Obsah
1. Celery: systém implementující asynchronní fronty úloh pro Python (dokončení)
2. Příprava pro otestování možností systému Celery
3. Nástroj celery events pro zobrazení stavu workerů a úloh
4. Zobrazení podrobnějších informací o vybrané úloze
5. Webový nástroj Flower pro monitoring i řízení naplánovaných úloh
6. Instalace a spuštění nástroje Flower
7. Informace zobrazované nástrojem Flower
8. HTTP API nabízené nástrojem Flower
10. Použití plánovače celery beat
11. Naplánování spouštění úloh podobné nástroji cron
12. Současné spuštění workerů i plánovače
13. Využití většího množství front
14. Worker přiřazený jediné frontě
15. Naplánovaní úloh pro jednotlivé workery
16. Sledování většího množství workerů a front
17. Worker přiřazený většímu množství front
18. Sledování tří front zpracovávaných jediným workerem
19. Repositář s demonstračními příklady
1. Celery: systém implementující asynchronní fronty úloh pro Python (dokončení)
Na úvodní článek o systému Celery dnes navážeme, protože se budeme zabývat složitějšími příklady použití. V první části budou popsány dva nástroje, které jsou určeny pro sledování stavu front popř. naplánovaných úloh a workerů, kteří úlohy zpracovávají. Jedná se o standardní nástroj celery events s textovým uživatelským rozhraním a dále nástroj pojmenovaný Flower, který svým uživatelům nabízí jak webové rozhraní, tak i poměrně jednoduše použitelné REST API.
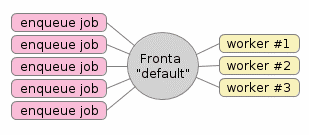
Obrázek 1: Typická konfigurace systému s frontami úloh.
Druhá část článku bude věnována poměrně často vyžadované funkcionalitě – jedná se o nutnost spouštění vybraných úloh v určený časový okamžik nebo dokonce periodicky (například každou hodinu, na začátku každého pracovního dne apod.). Závěrečná část článku bude věnována popisu použití většího množství (pojmenovaných) front. Úlohy je totiž možné posílat do pojmenovaných front a samotní workeři mohou úlohy vybírat pouze z nastavených front. Vše si samozřejmě ukážeme na demonstračních příkladech.
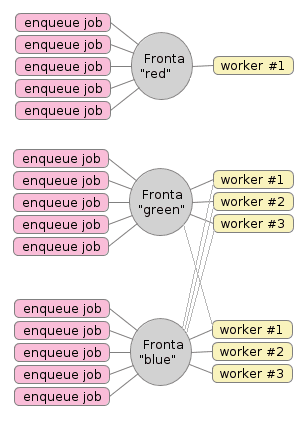
Obrázek 2: Ve skutečnosti však může být konfigurace Celery složitější. Můžeme například použít tři fronty, některé workery připojit na jedinou frontu a další workery na dvě či dokonce na všechny tři fronty.
2. Příprava pro otestování možností systému Celery
Podobně, jako tomu bylo v úvodním článku o Celery i v článcích o konkurenčním projektu Redis Queue (RQ), použijeme společně s nástrojem Celery i systém Redis, a to jak pro realizaci takzvaného brokera (tj. vlastní fronty resp. několika front, do nichž se ukládají naplánované úlohy), tak i pro implementaci backendu (ten primárně slouží k uložení výsledků úloh, popř. i pro uložení informací o výjimkách, pokud úloha zhavaruje). Budeme přitom předpokládat, že je Redis nakonfigurovaný takovým způsobem, aby byl dostupný pro lokální uživatele, což v praxi znamená, že bude naslouchat pouze na síťovém zařízení localhost:
$ redis-server redis.conf
V navazujících kapitolách si ukážeme použití dvou nástrojů určených pro monitoring front a workerů. Z tohoto důvodu použijeme tuto implementaci jednoduchého workera, v němž jsou předepsány dvě úlohy, jedna pro součet dvou číselných hodnot, druhá pro jejich součin. Funkce sleep() simuluje workery s déletrvající operací:
from time import sleep
from celery import Celery
app = Celery('tasks')
app.config_from_object('celeryconfig')
@app.task
def add(x, y):
print("Working, received parameters {} and {} to add".format(x, y))
sleep(2)
result = x + y
print("Done with result {}".format(result))
return result
@app.task
def multiply(x, y):
print("Working, received parameters {} and {} to multiply".format(x, y))
sleep(2)
result = x * y
print("Done with result {}".format(result))
return result
Celery s tímto workerem spustíme jednoduše. Pouze musíme dbát na to, aby se spuštění provedlo v adresáři obsahujícím implementaci workera:
$ cd message-queues-examples/celery/example06/ $ celery -A tasks worker --loglevel=info
3. Nástroj celery events pro zobrazení stavu workerů a úloh
Pro sledování stavu úloh a workerů (a nepřímo i front) slouží nástroj vybavený jednoduchým textovým uživatelským rozhraním (TUI), který je součástí základní instalace Celery. Tento nástroj se spustí příkazem celery events, protože skutečně zachycuje a zobrazuje události, ke kterým v průběhu činnosti Celery dochází (naplánování úlohy, její vykonání apod.).
Nástroj celery events můžeme samozřejmě spustit i ve chvíli, kdy nejsou žádné úlohy ani naplánovány ani vykonávány:
$ cd message-queues-examples/celery/example06/ $ celery events
V tomto případě by se mělo zobrazit celoobrazovkové (či spíše celoterminálové) textové uživatelské rozhraní, které bude vypadat přibližně takto:
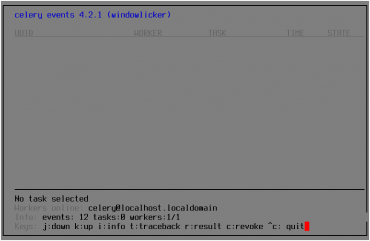
Obrázek 3: Spuštění nástroje celery events ve chvíli, kdy nejsou dokončeny žádné úlohy. Povšimněte si, že se zobrazil počet spuštěných workerů i počet čekajících úloh (nula v tomto případě)
Nyní nám pouze zbývá spustit několik úloh, které budou realizovány workerem, o němž jsme se zmínili v předchozí kapitole. Pro naplánování úloh s jejich vložením do fronty je použit tento skript, v němž se spustí úloha počítající součet, na kterou je navázána úloha počítající součin (koncept zřetězení úloh jsme si vysvětlili již v předchozím článku):
from tasks import add, multiply
for i in range(10):
add.apply_async((i, i + 1), link=multiply.s(i))
Následně všech deset úloh naplánujeme spuštěním tohoto skriptu z příkazového řádku:
$ cd message-queues-examples/celery/example06/ $ python3 enqueue_more_work.py
4. Zobrazení podrobnějších informací o vybrané úloze
V terminálu, v němž jsme spustili příkaz celery events, by se nyní měly jednotlivé úlohy vypsat, takže by obsah obrazovky mohl vypadat například takto:
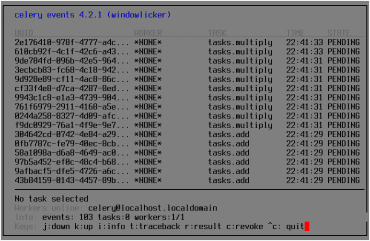
Obrázek 4: Seznam naplánovaných úloh. Všechny úlohy, které jsou zobrazeny, čekají ve frontě na nějakého workera, který je bude ochoten zpracovat.
