
Obsah
1. Kafka Connect: tvorba producentů a konzumentů bez nutnosti udržovat zdrojový kód
2. Tvorba producentů a konzumentů klasickým způsobem
3. Využití frameworku Kafka Connect
4. Konfigurace jednoduchého konektoru typu sink
5. Stručný popis jednotlivých konfiguračních parametrů
7. Spuštění Apache Kafky před inicializací konektoru
9. Poslání několika zpráv do tématu connect-test-1 s jejich konzumací konektorem
10. Skupina konzumentů (consumers group) vytvořená konektorem
11. Konektor akceptující zprávy ve formátu JSON
12. Zpracování zpráv posílaných ve formátu JSON
13. Výchozí reakce na zprávu se špatným formátem
14. Přeskakování zpráv s nekorektním formátem
15. Otestování upraveného konektoru
16. Poslání všech nekorektně naformátovaných zpráv do „dead letter queue“
17. Otestování upraveného konektoru a výpis obsahu „dead letter queue“
19. Příloha: nástroj Kafkacat (Kcat)
1. Kafka Connect: tvorba producentů a konzumentů bez nutnosti udržovat zdrojový kód
V dnešním článku se ve stručnosti seznámíme s frameworkem nazvaným Kafka Connect. S využitím této relativně nové technologie (navržené přímo od tvůrců Apache Kafky) je možné vytvářet producenty, konzumenty a taktéž různé transformátory a konvertory zpráv pro Apache Kafku, a to bez nutnosti tvorby, nasazení, monitoringu a následné údržby zdrojového kódu. Navíc je možné definovat chování konzumentů, kteří například mohou zprávy validovat oproti zadanému schématu, mohou přeposílat zprávy se špatným formátem do DLQ (dead letter queue), ukládat zprávy do relačních (ale i jiných) databází apod.

Obrázek 1: Logo nástroje Apache Kafka, kterému se budeme dnes věnovat.
2. Tvorba producentů a konzumentů klasickým způsobem
S využitím vhodných podpůrných knihoven může být tvorba producentů a konzumentů pro Apache Kafku zdánlivě poměrně jednoduchou záležitostí. Příkladem může být producent naprogramovaný v Pythonu, který po svém spuštění pošle do lokálně běžící Kafky 1000 zpráv:
#!/usr/bin/env python3
from kafka import KafkaProducer
from time import sleep
from json import dumps
server = "localhost:9092"
topic = "upload"
print("Connecting to Kafka")
producer = KafkaProducer(
bootstrap_servers=[server], value_serializer=lambda x: dumps(x).encode("utf-8")
)
print("Connected to Kafka")
for i in range(1000):
data = {"counter": i}
producer.send(topic, value=data)
sleep(5)
I zdrojový kód konzumenta může být na první pohled snadný a bezchybný (ať již toto slovo v kontextu IT znamená cokoli):
#!/usr/bin/env python3
import sys
from kafka import KafkaConsumer
server = "localhost:9092"
topic = "upload"
group_id = "group1"
print("Connecting to Kafka")
consumer = KafkaConsumer(
topic, group_id=group_id, bootstrap_servers=[server], auto_offset_reset="earliest"
)
print("Connected to Kafka")
try:
for message in consumer:
print(
"%s:%d:%d: key=%s value=%s"
% (
message.topic,
message.partition,
message.offset,
message.key,
message.value,
)
)
except KeyboardInterrupt:
sys.exit()

Obrázek 2: Sledování činnosti brokeru přes standardní nástroj JConsole.
Podobným způsobem můžeme naprogramovat producenta i v dalších jazycích, například v Go. Zde konkrétně používáme knihovnu Sarama, i když pro Go existují i další podpůrné knihovny:
package main
import (
"log"
"github.com/Shopify/sarama"
)
const (
// KafkaConnectionString obsahuje jméno počítače a port, na kterém běží Kafka broker
KafkaConnectionString = "localhost:9092"
// KafkaTopic obsahuje jméno tématu
KafkaTopic = "test-topic"
)
func main() {
// konstrukce konzumenta
producer, err := sarama.NewSyncProducer([]string{KafkaConnectionString}, nil)
// kontrola chyby při připojování ke Kafce
if err != nil {
log.Fatal(err)
}
log.Printf("Connected to %s", KafkaConnectionString)
// zajištění uzavření připojení ke Kafce
defer func() {
if err := producer.Close(); err != nil {
log.Fatal(err)
}
}()
// poslání (produkce) zprávy
msg := &sarama.ProducerMessage{Topic: KafkaTopic, Value: sarama.StringEncoder("testing 123")}
partition, offset, err := producer.SendMessage(msg)
if err != nil {
log.Printf("FAILED to send message: %s\n", err)
} else {
log.Printf("> message sent to partition %d at offset %d\n", partition, offset)
}
log.Print("Done")
}
A nakonec se podívejme na konzumenta, opět naprogramovaného v jazyce Go:
package main
import (
"log"
"github.com/Shopify/sarama"
)
const (
// KafkaConnectionString obsahuje jméno počítače a port, na kterém běží Kafka broker
KafkaConnectionString = "localhost:9092"
// KafkaTopic obsahuje jméno tématu
KafkaTopic = "test-topic"
)
func main() {
// konstrukce konzumenta
consumer, err := sarama.NewConsumer([]string{KafkaConnectionString}, nil)
// kontrola chyby při připojování ke Kafce
if err != nil {
log.Fatal(err)
}
log.Printf("Connected to %s", KafkaConnectionString)
// zajištění uzavření připojení ke Kafce
defer func() {
if err := consumer.Close(); err != nil {
