
Obě výše uvedené možnosti spadají do oblasti, které se obecnou zkratkou říká ORM (object-relational mapping). Jedná se o trochu odlišný způsob propojení JavaFX (nebo nějaké jiné) aplikace s databází pomocí mapování relačních objektů v databázi na objekty běžně přístupné v dané aplikaci. Pro tuto oblast je k dispozici poměrně velké množství aplikací a frameworků, jak to ukazuje např. přehled zde: ORM software for Java
My si z celé této palety (a to v přehledu určitě nejsou zahrnuté všechny dostupné možnosti) vybereme dva odlišné zástupce. Jako první to bude poměrně mladý projekt JOOQ a druhým bude již dlouho dobu známý a velmi intenzivně využívaný framework Hibernate. Ten si necháme na později a v tomto dílu se zaměříme na JOOQ. V daném případě se vlastně ani nejedná o „čistokrevný“ ORM systém, jak už napovídá celý název projektu: Java Object Oriented Querying. To znamená, že se zde databázové dotazy řeší pomocí objektově orientovaných příkazů jazyka JavaFX. Jedná se sice o poměrně „mladý“ projekt, ale je stále vyvíjen a je možné dokonce získat placené verze a profesionální firemní podporu. My v našem seriálu budeme samozřejmě používat komunitní verzi, která je také k dispozici. Vlastní projekt je k nalezení zde: Web JOOQ. Stažení a přehled cen placených verzí je zde: JOOQ Download/Pricing a informace o možnostech podpory zde: JOOQ Support.
Když už jsme u těch webových odkazů, tak si uvedeme ještě další dva, které ukazují na rozdíly mezi oběma probíranými projekty a případy, kdy použít jeden z nich nebo i jejich kombinaci. Zde je stručně popsaný rozdíl při různém využití: JOOQ vs Hibernate. Zde jsou pak popsány možnosti obou projektů při volbě doménového nebo relačního modelu: Hibernate alternative. Je samozřejmě možné najít mnohem víc informací o srovnání obou projektů, ale tím se zde již nebudeme zabývat. Spíše se podíváme na to, proč byl vybrán zrovna projekt JOOQ:
- jedná se o systém, který tvůrcům aplikací umožní vytvořit velmi dobře čitelné a přehledné SQL dotazy
- dotazy se tvoří velmi rychle a jednoduše
- dotazy se tvoří pomocí standardních nástrojů jazyka JavaFX a je k nim k dispozici dobrá kontextová nápověda
- projekt má k dispozici vlastní generátor javovských tříd, které jsou nutné k provozu aplikace
- jsou zde k dispozici nástroje pro řízení „životního cyklu“ dotazu, jako je např. uživatelské logování, řízení transakcí, spouštěče událostí a SQL transformace
- jsou k dispozici nástroje pro snadné provádění součástí CRUD pomocí tzv. aktivních záznamů
- jsou k dispozici nástroje pro volání uložených databázových procedur a funkcí
- komunitní verze umožňuje bezproblémovou práci s Open Source databázemi
- v případě potřeby je možné získat placené verze, které pracují s enterprise databázemi a k nim firemní podporu
- je k dispozici rozsáhlý systém návodů, nápovědy, komunitní podpory atd.
Uvedený výčet by asi mohl být v tomto rozsahu dostatečný a my se můžeme pustit do konkrétnějších informací o JOOQ a zkusit si první kroky, které povedou k jeho využití v naší ukázkové aplikaci. Obecně se budeme snažit, abychom ve stručnější formě a podobě vytvořili kompletní CRUD systém pro ukázkovou databázi udaje. Tedy vlastně to, co jsme v minulé kapitole a několika dílech vyzkoušeli a předvedli pomocí klasických SQL dotazů. Jako první asi každého napadne, že je nutné stáhnout nějaké soubory ze stránek projektu. My to ale ještě chvíli necháme stranou a zaměříme se na jednu výše uvedenou vlastnost JOOQ – integrovaný generátor aplikačních tříd. Generování je možné provádět dvojím způsobem:
- využít samostatné třídy z projektu JOOQ a vytvořit aplikační třídy „externě“, tedy mimo vlastní aplikaci
- pro generování aplikačních tříd využít samotnou aplikaci
První možnost je velmi podrobně popsána v manuálu: Code Generator Extern. Vlastní generování sestává ze dvou kroků, kdy se v prvním vytvoří XML soubor, který umožní generátoru připojení k databázi a nastaví vlastnosti pro generované aplikační třídy. Druhým krokem je pak spuštění konzolového příkazu, kde se provede samotné generování za pomocí tříd JOOQ a databázového konektoru. Zde je tato varianta popsána ještě trochu podrobněji: Code Generation. Kromě uvedené možnosti jsou zde popsány ještě další varianty, jak generovat aplikační třídy: pomocí prostředí Eclipse a nástrojů Maven, Ant a Gradle. Zájemci se zde mohou dozvědět opravdu hodně zajímavých a přínosných informací.