V případě, že se výsledek úlohy uložil do nakonfigurovaného backendu (například opět do Redisu), můžeme si tento výsledek snadno zobrazit. Taktéž si můžeme zobrazit podrobnější informace o úloze, která prozatím nebyla žádným workerem zpracována, tj. takové úlohy, která je uložena v některé frontě (připomeňme si, že výchozí fronta se jmenuje celery, stav úlohy bude PENDING). Způsob, jakým jsou tyto informace prezentovány uživateli, je vidět na třetím screenshotu:
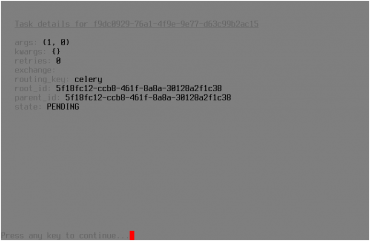
Obrázek 5: Zobrazení podrobnějších informací o vybrané úloze po stisku klávesy i.
5. Webový nástroj Flower pro monitoring i řízení naplánovaných úloh
Výše popsaný nástroj pro zobrazení stavu workerů a úloh sice může být užitečný, ovšem při administraci Celery nenabízí všechny potřebné operace a ani například neumožňuje dlouhodobější sledování využití front, workerů a počítačů zapojených do nakonfigurovaného clusteru. Tyto operace, které jsou ve skutečnosti poměrně často využívány jak vývojáři, tak i (a to možná častěji) administrátory, nabízí jiný nástroj, který se jmenuje Flower. Jméno tohoto nástroje není odvozeno od květiny, ale od slova flow, což naznačuje i některé funkce, které Flower uživatelům nabízí (liší se i výslovnost, která je taktéž odvozena od „flow“).
Mezi základní operace nástroje Flower patří pochopitelně zobrazení úloh ve frontách a taktéž zobrazení případných výsledků úloh (pokud je ovšem nakonfigurován backend pro uložení výsledků). Mezi další podporované operace patří:
- Zobrazení historie úloh (vykonané úlohy, pády apod.).
- Zobrazení statistiky o workerech i o frontách.
- Zobrazení grafů s naplánovanými úlohami, dokončenými úlohami, zaplněností front atd.
- Jednotlivé úlohy lze přímo z UI odstranit.
- Nakonfigurovat lze i fronty (přidání, vymazání atd.), pokud tuto operaci podporuje broker.
- Nastavení škálovatelnosti workerů (počet podprocesů).
- Aplikační programové rozhraní k většině operací.
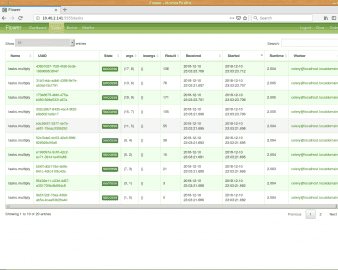
Obrázek 6: Prakticky celé webové rozhraní nástroje Flower (kromě grafů) je stylizováno do barvy celeru.
6. Instalace a spuštění nástroje Flower
Nástroj Flower se instaluje, podobně jako další aplikace, nástroje a knihovny naprogramované v Pythonu, s využitím utility pip popř. pip3. Pro účely otestování si Flower nainstalujeme lokálně, tj. nástroj bude dostupný pouze pro aktuálně přihlášeného uživatele, protože se instalace provede do adresáře ~/.local:
$ pip3 install --user flower
Samotný průběh instalace není ničím výjimečný:
Collecting flower
Downloading https://files.pythonhosted.org/packages/48/7f/344a8f93cbd6669b4fd03c04d8f9a06e9023da7b61145dea5836433bbbe5/flower-0.9.2.tar.gz (1.3MB)
100% |████████████████████████████████| 1.3MB 853kB/s
Requirement already satisfied: celery>=3.1.0 in /home/tester/.local/lib/python3.6/site-packages (from flower)
Collecting tornado>=4.2.0 (from flower)
Downloading https://files.pythonhosted.org/packages/e6/78/6e7b5af12c12bdf38ca9bfe863fcaf53dc10430a312d0324e76c1e5ca426/tornado-5.1.1.tar.gz (516kB)
100% |████████████████████████████████| 522kB 1.6MB/s
Collecting babel>=1.0 (from flower)
Downloading https://files.pythonhosted.org/packages/b8/ad/c6f60602d3ee3d92fbed87675b6fb6a6f9a38c223343ababdb44ba201f10/Babel-2.6.0-py2.py3-none-any.whl (8.1MB)
100% |████████████████████████████████| 8.1MB 198kB/s
Requirement already satisfied: pytz in /usr/lib/python3.6/site-packages (from flower)
Requirement already satisfied: kombu<5.0,>=4.2.0 in /home/tester/.local/lib/python3.6/site-packages (from celery>=3.1.0->flower)
Requirement already satisfied: billiard<3.6.0,>=3.5.0.2 in /home/tester/.local/lib/python3.6/site-packages (from celery>=3.1.0->flower)
Requirement already satisfied: amqp<3.0,>=2.1.4 in /home/tester/.local/lib/python3.6/site-packages (from kombu<5.0,>=4.2.0->celery>=3.1.0->flower)
Requirement already satisfied: vine>=1.1.3 in /home/tester/.local/lib/python3.6/site-packages (from amqp<3.0,>=2.1.4->kombu<5.0,>=4.2.0->celery>=3.1.0->flower)
Installing collected packages: tornado, babel, flower
Running setup.py install for tornado ... done
Running setup.py install for flower ... done
Successfully installed babel-2.6.0 flower-0.9.2 tornado-5.1.1
Vzhledem k tomu, že instalace byla označena za úspěšnou (viz poslední řádek z předchozího výpisu), měl by být na $PATH dostupný i příkaz flower, což si pro jistotu ověříme s využitím příkazu whereis:
$ whereis flower flower: /home/tester/.local/bin/flower
Po úspěšné instalaci si zkusme tento příkaz spustit, a to tím nejsnadnějším způsobem – bez jakýchkoli parametrů. Spuštění by ideálně mělo být provedeno z adresáře, v němž jsou nakonfigurování workeři:
$ flower
[I 181210 22:59:05 command:139] Visit me at http://localhost:5555
[I 181210 22:59:06 command:144] Broker: redis://localhost:6379/0
[I 181210 22:59:06 command:147] Registered tasks:
['celery.accumulate',
'celery.backend_cleanup',
'celery.chain',
'celery.chord',
'celery.chord_unlock',
'celery.chunks',
'celery.group',
'celery.map',
'celery.starmap']
[I 181210 22:59:06 mixins:224] Connected to redis://localhost:6379/0
Jak je z vypsaných zpráv patrné, je webové uživatelské rozhraní Floweru dostupné na adrese localhost:5555. Ve skutečnosti ovšem ve výchozím nastavení není přístup omezen ani z okolních počítačů (!), což je sice užitečné, ovšem potenciálně nebezpečné. V případě potřeby můžete použít přepínače –auth, –basic-auth popř. –oauth2* pro povolení autentizace.
