
Obsah
1. Čipy DaVinci aneb úspěšná kombinace jader ARM a DSP s architekturou VLIW
2. Typy čipů vyvinutých v rámci série DaVinci
3. Skupiny čipů DM36×, DM38×, DM812×, DM814× a DM816×
4. Rozdíly mezi čipy ve skupině DM3×x
5. Modulární struktura čipů DaVinci
6. Modul s ARMovským jádrem a jeho paměťovým subsystémem
9. Modul s DSP jádrem a jeho paměťovým subsystémem
10. Násobičky a teoretický špičkový výpočetní výkon DSP
11. Video-Imaging Coprocessor (VICP) a Video-Imaging Subsystem (VPSS)
1. Čipy DaVinci aneb úspěšná kombinace jader ARM a DSP s architekturou VLIW
Minule jsme se seznámili s digitálními signálovými procesory řady C5000 (konkrétně se jednalo o čipy s DSP jádry TMS320C54× a TMS320C55×). Připomeňme si, že tyto relativně jednoduché čipy určené pro typické DSP aplikace, mezi než patří zpracování audio signálu atd., začaly být kombinovány s mikroprocesorovými jádry ARM. Tímto způsobem, který je dnes s úspěchem používán i mnoha dalšími firmami, vznikla série OMAP, jež se v minulosti velmi často používala v mobilních telefonech, handheldech a dalších podobných aplikacích. Později, kdy již výpočetní výkon jader TMS320C55× přestal pro některé aplikace dostačovat, se v rámci novější série OMAP 2 a OMAP 3 začaly používat výkonnější DSP jádra TMS320C64×+ (fixed point) a dokonce i TMS320C674× (kombinace fixed point + floating point):
| Série OMAP | Označení | DSP | Jádro ARM |
|---|---|---|---|
| OMAP 1 | OMAP171× | TMS320C55× | ARM926EJ-S |
| OMAP 1 | OMAP162× | TMS320C55× | ARM926EJ-S |
| OMAP 1 | OMAP5912 | TMS320C55× | ARM926EJ-S |
| OMAP 1 | OMAP161× | TMS320C55× | ARM926EJ-S |
| OMAP 1 | OMAP1510 | TMS320C55× | ARM925T |
| OMAP 1 | OMAP5910 | TMS320C55× | ARM925T |
| OMAP 2 | OMAP2431 | TMS320C64× | ARM1136 |
| OMAP 2 | OMAP2430 | TMS320C64× | ARM1136 |
| OMAP 2 | OMAP2420 | TMS320C55× | ARM1136 |
| OMAP 3 | OMAP3430 | TMS320C64×+ | Cortex-A8 + GPU |
| OMAP 3 | OMAP3530 | TMS320C64×+ | Cortex-A8 + GPU |
| OMAP 3 | OMAP3611 | TMS320C64×+ | Cortex-A8 + GPU |
| OMAP 3 | OMAP3621 | TMS320C64×+ | Cortex-A8 + GPU |
| OMAP 3 | OMAP3622 | TMS320C64×+ | Cortex-A8 + GPU |
| OMAP 4 | OMAP4430 | TMS320C64×+ (Tesla) | Cortex-A9 popř. ARMv7 + GPU |
| OMAP 4 | OMAP4460 | TMS320C64×+ (Tesla) | Cortex-A9 popř. ARMv7 + GPU |
| OMAP 4 | OMAP4470 | TMS320C64×+ (Tesla) | Cortex-A9 popř. ARMv7 + GPU |
| OMAP 5 | OMAP5430 | TMS320C64×+ (Tesla) | Cortex-A15 (dual core) + Cortex-M4 + GPU |
| OMAP 5 | OMAP5432 | TMS320C64×+ (Tesla) | Cortex-A15 (dual core) + Cortex-M4 + GPU |
| OMAP L-1× | OMAP-L137 | TMS320C674× | ARM926EJ-S |
| OMAP L-1× | OMAP-L138 | TMS320C674× | ARM926EJ-S |
Kromě této série, kterou nalezneme například i na BeagleBoardu či PandaBoardu, však společnost Texas Instruments v roce 2005 představila i novou sérii čipů pojmenovaných DaVinci. Tyto čipy jsou určeny především pro ty aplikace, v nichž se zpracovává video signál a proto je i jejich interní podoba odlišná – obsahují ARMovská jádra ARM9 či A8 a pokud je použit DSP, jedná se o jádro TMS320C64× (+) s osmi paralelně pracujícími výkonnými jednotkami a architekturou VLIW. Navíc tyto čipy prakticky vždy obsahují i další specializované subsystémy určené pro zpracování videa.
