Obsah
1. Instrukce typu SIMD na mikroprocesorech RISC
2. Implementace instrukcí SIMD na mikroprocesorech RISC
3. Malé historické porovnání: SIMD na RISC vs. CISC
4. SIMD instrukce na RISCových mikroprocesorech řady MIPS
5. Rozšiřující instrukční sada MDMX (MaDMaX)
6. Nové operace implementované v instrukční sadě MDMX
7. Problémy provázející operaci multiply & accumulate (MAC)
8. Operace prováděné se „širokým akumulátorem“
1. Instrukce typu SIMD na mikroprocesorech RISC
V předchozích třech částech seriálu o architekturách počítačů jsme se zabývali popisem rozšiřujících instrukčních sad obsahujících SIMD instrukce, tj. instrukce určené pro provádění operací nad vektory konstantní délky. Zaměřili jsme se pouze na platformu x86, na níž byla technologie SIMD instrukcí poprvé implementována na mikroprocesorech Pentium P55C v roce 1996 (další čipy s technologií SIMD začaly být prodávány hned následující rok). Jednalo se o instrukční sadu nazvanou MMX, která byla později následována instrukční sadou 3DNow! a později též sadami SSE, SSE2, SSE4 atd. Ovšem SIMD instrukce samozřejmě nejsou používány pouze na platformě x86, ale můžeme se s nimi setkat i na mnoha typech procesorů RISC. Ve skutečnosti se dokonce tento typ instrukcí poprvé objevil právě na mikroprocesorech RISC a teprve se zhruba dvouletým zpožděním byl převzat i na původně čistě CISCovou architekturu x86 (ostatně se zdaleka nejedná o první ani o poslední technologii, která byla na x86 převzata právě z RISCových procesorů).

Obrázek 1: Superpočítač Cray-1 byl jedním ze superpočítačů s velmi dobrou podporou vektorových operací, ať se to týkalo instrukční sady, tak i podpory v překladači Fortranu.
Důvodů, proč se instrukce typu SIMD na RISCových procesorech vůbec objevily, je větší množství. Jedním z nich je to, že se tyto procesory začaly používat v grafických pracovních stanicích, mj. i pro zpracování videa, provádění rastrových operací i 3D operací, což je přesně ta oblast, v níž je možné informace zpracovávat nikoli jen ve formě skalárních dat, ale i jako vektory pevné délky. Dalším důvodem byla snaha výrobců RISCových procesorů o průnik na trh s počítači určenými pro náročné výpočty (jedná se o určitý mezistupeň mezi výkonnými pracovními stanicemi a superpočítači). V tomto oboru se mnoho algoritmů provádí nad maticemi a vektory obsahujícími numerické hodnoty reprezentované v systému plovoucí řádové čárky (FP: Floating Point). Třetím důvodem je samozřejmě snaha o zvýšení výpočetního výkonu a právě SIMD instrukce k němu mohou vést, aniž by bylo nutné radikálně měnit používanou výrobní technologii čipů (zvyšovat úroveň integrace, snižovat napěťové úrovně či zvyšovat frekvenci, popř. přidávat vyrovnávací paměti/cache).

Obrázek 2: Superpočítač CDC 7600 je předchůdcem superpočítačů Cray.
2. Implementace instrukcí SIMD na mikroprocesorech RISC
Prakticky každá významnější společnost (v případě PowerPC pak dokonce aliance) navrhující mikroprocesory s architekturou RISC přišla dříve či později na trh s instrukční sadou obsahující „vektorové“ instrukce, které jsou dnes souhrnně označovány zkratkou SIMD (původní vektorové instrukce používané na superpočítačích jsou v některých ohledech flexibilnější, proto budeme používat spíše zkratku SIMD). Rozšiřující instrukční sady byly pojmenovávány nejrůznějšími názvy a zkratkami a nikdy vlastně nedošlo – na rozdíl od platformy x86 – ke sjednocení těchto instrukcí do jediné skupiny „SIMD pro RISC“, což je vlastně logické, protože procesory RISC jsou mnohdy určeny pro specializované oblasti použití, od vestavných (embedded) systémů přes smartphony a tablety až po superpočítače.

