
Obsah
2. Některá úskalí klasických message brokerů
3. Práce se zprávami (či událostmi) v systému Apache Kafka
4. Témata a oddíly a replikace
6. Spuštění nástroje ZooKeeper a jedné instance brokera
7. Konfigurace většího množství brokerů
9. Instalace nástroje kafkacat
10. Kafkacat v roli producenta i konzumenta zpráv
11. Naprogramování klientů pro Kafku
12. Producent zpráv vytvořený v Pythonu
13. Konzument zpráv naprogramovaný v Pythonu
15. Producent zpráv naprogramovaný v jazyce Go
16. Konzument zpráv vytvořený v Go
17. Alternativa k systému Kafka: nástroj NATS
18. Termíny používané v souvislosti s message brokery
19. Repositář s demonstračními příklady
1. Apache Kafka
V seriálu o message brokerech jsme si již popsali prakticky všechny nejvýznamnější a nejvíce nasazované implementace klasických brokerů založených na frontách zpráv (message queues). Ovšem kromě front zpráv existují i další typy brokerů, kteří podporují takzvaný streaming a s ním spojenou komunikační strategii nazývanou pub-sub, popř. publish-subscribe. Kromě toho je většinou podporováno i „přehrání“ (replay) starších zpráv, což je operace, kterou klasické message brokery založené na frontách, většinou nepodporují (už jen z toho důvodu, že zpráva je po potvrzení producentem z fronty odstraněna, popř. přesunuta do fronty jiné). Jedním z nejznámějších brokerů podporujících streaming je Apache Kafka. S tímto nástrojem jsme se nepřímo setkali v seriálu o mikroslužbách, ovšem prozatím jsme si neukázali, jakým způsobem je možné Kafku zprovoznit na vývojovém stroji a jak lze naprogramovat jednoduché producenty a konzumenty zpráv.

Obrázek 1: Komunikační strategie PUSH-PULL používaná klasickými message brokery se hodí například pro implementaci takzvaných workerů, kteří se dělí o zadávané úkoly a mohou být rozděleni podle toho, ke které frontě se připojují, popř. jaký „topic“ zpracovávají. Ovšem ve chvíli, kdy je nutné mít možnost si jednou zaznamenané zprávy (resp. události) „přehrát“, je vhodnější použít jiný princip zpracování podporovaný právě systémem Apache Kafka.
Díky konceptům, na nichž je projekt Kafka založen, je možné tento systém použít v několika oblastech, například ve funkci distribuovaného logu, databáze událostí (events), zobecněného message brokera, je ústředním prvkem architektur lambda a kappa, příjemci zpráv se mohou sdružovat do skupin atd. Ovšem i další vlastnosti, které projekt Kafka nabízí, jsou velmi užitečné. Jedná se především o možnost nasazení celého clusteru brokerů řízených z jednoho místa, možnost replikace záznamů (zpráv, událostí), řízení, které zprávy mají být zachovány a které (ty starší) smazány apod. Existují ale samozřejmě i alternativy k tomuto projektu, například již popsaný NATS Streaming Server [1] [2]. Zavrhnout nelze ani možnost použít Kafku jako klasického message brokera s frontami zpráv, to ovšem vyžaduje použití většího množství topiců (jeden topic se používá pro ukládání informací o zpracovaných zprávách) a navíc je nutné použít i specializovaného klienta (konzumenta + producenta).

Obrázek 2: Logo nástroje Apache Kafka, kterému se budeme dnes věnovat.
2. Některá úskalí klasických message brokerů
Klasické implementace message brokerů založených na komunikačních strategiích PUSH-PULL a popř. i na původním konceptu PUBLISH-SUBSCRIBE mají určitá omezení. Většina těchto úskalí je do větší či menší míry řešena moderními streaming brokery, mezi něž patří (na prvním místě) právě Apache Kafka:
- U strategie PUBLISH-SUBSCRIBE získají zprávu pouze ti konzumenti, kteří jsou v daný okamžik přihlášeni k příjmu zpráv. Pokud je nějaký konzument z nějakého důvodu odpojený, zprávu již nikdy později nedostane (protože ji message broker nemá uloženou). V případě streamingu si čtení zpráv od zadaného okamžiku řídí samotný konzument zpráv, pochopitelně s tím omezením, že se starší (většinou mnohem starší) zprávy mohou automaticky odstraňovat na základě kritérií nastavených administrátorem (někdy to ovšem znamená, že si konzument musí pamatovat například offset poslední zpracované zprávy – zde již konkrétní chování závisí na možnostech brokera).
- U strategie PUSH-PULL je jednou doručená zpráva z message brokera (přesněji řečeno z fronty implementované v message brokeru) odstraněna a nelze se k ní později vrátit. Tím pádem pochopitelně není umožněna ani podpora pro přehrávání zpráv (replay). I toto je do značné míry vyřešeno v případě nasazení streamingu; vše je omezeno nastavením provedeném administrátorem (a teoreticky existuje pouze jedno omezení na 263-1 zpráv v jedné oblasti, což je však hodnota, které v reálném nasazení prakticky nelze dosáhnout).
- Původní strategie PUSH-PULL navíc předpokládá, že se zpráva doručí jen jedinému konzumentovi. Někteří message brokeři ovšem podporují i rozšíření funkcionality a implementují tak kombinaci obou strategií, jak PUBLISH-SUBSCRIBE, tak i PUSH-PULL (dobrým příkladem může být populární message broker RabbitMQ). Streaming servery používají zobecněnou strategii PUBLISH-SUBSCRIBE, takže toto omezení nemají, pochopitelně při správném nastavení témat a jejich replikací.
- U strategie PUSH-PULL se v případě výchozího chování nijak nespecifikuje maximální počet zpráv ve frontě, popř. maximální povolené obsazení místa na disku. V případě, že konzumenti budou delší dobu odpojeni, se může jednat o potenciální problém (opět platí, že u některých message brokerů se můžeme setkat s určitou podporu pro mazání starších zpráv při dosažení administrátorem specifikovaných limitů). Řešení v případě streaming serverů bylo zmíněno výše a ke konkrétním příkladům se vrátíme v dalším textu.
- Problematický může být i relativně nízký výkon přeposílání zpráv systémemPUSH-PULL (přibližně do limitu 100 000 zpráv za sekundu při použití RabbitMQ v clusteru, zatímco systémy založené na Kafce mohou mít i řádově vyšší rychlost práce se zprávami).
3. Práce se zprávami (či událostmi) v systému Apache Kafka
V systému Apache Kafka se se zprávami (které se zde ale typicky nazývají spíše záznamy, record, popř. možná poněkud nepřesně události neboli events) pracuje poněkud odlišným způsobem, který do jisté míry kombinuje jak možnosti klasické fronty zpráv, tak i rozesílání zpráv systémem PUBLISH-SUBSCRIBE. Zprávy se ovšem neukládají do běžné fronty, ale (v tom zcela nejjednodušším případě) do neustále rostoucí sekvence záznamů, přičemž každému záznamu je přiřazeno jednoznačné číslo – offset. Z pohledu zdroje zpráv (publisher) vlastně nedochází k žádné podstatnější změně. Rozdílné je ovšem další zpracování záznamů. Tyto záznamy mohou číst příjemci zpráv (subscribeři), kteří si sami zvolí, od jakého offsetu potřebují zprávy přečíst. Offset lze kromě celočíselného údaje zadat i jinak: „číst od začátku“, „číst od poslední zpracované zprávy“ apod.
Přečtením ovšem zpráva nezanikne, na rozdíl od klasické fronty, kde operace PULL zprávu z fronty navždy odstraní a message broker ji ihned poté odstraní i ze své paměti a perzistentního úložiště. A je zde i rozdíl oproti systému PUBLISH-SUBSCRIBE, protože v systému Apache Kafka může subscriber zprávu získat kdykoli později – nemusí být tedy připraven zprávu zpracovat v ten přesný okamžik, kdy je zpráva message brokerem rozesílána.