2. Typy čipů vyvinutých v rámci série DaVinci
V sérii DaVinci bylo vyvinuto poměrně velké množství různých čipů, z nichž některé byly běžně prodávány prakticky všem zákazníkům a jiné byly vyvinuty na základě konkrétních požadavků jediného zákazníka (proto je o těchto čipech dostupných méně informací). V následující tabulce jsou vypsány ty základní čipy, které jsou či byly běžně dostupné. Povšimněte si zejména toho, že název každého čipu začíná písmeny „DM“ neboli „Digital Media“. Ve skutečnosti úplné názvy těchto čipů začínají na TMS320…, toto označení se však většinou vynechává, protože je z kontextu jasné, o jaké čipy se jedná:
| Čip | Jádro ARM | Jádro DSP | OSD | VENC | HDVPSS |
|---|---|---|---|---|---|
| DM6446 | ARM9 | TMS320C64× | ✓ | ✓ | × |
| DM6437 | ARM9 | TMS320C64× | ✓ | ✓ | × |
| DM6441 | ARM9 | TMS320C64× | ✓ | ✓ | × |
| DM648 | TMS320C64× | × | × | × | |
| DM355 | ARM9 | ✓ | ✓ | × | |
| DM6467 | ARM9 | TMS320C64× | × | × | × |
| DM335 | ARM9 | × | × | × | |
| DM357 | ARM9 | × | × | × | |
| DMVA2 | ARM9 | ✓ | ✓ | × | |
| DM8107 | Cortex-A8 | × | × | ✓ | |
| DMVA3 | Cortex-A8 | × | × | ✓ |
Význam zkratek použitých v předchozí tabulce:
| Zkratka | Význam | Stručný popis |
|---|---|---|
| OSD | On-Screen Display | Modul umožňující přimíchat například menu do zpracovávaného video signálu. Podporována jsou většinou dvě samostatná okna (menu + například seznam programů atd.). |
| VENC | Video Encoder | Několik rychlých D/A převodníků použitých pro výstup v normě PAL, NTSC, S-video atd. |
| HDVPSS | HD Video Processing Subsystem | Jedna nebo dvě samostatné pipeline pro zpracování video signálu, včetně vstupního bloku (de-interlace, scale atd.) a bloku výstupního (HD video, demultiplexing, kompozitního výstupu atd.) |
3. Skupiny čipů DM36×, DM38×, DM812×, DM814× a DM816×
Následující řady čipů rodiny DM jsou nabízeny v současnosti. Povšimněte si, že čipy jsou rozděleny do pěti skupin: DM36×, DM38×, DM812×, DM814× a DM816×. V každé skupině se nachází čipy se stejným ARMovským jádrem, stejným DSP (pokud je použit) i podobnými subsystémy.