Obrázek 3: Mikroprocesor HP PA-RISC 7300LC (PA=Precision Architecture). Jedná se moderní variantu procesorů RISC se zabudovaným matematickým koprocesorem a sadou 32bitových celočíselných registrů a taktéž 64bitových registrů pro FPU operace.
Zdroj: Wikipedia
Nejvýznamnější implementace instrukcí SIMD na mikroprocesorech s architekturou RISC, ať již se jedná o instrukce určené pro operace s celými čísly či s čísly reálnými (přesněji řečeno s plovoucí řádovou čárkou), jsou vypsány v následující tabulce:
| # | Zkratka/název | Plný název | Rodina procesorů |
|---|---|---|---|
| 1 | MAX-1 | Multimedia Acceleration eXtensions v1 | HP-PA RISC |
| 2 | MAX-2 | Multimedia Acceleration eXtensions v2 | HP-PA RISC |
| 3 | VIS 1 | Visual Instruction v1 | Set SPARC V9 |
| 4 | VIS 2 | Visual Instruction v2 | Set SPARC V9 |
| 5 | AltiVec | (obchodní názvy Velocity Engine, VMX) | PowerPC |
| 6 | MDMX | MIPS Digital Media eXtension (MaDMaX) | MIPS |
| 7 | MIPS-3D | MIPS-3D | MIPS |
| 8 | MVI | Motion Video Instructions | DEC Alpha |
| 9 | NEON | Advanced SIMD | Cortex (ARMv7) |

Obrázek 4: Jedna z mnoha 64bitových variant mikroprocesoru využívajícího instrukční sadu MIPS.
3. Malé historické porovnání: SIMD na RISC vs. CISC
RISCové procesory jsou i – i přes své velké rozšíření v různých typech elektronických zařízení – mezi odbornou veřejností poněkud méně známé, než na desktop orientované mikroprocesory řady x86 a dnes taktéž x86_64. Méně známý je i fakt, že instrukce typu SIMD byly, jak jsme si již řekli v úvodní kapitole, poprvé implementovány právě na mikroprocesorech s architekturou RISC a teprve o přibližně dva roky později se již existujícími instrukčními sadami nechala inspirovat firma Intel při návrhu své instrukční sady MMX. Ostatně podívejme se na doby vzniku některých instrukčních sad se SIMD instrukcemi ve světě RISC:
| # | Název technologie | Rodina procesorů | Rok uvedení | Před x86? |
|---|---|---|---|---|
| 1 | MAX-1 | HP-PA RISC | 1994 | ano |
| 2 | MAX-2 | HP-PA RISC | 1996 | ne |
| 3 | VIS 1 | SPARC V9 | 1994 | ano |
| 4 | VIS 2 | SPARC V9 | 1999 | ne |
| 5 | AltiVec | PowerPC | 1998 | ne |
| 6 | MDMX | MIPS | 1996 | ne |
| 7 | MIPS-3D | MIPS | 1999 | ne |
| 8 | MVI | DEC Alpha | 1995 | ano |

Obrázek 5: Pohled na mikroprocesor AMD K6–2 s implementací instrukční sady 3DNow! obsahující SIMD instrukce.
Pro historické porovnání si ještě uveďme, ve kterých letech byly nejdůležitější instrukční sady se SIMD instrukcemi uvedeny na platformě x86, tj. především na mikroprocesorech navrhovaných a vyráběných společnostmi Intel a AMD. Z této tabulky je zřejmé, že technologie SIMD byla na platformě x86 skutečně uvedena o něco později, než tomu bylo u některých rodin mikroprocesorů s architekturou RISC:
| # | Název technologie | Společnost | Rok uvedení | Poprvé použito v čipu |
|---|---|---|---|---|
| 1 | MMX | Intel | 1996 | Intel Pentium P5 |
| 2 | 3DNow! | AMD | 1998 | AMD K6–2 |
| 3 | SSE | Intel | 1999 | Intel Pentium III (mikroarchitektura P6) |
| 4 | SSE2 | Intel | 2001 | Intel Pentium 4 (mikroarchitektura NetBurst) |
| 5 | SSE3 | Intel | 2004 | Intel Pentium 4 (Prescott) |
| 6 | SSSE3 | Intel | 2006 | mikroarchitektura Intel Core |
| 7 | SSE4 | Intel+AMD | 2006 | AMD K10 (SSE4a) , mikroarchitektura Intel Core |