To však není jediná změna či vylepšení. Vzhledem k tomu, že příjemci zpráv (subscribeři) si sami volí offset, od kterého chtějí zprávy číst, je možné provádět takzvanou operaci replay, což ve skutečnosti není nic jiného, než nové zpracování zpráv od jejich začátku, od určitého (třeba i relativně zadaného) časového okamžiku atd. Tato vlastnost má dosti závažné důsledky pro mnohé oblasti, v nichž se systém Apache Kafka nasazuje. Umožňuje totiž postupné přidávání nových příjemců zpráv, kteří ihned mohou začít zpracovávat i historické záznamy. Ostatně to je i jeden z důvodů, proč je Apache Kafka tak populární v oblasti strojového učení (machine learning – ML), protože umožňuje prakticky dokonalé oddělení systémů sloužících pro sběr dat od modulů, které tato data nějakým způsobem dále zpracovávají.
+---+---+---+---+---+---+---+---+---+
téma | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ...
+---+---+---+---+---+---+---+---+---+
^ ^
| zápis
čtení
Aby bylo možné nějakým způsobem konfigurovat a řídit, které zprávy mají být na message brokeru uloženy a které již smazány, specifikuje se takzvaný retention time zajišťující, aby počet zpráv/záznamů nepřekročil časovou mez. Streaming server dokáže omezit i celkový počet zpráv, počet zpráv v tématu a/nebo počet zpráv na jednom serveru v clusteru. Totéž omezení je možné aplikovat na celkovou velikost použitého paměťového či diskového prostoru – vše podle požadavků, které jsou na celý systém kladeny.
4. Témata a oddíly a replikace
Systém Apache Kafka umožňuje ukládání zpráv (zde se ovšem, jak již víme, používá termín záznam – record) do různých témat, přičemž každé téma je rozděleno do oddílů neboli partition (samozřejmě je možné pro téma vyhradit pouze jediný oddíl a tvářit se, že máme k dispozici „vylepšenou“ frontu – ostatně přesně takto lze s Kafkou začít). Rozdělení do oddílů se provádí z několika důvodů. Jedním z nich je rozdělení zátěže, protože jednotlivé oddíly mohou být provozovány na různých počítačích v mnohdy i velmi rozsáhlém clusteru.
Dále se dělení provádí z toho důvodu, že každý oddíl obsahuje neměnnou (immutable) sekvenci zpráv. Oddíly pro jednotlivá témata lze zpracovávat v několika brokerech umístěných do clusteru a tak zajistit potřebný load balancing, případnou replikaci zpráv atd. Každá zpráva uložená do oddílu má přiřazen jednoznačný offset (reprezentovaný v Javě typem long). Navíc je možné, aby se pro každé téma udržovalo několik logů (partition logs), což umožňuje připojení většího množství konzumentů zpráv k jednomu tématu s tím, že tito konzumenti budou pracovat paralelně a nezávisle na sobě.
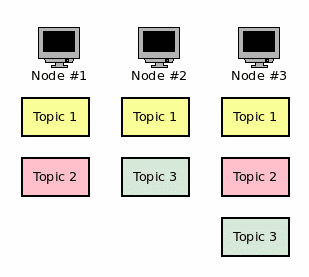
Obrázek 3: Příklad rozdělení témat v clusteru.
U většiny nasazení Kafky se taktéž počítá s využitím většího množství instancí brokerů, z nichž je vytvořen cluster. Zde se setkáme s důležitým termínem replikace – každý oddíl je typicky replikován na několika message brokerech v clusteru (ovšem nemusí se jednat o všechny brokery, replikace se provádí například na tři brokery ve větším clusteru).
To však není vše, jelikož je ve skutečnosti konfigurace poněkud složitější – každý oddíl totiž může být replikován na více počítačích, přičemž jeden z těchto oddílů je takzvaným „leaderem“ a ostatní jsou „followeři“. Zápis nových zpráv, popř. čtení se provádí vždy jen v rámci leaderu, ovšem změny jsou replikovány na všechny kopie oddílu. Ve chvíli, kdy z nějakého (libovolného) důvodu dojde k pádu „leadera“, převezme jeho roli jeden z dalších uzlů. Pokud tedy existuje N uzlů s replikou oddílu, bude systém funkční i ve chvíli, kdy zhavaruje N-1 uzlů!
Téma zpracovávané Kafkou může na clusteru vypadat například následovně:
+---+---+---+---+---+---+
oddíl #0 | 0 | 1 | 2 | 3 | 4 | 5 | ...
+---+---+---+---+---+---+
oddíl #1 | 0 | 1 | 2 | ...
+---+---+---+
oddíl #2 | ...
+---+---+---+---+---+---+---+---+---+
oddíl #3 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ...
+---+---+---+---+---+---+---+---+---+
Boxy s čísly odpovídají jednotlivým zprávám, kterým jsou tato pořadová čísla v sekvenci postupně přiřazována. Zápis nových zpráv je prováděn do oblastí označených třemi tečkami. Z tohoto diagramu můžeme odvodit, že každý oddíl obsahuje vlastní sekvenci zpráv/záznamů, ke kterým se postupně připojují záznamy další.
5. Instalace Kafky
V případě, že je na počítači nainstalováno JRE, je instalace Kafky pro testovací účely triviální. Tarball s instalací Kafky lze získat z adresy https://www.apache.org/dyn/closer.cgi?path=/kafka/2.4.0/kafka2.12–2.4.0.tgz. Stažení a rozbalení tarballu:
$ wget http://apache.miloslavbrada.cz/kafka/2.4.0/kafka_2.12-2.4.0.tgz $ tar -xzf kafka_2.12-2.4.0.tgz $ cd kafka_2.12-2.4.0
Po rozbalení získáme adresář, v němž se nachází všechny potřebné Java archivy (JAR), konfigurační soubory (v podadresáři config) a několik pomocných skriptů (v podadresáři bin). Pro spuštění Zookeepera a brokerů je zapotřebí mít nainstalovánu JRE (Java Runtime Environment) a samozřejmě též nějaký shell (BASH, cmd, …).
Prozatím nebudeme žádné další nastavení ani žádné další nástroje potřebovat, ovšem v navazujícím článku se zmíníme o některých užitečných utilitách určených pro administraci a sledování (monitorování) Kafky.

Obrázek 4: Sledování činnosti brokeru přes standardní nástroj JConsole.
6. Spuštění nástroje ZooKeeper a jedné instance brokera
Po (doufejme že úspěšné) instalaci Kafky již můžeme spustit ZooKeeper a jednu instanci brokera (a to přesně v tomto pořadí!). Konfigurace ZooKeepera je uložena v souboru config/zookeeper.properties a zajímat nás budou především tyto volby – adresář, kam ZooKeeper ukládá svoje data, port, který použijí brokeři a omezení počtu připojení jednoho klienta v daný okamžik:
dataDir=/tmp/zookeeper clientPort=2181 maxClientCnxns=0
Nyní již můžeme Zookeepera spustit:
$ bin/zookeeper-server-start.sh config/zookeeper.properties [2020-01-20 17:00:07,823] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig) [2020-01-20 17:00:07,825] WARN config/zookeeper.properties is relative. Prepend ./ to indicate that you're sure! (org.apache.zookeeper.server.quorum.QuorumPeerConfig) [2020-01-20 17:00:07,827] INFO clientPortAddress is 0.0.0.0/0.0.0.0:2181 (org.apache.zookeeper.server.quorum.QuorumPeerConfig) ... ... ... [2020-01-20 17:00:07,947] INFO Using checkIntervalMs=60000 maxPerMinute=10000 (org.apache.zookeeper.server.ContainerManager) [2020-01-20 17:00:26,978] INFO Creating new log file: log.1 (org.apache.zookeeper.server.persistence.FileTxnLog)
Konfigurace jednoho brokera je uložená v souboru config/server.properties. Samotný konfigurační soubor obsahuje několik sekcí:
- Port, na kterém broker naslouchá, jeho ID, počet použitých vláken pro IO operace a počet vláken pro komunikaci.
