
Obsah
1. Sledování činnosti systému Apache Kafka přes JMX i metriky Promethea
2. Technologie JMX – Java Management Extension
3. Zobrazení obsahu MBeans nástrojem jconsole
4. Změna stavu atributů MBeans dostupných přes JMX
5. Zobrazení a obnova hodnoty atributu MBeans v nástroji jconsole
6. Změna atributu MBeans přímo z nástroje jconsole
9. JMX Exporter – rozhraní mezi JMX a metrikami Promethea
10. Využití JMX Exporteru v demonstračním příkladu
11. Příprava témat a jejich obsahu pro Apache Kafku
12. Metriky systému Apache Kafka
13. Konfigurace JMX Exporteru pro využití s Kafkou
15. Repositář s demonstračními příklady
16. Odkazy na relevantní články na Rootu
1. Sledování činnosti systému Apache Kafka přes JMX i metriky Promethea
Na několik předchozích článků, v nichž jsme se zabývali různými způsoby použití technologie Apache Kafka (viz odkazy uvedené v devatenácté kapitole), dnes navážeme. Popíšeme si totiž některé možnosti sledování činnosti Kafky, což je velmi důležité, především na produkčních systémech. Samotná Kafka, jakožto aplikace určená pro běh nad virtuálním strojem programovacího jazyka Java, své metriky nabízí přes technologii nazvanou Java Management Extensions neboli JMX. Existuje několik aplikací, které JMX dokážou zpracovat; příkladem je standardní nástroj JConsole dodávaný přímo s JDK (nikoli ovšem s pouhým JRE). Ovšem s využitím pomocného nástroje nazvaného JMX Exporter je možné metriky převést do formátu zpracovatelného například známým nástrojem Prometheus zkombinovaným s Grafanou.
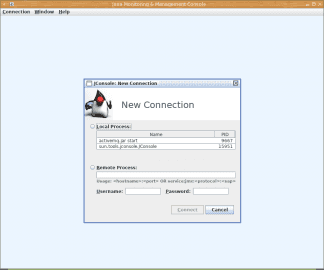
Obrázek 1: Standardním nástrojem pro prohlížení metrik dostupných přes JMX je nástroj jconsole dodávaný společně s JDK.
Vzhledem k tomu, že si nejdříve musíme popsat několik technologií, které se používají současně, bude dnešní článek rozdělen na několik částí. V úvodní části se budeme zabývat samotnou technologií JMX a MBeans z pohledu Javovského programátora. V části druhé se zmíníme o nástroji Prometheus. Následovat bude popis nástroje nazvaného JMX Exporter a konečně ve čtvrté části článku si ukážeme, jaké metriky jsou Apache Kafkou exportovány a v navazujícím článku si řekneme, co vlastně znamenají.

Obrázek 2: Přístup k MBeans (viz další text) message brokera Apache ActiveMQ přes nástroj jconsole.
Obrázek 3: Přístup k MBeans (viz další text) message brokera Apache ActiveMQ přes nástroj jconsole.
2. Technologie JMX – Java Management Extension
Podívejme se nyní na použití technologie JMX (Java Management Extension) v praxi, a to z pohledu programátora. JMX zajišťuje monitorování a popř. i ovládání (řízení) služeb, a to s využitím definovaných zdrojů (resources). V aplikačním kódu jsou tyto zdroje reprezentovány jako objekty nazvané MBean(s) neboli Managed Bean(s), přičemž přístup k atributům MBeans je zajištěn přes gettery a settery (s jejich standardním javovským pojmenováním). Deklarace a použití vlastního MBeans je řešeno přes rozhraní, které se musí jmenovat xxxMBean, tj. jméno tohoto rozhraní musí končit řetězcem „MBean“. Následuje příklad takového rozhraní, v němž jsou deklarovány tři atributy, které jsou určeny jen pro čtení (máme totiž k dispozici jen jejich gettery, nikoli settery):
public interface StatusMBean {
Integer getAnswer();
String getProgramName();
Boolean getSwitchStatus();
}
Následuje implementace tohoto rozhraní běžnou třídou (která ovšem může obsahovat i další atributy a metody):
public class Status implements StatusMBean {
private Integer answer;
private String programName;
private Boolean switchStatus;
public Status(String programName) {
this.answer = 42;
this.programName = programName;
this.switchStatus = false;
}
@Override
public Integer getAnswer() {
return this.answer;
}
@Override
public String getProgramName() {
return this.programName;
}
@Override
public Boolean getSwitchStatus() {
return switchStatus;
}
}
Poslední částí demonstračního příkladu je třída Main představující vstupní bod do aplikace. Po inicializaci JVM se nalezne a spustí metoda main, ve které se MBean zkonstruuje (objekt nazvaný systemStatus) a zaregistruje, takže jeho obsah bude dostupný přes JMX pod ve jmenném prostoru „cz.root.app“pod jménem „StatusExample“:
import java.util.Scanner;
import javax.management.*;
import java.lang.management.ManagementFactory;
public class Main {
public static void main(String[] args) {
try {
String programName = (args.length == 0) ? "foobar" : args[0];
StatusMBean systemStatus = new Status(programName);
MBeanServer platformMBeanServer = ManagementFactory.getPlatformMBeanServer();
ObjectName objectName = new ObjectName("cz.root.app:name=StatusExample");
platformMBeanServer.registerMBean(systemStatus, objectName);
} catch (Exception e) {
e.printStackTrace();
}
new Scanner(System.in).nextLine();
}
}
3. Zobrazení obsahu MBeans nástrojem jconsole
Nyní výše popsaný demonstrační projekt přeložíme a spustíme:
$ javac Main.java $ java Main
V této chvíli aplikace čeká na stisk klávesy, ovšem již v tento okamžik jsou atributy MBeanu „vystaveny“ k přečtení jakýmkoli nástrojem, který s JMX umí pracovat. Vše otestujeme na standardní aplikaci jconsole, kterou byste měli mít nainstalovanou (za předpokladu, že jste byli schopni demonstrační příklad přeložit):
$ export _JAVA_OPTIONS="-Dawt.useSystemAAFontSettings=on -Dswing.aatext=true -Dsun.java2d.xrender=true" $ jconsole