Obrázek 6: Interní struktura mikroprocesorů SPARC, na níž můžeme najít jak moduly pro práci s celými čísly, tak i moduly FPU. Mikroprocesory SPARC, popř. MicroSPARC a SuperSPARC mají své kořeny v popisované architektuře RISC 1.
4. SIMD instrukce na RISCových mikroprocesorech řady MIPS
Instrukce typu SIMD se začaly relativně brzy využívat i na mikroprocesorech MIPS, přičemž se jednalo o rozšíření instrukční sady MIPS V. Tímto jménem je označována pátá revize architektury MIPS (Microprocessor without Interlocked Pipeline Stages), s níž jsme se již v seriálu o architekturách počítačů podrobněji seznámili. Původní architektura MIPS představovaná mikroprocesory R2000 (rok vzniku 1985) a R3000 (rok vzniku 1988) byla typickou ukázkou čisté 32bitové technologie RISC s jednoduchými instrukcemi s pevným formátem o šířce 32 bitů (jednalo se o instrukce prováděné nad skalárními hodnotami). Aby bylo možné každý krok instrukce provést v pětiřezové instrukční pipeline za jediný takt, neobsahovaly tyto mikroprocesory ani instrukce se složitými adresovacími režimy, ani instrukce pro celočíselné násobení a dělení.

Obrázek 7: Výkonná a na dobu svého vzniku revoluční grafická stanice Onyx 2 vybavená systémem Infinite Reality. Tato grafická stanice je postavena na bázi mikroprocesorů R10000 vycházejících z původní architektury MIPS.
V dalších revizích architektury MIPS však docházelo k postupnému rozšiřování instrukční sady a tím pádem i k přidávání dalších funkčních jednotek buď přímo na čip s mikroprocesorem, nebo na další pomocné čipy (koprocesory). Instrukční sada byla rozšířena zejména o již zmíněné instrukce pro násobení a dělení (které se ve skutečnosti prováděly mimo vlastní pipeline ve specializované jednotce a s využitím dvojice specializovaných registrů), ale i o instrukce matematického koprocesoru a posléze i o instrukce typu SIMD (někteří odborníci se domnívají, že tím procesory MIPS ztratily jak svoji jednoduchost, tak i určitou eleganci). V roce 1996 byly představeny první čipy implementující rozšiřující instrukční sadu MDMX neboli MIPS Digital Media eXtension. Tato instrukční sada byla o tři roky později následována další rozšiřující instrukční sadou s všeříkajícím názvem MIPS-3D. Obě tyto technologie budou popsány v navazujících kapitolách.

