
Obsah
1. SIMD instrukce na platformě 80×86: nepřímý důsledek platnosti Mooreova zákona
2. Malá odbočka: Flynnova klasifikace sekvenčních a paralelních systémů
3. Kategorie SISD: základní způsob implementace skalárních procesorů CISC i RISC
4. Kategorie SIMD: procesory s podporou vektorových operací
5. Vektorové operace na platformě 80×86
6. Počty nových instrukcí v jednotlivých „vektorových“ rozšířeních instrukční sady
7. Instrukční sada MMX: první pokus o použití SIMD na platformě x86
8. Typy vektorů zpracovávaných instrukcemi MMX
10. Registry MMX, vztah ke standardnímu matematickému koprocesoru
11. Vztah mezi registry MMX a registry matematického koprocesoru
14. Načtení vektoru do MMX registru
15. Součet osmiprvkových vektorů s hodnotami typu byte
16. Výsledný vektor v případě přetečení
17. Součet osmiprvkových vektorů se saturací
19. Repositář s demonstračními příklady
1. SIMD instrukce na platformě 80×86: nepřímý důsledek platnosti Mooreova zákona
„…sequential computers are approaching a fundamental physical limit on their potential power. Such a limit is the speed of light…“
Na sérii článků o matematických koprocesorech na platformě 80×86 dnes nepřímo navážeme. Začneme se totiž seznamovat se SIMD instrukcemi (taktéž s ohledem na platformu 80×86), které jsou zde souhrnně nazývány, i když ne zcela přesně, vektorové instrukce. Přitom SIMD/vektorové instrukce v současnosti patří ke standardní výbavě prakticky všech variant moderních mikroprocesorů a dokážou v některých případech několikanásobně urychlit výpočty.
Připomeňme si, že z hlediska dosahovaného výpočetního výkonu leží na samém „výkonnostním dně“ klasické mikroprocesory s architekturou CISC, které vykonávají všechny instrukce postupně a dokončení jedné instrukce může v závislosti na jejich složitosti trvat i několik desítek strojových taktů (což byl příklad Intelu 8086, kde například dělení trvalo 168 taktů + až dalších 16 taktů nutných pro výpočet efektivní adresy).
Předností těchto procesorů může být poměrně velká informační hustota instrukční sady (například i díky tomu, že operandy některých instrukcí jsou zadány implicitně), což mj. znamená, že se procesory tohoto typu po poměrně dlouhou dobu obešly bez nutnosti využití drahých vyrovnávacích pamětí první a druhé úrovně (L1 cache, L2 cache). Klasické procesory s architekturou CISC byly založeny na mikroprogramovém řadiči vybaveném pamětí mikroinstrukcí a teprve později začaly být tyto procesory doplňovány technologiemi získanými z jiných architektur – postupně se jednalo o instrukční fronty, instrukční pipeline, prediktor skoků, vektorové instrukce (což byly oblasti klasických RISCových architektur) atd.

Obrázek 1: Ukázka časování instrukce ADC (Add with carry) dnes již klasického osmibitového mikroprocesoru MOS 6502 s architekturou CISC. V závislosti na zvoleném adresním režimu se liší počty strojových cyklů od dvou do šesti. Liší se samozřejmě i počet bajtů nutných pro zakódování instrukce, protože některé adresní režimy vyžadují zápis absolutní šestnáctibitové adresy a jiné režimy naopak používají jen 8bitový offset, popř. osmibitovou adresu v rámci takzvané nulté stránky (zero page).
Výpočetní výkon mikroprocesorů se podařilo poměrně výrazným způsobem zvýšit u architektury RISC zavedením již výše zmíněné instrukční pipeline. Provedení jedné instrukce sice stále trvalo větší počet strojových cyklů, ovšem díky rozfázování operací v instrukční pipeline bylo umožněno překrývání většího množství instrukcí, a to bez nutnosti zavádění skutečné paralelizace (která vede k velkému nárůstu složitosti a tím i ceny čipu). Spolu se zavedením mikroprocesorů RISC se skutečně stalo, že reálný i špičkový výpočetní výkon procesorů vzrostl, ale relativně brzy bylo nutné k těmto čipům přidat vyrovnávací paměti (cache), jelikož rychlost procesorů rostla mnohem rychleji, než vybavovací doba pamětí. Navíc typické RISCové procesory měly instrukční slova o konstantní délce a tudíž obecně menší hustotu kódu. Tento rozpor mezi rychlostmi obou nejdůležitějších součástí moderních počítačů ostatně trvá dodnes.

Obrázek 2: Ukázka časování některých instrukcí šestnáctibitového mikroprocesoru Intel 8086 s architekturou CISC, kterým jsme se až doposud primárně zabývali. I přesto, že se jedná o procesor o generaci mladší, než MOS 6502, mají oba zmíněné typy čipů poměrně velké množství společných vlastností.
Pro další zvýšení výpočetního výkonu však bylo nutné použít další více či méně pokročilé technologie, například instrukční sadu VLIW, která však – opět – měla velké nároky na rychlost pamětí. Podobně jako u procesorů RISC, i u VLIW bylo pro zmírnění požadavků na rychlost pamětí možné použít Harvardskou architekturu, tj. odděleni paměti programu od paměti dat (programová paměť navíc mohla mít větší šířku datové sběrnice odpovídající šířce instrukčních slov). Další zvýšení výkonu umožňují právě vektorové instrukce (SIMD), které ale mají jeden poměrně zásadní nedostatek – takzvanou sémantickou mezeru mezi imperativním „skalárním“ kódem psaným například v jazyku C (C++ atd.) a instrukční sadou, která je SIMD (jinými slovy – běžné programovací jazyky neumožňují dostatečně popsat vektorové operace). Tuto mezeru do určité míry vyplňuje rozšíření GCC o takzvané intrinsic.
My ovšem budeme stále pracovat v assembleru, v němž žádná sémantická mezera mezi assemblerem a instrukcemi vlastně neexistuje, protože se přímo pracuje na úrovni instrukčního souboru daného mikroprocesoru.

Obrázek 3: Typický formát instrukcí procesorů s architekturou CISC spadajících do kategorie SISD. U většiny procesorů v kategorii CISC+SISD jsou použity instrukce s mnoha adresními režimy, instrukční slova proměnné délky a s proměnným počtem strojových cyklů nutných pro vykonání operace zakódované v instrukci.
2. Malá odbočka: Flynnova klasifikace sekvenčních a paralelních systémů
Před popisem vektorových instrukcí (resp. rozšiřujících sad s těmito instrukcemi) je vhodné se alespoň ve stručnosti zmínit o takzvané Flynnově klasifikaci sekvenčních a paralelních systémů. Jedná se o způsob rozdělení systémů (někdy se jedná o procesory, jindy o celé počítače či výpočetní uzly) v závislosti na tom, zda je tok instrukcí prováděn sekvenčně či paralelně a taktéž na tom, zda je tok dat prováděn sekvenčně či paralelně. Jinými slovy je Flynnova klasifikace založena na rozboru instrukčního a datového paralelismu zkoumaného procesoru/počítače/výpočetního uzlu/cloudu.
Sekvenční tok instrukcí se značí zkratkou SI (Single Instruction Stream), paralelní tok instrukcí pak zkratkou MI (Multiple Instructions Stream). Při charakterizaci toků dat se používá zkratka SD (Single Data Stream) pro sekvenční tok dat a zkratka MD (Multiple Data Stream) pro paralelní tok dat.
Ve více než padesátileté historii vývoje výpočetní techniky se již objevily všechny čtyři možné kombinace instrukčního a datového paralelismu:
| Zkratka klasifikace | Anglický význam zkratky | Využití systémů s danou klasifikací |
|---|---|---|
| SISD | Single Instruction Stream, Single Data Stream | klasická architektura pro procesory CISC a RISC |
| SIMD | Single Instruction Stream, Multiple Data Stream | vektorové procesory, GPU, procesory s instrukční sadou SSE/MMX… |
| MISD | Multiple Instructions Stream, Single Data Stream | poměrně speciální případy, řídicí počítače raketoplánů (Space Shuttle) |
| MIMD | Multiple Instructions Stream, Multiple Data Stream | Connection Machine, transputery, symetrické multiprocesory |

Obrázek 4: U procesorů s instrukční sadou VLIW může být v jediném instrukčním slově (světle žlutý obdélník) uloženo větší množství operací. Na tomto obrázku je zobrazeno instrukční slovo hypotetického mikroprocesoru obsahujícího jeden modul pro komunikaci s pamětí, jednu ALU, matematický koprocesor a jednotku po provádění skoků. Spojování více operací do jednoho instrukčního slova je náplní práce překladače, přesněji řečeno jeho back endu (se všemi přednostmi i zápory, které toto řešení přináší).
3. Kategorie SISD: základní způsob implementace skalárních procesorů CISC i RISC
Z hlediska Flynnovy klasifikace patří mezi nejjednodušší systémy procesory a počítače ležící v kategorii SISD, která vlastně odpovídá klasické von Neumannově architektuře počítače. Do této kategorie spadají především původní mikroprocesory s architekturou CISC, ale i procesory RISC. Důvod, proč jsou oba tyto typy procesorů zařazeny do kategorie SISD, je jednoduchý – tyto čipy načítají instrukce z operační paměti sekvenčně a sekvenčně jsou taktéž vykonávány, samozřejmě s určitou výjimkou představovanou instrukční pipeline (tedy s překrýváním instrukcí). Nezávisle na konkrétním typu architektury procesoru jsou čipy patřící do kategorie SISD nejjednodušší jak z hlediska technické implementace a počtu tranzistorů, tak i nároky kladenými na překladač a v neposlední řadě i na vývojáře (kteří stále hledají vhodné prostředky pro vyjádření algoritmů určených pro paralelní systémy – tento problém totiž není ani zdaleka dobře vyřešen). Z tohoto hlediska se můžeme se systémy SISD stále v praxi setkávat a v mnoha oborech vlastně ani není důvod k přechodu k systémům složitějším a dražším.

Obrázek 5: Schéma systému patřícího do kategorie SISD.
Všechny CISCové mikroprocesory firmy Intel řady 80×86, od ještě z poloviny osmibitového čipu Intel 8088 (ten již dobře známe) až po model Intel 80486 (včetně) byly založeny na skalární architektuře SISD, stejně jako velké množství mikrořadičů či digitálních signálových procesorů (DSP – Digital Signal Processor). Nevýhodou systémů SISD ovšem je, že rychlost načítání a tím i zpracování instrukcí je shora omezena a že ani s využitím velmi dlouhé instrukční pipeline se nedá – vcelku logicky – překonat limit jedné zpracované instrukce za jeden takt. Příliš velké množství řezů (slices) pipeline má naopak i své zápory, především při zpracování skoků, návratů z podprogramů či odezvy na přerušení – ve všech těchto případech je nutné vyřešit problém, co se má udělat s instrukcemi, které se nachází v rozpracovaném stavu v pipeline (mohou se buď zahodit nebo naopak dokončit, podle toho, jakým způsobem byl lineární běh programu přerušen).
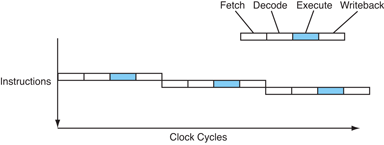
Obrázek 6: Sekvenční zpracování instrukcí, které jsou prováděny v několika fázích.
4. Kategorie SIMD: procesory s podporou vektorových operací
V současnosti se těší značné popularitě procesory patřící do kategorie SIMD, jejíž kořeny ovšem sahají hluboko do minulosti, konkrétně do šedesátých a sedmdesátých let minulého století (tato oblast výpočetní techniky je spojena se Symourem Crayem a jeho superpočítači Cray). Do této kategorie patří ty architektury procesorů, u kterých se s využitím jedné instrukce může zpracovat větší množství dat.
Například u rozšíření instrukční sady MMX, které si popíšeme v navazujících kapitolách, je možné s využitím jediné instrukce provést součet dvou vektorů číselných hodnot. Může se jednat o osm osmibitových hodnot uložených v jednom vektoru, čtyři šestnáctibitové hodnoty v jednom vektoru atd. (podrobnosti viz další text). Této vlastnosti se dá v mnoha případech využít pro urychlení běhu programů, protože některé algoritmy (ve skutečnosti je těchto algoritmů možná až udivující počet) provádí velké množství stejných operací s rozsáhlým objemem dat – například se může jednat o aplikaci konvolučního filtru na rastrový obrázek, zpracování zvukového signálu, vynásobení matice vektorem, vynásobení dvou matic, některé algoritmy z oblasti NLP (zpracování přirozeného jazyka) atd.

Obrázek 7: Schéma systému patřícího do kategorie SIMD.
