
Obsah
1. Úvod do problematiky fuzzingu a fuzz testování
4. Vyhledávání operačních kódů neznámých instrukcí aneb slavná instrukce HCF
8. Slavný nástroj AFL – american fuzzy lop
9. Generování vstupních souborů
10. Fuzzy testování webových služeb a webových aplikací
11. Přehled vybraných knihoven pro fuzzy testování
18. Obsah následujícího článku
1. Úvod do problematiky fuzzingu a fuzz testování
V dnešním článku se alespoň ve stručnosti seznámíme s problematikou takzvaného fuzzingu a fuzz testování. Jedná se o techniky určené pro testování stability, korektnosti a bezpečnosti aplikací či celých informačních systémů, které navíc mohou být – v porovnání s ručně vytvářenými testy – velmi efektivní jak z hlediska počtu nalezených chyb, tak i lidského času, který je nutné testování věnovat. Principem fuzzingu je (velmi vágně řečeno) generování pseudonáhodných dat, posílání těchto dat do testovaného systému a zjišťování, jak se systém chová, tedy jak na vstupní data reaguje.
Předchůdcem dnešních mnohdy velmi sofistikovaných systémů pro fuzzing jsou random testy, v některých odvětvích IT nazývané taktéž monkey testy. Toto označení vzniklo z představy tlupy opic, které na klávesnici vytváří nesmyslné sekvence znaků, jež jsou následně posílány do testované aplikace, popř. jiné tlupy opic zcela náhodně klikajících myší v grafickém uživatelském prostředí nějaké aplikace (mimochodem – tyto testy se někdy provádí skutečně ručně, což je ovšem velmi drahé a navíc ani nelze zaručit například skutečnou náhodnost sekvence prováděných operací).
Fuzzy testování je v současnosti považováno za poněkud odlišnou kategorii než monkey testování, a to z toho důvodu, že mnohé moderní fuzzery (příkladem budiž slavný AFL zmíněný v dalším textu) neprodukují čistě náhodné vstupy pro testovanou aplikaci, ale naopak se snaží produkovat vstup, který je do značné míry korektní, ovšem nějaká jeho část je vhodným způsobem modifikována. Navíc se většinou fuzzery snaží najít minimální množinu vstupních dat, která produkuje špatné výsledky, popř. způsobí pád aplikace. Fuzzing se ovšem používá nejenom pro čisté testování stability, korektnosti a bezpečnosti aplikací. Lze ho taktéž použít pro řízené útoky na jednotlivé aplikace, služby operačního systému, samotná jádra operačního systému a dokonce i na samotný hardware. Fuzzing tak může být do jisté míry alternativou či spíše doplňkem penetračních testů (ty mohou být velmi časově náročné z pohledu lidského času).
2. Typy fuzzingu
Nástrojů a knihoven určených pro fuzzy testování (v dalším textu jim většinou budeme zkráceně říkat fuzzery) dnes existuje poměrně velké množství, ovšem ne všechny dostupné nástroje nabízí svým uživatelům stejné vlastnosti a možnosti. Obecně je možné fuzzery rozdělit podle několika kritérií, zejména:
- Jakým způsobem jsou generovány vstupy použité v testech a jak je vůbec specifikováno, o jaká data se má jednat.
- Zda fuzzer zná a nějakým způsobem využívá informace o vnitřní struktuře testovaného systému či nikoli (rozdělení je na black-box, white-box a gray-box testování).
- A dále podle toho, zda a jak fuzzer rozumí struktuře vstupních dat či zda jen pseudonáhodně generuje vstupy bez dalších potřebných znalostí či zpětné vazby (ta je mnohdy důležitá pro vytvoření minimální sady vstupů, které způsobí chybu).
- Zda fuzz testy zjišťují pokrytí (coverage) a upravují podle toho svoji sadu testovacích dat (korpus). Obecně se jedná o nejrychlejší cestu k nalezení chyby.
Je ovšem důležité si uvědomit, že fuzz testy nejsou náhradou jednotkových testů, ale jejich vhodným doplňkem.
Jak pracují fuzzery založené na zjišťování pokrytí si můžeme ukázat na tomto kódu, který spadne pouze jediný vstup, a to konkrétně „1234“:
if input[0] == '1' {
if input[1] == '2' {
if input[2] == '3' {
if input[3] == '4' {
panic("Foobar!")