7. Informace zobrazované nástrojem Flower
Nástroj Flower umožňuje zobrazit jak základní, tak i některé podrobnější informace o jednotlivých workerech, frontách a úlohách. Vzhledem k tomu, že se jedná o nástroj s poměrně přehledným uživatelským rozhraním, bude pravděpodobně nejjednodušší si možnosti uživatelského rozhraní popsat na sérii screenshotů:
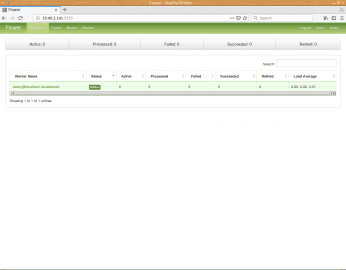
Obrázek 8: Výchozí pohled na sledovaný systém Celery. Vidíme, že je k dispozici pouze jediný worker s označením celery@localhost.localdomain, na němž zrovna není spuštěna žádná úloha.
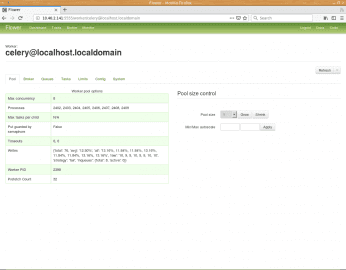
Obrázek 9: Na dalším listu můžeme vidět, že worker je ve skutečnosti realizován osmi procesy, jejichž ID (PID) jsou zobrazeny, stejně jako PID vlastního workera, který jsme spustili z příkazové řádky. V pravé části je možné počet subprocesů snížit či naopak zvýšit.
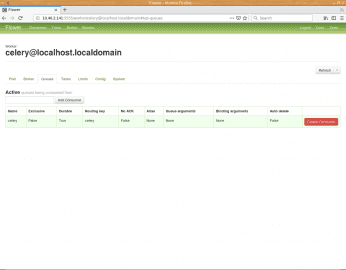
Obrázek 10: Ve výchozím nastavení se používá jediná fronta pojmenovaná „celery“.
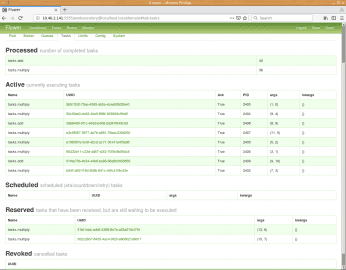
Obrázek 11: Podrobnější informace o jednotlivých úlohách, které byly naplánovány. Povšimněte si, že u každé úlohy máme k dispozici jak její jméno, tak i parametry, s nimiž byla zavolána. U aktivních úloh (které se právě zpracovávají) je samozřejmě k dispozici i ID příslušného procesu.
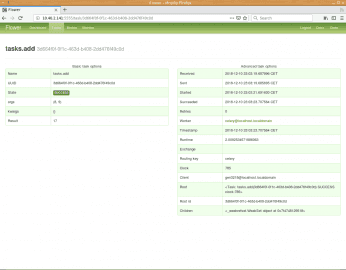
Obrázek 12: Podrobnější informace o vybrané úloze.
Obrázek 13: List se seznamem úloh, které byly naplánovány a/nebo dokončeny.
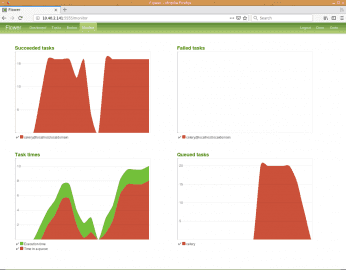
Obrázek 14: Grafy s informacemi o zpracovaných úlohách, času dokončení jednotlivých úloh, úloh, které nebyly z nějakého důvodu dokončeny (vznik výjimky) a konečně počtu úloh ve frontě nebo ve frontách. V dalších kapitolách uvidíme, jakým způsobem se zobrazí větší množství front.
8. HTTP API nabízené nástrojem Flower
V některých případech je užitečné využít HTTP API nabízené nástrojem Flower. Opět bude nejužitečnější si některé možnosti API ukázat na příkladech. Pro jednoduchost bude používat nástroj curl, ovšem samozřejmě nám nic nebrání použít jakýkoli jiný nástroj či knihovnu umožňující komunikaci s využitím HTTP.
Zobrazení seznamu všech workerů:
$ curl -v localhost:5555/api/workers
{"celery@localhost.localdomain": {"stats": {"total": {}, "pid": 11798, "clock": "100", "pool":
...
...
...
Informace o zaplnění fronty či front:
$ curl -v localhost:5555/api/queues/length
{"active_queues": [{"name": "celery", "messages": 0}]}
Zobrazení úloh:
$ curl -v localhost:5555/api/tasks ... ... dlouhý JSON s informacemi o úlohách ... ...
Zobrazení výsledku či stavu vybrané úlohy:
$ curl -v localhost:5555/api/task/result/534eff49-8029-4b4c-a380-3a18036702e0
{"task-id": "534eff49-8029-4b4c-a380-3a18036702e0", "state": "PENDING"}
Znovuspuštění vybrané úlohy:
$ curl -v -X POST localhost:5555/api/task/revoke/534eff49-8029-4b4c-a380-3a18036702e0
{"message": "Revoked '534eff49-8029-4b4c-a380-3a18036702e0'"}
Další příklady naleznete na adrese http://nbviewer.jupyter.org/github/mher/flower/blob/master/docs/api.ipynb ve formě Python Notebooku.