log.Fatal(err)
}
}()
// přihlášení ke zvolenému tématu
partitionConsumer, err := consumer.ConsumePartition(KafkaTopic, 0, sarama.OffsetNewest)
if err != nil {
log.Fatal(err)
}
// zajištění ukončení přihlášení ke zvolenému tématu
defer func() {
if err := partitionConsumer.Close(); err != nil {
log.Fatal(err)
}
}()
// postupné čtení zpráv, které byly do zvoleného tématu publikovány
consumed := 0
for {
msg := <-partitionConsumer.Messages()
// vypíšeme pouze offset zprávy, její klíč a tělo (value, payload)
log.Printf("Consumed message offset %d: %s:%s", msg.Offset, msg.Key, msg.Value)
consumed++
}
// výpis počtu zpracovaných zpráv (ovšem sem se stejně nedostaneme :-)
log.Printf("Consumed: %d", consumed)
log.Print("Done")
}
Mohlo by se zdát, že pokud je naprogramování producenta nebo konzumenta pro Kafku otázkou několika (desítek) řádků, nemá asi význam se frameworkem Kafka Connect zabývat. Ve skutečnosti je však existence samotného kódu jen nezbytnou podmínkou pro nasazení producenta/konzumenta do produkce. Kód je nutné otestovat, v tomto případě nejenom jednotkovými testy, ale i testy integračními (a záhy zjistíte, že kód obsahuje spoustu nedostatků). Dále je nutné mít k dispozici skripty pro nasazení nové verze služby (CD), musí se nastavit logování, monitoring, pravidla pro nasazení nové verze atd. A samozřejmě je nutné sledovat, zda použité knihovny nemají hlášená nová CVE popř. zajistit, že kód bude přeložitelný a/nebo spustitelný i po vydání nové verze jazyka. S využitím frameworku Kafka Connect mnoho z těchto požadavků odpadá, což uvidíme především ve druhém článku.
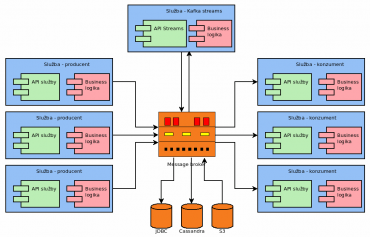
Obrázek 3: Příklad použití ekosystému Kafky (Kafka Streams, konektory pro databáze atd.).
3. Využití frameworku Kafka Connect
Některé možnosti využití frameworku Kafka Connect jsou ukázány na následujících diagramech i s příslušným popiskem:

Obrázek 4: Zprávy jsou přes jeden konektor načítány z databáze (například z PostgreSQL) a posílány do zvoleného tématu v Apache Kafce. Odtud si je načítá (konzumuje) další konektor, který zprávy ukládá do Hadoopu.

Obrázek 5: Zprávy jsou získávány z fronty MQTT (tedy z jiného message brokeru) a opět ukládány do zvoleného tématu. Odtud jsou konzumovány druhým konektorem, který zprávy posílá do třetího message brokeru, zde konkrétně do Amazon SQS (Amazon Simple Queue Service).

Obrázek 6: Alternativa k diagramu z obrázku číslo 4. Ke zvolenému tématu Apache Kafky je připojeno několik konektorů. Ty zprávy souběžně konzumují a ukládají do Amazon S3 (Amazon Simple Storage Service), do textového logu a souběžně například do dokumentové databáze.

Obrázek 7: Zprávy produkované přes Kafka Connect do zvoleného tématu se nijak neliší od zpráv produkovaných jakýmkoli jiným producentem. Proto tyto zprávy můžeme zpracovávat i dalšími nástroji, vlastními konzumenty, přes kSQL atd. atd.
4. Konfigurace jednoduchého konektoru typu sink
Podívejme se, jak může vypadat konfigurace velmi jednoduchého konektoru typu sink, který bude konzumovat zprávy z vybraného tématu (topic) a bude je ukládat do textového souboru, jehož jméno je opět uvedeno v konfiguračním souboru. Celá konfigurace je popsána v jediném (a to velmi krátkém) souboru ve formátu s koncovkou „.properties“. Tento formát, v němž jsou uloženy dvojice klíč(string)=hodnota(string), je velmi často používán v ekosystému Javy – nejenom vlastního jazyka, ale především JVM – takže jeho podpora v Apache Kafce nemusí být velkým překvapením (na rozdíl od jiných ekosystémů, v nichž se spíše setkáme s konfiguračními soubory ve formátu JSON, TOML, YAML atd.).
Vraťme se však ke konfiguraci našeho konektoru. Bude se (alespoň prozatím) jednat o specifikaci devíti parametrů:
name=local-file-sink connector.class=FileStreamSink tasks.max=1 file=test.sink.txt topics=connect-test-1 key.converter=org.apache.kafka.connect.storage.StringConverter value.converter=org.apache.kafka.connect.storage.StringConverter key.converter.schemas.enable=false value.converter.schemas.enable=false
V případě, že některou z voleb v našem .properties souboru neuvedeme, bude tato volba načtena ze souboru config/connect-standalone.properties:
bootstrap.servers=localhost:9092 key.converter.schemas.enable=true value.converter.schemas.enable=true offset.storage.file.filename=/tmp/connect.offsets offset.flush.interval.ms=10000 #plugin.path=
5. Stručný popis jednotlivých konfiguračních parametrů
Význam parametrů uložených v konfiguračním souboru je následující:
- name: jméno konektoru, které by mělo být unikátní.
- connector.class: třída implementující konektor. Jméno třídy FileStreamSink naznačuje, že se jedná o třídu, jenž je standardní součástí celého frameworku. V opačném případě by zde bylo uvedeno celé jméno i se jménem balíčku, popř. se zde může vyskytnout jméno JAR souboru s balíčky (s takovými třídami se setkáme příště).