}}}}
Testy založené na náhodném vzorku vstupů by vyžadovaly O(2564), tj. O(232) operací, zatímco pokud fuzzer sleduje pokrytí kódu, může dojít k chybě již za O(4*28) operací, tedy mnohem rychleji. Takzvaný korpus s testovacími daty bude postupně obsahovat:
"1" "1" "12" "1" "12" "123" "1" "12" "123" "1234"
3. Zrod termínu „fuzzing“
Termín fuzzing se začal používat již v roce 1988. Byl vymyšlen a zaveden Bartonem Millerem, který si všiml, že náhodné vstupy (způsobené šumem na telefonní lince, kterou používal po připojení k univerzitnímu serveru s Unixem) přivedené do některých programů a utilit mohou vést k jejich pádu, tj. že zdaleka ne všechny vstupy jsou vždy řádným způsobem ošetřeny (mimochodem: testovaly se klasické unixové programy a utility, včetně textového editoru Vi, awk, sort, sed, překladače cc atd.). Následně tento poznatek rozšířil a na kurzu, který na universitě vedl (Advanced Operating System) se tímto tématem začali do větší hloubky věnovat i jeho studenti. A právě na tomto kurzu se začal používat termín „fuzz“. Zpočátku se sice fuzzing používal pro testování utility spouštěných z příkazové řádky, ale později byl celý koncept rozšířen i na aplikace s grafickým uživatelským rozhraním (tím se vlastně navázalo na starší nástroj „The Monkey“ zmíněný v úvodní kapitole).
4. Vyhledávání operačních kódů neznámých instrukcí aneb slavná instrukce HCF
Techniky podobné fuzzingu se ovšem používaly i dříve, než vůbec termín fuzz testing vznikl. Oblíbenou kratochvílí bylo například vyhledávání nových operačních kódů nedokumentovaných instrukcí v instrukčních souborech starších procesorů a mikroprocesorů, u nichž se kvůli zjednodušení návrhu dekodéru (a většinou i mikroprogramového řadiče) neošetřovaly neznámé vstupy. Již v dobách počítačů řady IBM System/360 se polovážně mluvilo o instrukci s mnemotechnickou zkratkou HCF neboli plným jménem Halt and Catch Fire (vtip vznikl na základě toho, že instrukční soubor těchto systémů byl velmi rozsáhlý a mnohé zkratky nedávaly příliš velký význam). Tato instrukce sice ve skutečnosti pro řadu S/360 neexistovala, ale později se mnemotechnická zkratka HCF začala používat pro jiné nedokumentované instrukce, které nalezneme například u čipů Motorola 6800 (dvoubajtová sekvence způsobující zablokování mikroprocesoru), MOS 6502 (kombinace několika jednodušších instrukcí, některé dokonce dávají smysl), ale i u čipů Z80 apod.
5. Pentium F00F bug
Jednou z nejznámějších neplatných instrukcí spadajících do „kategorie HCF“ (která byla pravděpodobně objevena právě zkoušením různých kombinací neznámých operačních kódů nějakým jednoduchým fuzzerem) je instrukce mikroprocesorů Intel Pentium, která by v assembleru vypadala následovně (nejedná se ovšem o validní instrukci, protože operandem by v tomto případě měla být adresa v paměti a nikoli pracovní registr, už vůbec ne registr eax, který je operandem implicitním):
lock cmpxchg8b eax
operační kód této instrukce v hexadecimálním kódu je:
F0 0F C7 C8
přičemž první dva znaky daly této chybě jméno (už jen proto, že je v nich pěkný vzorek a extrémní hodnoty hexadecimálních číslic). Problém – a to v době objevení této chyby poměrně velký – spočíval v tom, že nevalidní instrukce by měly způsobit výjimku, kterou je možné dále zpracovat (aby například jádro systému mohlo vypsat informaci o tom, kde k takové výjimce došlo). Ovšem kombinace prefixu lock (zamčení sběrnice pro další procesory) s touto konkrétní instrukcí a operandy způsobila, že ani obsluha výjimky nebyla schopna přečíst data přes zamčenou sběrnici. Výsledkem bylo, že i běžný program spouštěný s právy běžného uživatele, dokázal celý procesor zastavit a ten musel být zresetován.
