
Nasazení mechanismu RPKI je však pomalé, a to navzdory jeho technologické vyspělosti, existenci všech potřebných standardů, software i detailní dokumentaci a propagaci standardu ze strany RIPE NCC. Článek se zabývá kvantifikací nasazení mechanismu ROV v současném internetu.
Motivace pro zabezpečení směrování v internetu
V únoru 2008 začal autonomní systém s číslem 17557 (Pakistan Telecommuication company) oznamovat svým sousedům nový prefix 208.65.153.0/24. Tato jinak všední provozní záležitost rozvířila diskuzi o bezpečnosti internetu jako celku, neboť zmíněný prefix byl součástí méně specifického prefixu, který měl tou dobou přidělený YouTube a který obsahoval servery tou dobou zcela klíčové pro doručování obsahu všem, kdo si chtěli na YouTube přehrávat video.
Jedním z fundamentálních aspektů protokolu TCP/IP je pravidlo, že specifičtější cesta vždy vyhrává. Oznámením specifičtější cesty k subnetu se servery YouTube tedy AS17557 přetáhl veškerý světový provoz na tyto klíčové body YouTube do své sítě a tam tento provoz potichu zahodil. Celá příhoda byla vysvětlena jako konfigurační chyba na straně AS17557, který ve snaze splnit příkaz vlády k omezení přístupu k YouTube ve vlastní síti injektoval slepou cestu do své sítě a nedopatřením došlo k redistribuci do protokolu BGP a k oznámení cesty všem sousedům.
Selhali i sousedé, zejména upstreamy, od kterých se očekává ochrana proti podobným konfiguračním chybám v podobě ručně nastavených filtrů, jejichž změna se musí explicitně domluvit, případně i ověřit správnost v databázích regionálních registrářů (RIR), kteří přidělují IP adresy a vedou databáze alokací. Nutno však podotknout, že provozní postupy a udržování oněch filtrů se v různých částech světa značně liší a že i data v databázích alokací nejsou mnohdy v nejlepší kondici. Nastavování filtrů představuje nepříjemnou administrativu spojenou s odhadováním a prověřováním podezřelých údajů s často těžko kontaktovatelnými protistranami. Zkrátka administrativu, kterou technici nedělají rádi a management je málokdy nadšený z nákladů na práci, která sice potenciálně může zabránit velkému problému, ale k němu skoro vždy vůbec nedojde.
V případě incidentu Pakistan Telecom vs. YouTube došlo k celosvětovému výpadku YouTube na dobu několika desítek minut. Tehdy uplatněné řešení situace ze strany YouTube se stalo prototypem pro mnoho následujících incidentů tohoto druhu: V první řadě YouTube oznámil tentýž prefix shodné, tedy specifičtější délky síťové masky, než původní legitimní prefix. Tím se část bližších sítí přesměrovala zpět na skutečný YouTube a z celosvětového výpadku se stal jen výpadek v blízkosti Pakistan Telecomu. Následovalo kontaktování viníků – správců autonomního systému, který oznamoval konfliktní prefixy a i jejich upstreamů, upozornění na problém a následné odfiltrování úniku. Tato cesta se však ukázala jako pomalá a k vyřešení incidentu stažením chybného oznámení cest došlo až o několik desítek minut po jeho objevení. Celý incident byl zanalyzován a popsán na webu RIPE NCC [1].
Vznik RPKI
Nejen tento incident, ale desítky dalších podobných úniků, útoků a nehod, které se stávaly a stávají relativně často, odhaduje se, že se jedná o jednotky případů za den, akcelerovaly vývoj automatických preventivních opatření. Návrh, který uspěl v diskuzi internetové komunity a v procesu vývoje standardů byl systém RPKI. K jeho standardizaci došlo v roce 2013 v dokumentu RFC 6480 [2] a v dalších návazných standardech. Jedná se o hierarchický systém, který staví na kryptografickém potvrzování transferu autority nad částmi adresního prostoru a proto byla klíčová podpora RIRů – mezinárodních koordinátorů užití adresního prostoru. Z hlediska Evropy přišla podpora RPKI od RIPE NCC velmi brzy po standardizaci a plnému nasazení RPKI již několik let vlastně nic nebrání.