- tasks.max: maximální počet souběžně spuštěných úloh pro zpracování zpráv. Tato hodnota není zcela směrodatná, neboť framework může počet úloh snížit.
- file: jméno souboru, do kterého se budou ukládat zprávy přečtené z vybraného tématu.
- topics: téma či témata, která budou konektorem konzumována.
- key.converter: třída, která je použita pro načtení a další zpracování klíče (key), který je součástí zprávy. V našem případě klíč přečteme a převedeme na řetězec (obecně se totiž jedná o sekvenci bajtů).
- value.converter: podobný význam, jako má předchozí volba, nyní ovšem pro hodnotu zprávy, tedy pro její tělo.
- key.converter.schemas.enable: formát klíče může být validován s využitím schématu (a samotné schéma je buď součástí zprávy nebo je přečtené z nakonfigurovaného úložiště). Prozatím schémata používat nebudeme, takže je vhodné explicitně použití schémat zakázat.
- value.converter.schemas.enable: podobný význam, jako má předchozí volba, nyní ovšem pro hodnotu zprávy, tedy pro její tělo.
6. Instalace Apache Kafky
V případě, že je na počítači nainstalováno JRE, je instalace Kafky pro testovací účely triviální. Tarball s instalací Kafky lze získat z adresy https://downloads.apache.org/kafka/3.3.2/kafka2.13–3.3.2.tgz. Stažení a rozbalení tarballu:
$ wget https://downloads.apache.org/kafka/3.3.2/kafka_2.13-3.3.2.tgz $ tar xvfz kafka_2.13-3.3.2.tgz $ cd kafka_2.13-3.3.2/
Po rozbalení získáme adresář, v němž se nachází všechny potřebné Java archivy (JAR), konfigurační soubory (v podadresáři config) a několik pomocných skriptů (v podadresáři bin). Pro spuštění Zookeepera a brokerů je zapotřebí mít nainstalovánu JRE (Java Runtime Environment) a samozřejmě též nějaký shell (BASH, cmd, …).
. ├── bin │ └── windows ├── config │ └── kraft ├── libs ├── licenses └── site-docs 7 directories
7. Spuštění Apache Kafky před inicializací konektoru
Po (doufejme že úspěšné) instalaci Kafky již můžeme spustit ZooKeeper a jednu instanci brokera (a to přesně v tomto pořadí!). Konfigurace ZooKeepera je uložena v souboru config/zookeeper.properties a zajímat nás budou především následující tři konfigurační volby – adresář, kam ZooKeeper ukládá svoje data, port, který použijí brokeři a omezení počtu připojení jednoho klienta v daný okamžik:
dataDir=/tmp/zookeeper clientPort=2181 maxClientCnxns=0
Nyní již můžeme ZooKeepera spustit:
$ cd kafka/kafka_2.12-3.3.2/ $ bin/zookeeper-server-start.sh config/zookeeper.properties
[2023-02-04 08:37:49,555] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig) ... ... ... [2023-02-04 08:37:49,591] INFO (org.apache.zookeeper.server.ZooKeeperServer) [2023-02-04 08:37:49,591] INFO ______ _ (org.apache.zookeeper.server.ZooKeeperServer) [2023-02-04 08:37:49,591] INFO |___ / | | (org.apache.zookeeper.server.ZooKeeperServer) [2023-02-04 08:37:49,591] INFO / / ___ ___ | | __ ___ ___ _ __ ___ _ __ (org.apache.zookeeper.server.ZooKeeperServer) [2023-02-04 08:37:49,592] INFO / / / _ \ / _ \ | |/ / / _ \ / _ \ | '_ \ / _ \ | '__| (org.apache.zookeeper.server.ZooKeeperServer) [2023-02-04 08:37:49,592] INFO / /__ | (_) | | (_) | | < | __/ | __/ | |_) | | __/ | | (org.apache.zookeeper.server.ZooKeeperServer) [2023-02-04 08:37:49,592] INFO /_____| \___/ \___/ |_|\_\ \___| \___| | .__/ \___| |_| (org.apache.zookeeper.server.ZooKeeperServer) [2023-02-04 08:37:49,592] INFO | | (org.apache.zookeeper.server.ZooKeeperServer) [2023-02-04 08:37:49,592] INFO |_| (org.apache.zookeeper.server.ZooKeeperServer) ... ... ... [2023-02-04 08:37:49,691] INFO zookeeper.request_throttler.shutdownTimeout = 10000 (org.apache.zookeeper.server.RequestThrottler) [2023-02-04 08:37:49,706] INFO Using checkIntervalMs=60000 maxPerMinute=10000 maxNeverUsedIntervalMs=0 (org.apache.zookeeper.server.ContainerManager)
Konfigurace jednoho brokera je uložená v souboru config/server.properties. Samotný konfigurační soubor obsahuje několik sekcí:
- Port, na kterém broker naslouchá, jeho ID, počet použitých vláken pro IO operace a počet vláken pro komunikaci.
- Velikost bufferů, maximální povolená velikost požadavků (což omezuje velikost zprávy) atd.