6. Nástroj crashme
„DO NOT USE THIS PROGRAM UNLESS YOU REALLY WANT TO CRASH YOUR COMPUTER.“
Vraťme se ještě na chvíli k prehistorii nástrojů, které bychom dnes zařadili do kategorie Monkey tester nebo i fuzzer. Jedním z dnes již značně letitých nástrojů, které je však možné stále nainstalovat i na moderní Linuxové distribuce, je nástroj nazvaný jednoduše a stručně crashme. Tento nástroj generuje náhodné sekvence bajtů, které se následně snaží spustit (čímž se vlastně blíží k hledání neznámých instrukcí atd.). Tímto způsobem se testuje stabilita a odolnost jádra operačního systému – předpokládá se totiž (a to zcela oprávněně), že ani zcela náhodná sekvence bajtů by neměla způsobit pád jádra operačního systému. Ovšem jak jsme mohli vidět v předchozí kapitole, ne vždy musí být chyba přítomna v samotném jádře systému, protože moderní mikroprocesory (především ty s CISCovou instrukční sadou) jsou již velmi složité obvody, které prakticky musí obsahovat chyby, jež jsou – jak ostatně můžeme číst prakticky každý měsíc – jen složitě odhalitelné a opravitelné.
7. Fuzzy testování API a ABI
Velmi často se fuzzery používají pro testování API, popř. i ABI, tedy rozhraní nabízených knihovnami, popř. i jádrem operačního systému. Typicky jsou fuzzery v tomto případě vhodným způsobem nakonfigurovány, aby mohly volat nativní funkce, popř. metody a předávat jim generované parametry. Existují ovšem i sofistikovanější varianty fuzzerů, které je možné přilinkovat k testované knihovně a tuto knihovnu dále používat (což bude pomalé, ovšem odhalí se tím množství potenciálních chyb). Díky tomu může fuzzer zjistit, který kód je pro jaké vstupy skutečně použit a příslušným způsobem vstupní data modifikovat. Příkladem takového fuzzeru je libFuzzer, který využívá SanitizerCoverage. Tímto typem fuzzerů se budeme zabývat v samostatném článku.
8. Slavný nástroj AFL – american fuzzy lop
Jedním z nejpoužívanějších a dalo by se říci, že i nejslavnějších fuzzy nástrojů je AFL neboli american fuzzy lop. Tento nástroj, kterému bude pochopitelně věnován samostatný článek, je možné použít pro zjištění neošetřených vstupů i potenciálních bezpečnostním problémů u prakticky libovolného typu aplikace. Primárně se jedná o binární spustitelné aplikace, ovšem AFL je v případě potřeby možné zkombinovat například i s Pythonem atd. AFL typicky zkouší různé vstupy a na základě chování aplikace se snaží odvodit takovou kombinaci vstupních dat (o minimální velikosti), která způsobí chybu. Samozřejmě se mnohdy může jednat o časově náročný proces, proto AFL obsahuje dnes již typický výstup s informacemi o probíhajících operacích:
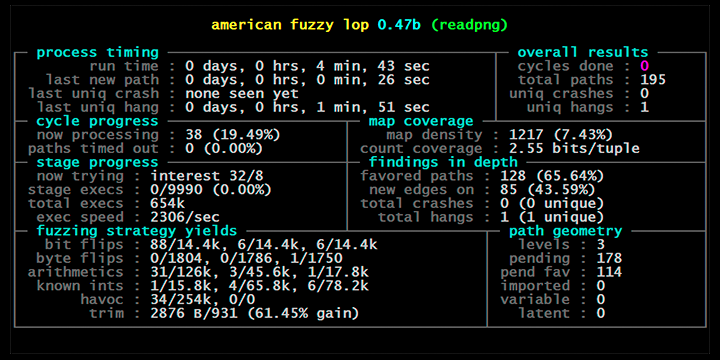
Obrázek: Činnost AFL (zdroj: http://lcamtuf.coredump.cx/afl/)
9. Generování vstupních souborů
Fuzzery se taktéž používají pro generování vstupních souborů, které jsou zpracovávány testovanými aplikacemi (což ostatně umí právě zmíněný AFL). V závislosti na typu aplikace může být takové testování přímočaré, ale mnohdy i velmi komplikované. Přímočaré testování lze použít u prakticky všech nástrojů, které čtou jeden vstupní soubor (či standardní vstup). Příkladem mohou být klasické unixové filtry (sort, uniq, sed, awk), ale i interně mnohem složitější nástroje typu překladač, interpret, linker, assembler apod., které již mnohdy vyžadují značně sofistikovaný fuzzer. Uveďme si ještě jeden příklad komplikovaného testování využívající fuzzer. Může se jednat o JVM či o webový browser, což jsou aplikace s mnoha (mnohdy poněkud skrytými vstupy). Například se jedná o soubory s fonty, což jsou (u TrueType) interně velmi komplikované datové struktury s mnoha interními referencemi, přičemž jakákoli chyba v knihovně, která tyto fonty zpracovává, může vést (v tom lepším případě) k pádu JVM/webového browseru, v horším případě pak k obejití „sandboxu“ či dokonce k pádu celého GUI na straně uživatele.