My ale tuto variantu používat nebudeme a na výše uvedeném odkazu přejdeme až skoro nakonec (konkrétně do odstavce 6.5), kde je popsaný druhý způsob, který v naší aplikaci použijeme a blíže si popíšeme. Abychom byli úplně přesní, jsou zde vlastně také dvě možnosti:
- využít pouze standardní možnosti jazyka a vše řešit programově
- využít XML soubor s nastavením a připojením a programově ho využít
Aby bylo generování co možná nejjasnější, tak použijeme standardní příkazy. Výhoda je zde i v tom, že příklad je vytvořen konkrétně pro PG databázi, kterou samozřejmě budeme dále využívat. Než ale budeme moci ukázkový kód použít, upravit a spustit, musíme na to připravit naší zkušební aplikaci. Otevřeme si tedy JFXSB a v minulých dílech použitý soubor samExam4.fxml. Ten uložíme pod novým názvem samExam5.fxml a uložíme do adresáře GUI-Files. Jediné, co je třeba změnit, je název kontroléru, kde nahradíme čtyřku pětkou, takže bude mít hodnotu jfxapp.samexam5. Necháme si zobrazit kostru kontroléru a uložíme si variantu Full.
Pak už otevřeme IJI, vytvoříme novou třídu s názvem samexam5.java, vložíme do ní kód z kostry kontroléru, doplníme potřebné importy a pod příslušné tlačítko vložíme volání nového formuláře s ukázkovou úlohou číslo 5. Ještě můžeme zkusit takto upravenou aplikaci přeložit a nový formulář otevřít, abychom měli jistotu, že vše funguje bez problémů. Pokud je vše v pořádku, můžeme použít ukázkový kód z manuálu a upravit ho do námi požadovaného stavu:
private void code_Gener() {
Configuration configuration = new Configuration() //1
.withJdbc(new Jdbc() //2
.withDriver("org.postgresql.Driver") //3
.withUrl("jdbc:postgresql://127.0.0.1:5432/fxguidedb") //4
.withUser("fxguide") //5
.withPassword("fxguide")) //6
.withGenerator(new Generator() //7
.withDatabase(new Database() //8
.withName("org.jooq.util.postgres.PostgresDatabase") //9
.withIncludes("udaje.*") //10
.withExcludes("") //11
.withInputSchema("public")) //12
.withTarget(new Target() //13
.withPackageName("jfxapp") //14
.withDirectory(""))); //15
try { //16
GenerationTool.generate(configuration); //17
} catch (Exception e) { e.printStackTrace(); } } //18
Pokud budeme kód kopírovat z manuálu, nesmíme zapomenout na příslušné importy. Problém je ale v tom, že zatím nemáme co importovat… Musíme si tedy stáhnout příslušný archiv s aktuální verzí JOOQ – jOOQ-3.7.1.zip a někam ho rozbalit. Je to z toho důvodu, že budeme potřebovat pouze tři soubory z adresáře /jOOQ-3.7.1/jOOQ-lib/ – jooq-3.7.1.jar, jooq-codegen-3.7.1.jar, jooq-meta-3.7.1.jar. Tyto soubory zkopírujeme do aplikačního adresáře libs. Tím pádem je již co importovat, a tak můžeme přidat příslušné knihovny:
import org.jooq.util.GenerationTool; import org.jooq.util.jaxb.*; import java.sql.Connection; import java.sql.DriverManager; import java.sql.SQLException;
Při úpravě kódu generační procedury musíme dbát na to, aby s výjimkou databázového konektoru byly všechny proměnné vztažené k projektu JOOQ!. Pokud máme všechny problémy vyřešené, můžeme si podrobněji představit proceduru:
- řádek – deklaruje se proměnná pro konfiguraci připojení k databázi. Generátor musí mít samozřejmě do databáze přístup, aby mohl použít dostupné informace o relačních objektech v ní