- Velikost bufferů, maximální povolená velikost požadavků (což omezuje velikost zprávy) atd.
- Nastavení počtu partitions
- Nastavení retence dat
- Připojení k Zookeeperovi
broker.id=0 listeners=PLAINTEXT://:9092 num.network.threads=3 num.io.threads=8 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 log.dirs=/tmp/kafka-logs num.partitions=1 num.recovery.threads.per.data.dir=1 log.retention.hours=168 log.segment.bytes=1073741824 zookeeper.connect=localhost:2181 zookeeper.connection.timeout.ms=6000
Spuštění jednoho brokera vypadá jednoduše:
$ bin/kafka-server-start.sh config/server.properties
Alternativně je možné Zookeepera i Kafku (jednu instanci brokera) spustit v Dockeru:
$ docker run -p 2181:2181 -p 9092:9092 --env ADVERTISED_HOST=`docker-machine ip \`docker-machine active\`` --env ADVERTISED_PORT=9092 spotify/kafka
7. Konfigurace většího množství brokerů
Spuštění většího množství brokerů je možné (a běžné). Postačuje pouze zkopírovat soubor config/server.properties do několika podobných souborů (config/server0.properties, config/server1.properties atd.) Dále je nutné provést následující úpravy v konfiguračním souboru:
- broker.id musí být jednoznačná hodnota, takže postačuje ID postupně zvyšovat: 0, 1, 2, atd.
- listeners musí obsahovat unikátní číslo portu, takže například 9092, 9192, 9292 atd.
- log.dirs by taktéž mělo ukazovat na unikátní adresář nesdílený s ostatními instancemi brokera
Po splnění těchto podmínek je možné brokery běžným způsobem spustit:
$ nohup bin/kafka-server-start.sh config/server1.properties & $ nohup bin/kafka-server-start.sh config/server2.properties & $ nohup bin/kafka-server-start.sh config/server3.properties & ... ... ...
Obrázek 5: Sledování činnosti brokeru přes standardní nástroj JConsole.
8. Užitečný nástroj kafkacat
Součástí ekosystému vytvořeného okolo Apache Kafky je i užitečný nástroj nazvaný kafkacat (autoři ho taktéž označují jako „netcat for Kafka“, v kontextu REST API by se hodilo i „curl for Kafka“). Tento nástroj, který naleznete na adrese https://github.com/edenhill/kafkacat slouží pro komunikaci s brokery přímo z příkazové řádky. Pochopitelně se s velkou pravděpodobností nebude jednat o řešení používané v produkčním kódu, ovšem možnost vytvořit producenta zpráv či jejich konzumenta přímo z CLI je použitelná jak při vývoji, tak i při řešení problémů, které mohou při běhu aplikace nastat. Tento nástroj budeme používat později, při ukázkách nasazení Apache Kafky, takže se v této kapitole krátce zmiňme o příkladech použití převzatých z oficiální dokumentace. Všechny ukázky předpokládají, že broker běží na lokálním počítači na portu 9092.
Výpis informací o všech tématech a jejich konfigurace:
$ kafkacat -L -b localhost:9092
Spuštění nového producenta zpráv čtených ze souborů specifikovaných na příkazové řádce:
$ kafkacat -P -b localhost:9092 -t filedrop -p 0 file1.bin file2.txt /etc/motd dalsi_soubor.tgz
Přečtení posledních 1000 zpráv z tématu „téma1“. Po této operaci se konzument automaticky ukončí, tj. nebude čekat na další zprávy:
$ kafkacat -C -b localhost:9092 -t tema1 -p 0 -o -1000 -e
Spuštění konzumentů, kteří jsou přihlášení k tématu „téma1“:
$ kafkacat -b localhost:9092 -G skupina_konzumentů téma1
Přihlásit se lze i k odběru většího množství témat:
$ kafkacat -b localhost:9092 -G skupina_konzumentů téma1 téma2
9. Instalace nástroje kafkacat
Nástroj kafkacat se skládá z několika komponent, které jsou většinou naprogramovány v jazyku C, popř. v C++. Překlad a slinkování lze provést takovým způsobem, že výsledkem bude jediný spustitelný soubor nazvaný též „kafkacat“, který bude obsahovat i všechny potřebné (tedy staticky slinkované) knihovny, což zjednodušuje nasazení této utility. Na druhou stranu však nebude možné použít běžné prostředky operačního systému při updatu knihoven, například při opravách CVE atd.
Napřed se provede naklonování repositáře:
$ git clone git@github.com:edenhill/kafkacat.git
po přesunu do naklonovaného repositáře:
$ cd kafkacat
se překlad provede běžnou trojkombinací configure+make+make install:
$ ./configure $ make $ sudo make install
Alternativně je ovšem možné použít připravený skript bootstrap.sh, který zajistí stažení všech potřebných knihoven (crypto atd.) s jejich překladem:
$ ./bootstrap.sh
Výsledkem je potom skutečně „tlustý“ binární soubor:
$ ls -l ~/bin/kafkacat -rwxrwxr-x. 1 ptisnovs ptisnovs 20987784 17. led 14.34 /home/ptisnovs/bin/kafkacat
Některé linuxové distribuce obsahují přímo ve svých repositářích balíček kafkacat, což samozřejmě celý proces instalace (a případných updatů) značně zjednodušuje. Například na systémech založených na Debianu postačuje použít:
$ apt-get install kafkacat
$ kafkacat Error: -b <broker,..> missing Usage: kafkacat [file1 file2 .. | topic1 topic2 ..]] kafkacat - Apache Kafka producer and consumer tool https://github.com/edenhill/kafkacat Copyright (c) 2014-2019, Magnus Edenhill Version 1.5.0-4-ge461fb (JSON, Avro, librdkafka 1.1.0 builtin.features=gzip,snappy,ssl,sasl,regex,lz4,sasl_plain,sasl_scram,plugins,zstd,sasl_oauthbearer) ... ... ...
10. Kafkacat v roli producenta i konzumenta zpráv
Nástroj kafkacat je možné použít společně s producenty a konzumenty, s nimiž se setkáme v navazujících kapitolách. Ve všech demonstračních příkladech budeme používat téma (topic) nazvaný „upload“.
Konzument zpráv posílaných do tématu „upload“:
$ kafkacat -C -b localhost:9092 -t "upload"
Producent zpráv zapisovaných na standardní vstup uživatelem (co zpráva, to jeden řádek):
$ kafkacat -P -b localhost:9092 -t "upload"
Dtto, ale u každé zprávy lze specifikovat i klíč oddělený od těla zprávy dvojtečkou:
$ kafkacat -P -b localhost:9092 -t "upload" -K:
11. Naprogramování klientů pro Kafku
Vzhledem k popularitě Kafky pravděpodobně nebude velkým překvapením, že okolo ní vznikl celý rozsáhlý ekosystém. Jedná se především o následující komponenty:
- Knihovnu Kafka Streams používanou při programování klientů pro Kafku v Javě a dalších jazycích postavených nad JVM.
- Knihovny umožňující připojení ke Kafce z mnoha programovacích jazyků.
- Konektory pro další služby, produkující proud dat.
- Konektory pro další služby, které naopak proudy dat konzumují.
- Konektory pro různé databáze sloužící pro vstup dat (relační databáze s JDBC driverem, Cassandra, Couchbase atd. atd.)
- Konektory pro databáze pro uložení dat (Amazon S3, Hadoop, …)
- Rozhraní pro systémy pro zpracování logů.
- Již připravení konzumenti zpráv.
- Již připravení producenti zpráv – systémy pro poskytování metrik atd. (viz též další text).
- Klient ovládaný z příkazové řádky (kafkacat), který byl již zmíněn v předchozích kapitolách.
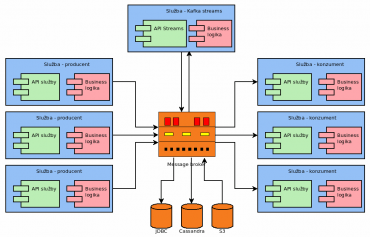
Obrázek 6: Příklad použití ekosystému Kafky (Kafka Streams, konektory pro databáze atd.).