- Nastavení počtu partitions
- Nastavení retence dat
- Připojení k Zookeeperovi
broker.id=0 listeners=PLAINTEXT://:9092 num.network.threads=3 num.io.threads=8 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 log.dirs=/tmp/kafka-logs num.partitions=1 num.recovery.threads.per.data.dir=1 log.retention.hours=168 log.segment.bytes=1073741824 zookeeper.connect=localhost:2181 zookeeper.connection.timeout.ms=6000
Spuštění jednoho brokera vypadá i probíhá jednoduše:
$ cd kafka/kafka_2.12-3.3.2/ $ bin/kafka-server-start.sh config/server.properties
[2023-02-04 08:41:47,105] INFO Registered kafka:type=kafka.Log4jController MBean (kafka.utils.Log4jControllerRegistration$) [2023-02-04 08:41:47,506] INFO Setting -D jdk.tls.rejectClientInitiatedRenegotiation=true to disable client-initiated TLS renegotiation (org.apache.zookeeper.common.X509Util) [2023-02-04 08:41:47,587] INFO Registered signal handlers for TERM, INT, HUP (org.apache.kafka.common.utils.LoggingSignalHandler) [2023-02-04 08:41:47,589] INFO starting (kafka.server.KafkaServer) [2023-02-04 08:41:47,590] INFO Connecting to zookeeper on localhost:2181 (kafka.server.KafkaServer) [2023-02-04 08:41:47,606] INFO [ZooKeeperClient Kafka server] Initializing a new session to localhost:2181. (kafka.zookeeper.ZooKeeperClient) ... ... ... [2023-02-04 08:49:52,076] INFO [KafkaServer id=0] started (kafka.server.KafkaServer) [2023-02-04 08:49:52,167] INFO [BrokerToControllerChannelManager broker=0 name=alterPartition]: Recorded new controller, from now on will use node localhost:9092 (id: 0 rack: null) (kafka.server.BrokerToControllerRequestThread) [2023-02-04 08:49:52,184] INFO [BrokerToControllerChannelManager broker=0 name=forwarding]: Recorded new controller, from now on will use node localhost:9092 (id: 0 rack: null) (kafka.server.BrokerToControllerRequestThread)
Alternativně je možné ZooKeepera i Kafku (jednu instanci brokera) spustit v Dockeru:
$ docker run -p 2181:2181 -p 9092:9092 --env ADVERTISED_HOST=`docker-machine ip \`docker-machine active\`` --env ADVERTISED_PORT=9092 spotify/kafka
8. Spuštění konektoru
Ve chvíli, kdy je spuštěn jak ZooKeeper, tak i minimálně jeden broker, již můžeme spustit náš jednoduchý konektor. Prozatím spustíme jediný konektor bez možnosti jeho distribuce přes více systémů. Z tohoto důvodu se pro spuštění použije skript bin/connect-standalone.sh, kterému se předá výchozí konfigurační soubor config/connect-standalone.properties i námi upravený konfigurační soubor config/connect-fie-sink.properties:
$ cd kafka/kafka_2.12-3.3.2/ $ bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-sink.properties
Nejprve by se měly vypsat obecné informace o konfiguraci:
[2023-02-04 08:46:13,573] INFO Kafka Connect standalone worker initializing ... (org.apache.kafka.connect.cli.ConnectStandalone:68)
[2023-02-04 08:46:13,580] INFO WorkerInfo values:
jvm.args = -Xms256M, -Xmx2G, -XX:+UseG1GC, -XX:MaxGCPauseMillis=20, -XX:
...
...
...
A následně i informace o tom, že došlo k připojení konektoru, a to včetně jména tématu, identifikace partition atd.:
[2023-02-04 08:47:06,680] INFO [local-file-sink|task-0] [Consumer clientId=connector-consumer-local-file-sink-0, groupId=connect-local-file-sink] Notifying assignor about the new Assignment(partitions=[connect-test-1-0]) (org.apache.kafka.clients.consumer.internals.ConsumerCoordinator:300)
[2023-02-04 08:47:06,682] INFO [local-file-sink|task-0] [Consumer clientId=connector-consumer-local-file-sink-0, groupId=connect-local-file-sink] Adding newly assigned partitions: connect-test-1-0 (org.apache.kafka.clients.consumer.internals.ConsumerCoordinator:312)
[2023-02-04 08:47:06,689] INFO [local-file-sink|task-0] [Consumer clientId=connector-consumer-local-file-sink-0, groupId=connect-local-file-sink] Found no committed offset for partition connect-test-1-0 (org.apache.kafka.clients.consumer.internals.ConsumerCoordinator:1538)
[2023-02-04 08:47:06,698] INFO [local-file-sink|task-0] [Consumer clientId=connector-consumer-local-file-sink-0, groupId=connect-local-file-sink] Resetting offset for partition connect-test-1-0 to position FetchPosition{offset=0, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=Optional[localhost:9092 (id: 0 rack: null)], epoch=0}}. (org.apache.kafka.clients.consumer.internals.SubscriptionState:399)
Pro kontrolu, zda vzniklo nové téma connect-test-1 si všechna témata můžeme nechat vypsat:
$ cd kafka/kafka_2.12-3.3.2/ bin/kafka-topics.sh --bootstrap-server=localhost:9092 --list __consumer_offsets connect-test-1
9. Poslání několika zpráv do tématu connect-test-1 s jejich konzumací konektorem