Mezi přednosti čipů náležejících do kategorie SIMD patří jak relativně kompaktní instrukční sada, tak i paralelní a tím pádem i rychlý běh mnoha algoritmů, ovšem za cenu větších nároků kladených na programátora, popř. na překladač. Stále jen velmi malé množství programovacích jazyků totiž umožňuje explicitně vyjádřit vektorové či maticové operace (například u překladače Fortranu určeného pro superpočítače Cray bylo v manuálu explicitně řečeno, které jazykové konstrukce se budou skutečně provádět ve vektorové – SISD – jednotce) a jen některé překladače dokážou podobné optimalizace provádět kvalitně a automaticky.
Z tohoto důvodu také není možné většinu SIMD konstrukcí zapsat v konvenčním vyšším programovacím jazyce: musí se použít buď hotová makra, ručně optimalizované knihovní funkce nebo specializované programovací jazyky. Určitou, ale nezanedbatelnou výjimku představují GPU na grafických akcelerátorech, které explicitně pracují s 2D a 3D vektory, přičemž programátor může předem zjistit, které operace budou skutečně provedeny paralelně.

Obrázek 8: Typy vektorů, s nimiž pracují instrukce MMX popsané níže.
5. Vektorové operace na platformě 80×86
Jak jsme se již několikrát zmínili v předchozích odstavcích, jsou v soudobých typech mikroprocesorů (přesněji řečeno mikroprocesorů pro pracovní stanice i servery) implementovány i některé vektorové instrukce (popravdě řečeno již celkový počet vektorových instrukcí pravděpodobně překročil počet instrukcí skalárních, a to pravděpodobně několikanásobně :-). Pokud prozatím zůstaneme u platformy 80×86, tak historicky první instrukční sadou, přesněji řečeno doplněním či rozšířením původní instrukční sady, s podporou vektorových operací byla sada instrukcí MMX, s níž přišla firma Intel.
Toto rozšíření instrukční sady sice umožňovalo provádění vektorových operací, ale mělo celou řadu omezení, především nízký počet „vektorových“ registrů, které navíc měly (z dnešního pohledu) malou bitovou šířku a z toho vycházející nízký počet prvků umístitelných ve vektorech atd. Nevýhodné taktéž bylo, že se pro instrukce MMX používaly registry určené původně pro práci s matematickým koprocesorem (FPU), takže současné provádění FP operací a MMX operací bylo minimálně složité; většinou i zcela nepraktické (na druhou stranu se však nemusely měnit operační systémy a jejich systém přepínáním úloh; totéž platí i pro přerušovací subrutiny). Ovšem poměrně brzy po uvedení sady MMX se objevila konkurenční instrukční sada 3Dnow! firmy AMD, která byla následovaná již zmíněnými sadami SSE až SSE5 a posléze několika generacemi AVX.

Obrázek 9: Dnes již historický mikroprocesor AMD K6–2 implementující mj. i rozšíření instrukční sady nazvané poněkud zvláštně 3Dnow!
Zkusme se nyní podívat na seznam různých SIMD (neboli nesprávně řečeno „vektorových“) rozšíření původní instrukční sady x86:
| Technologie | Rok uvedení | Společnost | Poprvé použito v čipu |
|---|---|---|---|
| MMX | 1996 | Intel | Intel Pentium P5 |
| 3DNow! | 1998 | AMD | AMD K6–2 |
| SSE | 1999 | Intel | Intel Pentium III (mikroarchitektura P6) |
| SSE2 | 2001 | Intel | Intel Pentium 4 (mikroarchitektura NetBurst) |
| SSE3 | 2004 | Intel | Intel Pentium 4 (Prescott) |
| SSSE3 | 2006 | Intel | mikroarchitektura Intel Core |
| SSE4 | 2006 | Intel+AMD | AMD K10 (SSE4a) , mikroarchitektura Intel Core |
| SSE5 | 2007 | AMD | (nakonec rozděleno do menších celků), mikroarchitektura Bulldozer |
| AVX | 2008 | Intel | mikroarchitektura Sandy Bridge |
| F16C (CVT16) | 2009 | AMD | Jaguar, Puma, Bulldozer atd. |
| XOP | 2009 | AMD | mikroarchitektura Bulldozer |
| FMA3 | 2012 | AMD | mikroarchitektura Piledriver, Intel: Haswell a Broadwell |
| FMA4 | 2011 | AMD | mikroarchitektura Bulldozer (pozdější architektury po Zen 1 již ne) |
| AVX2 | 2013 | Intel | mikroarchitektura Haswell |
| AVX-512 | 2013 | Intel | Knights Landing |
| AMX | 2020 | Intel | Sapphire Rapids |
Informaci o tom, jaká rozšíření instrukční sady podporuje váš mikroprocesor, lze získat snadno:
$ cat /proc/cpuinfo
V mém konkrétním případě (Intel® Core™ i7–8665U CPU @ 1.90GHz) se vypíšou následující vlastnosti CPU. Z těchto příznaků jsem zdůraznil příznaky odpovídající SIMD instrukcím:
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp md_clear flush_l1d arch_capabilities
6. Počty nových instrukcí v jednotlivých „vektorových“ rozšířeních instrukční sady
Pro někoho může být taktéž zajímavá i informace o tom, jak velké změny v instrukční sadě mikroprocesorů byly vlastně při přidávání nových „vektorových“ rozšiřujících instrukčních sad typu SIMD provedeny. To nám ukáže další tabulka. Je pouze nutné dát si pozor na to, že počty nových instrukcí zavedených v rámci těchto nových technologií, které jsou vypsány v tabulce pod odstavcem, nemusí přesně souhlasit s počty uváděnými v jiných informačních materiálech.
Je tomu tak především z toho důvodu, že se v některých případech rozlišuje i datový typ, s nímž instrukce pracují (například se může jednat o součet vektoru s 32 bitovými hodnotami nebo 64bitovými hodnotami reprezentovanými v obou případech ve formátu s plovoucí řádovou čárkou) a někdy se taková instrukce do celkové sumy započítává pouze jedenkrát. Nicméně údaje vypsané v níže uvedené tabulce by měly být konzistentní, protože se jedná o počty nově přidaných operačních kódů instrukcí (například u dále popsané instrukční sady SSE2 končí instrukce znakem D, S, I či Q podle typu zpracovávaných dat/operandů):
| Název technologie | Počet nových instrukcí |
|---|---|
| MMX | 56 (či 57 podle způsobu výpočtu) |
| 3DNow! | 21 |
| SSE | 70 |
| SSE2 | 144 |
| SSE3 | 13 |
| SSSE3 | 32 (ve skutečnosti vlastně jen 16 instrukcí, ovšem pro dva datové typy) |
| SSE4 | 54 (z toho 47 v rámci SSE4.1, zbytek v rámci SSE4.2) |
| SSE5 | 170 (z toho 46 základních instrukcí) |
| F16C | 4 |
7. Instrukční sada MMX: první pokus o použití SIMD na platformě x86
První rozšiřující instrukční sadou navrženou původně pro mikroprocesory na platformě x86 (tedy nikoli ještě x86–64), která obsahovala SIMD operace, je sada instrukcí nazvaná MMX (MultiMedia eXtension, později taktéž rozepisováno jako Matrix Math eXtension). Tato sada byla navržena již v roce 1996 společností Intel a od roku 1997 jí začaly být vybavovány prakticky všechny nové mikroprocesory této firmy, přesněji řečeno ty mikroprocesory, které patřily do rodiny x86 (připomeňme si, že se jednalo o 32bitové mikroprocesory, protože k rozšíření na 64bitovou ALU došlo u mainstreamových čipů až o několik let později). Prvním mikroprocesorem s plnou podporou MMX byl čip Pentium P55C nabízený od začátku roku 1997. Později došlo k implementaci instrukční sady MMX i na čipy Pentium II a procesory konkurenčních společností, konkrétně na čipy AMD K6 a taktéž na Cyrix M2 (6×86MX) a IDT C6.
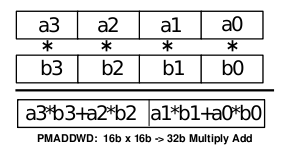
Obrázek 10: Jedna z poměrně složitých, ale užitečných instrukcí z instrukční sady MMX. Jedná se konkrétně o instrukci PMADDWD, která provádí paralelní součin čtveřice šestnáctibitových hodnot s 32 bitovým mezivýsledkem, s následným součtem prvního + druhého a třetího + čtvrtého mezivýsledku. Tuto instrukci lze použít například při implementaci konvolučních filtrů.
(Zdroj: Intel MMXTM Technology Overview, Intel corporation, 1996)
8. Typy vektorů zpracovávaných instrukcemi MMX
Většina nových instrukcí přidaných v rámci sady MMX byla určena pro provádění aritmetických a bitových operací s celočíselnými operandy o šířce 8, 16, 32 či 64 bitů, což pokrývá poměrně širokou oblast multimediálních dat – osmibitových i šestnáctibitových zvukových vzorků (samplů), barev pixelů (RGB, RGBA) atd. Zatímco při provádění aritmetických operací s využitím klasické aritmeticko-logické jednotky mohlo docházet k přetečení či podtečení hodnot při provádění instrukcí typu ADD či SUB (součet, rozdíl), je možné u MMX instrukcí zvolit i takzvanou aritmetiku se saturací, což znamená, že v případě přetečení se do výsledku uloží maximální reprezentovatelná hodnota a naopak při podtečení minimální hodnota, což je například při zpracování signálu (většinou) žádoucí chování (příkladem může být zesvětlení či naopak ztmavení obrázku). V následující tabulce jsou vypsány nově podporované datové typy i způsob jejich uložení ve slovech o šířce 64 bitů, které jsou zpracovávány jednotkou MMX:
| Datový typ | Bitová šířka operandu | Počet prvků vektoru |
|---|---|---|
| packed byte | 8 bitů | 8 |
| packed word | 16 bitů | 4 |
| packed doubleword | 32 bitů | 2 |
| quadword | 64 bitů | 1 |
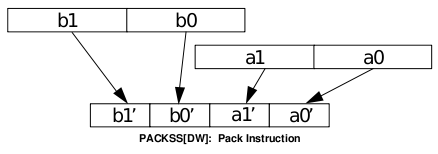
Obrázek 11: Ukázka jednoho typu konverzní funkce, kterých se v instrukční sadě MMX nachází několik.
(Zdroj: Intel MMXTM Technology Overview, Intel corporation, 1996)
Kromě přímé manipulace s celočíselnými hodnotami bylo relativně snadné pracovat i s numerickými hodnotami ukládanými ve formátu s pevnou řádovou čárkou (FX – fixed point), mohlo se například jednat o formáty 8.8 (osm bitů pro uložení celé části a osm bitů za řádovou čárkou), 8.24, 24.8 atd. O případné bitové posuny při normalizaci numerických hodnot se v tomto případě ovšem musel postarat programátor. Tyto formáty byly a jsou využívány v některých algoritmech implementujících FFT (rychlou Fourierovu transformaci využívanou v mnoha algoritmech pro zpracování signálů), DCT (diskrétní kosinovou transformaci využívanou například ve formátu JFIF-JPEG), FIR, IIR (filtry s konečnou a nekonečnou impulsní odezvou), operacemi nad vektory či operacemi nad maticemi.
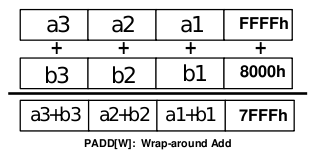
Obrázek 12: Ukázka chování MMX instrukce nazvané PADDW, která provádí součet čtveřice šestnáctibitových hodnot s přetečením, což je patrné z posledního sloupce (tuto instrukci si ukážeme v praktických příkladech).