Samotný systém Apache Kafka je naprogramován v Javě, takže jeho primární platformou je pochopitelně JVM (Java Virtual Machine). To však pochopitelně neznamená, že se Kafka nedá použít i z dalších programovacích jazyků. Ve skutečnosti existují rozhraní pro prakticky všechny používané a/nebo populární (což není v IT vždy totéž) programovací jazyky. Tato rozhraní jsou vypsána v následující tabulce:
| # | Jazyk/platforma |
|---|---|
| 1 | C/C++ |
| 2 | Python |
| 3 | Go/Golang Go/Golang |
| 4 | Erlang |
| 5 | .NET |
| 6 | Ruby |
| 7 | Node.js |
| 8 | Perl |
| 9 | PHP |
| 10 | Rust |
| 11 | Storm |
| 12 | Scala (DSL jazyk) |
| 13 | Clojure |
| 14 | Clojure |
| 15 | Swift |
| 16 | CLI (stdin/stdout) |
V navazujících kapitolách si ukážeme, jakým způsobem lze vytvořit producenta i konzumenta zpráv v programovacích jazycích Go a Python (typicky se Go používá na straně producenta zpráv, zatímco Python doplněný například o ML a AI knihovny na straně konzumenta).

Obrázek 7: Schéma aplikace založené na architektuře kappa, ke které se ještě vrátíme v dalších částech tohoto seriálu.
12. Producent zpráv vytvořený v Pythonu
Před vytvořením producenta zpráv v Pythonu je nutné nainstalovat knihovnu, která zabezpečuje připojení ke Kafce. Tuto knihovnu můžeme nainstalovat pouze pro aktivního uživatele (což je nejjednodušší a nevyžaduje to rootovská práva) s využitím příkazu pip, protože tato knihovna je pochopitelně dostupná na PyPi:
$ pip3 install --user kafka
Collecting kafka
Downloading https://files.pythonhosted.org/packages/21/71/73286e748ac5045b6a669c2fe44b03ac4c5d3d2af9291c4c6fc76438a9a9/kafka-1.3.5-py2.py3-none-any.whl (207kB)
100% |████████████████████████████████| 215kB 1.8MB/s
Installing collected packages: kafka
Successfully installed kafka-1.3.5
Producent je představován instancí třídy KafkaProducer. Konstruktoru této třídy se předává pouze seznam brokerů (v našem případě jediný broker) a popř. i další nepovinné údaje. Mezi ně patří i handler, který je zavolán před serializací každé zprávy. V tomto příkladu budou všechny zprávy ukládány do JSONu (může se tedy jednat o libovolnou datovou strukturu):
producer = KafkaProducer(bootstrap_servers=[server],
value_serializer=lambda x: dumps(x).encode('utf-8'))
Poslání zprávy se provádí metodou KafkaProducer.send. Zpráva je, jak již víme z předchozího textu, uložena do zvoleného tématu (topic) a skládá se z těla, popř. klíče a těla:
producer.send(topic, value=data)
V našem příkladu budou posílaná data ve formátu JSON a budou obsahovat klíč „counter“ a k němu přiřazenou hodnotu, která se postupně zvyšuje od 0 až do 1000:
for i in range(1000):
data = {'counter': i}
producer.send(topic, value=data)
sleep(5)
Celý zdrojový kód tohoto příkladu naleznete na adrese https://github.com/tisnik/message-queues-examples/blob/master/kafka/producer1.py:
#!/usr/bin/env python3
from kafka import KafkaProducer
from time import sleep
from json import dumps
server = 'localhost:9092'
topic = 'upload'
print('Connecting to Kafka')
producer = KafkaProducer(bootstrap_servers=[server],
value_serializer=lambda x: dumps(x).encode('utf-8'))
print('Connected to Kafka')
for i in range(1000):
data = {'counter': i}
producer.send(topic, value=data)
sleep(5)
13. Konzument zpráv naprogramovaný v Pythonu
Implementace jednoduchého konzumenta zpráv v programovacím jazyku Python je poměrně snadná a příliš se neliší od implementace konzumenta. Nejdříve je nutné vytvořit instanci třídy KafkaConsumer, přičemž se specifikuje téma (topic), skupina, seznam brokerů a nepovinně též informace o tom, jakým způsobem se má nastavit offset první zpracované zprávy. Většinou budeme potřebovat zpracovávat nejnovější zprávy:
consumer = KafkaConsumer(topic,
group_id=group_id,
bootstrap_servers=[server],
auto_offset_reset='earliest')
Dále se zprávy zpracovávají velmi intuitivním způsobem – v programové smyčce typu for-each:
for message in consumer:
print("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition, message.offset, message.key, message.value))
Úplný zdrojový kód konzumenta vypadá následovně:
#!/usr/bin/env python3
import sys
from kafka import KafkaConsumer
server = 'localhost:9092'
topic = 'upload'
group_id = 'group1'
print('Connecting to Kafka')
consumer = KafkaConsumer(topic,
group_id=group_id,
bootstrap_servers=[server],
auto_offset_reset='earliest')
print('Connected to Kafka')
try:
for message in consumer:
print("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition, message.offset, message.key, message.value))
except KeyboardInterrupt:
sys.exit()
14. Přehrání (replay) zpráv
V případě, že je zapotřebí přehrát (replay) již jednou zpracované zprávy (danou skupinou), lze použít metodu KafkaConsumer.seek, které se předá informace o tématu a offset. Pokud zprávy začínají nulovým offsetem, lze použít:
tp = TopicPartition(topic=topic, partition=0) consumer.assign([tp]) consumer.seek(tp, 0)
Lepší je však použít metodu seek_to_beginning(), která bude funkční i v případě, že první zpráva nemá offset nastavený na nulu.
Upravený konzument, který začne zpracovávat zprávy od začátku, vypadá následovně:
#!/usr/bin/env python3
import sys
from kafka import KafkaConsumer, TopicPartition
server = 'localhost:9092'
topic = 'upload'
group_id = 'group1'
print('Connecting to Kafka')
consumer = KafkaConsumer(group_id=group_id,
bootstrap_servers=[server])
print('Connected to Kafka')
tp = TopicPartition(topic=topic, partition=0)
consumer.assign([tp])
consumer.seek(tp, 0)
try:
for message in consumer:
print("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition, message.offset, message.key, message.value))
except KeyboardInterrupt:
sys.exit()
15. Producent zpráv naprogramovaný v jazyce Go
Nyní si ukažme, jak lze vytvořit producenta zpráv v programovacím jazyce Go. Nejprve je (opět) nutné nainstalovat knihovnu, která zajistí aplikacím přístup do Kafky. Tato knihovna je sice naprogramovaná v Go, ovšem vyžaduje i nativní knihovnu librdkafka, kterou lze nainstalovat buď z repositářů dané distribuce, nebo běžným postupem:
$ git clone https://github.com/edenhill/librdkafka.git $ cd librdkafka $ ./configure --prefix /usr $ make $ sudo make install
Dále je ještě před instalací knihovny pro Go většinou nutné nastavit PKG_CONFIG_PATH:
$ export PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/lib/pkgconfig/
Stažení a překlad knihovny pro Go je posléze již triviální:
$ go get -u gopkg.in/confluentinc/confluent-kafka-go.v1/kafka
Nyní se podívejme na samotnou implementaci producenta zpráv. Budeme potřebovat znát stejné údaje, jako tomu bylo u producenta pro Python:
const (
server = "localhost"
)
topic := "upload"
Vytvoření instance datové struktury představující producenta se zajištěním jeho destrukce na konci příslušné funkce se příliš neliší od podobného kódu, který jsme viděli v případě Pythonu:
producer, err := kafka.NewProducer(&kafka.ConfigMap{
"bootstrap.servers": server,
})
defer producer.Close()
Samotné vytváření zpráv s jejich naformátováním (do řetězce), převodem na pole bajtů a posíláním do Kafky vypadá následovně:
for i := 0; i < 100; i++ {
text := fmt.Sprintf("Message #%d", i)
producer.Produce(&kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny},
Value: []byte(text),
}, nil)
}
Vidíme, že je zapotřebí specifikovat téma (topic) a popř. i sekci (partition). Samotná zpráva je reprezentována polem bajtů, může se tedy jednat o libovolná data.