Nyní do nově vytvořeného tématu connect-test-1 pošleme několik zpráv. V případě, že zůstaneme u standardních nástrojů poskytovaných samotným systémem Apache Kafka, se pro posílání zpráv z příkazové řádky může využít skript kafka-console-producer.sh, a to konkrétně následujícím způsobem:
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic connect-test-1
Skript nyní očekává, že na standardní vstup zapíšeme těla zpráv oddělená Enterem. Ukončení posílání zpráv je snadné – použijeme standardní klávesovou zkratku Ctrl+D:
>foo >bar >baz <Ctrl-D>
Můžeme dokonce posílat i zprávy obsahující kromě těla (value, content) i klíč (key). V tomto případě je vhodné explicitně specifikovat, jakým způsobem je klíč oddělen od těla zprávy. Použijeme například dvojtečku (:) ve funkci oddělovače:
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic conect-test-1 -property parse.key=true --property key.separator=: >first:1 >second:2 >third:3
Pro kontrolu, jaké zprávy byly do tématu poslány, lze použít jak standardní nástroje Apache Kafky (konzument), tak i vlastní skripty nebo nástroj typu Kafkacat (nyní přejmenován na kcat, aby neobsahoval jméno „Kafka“, což mi osobně přijde jako poměrně absurdní požadavek – takový skoro až kafkovský). Kafkacat spustíme v režimu konzumenta (-C) a necháme si vypsat jak těla zpráv, tak i klíče:
$ kafkacat -C -b localhost:9092 -t connect-test-1 -K: :foo :bar :baz first:1 second:2 third:3
Ovšem samozřejmě nás bude zajímat to nejdůležitější – jak a zda vůbec vlastně konektor pracuje. V adresáři, z něhož byl konektor spuštěn, by se měl nacházet soubor test.sing.txt, jehož obsah si pochopitelně můžeme nechat vypsat:
$ cat test.sink.txt foo bar baz 1 2 3 1 2
10. Skupina konzumentů (consumers group) vytvořená konektorem
Konektor se po svém spuštění přidá do skupiny konzumentů, jejíž jméno je odvozeno od jeho jména uvedeného v souboru .properties a typu (lokální či distribuovaný konektor). I o této vlastnosti se můžeme přesvědčit a to velmi snadno: vypsáním všech skupin konzumentů, které Apache Kafka regitruje:
$ ./bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --all-groups count_errors --describe
Výpis by měl vypadat následovně (kromě jména konzumenta, které je generováno):
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID connect-local-file-sink connect-test-1 0 8 8 0 connector-consumer-local-file-sink-0-e6443ddc-4623-4995-a95d-9e659c0c657d /127.0.0.1 connector-consumer-local-file-sink-0
11. Konektor akceptující zprávy ve formátu JSON
V praxi se poměrně často setkáme s požadavkem na zpracování zpráv uložených ve formátu JSON. Tento formát může mít nejenom samotné tělo zprávy, ale i její klíč (tj. klíč nemusí být pouhým celým číslem nebo řetězcem, ale může mít složitější strukturu). Modifikace konektoru typu sink takovým způsobem, aby kontroloval, zda klíče i hodnoty zpráv odpovídají formátu JSON, je relativně snadná. Připomeňme si, jak vlastně vypadala konfigurace původního konektoru:
name=local-file-sink connector.class=FileStreamSink tasks.max=1 file=test.sink.txt topics=connect-test-1 key.converter=org.apache.kafka.connect.storage.StringConverter value.converter=org.apache.kafka.connect.storage.StringConverter key.converter.schemas.enable=false value.converter.schemas.enable=false
Od této konfigurace odvodíme konfiguraci novou. Změníme především jméno konektoru i jméno souboru, do kterého bude konektor zprávy ukládat. A taktéž změníme jméno tématu:
name=local-file-sink-json file=test.sink.jsons topics=connect-test-json
Ovšem modifikovat musíme především jméno třídy použité při interpretaci („konverzi“) klíče a těla zprávy. Namísto třídy org.apache.kafka.connect.storage.StringConverter se bude jednat o třídu org.apache.kafka.connect.json.JsonConverter. Pro zprávy prozatím nemáme definované schéma, takže stále necháme kontrolu vůči schématům zakázánu:
key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter
Nový konfigurační soubor by měl vypadat následovně (změněné položky jsou zvýrazněny):
name=local-file-sink-json connector.class=FileStreamSink tasks.max=1 file=test.sink.jsons topics=connect-test-json key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable=false value.converter.schemas.enable=false
12. Zpracování zpráv posílaných ve formátu JSON
V novém terminálu spustíme druhý konektor, a to příkazem:
$ cd kafka/kafka_2.12-3.3.2/ $ bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-sink-2.properties
Konektor při své inicializaci vypíše několik obrazovek logů, ovšem důležité jsou jen poslední záznamy, ve kterých se píše, zda při spuštění nastala chyba či nikoli:
...
...
...