Obrázek 4: Po spuštění jconsole se zobrazí všechny nalezené aplikace běžící nad JVM. Vybereme aplikaci Main.

Obrázek 5: Povolíme (protentokrát) připojení bez SSL.

Obrázek 6: Zobrazí se základní informace o sledované aplikace (obsazení paměti apod.).

Obrázek 7: Na listu MBeans se kromě standardních MBeans objeví i jmenný prostor „cz.root.app“.

Obrázek 8: Po otevření tohoto prostoru se objeví i náš MBean „StatusExample“.

Obrázek 9: A zde jsou všechny tři atributy, které jsme definovali.
4. Změna stavu atributů MBeans dostupných přes JMX
Při pohledu na demonstrační příklad popsaný v předchozích kapitolách by se mohlo zdát, že atributy objektů MBeans jsou neměnné. To však pochopitelně není pravda a ani by to nebylo praktické – vždyť velké množství metrik se v čase mění. Ukažme si proto, jak se kombinace technologií JMX+MBeans s nástrojem jconsole chová ve chvíli, kdy se některý z „vystavených“ atributů bude měnit. Použijeme toto rozhraní (s novým atributem představujícím čítač):
public interface StatusMBean {
Integer getAnswer();
Long getCounter();
String getProgramName();
Boolean getSwitchStatus();
}
Při pohledu na třídu Status je ihned vidět, že se hodnota čítače mění v jeho getteru (což je dosti netypické – většinou je čítač měněn v nezávislém asynchronně běžícím kódu):
public class Status implements StatusMBean {
private Integer answer;
private String programName;
private Boolean switchStatus;
private Long counter;
public Status(String programName) {
this.answer = 42;
this.programName = programName;
this.switchStatus = false;
this.counter = 0L;
}
@Override
public Integer getAnswer() {
return this.answer;
}
@Override
public Long getCounter() {
this.counter++;
return this.counter;
}
@Override
public String getProgramName() {
return this.programName;
}
@Override
public Boolean getSwitchStatus() {
return switchStatus;
}
}
Samotná třída Main je prakticky totožná s její předchozí variantou:
import java.util.Scanner;
import javax.management.*;
import java.lang.management.ManagementFactory;
public class Main {
public static void main(String[] args) {
try {
String programName = (args.length == 0) ? "foobar" : args[0];
StatusMBean systemStatus = new Status(programName);
MBeanServer platformMBeanServer = ManagementFactory.getPlatformMBeanServer();
ObjectName objectName = new ObjectName("cz.root.app:name=StatusExample");
platformMBeanServer.registerMBean(systemStatus, objectName);
} catch (Exception e) {
e.printStackTrace();
}
new Scanner(System.in).nextLine();
}
}
5. Zobrazení a obnova hodnoty atributu MBeans v nástroji jconsole
Chování nově vytvořené metriky nazvané Counter ukazují následující čtyři screenshoty:

Obrázek 10: Hodnota čítače po jejím prvním zobrazení v nástroji jconsole.

Obrázek 11: Tlačítkem Refresh je možné hodnotu znovu načíst a tím pádem i zvýšit (v getteru).

Obrázek 12: Hodnota po opětovném stisku tlačítka Refresh.

