nedošlo k chybovému hlášení, že mapování pro docs již existuje:
curl -XPUT "localhost:9200/docs2/" curl -XPUT "localhost:9200/docs2/document/_mapping" -d @create_mapping2.json
Tentokrát je již soubor create_mapping2.json nepatrně složitější, protože v něm specifikujeme další atributy, které se mají ukládat do databáze:
{
"document" : {
"properties" : {
"file" : {
"type" : "attachment",
"fields" : {
"title" : {"store" : "yes" },
"date" : {"store" : "yes" },
"content" : {"type":"string","term_vector":"with_positions_offsets", "store":"yes" },
"content_type" : {"store" : "yes"},
"content_length" : {"store" : "yes"},
"language" : {"store" : "yes"}
}
}
}
}
}
Poznámka: většinou se při konfiguraci lze spolehnout na úzus, že hodnota „yes“ je totožná s hodnotou „true“.
8. Vyhledávání v dokumentech se zobrazením základních metadat
Pomocný skript add_file.sh si upravte, aby používal odlišné URL a následně zkuste do databáze přidat další dokumenty:
#!/bin/sh
coded=`cat $1 | perl -MMIME::Base64 -ne 'print encode_base64($_)'`
json="{\"file\":\"${coded}\"}"
echo "$json" > file.json
curl -X POST "localhost:9200/docs2/document/" -d @file.json
I skript pro vyhledání je zapotřebí nepatrně upravit:
#!/bin/sh curl -XGET "http://localhost:9200/docs2/_search?pretty" -d @search2.json
Po těchto úpravách je možné při vyhledávání požadovat, aby se kromě vlastního textu s nalezenými slovy vrátily i metainformace o dokumentu, tj. konkrétně titulek, datum vytvoření/modifikace, délka a typ původního souboru:
{
"fields" : ["file.content_type", "file.title", "file.date", "file.content_length"],
"query" : {
"match" : {
"file.content" : "network"
}
},
"highlight" : {
"fields" : {
"file.content" : {}
}
}
}
V praxi může výsledek vyhledávání vypadat například takto:
{
"took" : 17,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.011244276,
"hits" : [ {
"_index" : "docs2",
"_type" : "document",
"_id" : "AVdnbbR-42uB_K-xw_ex",
"_score" : 0.011244276,
"fields" : {
"file.content_length" : [ "391905" ],
"file.content_type" : [ "application/xhtml+xml; charset=UTF-8" ],
"file.title" : [ "Fedora 22 Release Notes" ]
},
"highlight" : {
"file.content" : [
"Hardware Enablement. \n\n\t\t\t\n\n\t\n\t\t\t\tController Area Network (CAN) device drivers are now supported, see Chapter 12",
"possible to read information about the system network interfaces from the operating system. It has been",
"discovery to find the nearest servers, and to use the network in an optimized way. As a result, administrators",
"certificate can be used. For example, a Virtual Private Network (VPN) server can be configured to only accept certificates",
"option -p for the arpwatch command of the arpwatch network monitoring tool. This option disables promiscuous" ]
}
} ]
}
}
Povšimněte si, že u souborů HTML nebylo možné zjistit datum vytvoření. Například u PDF souborů je to však možné:
{
"took" : 19,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.028263604,
"hits" : [ {
"_index" : "docs2",
"_type" : "document",
"_id" : "AVdoKXkSdBFvurTfS8dM",
"_score" : 0.028263604,
"fields" : {
"file.content_length" : [ "958776" ],
"file.content_type" : [ "application/pdf" ],
"file.date" : [ "2013-09-16T15:55:06Z" ],
"file.title" : [ "VideoCore® IV 3D Architecture Reference Guide" ]
},
"highlight" : {
"file.content" : [ "to je ted nezajimave :-)" ]
}
} ]
}
}
9. Druhé vylepšení indexování: uživatelsky definovaná metadata
Kromě automaticky zjišťovaných metadat je samozřejmě možné k dokumentům přidat i uživatelská metadata. Opět si to vyzkoušejme; nejdříve však nakonfigurujeme další (už poslední) mapování:
curl -XPUT "localhost:9200/docs3/" curl -XPUT "localhost:9200/docs3/document/_mapping" -d @create_mapping2.json
Nyní můžeme u každého dokumentu specifikovat produkt, verzi produktu a URL s výsledným dokumentem (samozřejmě si můžete definovat vlastní metadata, například zda už byl dokument nahrán do čtečky, zda ho už indexuje taktéž NSA atd. atd.). K touto účelu postačuje nepatrně rozšířit JSON strukturu předávanou přes RESTful API při parsování a indexování dokumentu. Upravíme si tedy soubor add_file.sh, aby akceptoval čtyři parametry: jméno souboru, jméno produktu, jeho verzi a URL:
#!/bin/sh
coded=`cat $1 | perl -MMIME::Base64 -ne 'print encode_base64($_)'`
json="{\"product\":\"$2\",\"version\":\"$3\",\"url\":\"$4\",\"file\":\"${coded}\"}"
echo "$json" > file.json
curl -X POST "localhost:9200/docs3/document/" -d @file.json
Příklad použití:
./add_file.sh InstallationGuide.pdf "Fedora" "23" "https://docs.fedoraproject.org/en-US/Fedora/23/pdf/Installation_Guide/Fedora-23-Installation_Guide-en-US.pdf"
Poznámka: zajisté jste si všimli, že může dojít k problémům ve chvíli, kdy například název produktu obsahuje nějaké znaky, které by mohly způsobit chybu při zpracování JSONu. Úpravu skriptu ponechám na váženém čtenáři (není to nic složitého).
10. Vyhledávání v dokumentech se zobrazením uživatelských metadat
Opět je možné rozšířit možnosti vyhledávání o zobrazení nových metadat (produktu, jeho verze a URL):
#!/bin/sh curl -XGET "http://localhost:9200/docs2/_search?pretty" -d @search3.json
Jména atributů s metadaty se jednoduše přidají do pole dostupné pod klíčem fields:
{
"fields" : ["product", "version", "url", "file.content_type", "file.title", "file.date", "file.content_length"],
"query" : {
"match" : {
"file.content" : "network"
}
},
"highlight" : {
"fields" : {
"file.content" : {}
}
}
}
Výsledek může vypadat takto:
{
"took" : 26,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 0.042208605,
"hits" : [ {
"_index" : "docs3",
"_type" : "document",
"_id" : "AVdneznq42uB_K-xw_e_",
"_score" : 0.042208605,
"fields" : {
"product" : [ "Fedora" ],
"file.content_length" : [ "903404" ],
"file.content_type" : [ "application/xhtml+xml; charset=UTF-8" ],
"url" : [ "http://root.cz" ],
"version" : [ "22" ],
"file.title" : [ "Installation Guide" ]
},
"highlight" : {
"file.content" : [ "ted nezajimave" ]
}
} ]
}
}
Poznámka: metadata jsou vrácena ve formě polí! Proto pozor na způsob jejich přečtení.
11. Omezení počtu vyhledaných dokumentů i počtu zobrazených řetězců se zvýrazněním
Elasticsearch taktéž umožňuje omezení počtu vyhledávaných dokumentů. To lze zajistit atributem size, který je možné kombinovat s atributem from (tento druhý atribut je však možné vynechat). Příkladem z praxe může být (mezi uživateli nepříliš oblíbené) rozdělení výsledků do více stránek, mezi kterými se lze přepínat. Dále je možné omezit i počet řetězců nalezených v jednom dokumentu. Pozor: nejedná se o počet celkově nalezených slov či sousloví, protože pokud je slovo/sousloví umístěno například v jedné větě několikrát, je to stále považováno za jeden nález (například když budete v anglických dokumentech hledat slovo „the“). Ukažme si použití obou omezení v praxi:
#!/bin/sh curl -XGET "http://localhost:9200/docs2/_search?pretty" -d @search4.json
{
"size" : 1,
"fields" : ["product", "version", "url", "file.content_type", "file.title", "file.date", "file.content_length"],
"query" : {
"match" : {
"file.content" : "network"
}
},
"highlight" : {
"fields" : {
"file.content" : {"number_of_fragments":5}
}
}
}
Počet dokumentů byl omezen na jeden, počet tzv. fragmentů na pět.