| Čip | Jádro ARM | Jádro DSP | OSD | VENC | HDVPSS |
|---|---|---|---|---|---|
| DM365 | ARM9 | ✓ | ✓ | × | |
| DM368 | ARM9 | ✓ | ✓ | × | |
| DM369 | ARM9 | ✓ | ✓ | × | |
| DM385 | Cortex-A8 | × | × | ✓ | |
| DM388 | Cortex-A8 | × | × | ✓ | |
| DM8127 | Cortex-A8 | TMS320C64×+ | × | × | ✓ |
| DM8147 | Cortex-A8 | TMS320C64×+ | × | × | ✓ |
| DM8148 | Cortex-A8 | TMS320C64×+ | × | × | ✓ |
| DM8165 | Cortex-A8 | TMS320C64×+ | × | × | ✓ |
| DM8167 | Cortex-A8 | TMS320C64×+ | × | × | ✓ |
| DM8168 | Cortex-A8 | TMS320C64×+ | × | × | ✓ |
4. Rozdíly mezi čipy ve skupině DM3×x
Čipy patřící do jedné skupiny se od sebe liší dalšími vlastnostmi, které jsou shrnuty v poslední tabulce (jedná se konkrétně o řadu DM3×x, nikoli o řadu DM81×x):
| Čip | Jádro ARM | Frekvence ARM | Video vstupy | Kodek(y) | Max.video | Filtry |
|---|---|---|---|---|---|---|
| DM365 | ARM9 | 216–300 MHz | 1×paralelní 8/16b | H.264 BP/MP/HP | 720p30 | 2G Motion |
| DM368 | ARM9 | 432 MHz | 1×paralelní 8/16b | H.264 BP/MP/HP | 1080p30 | 2G Motion |
| DM369 | ARM9 | 432 MHz | 1×paralelní 8/16b | H.264 BP/MP/HP | 1080p30 | 2G Motion |
| DM385 | Cortex-A8 | 790–1000 MHz | 1×paralelní 8/16b nebo 1×CSI-2 | H.264 BP/MP/HP | 1080p60 | 3G Motion |
| DM388 | Cortex-A8 | 790–1000 MHz | 1×paralelní 8/16b nebo 1×CSI-2 | H.264 BP/MP/HP | 1080p60 | 4G Motion |
Poznámka: CSI znamená Camera Serial Interface.
Vidíme, že z hlediska zpracování video signálu skutečně mezi jednotlivými čipy existují rozdíly, a to zejména s ohledem na maximální podporované rozlišení a obnovovací frekvencí obrazu. Novější čipy navíc podporují rozhraní CSI-2 určené pro vstup video signálu.
5. Modulární struktura čipů DaVinci
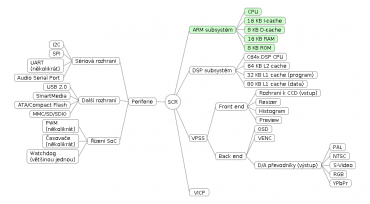
Na schématu zobrazeném pod tímto odstavcem jsem se pokusil načrtnout modulární uspořádání čipů DaVinci:

Obrázek 1: Modulární struktura čipů DaVinci.
Všechny základní moduly jsou propojeny přes SCR neboli Switched Central Resource zajišťující plynulé toky dat. Nejedná se tedy o klasickou sběrnici, o níž by jednotlivé moduly musely „bojovat“, což by ostatně odporovalo požadavku na zpracování video signálu v reálném čase. K SCR je připojen modul s mikroprocesorovým jádrem ARM a svým vlastním paměťovým subsystémem, modul s digitálním signálovým procesorem a taktéž svým vlastním paměťovým subsystémem, modul pro řízení periferních zařízení (včetně sériových sběrnic a rozhraní, PWM, časovači a watchdogem) a v neposlední řadě taktéž blok nazvaný VPSS neboli Video Processing Subsystem, který je rozdělen na front end (zpracování vstupního video signálu, změna rozlišení, deinterlace) a back end (OSD+generování výstupního video signálu). U některých čipů je navíc přítomen i VICP neboli Video-Imaging Coprocessor popř. i GPIO, tedy vstupně-výstupní piny, které je možné programově ovládat.
6. Modul s ARMovským jádrem a jeho paměťovým subsystémem
První modul, který si popíšeme, obsahuje jako svůj ústřední prvek ARMovské jádro ARM9 nebo u novějších čipů Cortex-A8 (oba typy jader obsahují i MMU). Kromě toho na tomto modulu nalezneme i instrukční cache (I-Cache) o typické kapacitě 16 KB a datovou cache (D-Cache) o kapacitě 8 KB. U některých modernějších čipů DaVinci jsou tyto kapacity vyšší. Dále se na tomto modulu nachází blok RAM o velikosti 16 KB (rozdělená na dva bloky o poloviční velikosti pro souběžný přístup k instrukcím i datům) a ROM/Flash o kapacitě 8 KB, na níž se nachází bootloader. Samozřejmě se nejedná o jedinou paměť, ke které má ARMovské jádro přístup, protože přes SCR jde přistupovat k DRAM (většinou DDR2) popř. k externí paměti Flash.
Obrázek 2: Modul s ARMovským jádrem a jeho paměťovým subsystémem.