(Zdroj: Intel MMXTM Technology Overview, Intel corporation, 1996)
9. Seznam instrukcí MMX
Všech 57 instrukcí zavedených v instrukční sadě MMX lze rozdělit podle jejich funkce do několika skupin vypsaných v následující tabulce:
| # | Skupina instrukcí | Příklady instrukcí |
|---|---|---|
| 1 | Základní aritmetické operace | PADD, PADDS, PADDUS, PSUBS, PSUBUS, PMULHW, PMULLW |
| 2 | Logické (bitové) operace | PAND, PANDN, POR, PXOR |
| 3 | Bitové posuny | PSLL, PSRL, PSRA |
| 4 | Porovnávání | PCMPEQ, PCMGT |
| 5 | Konverze dat | PACKUSWB, PACKSS, PUNPCKH, PUNPCKL |
| 6 | Přenosy dat + práce s pamětí | MOV (přesněji MOVD a MOVQ podle šířky dat) |
| 7 | Řízení jednotky MMX | EMMS |
Většina instrukcí uvedených v předchozí tabulce má navíc několik variant v závislosti na tom, s jakými operandy má instrukce ve skutečnosti pracovat. Například u instrukce PADD (tedy operace součtu) je možné zvolit, zda se mají sečíst dva osmiprvkové vektory, kde každý prvek má šířku 8 bitů, zda se má provést součet dvou čtyřprvkových vektorů (16bitové prvky), dvou dvouprvkových vektorů (32bitové prvky) či zda se jedná o součet dvojice 64bitových skalárních hodnot. To tedy znamená, že instrukce PADD může být reprezentována čtveřicí různých operačních kódů:
| # | Instrukce | Význam |
|---|---|---|
| 1 | PADDB | součet dvou vektorů majících osm osmibitových prvků |
| 2 | PADDW | součet dvou vektorů majících čtyři šestnáctibitové prvky |
| 3 | PADDD | součet dvou vektorů majících dva 32bitové prvky |
| 4 | PADDQ | součet dvou 64bitových skalárních hodnot |
Výjimkou z výše uvedeného pravidla jsou instrukce nazvané PAND, PANDN, POR a PXOR, pomocí nichž lze provádět bitové operace s dvojicí 64bitových slov. Důvod, proč není zapotřebí tyto instrukce dále rozdělovat podle počtu a šířky prvků vektorů, je zřejmý – tyto operace pracují nad jednotlivými bity, nikoli nad skupinami bitů. Na tomto místě je možná dobré upozornit na instrukci PANDN (not-and), která sice není ve většině běžných (skalárních) aritmeticko-logických jednotkách implementována, ovšem v případě zpracování rastrových obrazů se jedná o velmi užitečnou instrukci používanou například při vykreslování spritů atd.
10. Registry MMX, vztah ke standardnímu matematickému koprocesoru
Inženýři ve firmě Intel stáli při návrhu instrukční sady MMX před požadavkem na vytvoření výkonných instrukcí provádějících SIMD operace, na druhou stranu však bylo nutné šetřit počtem tranzistorů a tím pádem i plochou čipu, na němž byl mikroprocesor vytvořen. Navíc bylo nutné zachovat kompatibilitu s existujícími programy a operačními systémy, zejména při ukládání registrů na zásobník v subrutinách atd. Pravděpodobně právě z tohoto důvodu se rozhodli učinit poněkud problematický krok – navrhli MMX instrukce takovým způsobem, aby mohly pracovat s osmicí 64bitových registrů rozdělených na jeden, dva, čtyři či osm prvků.
Ovšem nejednalo se, jak by se dalo předpokládat, o nové registry rozšiřující původní sadu registrů procesoru Pentium, ale o část registrů využívaných matematickým koprocesorem (FPU). Ten na platformě x86 prováděl operace s osmicí 80bitových registrů uspořádaných do zásobníku (u matematického koprocesoru Intel 8087 byly používány čistě zásobníkové instrukce doplněné o možnost specifikace druhého operandu, později byly přidány i další adresovací režimy, které umožňovaly registry adresovat přímo, což se ukázalo být výhodnější především kvůli možnostem provádění různých optimalizací).
V případě instrukcí MMX se sice registry adresovaly přímo (popř. se adresovala slova uložená v operační paměti, která mohla tvořit jeden z operandů instrukce), ale kvůli tomu, že jak FPU, tak i jednotka MMX pracovala se shodnými registry (horních 16 bitů těchto registrů nebylo v MMX využito), bylo současné používání SIMD operací a operací s hodnotami uloženými v systému plovoucí řádové čárky poměrně komplikované, což je škoda, protože právě souběžná práce superskalárního CPU (u mikroprocesorů Pentium byly vytvořeny dvě instrukční pipeline „u“ a „v“), jednotky MMX a navíc ještě matematického koprocesoru by v mnoha případech mohla vést k citelnému nárůstu výpočetního výkonu.
11. Vztah mezi registry MMX a registry matematického koprocesoru
V následující tabulce jsou vypsána jména registrů tak, jak jsou použita v instrukcích matematického koprocesoru, i ve formě používané jednotkou MMX::
| Registr FPU | bity 79–64 | bity 63–0 |
|---|---|---|
| ST0 | nepoužito | MM0 |
| ST1 | nepoužito | MM1 |
| ST2 | nepoužito | MM2 |
| ST3 | nepoužito | MM3 |
| ST4 | nepoužito | MM4 |
| ST5 | nepoužito | MM5 |
| ST6 | nepoužito | MM6 |
| ST7 | nepoužito | MM7 |
12. Využití MMX v assembleru
V praktické části článku si ukážeme vybrané základní instrukce z rozšíření MMX. Ovšem oproti všem předchozím článkům, které byly v seriálu o vývoji pro PC prozatím vydány, nebudou tyto demonstrační příklady určeny pro operační systém DOS, ale pro Linux. Nejedná se o to, že by DOS instrukce MMX nepodporoval (lze je běžně využít i v reálném režimu a existuje i několik komerčních her, které je využívaly), ale některé emulátory PC a DOSu mají nedostatečnou podporu pro MMX a zejména pak pro rozšíření instrukčních sad SSE a AVX.
Z tohoto důvodu, alespoň pro tento okamžik, přejdeme z DOSu na Linux, přičemž ovšem díky použití assembleru NASM a jeho podpoře maker vlastně k žádným přelomovým změnám ve způsobu zápisu programů nedojde. Je tomu tak z toho důvodu, že volání služeb nabízených jádrem Linuxu bude „schováno“ do maker, podobně, jako jsme to dělali v DOSu. Jediným viditelnějším rozdílem je striktní oddělení kódu od inicializovaných dat i od dat neinicializovaných. To je řešeno takzvanými sekcemi TEXT (zde je uložen přeložený kód), DATA (inicializovaná data) a BSS (neinicializovaná data – nejsou uložena ve výsledném spustitelném binárním souboru).
info registers mm
mm0 {uint64 = 0x0, v2_int32 = {0x0, 0x0}, v4_int16 = {0x0, 0x0, 0x0, 0x0}, v8_int8 = {0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0}}
mm1 {uint64 = 0x807060504030201, v2_int32 = {0x4030201, 0x8070605}, v4_int16 = {0x201, 0x403, 0x605, 0x807}, v8_int8 = {0x1, 0x2, 0x3, 0x4, 0x5, 0x6, 0x7, 0x8}}
mm2 {uint64 = 0x807060504030201, v2_int32 = {0x4030201, 0x8070605}, v4_int16 = {0x201, 0x403, 0x605, 0x807}, v8_int8 = {0x1, 0x2, 0x3, 0x4, 0x5, 0x6, 0x7, 0x8}}
mm3 {uint64 = 0x0, v2_int32 = {0x0, 0x0}, v4_int16 = {0x0, 0x0, 0x0, 0x0}, v8_int8 = {0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0}}
mm4 {uint64 = 0x0, v2_int32 = {0x0, 0x0}, v4_int16 = {0x0, 0x0, 0x0, 0x0}, v8_int8 = {0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0}}
mm5 {uint64 = 0x0, v2_int32 = {0x0, 0x0}, v4_int16 = {0x0, 0x0, 0x0, 0x0}, v8_int8 = {0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0}}
mm6 {uint64 = 0x0, v2_int32 = {0x0, 0x0}, v4_int16 = {0x0, 0x0, 0x0, 0x0}, v8_int8 = {0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0}}
mm7 {uint64 = 0x0, v2_int32 = {0x0, 0x0}, v4_int16 = {0x0, 0x0, 0x0, 0x0}, v8_int8 = {0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0}}
13. Pomocný soubor s makry pro Linux a funkcí pro převod celočíselné hodnoty na hexadecimální řetězec
Makra, která jsou použita pro volání služeb Linuxu, jsou uložena do zvláštního souboru nazvaného linux_macros.asm. Nalezneme zde i makro pro převod celočíselné hodnoty na hexadecimální řetězec, ovšem vlastní subrutina pro převod je uložena v jiném souboru (prozatím jsme totiž nepsali o tom, jak pracuje linker):
%ifndef LINUX_MACROS_LIB
%define LINUX_MACROS_LIB
; Linux kernel system call table
sys_exit equ 1
sys_write equ 4
; makro pro tisk retezce na obrazovku
%macro print_string 2
mov eax, sys_write ; cislo syscallu pro funkci "write"
mov ebx, 1 ; standardni vystup
mov ecx, %1 ; adresa retezce, ktery se ma vytisknout
mov edx, %2 ; delka retezce
int 80h ; volani Linuxoveho kernelu
%endmacro
; makro pro tisk 32bitove hexadecimalni hodnoty
; na standardni vystup
%macro print_hex 2
push ebx ; uschovat EBX pro dalsi pouziti
mov edx, %1 ; zapamatovat si hodnotu pro tisk
mov ebx, hex_message ; buffer, ktery se zaplni hexa cislicemi
mov byte [ebx+8], %2 ; oddelovac, konec radku, atd.
call hex2string ; zavolani prislusne subrutiny
print_string hex_message, hex_message_length ; tisk hexadecimalni hodnoty
pop ebx ; obnovit EBX
%endmacro
; makro pro vypis obsahu MMX vektoru
%macro print_mmx_reg_as_hex 1
mov ebx, mmx_tmp ; adresa bufferu
movq [ebx], %1 ; ulozeni do pameti (8 bajtu)
mov eax, [ebx+4] ; nacteni casti MMX vektoru do celociselneho registru
print_hex eax, ' ' ; zobrazeni obsahu tohoto registru v hexadecimalnim tvaru
mov eax, [ebx] ; nacteni casti MMX vektoru do celociselneho registru
print_hex eax, 0x0a ; zobrazeni obsahu tohoto registru v hexadecimalnim tvaru
%endmacro
; makro pro ukonceni procesu
%macro exit 0
mov eax,sys_exit ; cislo sycallu pro funkci "exit"
mov ebx,0 ; exit code = 0
int 80h ; volani Linuxoveho kernelu
%endmacro
%endif
V dalším souboru hex2string.asm je uložena subrutina (podprogram) pro převod 32bitové hodnoty z registru EDX na hexadecimální vyjádření formou řetězce, jehož adresa je uložena v registru EBX:
%ifndef HEX_2_STRING_LIB
%define HEX_2_STRING_LIB
; subrutina urcena pro prevod 32bitove hexadecimalni hodnoty na retezec
; Vstup: EDX - hodnota, ktera se ma prevest na retezec
; EBX - adresa jiz drive alokovaneho retezce (resp. osmice bajtu)
hex2string:
mov ecx, 8 ; pocet opakovani smycky
.print_one_digit: rol edx, 4 ; rotace doleva znamena, ze se do spodnich 4 bitu nasune dalsi cifra
mov al, dl ; nechceme porusit obsah vstupni hodnoty v EDX, proto pouzijeme AL
and al, 0x0f ; maskovani, potrebujeme pracovat jen s jednou cifrou
cmp al, 10 ; je cifra vetsi nebo rovna 10?
jl .store_digit ; neni, pouze prevest 0..9 na ASCII hodnotu '0'..'9'
.alpha_digit: add al, 'A'-10-'0' ; prevod hodnoty 10..15 na znaky 'A'..'F'
.store_digit: add al, '0'
mov [ebx], al ; ulozeni cifry do retezce
inc ebx ; dalsi cifra
loop .print_one_digit ; a opakovani smycky, dokud se nedosahlo nuly
ret ; navrat ze subrutiny
%endif
Pro překlad demonstračních příkladů slouží Makefile, který vypadá (ve zkrácené podobě) následovně:
ASM=nasm
LINKER=ld
execs := mmx_init mmx_paddb_1 mmx_paddb_2 mmx_paddusb
all: $(execs)
clean:
rm -f *.o $(execs)
.PHONY: all clean
%.o: %.asm linux_macros.asm hex2string.asm
${ASM} -f elf $< -o $@
mmx_init: mmx_init.o
ld -melf_i386 $< -o $@
mmx_paddb_1: mmx_paddb_1.o
ld -melf_i386 $< -o $@
mmx_paddb_2: mmx_paddb_2.o
ld -melf_i386 $< -o $@
mmx_paddusb: mmx_paddusb.o
ld -melf_i386 $< -o $@
14. Načtení vektoru do MMX registru
V dnešním prvním demonstračním příkladu si ukážeme, jakým způsobem se načítá vektor, konkrétně vektor osmi hodnot typu byte do zvoleného MMX registru. Na začátku programu pro jistotu zavoláme instrukci EMMS, která inicializuje tagy pro všechny FPU registry (které jsou sdíleny s MMX). Tuto instrukci je nutné zavolat i při opuštění kódu (například subrutiny), která s MMX pracuje, to však prozatím není náš problém:
emms ; inicializace MMX
Samotné načtení vektoru je snadné. První instrukce načte adresu vektoru (v paměti) do zvoleného registru, například EBX (ale může jít i o jiný registr) a druhá instrukce MOVQ přesune všech osm bajtů do registru MM1 (z rozsahu MM0-MM7):
mov ebx, mmx_val
movq mm1, [ebx] ; nacteni hodnoty do registru MM1
Vektor je uložen následovně:
mmx_val db 1, 2, 3, 4, 5, 6, 7, 8
Tento demonstrační příklad by po svém spuštění měl vypsat obsah registru MM1, a to takto:
08070605 04030201
Dvě 32bitové hexadecimální hodnoty jsou pro větší čitelnost odděleny mezerou. A za povšimnutí stojí, že se vektor do registru MMX načetl tak, jako by bylo uložen v pořadí little-endian, což odpovídá architektuře x86. Konkrétně poslední dvě číslice 01 odpovídají nejnižšímu prvku atd.