10. Fuzzy testování webových služeb a webových aplikací
Po relativně dlouhé časové období se fuzzy testování používalo zejména pro zjišťování problémů v různých knihovnách (zmiňme například SSL, libpng, FreeType, Qt), utilitách a například i překladačích. Ovšem dnes můžeme sledovat poměrně rychlou adaptaci této technologie při testování webových služeb či celých webových aplikací. Je to ostatně logické, zejména když si uvědomíme, že právě webové služby a aplikace poskytují svá rozhraní mnohdy všem uživatelům Internetu a tedy i mnoha potenciálním útočníkům. Snaha o co nejlepší zabezpečení je tedy v této oblasti IT zcela pochopitelná. Testovat je možné například REST API. V tomto případě mohou fuzzery použít popis API (OpenAPI/Swagger atd.) a na základě něho začít generovat různé potenciálně problematické vstupy se snahou o obejití vnitřních kontrolních mechanismů aplikace či služby. Některé nástroje, například https://github.com/dubzzz/fuzz-rest-api/, se navíc snaží o různé specifické typy útoků, například do dat přidávají řetězce s příklady SQL Injection apod. Dále lze pochopitelně posílat pseudonáhodná data v tělech požadavků, měnit parametry URL i hlavičky požadavků.
11. Přehled vybraných knihoven pro fuzzy testování
V navazujících sedmi kapitolách se ve stručnosti zmíníme o vybraných knihovnách, které je možné použít pro fuzzy testování. Vybrané knihovny jsou určeny pro rozličné programovací jazyky a mají i rozdílnou funkci – některé testují API a ABI, další jsou určeny spíše pro testování odolnosti celých aplikací, ostatní pak například pro testování webových služeb a aplikací založených na protokolu HTTP nebo HTTP/2. Nejprve si popíšeme některé knihovny určené pro programovací jazyk Python (seznam dalších knihoven s podobným zaměřením je dostupný například zde), ovšem nezapomeneme ani na programovací jazyk Go (viz též tento obsáhlý seznam) či na mainstreamový programovací jazyk Java s jeho rozsáhlým ekosystémem.
12. Hypothesis
Prvním nástrojem, který je do určité míry založen na fuzzingu, je nástroj nazvaný Hypothesis. Jedná se o nástroj původně určený pro testování aplikací naprogramovaných v Pythonu, ovšem rozšiřuje se i do dalších oblastí. Primárním cílem Hypothesis je automatické generování testů na základě pouze základních pravidel, resp. scénářů zadaných programátorem. Na rozdíl od klasických testů, v nichž je nutné jednotlivé scénáře explicitně zapisovat se v případě Hypothesis v jediném scénáři specifikuje celý rozsah parametrů, na jejichž základě se pak jednotlivé testy automaticky generují. V článcích, které popisují rozdíly mezi klasicky pojatými testy a Hypothesis, se běžné testy označují jako example-based, tedy testy, v nichž jsou explicitně zadány příklady vstupních dat (například se budeme snažit předat zápornou hodnotu, maximální a minimální povolenou hodnotu, nekonečno atd.). Naproti tomu se testy vytvářené s využitím Hypothesis označují jako property-based.
Příklad velmi jednoduchého testu (získaného přímo z dokumentace). Tento test zjistí, zda funkce volání decode(encode(řetězec)) dává korektní výsledky (původní řetězec) pro každý vstup:
from hypothesis import given
from hypothesis.strategies import text
@given(text())
def test_decode_inverts_encode(s):
assert decode(encode(s)) == s
Příklad nalezené chyby v programovém kódu, konkrétně pro případ, že je vstupní řetězec prázdný:
Falsifying example: test_decode_inverts_encode(s='') UnboundLocalError: local variable 'character' referenced before assignment
Jiný jednoduchý příklad, tentokrát pro binární data:
@given(binary())
def test_decode_inverts_encode(s):
assert fromutf8b(toutf8b(s)) == s
13. pythonfuzz
Jedná se o klasický fuzzer určený pro použití v programovacím jazyce Python. Zjišťuje se přitom pokrytí testované funkce či metody a vstupní data se vybírají takovým způsobem, aby pokrytí bylo co největší. Navíc je možné použít takzvaný korpus, který mj. zajišťuje, že další testování bude probíhat za stejných podmínek, jako testování předchozí. Pro dnešek si pouze ukažme příklad použití:
from html.parser import HTMLParser
from pythonfuzz.main import PythonFuzz
@PythonFuzz
def fuzz(buf):
try:
string = buf.decode("ascii")
parser = HTMLParser()
parser.feed(string)
except UnicodeDecodeError:
pass
Tato funkce je volána neustále dokola s náhodně generovanými daty. Přitom se testuje metoda HTMLParser.feed(), která může pro neplatný vstup vyhazovat výjimku typu UnicodeDecodeError. Pokud tato výjimka nastane, je ignorována, ovšem ostatní výjimky jsou knihovnou pythonfuzz detekovány.