7. ARM9
Všechny původní čipy DaVinci, včetně prvního čipu DM6446 (viz druhou kapitolu), byly (a některé dodnes jsou) vybaveny mikroprocesorovým jádrem ze skupiny ARM9. Do této skupiny řadíme větší množství mikroprocesorových jader, především pak jádra ARM9TDMI, ARM940T, ARM9E-S, ARM966E-S, ARM920T, ARM922T, ARM946E-S, ARM9EJ-S, ARM926EJ-S, ARM968E-S a ARM996HS. V čipech DaVinci se většinou používá jádro ARM926EJ-S podporující jak původní 32bitovou RISCovou instrukční sadu, tak i 16bitovou sadu Thumb, kterou lze použít při požadavku na strojový kód s větší hustotou a většinou nepatrně menším výkonem. Kromě toho tato jádra obsahují i implementaci technologie Jazelle, tedy podporu pro bajtkód virtuálního stroje Javy (tyto čipy jsou postaveny na mikroarchitektuře ARMv5TEJ).
Jádra ze skupiny ARM9 jsou sice postavena na starších, ovšem velmi úspěšných jádrech ARM7 (viz například text o čipech OMAP), ovšem interní struktura byla v mnoha ohledech vylepšena. Zásadní byl přechod na modifikovanou Harvardskou architekturu umožňující mj. rychlejší provádění instrukcí typu Load & Store (čtení a zápisy do datové paměti, resp. do datové cache neblokovaly čtení instrukčního kódu následujících instrukcí). Taktéž se změnil počet řezů pipeline ze tří na pět, což mimochodem znamenalo, že se při použití stejné výrobní technologie a hodinové frekvence mohl počet zpracovávaných instrukcí zvýšit prakticky na dvojnásobek (instrukce ovšem na druhou stranu měly delší latenci). Díky těmto úpravám se některé instrukce urychlily, takže původní strojový kód vygenerovaný pro jádra ARM7 byl po přenosu na jádra ARM9 až o 30% rychlejší. Změny se projevily i na menší spotřebě (přepočtené na počet provedených instrukcí).
8. Cortex-A8
Novější čipy DaVinci již namísto jádra ARM926EJ-S používají některé jádro Cortex-A8. Připomeňme si, že všechna nová ARMovská jádra jsou dělena do třech skupin začínající názvem Cortex následovaným jedním z těchto znaků: Application, Realtime, Microcontroller (název první skupiny pravděpodobně vznikl ze snahy o její „napasování“ na zkratku ARM):
| # | Architektura | Adresová/datová sběrnice | Jádro | Poznámka/profil (u Cortex) |
|---|---|---|---|---|
| 1 | ARMv6-M | 32 bitů | Cortex-M0, Cortex-M0+, Cortex-M1 | mikrořadiče (M v názvu) |
| 2 | ARMv7-M | 32 bitů | Cortex-M3 | mikrořadiče (poznáme podle M v názvu) |
| 3 | ARMv7E-M | 32 bitů | Cortex-M4, Cortex-M7 | mikrořadiče (M v názvu) |
| 4 | ARMv7-R | 32 bitů | Cortex-R4, Cortex-R5, Cortex-R7 | realtime aplikace (R v názvu) |
| 5 | ARMv7-A | 32 bitů | Cortex-A5, Cortex-A7, Cortex-A8, Cortex-A9, Cortex-A12, Cortex-A15, Cortex-A17 | smartphony atd. |
| 6 | ARMv8-A | 32/64 bitů | Cortex-A35, Cortex-A53, A57, A72 a A73 | smartphony atd. |
Oproti ARM9 došlo u jader Cortex-A8 k mnoha interním úpravám i k rozšíření instrukční sady. Mezi interní úpravy a vylepšení patří použití pipeline se třinácti řezy pro celočíselné operace a pipeline s deseti řezy pro SIMD operace (NEON). Taktéž je použita superskalární architektura umožňující paralelní spuštění dvou instrukcí (díky pipeline a superskalární architektuře tedy Cortex-A8 v jeden okamžik zpracovává až dvě desítky instrukcí v různém stavu rozpracování). Vzhledem k tomu, že pipeline je velmi dlouhá, má velký vliv na celkový výpočetní výkon prediktor skoků, který byl taktéž vylepšen – udává se, že přesnost jeho odhadu je větší než 95 %.
