
Obsah
1. Mikroprocesory a mikrořadiče ARM s podporou DSP operací
3. Použití dvojice samostatně pracujících čipů CPU+DSP či MCU+DSP
4. Jádro MCU/CPU kombinované na jednom integrovaném obvodu s DSP
5. Sdílení pamětí mezi CPU/MCU a DSP, společný řadič a instrukční sada
7. Modulární struktura čipů DaVinci
10. Výhody a nevýhody předchozích řešení
11. DSP integrovaný přímo do jádra ARM?
13. Cortex-M4, Cortex-M33 a Cortex-M7
14. Formáty zpracovávaných dat
15. „DSP násobička“ u jader Cortex-M3/M33/M7
16. Aritmetické operace se saturací
1. Mikroprocesory a mikrořadiče ARM s podporou DSP operací
V současnosti se v těch aplikacích, v nichž je požadován vysoký výpočetní výkon, používá několik typů 32bitových mikrořadičů. Jedná se například o mikrořadiče s architekturou PowerPC, SuperH, PIC32, AVR32, TriCore či čipy s jádrem MIPS. V tomto seznamu však nesmí chybět dnes velmi populární mikrořadiče ARM Cortex-M, konkrétně řady Cortex-M0, Cortex-M0+, Cortex-M3, Cortex-M4, Cortex-M7 a nověji též Cortex-M23 a Cortex-M33 (poslední dva typy jsou však staré jen zhruba půl roku, takže se nestačily rozšířit do té míry jako jejich starší kolegové).

Obrázek 1: Řetězec zpracování analogového signálu pomocí DSP. Toto schéma je poněkud zjednodušené, protože neobsahuje například obvod typu Sample and Hold (S&H) před A/D převodníkem ani rekonstrukční filtr umístěný za D/A převodníkem.
Jednou z velkých předností řady ARM Cortex-M, ale i předchozích procesorů a řadičů s jádry ARMv7, je fakt, že si firmy mohou zakoupit licenci na použití mikrořadičového jádra, které následně mohou použít ve svých vlastních čipech, ať již samostatně (například čipy STM32) či v kombinaci s digitálním signálovým procesorem, což je dnes poměrně populární volba. Proč se vlastně kombinuje ARMovské jádro s DSP? Pokud je zapotřebí v nějaké aplikaci zpracovávat signály (SDR, všudypřítomné video a audio, Wi-Fi, v budoucnu pravděpodobně Li-Fi atd.), mají konstruktéři k dispozici několik možností, jak DSP použít.
2. DSP ve funkci mikrořadiče
Digitální signálový procesor je použit ve funkci jediného řídicího prvku celé aplikace. To znamená, že kromě DSP operací (zpracování signálů) musí tento čip reagovat na přerušení, řídit připojená zařízení (nebo z nich jen číst data), většinou musí být vybaven watchdogem atd. Samozřejmě to znamená, že na čipu s jádrem DSP jsou umístěny i další moduly, typicky paralelní porty, sériové porty a sběrnice (UART, SPI, I2C), A/D a D/A převodníky či modul pro PWM. Z tohoto důvodu začaly být DSP vybavovány instrukcemi, které jsou typické pro mikrořadiče (Booleovský procesor). Z hlediska architektury čipů je toto řešení problematické, zejména ve chvíli, kdy je použita architektura VLIW, která je pro mnohé DSP typická. Toto řešení ovšem není ideální ani z dalších důvodů, protože programování DSP (opět typicky postaveného na architektuře VLIW) bývá složitější, než je tomu u mikrořadičů, které jsou mnohdy z hlediska programování, ladění atd. doslova „vymazlené“. Ostatně už jen fakt, že mnohé DSP nedokážou pracovat s jednotlivými bajty a tudíž je šířka typu char 16bitů či dokonce 24bitů, dokáže způsobit mnoho starostí.
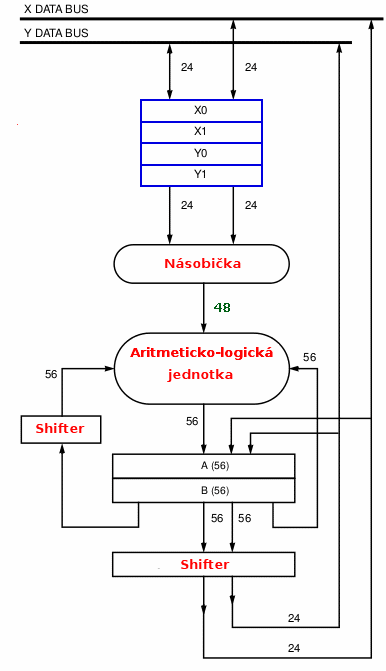
Obrázek 2: Schéma jádra digitálního signálového procesoru Motorola 56000. Čtveřice pracovních registrů je zobrazena v horní části a je obarvena modře. Povšimněte si, jak jsou registry propojeny se sběrnicemi (obousměrně) i s násobičkou (jednosměrně). Čísla značí bitovou šířku dat. Tato specializace DSP na zpracování signálu je v rozporu s použitím těchto čipů pro řízení (tam zase excelují interně zcela odlišné mikrořadiče).