[2023-02-06 17:38:49,169] INFO [local-file-sink-json|task-0] [Consumer clientId=connector-consumer-local-file-sink-json-0, groupId=connect-local-file-sink-json] Found no committed offset for partition connect-test-json-0 (org.apache.kafka.clients.consumer.internals.ConsumerCoordinator:1538)
[2023-02-06 17:38:49,186] INFO [local-file-sink-json|task-0] [Consumer clientId=connector-consumer-local-file-sink-json-0, groupId=connect-local-file-sink-json] Resetting offset for partition connect-test-json-0 to position FetchPosition{offset=0, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=Optional[localhost:9092 (id: 0 rack: null)], epoch=0}}. (org.apache.kafka.clients.consumer.internals.SubscriptionState:399)
Nyní pošleme do tématu connect-test-json několik zpráv, které jsou všechny reprezentovány v JSONu (jak klíče, tak i hodnoty). U poslední zprávy je klíč vynechán, což je ovšem korektní:
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic connect-test-json -property parse.key=true --property key.separator=;
>{"foo":1};{"bar":2}
>{"baz":false}
>42
Konektor by měl všechny tyto zprávy zpracovat a vypsat do souboru test.sink.jsons. Opět zde nalezneme jen těla zpráv, nikoli jejich klíče:
$ cat test.sink.jsons
{foo=1}
{baz=false}
42
13. Výchozí reakce na zprávu se špatným formátem
Nyní se pokusme poslat do tématu connect-test-json zprávu, která není uložena ve formátu JSON:
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic connect-test-json -property parse.key=true --property key.separator=; >xyzzy
V logu connectoru by se měla zobrazit tato chyba (resp. přesněji řečeno výjimka):
[2023-02-06 17:45:34,590] ERROR [local-file-sink-json|task-0] WorkerSinkTask{id=local-file-sink-json-0} Task threw an uncaught and unrecoverable exception. Task is being killed and will not recover until manually restarted (org.apache.kafka.connect.runtime.WorkerTask:196)
org.apache.kafka.connect.errors.ConnectException: Tolerance exceeded in error handler
Výše uvedená výjimka je způsobena touto výjimkou:
Caused by: org.apache.kafka.common.errors.SerializationException: com.fasterxml.jackson.core.JsonParseException: Unrecognized token 'xyzzy': was expecting (JSON String, Number, Array, Object or token 'null', 'true' or 'false')
at [Source: (byte[])"xyzzy"; line: 1, column: 6]
at org.apache.kafka.connect.json.JsonDeserializer.deserialize(JsonDeserializer.java:66)
at org.apache.kafka.connect.json.JsonConverter.toConnectData(JsonConverter.java:322)
... 17 more
Caused by: com.fasterxml.jackson.core.JsonParseException: Unrecognized token 'xyzzy': was expecting (JSON String, Number, Array, Object or token 'null', 'true' or 'false')
at [Source: (byte[])"xyzzy"; line: 1, column: 6]
Následně je konektor ukončen:
[2023-02-06 17:45:34,600] INFO [local-file-sink-json|task-0] Metrics reporters closed (org.apache.kafka.common.metrics.Metrics:703) [2023-02-06 17:45:34,605] INFO [local-file-sink-json|task-0] App info kafka.consumer for connector-consumer-local-file-sink-json-0 unregistered (org.apache.kafka.common.utils.AppInfoParser:83)
14. Přeskakování zpráv s nekorektním formátem
Chování konektoru, s nímž jsme se setkali v předchozí kapitole pochopitelně nemusí vyhovovat pro každou situaci. Framework Kafka Connect ovšem nabízí i další možnosti zpracování zpráv, které nemají korektní formát. Jedna z nabízených možností spočívá v přeskakování těchto zpráv. Úprava konfiguračního souboru konektoru je v tomto případě triviální, protože do něj postačuje přidat jediný řádek:
errors.tolerance=all
Navíc ještě změníme řádek se jménem souboru, do kterého se budou ukládat zprávy s korektním formátem:
file=test.sink3.jsons
Výsledná podoba upraveného konfiguračního souboru je následující:
name=local-file-sink-json connector.class=FileStreamSink tasks.max=1 file=test.sink3.jsons topics=connect-test-json key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable=false value.converter.schemas.enable=false errors.tolerance=all
15. Otestování upraveného konektoru
Nově nakonfigurovaný konektor je samozřejmě vhodné si otestovat a vyzkoušet si tak, jak a zda vůbec reaguje na zprávy s nekorektním formátem. Konektor tedy spustíme, a to konkrétně následujícím příkazem:
$ bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-sink-3.properties
Dále v novém terminálu spustíme producenta zpráv ovládaného z příkazové řádky. Povšimněte si toho, že stále používáme téma nazvané connect-test-json:
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic connect-test-json -property parse.key=true --property key.separator=;
Do tématu pošleme pět zpráv s tímto formátem (znak > na začátku řádku je výzva vypisovaná řádkovým klientem):
>{"1st":1}
>{"2nd":2}
>{"improper":message}
>"proper one"
>xyzzy
Producenta nyní můžeme ukončit klávesovou zkratkou CTRL+D a zjistit, jaké zprávy (resp. přesněji řečeno jejich těla) byly zapsány do souboru test.sink3.jsons:
$ cat test.sink3.jsons
Z výpisu obsahu tohoto souboru by mělo být patrné, že zapsány byly pouze ty zprávy, jejichž těla jsou uložena ve formátu JSON. Ostatní zprávy by měly být přeskočeny:
{1st=1}
{2nd=2}
proper one
16. Poslání všech nekorektně naformátovaných zpráv do „dead letter queue“
Prozatím jsme si ukázali dvě varianty „zpracování“ zpráv s nekorektním formátem (v našem konkrétním případě zpráv, jejichž klíč nebo tělo není uloženo v JSONu). První varianta spočívala v tom, že se konektor (konzument) zastavil, což znamená, že nekorektní zprávu bude nutné z tématu načíst jinými prostředky. Druhá varianta naopak zprávy s nekorektním formátem zcela přeskakovala. Ovšem v mnoha situacích je vhodnější zvolit si nějakou formu střední cesty – konektor (konzument) se při příjmu nekorektní zprávy nezastaví a současně nebude taková zpráva zcela ignorována. V oblasti message brokerů samozřejmě řešení existuje, a to již velmi dlouho. Jedná se o využití DLQ neboli dead letter queue. Ve světě message brokerů se jedná o frontu či o fronty, kam se ukládají jinak nezpracované zprávy, ve světě Apache Kafky se samozřejmě namísto fronty použije téma.