9. Periodické spouštění úlohy
Ve všech demonstračních příkladech, které jsme si prozatím ukázali, se úlohy vkládaly do fronty s tím, že budou vykonány v nejbližším možném čase. Takové úlohy jsou vybraným workerem přečteny, zpracovány a jejich výsledky popř. uloženy do zvoleného datového úložiště (backendu). V některých aplikacích se ovšem můžeme setkat i s jiným typem úloh. Jedná se o takové úlohy, které mají být spouštěny buď periodicky popř. se mají spustit jednou, ovšem až v definovaný okamžik. I takové úlohy je možné v Celery vytvářet – ostatně právě z tohoto důvodu se nejedná o čistou a přímočarou implementaci task queue, ale o komplikovanější systém.
Nejprve se podívejme, jakým způsobem je možné zajistit, aby se vytvořila úloha, která se bude periodicky opakovat.
from time import sleep
from datetime import datetime
from celery import Celery
from celery.schedules import crontab
app = Celery('tasks')
app.config_from_object('celeryconfig')
app.conf.beat_schedule = {
'run-every-two-seconds': {
'task': 'tasks.periodic_task',
'schedule': 2,
'args': (),
},
}
@app.task
def periodic_task():
print("Working, called @ {now}".format(now=datetime.now()))
sleep(2)
print("Done")
Nová je prostřední část skriptu, v němž je specifikována konfigurace úlohy, která má být naplánována na spuštění každé dvě sekundy:
app.conf.beat_schedule = {
'run-every-two-seconds': {
'task': 'tasks.periodic_task',
'schedule': 2,
'args': (),
},
}
Hodnota uložená pod klíčem task musí přesně specifikovat funkci označenou dekorátorem @app.task. Pod klíčem args mohou být uloženy případné argumenty (parametry) předávané úloze. Pojmenované parametry (pokud je samozřejmě úloha používá) se předávají přes kwargs ve formě slovníku. Posledním důležitým parametrem je parametr nazvaný relative, kterému lze přiřadit pravdivostní hodnotu True nebo False. Tímto parametrem se řídí význam časového údaje zadaného v schedule. Buď se jedná o relativní čas vztažený k okamžiku, kdy byl nastartován plánovač, nebo o čas absolutní vztažený k hodinám (při použití dvousekundového intervalu je chování prakticky totožné, ale pokud bychom například zadali celou hodinu, je již mezi relativním či absolutním chápáním času podstatný rozdíl).
Specifikovat je možné přes parametr beat_schedule_filename i jméno souboru, do kterého budou uloženy informace o naplánovaných úlohách.
10. Použití plánovače celery beat
V případě, že budeme potřebovat periodicky spouštět úlohu či úlohy, musí se inicializovat plánovač (scheduler), který se v systému Celery nazývá celery beat. Spuštění plánovače se podobá spuštění workeru, pouze se použije odlišný podpříkaz:
$ celery -A tasks beat --loglevel=info
celery beat v4.2.1 (windowlicker) is starting.
__ - ... __ - _
LocalTime -> 2018-12-11 12:35:34
Configuration ->
. broker -> redis://localhost:6379/0
. loader -> celery.loaders.app.AppLoader
. scheduler -> celery.beat.PersistentScheduler
. db -> celerybeat-schedule
. logfile -> [stderr]@%INFO
. maxinterval -> 5.00 minutes (300s)
[2018-12-11 12:35:34,595: INFO/MainProcess] beat: Starting...
Prakticky ihned po inicializaci plánovače se začnou do výchozí fronty vkládat nové načasované úlohy, což je patrné z logu:
[2018-12-11 12:35:34,607: INFO/MainProcess] Scheduler: Sending due task run-every-two-seconds (tasks.periodic_task) [2018-12-11 12:35:36,601: INFO/MainProcess] Scheduler: Sending due task run-every-two-seconds (tasks.periodic_task) [2018-12-11 12:35:38,601: INFO/MainProcess] Scheduler: Sending due task run-every-two-seconds (tasks.periodic_task)
Plánovač můžeme nechat běžet a v jiném terminálu si (ze stejného adresáře) spustíme workera:
$ celery -A tasks worker
-------------- celery@localhost.localdomain v4.2.1 (windowlicker)
---- **** -----
--- * *** * -- Linux-4.14.11-200.fc26.x86_64-x86_64-with-fedora-26-Twenty_Six 2018-12-11 12:37:44
-- * - **** ---
- ** ---------- [config]
- ** ---------- .> app: tasks:0x7f1e571bc2e8
- ** ---------- .> transport: redis://localhost:6379/0
- ** ---------- .> results: redis://localhost:6379/0
- *** --- * --- .> concurrency: 8 (prefork)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> celery exchange=celery(direct) key=celery
Vidíme, že na mém testovacím počítači s osmi jádry (4 fyzická jádra s hyper-threadingem) se spustilo osm podprocesů s workery. Ihned poté začnou tyto procesy zpracovávat naplánované úlohy, které si vyzvednou z fronty:
[2018-12-11 12:37:46,263: WARNING/ForkPoolWorker-8] Working, called @ 2018-12-11 12:37:46.263094 [2018-12-11 12:37:46,263: WARNING/ForkPoolWorker-1] Working, called @ 2018-12-11 12:37:46.263146 [2018-12-11 12:37:46,269: WARNING/ForkPoolWorker-3] Working, called @ 2018-12-11 12:37:46.268838 [2018-12-11 12:37:46,274: WARNING/ForkPoolWorker-5] Working, called @ 2018-12-11 12:37:46.274475 [2018-12-11 12:37:46,274: WARNING/ForkPoolWorker-6] Working, called @ 2018-12-11 12:37:46.274637 [2018-12-11 12:37:46,281: WARNING/ForkPoolWorker-2] Working, called @ 2018-12-11 12:37:46.281300 [2018-12-11 12:37:46,281: WARNING/ForkPoolWorker-4] Working, called @ 2018-12-11 12:37:46.281385 [2018-12-11 12:37:46,288: WARNING/ForkPoolWorker-7] Working, called @ 2018-12-11 12:37:46.288331 [2018-12-11 12:37:48,266: WARNING/ForkPoolWorker-8] Done [2018-12-11 12:37:48,266: WARNING/ForkPoolWorker-1] Done ... ... ...