14. go-fuzz
Nástroj go-fuzz, jehož zdrojové kódy jsou dostupné na adrese https://github.com/dvyukov/go-fuzz, je určen pro použití v programovacím jazyku Go, zejména pro testování korektnosti zpracování vstupů předávaných funkcím a metodám. I tento nástroj již našel mnoho chyb, které jsou vypsány zde. Následuje ukázka primitivního příkladu použití, jenž testuje chování funkce png.Decode pro jakákoli vstupní data:
func Fuzz(data []byte) int {
png.Decode(bytes.NewReader(data))
return 0
}
popř. taktéž (kontroluje se formát gob):
func Fuzz(data []byte) int {
gob.NewDecoder(bytes.NewReader(data)).Decode(new(interface{}))
return 0
}
Tuto knihovnu si popíšeme příště.
15. gofuzz
Druhou knihovnou pro fuzz testování určenou pro použití s programovacím jazykem Go je knihovna nazvaná gofuzz. Jedná se o relativně jednoduchý balíček, který slouží pro generování pseudonáhodných testovacích dat. Není zde tedy implementována zpětná vazba založená na zjišťování pokrytí tak, jako je tomu v předchozím projektu go-fuzz. I tímto projektem se budeme podrobněji zabývat v navazujícím článku.
16. tavor
Mnoho fuzzerů, například již dříve zmíněný AFL, je primárně určeno pro generování binárních dat, která jsou přivedena na vstup testovaných funkcí, metod či celých aplikací. Mnohdy se však setkáme spíše se vstupem textovým, resp. se speciálně strukturovanými textovými daty. A právě pro tyto účely je možné použít fuzzer nazvaný tavor, při jehož použití se vstupní data popisují v takzvaném Tavor formátu založeném na klasickém EBNF. Tomuto nástroji bude kvůli jeho relativně velké komplexnosti věnován samostatný článek.
17. JQF
Zapomenout pochopitelně nesmíme na ekosystém programovacího jazyka Java. Pro něj taktéž vzniklo několik fuzzerů. Jedním z těch nejpokročilejších je JQF, jenž lze použít společně s fuzzy algoritmem Zest, popř. s klasickým AFL. Příklady skutečných chyb nalezených tímto nástrojem naleznete na stránce https://github.com/rohanpadhye/jqf#trophies.
S využitím JQF může být psaní testů skutečně jednoduché, což je patrné z demonstračního příkladu, který je uvedený přímo na stránce tohoto projektu (uvádím jen zkrácenou variantu):

@Fuzz
public void testMap2Trie(Map<String, Integer> map, String key) {
// Key should exist in map
assumeTrue(map.containsKey(key)); // the test is invalid if this predicate is not true
// Create new trie with input `map`
Trie trie = new PatriciaTrie(map);
// The key should exist in the trie as well
assertTrue(trie.containsKey(key)); // fails when map = {"x": 1, "x\0": 2} and key = "x"
}
Parametry do testovací metody testMap2Trie jsou generovány automaticky na základě anotace @Fuzz. Díky algoritmu Zest je nalezení chyb v implementaci PatriciaTrie poměrně rychlé (přesněji – proběhne jen relativně malé množství iterací), zejména v porovnání s testováním náhodných vstupních dat.
18. Obsah následujícího článku
V navazujícím článku si ukážeme, jak lze využít vybrané knihovny pro vytvoření a spuštění skutečných fuzzy testů. Zaměříme se přitom (alespoň zpočátku) na ty knihovny, které jsou určené pro programovací jazyk Python (zde vítězí Hypothesis, ale popíšeme si i PyJFuzz) a nezapomeneme ani na programovací jazyk Go. Ovšem to neznamená, že ostatní jazyky a jejich mnohdy specifické doménové oblasti vynecháme, protože se ve třetím článku pro změnu zaměříme na JavaScript a pro něj určené knihovny a frameworku. Samostatný článek je vyhrazen pro popis AFL i na knihovny uvedené výše.