Obrázek 8: Laboratoř specializovaná na simulace a vizualizace, jejíž nezbytnou součástí jsou stroje Onyx 2 Infinite Reality, což znamená, že se jedná o další způsob využití mikroprocesorů s architekturou RISC a současně i o jednu z oblastí, kde je možné využívat SIMD instruce.
5. Rozšiřující instrukční sada MDMX (MaDMaX)
Instrukční sada MDMX (MIPS Digital Media eXtension), nazývaná taktéž MaDMaX, se v mnoha ohledech podobá technologii MMX, s níž jsme se již v tomto seriálu seznámili. Podobností mezi oběma zmíněnými technologiemi můžeme nalézt celou řadu – týká se jak orientace na operace prováděné pouze s celými čísly, tak i existence instrukcí pro aritmetické operace součtu a rozdílu se saturací i o využití registrů určených původně pro operace matematického koprocesoru (což mj. zajišťuje zpětnou kompatibilitu s existujícími operačními systémy). Podívejme se však na instrukční sadu MDMX poněkud podrobněji. Tato technologie byla navržena s ohledem na to, aby ji bylo možné snadno využít k urychlení různých rastrových operací i operací prováděných s audio daty. U rastrových operací (operací prováděných s pixely obrazu) se uvažovalo i o diskrétní kosinové transformaci (DCT) a inverzní diskrétní kosinové transformaci používané mj. i u formátu JFIF/JPEG.
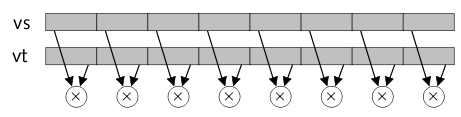
Obrázek 9: První typ MDMX instrukcí: instrukce typu „vector to vector“.
Z tohoto důvodu pracují instrukce MDMX s celočíselnými osmibitovými hodnotami (bajty), popř. se šestnáctibitovými hodnotami (polovičními slovy). Tyto hodnoty jsou umístěny do vektorů konstantní délky představovanými 64bitovými registry původně určenými pouze pro matematický koprocesor mikroprocesorů MIPS. Snadno můžeme spočítat, že při uložení osmibitových prvků (pojmenovaných OB – oct byte) do vektoru představovaného 64bitovým registrem má tento vektor délku osm prvků a při uložení šestnáctibitových prvků (QH – quad half) má vektor délku čtyři prvky. Jedná se tedy o formáty podobné těm, které můžeme nalézt i u instrukční sady MMX, ovšem jsou zde dva rozdíly – v MDMX nejsou podporovány operace s 32bitovými a 64bitovými hodnotami, na druhou stranu se však pro uložení 64bitových vektorů může využít kterýkoli registr matematického koprocesoru, kterých je na architektuře MIPS celkem 32, což je velký rozdíl oproti pouhým osmi registrům v případě instrukcí MMX.
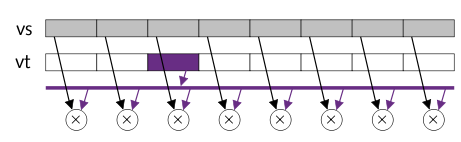
Obrázek 10: První typ MDMX instrukcí: instrukce typu „vector to scalar“
6. Nové operace implementované v instrukční sadě MDMX
V instrukční sadě mikroprocesorů s architekturou MIPS došlo kvůli implementaci technologie MDMX k rozšíření významu některých instrukcí a samozřejmě též k přidání instrukcí nových. Upraveny byly především aritmetické instrukce ADD, SUB, MUL, MIN a MAX, které v případě využití příznaků OB (oct byte) či QH (quad half) pracují nad čtyřprvkovými popř. osmiprvkovými vektory a navíc s aritmetikou se saturací, kdy nedochází k přetečení ani podtečení. Podporovány jsou tři nové režimy instrukcí. První režim se nazývá „vector to vector“ a nejde o nic jiného, než o režim, v němž se operace provádí s dvojicí vektorů a výsledkem operace je většinou opět vektor. Druhý režim je nazývaný „vector to scalar“. V tomto režimu lze vybrat kterýkoli prvek z vektorového registru a provést operaci s tímto prvkem zkombinovaným s libovolným skalárním registrem. Třetí režim „vector to immediate“ slouží k provedení operace nad vektorem zkombinovaným s konstantou.
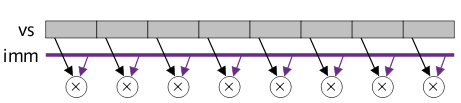
Obrázek 11: Třetí typ MDMX instrukcí: instrukce typu „vector to immediate“
Některé operace mohou nastavovat příznaky (flags). Z tohoto důvodu je v technologii MDMX implementován i vektor obsahující osm jednobitových prvků, do nějž se mohou příznaky ukládat. Tento vektor je mapován do registru příznaků matematického koprocesoru; důvodem je opět kompatibilita se staršími operačními systémy. Se čtveřicí nebo osmicí jednobitových příznaků pracují porovnávací instrukce C.EQ, C.LT a C.LE, jejichž význam je pravděpodobně zřejmý (EQ=equals, LT=less than, LE=less or equal). Další tři relační (porovnávací) operace lze implementovat prostým otočením operandů nebo bitovou negací vektoru s bitovými příznaky (navíc instrukce využívající vektor příznaků dokážou pracovat jak s přímými hodnotami, tak i s hodnotami negovanými). Další skupinou instrukcí upravených pro využití technologie MDMX jsou instrukce ALNI a ALNV sloužící pro zarovnání (bitový posun) vektorů a instrukce pro operace s akumulátorem, které budou popsány v navazující kapitole.