Úplný zdrojový kód tohoto demonstračního příkladu vypadá následovně:
[bits 32]
%include "linux_macros.asm"
;-----------------------------------------------------------------------------
section .data
hex_message:
times 8 db '?'
db ' '
hex_message_length equ $ - hex_message
mmx_val db 1, 2, 3, 4, 5, 6, 7, 8
;-----------------------------------------------------------------------------
section .bss
mmx_tmp resb 8
;-----------------------------------------------------------------------------
section .text
global _start ; tento symbol ma byt dostupny i linkeru
_start:
emms ; inicializace MMX
mov ebx, mmx_val
movq mm1, [ebx] ; nacteni hodnoty do registru MM1
print_mmx_reg_as_hex mm1 ; tisk hodnoty registru MM1
exit ; ukonceni procesu
%include "hex2string.asm"
15. Součet osmiprvkových vektorů s hodnotami typu byte
Ve druhém demonstračním příkladu je ukázán součet dvou osmiprvkových vektorů s hodnotami typu byte. Nejprve načteme dvojici vektorů do MMX registrů MM1 a MM2:
mov ebx, mmx_val_1
movq mm1, [ebx] ; nacteni prvni hodnoty do registru MM1
mov ebx, mmx_val_2
movq mm2, [ebx] ; nacteni druhe hodnoty do registru MM1
Načtení bude provedeno ze dvou paměťových oblastí:
mmx_val_1 db 1, 2, 3, 4, 5, 6, 7, 8 mmx_val_2 db 1, 2, 3, 4, 5, 6, 7, 8
Následně provedeme součet obou vektorů instrukcí PADDB, která provádí součet bajt po bajtu (tedy paralelně se sečte osm hodnot prvního vektoru s osmi hodnotami vektoru druhého):
paddb mm1, mm2 ; soucet hodnot ve vektoru bajt po bajtu
Výsledky by měly vypadat následovně:
08070605 04030201 08070605 04030201 100E0C0A 08060402
Což lze chápat následovně:
první vektor: 08 07 06 05 04 03 02 01 druhý vektor: 08 07 06 05 04 03 02 01 součet vektorů: 10 0E 0C 0A 08 06 04 02
Opět si ukažme úplný zdrojový kód tohoto demonstračního příkladu:
[bits 32]
%include "linux_macros.asm"
;-----------------------------------------------------------------------------
section .data
hex_message:
times 8 db '?'
db ' '
hex_message_length equ $ - hex_message
mmx_val_1 db 1, 2, 3, 4, 5, 6, 7, 8
mmx_val_2 db 1, 2, 3, 4, 5, 6, 7, 8
;-----------------------------------------------------------------------------
section .bss
mmx_tmp resb 8
;-----------------------------------------------------------------------------
section .text
global _start ; tento symbol ma byt dostupny i linkeru
_start:
emms ; inicializace MMX
mov ebx, mmx_val_1
movq mm1, [ebx] ; nacteni prvni hodnoty do registru MM1
print_mmx_reg_as_hex mm1 ; tisk hodnoty registru MM1
mov ebx, mmx_val_2
movq mm2, [ebx] ; nacteni druhe hodnoty do registru MM1
print_mmx_reg_as_hex mm2 ; tisk hodnoty registru MM2
paddb mm1, mm2 ; soucet hodnot ve vektoru bajt po bajtu
print_mmx_reg_as_hex mm1 ; tisk hodnoty registru MM1
exit ; ukonceni procesu
%include "hex2string.asm"
16. Výsledný vektor v případě přetečení
V předchozím demonstračním příkladu byly hodnoty vektorů zvoleny tak vhodně, že nedošlo k žádnému přetečení. Co se však stane v případě, kdy použijeme instrukci PADDB a hodnoty ve vektorech budou zvoleny tak vhodně, že dojde k přetečení? To si lze snadno otestovat:
mmx_val_1 db 1, 2, 3, 4, 5, 6, 7, 8 mmx_val_2 db 0xfb, 0xfb, 0xfb, 0xfb, 0xfb, 0xfb, 0xfb, 0xfb
Výsledky:
08070605 04030201 FBFBFBFB FBFBFBFB 03020100 FFFEFDFC
Což lze interpretovat následovně:
první vektor: 08 07 06 05 04 03 02 01 druhý vektor: FB FB FB FB FB FB FB FB součet vektorů: 03 02 01 00 FF FE FD FC
Opět si ukažme úplný zdrojový kód tohoto demonstračního příkladu:
[bits 32]
%include "linux_macros.asm"
;-----------------------------------------------------------------------------
section .data
hex_message:
times 8 db '?'
db ' '
hex_message_length equ $ - hex_message
mmx_val_1 db 1, 2, 3, 4, 5, 6, 7, 8
mmx_val_2 db 0xfb, 0xfb, 0xfb, 0xfb, 0xfb, 0xfb, 0xfb, 0xfb
;-----------------------------------------------------------------------------
section .bss
mmx_tmp resb 8
;-----------------------------------------------------------------------------
section .text
global _start ; tento symbol ma byt dostupny i linkeru
_start:
emms ; inicializace MMX
mov ebx, mmx_val_1
movq mm1, [ebx] ; nacteni prvni hodnoty do registru MM1
print_mmx_reg_as_hex mm1 ; tisk hodnoty registru MM1
mov ebx, mmx_val_2
movq mm2, [ebx] ; nacteni druhe hodnoty do registru MM1
print_mmx_reg_as_hex mm2 ; tisk hodnoty registru MM2
paddb mm1, mm2 ; soucet hodnot ve vektoru bajt po bajtu
print_mmx_reg_as_hex mm1 ; tisk hodnoty registru MM1
exit ; ukonceni procesu
%include "hex2string.asm"
17. Součet osmiprvkových vektorů se saturací
V multimediálních a DSP aplikacích je velmi užitečná i možnost sčítat a odčítat se saturací namísto přetečení. Podívejme se, proč jsou tyto operace v praxi velmi užitečné:

Obrázek 13: Zdrojový rastrový obrázek (známá fotografie Lenny), který tvoří zdroj pro jednoduchý konvoluční (FIR) filtr, jenž zvyšuje hodnoty pixelů o pevně zadanou konstantu (offset).

Obrázek 14: Pokud je pro přičtení offsetu použita operace součtu se zanedbáním přenosu (carry), tj. když se počítá systémem „modulo N“ (viz též výše zmíněná instrukce PADDB), dochází při překročení maximální hodnoty pixelu (čistě bílá barva) k viditelným chybám.

Obrázek 15: Při použití operace součtu se saturací sice dojde ke ztrátě informace (vzniknou oblasti s pixely majícími hodnotu 255), ovšem viditelná chyba je mnohem menší, než kdyby docházelo k přetečení (ostatně – dokážete chyby identifikovat?). Tento filtr by bylo možné realizovat s využitím instrukce PADDUSB s rychlostí výpočtu 8 pixelů/instrukci při bitové hloubce 8bpp.
Podívejme se tedy konkrétně na instrukci PADDUSB, která sčítá osmice bajtů se saturací. Vstupem jsou tyto dva vektory (totožné s předchozím příkladem):
mmx_val_1 db 1, 2, 3, 4, 5, 6, 7, 8 mmx_val_2 db 0xfb, 0xfb, 0xfb, 0xfb, 0xfb, 0xfb, 0xfb, 0xfb
Výsledek výpočtu:
první vektor: 08 07 06 05 04 03 02 01 druhý vektor: FB FB FB FB FB FB FB FB součet vektorů: FF FF FF FF FF FE FD FC
Což je značně odlišné od součtu s přetečením, jaký jsme už viděli:
první vektor: 08 07 06 05 04 03 02 01 druhý vektor: FB FB FB FB FB FB FB FB součet vektorů: 03 02 01 00 FF FE FD FC
Ukažme si pro úplnost i tento zdrojový příklad:

[bits 32]
%include "linux_macros.asm"
;-----------------------------------------------------------------------------
section .data
hex_message:
times 8 db '?'
db ' '
hex_message_length equ $ - hex_message
mmx_val_1 db 1, 2, 3, 4, 5, 6, 7, 8
mmx_val_2 db 0xfb, 0xfb, 0xfb, 0xfb, 0xfb, 0xfb, 0xfb, 0xfb
;-----------------------------------------------------------------------------
section .bss
mmx_tmp resb 8
;-----------------------------------------------------------------------------
section .text
global _start ; tento symbol ma byt dostupny i linkeru
_start:
emms ; inicializace MMX
mov ebx, mmx_val_1
movq mm1, [ebx] ; nacteni prvni hodnoty do registru MM1
print_mmx_reg_as_hex mm1 ; tisk hodnoty registru MM1
mov ebx, mmx_val_2
movq mm2, [ebx] ; nacteni druhe hodnoty do registru MM1
print_mmx_reg_as_hex mm2 ; tisk hodnoty registru MM2
paddusb mm1, mm2 ; soucet hodnot ve vektoru bajt po bajtu
print_mmx_reg_as_hex mm1 ; tisk hodnoty registru MM1
exit ; ukonceni procesu
%include "hex2string.asm"
18. Obsah navazujícího článku
Prozatím jsme si ukázali pouze naprosté základy rozšíření instrukční sady MMX. Příště budeme v popisu této sady pokračovat, přičemž si ukážeme velkou řadu různých demonstračních příkladů. Taktéž si ukážeme, jak lze vlastně detekovat, zda mikroprocesor vůbec MMX podporuje. Pro tento účel využijeme instrukci CPUID, která se pro tyto účely používá dodnes.