3. Použití dvojice samostatně pracujících čipů CPU+DSP či MCU+DSP
V implementovaném zařízení může být alternativně použita dvojice samostatných čipů CPU+DSP, popř. častěji MCU+DSP. Tímto způsobem bývaly často provozovány například první digitální signálové procesory ze série TMS32010 společnosti Texas Instruments. Nevýhodou je nutnost komunikace těchto dvou čipů přes externí sběrnici, složitější organizace pamětí (RAM, Flash), samozřejmě vyšší cena celého zařízení a v neposlední řadě i vyšší poruchovost, která roste (a to nelineárně) s počtem použitých integrovaných obvodů. V oblasti čipů firmy Texas Instruments se nabízí kombinace MSP430+TMS320×xx, což je téma podrobně popsané v článku Interfacing the MSP430 with a DSP Application. Dnes se již toto řešení prakticky vůbec nepoužívá (alespoň u nově navrhovaných zařízení), protože jsou k dispozici jednočipové varianty zmíněné v dalších kapitolách.
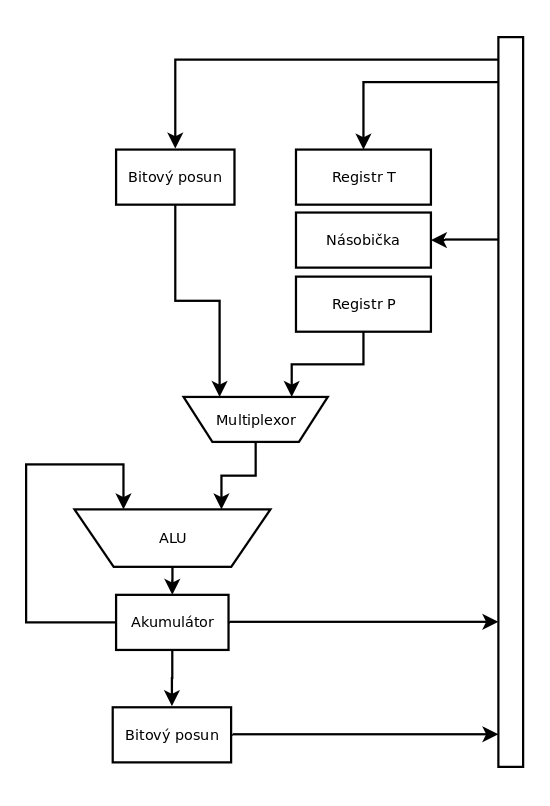
Obrázek 3: Interní struktura nejdůležitější části digitálního signálového procesoru TMS320, v níž se provádí všechny výpočty.
4. Jádro MCU/CPU kombinované na jednom integrovaném obvodu s DSP
Při použití tohoto řešení je sice dvojice CPU+DSP či MCU+DSP umístěna na jednom čipu, ale ve skutečnosti se jedná o dva samostatně pracující moduly, které spolu komunikují po interní sběrnici. Toto řešení sice může vypadat komplikovaně, ale ve skutečnosti nemusí být pro některé aplikace špatné, protože umožňuje, aby každé procesové jádro pracovalo paralelně a do značné míry nezávisle na jádru druhém, což je kritické zejména pro DSP postavené na architektuře VLIW (to mj. znamená i většinu sérií DSP firmy Texas Instruments). Typicky se při použití tohoto řešení programuje jen CPU/MCU, zatímco pro zpracování signálů se volají již odladěné a optimalizované knihovny dodávané výrobcem DSP nebo nějakou třetí stranou. Příklady použití jsou uvedeny dále – jsou jimi architektury DaVinci i OMAP, ale samozřejmě nesmíme zapomenout ani na architekturu TriCore (Infineon) atd.
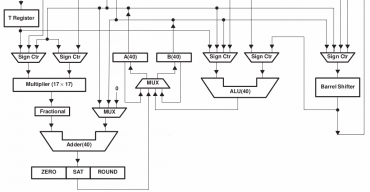
Obrázek 4: Zjednodušené schéma interní struktury čipu TMS320C54×. V horní části se nachází systém interních datových a adresových sběrnic, který byl pro zjednodušení vynechán; zobrazeny jsou jen výkonné jednotky a způsob jejich propojení.
Zdroj: TMS320C54×, TMS320LC54×, TMS320VC54× FIXED-POINT DIGITAL SIGNAL PROCESSORS, Texas Instrumens.
5. Sdílení pamětí mezi CPU/MCU a DSP, společný řadič a instrukční sada
Integrace CPU+DSP nebo MCU+DSP může jít ještě dále, protože oba procesory spolu mohou sdílet i paměti. Zde již záleží na míře integrace, tj. zda bude DSP řízen vlastní instrukční sadou a bude tedy relativně stále samostatně pracující, či zda se již bude jednat o sadu jedinou, v níž se bude instrukce mezi jednotlivé procesory rozdělovat v instrukční pipeline či ve fázi „decode“.