Celý sytém RPKI není ani příliš složitý, jeho návrh je přiměřeně elegantní a software realizující tento systém je k dispozici v produkční kvalitě i s dokumentací a s možností bezplatných školení ze strany RIPE NCC. Z hlediska jednotlivého provozovatele sítě (autonomního systému) lze RPKI implementovat i s relativně omezenými prostředky a časem. Nicméně již během standardizace se objevily výhrady proti hirearchické podobě RPKI, která efektivně umožní výše postaveným uzlům v RPKI stromu kdykoliv revokovat certifikáty pro nižší uzly a ve výsledku tak odpojit a nebo omezit konektivitu závislým sítím. Sluší se říct, že to není vedlejší účinek, ale prakticky to je prostředek i cíl RPKI.
Přijetí RPKI a nasazení
Bezpodmínečné nasazení RPKI by byla bezpochyby obrovská změna organizace internetu. V současnosti se internet skládá z autonomních systémů, které se svobodně dohodly o propojení, navzájem si přiměřeně důvěřují a proto přijímají prefixy oznámené protokolem BGP a předávají je dál. Nad tím, co kdo oznámí protokolem BGP svým sousedům, není tedy žádná centrální kontrola, a veškerá zodpovědnost padá na zdroj oznámení cesty a částečně na jeho bezprostřední sousedy. Těžiště odrážení chybných a nebo zlovolných oznámení a obecně rozhodování o tom, jaké oznámení prefixů se do internetu vpustí, leží na upstream ISP případného škůdce. V mnoha případech není kvůli počtu oznamovaných prefixů a frekvenci změn reálné všechny příchozí oznámení kontrolovat a proto je na mnoha místech ve filtrech vše povoleno, stejně jako v případě Pakistan Telecomu a jeho upstreamů. RPKI by pravomoc rozhodovat o příchozích oznámeních přeneslo ve prospěch automatického systému. Správci by sice stále mohli ručně zasáhnout. Stejně jako dnes od určitého množství není ruční kontrola únosná, vše zůstává povoleno a správci ručně zasahují až po důrazném upozornění, tak v případě automatizace kontroly pomocí RPKI by v drtivé většině případů rozhodovaly hierarchicky vydávané certifikáty, a to se všemi důsledky pro omezení decentralizace internetu.
Odpor proti RPKI z důvodů přenesení rozhodovací pravomoci o přijímaných prefixech na hierarchickou autoritu, které by podle některých hlasů mohlo vést k omezení svobody internetu, přetrval. Přidaly se i prvotní negativní zkušenosti s konkrétními implementacemi, jistá neprůhlednost a komplikovanost distribuce kryptografických artefaktů ROA a pomalá implementace protokolu RTR ze strany výrobců routerů. Tyto faktory jsou v současnosti vyřešené a nebo přinejmenším vyřešitelné. Přesto prefixů, které jsou pokryté příslušným ROA, je zatím jen kolem 10 % celkového počtu a růst počtu takto chráněných sítí neslibuje všeobecné přijetí v nejbližší budoucnosti. Mimo to je 0,5 – 1 % celkového počtu prefixů pravděpodobně pokryto chybným ROA. Validace a vynucování platných ROA by v současnosti teoreticky ochránilo kolem 10 % prefixů a až 1 % by bylo neprávem odpojeno.
Otázka počtu sítí, které validují a vynucují ROA byla donedávna předmětem spekulací a převládaly spekulace, že se jedná o marginální počet, omezený zejména na výzkumné sítě a experimentální nasazení.
Měření nasazení ROV
Změřit, kolik autonomních systémů v internetu vytvořilo a zveřejnilo ROA pro své prefixy a spočítat, kolik prefixů je chráněno, je v principu jednoduchá úloha. Je sice možné vytvořit alternativní neveřejný RPKI strom, mít oddělená úložiště kryptografických artefaktů a klidně i vlastní Trust Anchors, nicméně taková iniciativa nedává v daném okamžiku příliš velký smysl a ani se o ničem podobném neví. Vezmeme-li ROA dostupná na úložištích regionálních registrů (RIR), dospějeme k uvedenému číslu kolem 10 % prefixů, pokrytých příslušnými ROA. Z toho je určitá část, až 1 %, podezřelá, že obsahuje zastaralé a nebo chybné informace. Detailní analýza konfliktů mezi BGP a RPKI je dostupná na webu NIST [3].
Naproti tomu je komplikované najít a kvantifikovat v internetu sítě, které validují ROA a skutečně aplikují výsledky ROV na routing, tedy zahazují prefixy, pro které existují konfliktní ROA a neexistuje ROA povolující daný pár prefix a origin (t.j. autonomní systém, který prefix oznamuje).