Obrázek 13: Dvojitým klikem na atribut (s číselným typem) se zobrazí graf. Ten se pravidelně aktualizuje a tudíž volá getter, který postupně zvyšuje hodnotu čítače.
6. Změna atributu MBeans přímo z nástroje jconsole
Ještě se podívejme na jednu úpravu demonstračního příkladu, který přes JMX „nabízí“ metriky. Tentokrát přidáme přepínač Switch, jehož hodnotu bude možné měnit přímo z nástroje jconsole. Modifikace se týká i rozhraní StatusMBean, do něhož je přidán setter, ale i nová metoda:
public interface StatusMBean {
Integer getAnswer();
Long getCounter();
String getProgramName();
Boolean getSwitchStatus();
void setSwitchStatus(Boolean newStatus);
void flipSwitchStatus();
}
Implementace tohoto rozhraní, i se setterem a metodou pro negaci přepínače:
public class Status implements StatusMBean {
private Integer answer;
private String programName;
private Boolean switchStatus;
private Long counter;
public Status(String programName) {
this.answer = 42;
this.programName = programName;
this.switchStatus = false;
this.counter = 0L;
}
@Override
public Integer getAnswer() {
return this.answer;
}
@Override
public Long getCounter() {
this.counter++;
return this.counter;
}
@Override
public String getProgramName() {
return this.programName;
}
@Override
public Boolean getSwitchStatus() {
return switchStatus;
}
@Override
public void setSwitchStatus(Boolean newStatus) {
this.switchStatus = newStatus;
}
@Override
public void flipSwitchStatus() {
System.out.println("Flip switch status called!");
this.switchStatus = !this.switchStatus;
}
}
Třída Main se opět nijak zásadně nemění:
import java.util.Scanner;
import javax.management.*;
import java.lang.management.ManagementFactory;
public class Main {
public static void main(String[] args) {
try {
String programName = (args.length == 0) ? "foobar" : args[0];
StatusMBean systemStatus = new Status(programName);
MBeanServer platformMBeanServer = ManagementFactory.getPlatformMBeanServer();
ObjectName objectName = new ObjectName("cz.root.app:name=StatusExample");
platformMBeanServer.registerMBean(systemStatus, objectName);
} catch (Exception e) {
e.printStackTrace();
}
new Scanner(System.in).nextLine();
}
}
Chování je opět ukázáno na čtveřici screenshotů:

Obrázek 14: Výchozí hodnota přepínače Switch.

Obrázek 15: Nová operace (metoda) předepsaná v rozhraní je dostupná přímo z jconsole.

Obrázek 16: Zavolání metody vzdáleně, tedy přes JMX.