11. Naplánování spouštění úloh podobné nástroji cron
Při plánování úloh je možné použít podobný styl specifikace času, jaký je použit v nástroji cron (podobně se ovšem mohou nastavovat i úlohy v Jenkinsu a dalších nástrojích). V nejjednodušším případě se explicitně zadá čas spuštění:
app.conf.beat_schedule = {
# Executes every day morning at 8:45 a.m.
'add-every-day-morning': {
'task': 'tasks.add',
'schedule': crontab(hour=8, minute=45),
'args': (1, 2),
},
}
Taktéž je možné určit den v týdnu (ve výchozí časové zóně se začíná Nedělí):
app.conf.beat_schedule = {
# Executes every Monday morning at 7:30 a.m.
'add-every-monday-morning': {
'task': 'tasks.add',
'schedule': crontab(hour=7, minute=30, day_of_week=1),
'args': (3, 4),
},
}
Spuštění úlohy každých patnáct sekund:
'schedule': crontab(minute="*/15"),
Spuštění úlohy po čtyřech hodinách:
'schedule': crontab(hour="*/4"),
Spuštění úlohy pouze v pracovní dny:
'schedule': crontab(day_of_week="mon-fri"),
Možné jsou i kombinace podmínek:
'schedule': crontab(day_of_week="mon-fri", hour="*/4"),
Složitější schéma, kdy se má úloha spouštět v rámci jediné hodiny:
'schedule': crontab(minute="1/2,5-10,20,30-45,50-59/2"),
Použít lze i další možnosti (ty jsem popravdě nikdy nevyužil), například čas východu a západu Slunce nad Brnem:
'schedule': solar('sunrise', 49.19522, 16.60796)
'schedule': solar('sunset', 49.19522, 16.60796)
12. Současné spuštění workerů i plánovače
Připomeňme si, že klasický worker se startuje příkazem:
$ celery -A tasks worker --loglevel=info
Zatímco plánovač se spouští nepatrně odlišným příkazem:
$ celery -A tasks beat --loglevel=info
Pokud budeme chtít spustit současně jak workera, tak i plánovač, není možné napsat pouze tasks beat worker, protože by nástroj Celery nerozuměl poslednímu slovu. Namísto toho spustíme běžný worker a nepovinným přepínačem -B si vynutíme současné spuštění plánovače:
$ celery -A tasks worker -B
Pro účely odladění nastavení Celery je samozřejmě praktičtější nechat si zobrazit všechny logovací informace (kromě úrovně debug):
$ celery -A tasks worker -B --loglevel=info
Po spuštění se skutečně zobrazí základní informace i o plánovači (zvýrazněný text):
-------------- celery@localhost.localdomain v4.2.1 (windowlicker)
---- **** -----
--- * *** * -- Linux-4.14.11-200.fc26.x86_64-x86_64-with-fedora-26-Twenty_Six 2018-12-12 15:56:45
-- * - **** ---
- ** ---------- [config]
- ** ---------- .> app: tasks:0x7f51a781c048
- ** ---------- .> transport: redis://localhost:6379/0
- ** ---------- .> results: redis://localhost:6379/0
- *** --- * --- .> concurrency: 8 (prefork)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> celery exchange=celery(direct) key=celery
[tasks]
. tasks.periodic_task
[2018-12-12 15:56:45,301: INFO/Beat] beat: Starting...
[2018-12-12 15:56:45,306: INFO/MainProcess] Connected to redis://localhost:6379/0
[2018-12-12 15:56:45,314: INFO/MainProcess] mingle: searching for neighbors
[2018-12-12 15:56:46,332: INFO/MainProcess] mingle: all alone
[2018-12-12 15:56:46,345: INFO/MainProcess] celery@localhost.localdomain ready.
[2018-12-12 15:56:47,319: INFO/Beat] Scheduler: Sending due task run-every-two-seconds (tasks.periodic_task)
13. Využití většího množství front
Podívejme se ještě jednou na obrázek z první kapitoly, kde byla naznačena konfigurace systému se třemi frontami:
Obrázek 15: Konfigurace systému s více frontami.
S podobnou konfigurací se můžeme setkat i v praxi, protože je například užitečné rozdělit úlohy na základě očekávané náročnosti jejich vykonání (dlouhotrvající, krátkodobé), podle typu úlohy (databázové operace, posílání mailů, sledování dalších systémů), popř. podle toho, jak se úlohy spouští (ze skriptu, periodicky).
Pro účely testování si vytvoříme nový projekt, v němž budou definovány tři úlohy rozlišené podle barvy:
from time import sleep
from datetime import datetime
from celery import Celery
app = Celery('tasks')
app.config_from_object('celeryconfig')
@app.task
def red_task():
print("Red task called @ {now}".format(now=datetime.now()))
sleep(2)
print("Red task done")
@app.task
def green_task():
print("Green task called @ {now}".format(now=datetime.now()))
sleep(2)
print("Green task done")
@app.task
def blue_task():
print("Blue task called @ {now}".format(now=datetime.now()))
sleep(2)
print("Blue task done")
Na těchto úlohách není nic zvláštního a v případě potřeby je můžeme naplánovat přes výchozí frontu „celery“.
14. Worker přiřazený jediné frontě
Nyní je možné spustit workery, z nichž každý bude naslouchat na jiné pojmenované frontě. Fronta se specifikuje přepínačem -Q jméno_fronty. Navíc je většinou nutné workera pojmenovat, a to s využitím přepínače -n jméno_workera. Pokud pojmenování neprovedete, použije se hostname a to při větším množství současně běžících workerů bude způsobovat značné problémy.
Celkem spustíme tři workery pojmenované „red“, „green“, „blue“, přičemž každý bude mít přiřazenu vlastní frontu „red_queue“, „green_queue“ a „blue_queue“.
Worker „red“
$ celery -A tasks worker -l info -Q red_queue -n red
-------------- celery@red v4.2.1 (windowlicker)
---- **** -----
--- * *** * -- Linux-4.14.11-200.fc26.x86_64-x86_64-with-fedora-26-Twenty_Six 2018-12-11 20:38:26
-- * - **** ---
- ** ---------- [config]
- ** ---------- .> app: tasks:0x7f8652653c88
- ** ---------- .> transport: redis://localhost:6379/0
- ** ---------- .> results: redis://localhost:6379/0
- *** --- * --- .> concurrency: 8 (prefork)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> red_queue exchange=red_queue(direct) key=red_queue
[2018-12-11 20:38:26,626: INFO/MainProcess] Connected to redis://localhost:6379/0
[2018-12-11 20:38:26,634: INFO/MainProcess] mingle: searching for neighbors
[2018-12-11 20:38:27,651: INFO/MainProcess] mingle: sync with 1 nodes
[2018-12-11 20:38:27,653: INFO/MainProcess] mingle: sync complete
[2018-12-11 20:38:27,663: INFO/MainProcess] celery@red ready.
[2018-12-11 20:38:37,644: INFO/MainProcess] Events of group {task} enabled by remote.