Takovou DLQ (resp. spíše „dead letter topic“) si můžeme nadefinovat přímo v konfiguraci konektoru:
errors.deadletterqueue.topic.name=dlq_bad_jsons
Ještě je vhodné při lokálním běhu brokeru omezit počet replikací tohoto tématu na jedničku (při distribuovaném běhu však nikoli):
errors.deadletterqueue.topic.replication.factor=1
Úplná konfigurace upraveného konektoru by mohla vypadat následovně:
name=local-file-sink-json connector.class=FileStreamSink tasks.max=1 file=test.sink4.jsons topics=connect-test-json key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable=false value.converter.schemas.enable=false errors.tolerance=all errors.deadletterqueue.topic.name=dlq_bad_jsons errors.deadletterqueue.topic.replication.factor=1
17. Otestování upraveného konektoru a výpis obsahu „dead letter queue“
Nově nakonfigurovaný konektor si pochopitelně opět otestujeme. Nejdříve konektor spustíme, a to prakticky stejným způsobem, jako konektory předchozí:
$ bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-sink-4.properties
Nyní do tématu connect-test-json pošleme několik zpráv přes producenta ovládaného z příkazové řádky:
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic connect-test-json -property parse.key=true --property key.separator=;
Zprávy poslané do tématu a zapsané na příkazovou řádku:
>{"1st":1}
>{"2nd":2}
>{"improper":message}
>{"id":this-is-not-valid-too}
>"proper one"
>xyzzy
Po ukončení producenta klávesovou zkratkou CTRL+D si opět prohlédneme soubor, do něhož by se měly ukládat pouze korektní zprávy:
$ cat test.sink4.jsons
Soubor by měl vypadat takto:
{1st=1}
{2nd=2}
proper one
Ovšem navíc si můžeme prohlédnout i obsah tématu nazvaného dlq_bad_jsons, do něhož by měly být uloženy všechny nekorektní zprávy. Konzumaci zpráv začneme od zprávy první:
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic dlq_bad_jsons --partition 0 --offset earliest
Vypsat by se měly tyto tři řádky:
{"id":this-is-not-valid-too}
{"improper":message}
xyzzy
V tomto případě je ovšem výhodnější použít nástroj Kafkacat a netrápit se s uváděním offsetů a oddílů:
$ kafkacat -b localhost:9092 -t dlq_bad_jsons -C
Zprávy se vypíšou i s hlavičkou:
{"id":this-is-not-valid-too}
{"improper":message}
xyzzy
% Reached end of topic dlq_bad_jsons [0] at offset 6
Výpis podrobnějších informací (prakticky všech zjistitelných informací o zprávě) nám zajistí příkaz:
kafkacat -b localhost:9092 -t dlq_bad_jsons -C \ -f '\nKey (%K bytes): %k Value (%S bytes): %s Timestamp: %T Partition: %p Offset: %o Headers: %h\n'
Příklad výstupu:
Key (0 bytes):
Value (28 bytes): {"id":this-is-not-valid-too}
Timestamp: 1675703045452
Partition: 0
Offset: 3
Headers:
Key (0 bytes):
Value (20 bytes): {"improper":message}
Timestamp: 1675765176990
Partition: 0
Offset: 4
Headers:
Key (0 bytes):
Value (5 bytes): xyzzy
Timestamp: 1675765183798
Partition: 0
Offset: 5
Headers:
18. Obsah druhé části článku
Ve druhé části článku o frameworku Kafka Connect se nejdříve seznámíme s jednoduchým zdrojem zpráv realizovaným (například) obsahem zvoleného textového souboru:
name=local-file-source connector.class=FileStreamSource tasks.max=1 file=test.txt topic=connect-test
V mnoha oblastech je důležitá i kontrola formátu zprávy oproti zadanému schématu (tedy validace). Ukážeme si tedy způsob kontroly zpráv, což lze realizovat například takto nakonfigurovaným konektorem (ve skutečnosti bude konfigurace nepatrně složitější):
name=local-file-sink-json connector.class=FileStreamSink tasks.max=1 file=test.sink4.jsons topics=connect-test-json key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable=true value.converter.schemas.enable=true errors.tolerance=all errors.deadletterqueue.topic.name=dlq_bad_jsons errors.deadletterqueue.topic.replication.factor=1
A konečně si ukážeme, jak lze použít konektor pro parsing obsahu zpráv s jejich uložením do relační databáze. Použijeme konfigurační soubor, který bude zhruba vypadat následovně:
name=db-sink connector.class=io.confluent.connect.jdbc.JdbcSinkConnector tasks.max=1 topics=connect-test-3 key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable=true value.converter.schemas.enable=true connection.url=jdbc:postgresql://localhost:5432/kafka_sink?user=postgres&password=postgres auto.create=true delete.enabled=false
19. Příloha: nástroj Kafkacat (Kcat)
V předchozím textu jsme několikrát použili nástroj, který se jmenoval Kafkacat; v současnosti však došlo k jeho přejmenování na Kcat (jak jsem již psal výše, důvody pro přejmenování jsou poněkud absurdní). Tento nástroj, který jeho autoři taktéž označují jako „netcat for Apache Kafka“, a jenž slouží pro komunikaci s brokery přímo z příkazové řádky, naleznete na adrese https://github.com/edenhill/kafkacat.
Pochopitelně se s velkou pravděpodobností nebude jednat o řešení používané v produkčním kódu, ovšem možnost vytvořit producenta zpráv či jejich konzumenta přímo z CLI je vítaná jak při vývoji, tak i při řešení problémů, které mohou při běhu aplikace nastat (my Kafkacat mimochodem používáme i v integračních testech). Tento nástroj budeme volat i v navazujícím článku, a to konkrétně při ukázkách nasazení Apache Kafky a Kafka Connectu, takže se v této kapitole krátce zmiňme o příkladech použití převzatých z oficiální dokumentace. Všechny ukázky předpokládají, že broker je již spuštěn na lokálním počítači, a to konkrétně na portu 9092.