Aktivní experiment
Prezentovaná metoda, která umožňuje otestovat omezený vzorek sítí v internetu, zjistit, zda validují ROA a tyto výsledky následně zobecnit a usuzovat podle nich o rozšíření ROV v celém internetu, je závislá na aktivním experimentu. Podstata experimentu je, že se řízeně vyvolá konflikt mezi prefxy oznámenými v BGP a příslušnými ROA a následně se sondují vzdálené sítě, zda je v nich daný prefix dostupný. Tato metoda sama o sobě je velmi nespolehlivá kvůli náhodným fluktuacím v routingu, nedostupným sítím a ztrátám provozu. Spolehlivost i citlivost však lze zvýšit tím, že se připraví diferenciální experiment: Oznámeny jsou dvě sítě, z toho jedna s platným ROA a druhá s v konfliktu s příslušným ROA. Pak lze sledovat rozdíly v šíření těchto dvou prefixů v DFZ. To samo o sobě pořád nestačí, protože výsledkem ROV může být nejen zahození konfliktního prefixu, ale i pouhé snížení jeho priority. Proto je potřeba k nevalidnímu prefixu nabídnout validní alternativu, která by ovšem byla bez ROV méně prioritní. Proto byl připraven oboustranně symetrický experiment, jak ukazuje Obrázek 1.
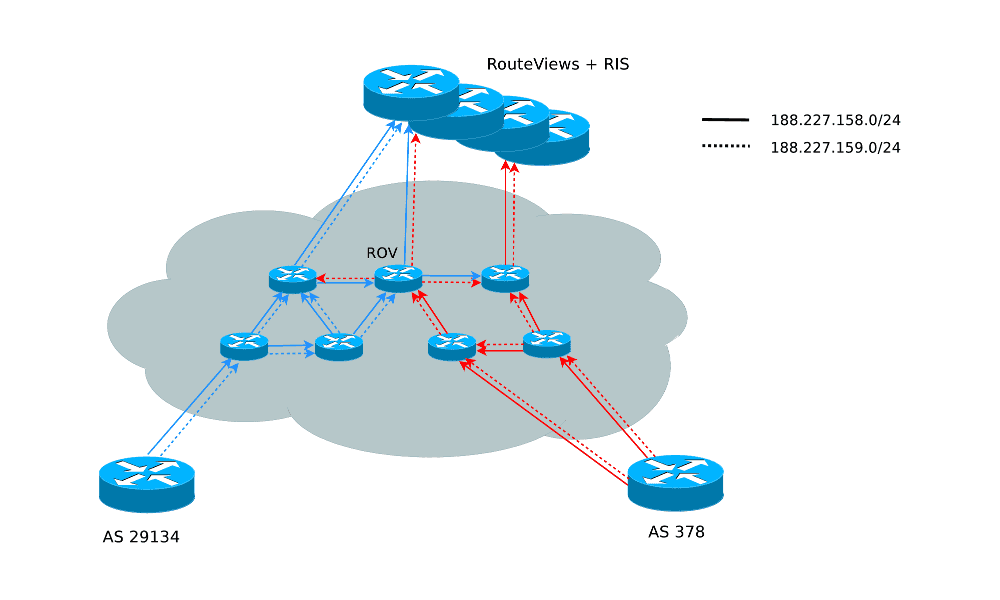
Obrázek 1: Oboustranně symetrický experiment
Aktivního experimentu se účastnily dva autonomní systémy ve dvou různých geograficky vzdálených lokalitách – AS29134 v ČR a AS378 v Izraeli. Z obou zmíněných AS byly oznamovány dva prefixy 188.227.158.0/24 a 188.227.159.0/24, přičemž pro první prefix bylo zveřejněno ROA autorizující jeho oznámení z AS29134 a pro druhý prefix bylo zveřejněno ROA autorizující oznámení z AS378. Oba spolupracující AS zajistily průchod prefixů filtry svých upstreamů a vytvořily příslušné route objekty v RIPE DB (oba AS patří do servisního regiónu RIPE NCC).
Rozpoznání ROV a kvantifikace
Druhá část experimentu je zjistit, ve kterých autonomních systémech byl konfliktní prefix potlačen, zatímco validní prefix procházel. Pro to je potřeba získat informace o routingu. První metoda, naznačená v Obrázku 1 využívá RouteViews [4] a RIPE RIS [5], což jsou služby, které stahují a dlouhodobě uchovávají obsahy BGP tabulek a celou historii změn v BGP z několika stovek autonomních systémů, které poskytují data ze svých routerů těmto projektům. V těchto datech lze snadno dohledat cesty, kde validní prefix prošel, zatímco nevalidní byl cestou ztracen. A s trochou kombinování získaných znalostí lze s různou mírou pravděpodobnosti dovodit i které autonomní systémy potlačují nevalidní prefixy. Průměrná délka cesty v internetu, měřeno počtem autonomních systémů, kterými cesta projde, je o něco méně, než 4. Proto je toto dovozování docela jednoduché a algoritmizovatelné. Problémem této metody však je, že umožňuje objevit ROV jen ve velmi omezené množině autonomních systémů, které jsou v cestě mezi oběma injektujícími body aktivního experimentu a některým z kolektorů projektů RouteViews a nebo RIS.
Jinou možností, jak získat obdobná data, avšak z mnohem větší a rozmanitější množiny bodů v síti je použít RIPE Atlas [5]. Tato síť malých a centrálně ovládaných sond umožňuje provádět aktivní měření pro výzkumné i provozní účely a jednou z funkcí, které RIPE Atlas poskytuje je vzdálené spuštění traceroute na vybraný cíl. V našem případě byl ze všech sond RIPE Atlasu spuštěn traceroute na jednu z IP adres uvnitř každého z námi injektovaných experimentálních prefixů, jak ukazuje Obrázek 2. Výsledek traceroute je sice seznam IP adres routerů, přes které přeskakují datagramy ve směru od RIPE Atlas sondy k našim bodům oznamujícím experimentální prefixy, avšak z těchto informací lze s velkou mírou jistoty odvodit cesty v BGP a tím výsledky tohoto měření převést na předchozí případ.
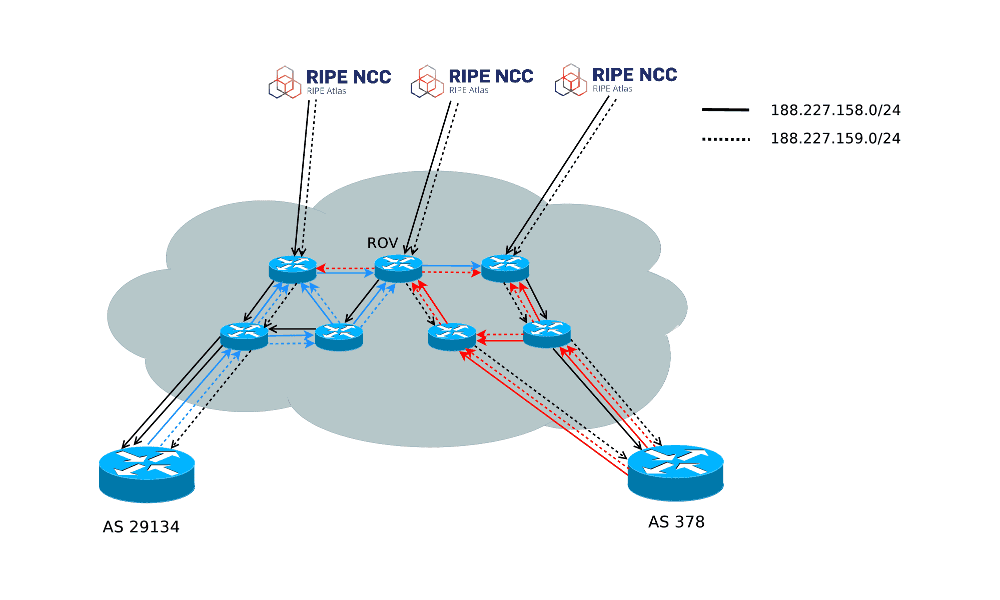
Obrázek 2: Použití RIPE Atlas sond pro získání dat z aktivního experimentu
Přestože se nám povedlo získat díky RIPE Atlasu data z bezmála 9000 sond, pořád tento experiment trpí omezeným rozsahem měření. Poslední krok byl naškálovat experiment do rozměrů, které umožní zobecnění výsledků s velkou mírou jistoty pro celý internet. Pro toto zobecnění je však zapotřebí slevit z požadavku na objevení konkrétních autonomních systémů, které provádí ROV. Místo toho byla položena otázka: Jaké procento komunikace a nebo přesněji jaké procento cest v internetu je chráněno ROV? Tato otázka umožňuje použít aktivní experiment k měření na (skoro) všechny aktivní IP adresy v internetu tím způsobem, že se do sítě injektují dva datagramu pro každou vzdálenou adresu, jejíž zabezpečení je testováno. První bude mít zdrojovou adresou z prvního námi injektovaného prefixu a testovaná adresa bude cílovou adresou. Druhý datagram bude mít odlišnou pouze zdrojovou adresu, která bude tentokrát z druhého prefixu. V obou případech je potřeba vytvořit takový datagram, na který vzdálená adresa odpoví. Následně stačí zachytit odpovědi, které dorazí buď do AS29134 a nebo do AS378. Pokud obě odpovědi dorazí do stejného AS, nedošlo k jejich ovlivnění ROV. Pokud dorazí každá do jiného AS, je možné a nebo dokonce pravděpodobné, že je testovaná adresa chráněná. Pokud dorazí odpověď jen na jednu nebo na žádnou ze sond, je situace složitější, nicméně v některých případech stále řešitelná. Metodu ilustruje Obrázek 3. V našem případě jsme vybrali nakonec jako metodu posílání TCP segmentů navazujících spojení na HTTP servery ze seznamu 1.5 milionu nejnavštěvovanějších webů podle Alexa rankingu [7], který byl zredukován asi na polovinu kvůli duplicitám a neodpovídajícím serverům.
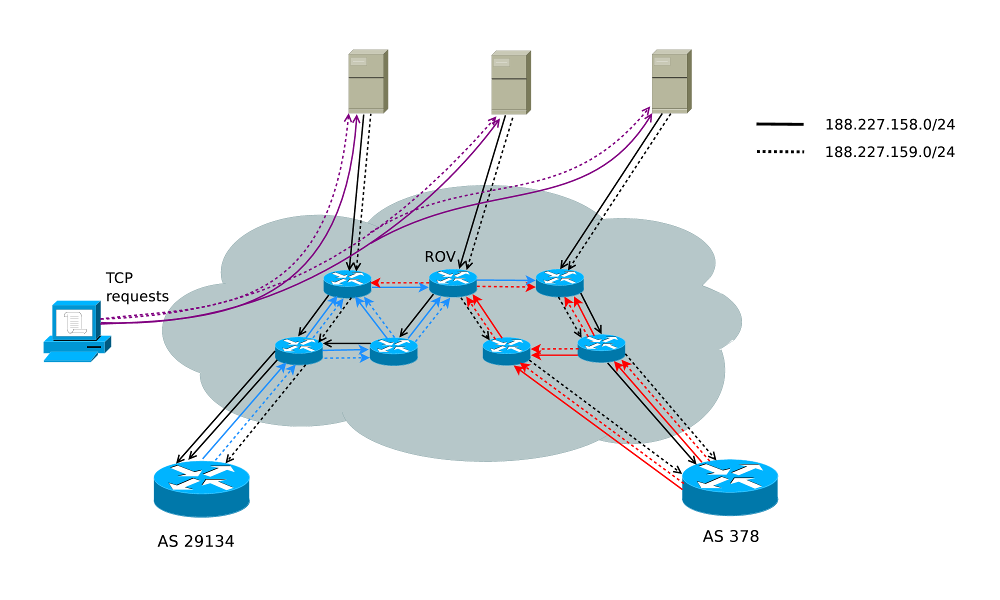
Obrázek 3: Testování ochrany vzdálených sítí pomocí TCP sond
Všechny tři zhruba popsané metody akvizice dat z jednoho společného aktivního experimentu jsou přirozeně komplikovanější z hlediska postprocessingu získaných dat, protože je nutné odfiltrovat náhodné chyby při doručování datagramů přes internet, nestandadní směrovací rozhodnutí, zejména náhodné vlivy ECMP, změny routingu v průběhu měření a další nepredikovatelné vlivy. Tyto vlivy lze odstranit statistickými úvahami a několikanásobným opakováním měření. Detaily akvizice a zpracování těchto dat jsou popsány v článku [8].
Výsledky
Hlavním výsledkem je potvrzení dlouho existující domněnky, že ROV je opravdu marginálním jevem. Validaci provádí jen několik málo sítí, zejména, akademických, výzkumných a nebo nějakým způsobem zainteresovaných na propagaci standardu RPKI. Obrázek 4 ukazuje procentuální výsledky všech tří experimentů.