Obrázek 17: Nová hodnota přepínače Switch
7. Nástroj Prometheus
Po popisu základních vlastností technologie JMX se nyní ve stručnosti zmíníme o nástroji Prometheus (který ovšem přímo s JMX nesouvisí). Prometheus se v současnosti velmi často používá pro sbírání metrik z běžících služeb, mikroslužeb, message brokerů, ale i IoT zařízení atd. Tyto metriky (metrikou může být v tomto případě například počet připojených klientů, aktuálně obsazená kapacita haldy – heapu, informace o tématech, informace o oddílech atd.) je následně možné filtrovat a analyzovat, přičemž výsledky mohou být vizualizovány například nástrojem Grafana (propojení Prometheus + Grafana je ostatně taktéž velmi časté, v mnoha firmách je to nepsaný standard). Jedno z typických použití Promethea je sledování (mikro)služby nasazené například v clusteru. Taková služba kromě své vlastní funkcionality nabízí jednoduché rozhraní REST API (HTTP/HTTPS) s typicky jediným koncovým bodem nazvaným /metrics. Nástroj Prometheus z tohoto koncového bodu metriky načítá a následně je nakonfigurovaným způsobem zpracovává.
Systém Prometheus interně používá databázi, do které se ukládají prakticky libovolné (číselné) hodnoty, které jsou opatřeny časovým razítkem, kromě toho i jménem metriky (ta musí být unikátní) a návěštím (label) umožňujícím podrobnější dělení hodnot, například podle toho, v jakém prostředí je měření prováděno. Doplněna bývá i nápověda, resp. přesněji řečeno popis metriky. To znamená, že pro zvolenou metriku, popř. pro metriku a návěští je možné získat celou časovou posloupnost s hodnotami, vracet se do minulosti, získat informace pro zvolené časové období apod. Samotné hodnoty jsou interně zpracovávány jako datový typ double/float64 (konkrétní jednotka již záleží na intepretaci dat) a časová razítka mají milisekundovou přesnost, což by mělo být pro účely tohoto nástroje dostačující, už jen z toho důvodu, že samotné pořízení záznamu přes API Promethea má určitou časovou složitost.
8. Dotazovací jazyk PromQL
Důležitou součástí Promethea je i PromQL, což je relativně snadno použitelný dotazovací jazyk používaný pro získání potřebných metrik, agregaci výsledků apod. Můžeme si ostatně uvést příklad jednoduchého dotazu vytvořeného v tomto jazyce, který vrátí časovou posloupnost hodnot trvání přípravy odpovědi na HTTP požadavky (předpokládejme, že jméno této metriky je „http_requests_total“). Dotaz vypadá takto:
http_requests_total
Celkovou dobu a průměrnou dobu dotazů získáme stejně snadno:
sum(http_requests_total) avg(http_requests_total)
V dotazu ovšem můžeme provést i jemnější dělení, například podle návěští:
http_requests_total{job="prometheus",group="canary"}
V jazyku PromQL je možné využívat například i regulární výrazy, což nám umožňuje získat časy odpovědí na HTTP dotazy typu GET, ovšem pouze pro zvolená prostředí:
http_requests_total{environment=~"staging|testing|development",method!="GET"}
Dotazovací jazyk PromQL je primárně určen pro práci s časovými řadami, takže nepřekvapí ani dobrá podpora specifikace časového období, pro které potřebujeme data získat. Výsledky trvání vyřízení HTTP dotazů typu GET za posledních pět minut by se získaly takto:
http_requests_total{job="prometheus"}[5m]
Výsledky za posledních třicet minut, ovšem s rozlišením jedné minuty se získají příkazem:
rate(http_requests_total[5m])[30m:1m]
Kromě dotazů zapisovaných v doménově specifickém jazyku PromQL je podporován již zmíněný výstup ve formě plně konfigurovatelných grafů, z nichž se posléze vytváří různé dashboardy, které sledují stav celého systému či jeho jednotlivých částí. Pro tento účel se používá Grafana. Pokud chcete vidět, jak může vypadat výstup z kombinace Prometheus+Grafana, můžete se podívat na obrázek na adrese https://prometheus.io/assets/grafana_prometheus.png.
9. JMX Exporter – rozhraní mezi JMX a metrikami Promethea
„Java is 23 years old, mature, and comes with unbeatable tooling and monitoring capabilities. At the very beginning, Java already incorporated microservice concepts with the Jini / JXTA frameworks mixed with no-SQL databases like e.g. JavaSpaces. As often – Java was just 15 years too early. The market was not ready for the technology back then. However, all the design principles from 1999 still do apply today. We don't have re-invent the wheel.“
Kombinace nástrojů Prometheus+Grafana se v praxi, například v oblasti mikroslužeb, používá velmi často. A do tohoto světa Javovské aplikace se svým JMX příliš nezapadají (i když možnosti JMX jsou ve skutečnosti širší, což jsme si ostatně již naznačili v předchozích kapitolách). Existuje však relativně snadná možnost, jakou se hodnoty nabízené přes JMX převedou na metriky kompatibilní s Prometheem. Tuto možnost nabízí nástroj nazvaný JMX Exporter, který je použit jako takzvaný Java agent, což je kód psaný většinou v Javě, který má přístup k instrumentaci v JVM a dokáže ovlivňovat běh aplikace v JVM. Java agenti se používají pro různé účely, například pro AOP (aspektově orientované programování), profilování, mutation testing (český ekvivalent pro cílenou změnu testovaného kódu pravděpodobně neexistuje) atd.
Konkrétně v případě JMX Exporteru se v rámci agenta spustí HTTP server na zvoleném portu a hodnoty MBeanů dostupné přes JMX mohou být dostupné právě přes tento HTTP server ve formátu kompatibilním s Promeheem.
10. Využití JMX Exporteru v demonstračním příkladu