Dalším (logickým) krokem je přidání DSP násobičky popř. dalších důležitých modulů (speciální adresování operandů, ALU se saturací výsledků, …) přímo do CPU/MCU. Toto řešení sice při zachování stejné taktovací frekvence nedosahuje takového výpočetního výkonu, jakého může dosahovat specializovaný DSP (ideálně s VLIW), ale pro mnoho aplikací a nyní i pro mnoho výrobců čipů se jedná o populární volbu, zejména ve chvíli, kdy toto „DSP Extension“ začaly podporovat některé čipy Cortex-M a taktéž Cortex-R (těmito čipy jsme se v tomto seriálu prozatím nezabývali). Největší předností takto pojaté integrace je jednotná instrukční sada, jediná množina vývojových a ladicích nástrojů atd.

Obrázek 4: Integrace DSP a jádra ARM. Povšimněte si, že každý z čipů má samostatnou L1 cache, ovšem hlavní paměť je sdílená přes interní sběrnici SCR.
Zdroj: stránky společnosti Texas Instruments.
6. Architektura DaVinci
V roce 2005 byly společností Texas Instruments představeny čipy DaVinci určené především pro zpracování videa a použitelné v různých aplikacích, v nichž se používají kamery a je nutné zpracovávat (popř. rozpoznávat) obrazy jimi získávané. První čipy DaVinci kombinovaly na jednom čipu jádro ARM9 a digitální signálový procesor řady C64× (přesněji TMS320C64×). Jednalo se o jednu z prvních úspěšných kombinací relativně výkonného procesorového jádra s digitálním signálovým procesorem a s dalšími moduly specializovanými na zpracování videa. Některé pozdější čipy DaVinci kombinaci CPU+DSP opustily, protože nemají DSP a další naopak neobsahují jádro ARM. Nicméně i tyto čipy stále patří do stejné řady, a to díky tomu, že obsahují další koprocesory a moduly používané při zpracování a zobrazování videa, zejména VENC (Video Encoder), VICP (Video Imaging Coprocessor), OSD (On-Screen Display) atd.
V tabulce zobrazené pod tímto odstavcem je vypsána většina dříve oficiálně prodávaných čipů DaVinci (další čipy jsou pravděpodobně vyráběny jen pro jednoho odběratele):
| Čip | Jádro ARM | Jádro DSP | OSD | VENC | HDVPSS |
|---|---|---|---|---|---|
| DM6446 | ARM9 | TMS320C64× | ✓ | ✓ | × |
| DM6437 | ARM9 | TMS320C64× | ✓ | ✓ | × |
| DM6441 | ARM9 | TMS320C64× | ✓ | ✓ | × |
| DM648 | TMS320C64× | × | × | × | |
| DM355 | ARM9 | ✓ | ✓ | × | |
| DM6467 | ARM9 | TMS320C64× | × | × | × |
| DM335 | ARM9 | × | × | × | |
| DM357 | ARM9 | × | × | × | |
| DMVA2 | ARM9 | ✓ | ✓ | × | |
| DM8107 | Cortex-A8 | × | × | ✓ | |
| DMVA3 | Cortex-A8 | × | × | ✓ |
Následující řady čipů rodiny DM jsou nabízeny v současnosti. Povšimněte si, že čipy jsou rozděleny do pěti skupin: DM36×, DM38×, DM812×, DM814× a DM816×. V každé skupině se nachází čipy se stejným ARMovským jádrem, stejným DSP (pokud je použit) i podobnými subsystémy.
| Čip | Jádro ARM | Jádro DSP | OSD | VENC | HDVPSS |
|---|---|---|---|---|---|
| DM365 | ARM9 | ✓ | ✓ | × | |
| DM368 | ARM9 | ✓ | ✓ | × | |
| DM369 | ARM9 | ✓ | ✓ | × | |
| DM385 | Cortex-A8 | × | × | ✓ | |
| DM388 | Cortex-A8 | × | × | ✓ | |
| DM8127 | Cortex-A8 | TMS320C64×+ | × | × | ✓ |
| DM8147 | Cortex-A8 | TMS320C64×+ | × | × | ✓ |
| DM8148 | Cortex-A8 | TMS320C64×+ | × | × | ✓ |
| DM8165 | Cortex-A8 | TMS320C64×+ | × | × | ✓ |
| DM8167 | Cortex-A8 | TMS320C64×+ | × | × | ✓ |
| DM8168 | Cortex-A8 | TMS320C64×+ | × | × | ✓ |
Poznámka: DM na začátku jména každého čipu znamená zkratku Digital Media.