19. Repositář s demonstračními příklady
Demonstrační příklady napsané v assembleru, které jsou určené pro překlad s využitím assembleru NASM, byly uloženy do Git repositáře, který je dostupný na adrese https://github.com/tisnik/8bit-fame. Jednotlivé demonstrační příklady si můžete v případě potřeby stáhnout i jednotlivě bez nutnosti klonovat celý (dnes již poměrně rozsáhlý) repositář:
| # | Příklad | Stručný popis | Adresa |
|---|---|---|---|
| 1 | hello.asm | program typu „Hello world“ naprogramovaný v assembleru pro systém DOS | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/hello.asm |
| 2 | hello_shorter.asm | kratší varianta výskoku z procesu zpět do DOSu | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/hello_shorter.asm |
| 3 | hello_wait.asm | čekání na stisk klávesy | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/hello_wait.asm |
| 4 | hello_macros.asm | realizace jednotlivých částí programu makrem | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/hello_macros.asm |
| 5 | gfx4_putpixel.asm | vykreslení pixelu v grafickém režimu 4 | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/gfx4_putpixel.asm |
| 6 | gfx6_putpixel.asm | vykreslení pixelu v grafickém režimu 6 | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/gfx6_putpixel.asm |
| 7 | gfx4_line.asm | vykreslení úsečky v grafickém režimu 4 | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/gfx4_line.asm |
| 8 | gfx6_line.asm | vykreslení úsečky v grafickém režimu 6 | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/gfx6_line.asm |
| 9 | gfx6_fill1.asm | vyplnění obrazovky v grafickém režimu, základní varianta | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/gfx6_fill1.asm |
| 10 | gfx6_fill2.asm | vyplnění obrazovky v grafickém režimu, varianta s instrukcí LOOP | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/gfx6_fill2.asm |
| 11 | gfx6_fill3.asm | vyplnění obrazovky instrukcí REP STOSB | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/gfx6_fill3.asm |
| 12 | gfx6_fill4.asm | vyplnění obrazovky, synchronizace vykreslování s paprskem | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/gfx6_fill4.asm |
| 13 | gfx4_image1.asm | vykreslení rastrového obrázku získaného z binárních dat, základní varianta | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/gfx4_image1.asm |
| 14 | gfx4_image2.asm | varianta vykreslení rastrového obrázku s využitím instrukce REP MOVSB | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/gfx4_image2.asm |
| 15 | gfx4_image3.asm | varianta vykreslení rastrového obrázku s využitím instrukce REP MOVSW | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/gfx4_image3.asm |
| 16 | gfx4_image4.asm | korektní vykreslení všech sudých řádků bitmapy | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/gfx4_image4.asm |
| 17 | gfx4_image5.asm | korektní vykreslení všech sudých i lichých řádků bitmapy | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/gfx4_image5.asm |
| 18 | gfx4_image6.asm | nastavení barvové palety před vykreslením obrázku | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/gfx4_image6.asm |
| 19 | gfx4_image7.asm | nastavení barvové palety před vykreslením obrázku, snížená intenzita barev | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/gfx4_image7.asm |
| 20 | gfx4_image8.asm | postupná změna barvy pozadí | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/gfx4_image8.asm |
| 21 | gfx6_putpixel1.asm | vykreslení pixelu, základní varianta se 16bitovým násobením | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/gfx6_putpixel1.asm |
| 22 | gfx6_putpixel2.asm | vykreslení pixelu, varianta s osmibitovým násobením | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/gfx6_putpixel2.asm |
| 23 | gfx6_putpixel3.asm | vykreslení pixelu, varianta bez násobení | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/gfx6_putpixel3.asm |
| 24 | gfx6_putpixel4.asm | vykreslení pixelu přes obrázek, nekorektní chování (přepis obrázku) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/gfx6_putpixel4.asm |
| 25 | gfx6_putpixel5.asm | vykreslení pixelu přes obrázek, korektní varianta pro bílé pixely | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/gfx6_putpixel5.asm |
| 26 | cga_text_mode1.asm | standardní textový režim s rozlišením 40×25 znaků | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/cga_text_mode1.asm |
| 27 | cga_text_mode3.asm | standardní textový režim s rozlišením 80×25 znaků | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/cga_text_mode3.asm |
| 28 | cga_text_mode_intensity.asm | změna významu nejvyššího bitu atributového bajtu: vyšší intenzita namísto blikání | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/cga_text_mode_intensity.asm |
| 29 | cga_text_mode_cursor.asm | změna tvaru textového kurzoru | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/cga_text_mode_cursor.asm |
| 30 | cga_text_gfx1.asm | zobrazení „rastrové mřížky“: pseudografický režim 160×25 pixelů (interně textový režim) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/cga_text_gfx1.asm |
| 31 | cga_text_mode_char_height.asm | změna výšky znaků | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/cga_text_mode_char_height.asm |
| 32 | cga_text_160×100.asm | grafický režim 160×100 se šestnácti barvami (interně upravený textový režim) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/cga_text_160×100.asm |
| 33 | hercules_text_mode1.asm | využití standardního textového režimu společně s kartou Hercules | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/hercules_text_mode1.asm |
| 34 | hercules_text_mode2.asm | zákaz blikání v textových režimech | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/hercules_text_mode2.asm |
| 35 | hercules_turn_off.asm | vypnutí generování video signálu | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/hercules_turn_off.asm |
| 36 | hercules_gfx_mode1.asm | přepnutí karty Hercules do grafického režimu (základní varianta) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/hercules_gfx_mode1.asm |
| 37 | hercules_gfx_mode2.asm | přepnutí karty Hercules do grafického režimu (vylepšená varianta) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/hercules_gfx_mode2.asm |
| 38 | hercules_putpixel.asm | subrutina pro vykreslení jediného pixelu na kartě Hercules | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/hercules_putpixel.asm |
| 39 | ega_text_mode_80×25.asm | standardní textový režim 80×25 znaků na kartě EGA | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/ega_text_mode_80×25.asm |
| 40 | ega_text_mode_80×43.asm | zobrazení 43 textových řádků na kartě EGA | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/ega_text_mode_80×43.asm |
| 41 | ega_gfx_mode_320×200.asm | přepnutí do grafického režimu 320×200 pixelů se šestnácti barvami | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/ega_gfx_mode_320×200.asm |
| 42 | ega_gfx_mode_640×200.asm | přepnutí do grafického režimu 640×200 pixelů se šestnácti barvami | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/ega_gfx_mode_640×200.asm |
| 43 | ega_gfx_mode_640×350.asm | přepnutí do grafického režimu 640×350 pixelů se čtyřmi nebo šestnácti barvami | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/ega_gfx_mode_640×350.asm |
| 44 | ega_gfx_mode_bitplanes1.asm | ovládání zápisu do bitových rovin v planárních grafických režimech (základní způsob) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/ega_gfx_mode_bitplanes1.asm |
| 45 | ega_gfx_mode_bitplanes2.asm | ovládání zápisu do bitových rovin v planárních grafických režimech (rychlejší způsob) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/ega_gfx_mode_bitplanes2.asm |
| 46 | ega_320×200_putpixel.asm | vykreslení pixelu v grafickém režimu 320×200 pixelů se šestnácti barvami | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/ega_320×200_putpixel.asm |
| 47 | ega_640×350_putpixel.asm | vykreslení pixelu v grafickém režimu 640×350 pixelů se šestnácti barvami | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/ega_640×350_putpixel.asm |
| 48 | ega_standard_font.asm | použití standardního fontu grafické karty EGA | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/ega_standard_font.asm |
| 49 | ega_custom_font.asm | načtení vlastního fontu s jeho zobrazením | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/ega_custom_font.asm |
| 50 | ega_palette1.asm | změna barvové palety (všech 16 barev) v grafickém režimu 320×200 se šestnácti barvami | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/ega_palette1.asm |
| 51 | ega_palette2.asm | změna barvové palety (všech 16 barev) v grafickém režimu 640×350 se šestnácti barvami | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/ega_palette2.asm |
| 52 | ega_palette3.asm | změna všech barev v barvové paletě s využitím programové smyčky | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/ega_palette3.asm |
| 53 | ega_palette4.asm | změna všech barev, včetně barvy okraje, v barvové paletě voláním funkce BIOSu | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/ega_palette4.asm |
| 54 | vga_text_mode_80×25.asm | standardní textový režim 80×25 znaků na kartě VGA | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_text_mode_80×25.asm |
| 55 | vga_text_mode_80×50.asm | zobrazení 50 a taktéž 28 textových řádků na kartě VGA | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_text_mode_80×50.asm |
| 56 | vga_text_mode_intensity1.asm | změna chování atributového bitu pro blikání (nebezpečná varianta změny registrů) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_text_mode_intensity1.asm |
| 57 | vga_text_mode_intensity2.asm | změna chování atributového bitu pro blikání (bezpečnější varianta změny registrů) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_text_mode_intensity2.asm |
| 58 | vga_text_mode_9th_column.asm | modifikace způsobu zobrazení devátého sloupce ve znakových režimech (720 pixelů na řádku) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_text_mode_9th_column.asm |
| 59 | vga_text_mode_cursor_shape.asm | změna tvaru textového kurzoru na grafické kartě VGA | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_text_mode_cursor_shape.asm |
| 60 | vga_text_mode_custom_font.asm | načtení vlastního fontu s jeho zobrazením | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_text_mode_custom_font.asm |
| 61 | vga_gfx_mode_640×480.asm | přepnutí do grafického režimu 640×480 pixelů se šestnácti barvami, vykreslení vzorků | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_gfx_mode_640×480.asm |
| 62 | vga_gfx_mode_320×200.asm | přepnutí do grafického režimu 320×200 pixelů s 256 barvami, vykreslení vzorků | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_gfx_mode_320×200.asm |
| 63 | vga_gfx_mode_palette.asm | změna všech barev v barvové paletě grafické karty VGA | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_gfx_mode_palette.asm |
| 64 | vga_gfx_mode_dac1.asm | využití DAC (neočekávané výsledky) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_gfx_mode_dac1.asm |
| 65 | vga_gfx_mode_dac2.asm | využití DAC (očekávané výsledky) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_gfx_mode_dac2.asm |
| 66 | vga_640×480_putpixel.asm | realizace algoritmu pro vykreslení pixelu v grafickém režimu 640×480 pixelů se šestnácti barvami | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_640×480_putpixel.asm |
| 67 | vga_320×200_putpixel1.asm | realizace algoritmu pro vykreslení pixelu v grafickém režimu 320×200 s 256 barvami (základní varianta) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×200_putpixel1.asm |
| 68 | vga_320×200_putpixel2.asm | realizace algoritmu pro vykreslení pixelu v grafickém režimu 320×200 s 256 barvami (rychlejší varianta) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×200_putpixel2.asm |
| 69 | vga_gfx_mode_dac3.asm | přímé využití DAC v grafickém režimu 13h | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_gfx_mode_dac3.asm |
| 70 | vga_gfx_mode_unchained_step1.asm | zobrazení barevných pruhů v režimu 13h | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_gfx_mode_unchained_step1.asm |
| 71 | vga_gfx_mode_unchained_step2.asm | vypnutí zřetězení bitových rovin a změna způsobu adresování pixelů | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_gfx_mode_unchained_step2.asm |
| 72 | vga_gfx_mode_unchained_step3.asm | vykreslení barevných pruhů do vybraných bitových rovin | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_gfx_mode_unchained_step3.asm |
| 73 | vga_gfx_mode_320×400.asm | nestandardní grafický režim s rozlišením 320×400 pixelů a 256 barvami | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_gfx_mode_320×400.asm |
| 74 | vga_320×200_image.asm | zobrazení rastrového obrázku ve standardním grafickém režimu 320×200 pixelů | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×200_image.asm |
| 75 | vga_320×200_unchained_image1.asm | zobrazení rastrového obrázku v režimu s nezřetězenými rovinami (nekorektní řešení) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×200_unchained_image1.asm |
| 76 | vga_320×200_unchained_image2.asm | zobrazení rastrového obrázku v režimu s nezřetězenými rovinami (korektní řešení) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×200_unchained_image2.asm |
| 77 | vga_320×400_unchained_image.asm | zobrazení rastrového obrázku v nestandardním režimu 320×400 pixelů | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×400_unchained_image.asm |
| 78 | vga_vertical_scroll1.asm | vertikální scrolling na kartě VGA v režimu s rozlišením 320×200 pixelů | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_vertical_scroll1.asm |
| 79 | vga_vertical_scroll2.asm | vertikální scrolling na kartě VGA v režimu s rozlišením 320×400 pixelů | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_vertical_scroll2.asm |
| 80 | vga_split_screen1.asm | režim split-screen a scrolling, nefunční varianta | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_split_screen1.asm |
| 81 | vga_split_screen2.asm | režim split-screen a scrolling, plně funkční varianta | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_split_screen2.asm |
| 82 | vga_horizontal_scroll1.asm | horizontální scrolling bez rozšíření počtu pixelů na virtuálním řádku | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_horizontal_scroll1.asm |