12. Jednoduché GUI k vyhledávacímu Engine naprogramované v jazyce Clojure
Popis základní instalace jednoho uzlu Elasticsearche a jeho konfigurace pro fulltextové vyhledávání tedy máme za sebou, takže se pro ukázku komunikace aplikace s Elasticsearchem přes RESTful API podívejme na velmi jednoduchou webovou aplikaci naprogramovanou v Clojure. Jedná se o aplikaci postavenou nad knihovnami clojure-ring a hiccup, s nimiž jsme se seznámili v seriálu o programovacím jazyku Clojure. V aplikaci lze zadat vyhledávanou frázi, limit na počet vrácených dokumentů i limit na počet bloků s vyhledanou frází. Veškerá kontrola zadaných dat je provedena jen na straně serveru, přidání JS (nebo přenos celé aplikace například do Angularu) není příliš složité.
Struktura projektu vygenerovaná nástrojem Leiningen je následující:
.
├── doc
│ └── intro.md
├── LICENSE
├── project.clj
├── README.md
├── resources
├── src
│ └── es
│ ├── core.clj
│ └── server.clj
└── test
└── es
└── core_test.clj
Důležité jsou jen soubory project.clj, src/es/core.clj a src/es/server.clj.
project.clj
V tomto souboru je důležitá především specifikace všech použitých knihoven:
(defproject es "0.1.0-SNAPSHOT"
:description "FIXME: write description"
:url "http://example.com/FIXME"
:license {:name "Eclipse Public License"
:url "http://www.eclipse.org/legal/epl-v10.html"}
:dependencies [[org.clojure/clojure "1.6.0"]
[org.clojure/data.json "0.2.5"]
[org.clojure/tools.cli "0.3.1"]
[ring/ring-core "1.3.2"]
[ring/ring-jetty-adapter "1.3.2"]
[clj-http "2.0.0"]
[hiccup "1.0.4"]]
:dev-dependencies [[lein-ring "0.8.10"]]
:plugins [[lein-ring "0.8.10"]]
:ring {:handler es.core/app}
:main ^:skip-aot es.core
:target-path "target/%s"
:profiles {:uberjar {:aot :all}})
core.clj
V souboru core.clj je umístěn programový kód, který aplikaci spustí jako webový server na zadaném portu. Pokud port není zadán, použije se výchozí hodnota 3000:
(ns es.core)
(require '[ring.adapter.jetty :as jetty])
(require '[clojure.tools.cli :as cli])
(require '[ring.middleware.params :as http-params])
(require '[ring.middleware.session :as http-session])
(require '[es.server :as server])
(def default-port
"3000")
(def cli-options
"Definitions of all command line options currenty supported."
[["-p" "--port PORT" "port number" :id :port]])
(def app
"Definition of a Ring-based application behaviour."
(-> server/handler ; handle all events
http-session/wrap-session ; we need to work with HTTP sessions
http-params/wrap-params)) ; and to process request parameters, of course
(defn start-server
"Start the HTTP server on the specified port."
[port]
(println "Starting the server at the port: " port)
(jetty/run-jetty app {:port (read-string port)}))
(defn get-port
"Returns specified port or default port if none is specified on the command line."
[specified-port]
(if (or (not specified-port) (not (string? specified-port)) (empty? specified-port))
default-port
specified-port))
(defn -main
"Entry point to the Jenkins dashboard."