7. Modulární struktura čipů DaVinci
Na schématu zobrazeném pod tímto odstavcem jsem se pokusil načrtnout modulární uspořádání čipů DaVinci:

Obrázek 5: Modulární struktura čipů DaVinci.
Všechny základní moduly jsou propojeny přes SCR neboli Switched Central Resource zajišťující plynulé toky dat. Nejedná se tedy o klasickou sběrnici, o níž by jednotlivé moduly musely „bojovat“, což by ostatně odporovalo požadavku na zpracování video signálu v reálném čase. K SCR je připojen modul s mikroprocesorovým jádrem ARM a svým vlastním paměťovým subsystémem, modul s digitálním signálovým procesorem a taktéž svým vlastním paměťovým subsystémem, modul pro řízení periferních zařízení (včetně sériových sběrnic a rozhraní, PWM, časovači a watchdogem) a v neposlední řadě taktéž blok nazvaný VPSS neboli Video Processing Subsystem, který je rozdělen na front end (zpracování vstupního video signálu, změna rozlišení, deinterlace) a back end (OSD+generování výstupního video signálu). U některých čipů je navíc přítomen i VICP neboli Video-Imaging Coprocessor, popř. i GPIO, tedy vstupně-výstupní piny, které je možné programově ovládat.
8. Architektura OMAP
Architektura OMAP je založena na kombinaci výkonných digitálních signálových procesorů řady TMS320C55×, TMC320C64× a TMS320C64×+ s jádry ARM. V rámci této série jsou vyráběny čipy určené především pro mobilní aplikace: od sluchátek s Bluetooth přes Google Glass k tabletům. Většina čipů OMAP obsahuje kombinaci digitálního signálového procesoru s jádrem ARM, ovšem od OMAP 3 jsou k této dvojici modulů přidány i GPU (buď jeden nebo dokonce více GPU). Nejvýkonnější jsou čipy ze série OMAP 5 představené v roce 2013, které kromě výkonného DSP TMS320C64×+ (Tesla) obsahují i dvoujádrový Cortex-A15, další ARM jádro Cortex-M, grafický akcelerátor a navíc ještě další specializovaný modul určený pro operace typu BitBlt, tedy pro rychlé vykreslování, přesun a zpracování rastrových obrázků:
| Série OMAP | Označení | DSP | Jádro ARM |
|---|---|---|---|
| OMAP 1 | OMAP171× | TMS320C55× | ARM926EJ-S |
| OMAP 1 | OMAP162× | TMS320C55× | ARM926EJ-S |
| OMAP 1 | OMAP5912 | TMS320C55× | ARM926EJ-S |
| OMAP 1 | OMAP161× | TMS320C55× | ARM926EJ-S |
| OMAP 1 | OMAP1510 | TMS320C55× | ARM925T |
| OMAP 1 | OMAP5910 | TMS320C55× | ARM925T |
| OMAP 2 | OMAP2431 | TMS320C64× | ARM1136 |
| OMAP 2 | OMAP2430 | TMS320C64× | ARM1136 |
| OMAP 2 | OMAP2420 | TMS320C55× | ARM1136 |
| OMAP 3 | OMAP3430 | TMS320C64×+ | Cortex-A8 + GPU |
| OMAP 3 | OMAP3530 | TMS320C64×+ | Cortex-A8 + GPU |
| OMAP 3 | OMAP3611 | TMS320C64×+ | Cortex-A8 + GPU |
| OMAP 3 | OMAP3621 | TMS320C64×+ | Cortex-A8 + GPU |
| OMAP 3 | OMAP3622 | TMS320C64×+ | Cortex-A8 + GPU |
| OMAP 4 | OMAP4430 | TMS320C64×+ (Tesla) | Cortex-A9 popř. ARMv7 + GPU |
| OMAP 4 | OMAP4460 | TMS320C64×+ (Tesla) | Cortex-A9 popř. ARMv7 + GPU |
| OMAP 4 | OMAP4470 | TMS320C64×+ (Tesla) | Cortex-A9 popř. ARMv7 + GPU |
| OMAP 5 | OMAP5430 | TMS320C64×+ (Tesla) | Cortex-A15 (dual core) + Cortex-M4 + GPU |
| OMAP 5 | OMAP5432 | TMS320C64×+ (Tesla) | Cortex-A15 (dual core) + Cortex-M4 + GPU |
9. C6-Integra
Další kombinace digitálního signálového procesoru a jádra ARM představují čipy C6-Integra určené pro zpracování signálů v reálném čase, přičemž podle možností DSP je možné zpracovávat jak data uložená ve formátu s pevnou řádovou čárkou, tak i data s čárkou plovoucí. Technicky tyto čipy spadají do kategorie OMAP (OMAP-L):
| Označení | DSP | Jádro ARM |
|---|---|---|
| OMAP-L133 | TMS320C674× | ARM926EJ-S |
| OMAP-L137 | TMS320C674× | ARM926EJ-S |
| OMAP-L138 | TMS320C674× | ARM926EJ-S |
| C6A816× | TMS320C674× | Cortex-A8 |
10. Výhody a nevýhody předchozích řešení
Tím, že v předchozích čipech pracuje DSP do značné míry nezávisle na ARMovském jádru (někdy má dokonce i jinou hodinovou frekvenci), je umožněno optimální využití všech možností, které digitální signálový procesor nabízí, tj. paralelní zpracování operandů, práce s akumulátory o větší bitové šířce, než jakou bude mít výsledný operand (nedochází ke ztrátě informace při výpočtu mezivýsledků), použití Q-formátu (pevná řádová čárka), použití speciální adresovacích režimů (FFT, číslicové filtry) a v neposlední řadě mohou programátoři využít již hotové knihovny, které jsou optimalizované a otestované (překlad pro DSP je stále ještě problematický). Je pravděpodobné, že v mnoha aplikacích je DSP řízen jen s využitím převzatých knihoven. Ovšem to je současně i jedna z největších nevýhod tohoto řešení, protože pokud je zapotřebí použít vlastní DSP algoritmy, musí se programátor zabývat programování dvou zcela odlišných jader, způsobům komunikace mezi těmito jádry atd.