19. Odkazy na Internetu
- Fuzzing (Wikipedia)
https://en.wikipedia.org/wiki/Fuzzing - american fuzzy lop
http://lcamtuf.coredump.cx/afl/ - Fuzzing: the new unit testing
https://go-talks.appspot.com/github.com/dvyukov/go-fuzz/slides/fuzzing.slide#1 - AFL – QuickStartGuide.txt
https://github.com/google/AFL/blob/master/docs/QuickStartGuide.txt - Introduction to Fuzzing in Python with AFL
https://alexgaynor.net/2015/apr/13/introduction-to-fuzzing-in-python-with-afl/ - Writing a Simple Fuzzer in Python
https://jmcph4.github.io/2018/01/19/writing-a-simple-fuzzer-in-python/ - Golang Fuzzing: A go-fuzz Tutorial and Example
http://networkbit.ch/golang-fuzzing/ - Fuzzing Python Modules
https://stackoverflow.com/questions/20749026/fuzzing-python-modules - 0×3 Python Tutorial: Fuzzer
http://www.primalsecurity.net/0×3-python-tutorial-fuzzer/ - fuzzing na PyPi
https://pypi.org/project/fuzzing/ - Fuzzing 0.3.2 documentation
https://fuzzing.readthedocs.io/en/latest/ - Randomized testing for Go
https://github.com/dvyukov/go-fuzz - HTTP/2 fuzzer written in Golang
https://github.com/c0nrad/http2fuzz - Ffuf (Fuzz Faster U Fool) – An Open Source Fast Web Fuzzing Tool
https://hacknews.co/hacking-tools/20191208/ffuf-fuzz-faster-u-fool-an-open-source-fast-web-fuzzing-tool.html - Continuous Fuzzing Made Simple
https://fuzzit.dev/ - Halt and Catch Fire
https://en.wikipedia.org/wiki/Halt_and_Catch_Fire#Intel_x86 - Pentium F00F bug
https://en.wikipedia.org/wiki/Pentium_F00F_bug - Random testing
https://en.wikipedia.org/wiki/Random_testing - Monkey testing
https://en.wikipedia.org/wiki/Monkey_testing - Fuzzing for Software Security Testing and Quality Assurance, Second Edition
https://books.google.at/books?id=tKN5DwAAQBAJ&pg=PR15&lpg=PR15&q=%22I+settled+on+the+term+fuzz%22&redir_esc=y&hl=de#v=onepage&q=%22I%20settled%20on%20the%20term%20fuzz%22&f=false - Z80 Undocumented Instructions
http://www.z80.info/z80undoc.htm - The 6502/65C02/65C816 Instruction Set Decoded
http://nparker.llx.com/a2/opcodes.html - libFuzzer – a library for coverage-guided fuzz testing
https://llvm.org/docs/LibFuzzer.html - fuzzy-swagger na PyPi
https://pypi.org/project/fuzzy-swagger/ - fuzzy-swagger na GitHubu
https://github.com/namuan/fuzzy-swagger - Fuzz testing tools for Python
https://wiki.python.org/moin/PythonTestingToolsTaxonomy#Fuzz_Testing_Tools - A curated list of awesome Go frameworks, libraries and software
https://github.com/avelino/awesome-go - gofuzz: a library for populating go objects with random values
https://github.com/google/gofuzz - tavor: A generic fuzzing and delta-debugging framework
https://github.com/zimmski/tavor - hypothesis na GitHubu
https://github.com/HypothesisWorks/hypothesis - Hypothesis: Test faster, fix more
https://hypothesis.works/ - Hypothesis
https://hypothesis.works/articles/intro/ - What is Hypothesis?
https://hypothesis.works/articles/what-is-hypothesis/ - Databáze CVE
https://www.cvedetails.com/ - Fuzz test Python modules with libFuzzer
https://github.com/eerimoq/pyfuzzer - Taof – The art of fuzzing
https://sourceforge.net/projects/taof/ - JQF + Zest: Coverage-guided semantic fuzzing for Java
https://github.com/rohanpadhye/jqf - http2fuzz
https://github.com/c0nrad/http2fuzz - Demystifying hypothesis testing with simple Python examples
https://towardsdatascience.com/demystifying-hypothesis-testing-with-simple-python-examples-4997ad3c5294