[& args]
; Load configuration from the provided INI file
(let [all-options (cli/parse-opts args cli-options)
options (all-options :options)
port (options :port)]
(start-server (get-port port))))
server.clj
Nejdůležitější část aplikace, která na základě uživatelem zadaných dat (do dynamicky generované webové stránky) vytvoří strukturu JSON, tu předá do Elasticsearche a zpracuje výsledek (tedy další JSON). Pro komunikaci se používá knihovna http-client, obousměrnou transformaci dat Clojure-JSON zajišťuje knihovna clojure.data.json:
(ns es.server)
(require 'clojure.string)
(require '[hiccup.core :as hiccup])
(require '[hiccup.page :as page])
(require '[hiccup.form :as form])
(require '[clj-http.client :as http-client])
(require '[ring.util.response :as http-response])
(require '[clojure.data.json :as json])
(def default-fulltext-limit
10)
(def default-highlighted-lines
10)
(def search-url
"http://localhost:9200/docs3")
(defn render-highlight
"Converts output from ElasticSearch into HTML"
[highlight]
(-> (reduce #(str %1 "<hr/>" %2) highlight)
(.replaceAll "\n" "<br>")
(.replaceAll "\t" "")))
(defn render-search-page
[text-to-search search-results limit highlight]
(page/xhtml
[:head
[:title "Elastic Search GUI"]
[:meta {:name "Generator" :content "Clojure"}]
[:meta {:http-equiv "Content-type" :content "text/html; charset=utf-8"}]
]
[:body
[:div
(form/form-to [:get "/"]
[:h2 "Fulltext search"]
[:table
[:tr
[:td (form/text-field {:size "50" :class "-form-control" :id "text_to_search" :value text-to-search} "text_to_search") " "]
[:td (form/submit-button {:class "btn btn-primary" :id "submit"} "Search")]
[:td "Limit max " (form/text-field {:size "5" :value limit} "limit") " guide(s)"]
[:td "Highlight " (form/text-field {:size "5" :value highlight} "highlight") " part(s)"]
]
])
(if search-results
[:table
[:tr
[:td "Finished in:"]
[:td (:took search-results) "ms"]
[:td " "]
]
[:tr
[:td "Found:"]
[:td (:total (:hits search-results)) " guides"]
[:td {:colspan "4"} " "]
]
[:tr
[:td {:colspan "6"} " "]
]
[:tr
[:th "Score"]
[:th "Product"]
[:th "Guide"]
[:th "Date"]
[:th "Type"]
[:th "Size"]
]
(for [hit (:hits (:hits search-results))]
[:tpart
[:tr [:td (-> hit :_score)]
[:td (-> hit :fields :product first)]
[:td [:a {:href (-> hit :fields :url first)} (-> hit :fields :file.title first)]]
[:td (-> hit :fields :file.date first)]
[:td (-> hit :fields :file.content_type first)]
[:td (-> hit :fields :file.content_length first)]
]
[:tr
[:td {:colspan "6"} (render-highlight (-> hit :highlight :file.content))]
]
[:tr
[:td {:colspan "6"} " "]
]
])
])]]))
(defn post-method-to-call-elastic-search
[url postdata]
(println url)
(try
(http-client/post url {
:body postdata
:content-type "application/json"})
(catch Exception e
(.printStackTrace e))))
(defn fulltext-search-json
[text-to-search limit highlight-items]
{
:fields ["title" "url" "product" "name" "file.title" "file.content_type" "file.date" "file.content_length"]
:size limit
:query {
:match {
:file.content text-to-search
}
}
:highlight {
:fields {
:file.content {:number_of_fragments highlight-items}
}
}
})
(defn fulltext-search
[text-to-search limit highlight-items]
(if (and text-to-search (not (empty? (clojure.string/trim text-to-search))))
(let [search-json (json/write-str (fulltext-search-json text-to-search limit highlight-items))
response (post-method-to-call-elastic-search (str search-url "/_search?pretty") search-json)]
(if (and response (:body response))
(json/read-str (:body response) :key-fn keyword)))))
(defn parse-int-parameter
"Try to parse parameter into integer, nil is returned in case of any error."