11. DSP integrovaný přímo do jádra ARM?
Alternativou pro některé aplikace (řekněme si rovnou, že pro aplikace s menšími výpočetními nároky) může být jádro ARM implementující DSP operace. Teorie tohoto řešení je jednoduchá – mějme klasické ARMovské jádro, které má nepatrně upravenou ALU umožňující výpočty se saturací a které je vybaveno rychlou násobičkou (dokončení výpočtu v každém taktu). Pokud rozšíříme instrukční sadu o nové „DSP operace“, dostaneme čip, který je hybridem mezi MCU/CPU a DSP, navíc bude možné využít již stávající nástroje (překladače, debuggery, …), knihovny atd. Na druhou stranu však zdaleka nebudou k dispozici všechny vlastnosti zmíněné v předchozí kapitole – týká se to adresovacích režimů, Q-formátu, akumulátorů atd. Taktéž můžeme zapomenout na použití VLIW a tím pádem paralelizace na úrovni instrukční sady. DSP rozšíření je v oblasti ARM relativně nové a nalezneme ho například u čipů Cortex-M4, Cortex-M7, Cortex-M33 a řady Cortex-R.
12. Architektura Cortex-M
Mikrořadičová jádra Cortex-M ve skutečnosti tvoří poměrně rozsáhlou skupinu s rozdílnými vlastnostmi jednotlivých modelů. Menší jádra používají starší, ale stále oblíbenou architekturu ARMv6-M, zatímco ta nejvýkonnější jádra přešla na novější architekturu ARMv7E-M. Na pomezí pak stojí jádra Cortex-M3 s architekturou ARMv7-M, naopak Cortex-M33 má architekturu ARMv8-M:
| # | Jádro (řada) | Architektura ARM | Architektura CPU/MCU |
|---|---|---|---|
| 1 | Cortex-M0 | ARMv6-M | Von Neumannova |
| 2 | Cortex-M0+ | ARMv6-M | Von Neumannova |
| 3 | Cortex-M1 | ARMv6-M | Von Neumannova |
| 4 | Cortex-M3 | ARMv7-M | Harvardská |
| 5 | Cortex-M4 | ARMv7E-M | Harvardská |
| 6 | Cortex-M7 | ARMv7E-M | Harvardská |
| 7 | Cortex-M23 | ARMv8-M | Harvardská |
| 8 | Cortex-M33 | ARMv8-M | Harvardská |
Při pohledu na druhou tabulku se dozvíme, kolik řezů mají pipeline v jednotlivých jádrech a taktéž kolik vstupů přerušení je možné maximálně obsloužit. Na tomto místě stojí za připomenutí, že větší počet řezů v RISCových procesorech na jednu stranu může zvýšit jejich výpočetní výkon (zvětšení frekvence), na stranu druhou však zvětšuje plochu samotného CPU, reakce na přerušení se musí řešit složitějším způsobem (u některých čipů dosahuje latence reakce na přerušení až 12 cyklů) a taktéž se při špatné predikci skoků může zhoršit celkový výkon. U jader Cortex-M je patrné, že se designéři snažili o vybalancování všech veličin a vlastností (právě z tohoto důvodu se například dnes namísto papírově výkonnějších jader Cortex-M0 používají jádra Cortex-M0+ s jednodušší strukturou pipeline):
| # | Jádro | Pipeline | Přerušení |
|---|---|---|---|
| 1 | Cortex-M0 | 3 řezy | 1–32 + NMI |
| 2 | Cortex-M0+ | 2 řezy | 1–32 + NMI |
| 3 | Cortex-M1 | 3 řezy | 1–32 + NMI |
| 4 | Cortex-M23 | 2 řezy | 1–32 + NMI |
| 5 | Cortex-M3 | 3 řezy | 1–240 + NMI |
| 6 | Cortex-M33 | 3 řezy | 1–240 + NMI |
| 7 | Cortex-M4 | 3 řezy | 1–240 + NMI |
| 8 | Cortex-M7 | 6 řezů | 1–240 + NMI |
Ve třetí tabulce jsou shrnuty vlastnosti instrukčních sad, které si sice jsou v některých ohledech velmi podobné (například absencí původních 32bitových „RISCových“ instrukcí ARM), ovšem je patrné, že některé vlastnosti jsou dostupné až u větších, výkonnějších a nutno říci, že taktéž energeticky náročnějších jader:
| # | Jádro | Instrukční sada | HW násobička | HW dělička | Sat.ADD/SUB | DSP | FPU |
|---|---|---|---|---|---|---|---|
| 1 | Cortex-M0 | Thumb | 32bit | ne | ne | ne | ne |
| 2 | Cortex-M0+ | Thumb | 32bit | ne | ne | ne | ne |
| 3 | Cortex-M1 | Thumb | 32bit | ne | ne | ne | ne |
| 4 | Cortex-M23 | Thumb | 32bit | ano (17 cyklů) | ne | ne | ne |
| 5 | Cortex-M3 | Thumb+Thumb2 | 32/64bit | ano | ano | ne | ne |
| 6 | Cortex-M33 | Thumb+Thumb2 | 32/64bit | ano (17 cyklů) | ano | opt | ano |
| 7 | Cortex-M4 | Thumb+Thumb2 | 32/64bit | ano | ano | ano | opt |
| 8 | Cortex-M7 | Thumb+Thumb2 | 32/64bit | ano | ano | ano | opt |
Poznámky k předchozí tabulce:
- Jádra Cortex-M0/M0+/M1 obsahují většinu instrukcí Thumb kromě trojice instrukcí CBZ, CBNZ a prefixu IT. Taktéž obsahují šest vybraných instrukcí ze sady Thumb-2.
- Ve sloupci „HW násobička“ je napsáno, zda je výsledek násobení dvou 32bitových čísel taktéž 32bitový (spodní polovina výsledku) či 64bitový. U některých čipů lze zvolit, zda je násobička sériová (pomalý výpočet, malá plocha čipu, malá spotřeba) či paralelní (rychlý výpočet, ovšem na úkor větší plochy čipy a taktéž vyšší spotřeby).
13. Cortex-M4, Cortex-M33 a Cortex-M7
Z poslední tabulky uvedené v předchozí kapitole vyplývá, že DSP instrukce nalezneme jen u čipů Cortex-M4 a Cortex-M7, zatímco u nových čipů Cortex-M33 je DSP volitelným modulem, který může ale nemusí být na konkrétním čipu syntetizován. Proto se v dalších kapitolách soustředíme pouze na tato tři jádra.
Mikroprocesory a mikrořadiče s jádry Cortex-M4 jsou určeny pro ty aplikační oblasti, v nichž je vyžadováno zpracování digitálního signálu (může se jednat o osmibitové, šestnáctibitové či dokonce o 32bitové vzorky) popř. práce s daty uloženými v systému plovoucí řádové čárky (float/single). V těchto oblastech totiž již možnosti menších jader Cortex-M3 nemusí být dostačující a řada Cortex-M4 (nyní i Cortex-M33) je první výkonnější řadou mikrořadičů ARM, kterou lze v tomto případě použít.
Pokud je ovšem vyžadováno zpracování numerických hodnot typu double (tj. čísel s plovoucí řádovou čárkou s takzvanou dvojitou přesností), je nutné použít čipy s jádrem Cortex-M7 nebo se spokojit se softwarovou implementací všech operací s čísly typu double. Opět zde tedy můžeme vidět snahu o vybalancování vlastností se spotřebou a cenou.
Mikrořadiče s jádry Cortex-M33 byly představeny před zhruba sedmi měsíci, takže se jedná o poměrně nové typy čipů. Tyto mikrořadiče jsou postaveny okolo jádra ARMv8-M a technologie TrustZone zajišťující integritu a ochranu dat (většinou před zneužitím uživatelem :-) Vlastnosti těchto čipů jsou konfigurovatelné, takže si lze zvolit například mezi DSP a FPU, popř. použít oba tyto moduly. Ostatní parametry jsou v mnoha ohledech podobné čipům Cortex-M4 (kupodivu nikoli Cortex-M3), což je ostatně patrné i z tabulek uvedených v předchozí kapitole. Jedinou operací, která je oproti Cortex-M4 pomalejší, je operace dělení, která je provedena v sedmnácti cyklech.
14. Formáty zpracovávaných dat
U naprosté většiny DSP operací jsou podporovány tři formáty dat odpovídající běžně zpracovávaným signálům:
- Osmibitová čísla se znaménkem nebo bez znaménka.
- 16bitová čísla se znaménkem nebo bez znaménka.
- 32bitová čísla se znaménkem nebo bez znaménka.