Instrukční sada Cortex-A8 obsahuje jak již zmíněné SIMD instrukce NEON, tak i VFPv3, tedy instrukce matematického koprocesoru (viz též Mikroprocesory ARM a architektura VFP (Vector Floating Poin). Kromě toho je podporován i instrukční formát Thumb-2 s instrukcemi proměnné délky (16 bitů či 32 bitů) a především pak prefixem IT, díky němuž je možné do velké míry omezit počet podmíněných skoků.
9. Modul s DSP jádrem a jeho paměťovým subsystémem
Modul, který obsahuje digitální signálový procesor řady TMS320C64× či TMS320C64×+, se částečně podobá modulu s ARMovským jádrem. I zde kromě vlastního CPU nalezneme cache, zde je ovšem rozdělena na dvě úrovně. Cache první úrovně (L1-cache) obsahuje dva bloky – blok pro instrukce s kapacitou až 32 KB a blok pro data s kapacitou 80 KB. Cache druhé úrovně (L2-cache) je unifikovaná a její kapacita je typicky 64 KB. Povšimněte si, že v tomto modulu nenalezneme ROM, protože se o inicializaci DSP postará ARMovské jádro se svým vlastním bootloaderem (pokud se tyto čipy používají například v Linuxu, běží Linux na ARMu a DSP je ovládáno přes knihovnu).
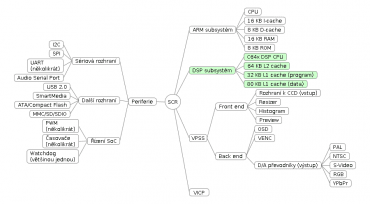
Obrázek 3: Modul s DSP jádrem a jeho paměťovým subsystémem.
10. Násobičky a teoretický špičkový výpočetní výkon DSP
Samotný digitální signálový procesor TMS320C64× a TMS320C64×+ vznikl z řady TMS320C62×, kterou jsme si již popsali. Je taktéž založen na architektuře VLIW s instrukčními slovy, u nichž lze takzvanými p-bity určit ty instrukce, které se budou provádět paralelně. TMS320C64× obsahuje osm nezávisle pracujících jednotek a jeho nejdůležitější částí jsou čtyři 16bitové násobičky spojené se sčítačkami (takže mohou provádět operace MAC – Multiply Accumulate). Při paralelní práci dokážou tyto jednotky provést 3240 milionů MAC operací za sekundu při použití hodinové frekvence 810 MHz (v každém cyklu dokáže násobička dokončit jeden výpočet). Každou 16bitovou násobičku lze v případě potřeby použít ve funkci dvou osmibitových násobiček. V tomto případě dosahuje maximální počet operací u optimálně napsaných algoritmů 6480 MAC za sekundu (opět při frekvenci 810 MHz).
Poznámka: u mnoha algoritmů pro zpracování videa se setkáme právě s použitím osmibitových vzorků, takže se rozdělení každé 16bitové násobičky na dvě násobičky osmibitové využívá.
11. Video-Imaging Coprocessor (VICP) a Video-Imaging Subsystem (VPSS)
Čipy DaVinci se od běžných kombinací ARM CPU+DSP odlišují především tím, že obsahují blok VICP neboli Video-Imaging Coprocessor a VPSS neboli Video-Imaging Subsystem (někdyse před tuto zkratku přidává HD odkazující na možnost zpracování videa 1080p). VPSS je rozdělen na dvě části nazvané VPFE a VPBE, kde první zkratka znamená Video Processing Front-End a zkratka druhá Video Processing Back-End (IT firmy milují třípísmenné a čtyřpísmenné zkratky). Důvod, proč je VICP rozdělený na dvě části, je pochopitelný, protože celé zpracování videa má typicky tři části:
- Čtení video signálu, například přímo z CCD či CMOS prvků. Během čtení se většinou provádí i transformace barev, například aplikace Bayerova filtru. Možné jsou i další operace, typicky změna rozlišení, deinterlace atd. Tyto operace se provádí ve front-endu.