Navíc je ovšem někdy vhodné asynchronně reagovat na události, které mohou při práci s Kafkou nastat. Asynchronní zpracování je v Go přímočaré – použijeme k tomu gorutinu a budeme reagovat na případné chyby a informace o doručení zprávy:
go func() {
for event := range producer.Events() {
switch ev := event.(type) {
case *kafka.Message:
if ev.TopicPartition.Error != nil {
fmt.Printf("Delivery failed: %v\n", ev.TopicPartition)
} else {
fmt.Printf("Delivered message to %v\n", ev.TopicPartition)
}
}
}
}()
Úplný zdrojový kód producenta naleznete na adrese https://github.com/tisnik/message-queues-examples/blob/master/kafka/producer1.go:
package main
import (
"fmt"
"gopkg.in/confluentinc/confluent-kafka-go.v1/kafka"
)
const (
server = "localhost"
)
func main() {
topic := "upload"
producer, err := kafka.NewProducer(&kafka.ConfigMap{
"bootstrap.servers": server,
})
defer producer.Close()
if err != nil {
panic(err)
}
go func() {
for event := range producer.Events() {
switch ev := event.(type) {
case *kafka.Message:
if ev.TopicPartition.Error != nil {
fmt.Printf("Delivery failed: %v\n", ev.TopicPartition)
} else {
fmt.Printf("Delivered message to %v\n", ev.TopicPartition)
}
}
}
}()
for i := 0; i < 100; i++ {
text := fmt.Sprintf("Message #%d", i)
producer.Produce(&kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny},
Value: []byte(text),
}, nil)
}
producer.Flush(15 * 1000)
}
Překlad producenta lze provést buď s tím, že při spuštění bude vyžadována dynamicky linkovaná knihovna librdkafka:
$ go build producer1.go
$ ldd ./producer1
linux-vdso.so.1 (0x00007ffc70b8e000)
librdkafka.so.1 => not found
libpthread.so.0 => /lib64/libpthread.so.0 (0x00007ffb2b6f8000)
libc.so.6 => /lib64/libc.so.6 (0x00007ffb2b342000)
/lib64/ld-linux-x86-64.so.2 (0x00007ffb2b916000)
Alternativně lze vynutit statické slinkování, což je v tomto případě podle mého názoru lepší řešení (není zapotřebí nastavovat LD_LIBRARY_PATH atd.):
$ go build -tags static producer1.go
$ ldd ./producer1
linux-vdso.so.1 (0x00007ffdd3156000)
libm.so.6 => /lib64/libm.so.6 (0x00007f424359c000)
libz.so.1 => /lib64/libz.so.1 (0x00007f4243385000)
libdl.so.2 => /lib64/libdl.so.2 (0x00007f4243181000)
libpthread.so.0 => /lib64/libpthread.so.0 (0x00007f4242f63000)
librt.so.1 => /lib64/librt.so.1 (0x00007f4242d5b000)
libc.so.6 => /lib64/libc.so.6 (0x00007f42429a5000)
/lib64/ld-linux-x86-64.so.2 (0x00007f42438e7000)
16. Konzument zpráv vytvořený v Go
Konzument zpráv naprogramovaný v jazyce Go je založen na použití struktury Consumer:
consumer, err := kafka.NewConsumer(&kafka.ConfigMap{
"bootstrap.servers": server,
"group.id": group_id,
"auto.offset.reset": "earliest",
})
defer consumer.Close()
což je sémanticky prakticky totožný kód, který známe z Pythonu:
consumer = KafkaConsumer(topic,
group_id=group_id,
bootstrap_servers=[server],
auto_offset_reset='earliest')
Dále se přihlásíme k příjmu zpráv se zadaným tématem:
consumer.SubscribeTopics([]string{topic}, nil)
Příjem zpráv (s případným čekáním na nové zprávy) je řešen v nekonečné smyčce:
for {
message, err := consumer.ReadMessage(-1)
if err == nil {
fmt.Printf("Message on %s: %s %s\n", message.TopicPartition, string(message.Key), string(message.Value))
} else {
fmt.Printf("Consumer error: %v (%v)\n", err, message)
}
}
Úplný zdrojový kód konzumenta naleznete na adrese https://github.com/tisnik/message-queues-examples/blob/master/kafka/consumer1.go:
package main
import (
"fmt"
"gopkg.in/confluentinc/confluent-kafka-go.v1/kafka"
)
const (
server = "localhost:9092"
topic = "upload"
group_id = "group1"
)
func main() {
consumer, err := kafka.NewConsumer(&kafka.ConfigMap{
"bootstrap.servers": server,
"group.id": group_id,
"auto.offset.reset": "earliest",
})
defer consumer.Close()
if err != nil {
panic(err)
}
consumer.SubscribeTopics([]string{topic}, nil)
for {
message, err := consumer.ReadMessage(-1)
if err == nil {
fmt.Printf("Message on %s: %s %s\n", message.TopicPartition, string(message.Key), string(message.Value))
} else {
fmt.Printf("Consumer error: %v (%v)\n", err, message)
}
}
}
17. Alternativa k systému Kafka: nástroj NATS
V článku Komunikace s message brokery z programovacího jazyka Go, který je taktéž součástí seriálu o message brokerech, jsme se ve stručnosti seznámili s projektem NATS. Připomeňme si, že se jedná o poměrně úspěšný a často nasazovaný projekt, jenž je vyvinut v programovacím jazyku Go, což mu do jisté míry zajišťuje stabilitu i škálovatelnost. To jsou vlastnosti, které u message brokerů většinou očekáváme.
Také jsme si řekli, že se systém NATS skládá z několika komponent:

- V první řadě se jedná o samotný server, jenž se spouští příkazem gnatsd. Server je naprogramovaný v Go a při jeho vývoji bylo dbáno na to, aby byla zaručena vysoká dostupnost celé služby a přitom byla samotná služba s běžícím serverem málo náročná na systémové zdroje, především na spotřebu operační paměti (to má v době Dockeru a podobných nástrojů poměrně velký význam).
- Dalším typem komponenty jsou programátorská rozhraní pro klienty, která v současnosti existují pro několik ekosystémů (což je většinou kombinace programovacího jazyka, knihoven a popř. jeho virtuálního stroje); viz též tabulky s podporovanými ekosystémy, které jsou zobrazeny pod tímto seznamem.
- Třetí komponentou je NATS Streaming Server, který je opět naprogramován v jazyce Go. Způsobem využití Streaming Serveru a vůbec teorií, na které streamování stojí, se budeme věnovat v dalším článku.
- Čtvrtým typem komponenty je takzvaný NATS Connector Framework zajišťující propojení systému NATS s dalšími technologiemi (XMPP, logování, notifikační služby aj.). Ten je naprogramovaný v Javě a v současnosti je podporován například konektor pro Redis.