Worker „green“
$ celery -A tasks worker -l info -Q green_queue -n green
-------------- celery@green v4.2.1 (windowlicker)
---- **** -----
--- * *** * -- Linux-4.14.11-200.fc26.x86_64-x86_64-with-fedora-26-Twenty_Six 2018-12-11 20:39:22
-- * - **** ---
- ** ---------- [config]
- ** ---------- .> app: tasks:0x7ff0eb87dc88
- ** ---------- .> transport: redis://localhost:6379/0
- ** ---------- .> results: redis://localhost:6379/0
- *** --- * --- .> concurrency: 8 (prefork)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> green_queue exchange=green_queue(direct) key=green_queue
[2018-12-11 20:39:22,810: INFO/MainProcess] Connected to redis://localhost:6379/0
[2018-12-11 20:39:22,818: INFO/MainProcess] mingle: searching for neighbors
[2018-12-11 20:39:23,836: INFO/MainProcess] mingle: sync with 2 nodes
[2018-12-11 20:39:23,838: INFO/MainProcess] mingle: sync complete
[2018-12-11 20:39:23,854: INFO/MainProcess] celery@green ready.
[2018-12-11 20:38:26,647: INFO/MainProcess] sync with celery@red
[2018-12-11 20:39:27,645: INFO/MainProcess] Events of group {task} enabled by remote.
Worker „blue“
$ celery -A tasks worker -l info -Q blue_queue -n blue
-------------- celery@blue v4.2.1 (windowlicker)
---- **** -----
--- * *** * -- Linux-4.14.11-200.fc26.x86_64-x86_64-with-fedora-26-Twenty_Six 2018-12-11 20:38:22
-- * - **** ---
- ** ---------- [config]
- ** ---------- .> app: tasks:0x7f96b46b1c88
- ** ---------- .> transport: redis://localhost:6379/0
- ** ---------- .> results: redis://localhost:6379/0
- *** --- * --- .> concurrency: 8 (prefork)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> blue_queue exchange=blue_queue(direct) key=blue_queue
[2018-12-11 20:38:22,966: INFO/MainProcess] Connected to redis://localhost:6379/0
[2018-12-11 20:38:22,974: INFO/MainProcess] mingle: searching for neighbors
[2018-12-11 20:38:23,992: INFO/MainProcess] mingle: all alone
[2018-12-11 20:38:24,003: INFO/MainProcess] celery@blue ready.
[2018-12-11 20:38:26,647: INFO/MainProcess] sync with celery@red
[2018-12-11 20:38:26,647: INFO/MainProcess] sync with celery@green
[2018-12-11 20:38:37,644: INFO/MainProcess] Events of group {task} enabled by remote.
15. Naplánovaní úloh pro jednotlivé workery
Nyní nám zbývá jediné – poslat jednotlivým workerům (přes jejich fronty) nějakou úlohu. Fronty přitom musíme explicitně specifikovat, protože nemáme žádného workera, který by zpracovával úlohy z výchozí fronty „celery“. Ve skutečnosti je specifikace fronty při plánování úlohy triviální operace:
from tasks import red_task, green_task, blue_task
for _ in range(25):
red_task.apply_async(queue="red_queue")
green_task.apply_async(queue="green_queue")
blue_task.apply_async(queue="blue_queue")
Jakmile tento skript spustíme, začnou jednotliví workeři zpracovávat úlohy:
Worker „red“
[2018-12-11 20:40:31,801: INFO/MainProcess] Received task: tasks.red_task[c73537d5-9aed-4e2f-94ac-8513d9cac65c] [2018-12-11 20:40:31,803: WARNING/ForkPoolWorker-8] Red task called @ 2018-12-11 20:40:31.802849 [2018-12-11 20:40:33,805: WARNING/ForkPoolWorker-8] Red task done [2018-12-11 20:40:33,811: INFO/ForkPoolWorker-8] Task tasks.red_task[c73537d5-9aed-4e2f-94ac-8513d9cac65c] succeeded in 2.0087841898202896s: None
Worker „green“
[2018-12-11 20:40:31,802: INFO/MainProcess] Received task: tasks.green_task[b3eae1aa-fdf5-4c92-84a9-94079203004e] [2018-12-11 20:40:31,804: WARNING/ForkPoolWorker-8] Green task called @ 2018-12-11 20:40:31.804579 [2018-12-11 20:40:33,806: WARNING/ForkPoolWorker-8] Green task done [2018-12-11 20:40:33,811: INFO/ForkPoolWorker-8] Task tasks.green_task[b3eae1aa-fdf5-4c92-84a9-94079203004e] succeeded in 2.0071335807442665s: None
Worker „blue“
[2018-12-11 20:40:31,805: INFO/MainProcess] Received task: tasks.blue_task[9aebfb6c-ed75-4c11-9a3b-d54317c6cdb6] [2018-12-11 20:40:31,806: WARNING/ForkPoolWorker-8] Blue task called @ 2018-12-11 20:40:31.806742 [2018-12-11 20:40:33,809: WARNING/ForkPoolWorker-8] Blue task done [2018-12-11 20:40:33,814: INFO/ForkPoolWorker-8] Task tasks.blue_task[9aebfb6c-ed75-4c11-9a3b-d54317c6cdb6] succeeded in 2.0078650191426277s: None
16. Sledování většího množství workerů a front
Ve chvíli, kdy je spuštěno větší množství workerů a je k dispozici více front, se samozřejmě změní i informace zobrazené nástrojem Flower:
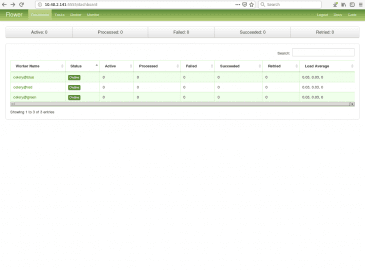
Obrázek 16: Informace o třech workerech.
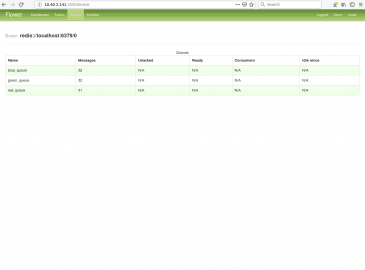
Obrázek 17: Broker má k dispozici trojici front.
17. Worker přiřazený většímu množství front
Worker může být nakonfigurován i takovým způsobem, že bude přijímat úlohy vložené do několika front. Pokud budete vytvářet instanci takového workera, předávají se jména všech front v jediném parametru -Q (jména jsou oddělena čárkou). Ukažme si, jak se takový worker nastartuje:
$ celery -A tasks worker -l info -Q red_queue,blue_queue,green_queue -n colorful
-------------- celery@colorful v4.2.1 (windowlicker)
---- **** -----
--- * *** * -- Linux-4.14.11-200.fc26.x86_64-x86_64-with-fedora-26-Twenty_Six 2018-12-11 20:43:57
-- * - **** ---
- ** ---------- [config]
- ** ---------- .> app: tasks:0x7fc0a8d8fc50
- ** ---------- .> transport: redis://localhost:6379/0
- ** ---------- .> results: redis://localhost:6379/0
- *** --- * --- .> concurrency: 8 (prefork)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> blue_queue exchange=blue_queue(direct) key=blue_queue
.> green_queue exchange=green_queue(direct) key=green_queue
.> red_queue exchange=red_queue(direct) key=red_queue
[2018-12-11 20:43:57,707: INFO/MainProcess] Connected to redis://localhost:6379/0
[2018-12-11 20:43:57,716: INFO/MainProcess] mingle: searching for neighbors
[2018-12-11 20:43:58,733: INFO/MainProcess] mingle: all alone
[2018-12-11 20:43:58,748: INFO/MainProcess] celery@colorful ready.