- řádek – připojení se bude provádět pomocí obecného JDBC konektoru, který je zde deklarován
- řádek – definuje se konkrétní DB konektor, v našem případě samozřejmě PG
- řádek – definuje se konkrétní napojení do PG včetně požadované databáze
- řádek – definuje se uživatelské jméno pro přístup k vybrané databázi
- řádek – definuje se uživatelské heslo pro přístup k vybrané databázi
- řádek – deklaruje se nová proměnná pro generátor
- řádek – deklaruje se nová proměnná pro vybranou databázi
- řádek – definuje se tzv. databázový dialekt. K nim se ještě dostaneme v dalším textu
- řádek – definuje se konkrétní tabulka (tabulky, vše), pro které chceme generovat aplikační třídy
- řádek – může se naopak definovat vše, co se má z generování vynechat
- řádek – definuje se tzv. databázové schéma. Pro PG je to prakticky vždy uvedená hodnota public
- řádek – deklaruje se nová proměnná, která určuje místo v adresářové struktuře projektu
- řádek – definuje se název balíčku pro příslušnost nově generovaných tříd. V našem případě je použita hodnoty, která odpovídá vrcholovému balíčku aplikace
- řádek – definuje se adresář, do kterého se mají generované třídy uložit. V našem případě je to kořenový adresář vrcholového balíčku
- řádek – začátek sekce pro zachycení výjimek
- řádek – provádí se vlastní běh generátoru a vytvoření aplikačních tříd
- řádek – zachycení a zobrazení případné výjimky. Pokud bychom nechali řádek se startem generátoru tak, jak je v příkladu manuálu, IJI hlásí chybu. Je tedy nutné přidat sekci pro zachycení výjimek a pak je vše v pořádku
V popisu procedury jsme narazili na pojem databázový dialekt. Jedná se vlastně o to, s jakými databázemi je JOOQ možné propojit. Jejich přehled je uveden na výše zmíněná stránce v manuálu v popisu konfiguračního XML souboru. Bez dalšího komentáře zde uvedeme pouze přehled dialektů, ze kterého je jasné, že možnosti jsou opravdu zajímavé:
org.jooq.util.ase.ASEDatabase, org.jooq.util.cubrid.CUBRIDDatabase, org.jooq.util.db2.DB2Database, org.jooq.util.derby.DerbyDatabase, org.jooq.util.firebird.FirebirdDatabase, org.jooq.util.h2.H2Database, org.jooq.util.hsqldb.HSQLDBDatabase, org.jooq.util.informix.InformixDatabase, org.jooq.util.ingres.IngresDatabase, org.jooq.util.mariadb.MariaDBDatabase, org.jooq.util.mysql.MySQLDatabase, org.jooq.util.oracle.OracleDatabase, org.jooq.util.postgres.PostgresDatabase, org.jooq.util.sqlite.SQLiteDatabase, org.jooq.util.sqlserver.SQLServerDatabase, org.jooq.util.sybase.SybaseDatabase
Kromě těchto nativních dialektů je možné použít ještě dva obecnější. První z nich slouží třeba pro reverzní engeneering generických JDBC metadat (např. pro MS Access atd):
org.jooq.util.jdbc.JDBCDatabase
Druhá možnost slouží k podobnému účelu, ale pro metadata uložená v XML formátu:
org.jooq.util.xml.XMLDatabase
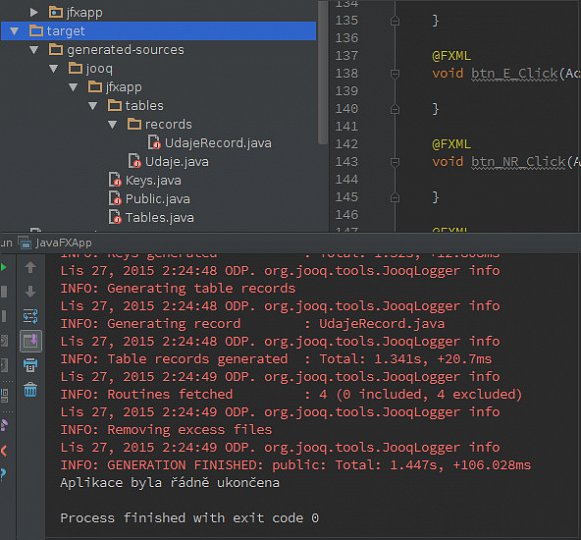

Volání generační procedury přiřadíme k akci nějakého vybraného tlačítka, aplikaci spustíme a klikneme na příslušné tlačítko. Ve spodní konzole se objeví spousta textového výstupu, který vyplivl spuštěný generátor. Jeho ukázka je i v manuálu, takže nemá smysl to více komentovat. Pokud se pak formulář a aplikace zavřou, objeví se nový adresář s názvem target, jak to ukazuje první obrázek v galerii. Adresář se nachází v hlavním adresáři aplikace. Bylo by samozřejmě možné ho umístit i někam jinak (za pomoci parametrů v generační proceduře), ale jak uvidíme později, nemělo by to valný smysl. Z obrázku je patrné, že vznikla celá adresářová struktura, ale pro naše potřeby jsou zásadní tyto soubory a adresáře:
- soubory Keys.java, Public.java, Tables.java v podadresáři ../jfxapp
- soubor Udaje.java v podadresáři ../jfxapp/tables
- soubor UdajeRecord.java v podadresáři ../jfxapp/tables/records
Pro správnou funkce aplikace s aplikačními třídami je nutné tři samostatné soubory přesunout či zkopírovat do adresáře ../src/jfxapp a tamtéž přesunout či zkopírovat celý adresář tables. Výsledná struktura projektu je pak vidět na druhém obrázku galerie. Vygenerovaný adresář target můžeme nechat na místě nebo ho klidně smazat, protože ho už více nebudeme potřebovat. Generování je totiž jednorázovým krokem, který není nutné opakovat, pokud se nějak nezměnila struktura připojované databáze (nové tabulky, změna jejich struktury atd.). Abychom si mohli vygenerované třídy vyzkoušet, pokusíme se do tabulky vyslat dotaz, který nám zobrazí vybrané údaje. K tomu potřebujeme udělat tři jednoduché a jeden trochu složitější krok:
- přidat do třídy deklarace dvou proměnných (kopie z minule používané třídy):
private Connection CONN = null; private String host = "jdbc:postgresql://127.0.0.1:5432/fxguidedb";
Když už máme definované připojení k databázi, můžeme v generační proceduře nahradit příslušný řádek:
.withUrl(host)
- zpřístupnit tabulku, pro kterou jsme generovali aplikační třídy (vybrali jsme pouze jednu). To se provede statickým importem příslušné třídy:
import static jfxapp.Tables.UDAJE;
- z minulé úlohy zkopírovat funkci connDB pro připojení do PG databáze
- vytvořit výkonnou proceduru, která do databáze pošle dotaz a jeho výsledky zobrazí zatím v textové konzole
Jako základ výkonné procedury použijeme příklady, které najdeme v PDF verzi manuálu. Tam je od strany 20 kapitola 3.4.1 jOOQ in 7 easy steps. My už máme první 4 kroky hotové a tak si vezmeme za základ kroky 5 (kapitola 3.4.1.5 Querying) a 6 (kapitola 3.4.1.6 Iterating) na straně 24. Procedura pak může vypadat třeba takto:
private void jooq_Query() {
DSLContext create = DSL.using(connDB("fxguide", "fxguide"), SQLDialect.POSTGRES);
Result<Record> result = create.select().from(UDAJE).fetch();
for (Record r : result) {
Short id = r.getValue(UDAJE.ID);
String str = r.getValue(UDAJE.RETEZEC);
Date dtm = r.getValue(UDAJE.DATUM);
System.out.println("ID= " + id.toString() + " String: " + str + " Datum= " + dtm); } }
Procedura má celkem 3 sekce:
- první řádek deklaruje připojení pomocí propojovací funkce (parametry jsou uživatelské jméno a heslo) a dalšího nastavení DB dialektu. Druhý příkaz obsahuje deklaraci a definici výsledku záznamů, který vznikl na základě databázového dotazu a posledního příkazu pro jeho volání
- ve druhé sekci je iterace přes získaný záznam výsledků a definuje jednotlivé položky tabulky
- poslední sekci pak představuje příkaz pro výpis jednotlivých řádků celkového výsledku do konzole
V této souvislosti se nyní vrátíme ke generovaným aplikačním třídám, které jsme si doposud pouze vyjmenovali. Nějaký jejich hlubší rozbor není nutný (jsou přece generované a není nutné je ručně upravovat), ale stručně si je popíšeme:
- Keys – jak název již sám napovídá, zde jsou definovány klíčové položky tabulky (primární a unikátní klíče)
- Public – definice databázového schématu
- Tables – definice všech dotčených tabulek. V našem případě pouze jedna, deklarovaná pomocí velkých písmen (UDAJE)
- Udaje – definice všech položek tabulky. Je třeba si všimnout, že pole ID je generováno jako Short (nikoliv Integer, ale to určitě odpovídá databázovému typ Small Integer). Desetinná čísla pak mají typ math.BigDecimal, což opět koresponduje s databázovým typem Numeric
- UdajeRecord – zde jsou definice všech položek databázového záznamu včetně obvyklých Getterů/Setterů – Gett/Sett 1, Gett/Sett 2
Krátký rozbor generovaných tříd tak ukazuje, proč se musí v „dotazu“ použít název tabulky velkými písmeny a proč musí být položky ID typu Short (při snaze definovat jí jako Integer IJI trvá na chybě!). Po krátkém objasnění obsahu generovaných tříd můžeme výkonnou proceduru přiřadit nějakému tlačítku, spustit aplikaci a pokusit se o zobrazení výsledků jednoduchého dotazu. Výsledek se skutečně dostaví a je viditelný na třetím obrázku v galerii. Z obrázku je patrné, že byly zobrazeny všechny záznamy z tabulky a že výpis není seřazený podle pořadových čísel. Proto si trochu upravíme definici dotazu a zároveň s tím si ukážeme, jak jednoduše se dají tvořit. Velmi zajímavou výhodou je zde perfektní nápověda, kterou má na svědomí IJI společně s projektem JOOQ:
Result<Record> result = create
.select()
.from(UDAJE)
.where(UDAJE.ID.lt((short) 10))
.orderBy(UDAJE.ID)
.fetch();
Je důležité si všimnout, že zadaná hodnota pro omezení počtu zobrazených záznamů musí být převedena na typ Short (opět velmi jednoduše pomůže IJI a udělá to za nás pouze kliknutím na příslušnou volbu při zobrazení chyby). Výsledek změněného dotazu je vidět na čtvrtém obrázku galerie. Nakonec můžeme definovat všechny položky v tabulce a také je zobrazit:

for (Record r : result) {
Short id = r.getValue(UDAJE.ID);
Integer cis = r.getValue(UDAJE.CELECIS);
BigDecimal des = r.getValue(UDAJE.DESCIS);
BigDecimal mad = r.getValue(UDAJE.MALEDES);
String str = r.getValue(UDAJE.RETEZEC);
Date dtm = r.getValue(UDAJE.DATUM);
System.out.println("ID= " + id.toString() + " Cele= " + cis.toString() + " Desetinne= " + des.toString()
+ " Male des.= " + mad.toString() + " String: " + str + " Datum= " + dtm);
Výsledek změny je vidět na posledním obrázku v galerii. Na závěr dáváme do přílohy všechny nové třídy včetně těch generovaných: Keys.java, Public.java, samexam5.java, Tables.java, Udaje.java a UdajeRecord.java.
V dnešním dílu jsme se zaměřili na úvod do problematiky ORM a základní popis projektu JOOQ. také jsme si ukázali jednoduchý příklad pro výpis obsahu tabulky do konzole. V příštím dílu se pustíme do jednoduššího způsobu uložení výsledků dotazů. Tuto variantu zobecníme tak, abychom si mohli zobrazit výsledky dotazu ve widgetu tabulky. Také si ukážeme další součást CRUD – mazání záznamů.