18. Termíny používané v souvislosti s message brokery
V této kapitole jsou zmíněny významy některých termínů, s nimiž se v souvislosti s message brokery a se streamingem často setkáme. České překlady jsou ovšem pouze přibližné, protože oficiální terminologie pravděpodobně ještě neexistuje:
| # | Původní termín | Přibližný český překlad | Stručný popis významu termínu |
|---|---|---|---|
| 1 | message | zpráva | ucelená informace či data posílaná mezi producentem a konzumentem přes message brokera, popř. větší množství message brokerů |
| 2 | record | záznam | alternativní pojmenování pro zprávu, používané především v některých streamovacích message brokerech, například v Apache Kafka |
| 3 | producer | producent | aplikace/proces, která vytváří zprávy a posílá je do message brokera |
| 4 | consumer | konzument | aplikace/proces, která zprávy z message brokera přijímá |
| 5 | consumer group | skupina konzumentů | skupina konzumentů přijímajících zprávy z jednoho společného tématu; používáno například v dnes popisovaném systému Apache Kafka |
| 6 | topic | téma | kategorie či značka, pod kterou je zpráva v brokeru uložena a publikována; používá se pro směrování a/nebo pro ukládání zpráv |
| 7 | subject | téma | alternativní označení pro topic; použito pouze v některých message brokerech |
| 8 | topic partition | rozdělení tématu na oddíly, které mohou být rozmístěny na různé brokery v clusteru (opět najdeme i v Kafce) | |
| 9 | replica | replika/duplikát | záložní kopie oddílu, typicky uložená na jiném brokeru |
| 10 | offset | ofset | unikátní identifikátor platný v rámci oddílu (popř. tématu), který umožňuje konzumentům specifikovat, kterou zprávu mají zpracovávat |
19. Repositář s demonstračními příklady
Zdrojové kódy všech dnes popsaných demonstračních příkladů vyvinutých v programovacím jazyku Python a Go byly uloženy do Git repositáře, který je dostupný na adrese https://github.com/tisnik/message-queues-examples (stále na GitHubu :-). V případě, že nebudete chtít klonovat celý repositář (ten je ovšem – alespoň prozatím – velmi malý, dnes má stále ještě doslova několik kilobajtů), můžete namísto toho použít odkazy na jednotlivé příklady, které naleznete v následující tabulce:
| # | Zdrojový kód | Stručný popis | Cesta |
|---|---|---|---|
| 1 | producer1.py | producent pro Kafku naprogramovaný v Pythonu | https://github.com/tisnik/message-queues-examples/blob/master/kafka/producer1.py |
| 2 | consumer1.py | konzument pro Kafku naprogramovaný v Pythonu | https://github.com/tisnik/message-queues-examples/blob/master/kafka/consumer1.py |
| 3 | consumer2.py | konzument pro Kafku s přehráním zpráv | https://github.com/tisnik/message-queues-examples/blob/master/kafka/consumer2.py |
| 4 | producer1.go | producent pro Kafku naprogramovaný v jazyce Go | https://github.com/tisnik/message-queues-examples/blob/master/kafka/producer1.go |
| 5 | consumer1.go | konzument pro Kafku naprogramovaný v jazyce Go | https://github.com/tisnik/message-queues-examples/blob/master/kafka/consumer1.go |
20. Odkazy na Internetu
- Microservices: The Rise Of Kafka
https://movio.co/blog/microservices-rise-kafka/ - Building a Microservices Ecosystem with Kafka Streams and KSQL
https://www.confluent.io/blog/building-a-microservices-ecosystem-with-kafka-streams-and-ksql/ - An introduction to Apache Kafka and microservices communication
https://medium.com/@ulymarins/an-introduction-to-apache-kafka-and-microservices-communication-bf0a0966d63 - kappa-architecture.com
http://milinda.pathirage.org/kappa-architecture.com/ - Questioning the Lambda Architecture
https://www.oreilly.com/ideas/questioning-the-lambda-architecture - Lambda architecture
https://en.wikipedia.org/wiki/Lambda_architecture - Kafka – ecosystem (Wiki)
https://cwiki.apache.org/confluence/display/KAFKA/Ecosystem - The Kafka Ecosystem – Kafka Core, Kafka Streams, Kafka Connect, Kafka REST Proxy, and the Schema Registry
http://cloudurable.com/blog/kafka-ecosystem/index.html - A Kafka Operator for Kubernetes
https://github.com/krallistic/kafka-operator - Kafka Streams
https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Streams - Kafka Streams
http://kafka.apache.org/documentation/streams/ - Kafka Streams (FAQ)
https://cwiki.apache.org/confluence/display/KAFKA/FAQ#FAQ-Streams - Event stream processing
https://en.wikipedia.org/wiki/Event_stream_processing - Part 1: Apache Kafka for beginners – What is Apache Kafka?
https://www.cloudkarafka.com/blog/2016–11–30-part1-kafka-for-beginners-what-is-apache-kafka.html - What are some alternatives to Apache Kafka?
https://www.quora.com/What-are-some-alternatives-to-Apache-Kafka - What is the best alternative to Kafka?
https://www.slant.co/options/961/alternatives/~kafka-alternatives - A super quick comparison between Kafka and Message Queues
https://hackernoon.com/a-super-quick-comparison-between-kafka-and-message-queues-e69742d855a8?gi=e965191e72d0 - Kafka Queuing: Kafka as a Messaging System
https://dzone.com/articles/kafka-queuing-kafka-as-a-messaging-system - POSIX message queues in Linux
https://www.softprayog.in/programming/interprocess-communication-using-posix-message-queues-in-linux - How is a message queue implemented in the Linux kernel?
https://unix.stackexchange.com/questions/6930/how-is-a-message-queue-implemented-in-the-linux-kernel/6935 - ‘IPCS’ command in Linux with examples
https://www.geeksforgeeks.org/ipcs-command-linux-examples/ - System V IPC: Message Queues
https://nitish712.blogspot.com/2012/11/system-v-ipc-message-queues.html - How to create, check and delete IPC share memory, semaphare and message queue on linux
https://fibrevillage.com/sysadmin/225-how-to-create-check-and-delete-ipc-share-memory-semaphare-and-message-queue-on-linux - MQ_OVERVIEW(7): Linux Programmer's Manual
http://man7.org/linux/man-pages/man7/mq_overview.7.html - mq_overview (7) – Linux Man Pages
https://www.systutorials.com/docs/linux/man/7-mq_overview/ - POSIX.4 Message Queues (+ rozšíření QNX)
https://users.pja.edu.pl/~jms/qnx/help/watcom/clibref/mq_overview.html - System V message queues in Linux
https://www.softprayog.in/programming/interprocess-communication-using-system-v-message-queues-in-linux - Linux System V and POSIX IPC Examples
http://hildstrom.com/projects/ipc_sysv_posix/index.html - Programming Tutorial – Linux: Message Queues
https://ccppcoding.blogspot.com/2013/03/linux-message-queues.html - Go wrapper for POSIX Message Queues
https://github.com/syucream/posix_mq - Stránka projektu NSQ
https://nsq.io/ - Dokumentace k projektu NSQ
https://nsq.io/overview/design.html - Dokumentace ke klientovi pro Go
https://godoc.org/github.com/nsqio/go-nsq - Dokumentace ke klientovi pro Python
https://pynsq.readthedocs.io/en/latest/ - Binární tarbally s NSQ
https://nsq.io/deployment/installing.html - GitHub repositář projektu NSQ
https://github.com/nsqio/nsq - Klienti pro NSQ
https://nsq.io/clients/client_libraries.html - Klient pro Go