Nyní si ukážeme, jakým způsobem je možné JMX Exporter použít v jednom z našich demonstračních příkladů. Uvidíme, že je to velmi snadné a přímočaré – a především nejsou vyžadovány žádné změny na straně zdrojového kódu aplikaci ani na straně vygenerovaných class souborů.
Nejprve je nutné stáhnout poslední stabilní verzi JMX Exporteru. Ta je dodávána ve formě Java archivu, tedy souboru s koncovkou .jar. Tento soubor je nutné stáhnout buď přímo do adresáře s projektem, nebo si zde vytvořit symbolický link:
$ wget https://repo1.maven.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/0.15.0/jmx_prometheus_javaagent-0.15.0.jar
Dále přímo v adresáři s demonstračním projektem vytvoříme soubor nazvaný config.yaml. Tento soubor totiž musí existovat, ale může být prázdný (což je i náš případ):
$ touch config.yaml
Nyní již můžeme spustit náš demonstrační příklad, ovšem s tím, že virtuálnímu stroji Javy předáme další parametr -javaagent. Ten bude obsahovat cestu k Java archivu JMX Exporteru a taktéž určení, na kterém portu mají být metriky „vystaveny&ldquoa;. Taktéž se zde specifikuje jméno (prázdného) konfiguračního souboru:
$ java -javaagent:./jmx_prometheus_javaagent-0.15.0.jar=8080:config.yaml Main
V této chvíli by měl demonstrační příklad běžet ve své JVM. V dalším terminálu se pokusíme přečíst jeho metriky. JMX Exporteru jsme určili port 8080, takže by metriky měly být „vystaveny“ na adrese localhost:8080/metrics:
$ curl localhost:8080/metrics
Skutečně je tomu tak:
# HELP jvm_classes_loaded The number of classes that are currently loaded in the JVM
# TYPE jvm_classes_loaded gauge
jvm_classes_loaded 1438.0
# HELP jvm_classes_loaded_total The total number of classes that have been loaded since the JVM has started execution
# TYPE jvm_classes_loaded_total counter
jvm_classes_loaded_total 1438.0
# HELP jvm_classes_unloaded_total The total number of classes that have been unloaded since the JVM has started execution
# TYPE jvm_classes_unloaded_total counter
jvm_classes_unloaded_total 0.0
...
...
...
# TYPE java_lang_MemoryPool_UsageThreshold untyped
java_lang_MemoryPool_UsageThreshold{name="Metaspace",} 0.0
java_lang_MemoryPool_UsageThreshold{name="PS Old Gen",} 0.0
java_lang_MemoryPool_UsageThreshold{name="Code Cache",} 0.0
java_lang_MemoryPool_UsageThreshold{name="Compressed Class Space",} 0.0
...
...
...
# HELP jvm_buffer_pool_capacity_bytes Bytes capacity of a given JVM buffer pool.
# TYPE jvm_buffer_pool_capacity_bytes gauge
jvm_buffer_pool_capacity_bytes{pool="direct",} 89548.0
jvm_buffer_pool_capacity_bytes{pool="mapped",} 0.0
# HELP jvm_buffer_pool_used_buffers Used buffers of a given JVM buffer pool.
# TYPE jvm_buffer_pool_used_buffers gauge
jvm_buffer_pool_used_buffers{pool="direct",} 5.0
jvm_buffer_pool_used_buffers{pool="mapped",} 0.0
...
...
...
Můžeme si vyfiltrovat pouze ty metriky, které jsme sami do projektu přidali (a nikoli metriky dodané vlastním virtuálním strojem Javy):
$ curl localhost:8080/metrics | grep "cz.root.app"
# HELP cz_root_app_StatusExample_Counter Attribute exposed for management (cz.root.app<name=StatusExample><>Counter) # TYPE cz_root_app_StatusExample_Counter untyped cz_root_app_StatusExample_Counter 6.0 # HELP cz_root_app_StatusExample_Answer Attribute exposed for management (cz.root.app<name=StatusExample><>Answer) # TYPE cz_root_app_StatusExample_Answer untyped cz_root_app_StatusExample_Answer 42.0 # HELP cz_root_app_StatusExample_SwitchStatus Attribute exposed for management (cz.root.app<name=StatusExample><>SwitchStatus) # TYPE cz_root_app_StatusExample_SwitchStatus untyped cz_root_app_StatusExample_SwitchStatus 0.0
11. Příprava témat a jejich obsahu pro Apache Kafku
Abychom si mohli JMX odzkoušet v praxi, vytvoříme v Kafce (přes broker) několik témat (topic) a pošleme do nich nějaké zprávy. Podobně jako minule, i dnes pro tento účel použijeme užitečný nástroj kafkacat, který nám umožní simulovat práci producenta i konzumenta zpráv.
Téma se automaticky vytvoří s první poslanou zprávou, čímž se nám situace zjednodušuje. Vytvoříme tedy téma nazvané topic1 a na příkazové řádce zadáme trojici zpráv (jejich těl), které se do tohoto tématu uloží. Zadávání (resp. přesněji řečeno vstup) zpráv se ukončuje standardní klávesovou zkratkou Ctrl+D:
$ kafkacat -P -b localhost:9092 -t topic1 foo bar baz (Ctrl+D)
Totéž, tedy vstup tří zpráv, provedeme i pro téma názvem topic2:
$ kafkacat -P -b localhost:9092 -t topic2 first second third (Ctrl+D)
A do třetice pošleme tři zprávy do tématu s názvem topic3:
$ kafkacat -P -b localhost:9092 -t topic3 jedna dva tri (Ctrl+D)
Nakonec vytvoříme ještě jedno téma pojmenované partitioned, ovšem s tím, že toto téma bude mít tři oddíly. Pro tento účel použijeme skript pojmenovaný kafka-topics.sh, který je dodáván společně s Apache Kafkou (je v podadresáři bin):
$ ./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic partitioned Created topic partitioned.
Do prvního a druhého oddílu pošleme několik zpráv, poslední oddíl zůstane prázdný:
$ kafkacat -P -b localhost:9092 -P -t partitioned -p 0 jedna dva tri (Ctrl+D) $ kafkacat -P -b localhost:9092 -P -t partitioned -p 1 ctyri pet sest (Ctrl+D)
12. Metriky systému Apache Kafka
Apache Kafka, resp. přesněji řečeno její jednotlivé části (ZooKeeper a jednotliví brokeři) vytváří a „vystavují“ poměrně velké množství metrik. Ty je možné rozdělit do čtyř skupin:
- Metriky samotného brokera
- Metriky vztažené k producentům
- Metriky vztažené ke konzumentům
- Metriky ZooKeepera (což je samostatný proces)