| 83 | vga_horizontal_scroll2.asm | horizontální scrolling s rozšířením počtu pixelů na virtuálním řádku | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_horizontal_scroll2.asm |
| 84 | vga_horizontal_scroll3.asm | jemný horizontální scrolling s rozšířením počtu pixelů na virtuálním řádku | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_horizontal_scroll3.asm |
| 85 | vga_320×240_image.asm | nastavení grafického režimu Mode-X, načtení a vykreslení obrázku, scrolling | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×240_image.asm |
| 86 | io.asm | knihovna maker pro I/O operace | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/io.asm |
| 87 | vga_lib.asm | knihovna maker a podprogramů pro programování karty VGA | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_lib.asm |
| 88 | vga_320×240_lib.asm | nastavení grafického režimu Mode-X, tentokrát knihovními funkcemi | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×240_lib.asm |
| 89 | vga_bitblt1.asm | první (naivní) implementace operace BitBLT | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_bitblt1.asm |
| 90 | vga_bitblt2.asm | operace BitBLT s výběrem bitových rovin pro zápis | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_bitblt2.asm |
| 91 | vga_bitblt3.asm | operace BitBLT s výběrem bitových rovin pro čtení i zápis | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_bitblt3.asm |
| 92 | vga_bitblt4.asm | korektní BitBLT pro 16barevný režim, realizace makry | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_bitblt4.asm |
| 93 | vga_bitblt5.asm | korektní BitBLT pro 16barevný režim, realizace podprogramem | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_bitblt5.asm |
| 94 | vga_bitblt_rotate.asm | zápisový režim s rotací bajtu | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_bitblt_rotate.asm |
| 95 | vga_bitblt_fast.asm | rychlá korektní 32bitová operace typu BitBLT | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_bitblt_fast.asm |
| 96 | vga_320×400_bitblt1.asm | přenos obrázku v režimu 320×400 operací BitBLT (neúplná varianta) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×400_bitblt1.asm |
| 97 | vga_320×400_bitblt2.asm | přenos obrázku v režimu 320×400 operací BitBLT (úplná varianta) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×400_bitblt2.asm |
| 98 | vga_write_modes1.asm | volitelné zápisové režimy grafické karty VGA, zápis bez úpravy latche | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_write_modes1.asm |
| 99 | vga_write_modes2.asm | volitelné zápisové režimy grafické karty VGA, zápis s modifikací latche | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_write_modes2.asm |
| 100 | vga_write_modes3.asm | volitelné zápisové režimy grafické karty VGA, cílená modifikace latche vzorkem | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_write_modes3.asm |
| 101 | instruction_jump.asm | použití instrukce JMP | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_jump.asm |
| 102 | instruction_jnz.asm | použití instrukce JNZ pro realizaci programové smyčky | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_jnz.asm |
| 103 | instruction_jz_jmp.asm | použití instrukcí JZ a JMP pro realizaci programové smyčky | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_jz_jmp.asm |
| 104 | instruction_loop.asm | použití instrukce LOOP pro realizaci programové smyčky | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_loop.asm |
| 105 | instruction_template.asm | šablona všech následujících demonstračních příkladů | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_template.asm |
| 106 | instruction_print_hex.asm | tisk osmibitové hexadecimální hodnoty | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_print_hex.asm |
| 107 | instruction_xlat.asm | využití instrukce XLAT pro získání tisknutelné hexadecimální cifry | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_xlat.asm |
| 108 | instruction_daa.asm | operace součtu s využitím binární i BCD aritmetiky | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_daa.asm |
| 109 | instruction_daa_sub.asm | instrukce DAA po provedení operace rozdílu | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_daa_sub.asm |
| 110 | instruction_das.asm | instrukce DAS po provedení operace rozdílu | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_das.asm |
| 111 | instruction_aaa.asm | korekce výsledku na jedinou BCD cifru operací AAA | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_aaa.asm |
| 112 | instruction_mul.asm | ukázka výpočtu součinu dvou osmibitových hodnot | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_mul.asm |
| 113 | instruction_aam.asm | BCD korekce po výpočtu součinu instrukcí AAM | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_aam.asm |
| 114 | instruction_stosb.asm | blokový zápis dat instrukcí STOSB | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_stosb.asm |
| 115 | instruction_rep_stosb.asm | opakované provádění instrukce STOSB | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_rep_stosb.asm |
| 116 | instruction_lodsb.asm | čtení dat instrukcí LODSB | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_lodsb.asm |
| 117 | instruction_movsb.asm | přenos jednoho bajtu instrukcí MOVSB | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_movsb.asm |
| 118 | instruction_rep_movsb.asm | blokový přenos po bajtech instrukcí MOVSB | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_rep_movsb.asm |
| 119 | instruction_rep_scas.asm | vyhledávání v řetězci instrukcí SCAS | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_rep_scas.asm |
| 120 | vga_320×200_image_0B.asm | výsledek blokového přenosu ve chvíli, kdy je CX=0 | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×200_image_0B.asm |
| 121 | vga_320×200_image_64kB.asm | výsledek blokového přenosu ve chvíli, kdy je CX=0×ffff | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×200_image_64kB.asm |
| 122 | vga_320×200_image_movsb.asm | blokový přenos v rámci obrazové paměti instrukcí REP MOVSB | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×200_image_movsb.asm |
| 123 | vga_320×200_image_movsw.asm | blokový přenos v rámci obrazové paměti instrukcí REP MOVSW | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×200_image_movsw.asm |
| 124 | vga_320×200_image_movsd.asm | blokový přenos v rámci obrazové paměti instrukcí REP MOVSD | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×200_image_movsd.asm |
| 125 | vga_320×200_image_movsb_forward.asm | blokový přenos překrývajících se bloků paměti (zvyšující se adresy) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×200_image_movsb_forward.asm |
| 126 | vga_320×200_image_movsb_backward1.asm | blokový přenos překrývajících se bloků paměti (snižující se adresy, nekorektní nastavení) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×200_image_movsb_backward1.asm |
| 127 | vga_320×200_image_movsb_backward2.asm | blokový přenos překrývajících se bloků paměti (snižující se adresy, korektní nastavení) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×200_image_movsb_backward2.asm |
| 128 | sound_bell.asm | přehrání zvuku pomocí tisku ASCII znaku BELL | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/sound_bell.asm |
| 129 | sound_beep.asm | přehrání zvuku o zadané frekvenci na PC Speakeru | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/sound_beep.asm |
| 130 | sound_play_pitch.asm | přehrání zvuku o zadané frekvenci na PC Speakeru, použití maker | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/sound_play_pitch.asm |
| 131 | sound_opl2_basic.asm | přehrání komorního A na OPL2 | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/sound_opl2_basic.asm |
| 132 | sound_opl2_table.asm | přehrání komorního A na OPL2, použití tabulky s hodnotami registrů | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/sound_opl2_table.asm |
| 133 | sound_opl2_table2.asm | přepis tabulky s obsahy registrů pro přehrání komorního A | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/sound_opl2_table2.asm |
| 134 | sound_key_on.asm | přímé ovládání bitu KEY ON mezerníkem | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/sound_key_on.asm |
| 135 | sound_adsr.asm | nastavení obálky pro tón přehrávaný prvním kanálem | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/sound_adsr.asm |
| 136 | sound_modulation.asm | řízení frekvence modulátoru klávesami 1 a 0 | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/sound_modulation.asm |
| 137 | keyboard_basic.asm | přímá práce s klávesnicí IBM PC | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/keyboard_basic.asm |
| 138 | sound_stereo_opl2.asm | stereo zvuk v konfiguraci DualOPL2 | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/sound_stereo_opl2.asm |
| 139 | sound_opl2_multichannel.asm | vícekanálový zvuk na OPL2 (klávesy), delší varianta | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/sound_opl2_multichannel.asm |
| 140 | sound_opl2_multichannel2.asm | vícekanálový zvuk na OPL2 (klávesy), kratší varianta | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/sound_opl2_multichannel2.asm |
| 141 | sound_opl3_stereo1.asm | stereo výstup na OPL3 (v kompatibilním režimu) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/sound_opl3_stereo1.asm |
| 142 | sound_opl3_stereo2.asm | stereo výstup na OPL3 (v režimu OPL3) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/sound_opl3_stereo2.asm |
| 143 | sound_opl3_multichannel.asm | vícekanálový zvuk na OPL3 (klávesy) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/sound_opl3_multichannel.asm |
| 144 | sound_opl3_waveform1.asm | interaktivní modifikace tvaru vlny u prvního operátoru | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/sound_opl3_waveform1.asm |
| 145 | sound_opl3_waveform2.asm | oprava chyby: povolení režimu kompatibilního s OPL3 | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/sound_opl3_waveform2.asm |
| 146 | sound_opl3_waveform3.asm | vliv tvaru vln na zvukový kanál s FM syntézou | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/sound_opl3_waveform3.asm |
| 147 | sound_opl3_waveform4.asm | modifikace tvaru vlny nosné vlny i modulátoru | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/sound_opl3_waveform4.asm |
| 148 | sound_opl3_4operators1.asm | výběr AM/FM režimu ve čtyřoperátorovém nastavení | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/sound_opl3_4operators1.asm |
| 149 | sound_opl3_4operators2.asm | výběr AM/FM režimu ve čtyřoperátorovém nastavení | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/sound_opl3_4operators2.asm |
| 150 | timer_basic.asm | základní obsluha přerušení od časovače/čítače | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/timer_basic.asm |
| 151 | timer_restore.asm | obnovení původní obsluhy přerušení při ukončování aplikace | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/timer_restore.asm |
| 152 | timer_restore_better_structure.asm | refaktoring předchozího demonstračního příkladu | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/timer_restore_better_structure.asm |
| 153 | timer_faster_clock.asm | zrychlení čítače na 100 přerušení za sekundu | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/timer_faster_clock.asm |
| 154 | instruction_push_imm.asm | instrukce PUSH s konstantou | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_push_imm.asm |
| 155 | instruction_imul_imm.asm | instrukce IMUL s konstantou | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_imul_imm.asm |
| 156 | instruction_into1.asm | instrukce INTO s obsluhou přerušení | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_into1.asm |
| 157 | instruction_into2.asm | instrukce INTO s obsluhou přerušení | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_into2.asm |
| 158 | instruction_bound1.asm | instrukce BOUND s obsluhou přerušení (nekorektní řešení) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_bound1.asm |
| 159 | instruction_bound2.asm | instrukce BOUND s obsluhou přerušení (korektní řešení) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_bound2.asm |
| 160 | vga_320×200_putpixel286.asm | instrukce bitového posunu s konstantou větší než 1 | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×200_putpixel286.asm |
| 161 | instruction_push_pop.asm | instrukce PUSH a POP se všemi pracovními registry | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_push_pop.asm |
| 162 | instruction_push_pop_B.asm | instrukce s novými segmentovými registry | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_push_pop_B.asm |
| 163 | instruction_near_jz_jmp.asm | blízké skoky | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_near_jz_jmp.asm |
| 164 | instruction_bsf.asm | nová instrukce BSF | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_bsf.asm |
| 165 | instruction_bsr.asm | nová instrukce BSR | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_bsr.asm |
| 166 | instruction_add_32bit.asm | 32bitový součet | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_add_32bit.asm |
| 167 | instruction_inc_32bit.asm | 32bitová instrukce INC v šestnáctibitovém režimu | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_inc_32bit.asm |
| 168 | instruction_inc_32bit_B.asm | 32bitová instrukce INC v 32bitovém režimu | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/instruction_inc_32bit_B.asm |
| 169 | ems_status.asm | zjištění stavu (emulace) paměti EMS | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/ems_status.asm |
| 170 | ems_total_mem.asm | získání celkové kapacity paměti EMS v blocích | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/ems_total_mem.asm |
| 171 | ems_free_mem.asm | získání volné kapacity paměti EMS v blocích | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/ems_free_mem.asm |
| 172 | xms_free_mem.asm | získání volné kapacity paměti XMS v blocích | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/xms_free_mem.asm |
| 173 | vga_320×200_short_address1.asm | blokový přenos provedený v rámci prostoru segmentu | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×200_short_address1.asm |
| 174 | vga_320×200_short_address2.asm | rozepsaný blokový přenos provedený v rámci prostoru segmentu | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×200_short_address2.asm |