https://github.com/nsqio/go-nsq - Klient pro Python
https://github.com/nsqio/pynsq - An Example of Using NSQ From Go
http://tleyden.github.io/blog/2014/11/12/an-example-of-using-nsq-from-go/ - Go Go Gadget
https://word.bitly.com/post/29550171827/go-go-gadget - Simplehttp
https://github.com/bitly/simplehttp - Dramatiq: simple task processing
https://dramatiq.io/ - Cookbook (for Dramatiq)
https://dramatiq.io/cookbook.html - Balíček dramatiq na PyPi
https://pypi.org/project/dramatiq/ - Dramatiq dashboard
https://github.com/Bogdanp/dramatiq_dashboard - Dramatiq na Redditu
https://www.reddit.com/r/dramatiq/ - A Dramatiq broker that can be used with Amazon SQS
https://github.com/Bogdanp/dramatiq_sqs - nanomsg na GitHubu
https://github.com/nanomsg/nanomsg - Referenční příručka knihovny nanomsg
https://nanomsg.org/v1.1.5/nanomsg.html - nng (nanomsg-next-generation)
https://github.com/nanomsg/nng - Differences between nanomsg and ZeroMQ
https://nanomsg.org/documentation-zeromq.html - NATS
https://nats.io/about/ - NATS Streaming Concepts
https://nats.io/documentation/streaming/nats-streaming-intro/ - NATS Streaming Server
https://nats.io/download/nats-io/nats-streaming-server/ - NATS Introduction
https://nats.io/documentation/ - NATS Client Protocol
https://nats.io/documentation/internals/nats-protocol/ - NATS Messaging (Wikipedia)
https://en.wikipedia.org/wiki/NATS_Messaging - Stránka Apache Software Foundation
http://www.apache.org/ - Informace o portu 5672
http://www.tcp-udp-ports.com/port-5672.htm - Třída MessagingHandler knihovny Qpid Proton
https://qpid.apache.org/releases/qpid-proton-0.27.0/proton/python/api/proton._handlers.MessagingHandler-class.html - Třída Event knihovny Qpid Proton
https://qpid.apache.org/releases/qpid-proton-0.27.0/proton/python/api/proton._events.Event-class.html - package stomp (Go)
https://godoc.org/github.com/go-stomp/stomp - Go language library for STOMP protocol
https://github.com/go-stomp/stomp - python-qpid-proton 0.26.0 na PyPi
https://pypi.org/project/python-qpid-proton/ - Qpid Proton
http://qpid.apache.org/proton/ - Using the AMQ Python Client
https://access.redhat.com/documentation/en-us/red_hat_amq/7.1/html-single/using_the_amq_python_client/ - Apache ActiveMQ
http://activemq.apache.org/ - Apache ActiveMQ Artemis
https://activemq.apache.org/artemis/ - Apache ActiveMQ Artemis User Manual
https://activemq.apache.org/artemis/docs/latest/index.html - KahaDB
http://activemq.apache.org/kahadb.html - Understanding the KahaDB Message Store
https://access.redhat.com/documentation/en-US/Fuse_MQ_Enterprise/7.1/html/Configuring_Broker_Persistence/files/KahaDBOverview.html - Command Line Tools (Apache ActiveMQ)
https://activemq.apache.org/activemq-command-line-tools-reference.html - stomp.py 4.1.21 na PyPi
https://pypi.org/project/stomp.py/ - Stomp Tutorial
https://access.redhat.com/documentation/en-US/Fuse_Message_Broker/5.5/html/Connectivity_Guide/files/FMBConnectivityStompTelnet.html - Heartbeat (computing)
https://en.wikipedia.org/wiki/Heartbeat_(computing) - Apache Camel
https://camel.apache.org/ - Red Hat Fuse
https://developers.redhat.com/products/fuse/overview/ - Confusion between ActiveMQ and ActiveMQ-Artemis?
https://serverfault.com/questions/873533/confusion-between-activemq-and-activemq-artemis - Staré stránky projektu HornetQ
http://hornetq.jboss.org/ - Snapshot JeroMQ verze 0.4.4
https://oss.sonatype.org/content/repositories/snapshots/org/zeromq/jeromq/0.4.4-SNAPSHOT/ - Difference between ActiveMQ vs Apache ActiveMQ Artemis
http://activemq.2283324.n4.nabble.com/Difference-between-ActiveMQ-vs-Apache-ActiveMQ-Artemis-td4703828.html - Microservices communications. Why you should switch to message queues
https://dev.to/matteojoliveau/microservices-communications-why-you-should-switch-to-message-queues–48ia - Stomp.py 4.1.19 documentation
https://stomppy.readthedocs.io/en/stable/ - Repositář knihovny JeroMQ
https://github.com/zeromq/jeromq/ - ØMQ – Distributed Messaging
http://zeromq.org/ - ØMQ Community
http://zeromq.org/community - Get The Software
http://zeromq.org/intro:get-the-software - PyZMQ Documentation
https://pyzmq.readthedocs.io/en/latest/ - Module: zmq.decorators
https://pyzmq.readthedocs.io/en/latest/api/zmq.decorators.html - ZeroMQ is the answer, by Ian Barber
https://vimeo.com/20605470 - ZeroMQ RFC
https://rfc.zeromq.org/ - ZeroMQ and Clojure, a brief introduction
https://antoniogarrote.wordpress.com/2010/09/08/zeromq-and-clojure-a-brief-introduction/ - zeromq/czmq
https://github.com/zeromq/czmq - golang wrapper for CZMQ
https://github.com/zeromq/goczmq - ZeroMQ version reporting in Python
http://zguide.zeromq.org/py:version - A Go interface to ZeroMQ version 4
https://github.com/pebbe/zmq4 - Broker vs. Brokerless
http://zeromq.org/whitepapers:brokerless - Learning ØMQ with pyzmq
https://learning-0mq-with-pyzmq.readthedocs.io/en/latest/ - Céčková funkce zmq_ctx_new
http://api.zeromq.org/4–2:zmq-ctx-new - Céčková funkce zmq_ctx_destroy
http://api.zeromq.org/4–2:zmq-ctx-destroy - Céčková funkce zmq_bind
http://api.zeromq.org/4–2:zmq-bind - Céčková funkce zmq_unbind
http://api.zeromq.org/4–2:zmq-unbind - Céčková C funkce zmq_connect
http://api.zeromq.org/4–2:zmq-connect - Céčková C funkce zmq_disconnect
http://api.zeromq.org/4–2:zmq-disconnect - Céčková C funkce zmq_send
http://api.zeromq.org/4–2:zmq-send - Céčková C funkce zmq_recv
http://api.zeromq.org/4–2:zmq-recv - Třída Context (Python)
https://pyzmq.readthedocs.io/en/latest/api/zmq.html#context - Třída Socket (Python)
https://pyzmq.readthedocs.io/en/latest/api/zmq.html#socket - Python binding
http://zeromq.org/bindings:python - Why should I have written ZeroMQ in C, not C++ (part I)
http://250bpm.com/blog:4 - Why should I have written ZeroMQ in C, not C++ (part II)
http://250bpm.com/blog:8 - About Nanomsg
https://nanomsg.org/ - Advanced Message Queuing Protocol
https://www.amqp.org/ - Advanced Message Queuing Protocol na Wikipedii
https://en.wikipedia.org/wiki/Advanced_Message_Queuing_Protocol - Dokumentace k příkazu rabbitmqctl
https://www.rabbitmq.com/rabbitmqctl.8.html - RabbitMQ
https://www.rabbitmq.com/ - RabbitMQ Tutorials
https://www.rabbitmq.com/getstarted.html - RabbitMQ: Clients and Developer Tools
https://www.rabbitmq.com/devtools.html - RabbitMQ na Wikipedii
https://en.wikipedia.org/wiki/RabbitMQ - Streaming Text Oriented Messaging Protocol
https://en.wikipedia.org/wiki/Streaming_Text_Oriented_Messaging_Protocol - Message Queuing Telemetry Transport
https://en.wikipedia.org/wiki/MQTT - Erlang
http://www.erlang.org/ - pika 0.12.0 na PyPi
https://pypi.org/project/pika/ - Introduction to Pika
https://pika.readthedocs.io/en/stable/ - Langohr: An idiomatic Clojure client for RabbitMQ that embraces the AMQP 0.9.1 model
http://clojurerabbitmq.info/ - AMQP 0–9–1 Model Explained
http://www.rabbitmq.com/tutorials/amqp-concepts.html - Part 1: RabbitMQ for beginners – What is RabbitMQ?