Na tomto místě je důležité si uvědomit, že oproti mnoha jiným digitálním signálovým procesorům zde nenajdeme například podporu pro 20bitové či 24bitové akumulátory, jejichž hodnoty se po dokončení celého vypočtu převádí na 16bitové výsledky. Také zde nenajdeme přímou podporu pro „Q-formát“, s nímž jsme se již v tomto seriálu několikrát setkali. Připomeňme si, že v Q-formátu je většinou nejvyšší bit použit pro uložení znaménka, za tímto bitem následuje binární čárka (tečka) a poté již bity s váhami 1/2, 1/4, 1/8 atd. Alternativně se v Q-formátu může používat až 8 bitů s celočíselnými váhami, které zde slouží pro ohlídání případného přetečení.
15. „DSP násobička“ u jader Cortex-M4/M33/M7
Podobně jako u klasických DSP, i u čipů Cortex-M s DSP instrukcemi je ústředním prvkem rychlá násobička. Ta podporuje takřka nepřeberné množství instrukcí pro násobení celočíselných operandů typu signed či unsigned (se znaménkem, bez znaménka) s tím, že výsledek je buď 32bitová hodnota či hodnota 64bitová. Navíc je možné určit, zda se má výsledek násobení přičíst k mezivýsledku a provést tak v oblasti digitálního zpracování signálů velmi užitečnou operaci nazývanou „Multiply&Accumulate“ (přičemž akumulátor má většinou šířku 32 bitů či 64 bitů, zatímco vstupní operand může být v některých instrukcích pouze šestnáctibitový). Následuje tabulka se základními operacemi násobičky:
| # | Instrukce | Operandy | Výsledek | Počet cyklů | Operace |
|---|---|---|---|---|---|
| 1 | MUL | 32bit×32bit | 32bit | 1 | násobení |
| 2 | MAL | 32bit×32bit | 32bit | 2 | násobení a přičtení výsledku (Multiply and Accumulate) |
| 3 | MLS | 32bit×32bit | 32bit | 2 | násobení a odečtení výsledku (Multiply and Subtract) |
| 4 | SMULL | 32bit×32bit | 64bit | 1 | násobení hodnot se znaménkem |
| 5 | SMLAL | 32bit×32bit | 64bit | 1 | Multiply and Accumulate (se znaménkem) |
| 6 | UMULL | 32bit×32bit | 64bit | 1 | násobení hodnot bez znaménka |
| 7 | UMLAL | 32bit×32bit | 64bit | 1 | Multiply and Accumulate (bez znaménka) |
| 8 | UMAAL | 32bit×32bit+32+32 | 64bit | 1 | Multiply and Accumulate long (bez znaménka) |
| 9 | SMLAD | 16bit×16bit | 32bit | 1 | násobení dvouprvkových vektorů |
| 10 | SMLADX | 16bit×16bit | 32bit | 1 | násobení dvouprvkových vektorů |
DSP operace (povšimněte si zejména konstantního počtu cyklů pro zahájení či dokončení operace):
| # | Instrukce | Počet cyklů | Operace |
|---|---|---|---|
| 1 | SMLALD | 1 | Signed Multiply Accumulate Long Dual (16bit×64bit) |
| 2 | SMLAWB | 1 | Signed Multiply Accumulate (word by halfword) |
| 3 | SMLAWT | 1 | Signed Multiply Accumulate (word by halfword) |
| 4 | SMLSD | 1 | Signed Multiply Subtract Dual |
| 5 | SMLSLD | 1 | Signed Multiply Subtract Long Dual |
| 6 | SMMLA | 1 | Signed Most Significant Word Multiply Accumulate |
| 7 | SMMLS | 1 | Signed Most Significant Word Multiply Subtract |
| 8 | SMUAD | 1 | Signed Dual Multiply Add |
| 9 | SMMUL | 1 | Signed Most Significant Word Multiply |
| 10 | SMULWB | 1 | Signed Multiply (word by halfword) |
| 11 | SMMLAR | 1 | 32-bit multiply with rounded 32-most-significant-bit accumulate |
| 12 | SMMLSR | 1 | 32-bit multiply with rounded 32-most-significant-bit subtract |
| 13 | SMMULR | 1 | 32-bit multiply returning rounded 32-most-significant-bits |
| 14 | SMLABB | 1 | Q setting 16-bit signed multiply with 32-bit accumulate, bottom by bottom |
| 15 | SMLABT | 1 | Q setting 16-bit signed multiply with 32-bit accumulate, bottom by top |
| 16 | SMLALBB | 1 | 16-bit signed multiply with 64-bit accumulate, bottom by bottom |
| 17 | SMLALBT | 1 | 16-bit signed multiply with 64-bit accumulate, bottom by top |
| 18 | SMLALTB | 1 | 16-bit signed multiply with 64-bit accumulate, top by bottom |
| 19 | SMLALTT | 1 | 16-bit signed multiply with 64-bit accumulate, top by top |