| 175 | vga_320×200_short_address3.asm | přenos nelze provést přes hranici offsetu | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×200_short_address3.asm |
| 176 | vga_320×200_short_address4.asm | přenos nelze provést přes hranici offsetu | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×200_short_address4.asm |
| 177 | vga_320×200_long_address1.asm | 32bitový blokový přenos | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×200_long_address1.asm |
| 178 | vga_320×200_long_address2.asm | rozepsaný 32bitový blokový přenos provedený v rámci prostoru segmentu | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×200_long_address2.asm |
| 179 | vga_320×200_long_address3.asm | přístup do obrazové paměti přes segment 0×0000 a 32bitový offset | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×200_long_address3.asm |
| 180 | vga_320×200_long_address4.asm | otestování, jak lze přenášet data s využitím 32bitového offsetu | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/vga_320×200_long_address4.asm |
| 181 | print_msw.asm | přečtení a zobrazení obsahu speciálního registru MSW | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/print_msw.asm |
| 182 | print_cr0.asm | přečtení a zobrazení obsahu speciálního registru CR0 | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/print_cr0.asm |
| 183 | prot_mode286.asm | přechod do chráněného režimu na čipech Intel 80286 | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/prot_mode286.asm |
| 184 | prot_mode386.asm | přechod do chráněného režimu na čipech Intel 80386 | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/prot_mode386.asm |
| 185 | prot_mode_back_to_real_mode286.asm | přechod mezi reálným režimem a chráněným režimem i zpět na čipech Intel 80286 | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/prot_mode_back_to_real_mode286.asm |
| 186 | prot_mode_back_to_real_mode386.asm | přechod mezi reálným režimem a chráněným režimem i zpět na čipech Intel 80386 | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/prot_mode_back_to_real_mode386.asm |
| 187 | prot_mode_check.asm | test, zda se mikroprocesor již nachází v chráněném režimu | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/prot_mode_check.asm |
| 188 | unreal_mode.asm | nastavení nereálného režimu (platné pro Intel 80386) | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/unreal_mode.asm |
| 189 | float32_constants.asm | vytištění základních FP konstant typu single | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/float32_constants.asm |
| 190 | float64_constants.asm | vytištění základních FP konstant typu double | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/float64_constants.asm |
| 191 | fpu_arithmetic.asm | základní aritmetické operace prováděné matematickým koprocesorem | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/fpu_arithmetic.asm |
| 192 | fpu_divide_by_zero.asm | dělení nulou matematickým koprocesorem | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/fpu_divide_by_zero.asm |
| 193 | fpu_divide_by_neg_zero.asm | dělení záporné hodnoty nulou matematickým koprocesorem | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/fpu_divide_by_neg_zero.asm |
| 194 | fpu_divide_by_neg_zero2.asm | dělení hodnoty zápornou nulou matematickým koprocesorem | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/fpu_divide_by_neg_zero2.asm |
| 195 | fpu_divide_zero_by_zero.asm | výpočet 0/0 matematickým koprocesorem | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/fpu_divide_zero_by_zero.asm |
| 196 | io.asm | pomocná makra pro komunikaci s DOSem a BIOSem | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/io.asm |
| 197 | print.asm | pomocná makra pro tisk FPU hodnot typu single a double v hexadecimálním tvaru | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/print.asm |
| 198 | fpu_divide.asm | operace podílu | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/fpu_divide.asm |
| 199 | fpu_divide_r.asm | operace podílu s prohozenými operandy | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/fpu_divide_r.asm |
| 200 | fpu_sqrt.asm | výpočet druhé odmocniny | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/fpu_sqrt.asm |
| 201 | fpu_sqrt_neg_value.asm | výpočet druhé odmocniny ze záporné hodnoty | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/fpu_sqrt_neg_value.asm |
| 202 | fpu_check.asm | detekce typu matematického koprocesoru | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/fpu_check.asm |
| 203 | fpu_compare.asm | porovnání dvou hodnot s vyhodnocením výsledku | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/fpu_compare.asm |
| 204 | fpu_status_word.asm | tisk obsahu stavového slova koprocesoru | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/fpu_status_word.asm |
| 205 | fpu_status_word_stack.asm | tisk obsahu stavového slova koprocesoru | https://github.com/tisnik/8bit-fame/blob/master/pc-dos/fpu_status_word_stack.asm |
| 206 | Makefile | https://github.com/tisnik/8bit-fame/blob/master/pc-linux/Makefile | |
| 207 | hex2string.asm | subrutina pro převod 32bitové hexadecimální hodnoty na řetězec | https://github.com/tisnik/8bit-fame/blob/master/pc-linux/hex2string.asm |
| 208 | linux_macros.asm | pomocná makra pro tvorbu aplikací psaných v assembleru pro Linux | https://github.com/tisnik/8bit-fame/blob/master/pc-linux/linux_macros.asm |
| 209 | mmx_init.asm | inicializace subsystému MMX | https://github.com/tisnik/8bit-fame/blob/master/pc-linux/mmx_init.asm |
| 210 | mmx_paddb1.asm | zavolání MMX instrukce pro součet vektorů bajtů (bez přetečení) | https://github.com/tisnik/8bit-fame/blob/master/pc-linux/mmx_paddb1.asm |
| 211 | mmx_paddb2.asm | zavolání MMX instrukce pro součet vektorů bajtů (s přetečením) | https://github.com/tisnik/8bit-fame/blob/master/pc-linux/mmx_paddb2.asm |
| 212 | mmx_paddusb.asm | zavolání MMX instrukce pro součet vektorů bajtů se saturací | https://github.com/tisnik/8bit-fame/blob/master/pc-linux/mmx_paddusb.asm |
| 213 | mmx_paddw.asm | zavolání MMX instrukce pro součet vektorů šestnáctibitových slov | https://github.com/tisnik/8bit-fame/blob/master/pc-linux/mmx_paddw.asm |
| 214 | mmx_paddd.asm | zavolání MMX instrukce pro součet vektorů 32bitových slov | https://github.com/tisnik/8bit-fame/blob/master/pc-linux/mmx_paddd.asm |
| 215 | mmx_paddq.asm | zavolání MMX instrukce pro součet 64bitových slov | https://github.com/tisnik/8bit-fame/blob/master/pc-linux/mmx_paddq.asm |
| 216 | mmx_paddx.asm | porovnání operací součtu pro vektory s prvky různých typů | https://github.com/tisnik/8bit-fame/blob/master/pc-linux/mmx_paddx.asm |
| 217 | mmx_support.asm | zjištění, zda je MMX podporována | https://github.com/tisnik/8bit-fame/blob/master/pc-linux/mmx_support.asm |
20. Odkazy na Internetu
- The Intel 8088 Architecture and Instruction Set
https://people.ece.ubc.ca/~edc/464/lectures/lec4.pdf - x86 Opcode Structure and Instruction Overview
https://pnx.tf/files/x86_opcode_structure_and_instruction_overview.pdf - x86 instruction listings (Wikipedia)
https://en.wikipedia.org/wiki/X86_instruction_listings - x86 assembly language (Wikipedia)
https://en.wikipedia.org/wiki/X86_assembly_language - Intel Assembler (Cheat sheet)
http://www.jegerlehner.ch/intel/IntelCodeTable.pdf - 25 Microchips That Shook the World
https://spectrum.ieee.org/tech-history/silicon-revolution/25-microchips-that-shook-the-world - Chip Hall of Fame: MOS Technology 6502 Microprocessor
https://spectrum.ieee.org/tech-history/silicon-revolution/chip-hall-of-fame-mos-technology-6502-microprocessor - Chip Hall of Fame: Intel 8088 Microprocessor
https://spectrum.ieee.org/tech-history/silicon-revolution/chip-hall-of-fame-intel-8088-microprocessor - Jak se zrodil procesor?
https://www.root.cz/clanky/jak-se-zrodil-procesor/ - Apple II History Home
http://apple2history.org/ - The 8086/8088 Primer
https://www.stevemorse.org/8086/index.html - flat assembler: Assembly language resources
https://flatassembler.net/ - FASM na Wikipedii
https://en.wikipedia.org/wiki/FASM - Fresh IDE FASM inside
https://fresh.flatassembler.net/ - MS-DOS Version 4.0 Programmer's Reference
https://www.pcjs.org/documents/books/mspl13/msdos/dosref40/ - DOS API (Wikipedia)
https://en.wikipedia.org/wiki/DOS_API - Bit banging
https://en.wikipedia.org/wiki/Bit_banging - IBM Basic assembly language and successors (Wikipedia)
https://en.wikipedia.org/wiki/IBM_Basic_assembly_language_and_successors - X86 Assembly/Bootloaders
https://en.wikibooks.org/wiki/X86_Assembly/Bootloaders - Počátky grafiky na PC: grafické karty CGA a Hercules
https://www.root.cz/clanky/pocatky-grafiky-na-pc-graficke-karty-cga-a-hercules/ - Co mají společného Commodore PET/4000, BBC Micro, Amstrad CPC i grafické karty MDA, CGA a Hercules?
https://www.root.cz/clanky/co-maji-spolecneho-commodore-pet-4000-bbc-micro-amstrad-cpc-i-graficke-karty-mda-cga-a-hercules/ - Karta EGA: první použitelná barevná grafika na PC
https://www.root.cz/clanky/karta-ega-prvni-pouzitelna-barevna-grafika-na-pc/ - RGB Classic Games
https://www.classicdosgames.com/ - Turbo Assembler (Wikipedia)
https://en.wikipedia.org/wiki/Turbo_Assembler - Microsoft Macro Assembler
https://en.wikipedia.org/wiki/Microsoft_Macro_Assembler - IBM Personal Computer (Wikipedia)
https://en.wikipedia.org/wiki/IBM_Personal_Computer - Intel 8251
https://en.wikipedia.org/wiki/Intel_8251 - Intel 8253
https://en.wikipedia.org/wiki/Intel_8253 - Intel 8255
https://en.wikipedia.org/wiki/Intel_8255 - Intel 8257
https://en.wikipedia.org/wiki/Intel_8257 - Intel 8259
https://en.wikipedia.org/wiki/Intel_8259 - Support/peripheral/other chips – 6800 family
http://www.cpu-world.com/Support/6800.html - Motorola 6845
http://en.wikipedia.org/wiki/Motorola_6845 - The 6845 Cathode Ray Tube Controller (CRTC)
http://www.tinyvga.com/6845 - CRTC operation
http://www.6502.org/users/andre/hwinfo/crtc/crtc.html - The 6845 Cathode Ray Tube Controller (CRTC)
http://www.tinyvga.com/6845 - Motorola 6845 and bitwise graphics
https://retrocomputing.stackexchange.com/questions/10996/motorola-6845-and-bitwise-graphics - IBM Monochrome Display Adapter
http://en.wikipedia.org/wiki/Monochrome_Display_Adapter - Color Graphics Adapter
http://en.wikipedia.org/wiki/Color_Graphics_Adapter - Color Graphics Adapter and the Brown color in IBM 5153 Color Display
https://www.aceinnova.com/en/electronics/cga-and-the-brown-color-in-ibm-5153-color-display/ - The Modern Retrocomputer: An Arduino Driven 6845 CRT Controller
https://hackaday.com/2017/05/14/the-modern-retrocomputer-an-arduino-driven-6845-crt-controller/ - flat assembler: Assembly language resources
https://flatassembler.net/ - FASM na Wikipedii
https://en.wikipedia.org/wiki/FASM - Fresh IDE FASM inside
https://fresh.flatassembler.net/ - MS-DOS Version 4.0 Programmer's Reference
https://www.pcjs.org/documents/books/mspl13/msdos/dosref40/ - DOS API (Wikipedia)
https://en.wikipedia.org/wiki/DOS_API - IBM Basic assembly language and successors (Wikipedia)
https://en.wikipedia.org/wiki/IBM_Basic_assembly_language_and_successors - X86 Assembly/Arithmetic
https://en.wikibooks.org/wiki/X86_Assembly/Arithmetic - Art of Assembly – Arithmetic Instructions
http://oopweb.com/Assembly/Documents/ArtOfAssembly/Volume/Chapter6/CH06–2.html - ASM Flags
http://www.cavestory.org/guides/csasm/guide/asm_flags.html - Status Register
https://en.wikipedia.org/wiki/Status_register - Linux assemblers: A comparison of GAS and NASM
http://www.ibm.com/developerworks/library/l-gas-nasm/index.html - Programovani v assembleru na OS Linux
http://www.cs.vsb.cz/grygarek/asm/asmlinux.html - Is it worthwhile to learn x86 assembly language today?
https://www.quora.com/Is-it-worthwhile-to-learn-x86-assembly-language-today?share=1 - Why Learn Assembly Language?
http://www.codeproject.com/Articles/89460/Why-Learn-Assembly-Language - Is Assembly still relevant?
http://programmers.stackexchange.com/questions/95836/is-assembly-still-relevant - Why Learning Assembly Language Is Still a Good Idea
http://www.onlamp.com/pub/a/onlamp/2004/05/06/writegreatcode.html - Assembly language today
http://beust.com/weblog/2004/06/23/assembly-language-today/ - Assembler: Význam assembleru dnes
http://www.builder.cz/rubriky/assembler/vyznam-assembleru-dnes-155960cz - Programming from the Ground Up Book – Summary
http://savannah.nongnu.org/projects/pgubook/ - DOSBox
https://www.dosbox.com/ - The C Programming Language
https://en.wikipedia.org/wiki/The_C_Programming_Language - Hercules Graphics Card (HCG)
https://en.wikipedia.org/wiki/Hercules_Graphics_Card - Complete 8086 instruction set
https://content.ctcd.edu/courses/cosc2325/m22/docs/emu8086ins.pdf - Complete 8086 instruction set
https://yassinebridi.github.io/asm-docs/8086_instruction_set.html - 8088 MPH by Hornet + CRTC + DESiRE (final version)
https://www.youtube.com/watch?v=hNRO7lno_DM - Area 5150 by CRTC & Hornet (Party Version) / IBM PC+CGA Demo, Hardware Capture
https://www.youtube.com/watch?v=fWDxdoRTZPc - 80×86 Integer Instruction Set Timings (8088 – Pentium)
http://aturing.umcs.maine.edu/~meadow/courses/cos335/80×86-Integer-Instruction-Set-Clocks.pdf - Colour Graphics Adapter: Notes
https://www.seasip.info/VintagePC/cga.html - Restoring A Vintage CGA Card With Homebrew HASL
https://hackaday.com/2024/06/12/restoring-a-vintage-cga-card-with-homebrew-hasl/ - Demoing An 8088
https://hackaday.com/2015/04/10/demoing-an-8088/ - Video Memory Layouts
http://www.techhelpmanual.com/89-video_memory_layouts.html - Screen Attributes
http://www.techhelpmanual.com/87-screen_attributes.html - IBM PC Family – BIOS Video Modes
https://www.minuszerodegrees.net/video/bios_video_modes.htm - EGA Functions
https://cosmodoc.org/topics/ega-functions/#the-hierarchy-of-the-ega - Why the EGA can only use 16 of its 64 colours in 200-line modes
https://www.reenigne.org/blog/why-the-ega-can-only-use-16-of-its-64-colours-in-200-line-modes/ - How 16 colors saved PC gaming – the story of EGA graphics
https://www.custompc.com/retro-tech/ega-graphics - List of 16-bit computer color palettes
https://en.wikipedia.org/wiki/List_of16-bit_computer_color_palettes - Why were those colors chosen to be the default palette for 256-color VGA?