Obrázek 18: Jak ZooKeeper, tak i broker běží každý v samostatné JVM.
Jednotlivými skupinami se budeme zabývat v navazujícím (samostatném) článku.

Obrázek 19: Jmenné prostory MBeans brokera.
13. Konfigurace JMX Exporteru pro využití s Kafkou
Posledním krokem je využití JMX Exporteru, jehož základní způsob použití jsme si ukázali v desáté kapitole, společně s Apache Kafkou. Nejdříve přejdeme do adresáře, v němž je uložen rozbalený balíček s Apache Kafkou (což může být například adresář /opt/kafka atd.):
$ cd ${KAFKA_LOCATION}
Tento adresář by měl obsahovat čtveřici podadresářů (popř. doplněnou o podadresář s nápovědou):
bin config libs logs
Již známým způsobem získáme Java archiv s nástrojem JXM Exporter:
$ wget https://repo1.maven.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/0.15.0/jmx_prometheus_javaagent-0.15.0.jar
Adresář s Apache Kafkou tedy bude vypadat takto:
bin config jmx_prometheus_javaagent-0.15.0.jar libs logs
Dále do podadresáře config stáhneme již připravený konfigurační soubor JMX Exporteru určený přímo pro Apache Kafku. Tento soubor je dostupný na adrese https://github.com/prometheus/jmx_exporter/blob/master/example_configs/kafka-2_0_0.yml:
$ wget -O config/kafka-2_0_0.yml https://raw.githubusercontent.com/prometheus/jmx_exporter/master/example_configs/kafka-2_0_0.yml
Do proměnné prostředí KAFKA_OPTS uložíme přepínač JVM, který povoluje JMX agenta a předává mu potřebné konfigurační volby:
export KAFKA_OPTS=' -javaagent:jmx_prometheus_javaagent-0.15.0.jar=9999:./config/kafka-2_0_0.yml'
Spustíme brokera Apache Kafky:
$ bin/kafka-server-start.sh config/server.properties
Nyní by měly být metriky dostupné na portu 9999:
$ curl localhost:9999
Alternativně je možné si připravit skript určený pro spuštění Apache Kafky s nastavením JXM Exporteru jakožto agenta. Přejdeme do podadresáře bin a vytvoříme si kopii skriptu kafka-server-start.sh:
$ pushd bin $ cp kafka-server-start.sh kafka-server-start-prometheus.sh
Obsah podadresáře bin by nyní mohl vypadat následovně:
connect-distributed.sh connect-mirror-maker.sh connect-standalone.sh kafka-acls.sh kafka-broker-api-versions.sh kafka-configs.sh kafka-console-consumer.sh kafka-console-producer.sh kafka-consumer-groups.sh kafka-consumer-perf-test.sh kafka-delegation-tokens.sh kafka-delete-records.sh kafka-dump-log.sh kafka-leader-election.sh kafka-log-dirs.sh kafka-mirror-maker.sh kafka-preferred-replica-election.sh kafka-producer-perf-test.sh kafka-reassign-partitions.sh kafka-replica-verification.sh kafka-run-class.sh kafka-server-start-prometheus.sh kafka-server-start.sh kafka-server-stop.sh kafka-streams-application-reset.sh kafka-topics.sh kafka-verifiable-consumer.sh kafka-verifiable-producer.sh trogdor.sh zookeeper-security-migration.sh zookeeper-server-start.sh zookeeper-server-stop.sh zookeeper-shell.sh
Nový skript kafka-server-start-prometheus.sh upravíme v textovém editoru:
$ vim kafka-server-start-prometheus.sh
Do skriptu přidáme zvýrazněný řádek:
if [ $# -lt 1 ];
then
echo "USAGE: $0 [-daemon] server.properties [--override property=value]*"
exit 1
fi
base_dir=$(dirname $0)
if [ "x$KAFKA_LOG4J_OPTS" = "x" ]; then
export KAFKA_LOG4J_OPTS="-Dlog4j.configuration=file:$base_dir/../config/log4j.properties"
fi
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
EXTRA_ARGS=${EXTRA_ARGS-'-name kafkaServer -loggc'}
COMMAND=$1
case $COMMAND in
-daemon)
EXTRA_ARGS="-daemon "$EXTRA_ARGS
shift
;;
*)
;;
esac
export KAFKA_OPTS=' -javaagent:jmx_prometheus_javaagent-0.15.0.jar=9999:./config/kafka-2_0_0.yml'
exec $base_dir/kafka-run-class.sh $EXTRA_ARGS kafka.Kafka "$@"
Vrátíme se zpět do původního adresáře:
$ popd
A následně brokera Apache Kafky spustíme běžným způsobem:
$ bin/kafka-server-start-prometheus.sh config/server.properties
Metriky nyní budou opět dostupné na portu 9999:

$ curl localhost:9999
lowercaseOutputName: true
rules:
# Special cases and very specific rules
- pattern : kafka.server<type=(.+), name=(.+), clientId=(.+), topic=(.+), partition=(.*)><>Value
name: kafka_server_$1_$2
type: GAUGE
labels:
clientId: "$3"
topic: "$4"
partition: "$5"
- pattern : kafka.server<type=(.+), name=(.+), clientId=(.+), brokerHost=(.+), brokerPort=(.+)><>Value
name: kafka_server_$1_$2
type: GAUGE
labels:
clientId: "$3"
broker: "$4:$5"
- pattern : kafka.coordinator.(\w+)<type=(.+), name=(.+)><>Value
name: kafka_coordinator_$1_$2_$3
type: GAUGE
# Generic per-second counters with 0-2 key/value pairs
- pattern: kafka.(\w+)<type=(.+), name=(.+)PerSec\w*, (.+)=(.+), (.+)=(.+)><>Count
name: kafka_$1_$2_$3_total
type: COUNTER
labels:
"$4": "$5"
"$6": "$7"
- pattern: kafka.(\w+)<type=(.+), name=(.+)PerSec\w*, (.+)=(.+)><>Count
name: kafka_$1_$2_$3_total
type: COUNTER
labels:
"$4": "$5"
- pattern: kafka.(\w+)<type=(.+), name=(.+)PerSec\w*><>Count
name: kafka_$1_$2_$3_total
type: COUNTER
- pattern: kafka.server<type=(.+), client-id=(.+)><>([a-z-]+)
name: kafka_server_quota_$3
type: GAUGE
labels:
resource: "$1"
clientId: "$2"
- pattern: kafka.server<type=(.+), user=(.+), client-id=(.+)><>([a-z-]+)
name: kafka_server_quota_$4
type: GAUGE
labels:
resource: "$1"
user: "$2"
clientId: "$3"
# Generic gauges with 0-2 key/value pairs
- pattern: kafka.(\w+)<type=(.+), name=(.+), (.+)=(.+), (.+)=(.+)><>Value
name: kafka_$1_$2_$3
type: GAUGE
labels:
"$4": "$5"
"$6": "$7"
- pattern: kafka.(\w+)<type=(.+), name=(.+), (.+)=(.+)><>Value
name: kafka_$1_$2_$3
type: GAUGE
labels:
"$4": "$5"
- pattern: kafka.(\w+)<type=(.+), name=(.+)><>Value
name: kafka_$1_$2_$3
type: GAUGE
# Emulate Prometheus 'Summary' metrics for the exported 'Histogram's.
#
# Note that these are missing the '_sum' metric!
- pattern: kafka.(\w+)<type=(.+), name=(.+), (.+)=(.+), (.+)=(.+)><>Count
name: kafka_$1_$2_$3_count
type: COUNTER
labels:
"$4": "$5"
"$6": "$7"
- pattern: kafka.(\w+)<type=(.+), name=(.+), (.+)=(.*), (.+)=(.+)><>(\d+)thPercentile
name: kafka_$1_$2_$3
type: GAUGE
labels:
"$4": "$5"
"$6": "$7"
quantile: "0.$8"
- pattern: kafka.(\w+)<type=(.+), name=(.+), (.+)=(.+)><>Count
name: kafka_$1_$2_$3_count
type: COUNTER
labels:
"$4": "$5"
- pattern: kafka.(\w+)<type=(.+), name=(.+), (.+)=(.*)><>(\d+)thPercentile
name: kafka_$1_$2_$3
type: GAUGE
labels:
"$4": "$5"
quantile: "0.$6"
- pattern: kafka.(\w+)<type=(.+), name=(.+)><>Count
name: kafka_$1_$2_$3_count
type: COUNTER
- pattern: kafka.(\w+)<type=(.+), name=(.+)><>(\d+)thPercentile
name: kafka_$1_$2_$3
type: GAUGE
labels:
quantile: "0.$4"
14. Obsah navazujícího článku
V navazujícím článku si podrobněji popíšeme jednotlivé metriky, které jsou nabízeny jak nástrojem ZooKeeper, tak i samotnými brokery Apache Kafky.
15. Repositář s demonstračními příklady
Zdrojové soubory naprogramované v Javě a použité v dnešním článku byly uloženy do Git repositáře, který je dostupný na adrese https://github.com/tisnik/presentations/. V případě, že nebudete chtít klonovat celý repositář, můžete namísto toho použít odkazy na jednotlivé soubory, které naleznete v následující tabulce:
16. Odkazy na relevantní články na Rootu
- Použití nástroje Apache Kafka v aplikacích založených na mikroslužbách
https://www.root.cz/clanky/pouziti-nastroje-apache-kafka-v-aplikacich-zalozenych-na-mikrosluzbach/ - Apache Kafka: distribuovaná streamovací platforma
https://www.root.cz/clanky/apache-kafka-distribuovana-streamovaci-platforma/ - Pokročilý streaming založený na Apache Kafce, jazyku Clojure a knihovně Jackdaw
https://www.root.cz/clanky/pokrocily-streaming-zalozeny-na-apache-kafce-jazyku-clojure-a-knihovne-jackdaw/ - Pokročilý streaming založený na Apache Kafce, jazyku Clojure a knihovně Jackdaw (2. část)
https://www.root.cz/clanky/pokrocily-streaming-zalozeny-na-apache-kafce-jazyku-clojure-a-knihovne-jackdaw-2-cast/ - Pokročilý streaming založený na projektu Apache Kafka, jazyku Clojure a knihovně Jackdaw (streamy a kolony)
https://www.root.cz/clanky/pokrocily-streaming-zalozeny-na-projektu-apache-kafka-jazyku-clojure-a-knihovne-jackdaw-streamy-a-kolony/ - Vývoj služeb postavených na systému Apache Kafka v jazyku Go
https://www.root.cz/clanky/vyvoj-sluzeb-postavenych-na-systemu-apache-kafka-v-jazyku-go/ - Práce s Kafkou z příkazové řádky: nástroje Kafkacat a Kcli
https://www.root.cz/clanky/prace-s-kafkou-z-prikazove-radky-nastroje-kafkacat-a-kcli/ - Apache ActiveMQ – další systém implementující message brokera
https://www.root.cz/clanky/apache-activemq-dalsi-system-implementujici-message-brokera/#k12