- Zpracování videa. Pro tyto účely mají vývojáři k dispozici výkonné DSP a univerzální ARM CPU. V případě kodeků lze využít VICP, takže není nutné tyto náročné algoritmy implementovat softwarově (MPEG-4, H.264 atd.)
- Výstup video signálu popř. automatické přidání dalších informací do video signálu (menu, titulky, …). Tyto operace se provádí v back-endu.

Obrázek 4: Video-Imaging Coprocessor a Video-Imaging Subsystem rozdělený na front end a back end.

12. Front-end VICP (VPFE)
Modul VPFE se v první řadě stará o čtení video signálu z CCD či CMOS čipů, což kromě generování příslušných řídicích signálů většinou znamená i transformaci barev, aplikaci již zmíněného Bayerova filtru, změnu rozlišení apod. Tento modul navíc dokáže v reálném čase vypočítat histogram, provést vyvážení bílé barvy (white balance), vygenerovat náhled na obrázek ve formátu vhodném pro zobrazení na LCD apod. Výsledkem práce tohoto modulu je většinou kontinuální video signál ve zvoleném barvovém prostoru a formátu (RGB, YUV…), který může být zpracován dalšími moduly, uložen na externí médium, poslán přes EMAC (Ethernet Media Access Controller) na zvolené zařízení atd.
13. Back-end VICP (VPBE)
Jakmile je video signál zpracován, je nutné ho nějakým způsobem zobrazit resp. přesněji řečeno poslat na zvolené zobrazovací zařízení (monitor…). K tomuto účelu se používá modul VPBE vybavený čtveřicí rychlých D/A převodníků (frekvence vzorků vstupujících do těchto převodníků většinou překračuje 54 MHz; ostatně připomeňme si, že některé čipy DaVinci dokážou pracovat s videem 1080p60). Vstupy D/A převodníků jsou konfigurovatelné, takže je lze využít pro generování PAL či NTSC signálu (včetně synců), S-Videa, kompozitního videa, analogového RGB atd. Kromě toho tento modul obsahuje i digitální výstup s 24bitovým RGB signálem, BT.656 atd. (možnosti jednotlivých čipů DaVinci se v tomto ohledu mohou lišit). Navíc VPBE umožňuje do video signálu přimíchat další dvě nezávislá „okna“, v nichž může být zobrazeno menu, titulky, další informace (u kamery různé ikonky, zaměřovací kříž, histogram …).
14. Odkazy na Internetu
- DaVinci processor family
http://www.ti.com/general/docs/datasheetdiagram.tsp?genericPartNumber=TMS320DM365&diagramId=64193 - Texas Instruments DaVinci
https://en.wikipedia.org/wiki/Texas_Instruments_DaVinci - TMS320DM6446 (DaVinci)
http://www.ti.com/product/tms320dm6446 - Digital Media Video Processors (TI)
http://www.ti.com/lsds/ti/processors/dsp/media_processors/davinci/products.page# - TI Wiki
http://processors.wiki.ti.com/index.php/Main_Page - C5000 ultra-low-power DSP
http://www.ti.com/lsds/ti/processors/dsp/c5000_dsp/overview.page - OMAP (Wikipedia)
https://en.wikipedia.org/wiki/OMAP - OMAP – TI Wiki
http://processors.wiki.ti.com/index.php/OMAP - Why OMAP can't compete in smartphones
http://www.eetimes.com/author.asp?section_id=40&doc_id=1286602 - Applications Processors – The Heart of the Smartphone
http://www.engineering.com/ElectronicsDesign/ElectronicsDesignArticles/ArticleID/5791/Applications-Processors-The-Heart-of-the-Smartphone.aspx - TI cuts 1,700 jobs in OMAP shift
http://www.eetimes.com/document.asp?doc_id=1262782 - VLIW: Very Long Instruction Word: Texas Instruments TMS320C6×
http://www.ecs.umass.edu/ece/koren/architecture/VLIW/2/ti1.html - An Introduction To Very-Long Instruction Word (VLIW) Computer Architecture
Philips Semiconductors - VLIW Architectures for DSP: A Two-Part Lecture (PDF, slajdy)
http://www.bdti.com/MyBDTI/pubs/vliw_icspat99.pdf - Very long instruction word (Wikipedia)