Obrázek 12: Způsob zakódování nových či modifikovaných MDMX instrukcí.
7. Problémy provázející operaci multiply & accumulate (MAC)
Další instrukce, které byly na platformu MIPS přidány, jsou určeny pro práci s takzvaným „širokým akumulátorem“ (wide accumulator). Jedná se o technologii určenou především pro usnadnění násobení s akumulací výsledku, která je implementovaná i na moderních digitálních signálových procesorech. Operace násobení (následovaná akumulací výsledku), jenž je velmi často používaná v mnoha algoritmech pro zpracování audio i video signálu, totiž vede k tomu, že počet bitů výsledku obecně odpovídá součtu bitů obou operandů, což například znamená, že při násobení dvou osmibitových čísel je nutné výsledek uložit do 16bitového slova (naproti tomu u sčítání následujícího za násobením se počet bitů zvýší pouze o jedničku; tento přebývající bit je typicky ukládán do příznakového bitu carry). Pro operace násobení lze zvolit několik typů SIMD instrukcí. V instrukční sadě MMX se jedná například o instrukci PMADDWD provádějící násobení a součet (akumulaci) výsledku, ovšem výsledek násobení dvou 16bitových slov je uložen do 32 bitů, což poměrně zásadním způsobem snižuje paralelismus této operace.

Obrázek 13: Nové instrukce určené pro práci se širokým akumulátorem
Zdroj: Digital, MIPS Add Multimedia Extensions Digital Focuses on Video, MIPS on 3D Graphics; Vendors Debate Differences

8. Operace prováděné se „širokým akumulátorem“
V případě instrukční sady MDMX byla zvolena jiná technologie založená na již zmíněném „širokém akumulátoru“, což je registr s opravdu velkou šířkou – celých 192 bitů. Tento speciální registr může být rozdělen na osm 24bitových slov, popřípadě na čtyři 48bitová slova. Tyto bitové šířky jednotlivých prvků osmiprvkového či čtyřprvkového vektoru zaručují, že lze provést 256 násobení typu 8×8 bitů, popř. 65536 násobení typu 16×16 bitů, aniž by došlo k přetečení postupně akumulovaného výsledku. K dispozici jsou samozřejmě instrukce, které dokážou do tohoto akumulátoru uložit data, popř. data vyzvednout, a to se současným provedením všech potřebných konverzí (bitových posunů a maskování). Jedinou nevýhodou této technologie je existence pouze jednoho širokého akumulátoru, což například znamená, že optimalizace spočívající v rozbalení smyček nemusí být tak účinná jako v jiných případech, protože se nutnost práce jen s jedním akumulátorem stává úzkým hrdlem systému – nicméně bez existence širokého akumulátoru by byla situace ještě horší.