Ze zvýrazněných řádků je patrné, že worker bude skutečně používat všechny tři specifikované fronty.
Po naplánování tří úloh:
from tasks import red_task, green_task, blue_task red_task.apply_async(queue="red_queue") green_task.apply_async(queue="green_queue") blue_task.apply_async(queue="blue_queue")
Se všechny tři úlohy skutečně zpracují jediným workerem:
[2018-12-11 20:44:50,233: INFO/MainProcess] Received task: tasks.red_task[36e26c26-20a0-4c0c-9f3f-a30ad1af52fa] [2018-12-11 20:44:50,235: INFO/MainProcess] Received task: tasks.green_task[99eca780-4b78-4bc0-a013-993a993bd0b5] [2018-12-11 20:44:50,236: WARNING/ForkPoolWorker-1] Green task called @ 2018-12-11 20:44:50.236392 [2018-12-11 20:44:50,236: WARNING/ForkPoolWorker-8] Red task called @ 2018-12-11 20:44:50.236387 [2018-12-11 20:44:50,236: INFO/MainProcess] Received task: tasks.blue_task[85809695-ffa0-42a8-b863-6c85e4555857] [2018-12-11 20:44:50,239: WARNING/ForkPoolWorker-3] Blue task called @ 2018-12-11 20:44:50.239053 [2018-12-11 20:44:52,239: WARNING/ForkPoolWorker-8] Red task done [2018-12-11 20:44:52,239: WARNING/ForkPoolWorker-1] Green task done [2018-12-11 20:44:52,241: WARNING/ForkPoolWorker-3] Blue task done [2018-12-11 20:44:52,244: INFO/ForkPoolWorker-1] Task tasks.green_task[99eca780-4b78-4bc0-a013-993a993bd0b5] succeeded in 2.0082848705351353s: None [2018-12-11 20:44:52,244: INFO/ForkPoolWorker-8] Task tasks.red_task[36e26c26-20a0-4c0c-9f3f-a30ad1af52fa] succeeded in 2.008291855454445s: None [2018-12-11 20:44:52,245: INFO/ForkPoolWorker-3] Task tasks.blue_task[85809695-ffa0-42a8-b863-6c85e4555857] succeeded in 2.0061764754354954s: None
18. Sledování tří front zpracovávaných jediným workerem
Opět si – jen pro úplnost – ukažme, jakým způsobem se informace o workeru navázaného na tři fronty zobrazí v nástroji Flower:
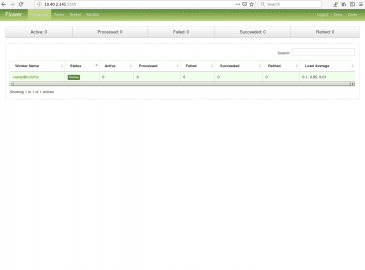
Obrázek 18: Worker nazvaný colorful v nástroji Flower.
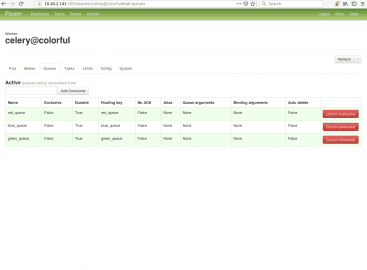
Obrázek 19: Všechny tři fronty, které jsou k dispozici.
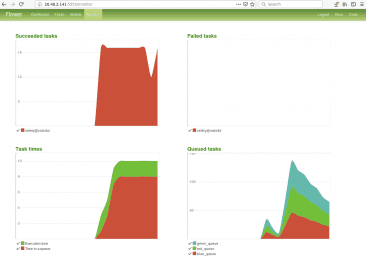
Obrázek 20: Na pravém dolním grafu je patrné, že se mi nakonec nepodařilo sladit názvy front s barvami zvolenými nástrojem Flower.

Obrázek 21: Zde je patrné, že worker skutečně přijímá všechny úlohy.
19. Repositář s demonstračními příklady
Zdrojové kódy všech dnes popsaných demonstračních příkladů naprogramovaných v Pythonu byly uloženy do Git repositáře, který je dostupný na adrese https://github.com/tisnik/message-queues-examples (stále na GitHubu :-). V případě, že nebudete chtít klonovat celý repositář (ten je ovšem – alespoň prozatím – velmi malý, dnes má doslova několik kilobajtů), můžete namísto toho použít odkazy na jednotlivé příklady, které naleznete v následující tabulce. Každý příklad se skládá minimálně ze dvou skriptů – implementace workera a skriptu pro uložení nové úlohy do fronty:
20. Odkazy na Internetu
- celery na PyPi
https://pypi.org/project/celery/ - Databáze Redis (nejenom) pro vývojáře používající Python
https://www.root.cz/clanky/databaze-redis-nejenom-pro-vyvojare-pouzivajici-python/ - Databáze Redis (nejenom) pro vývojáře používající Python (dokončení)
https://www.root.cz/clanky/databaze-redis-nejenom-pro-vyvojare-pouzivajici-python-dokonceni/ - Použití nástroje RQ (Redis Queue) pro správu úloh zpracovávaných na pozadí
https://www.root.cz/clanky/pouziti-nastroje-rq-redis-queue-pro-spravu-uloh-zpracovavanych-na-pozadi/ - Redis Queue (RQ)
https://www.fullstackpython.com/redis-queue-rq.html - Python Celery & RabbitMQ Tutorial
https://tests4geeks.com/python-celery-rabbitmq-tutorial/ - Flower: Real-time Celery web-monitor
http://docs.celeryproject.org/en/latest/userguide/monitoring.html#flower-real-time-celery-web-monitor - Asynchronous Tasks With Django and Celery
https://realpython.com/asynchronous-tasks-with-django-and-celery/ - First Steps with Celery
http://docs.celeryproject.org/en/latest/getting-started/first-steps-with-celery.html - node-celery
https://github.com/mher/node-celery - Full Stack Python: web development
https://www.fullstackpython.com/web-development.html - Introducing RQ
https://nvie.com/posts/introducing-rq/ - Asynchronous Tasks with Flask and Redis Queue
https://testdriven.io/asynchronous-tasks-with-flask-and-redis-queue - rq-dashboard
https://github.com/eoranged/rq-dashboard - Stránky projektu Redis
https://redis.io/ - Introduction to Redis
https://redis.io/topics/introduction - Try Redis
http://try.redis.io/ - Redis tutorial, April 2010 (starší, ale pěkně udělaný)
https://static.simonwillison.net/static/2010/redis-tutorial/ - Python Redis
https://redislabs.com/lp/python-redis/ - Redis: key-value databáze v paměti i na disku
https://www.zdrojak.cz/clanky/redis-key-value-databaze-v-pameti-i-na-disku/ - Praktický úvod do Redis (1): vaše distribuovaná NoSQL cache
http://www.cloudsvet.cz/?p=253 - Praktický úvod do Redis (2): transakce
http://www.cloudsvet.cz/?p=256 - Praktický úvod do Redis (3): cluster