https://en.wikipedia.org/wiki/Very_long_instruction_word - A VLIW Approach to Architecture, Compilers and Tools
http://www.vliw.org/book/ - VEX Toolchain (VEX = VLIW Example)
http://www.hpl.hp.com/downloads/vex/ - Elbrus (computer)
https://en.wikipedia.org/wiki/Elbrus_%28computer%29 - Super Harvard Architecture Single-Chip Computer
https://en.wikipedia.org/wiki/Super_Harvard_Architecture_Single-Chip_Computer - Digital Signal Processors (stránky TI)
http://www.ti.com/lsds/ti/processors/dsp/overview.page - C674× Low Power DSP (stránky TI)
http://www.ti.com/lsds/ti/processors/dsp/c6000_dsp/c674×/overview.page - TMS320C30 (stránky TI)
http://www.ti.com/product/tms320c30 - TMS320C6722B
http://www.ti.com/product/tms320c6722b/description - Introduction to DSP
http://www.ti.com/lit/wp/spry281/spry281.pdf - The Evolution of TMS (Family of DSPs)
http://www.slideshare.net/moto_modx/theevo1 - Datasheet k TMS32010
http://www.datasheetarchive.com/dlmain/49326c32a52050140abffe6f0ac4894aa09889/M/TMS32010 - 1979: Single Chip Digital Signal Processor Introduced
http://www.computerhistory.org/siliconengine/single-chip-digital-signal-processor-introduced/ - The TMS32010. The DSP chip that changed the destiny of a semiconductor giant
http://www.tihaa.org/historian/TMS32010–12.pdf - Texas Instruments TMS320 (Wikipedia)
https://en.wikipedia.org/wiki/Texas_Instruments_TMS320 - Great Microprocessors of the Past and Present: Part IX: Signetics 8×300, Early cambrian DSP ancestor (1978):
http://www.cpushack.com/CPU/cpu2.html#Sec2Part9 - Great Microprocessors of the Past and Present (V 13.4.0)
http://jbayko.sasktelwebsite.net/cpu.html - Introduction to DSP – DSP processors:
http://www.bores.com/courses/intro/chips/index.htm - The Scientist and Engineer's Guide to Digital Signal Processing:
http://www.dspguide.com/ - Digital signal processor (Wikipedia EN)
http://en.wikipedia.org/wiki/Digital_signal_processor - Digitální signálový procesor (Wikipedia CZ)
http://cs.wikipedia.org/wiki/Digitální_signálový_procesor - Digital Signal Processing FAQs
http://dspguru.com/dsp/faqs - Reprezentace numerických hodnot ve formátech FX a FP
http://www.root.cz/clanky/fixed-point-arithmetic/ - IEEE 754 a její příbuzenstvo: FP formáty
http://www.root.cz/clanky/norma-ieee-754-a-pribuzni-formaty-plovouci-radove-tecky/ - Čtyři základní způsoby uložení čísel pomocí FX formátů
http://www.root.cz/clanky/binarni-reprezentace-numerickych-hodnot-v-fx-formatu/ - Základní aritmetické operace prováděné v FX formátu
http://www.root.cz/clanky/zakladni-aritmeticke-operace-provadene-ve-formatu-fx/ - Aritmetické operace s hodnotami uloženými ve formátu FP
http://www.root.cz/clanky/aritmeticke-operace-s-hodnotami-ve-formatu-plovouci-radove-carky/ - FIR Filter FAQ
http://dspguru.com/dsp/faqs/fir - Finite impulse response (Wikipedia)
http://en.wikipedia.org/wiki/Finite_impulse_response - DSPRelated
http://www.dsprelated.com/ - Addressing mode (Wikipedia)
https://en.wikipedia.org/wiki/Addressing_mode - Orthogonal instruction set
https://en.wikipedia.org/wiki/Orthogonal_instruction_set - TI 16-bit and 32-bit microcontrollers
http://www.ti.com/lsds/ti/microcontrollers16-bit32-bit/overview.page - TMS 32010 Assembly Language Programmer's Guide (kniha na Amazonu)
https://www.amazon.com/32010-Assembly-Language-Programmers-Guide/dp/0904047423 - COSC2425: PC Architecture and Machine Language, PC Assembly Language
http://www.austincc.edu/rblack/courses/COSC2425/index.html