Obrázek 14: Porovnání základních vlastností některých instrukčních sad se SIMD instrukcemi.
Zdroj: Digital, MIPS Add Multimedia Extensions Digital Focuses on Video, MIPS on 3D Graphics; Vendors Debate Differences
9. Odkazy na Internetu
- NEON
http://www.arm.com/products/processors/technologies/neon.php - Architecture and Implementation of the ARM Cortex-A8 Microprocessor
http://www.design-reuse.com/articles/11580/architecture-and-implementation-of-the-arm-cortex-a8-microprocessor.html - Multimedia Acceleration eXtensions (Wikipedia)
http://en.wikipedia.org/wiki/Multimedia_Acceleration_eXtensions - AltiVec (Wikipedia)
http://en.wikipedia.org/wiki/AltiVec - Visual Instruction Set (Wikipedia)
http://en.wikipedia.org/wiki/Visual_Instruction_Set - MAJC (Wikipedia)
http://en.wikipedia.org/wiki/MAJC - MDMX (Wikipedia)
http://en.wikipedia.org/wiki/MDMX - MIPS Multiply Unit
http://programmedlessons.org/AssemblyTutorial/Chapter-14/ass14_3.html - Silicon Graphics Introduces Enhanced MIPS Architecture
http://bwrc.eecs.berkeley.edu/CIC/otherpr/enhanced_mips.html - MIPS-3D (Wikipedia)
http://en.wikipedia.org/wiki/MIPS-3D - MIPS Technologies, Inc. announces new MIPS-3D technology to provide silicon-efficient 3D graphics acceleration
http://www.design-reuse.com/news/2057/mips-mips-3d-technology-silicon-efficient-3d-graphics-acceleration.html - MIPS-3D Built-in Function (gcc.gnu.org)
http://gcc.gnu.org/onlinedocs/gcc/MIPS_002d3D-Built_002din-Functions.html - Baha Guclu Dundar:
Intel MMX, SSE, SSE2, SSE3/SSSE3/SSE4 Architectures - SSE (Streaming SIMD Extentions)
http://www.songho.ca/misc/sse/sse.html - Timothy A. Chagnon: SSE and SSE2
http://www.cs.drexel.edu/~tc365/mpi-wht/sse.pdf - Intel corporation: Extending the Worldr's Most Popular Processor Architecture
http://download.intel.com/technology/architecture/new-instructions-paper.pdf - SIMD architectures:
http://arstechnica.com/old/content/2000/03/simd.ars/ - Tour of the Black Holes of Computing!: Floating Point
http://www.cs.hmc.edu/~geoff/classes/hmc.cs105…/slides/class02_floats.ppt - 3Dnow! Technology Manual
AMD Inc., 2000 - Intel MMXTM Technology Overview
Intel corporation, 1996 - MultiMedia eXtensions
http://softpixel.com/~cwright/programming/simd/mmx.phpi - AMD K5 („K5“ / „5k86“)
http://www.pcguide.com/ref/cpu/fam/g5K5-c.html - Sixth Generation Processors
http://www.pcguide.com/ref/cpu/fam/g6.htm - Great Microprocessors of the Past and Present
http://www.cpushack.com/CPU/cpu1.html - Very long instruction word (Wikipedia)
http://en.wikipedia.org/wiki/Very_long_instruction_word - CPU design (Wikipedia)
http://en.wikipedia.org/wiki/CPU_design - Control unit (Wikipedia)
http://en.wikipedia.org/wiki/Control_unit - Cray History
http://www.cray.com/About/History.aspx?404;http://www.cray.com:80/about_cray/history.html - Cray Historical Timeline
http://www.cray.com/Assets/PDF/about/CrayTimeline.pdf - Computer Speed Claims 1980 to 1996
http://homepage.virgin.net/roy.longbottom/mips.htm - Superpočítače Cray
http://www.root.cz/clanky/superpocitace-cray/ - Superpočítače Cray (druhá část)
http://www.root.cz/clanky/superpocitace-cray-druha-cast/ - Superpočítače Cray (třetí část)
http://www.root.cz/clanky/superpocitace-cray-treti-cast/ - Superpočítače Cray (čtvrtá část)
http://www.root.cz/clanky/superpocitace-cray-ctvrta-cast/ - Superpočítače Cray (pátá část): architektura Cray X-MP
http://www.root.cz/clanky/superpocitace-cray-pata-cast-architektura-pocitace-cray-x-mp-a-jeho-pouziti-ve-filmovem-prumyslu/

