https://www.cloudamqp.com/blog/2015–05–18-part1-rabbitmq-for-beginners-what-is-rabbitmq.html - Downloading and Installing RabbitMQ
https://www.rabbitmq.com/download.html - celery na PyPi
https://pypi.org/project/celery/ - Databáze Redis (nejenom) pro vývojáře používající Python
https://www.root.cz/clanky/databaze-redis-nejenom-pro-vyvojare-pouzivajici-python/ - Databáze Redis (nejenom) pro vývojáře používající Python (dokončení)
https://www.root.cz/clanky/databaze-redis-nejenom-pro-vyvojare-pouzivajici-python-dokonceni/ - Redis Queue (RQ)
https://www.fullstackpython.com/redis-queue-rq.html - Python Celery & RabbitMQ Tutorial
https://tests4geeks.com/python-celery-rabbitmq-tutorial/ - Flower: Real-time Celery web-monitor
http://docs.celeryproject.org/en/latest/userguide/monitoring.html#flower-real-time-celery-web-monitor - Asynchronous Tasks With Django and Celery
https://realpython.com/asynchronous-tasks-with-django-and-celery/ - First Steps with Celery
http://docs.celeryproject.org/en/latest/getting-started/first-steps-with-celery.html - node-celery
https://github.com/mher/node-celery - Full Stack Python: web development
https://www.fullstackpython.com/web-development.html - Introducing RQ
https://nvie.com/posts/introducing-rq/ - Asynchronous Tasks with Flask and Redis Queue
https://testdriven.io/asynchronous-tasks-with-flask-and-redis-queue - rq-dashboard
https://github.com/eoranged/rq-dashboard - Stránky projektu Redis
https://redis.io/ - Introduction to Redis
https://redis.io/topics/introduction - Try Redis
http://try.redis.io/ - Redis tutorial, April 2010 (starší, ale pěkně udělaný)
https://static.simonwillison.net/static/2010/redis-tutorial/ - Python Redis
https://redislabs.com/lp/python-redis/ - Redis: key-value databáze v paměti i na disku
https://www.zdrojak.cz/clanky/redis-key-value-databaze-v-pameti-i-na-disku/ - Praktický úvod do Redis (1): vaše distribuovaná NoSQL cache
http://www.cloudsvet.cz/?p=253 - Praktický úvod do Redis (2): transakce
http://www.cloudsvet.cz/?p=256 - Praktický úvod do Redis (3): cluster
http://www.cloudsvet.cz/?p=258 - Connection pool
https://en.wikipedia.org/wiki/Connection_pool - Instant Redis Sentinel Setup
https://github.com/ServiceStack/redis-config - How to install REDIS in LInux
https://linuxtechlab.com/how-install-redis-server-linux/ - Redis RDB Dump File Format
https://github.com/sripathikrishnan/redis-rdb-tools/wiki/Redis-RDB-Dump-File-Format - Lempel–Ziv–Welch
https://en.wikipedia.org/wiki/Lempel%E2%80%93Ziv%E2%80%93Welch - Redis Persistence
https://redis.io/topics/persistence - Redis persistence demystified
http://oldblog.antirez.com/post/redis-persistence-demystified.html - Redis reliable queues with Lua scripting
http://oldblog.antirez.com/post/250 - Ost (knihovna)
https://github.com/soveran/ost - NoSQL
https://en.wikipedia.org/wiki/NoSQL - Shard (database architecture)
https://en.wikipedia.org/wiki/Shard_%28database_architecture%29 - What is sharding and why is it important?
https://stackoverflow.com/questions/992988/what-is-sharding-and-why-is-it-important - What Is Sharding?
https://btcmanager.com/what-sharding/ - Redis clients
https://redis.io/clients - Category:Lua-scriptable software
https://en.wikipedia.org/wiki/Category:Lua-scriptable_software - Seriál Programovací jazyk Lua
https://www.root.cz/serialy/programovaci-jazyk-lua/ - Redis memory usage
http://nosql.mypopescu.com/post/1010844204/redis-memory-usage - Ukázka konfigurace Redisu pro lokální testování
https://github.com/tisnik/presentations/blob/master/redis/redis.conf - Resque
https://github.com/resque/resque - Nested transaction
https://en.wikipedia.org/wiki/Nested_transaction - Publish–subscribe pattern
https://en.wikipedia.org/wiki/Publish%E2%80%93subscribe_pattern - Messaging pattern
https://en.wikipedia.org/wiki/Messaging_pattern - Using pipelining to speedup Redis queries
https://redis.io/topics/pipelining - Pub/Sub
https://redis.io/topics/pubsub - ZeroMQ distributed messaging
http://zeromq.org/ - ZeroMQ: Modern & Fast Networking Stack
https://www.igvita.com/2010/09/03/zeromq-modern-fast-networking-stack/ - Publish/Subscribe paradigm: Why must message classes not know about their subscribers?
https://stackoverflow.com/questions/2908872/publish-subscribe-paradigm-why-must-message-classes-not-know-about-their-subscr - Python & Redis PUB/SUB
https://medium.com/@johngrant/python-redis-pub-sub-6e26b483b3f7 - Message broker
https://en.wikipedia.org/wiki/Message_broker - RESP Arrays
https://redis.io/topics/protocol#array-reply - Redis Protocol specification
https://redis.io/topics/protocol - Redis Pub/Sub: Intro Guide
https://www.redisgreen.net/blog/pubsub-intro/ - Redis Pub/Sub: Howto Guide
https://www.redisgreen.net/blog/pubsub-howto/ - Comparing Publish-Subscribe Messaging and Message Queuing
https://dzone.com/articles/comparing-publish-subscribe-messaging-and-message - Apache Kafka
https://kafka.apache.org/ - Iron
http://www.iron.io/mq - kue (založeno na Redisu, určeno pro node.js)
https://github.com/Automattic/kue - Cloud Pub/Sub
https://cloud.google.com/pubsub/ - Introduction to Redis Streams
https://redis.io/topics/streams-intro - glob (programming)
https://en.wikipedia.org/wiki/Glob_(programming) - Why and how Pricing Assistant migrated from Celery to RQ – Paris.py
https://www.slideshare.net/sylvinus/why-and-how-pricing-assistant-migrated-from-celery-to-rq-parispy-2 - Enqueueing internals
http://python-rq.org/contrib/ - queue — A synchronized queue class
https://docs.python.org/3/library/queue.html - Queue – A thread-safe FIFO implementation
https://pymotw.com/2/Queue/ - Queues
http://queues.io/ - Windows Subsystem for Linux Documentation
https://docs.microsoft.com/en-us/windows/wsl/about - RestMQ
http://restmq.com/ - ActiveMQ
http://activemq.apache.org/ - Amazon MQ
https://aws.amazon.com/amazon-mq/ - Amazon Simple Queue Service
https://aws.amazon.com/sqs/ - Celery: Distributed Task Queue
http://www.celeryproject.org/ - Disque, an in-memory, distributed job queue
https://github.com/antirez/disque - rq-dashboard
https://github.com/eoranged/rq-dashboard - Projekt RQ na PyPi
https://pypi.org/project/rq/ - rq-dashboard 0.3.12
https://pypi.org/project/rq-dashboard/ - Job queue
https://en.wikipedia.org/wiki/Job_queue - Why we moved from Celery to RQ
https://frappe.io/blog/technology/why-we-moved-from-celery-to-rq - Running multiple workers using Celery
https://serverfault.com/questions/655387/running-multiple-workers-using-celery - celery — Distributed processing
http://docs.celeryproject.org/en/latest/reference/celery.html - Chains
https://celery.readthedocs.io/en/latest/userguide/canvas.html#chains - Routing
http://docs.celeryproject.org/en/latest/userguide/routing.html#automatic-routing - Celery Distributed Task Queue in Go
https://github.com/gocelery/gocelery/ - Python Decorators
https://wiki.python.org/moin/PythonDecorators - Periodic Tasks
http://docs.celeryproject.org/en/latest/userguide/periodic-tasks.html - celery.schedules
http://docs.celeryproject.org/en/latest/reference/celery.schedules.html#celery.schedules.crontab - Pros and cons to use Celery vs. RQ
https://stackoverflow.com/questions/13440875/pros-and-cons-to-use-celery-vs-rq - Priority queue
https://en.wikipedia.org/wiki/Priority_queue - Jupyter
https://jupyter.org/ - How IPython and Jupyter Notebook work
https://jupyter.readthedocs.io/en/latest/architecture/how_jupyter_ipython_work.html - Context Managers
http://book.pythontips.com/en/latest/context_managers.html