[params param-name]
(try
(Integer/parseInt (get params param-name))
(catch Exception e
nil)))
(defn handler
"Handler for all HTTP requests."
[request]
(println "request URI: " (request :uri))
(let [uri (:uri request)
params (:params request)
text-to-search (get params "text_to_search")
limit (or (parse-int-parameter params "limit") default-fulltext-limit)
highlight (or (parse-int-parameter params "highlight") default-highlighted-lines)
search-results (fulltext-search text-to-search limit highlight)
page-content (render-search-page text-to-search search-results limit highlight)]
(-> (http-response/response page-content)
(http-response/content-type "text/html; charset=utf-8"))))
13. Spuštění a použití GUI
Aplikace (přesněji webový server) se spustí příkazem:

lein run
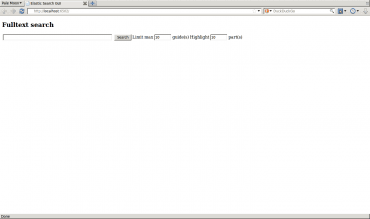
Obrázek 1: rozhraní aplikace po spuštění.
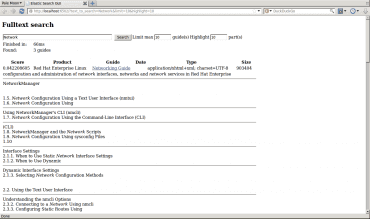
Obrázek 2: výsledek vyhledání.
14. Odkazy na Internetu
- Elasticsearch home page
https://www.elastic.co/products/elasticsearch - elasticsearch-mapper-attachments (GitHub)
https://github.com/elastic/elasticsearch-mapper-attachments - Elasticsearch (EN Wikipedia)
https://en.wikipedia.org/wiki/Elasticsearch - Elasticsearch (CZ Wikipedia)
https://cs.wikipedia.org/wiki/Elasticsearch - Apache Lucene home page
https://lucene.apache.org/ - Apache Lucene Core
https://lucene.apache.org/core/ - Apache Tika home page
http://tika.apache.org/ - Apache Tika: Supported Document Formats
http://tika.apache.org/1.13/formats.html - Apache Tika (Wikipedia)
https://en.wikipedia.org/wiki/Apache_Tika - Leiningen: nástroj pro správu projektů napsaných v Clojure
http://www.root.cz/clanky/leiningen-nastroj-pro-spravu-projektu-napsanych-v-clojure/ - Leiningen: nástroj pro správu projektů napsaných v Clojure (2)
http://www.root.cz/clanky/leiningen-nastroj-pro-spravu-projektu-napsanych-v-clojure-2/ - Leiningen: nástroj pro správu projektů napsaných v Clojure (3)
http://www.root.cz/clanky/leiningen-nastroj-pro-spravu-projektu-napsanych-v-clojure-3/ - Leiningen: nástroj pro správu projektů napsaných v Clojure (4)
http://www.root.cz/clanky/leiningen-nastroj-pro-spravu-projektu-napsanych-v-clojure-4/ - Leiningen: nástroj pro správu projektů napsaných v Clojure (5)
http://www.root.cz/clanky/leiningen-nastroj-pro-spravu-projektu-napsanych-v-clojure-5/ - Leiningen: nástroj pro správu projektů napsaných v Clojure (6)
http://www.root.cz/clanky/leiningen-nastroj-pro-spravu-projektu-napsanych-v-clojure-6/ - Clojure home page
http://clojure.org/ - Clojure (downloads)
http://clojure.org/downloads - Clojure – Functional Programming for the JVM
http://java.ociweb.com/mark/clojure/article.html - Clojure quick reference
http://faustus.webatu.com/clj-quick-ref.html - Putting term vectors on a diet
http://blog.jpountz.net/post/41301889664/putting-term-vectors-on-a-diet - What is REST API
http://restfulapi.net/