http://www.cloudsvet.cz/?p=258 - Connection pool
https://en.wikipedia.org/wiki/Connection_pool - Instant Redis Sentinel Setup
https://github.com/ServiceStack/redis-config - How to install REDIS in LInux
https://linuxtechlab.com/how-install-redis-server-linux/ - Redis RDB Dump File Format
https://github.com/sripathikrishnan/redis-rdb-tools/wiki/Redis-RDB-Dump-File-Format - Lempel–Ziv–Welch
https://en.wikipedia.org/wiki/Lempel%E2%80%93Ziv%E2%80%93Welch - Redis Persistence
https://redis.io/topics/persistence - Redis persistence demystified
http://oldblog.antirez.com/post/redis-persistence-demystified.html - Redis reliable queues with Lua scripting
http://oldblog.antirez.com/post/250 - Ost (knihovna)
https://github.com/soveran/ost - NoSQL
https://en.wikipedia.org/wiki/NoSQL - Shard (database architecture)
https://en.wikipedia.org/wiki/Shard_%28database_architecture%29 - What is sharding and why is it important?
https://stackoverflow.com/questions/992988/what-is-sharding-and-why-is-it-important - What Is Sharding?
https://btcmanager.com/what-sharding/ - Redis clients
https://redis.io/clients - Category:Lua-scriptable software
https://en.wikipedia.org/wiki/Category:Lua-scriptable_software - Seriál Programovací jazyk Lua
https://www.root.cz/serialy/programovaci-jazyk-lua/ - Redis memory usage
http://nosql.mypopescu.com/post/1010844204/redis-memory-usage - Ukázka konfigurace Redisu pro lokální testování
https://github.com/tisnik/presentations/blob/master/redis/redis.conf - Resque
https://github.com/resque/resque - Nested transaction
https://en.wikipedia.org/wiki/Nested_transaction - Publish–subscribe pattern
https://en.wikipedia.org/wiki/Publish%E2%80%93subscribe_pattern - Messaging pattern
https://en.wikipedia.org/wiki/Messaging_pattern - Using pipelining to speedup Redis queries
https://redis.io/topics/pipelining - Pub/Sub
https://redis.io/topics/pubsub - ZeroMQ distributed messaging
http://zeromq.org/ - ZeroMQ: Modern & Fast Networking Stack
https://www.igvita.com/2010/09/03/zeromq-modern-fast-networking-stack/ - Publish/Subscribe paradigm: Why must message classes not know about their subscribers?
https://stackoverflow.com/questions/2908872/publish-subscribe-paradigm-why-must-message-classes-not-know-about-their-subscr - Python & Redis PUB/SUB
https://medium.com/@johngrant/python-redis-pub-sub-6e26b483b3f7 - Message broker
https://en.wikipedia.org/wiki/Message_broker - RESP Arrays
https://redis.io/topics/protocol#array-reply - Redis Protocol specification
https://redis.io/topics/protocol - Redis Pub/Sub: Intro Guide
https://www.redisgreen.net/blog/pubsub-intro/ - Redis Pub/Sub: Howto Guide
https://www.redisgreen.net/blog/pubsub-howto/ - Comparing Publish-Subscribe Messaging and Message Queuing
https://dzone.com/articles/comparing-publish-subscribe-messaging-and-message - Apache Kafka
https://kafka.apache.org/ - Iron
http://www.iron.io/mq - kue (založeno na Redisu, určeno pro node.js)
https://github.com/Automattic/kue - Cloud Pub/Sub
https://cloud.google.com/pubsub/ - Introduction to Redis Streams
https://redis.io/topics/streams-intro - glob (programming)
https://en.wikipedia.org/wiki/Glob_(programming) - Why and how Pricing Assistant migrated from Celery to RQ – Paris.py
https://www.slideshare.net/sylvinus/why-and-how-pricing-assistant-migrated-from-celery-to-rq-parispy-2 - Enqueueing internals
http://python-rq.org/contrib/ - queue — A synchronized queue class
https://docs.python.org/3/library/queue.html - Queues
http://queues.io/ - Windows Subsystem for Linux Documentation
https://docs.microsoft.com/en-us/windows/wsl/about - RestMQ
http://restmq.com/ - ActiveMQ
http://activemq.apache.org/ - Amazon MQ
https://aws.amazon.com/amazon-mq/ - Amazon Simple Queue Service
https://aws.amazon.com/sqs/ - Celery: Distributed Task Queue
http://www.celeryproject.org/ - Disque, an in-memory, distributed job queue
https://github.com/antirez/disque - rq-dashboard
https://github.com/eoranged/rq-dashboard - Projekt RQ na PyPi
https://pypi.org/project/rq/ - rq-dashboard 0.3.12
https://pypi.org/project/rq-dashboard/ - Job queue
https://en.wikipedia.org/wiki/Job_queue - Why we moved from Celery to RQ
https://frappe.io/blog/technology/why-we-moved-from-celery-to-rq - Running multiple workers using Celery
https://serverfault.com/questions/655387/running-multiple-workers-using-celery - celery — Distributed processing
http://docs.celeryproject.org/en/latest/reference/celery.html - Chains
https://celery.readthedocs.io/en/latest/userguide/canvas.html#chains - Routing
http://docs.celeryproject.org/en/latest/userguide/routing.html#automatic-routing - Celery Distributed Task Queue in Go
https://github.com/gocelery/gocelery/ - Python Decorators
https://wiki.python.org/moin/PythonDecorators - Periodic Tasks
http://docs.celeryproject.org/en/latest/userguide/periodic-tasks.html - celery.schedules
http://docs.celeryproject.org/en/latest/reference/celery.schedules.html#celery.schedules.crontab
