17. Odkazy na Internetu
- The Java™ Tutorials – Introducing MBeans
https://docs.oracle.com/javase/tutorial/jmx/mbeans/index.html - Standard MBeans
https://docs.oracle.com/javase/tutorial/jmx/mbeans/standard.html - JMX Exporter
https://github.com/prometheus/jmx_exporter - Monitor Apache Kafka with Prometheus and Grafana
https://computingforgeeks.com/monitor-apache-kafka-with-prometheus-and-grafana/ - Kafka Monitoring Using Prometheus
https://www.metricfire.com/blog/kafka-monitoring-using-prometheus/ - Collecting Kafka Performance Metrics with OpenTelemetry
https://www.splunk.com/en_us/blog/devops/monitoring-kafka-performance-metrics-with-splunk-infrastructure-monitoring.html - Monitoring Kafka performance metrics
https://www.datadoghq.com/blog/monitoring-kafka-performance-metrics/ - Kcli: is a kafka read only command line browser.
https://github.com/cswank/kcli - Kcli: a kafka command line browser
https://go.libhunt.com/kcli-alternatives - Awesome Go
https://github.com/avelino/awesome-go - Real-Time Payments with Clojure and Apache Kafka (podcast)
https://www.evidentsystems.com/news/confluent-podcast-about-apache-kafka/ - Microservices: The Rise Of Kafka
https://movio.co/blog/microservices-rise-kafka/ - Building a Microservices Ecosystem with Kafka Streams and KSQL
https://www.confluent.io/blog/building-a-microservices-ecosystem-with-kafka-streams-and-ksql/ - An introduction to Apache Kafka and microservices communication
https://medium.com/@ulymarins/an-introduction-to-apache-kafka-and-microservices-communication-bf0a0966d63 - kappa-architecture.com
http://milinda.pathirage.org/kappa-architecture.com/ - Questioning the Lambda Architecture
https://www.oreilly.com/ideas/questioning-the-lambda-architecture - Lambda architecture
https://en.wikipedia.org/wiki/Lambda_architecture - Kafka – ecosystem (Wiki)
https://cwiki.apache.org/confluence/display/KAFKA/Ecosystem - The Kafka Ecosystem – Kafka Core, Kafka Streams, Kafka Connect, Kafka REST Proxy, and the Schema Registry
http://cloudurable.com/blog/kafka-ecosystem/index.html - A Kafka Operator for Kubernetes
https://github.com/krallistic/kafka-operator - Kafka Streams
https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Streams - Kafka Streams
http://kafka.apache.org/documentation/streams/ - Kafka Streams (FAQ)
https://cwiki.apache.org/confluence/display/KAFKA/FAQ#FAQ-Streams - Event stream processing
https://en.wikipedia.org/wiki/Event_stream_processing - Part 1: Apache Kafka for beginners – What is Apache Kafka?
https://www.cloudkarafka.com/blog/2016–11–30-part1-kafka-for-beginners-what-is-apache-kafka.html - What are some alternatives to Apache Kafka?
https://www.quora.com/What-are-some-alternatives-to-Apache-Kafka - What is the best alternative to Kafka?
https://www.slant.co/options/961/alternatives/~kafka-alternatives - A super quick comparison between Kafka and Message Queues
https://hackernoon.com/a-super-quick-comparison-between-kafka-and-message-queues-e69742d855a8?gi=e965191e72d0 - Kafka Queuing: Kafka as a Messaging System
https://dzone.com/articles/kafka-queuing-kafka-as-a-messaging-system - Apache Kafka Logs: A Comprehensive Guide
https://hevodata.com/learn/apache-kafka-logs-a-comprehensive-guide/ - Microservices – Not a free lunch!
http://highscalability.com/blog/2014/4/8/microservices-not-a-free-lunch.html - Microservices, Monoliths, and NoOps
http://blog.arungupta.me/microservices-monoliths-noops/ - Microservice Design Patterns
http://blog.arungupta.me/microservice-design-patterns/ - REST vs Messaging for Microservices – Which One is Best?
https://solace.com/blog/experience-awesomeness-event-driven-microservices/ - Kappa Architecture Our Experience
https://events.static.linuxfound.org/sites/events/files/slides/ASPgems%20-%20Kappa%20Architecture.pdf - Apache Kafka Streams and Tables, the stream-table duality
https://towardsdatascience.com/apache-kafka-streams-and-tables-the-stream-table-duality-ee904251a7e?gi=f22a29cd1854 - Alertmanager
https://prometheus.io/docs/alerting/alertmanager/ - Grafana support for Prometheus
https://prometheus.io/docs/visualization/grafana/ - Prometheus: from metrics to insight
https://prometheus.io/ - Java Management Extensions (JMX)
https://en.wikipedia.org/wiki/Java_Management_Extensions - JConsole
https://en.wikipedia.org/wiki/JConsole - Using JConsole
https://docs.oracle.com/javase/8/docs/technotes/guides/management/jconsole.html - Overview of Java SE Monitoring and Management
https://docs.oracle.com/en/java/javase/15/management/overview-java-se-monitoring-and-management.html