Obrázek 4: Porovnání výsledků tří metod akvizice dat z aktivního experimentu
V prvním případě control plane experimentu s RouteViews a RIPE RIS experimentu byla výsledkem následující sumarizace:
- Nevalidující autonomní systémy: 250 (84.5%)
- Možná validace (horní hranice, autonomní systémy bez negativních výsledků): 46 (15.5%)
- Pravděpodobně validující AS: 4 (1.35%)
V druhém případě měření pomocí RIPE Atlas sond jsme získali následující výsledky:
- Nevalidující autonomní systémy: 2043 (97.0%)
- Možná validace (horní hranice, autonomní systémy bez negativních výsledků): 49 (2.3%)
- Prokázaná validace (spodní hranice): 2 (0.1%)
- Pravděpodobně validující AS: 12 (0.5%)
V posledním případě experimentu s odraženými odpověďmi od HTTP serverů byly změřeny následující počty chráněných sítí:
- Nechráněné adresy: 632570 (93.30%)
- Pravděpodobně chráněné: 201 (0.03%)
- Ochranu nelze určit: 45163 (6.66%)
Zabezpečení routingu v internetu
Z uvedených výsledků je zřejmé, že původní domněnka o zanedbatelném nasazení ROV a tedy prakticky neexistujícím dopadu na zabezpečení internetu je správná a lze ji považovat za prokázanou. Na druhou stranu byly objeveny a dokonce ověřeny u zodpovědných správců dva případy AS, které ROV provádějí jako součást běžného provozu AS, což dokazuje, že to v současnosti je technicky i provozně možné.
Zajímavou otázku vzbuzuje pohled na graf srovnání výsledků jednotlivých metod (Obrázek 4). Podezřelá je skutečnost, že nejvíce nadějí pro ROV dává první, co do počtu otestovaných AS, nejomezenější metoda, která závisela na RouteViews a RIPE RISu. Následuje druhá metoda s RIPE Atlasem a nejhůře dopadla metoda s nejširší množinou testovaných sítí pomocí TCP sond. Vysvětlení, byť částečně spekulativní, pro tento výsledek je, že měření přes RouteViews a RIS a i přes RIPE Atlas trpí určitou pozitivní odchylkou: Sítě, které participují v těchto projektech, jsou inovátoři, aktivní přispěvatelé v internetové komunitě a pravděpodobnost, že budou testovat a nebo dokonce nasadí relativní novinku s hlubokým bezpečnostním dosahem, jakou je validace ROV, je u nich vyšší, než u zbytku běžné populace autonomních systémů v internetu.
Důsledkem tohoto výzkumu bylo rozpracování metodiky měření ROV v internetu, což mimo jiné doplňuje komplementární článek [9] nezávislé výzkumné skupiny, který došel odlišnými metodami k podobným procentuálním i absolutním výsledkům. Samotný výsledek neznamená pro internetovou komunitu, proponenty technologie RPKI ani pro provozovatele sítí tragickou zprávu. Cílem experimentu bylo ověřit výchozí bod pro další výzkum, totiž že bezpečnost routingu není, navzdory existenci příslušné technologie, standardů i softwaru, uspokojivě vyřešená. Zároveň však bylo dokázáno, že RPKI je potenciální a schůdné řešení problémů, bude-li masivně nasazeno. Dopady případného nasazení ROV prozkoumal pomocí simulací článek [10] a z jeho závěry jsou pozitivní.

Odkazy
[1] https://www.ripe.net/publications/news/industry-developments/youtube-hijacking-a-ripe-ncc-ris-case-study
[2] https://tools.ietf.org/html/rfc6480
[3] https://rpki-monitor.antd.nist.gov/
[4] http://www.routeviews.org/routeviews/
[5] https://www.ripe.net/analyse/internet-measurements/routing-information-service-ris
[6] https://atlas.ripe.net/
[7] https://www.alexa.com/siteinfo
[8] T. Hlavacek, A. Herzberg, H. Shulman, M. Waidner „Practical Experience: Methodologies for Measuring Route Origin Validation„, DSN 2018
[9] A. Reuter, R. Bush, Í. Cunha, E. Katz-Bassett, T. C. Schmidt, M. Wählisch: „Towards a Rigorous Methodology for Measuring Adoption of RPKI Route Validation and Filtering„, ACM SIGCOMM CCR 48(1) pp. 19–27, 2018
[10] Y. Gilad, A. Cohen, A. Herzberg, M. Schapira, H. Shulman: „Are We There Yet? On RPKI’s Deployment and Security„, NDSS 2017
Původně napsáno pro blog CZ.NIC.