Výpis informací o všech tématech a jejich konfigurace:
$ kafkacat -L -b localhost:9092
Spuštění nového producenta zpráv čtených ze souborů specifikovaných na příkazové řádce:
$ kafkacat -P -b localhost:9092 -t filedrop -p 0 file1.bin file2.txt /etc/motd dalsi_soubor.tgz
Přečtení posledních 1000 zpráv z tématu „téma1“. Po této operaci se konzument automaticky ukončí, tj. nebude čekat na další zprávy:
$ kafkacat -C -b localhost:9092 -t tema1 -p 0 -o -1000 -e
Spuštění konzumentů, kteří jsou přihlášení k tématu „téma1“:
$ kafkacat -b localhost:9092 -G skupina_konzumentů téma1
Přihlásit se lze i k odběru většího množství témat:
$ kafkacat -b localhost:9092 -G skupina_konzumentů téma1 téma2
Nástroj kafkacat je možné použít společně s producenty a konzumenty, s nimiž se setkáme v navazujících kapitolách. Ve všech demonstračních příkladech budeme používat téma (topic) nazvaný „upload“.
Konzument zpráv posílaných do tématu „upload“:

$ kafkacat -C -b localhost:9092 -t "upload"
Producent zpráv zapisovaných na standardní vstup uživatelem (co zpráva, to jeden řádek):
$ kafkacat -P -b localhost:9092 -t "upload"
Dtto, ale u každé zprávy lze specifikovat i klíč oddělený od těla zprávy dvojtečkou:
$ kafkacat -P -b localhost:9092 -t "upload" -K:
20. Odkazy na Internetu
- Kafka Connect and Schemas
https://rmoff.net/2020/01/22/kafka-connect-and-schemas/ - JSON and schemas
https://www.confluent.io/blog/kafka-connect-deep-dive-converters-serialization-explained/#json-schemas - What, why, when to use Apache Kafka, with an example
https://www.startdataengineering.com/post/what-why-and-how-apache-kafka/ - When NOT to use Apache Kafka?
https://www.kai-waehner.de/blog/2022/01/04/when-not-to-use-apache-kafka/ - Microservices: The Rise Of Kafka
https://movio.co/blog/microservices-rise-kafka/ - Building a Microservices Ecosystem with Kafka Streams and KSQL
https://www.confluent.io/blog/building-a-microservices-ecosystem-with-kafka-streams-and-ksql/ - An introduction to Apache Kafka and microservices communication
https://medium.com/@ulymarins/an-introduction-to-apache-kafka-and-microservices-communication-bf0a0966d63 - kappa-architecture.com
http://milinda.pathirage.org/kappa-architecture.com/ - Questioning the Lambda Architecture
https://www.oreilly.com/ideas/questioning-the-lambda-architecture - Lambda architecture
https://en.wikipedia.org/wiki/Lambda_architecture - Kafka – ecosystem (Wiki)
https://cwiki.apache.org/confluence/display/KAFKA/Ecosystem - The Kafka Ecosystem – Kafka Core, Kafka Streams, Kafka Connect, Kafka REST Proxy, and the Schema Registry
http://cloudurable.com/blog/kafka-ecosystem/index.html - A Kafka Operator for Kubernetes
https://github.com/krallistic/kafka-operator - Kafka Streams
https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Streams - Kafka Streams
http://kafka.apache.org/documentation/streams/ - Kafka Streams (FAQ)
https://cwiki.apache.org/confluence/display/KAFKA/FAQ#FAQ-Streams - Event stream processing
https://en.wikipedia.org/wiki/Event_stream_processing - Part 1: Apache Kafka for beginners – What is Apache Kafka?
https://www.cloudkarafka.com/blog/2016–11–30-part1-kafka-for-beginners-what-is-apache-kafka.html - What are some alternatives to Apache Kafka?
https://www.quora.com/What-are-some-alternatives-to-Apache-Kafka - What is the best alternative to Kafka?
https://www.slant.co/options/961/alternatives/~kafka-alternatives - A super quick comparison between Kafka and Message Queues
https://hackernoon.com/a-super-quick-comparison-between-kafka-and-message-queues-e69742d855a8?gi=e965191e72d0 - Kafka Queuing: Kafka as a Messaging System
https://dzone.com/articles/kafka-queuing-kafka-as-a-messaging-system - Configure Self-Managed Connectors
https://docs.confluent.io/kafka-connectors/self-managed/configuring.html#configure-self-managed-connectors - Schema Evolution and Compatibility
https://docs.confluent.io/platform/current/schema-registry/avro.html#schema-evolution-and-compatibility - Configuring Key and Value Converters
https://docs.confluent.io/kafka-connectors/self-managed/userguide.html#configuring-key-and-value-converters - Introduction to Kafka Connectors
https://www.baeldung.com/kafka-connectors-guide - Kafka CLI: command to list all consumer groups for a topic?
https://stackoverflow.com/questions/63883999/kafka-cli-command-to-list-all-consumer-groups-for-a-topic - Java Property File Processing
https://www.w3resource.com/java-tutorial/java-propertyfile-processing.php - Skipping bad records with the Kafka Connect JDBC sink connector
https://rmoff.net/2019/10/15/skipping-bad-records-with-the-kafka-connect-jdbc-sink-connector/ - Kafka Connect Deep Dive – Error Handling and Dead Letter Queues
https://www.confluent.io/blog/kafka-connect-deep-dive-error-handling-dead-letter-queues/ - Errors and Dead Letter Queues
https://developer.confluent.io/learn-kafka/kafka-connect/error-handling-and-dead-letter-queues/ - Confluent Cloud Dead Letter Queue
https://docs.confluent.io/cloud/current/connectors/dead-letter-queue.html - Dead Letter Queues (DLQs) in Kafka
https://medium.com/@sannidhi.s.t/dead-letter-queues-dlqs-in-kafka-afb4b6835309


