https://retrocomputing.stackexchange.com/questions/27994/why-were-those-colors-chosen-to-be-the-default-palette-for-256-color-vga - VGA Color Palettes
https://www.fountainware.com/EXPL/vga_color_palettes.htm - Hardware Level VGA and SVGA Video Programming Information Page
http://www.osdever.net/FreeVGA/vga/vga.htm - Hardware Level VGA and SVGA Video Programming Information Page – sequencer
http://www.osdever.net/FreeVGA/vga/seqreg.htm - VGA Basics
http://www.brackeen.com/vga/basics.html - Introduction to VGA Mode ‚X‘
https://web.archive.org/web/20160414072210/http://fly.srk.fer.hr/GDM/articles/vgamodex/vgamx1.html - VGA Mode-X
https://web.archive.org/web/20070123192523/http://www.gamedev.net/reference/articles/article356.asp - Mode-X: 256-Color VGA Magic
https://downloads.gamedev.net/pdf/gpbb/gpbb47.pdf - Instruction Format in 8086 Microprocessor
https://www.includehelp.com/embedded-system/instruction-format-in-8086-microprocessor.aspx - How to use „AND,“ „OR,“ and „XOR“ modes for VGA Drawing
https://retrocomputing.stackexchange.com/questions/21936/how-to-use-and-or-and-xor-modes-for-vga-drawing - VGA Hardware
https://wiki.osdev.org/VGA_Hardware - Programmer's Guide to Yamaha YMF 262/OPL3 FM Music Synthesizer
https://moddingwiki.shikadi.net/wiki/OPL_chip - Does anybody understand how OPL2 percussion mode works?
https://forum.vcfed.org/index.php?threads/does-anybody-understand-how-opl2-percussion-mode-works.60925/ - Yamaha YMF262 OPL3 music – MoonDriver for OPL3 DEMO [Oscilloscope View]
https://www.youtube.com/watch?v=a7I-QmrkAak - Yamaha OPL vs OPL2 vs OPL3 comparison
https://www.youtube.com/watch?v=5knetge5Gs0 - OPL3 Music Crockett's Theme
https://www.youtube.com/watch?v=HXS008pkgSQ - Bad Apple (Adlib Tracker – OPL3)
https://www.youtube.com/watch?v=2lEPH6Y3Luo - FM Synthesis Chips, Codecs and DACs
https://www.dosdays.co.uk/topics/fm_synthesizers.php - The Zen Challenge – YMF262 OPL3 Original (For an upcoming game)
https://www.youtube.com/watch?v=6JlFIFz1CFY - [adlib tracker II techno music – opl3] orbit around alpha andromedae I
https://www.youtube.com/watch?v=YqxJCu_WFuA - [adlib tracker 2 music – opl3 techno] hybridisation process on procyon-ii
https://www.youtube.com/watch?v=daSV5mN0sJ4 - Hyper Duel – Black Rain (YMF262 OPL3 Cover)
https://www.youtube.com/watch?v=pu_mzRRq8Ho - IBM 5155–5160 Technical Reference
https://www.minuszerodegrees.net/manuals/IBM/IBM_5155_5160_Technical_Reference_6280089_MAR86.pdf - a ymf262/opl3+pc speaker thing i made
https://www.youtube.com/watch?v=E-Mx0lEmnZ0 - [OPL3] Like a Thunder
https://www.youtube.com/watch?v=MHf06AGr8SU - (PC SPEAKER) bad apple
https://www.youtube.com/watch?v=LezmKIIHyUg - Powering devices from PC parallel port
http://www.epanorama.net/circuits/lptpower.html - Magic Mushroom (demo pro PC s DOSem)
http://www.crossfire-designs.de/download/articles/soundcards//mushroom.rar - Píseň Magic Mushroom – originál
http://www.crossfire-designs.de/download/articles/soundcards/speaker_mushroom_converted.mp3 - Píseň Magic Mushroom – hráno na PC Speakeru
http://www.crossfire-designs.de/download/articles/soundcards/speaker_mushroom_speaker.mp3 - Pulse Width Modulation (PWM) Simulation Example
http://decibel.ni.com/content/docs/DOC-4599 - Resistor/Pulse Width Modulation DAC
http://www.k9spud.com/traxmod/pwmdac.php - Class D Amplifier
http://en.wikipedia.org/wiki/Electronic_amplifier#Class_D - Covox Speech Thing / Disney Sound Source (1986)
http://www.crossfire-designs.de/index.php?lang=en&what=articles&name=showarticle.htm&article=soundcards/&page=5 - Covox Digital-Analog Converter (Rusky, obsahuje schémata)
http://phantom.sannata.ru/konkurs/netskater002.shtml - PC-GPE on the Web
http://bespin.org/~qz/pc-gpe/ - Keyboard Synthesizer
http://www.solarnavigator.net/music/instruments/keyboards.htm - FMS – Fully Modular Synthesizer
http://fmsynth.sourceforge.net/ - Javasynth
http://javasynth.sourceforge.net/ - Software Sound Synthesis & Music Composition Packages
http://www.linux-sound.org/swss.html - Mx44.1 Download Page (software synthesizer for linux)
http://hem.passagen.se/ja_linux/ - Software synthesizer
http://en.wikipedia.org/wiki/Software_synthesizer - Frequency modulation synthesis
http://en.wikipedia.org/wiki/Frequency_modulation_synthesis - Yamaha DX7
http://en.wikipedia.org/wiki/Yamaha_DX7 - Wave of the Future
http://www.wired.com/wired/archive/2.03/waveguides_pr.html - Analog synthesizer
http://en.wikipedia.org/wiki/Analog_synthesizer - Minimoog
http://en.wikipedia.org/wiki/Minimoog - Moog synthesizer
http://en.wikipedia.org/wiki/Moog_synthesizer - Tutorial for Frequency Modulation Synthesis
http://www.sfu.ca/~truax/fmtut.html - An Introduction To FM
http://ccrma.stanford.edu/software/snd/snd/fm.html - John Chowning
http://en.wikipedia.org/wiki/John_Chowning - I'm Impressed, Adlib Music is AMAZING!
https://www.youtube.com/watch?v=PJNjQYp1ras - Milinda- Diode Milliampere ( OPL3 )
https://www.youtube.com/watch?v=oNhazT5HG0E - Dune 2 – Roland MT-32 Soundtrack
https://www.youtube.com/watch?v=kQADZeB-z8M - Interrupts
https://wiki.osdev.org/Interrupts#Types_of_Interrupts - Assembly8086SoundBlasterDmaSingleCycleMode
https://github.com/leonardo-ono/Assembly8086SoundBlasterDmaSingleCycleMode/blob/master/sbsc.asm - Interrupts in 8086 microprocessor
https://www.geeksforgeeks.org/interrupts-in-8086-microprocessor/ - Interrupt Structure of 8086
https://www.eeeguide.com/interrupt-structure-of-8086/ - A20 line
https://en.wikipedia.org/wiki/A20_line - Extended memory
https://en.wikipedia.org/wiki/Extended_memory#eXtended_Memory_Specification_(XMS) - Expanded memory
https://en.wikipedia.org/wiki/Expanded_memory - Protected mode
https://en.wikipedia.org/wiki/Protected_mode - Virtual 8086 mode
https://en.wikipedia.org/wiki/Virtual_8086_mode - Unreal mode
https://en.wikipedia.org/wiki/Unreal_mode - DOS memory management
https://en.wikipedia.org/wiki/DOS_memory_management - Upper memory area
https://en.wikipedia.org/wiki/Upper_memory_area - Removing the Mystery from SEGMENT : OFFSET Addressing
https://thestarman.pcministry.com/asm/debug/Segments.html - Segment descriptor
https://en.wikipedia.org/wiki/Segment_descriptor - When using a 32-bit register to address memory in the real mode, contents of the register must never exceed 0000FFFFH. Why?
https://stackoverflow.com/questions/45094696/when-using-a-32-bit-register-to-address-memory-in-the-real-mode-contents-of-the - A Brief History of Unreal Mode
https://www.os2museum.com/wp/a-brief-history-of-unreal-mode/ - Segment Limits
https://wiki.osdev.org/Segment_Limits - How do 32 bit addresses in real mode work?
https://forum.osdev.org/viewtopic.php?t=30642 - The LOADALL Instruction by Robert Collins
https://www.rcollins.org/articles/loadall/tspec_a3_doc.html - How do you put a 286 in Protected Mode?
https://retrocomputing.stackexchange.com/questions/7683/how-do-you-put-a-286-in-protected-mode - Control register
https://en.wikipedia.org/wiki/Control_register - CPU Registers x86
https://wiki.osdev.org/CPU_Registers_x86 - x86 Assembly/Protected Mode
https://en.wikibooks.org/wiki/X86_Assembly/Protected_Mode - MSW: Machine Status Word
https://web.itu.edu.tr/kesgin/mul06/intel/intel_msw.html - 80×87 Floating Point Opcodes
http://www.techhelpmanual.com/876–80×87_floating_point_opcodes.html - Page Translation
https://pdos.csail.mit.edu/6.828/2005/readings/i386/s05_02.htm - 80386 Paging and Segmenation
https://stackoverflow.com/questions/38229741/80386-paging-and-segmenation - 80386 Memory Management
https://tldp.org/LDP/khg/HyperNews/get/memory/80386mm.html - DOSEMU
http://www.dosemu.org/ - Intel 80386, a revolutionary CPU
https://www.xtof.info/intel80386.html - PAI Unit 3 Paging in 80386 Microporcessor
https://www.slideshare.net/KanchanPatil34/pai-unit-3-paging-in-80386-microporcessor - 64 Terabytes of virtual memory for 32-bit x86 using segmentation: how?
https://stackoverflow.com/questions/5444984/64-terabytes-of-virtual-memory-for-32-bit-x86-using-segmentation-how - Pi in the Pentium: reverse-engineering the constants in its floating-point unit
http://www.righto.com/2025/01/pentium-floating-point-ROM.html - Simply FPU
http://www.website.masmforum.com/tutorials/fptute/ - Art of Assembly language programming: The 80×87 Floating Point Coprocessors
https://courses.engr.illinois.edu/ece390/books/artofasm/CH14/CH14–3.html - Art of Assembly language programming: The FPU Instruction Set
https://courses.engr.illinois.edu/ece390/books/artofasm/CH14/CH14–4.html - INTEL 80387 PROGRAMMER'S REFERENCE MANUAL
http://www.ragestorm.net/downloads/387intel.txt - x86 Instruction Set Reference: FLD
http://x86.renejeschke.de/html/file_module_x86_id100.html - x86 Instruction Set Reference: FLD1/FLDL2T/FLDL2E/FLDPI/FLDLG2/FLDLN2/FLDZ
http://x86.renejeschke.de/html/file_module_x86_id101.html - X86 Assembly/Arithmetic
https://en.wikibooks.org/wiki/X86_Assembly/Arithmetic - 8087 Numeric Data Processor
https://www.eeeguide.com/8087-numeric-data-processor/ - Data Types and Instruction Set of 8087 co-processor
https://www.eeeguide.com/data-types-and-instruction-set-of-8087-co-processor/ - 8087 instruction set and examples
https://studylib.net/doc/5625221/8087-instruction-set-and-examples - GCC documentation: Extensions to the C Language Family
https://gcc.gnu.org/onlinedocs/gcc/C-Extensions.html#C-Extensions - GCC documentation: Using Vector Instructions through Built-in Functions
https://gcc.gnu.org/onlinedocs/gcc/Vector-Extensions.html - SSE (Streaming SIMD Extentions)
http://www.songho.ca/misc/sse/sse.html - Timothy A. Chagnon: SSE and SSE2
http://www.cs.drexel.edu/~tc365/mpi-wht/sse.pdf - Intel corporation: Extending the Worldr's Most Popular Processor Architecture
http://download.intel.com/technology/architecture/new-instructions-paper.pdf - SIMD architectures:
http://arstechnica.com/old/content/2000/03/simd.ars/ - Tour of the Black Holes of Computing!: Floating Point
http://www.cs.hmc.edu/~geoff/classes/hmc.cs105…/slides/class02_floats.ppt - 3Dnow! Technology Manual
AMD Inc., 2000 - Intel MMXTM Technology Overview
Intel corporation, 1996 - MultiMedia eXtensions
http://softpixel.com/~cwright/programming/simd/mmx.phpi - AMD K5 („K5“ / „5k86“)
http://www.pcguide.com/ref/cpu/fam/g5K5-c.html - Sixth Generation Processors
http://www.pcguide.com/ref/cpu/fam/g6.htm - Great Microprocessors of the Past and Present
http://www.cpushack.com/CPU/cpu1.html - Very long instruction word (Wikipedia)
http://en.wikipedia.org/wiki/Very_long_instruction_word - CPU design (Wikipedia)
http://en.wikipedia.org/wiki/CPU_design - Bulldozer (microarchitecture)
https://en.wikipedia.org/wiki/Bulldozer_(microarchitecture) - MMX (instruction set)
https://en.wikipedia.org/wiki/MMX_(instruction_set) - Extended MMX
https://en.wikipedia.org/wiki/Extended_MMX























 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU