Minule jsme ukončili ukázky z aktualizace záznamů a můžeme se tedy vrhnout na další položku CRUD – ukládání nových záznamů do tabulky. Ještě než se do toho pustíme, musíme si vyjasnit jednu věc. Když jsme prováděli aktualizace záznamů, měli jsme jeden „pevný bod“ – položku s klíčovým polem tabulky. Ta byla neměnná a hlavně uživatelsky nepřístupná. Při vkládání nových záznamů ale tato možnost není, resp. je to o trochu složitější. Mohli bychom samozřejmě nechat zadání klíčové položky čistě na uživateli, ale asi je na první pohled jasné, že by to nebylo úplně šťastné řešení. Kdyby se mu totiž povedlo zadat položku nesprávně, mohlo by dojít k chybě při uložení záznamu a nebo ještě hůř – k uložení záznamu nekorektního až nesmyslného. Je také jasné, že by se mohlo nasadit řešení z minulých dílů – důsledná kontrola obsahu a formátu příslušného editačního pole. To by ale bylo celkem složité a i docela otravné, takže by bylo vhodné najít nějaké jiné řešení.
Takové řešení samozřejmě existuje a my si ho postupně představíme. Vyjdeme z několika skutečností:
- při manipulaci s tabulkou se mohou záznamy obecně mazat i vkládat
- při klíčové položce tabulky je nutné, aby její hodnota měla v tabulce unikátní hodnotu
- při stanovení unikátní hodnoty je nejjednodušší najít maximální hodnotu klíčové položky v aktuálním stavu tabulky a pro vkládaný záznam ji zvýšit o nějakou hodnotu
- i když dojde ke smazání posledního aktuálního záznamu, uložení nového se stejnou hodnotou klíčové položky bude bez problémů
- navržené řešení by mělo být platné hlavně pro celočíselné klíčové položky
- navržené řešení by mělo být jednodušší než porovnávání nově zadané hodnoty klíčové položky s ostatními hodnotami položky v tabulce
Na základě předchozích úvah můžeme tedy navrhnout jedno z možných řešení:
- editační pole s klíčovou položkou tabulky bude uživatelsky nepřístupné a jeho hodnota se bude vkládat programově
- při vkládání nového záznamu se zjistí maximální hodnota klíčové položky v tabulce (v našem konkrétním případě má formát SMALL INTEGER)
- zjištěná hodnota se zvýší o 1 a nová hodnota se uloží do příslušného editačního pole
- při ukládání nového záznamu tak máme jistotu, že hodnota klíčové položky je v tabulce unikátní
Pokud se na předchozí 4 body podíváme trochu blíže, tak zjistíme následující:
- pro tento požadavek již máme řešení a použili jsme ho při aktualizaci záznamů. Takže žádný problém
- není samozřejmě nijak zásadně složité SQL dotazem zjistit hodnotu libovolné položky v tabulce. My to ale budeme mít ještě jednodušší, protože jsme si v jednom z předchozích dílů vytvořili speciální PG funkci pro daný účel
- početní úkony s hodnotami a jejich ukládání do editačních polí také bez problémů zvládneme
- pokud je hodnota klíčové položky takto nastavena, nemusíme provádět žádné kontroly a rovnou ji uložíme s novým záznamem
Jak je z rozboru požadavků patrné, klíčové budou při operaci vkládání záznamů dvě věci – zjištění maximální hodnoty klíčové položky v tabulce a vlastní uložení zadaných hodnot do tabulky. Jako první si ukážeme volání PG funkce, která vrátí maximální hodnotu klíčové položky v tabulce. Pro tento účel použijeme již dříve vytvořenou PG funkci s názvem intCount. Již jsme to sice dělali, ale nyní se trochu podrobněji vrátíme k jejím vlastnostem a uvedeme si ty základní:
- funkce má tři vstupní parametry – název tabulky, název položky v této tabulce a typ operace, kterou požadujeme
- funkce má jeden výstupní parametr, a to je celočíselná hodnota
- funkce zajišťuje čtyři základní operace:
- maximální hodnota ve sloupci – bude plně funkční pro celočíselné i desetinné hodnoty, může fungovat i pro položky s typem datum nebo řetězcové
- minimální hodnota ve sloupci – platí stejný rozsah, jako u maxima
- počet položek ve sloupci – platí pro všechny typy sloupců
- součet hodnot ve sloupci – platí pro celočíselné a desetinné hodnoty
- možnosti využití PG funkcí (max, mim, count, sum) samozřejmě platí obecně, jak bylo uvedeno výše. Vzhledem k tomu, že samotná PG funkce má výstupní hodnotu celočíselnou, můžeme ji využít pouze pro sloupce tohoto typu
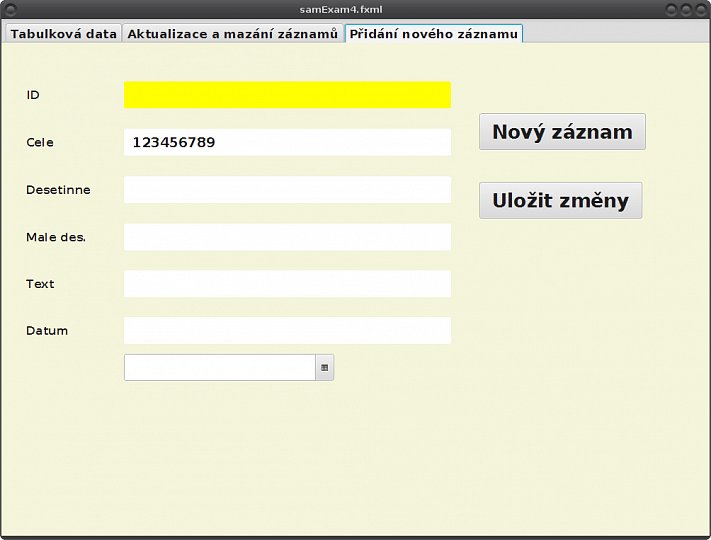

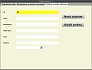
Abychom mohli začít s ukázkou PG funkce, musíme si ve třetí záložce našeho formuláře připravit příslušné widgety. Velmi jednoduše k tomu využijeme to, co máme ve druhé záložce pro aktualizaci záznamů. Odtud v JFXSB prostě všechno překopírujeme, smažeme dvě tlačítka, změníme názvy editačních polí, tlačítek a jejich akcí a přidáme jednu maličkost. Výsledek vidíme na prvním obrázku v galerii. Zobrazíme si kostru kontroléru a nové položky překopírujeme do příslušné třídy samexam4.java. Úspěšnost vyzkoušíme spuštěním aplikace a zobrazením příslušné záložky, jak to ukazuje druhý obrázek galerie. Do přílohy pak dáváme kompletní FXML soubor: samExam4.fxml.
Tím máme vše připraveno a můžeme se pustit do kódování. Budeme potřebovat funkci pro volání PG funkce a proceduru pro inicializaci vkládání záznamů. Do této třídy si vložíme zatím jediný příkaz, který do editačního pole n_ID vloží novou hodnotu klíčové položky. Volací funkce vypadá asi nějak takto:
private Integer maxKFV(final String tablename, final String colname, final Integer type) { //1
CallableStatement maxID = null; //2
Integer maxid = 0; //3
CONN = connDB("fxguide", "fxguide"); //4
try { maxID = CONN.prepareCall("{?=call intcount(?,?,?)}"); //5
maxID.registerOutParameter(1, Types.INTEGER); //6
maxID.setString(2,tablename); //7
maxID.setString(3,colname); //8
maxID.setInt(4,type); //9
maxID.execute(); //10
maxid = maxID.getInt(1); //11
} catch (SQLException e) { e.getMessage();
} finally { if (maxID != null) {
try { maxID.close(); }
catch (SQLException e) { e.getMessage(); }
try { CONN.close(); }
catch (SQLException e) { e.getMessage(); }} }
return maxid; } //12
Volání PG funkce jsme sice již prováděli, ale tato je trochu odlišná, a proto se sluší bližší komentář:
- řádek – funkce je celočíselného typu a má tři formální parametry stejné jako PG funkce
- řádek – jak je obvyklé při volání PG funkce, musíme použít jiný typ příkazu a deklarujeme ho právě zde
- řádek – deklarace návratové proměnné funkce
- řádek – klasicky se funkce přihlašuje k databázi
- řádek – připravuje se volání PG funkce. Zde je třeba si všimnout nejenom třech otazníků v parametrech PG funkce (to už známe…), ale hlavně toho před jejím voláním. Ten totiž představuje návratovou hodnotu PG funkce
- řádek – zde se právě deklaruje pořadí a typ výstupního parametru. Je samozřejmě první v pořadí a celočíselného typu. Typ musí být stejný, jako je typ návratové hodnoty PG funkce
- řádek – deklaruje se parametr pro název tabulky
- řádek – deklaruje se parametr pro název sloupce dané tabulky
- řádek – deklaruje se parametr pro typ operace. Všechny parametry musí mít stejný typ, jako mají formální parametry PG funkce!
- řádek – provádí se volání PG funkce
- řádek – výsledek volání PG funkce se přiřazuje do deklarované proměnné
- řádek – deklarovaná proměnná se vrací jako návratová hodnota výkonné funkce
Výkonnou funkci tedy máme připravenou a můžeme se pustit do funkce pro inicializaci vkládání záznamu. Ta bude v této fázi velmi jednoduchá:
pid = maxKFV("udaje", "id", 0) + 1;
n_ID.setText(pid.toString());
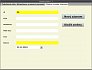
V prvním řádku používáme deklarovanou proměnnou celočíselného typu a vkládáme do ní výsledek z výkonné funkce zvětšený o 1. Používáme zde skutečné parametry pro název tabulky a sloupce a také příslušný typ operace (0=max, 1=min, 2=count, 3=sum). Druhý příkaz vkládá nově získanou hodnotu do příslušného editačního pole. Volání této procedury vložíme do akce příslušného tlačítka (Nový záznam) a můžeme dosavadní snažení vyzkoušet spuštěním aplikace a kliknutím na toto tlačítko. Výsledek je patrný ze třetího obrázku v galerii. Pro porovnání se můžeme podívat na zobrazení tabulky v první záložce a přesvědčit se, že poslední záznam má opravdu pořadové číslo 25. Nově vkládaný záznam tedy bude mít pořadové číslo 26, jak to ukazuje obrázek. Ostatní editační pole jsou uživatelsky přístupná a nemusíme je na tomto místě znovu rozebírat. Jejich editaci jsme si ukázali v minulém dílu a tento princip zůstane i zde stejný. Jediné, na co se zaměříme, je poslední editační pole, ve kterém je datum.
Jak bylo zvědavcům jistě patrné z předchozích obrázků, ve formuláři se objevil nový, dosud neznámý widget z balíku Controls s názvem DatePicker. Více informací je o něm možné získat např. zde: JavaFX DatePicker.
My tento widget použijeme pro vložení požadované hodnoty datum v našem malém formuláři. Minule jsme si ukázali ruční vkládání a nyní tedy trochu jinak. V prvním kroku se vrátíme do JFXSB a označíme si pole n_Datum jako uživatelsky nepřístupné (bude také při zobrazení formuláře žluté, jako je pole n_ID). My si na něm ukážeme dvě jednoduché operace. První z nich bude nastavení widgetu na aktuální datum. K tomu stačí do procedury new_Record přidat jeden řádek kódu:
dp_Datum.setValue(java.time.LocalDate.now());
Zde jsme provedli nastavení hodnoty widgetu pomocí funkce ze základního balíku Java a vložili aktuální strojové datum. Výsledek našeho snažení ukazuje čtvrtý obrázek galerie. Pátý obrázek v galerii pak ukazuje, jak to vypadá, když widget otevřeme pomocí ikony vpravo. Objeví se přehledný kalendář, který můžeme použít pro vkládání datových údajů. Je už pak na každém tvůrci a uživateli, jestli použije widget s kalendářem nebo prosté ruční vkládání tak, jak jsem to ukázali minule. Když už tedy máme kalendář před sebou, bylo by vhodné zajistit, aby se vybrané datum přeneslo do příslušného editačního pole. K tomu je nutné do procedury initialize přidat jednoduchou reakci na událost ve widgetu, která při každé změně data ve widgetu vloží příslušnou hodnotu do editačního pole n_Datum:
dp_Datum.setOnAction(event -> {
n_Datum.setText(dp_Datum.getValue().toString());
});
Jak je z kódu zřejmé, je to velmi jednoduché a kromě definice vlastní události je zde jenom přiřazení hodnoty v kalendáři do editačního pole. Šestý obrázek galerie pak ukazuje, co se stane buď při kliknutí na tlačítko Nový záznam (dojde při něm také k události v kalendáři, tj. nastaví se aktuální datum) nebo při volbě nějaké jiné hodnoty z kalendáře. Je také důležité si všimnout formátu obou hodnot. Ve widgetu nebo v kalendáři je formát pro datum takový, na jaký jsme v našich končinách zvyklí, a to je určitě dobře. Hodnota v editačním poli je naopak v takovém formátu, který je jediný možný pro vkládání do tabulky. Pro nás to znamená dvě zásadní věci:
- hodnotu v editačním poli nemusíme pro zobrazení formátovat, protože tu samou hodnotu ve vhodném formátu vidíme v kalendáři
- hodnotu v editačním poli nemusíme pro uložení do tabulky formátovat, protože už v potřebném formátu je
Na základě dosavadní práce již můžeme klidně uvažovat o vytvoření procedury pro uložení nového záznamu ze zadaných hodnot. Ještě předtím si ale přidáme dva řádky kódu do procedury new_Record:
sr_Button.setDisable(false); setFocus(n_Cele);
První příkaz zpřístupní uživateli tlačítko pro uložení nového záznamu a druhý nastaví kurzor na první uživatelsky zadávané editační pole. Procedura pro uložení nového záznamu bude velmi podobná té, kterou jsme minule použili pro uložení změn v záznamech. Bude použita dokonce i stejná výkonná procedura pro uložení dat do tabulky. Kód bude vypadat asi takto:
private void save_Record() {
if (emptyTF(n_ID)) return;
else if (emptyTF(n_Cele)) return;
else if (emptyTF(n_Desetinne)) return;
else if (emptyTF(n_Maledes)) return;
else if (emptyTF(n_Text)) return;
else if (emptyTF(n_Datum)) return;
else if (validLEN(n_Text, 32)) return;
else if (validINT(n_Cele)) return;
else if (validDBL(n_Desetinne)) return;
else if (validDBL(n_Maledes)) return;
else {
dataItems.clear();
dataItems.add(pid);
dataItems.add(n_Cele.getText());
dataItems.add(n_Desetinne.getText());
dataItems.add(n_Maledes.getText());
dataItems.add(n_Text.getText());
dataItems.add(n_Datum.getText());
dataInsert("INSERT INTO udaje VALUES (?,?,?,?,?,?);",
new String[] {"INT", "INT", "DBL", "DBL", "STR", "DTM"},
dataItems);
showFmt();
sr_Button.setDisable(true);
n_ID.setText("");
tabPane.getSelectionModel().select(0); }
}
Vzhledem k podobnosti obou procedur nemá smysl tuto komentovat podrobně po řádcích, takže rozebereme pouze jednotlivé sekce:
- blok kontrol byl rozšířen o editační pole n_ID, kde se kontroluje pouze přítomnost hodnoty. Formát není nutné kontrolovat, protože je zajištěn již programově. Z téhož důvodu mohla být vypuštěna kontrola formátu pole n_Datum. Ostatní kontroly jsou beze změny
- pro uložení obsahu editačních polí do proměnné se pouze změnilo pořadí a vyřadil převod hodnoty u pole n_Datum
- při volání stejné výkonné procedury se samozřejmě liší SQL příkaz vložení záznamu vs. uložení změn ve vybraném záznamu
- při zadání formátu ukládaných údajů se pouze přesune položky ID z posledního na první místo
- v bloku následném po uložení zadaných údajů jsou stejné příkazy pro znovu načtení tabulky a přechod do první záložky na její zobrazení. Nemá smysl zde zadávat příkaz pro nastavení jednotlivých editačních polí pouze pro čtení. Máme na to sice proceduru, ale ta je zaměřena pouze na editační pole pro aktualizaci záznamů. Bylo by samozřejmě možné tuto proceduru přetvořit tak, aby mohla fungovat obecněji, ale tím se již zabývat nebudeme. Také změny v tlačítkách jsou jiné a přibyl jeden příkaz pro vyprázdnění editačního pole n_ID. To je spíše ale jenom pro jistotu…
Novou proceduru přidáme do akce příslušného tlačítka a zkusíme spustit aplikaci a přidat nový záznam. Ukázkové zadání je vidět na sedmém obrázku v galerii, uložení nového záznamu do tabulky pak na osmém obrázku galerie. Devátý obrázek v galerii pak ukazuje, jak vypadá poslední záložka formuláře po uložení nového záznamu. Klíčové pole je prázdné, ale ostatní údaje jsou v editačních polích zachovány beze změny. Poslední obrázek galerie pak ukazuje, že stačí jenom iniciovat nový záznam a ke stávajícím hodnotám editačních polí se přidá i nová hodnota klíčového pole.

Tím bychom mohli ukončit dnešní díl a vlastně i celou kapitolu a do přílohy dát konečnou podobu procedury příslušné ukázkové úlohy: samexam4.java.
V dnešním dílu jsme se ukázali možnosti vkládání nového záznamu do tabulky. Tím jsme vlastně ukončili jednu větší kapitolu, která se zabývala kooperací aplikace JavaFX a databáze PG pomocí standardních SQL příkazů. Od příštího dílu se začneme věnovat jiným možnostem propojení aplikace s PG databází, které můžeme obecně zařadit do oblasti tzv. ORM.