| 20 | SMULBB | 1 | 16-bit signed multiply yielding 32-bit result, bottom by bottom |
| 21 | SMULBT | 1 | 16-bit signed multiply yielding 32-bit result, bottom by top |
| 22 | SMULTB | 1 | 16-bit signed multiply yielding 32-bit result, top by bottom |
| 23 | SMULTT | 1 | 16-bit signed multiply yielding 32-bit result, top by bottom |
| 24 | SMULWT | 1 | 16-bit by 32-bit signed multiply returning 32-most-significant-bits, top |
| 25 | SMUSD | 1 | Dual 16-bit signed multiply returning difference |
| 26 | SMLATB | 1 | Q setting 16-bit signed multiply with 32-bit accumulate, top by bottom |
| 27 | SMLATT | 1 | Q setting 16-bit signed multiply with 32-bit accumulate, top by top |
16. Aritmetické operace se saturací
Při zpracování signálu se téměř vždy používají aritmetické operace se saturací, u nichž je zaručeno, že při sčítání či odčítání nikdy nedojde k přetečení přes maximální či minimální 8bitovou, 16bitovou či 32bitovou hodnotu (se znaménkem či bez znaménka), ale výpočet se „zasekne“ na minimální či maximální hodnotě. Na následujících třech obrázcích (už jsme je v tomto seriálu použili) je naznačeno, jak se liší klasické operace s přetečením/podtečením a operace se saturací:

Obrázek xx: Zdrojový rastrový obrázek (známá fotografie Lenny), který tvoří zdroj pro jednoduchý konvoluční (FIR) filtr, jenž zvyšuje hodnoty pixelů o pevně zadanou konstantu (offset).

Obrázek xx: Pokud je pro přičtení offsetu použita operace součtu se zanedbáním přenosu (carry), tj. když se počítá systémem „modulo N“, dochází při překročení maximální hodnoty pixelu (čistě bílá barva) k jasně viditelným chybám.

Obrázek xx: Při použití operace součtu se saturací sice taktéž dojde ke ztrátě informace (vzniknou oblasti s pixely majícími hodnotu 255), ovšem viditelná chyba je mnohem menší než na předchozím obrázku.

U popisovaných čipů Cortex-M4, M33 a M7 najdeme tyto instrukce, které dokážou výsledky saturovat na minimální či maximální hodnotu:
| # | Instrukce | Typ | Šířka operandů | Poznámka |
|---|---|---|---|---|
| 1 | SSAT | Signed | 32 bitů | posun operandu před výpočtem |
| 2 | SSAT16 | Signed | 2×16 bitů | posun operandu před výpočtem |
| 3 | USAT | Unsigned | 32 bitů | posun operandu před výpočtem |
| 4 | USAT16 | Unsigned | 2×16 bitů | posun operandu před výpočtem |
| 5 | QADD | Signed | 32 bitů | součet se saturací |
| 6 | QADD8 | Signed | 4×8 bitů | součet se saturací |
| 7 | QADD16 | Signed | 2×16 bitů | součet se saturací |
| 8 | QSUB | Signed | 32 bitů | rozdíl se saturací |
| 9 | QSUB8 | Signed | 4×8 bitů | rozdíl se saturací |
| 10 | QSUB16 | Signed | 2×16 bitů | rozdíl se saturací |
| 11 | QASX | Signed | 32 bitů | add + exchange |
| 12 | QSAX | Signed | 32 bitů | sub + exchange |
| 13 | QDADD | Signed | 32 bitů | druhý operand je před výpočtem vynásoben dvěma |
| 14 | QDSUB | Signed | 32 bitů | druhý operand je před výpočtem vynásoben dvěma |
| 15 | UQADD8 | Unsigned | 4×8 bitů | součet se saturací |
| 16 | UQADD16 | Unsigned | 2×16 bitů | součet se saturací |
| 17 | UQSUB8 | Unsigned | 4×8 bitů | rozdíl se saturací |
| 18 | UQSUB16 | Unsigned | 2×16 bitů | rozdíl se saturací |
| 19 | UQASX | Unsigned | 32 bitů | add + exchange |
| 20 | UQSAX | Unsigned | 32 bitů | add + exchange |
Tyto operace mohou měnit příznak Q, jenž je nastaven ve chvíli, kdy při nějaké aritmetické operaci dojde k saturaci. To lze použít například k detekci špatně nastavených parametrů při zpracování signálu (příliš velké zesílení apod.). Díky tomu, že příznak Q není běžnými instrukcemi nulován (je takzvaně „sticky“), není nutné jeho nastavení testovat po každé aritmetické operaci, ale například až po zpracování celého bloku dat či po aplikaci celého filtru na jeden vzorek, což je rychlejší a většinou i dostačující.
17. Odkazy na Internetu
- DSP for Cortex-M
https://developer.arm.com/technologies/dsp/dsp-for-cortex-m - Cortex-M processors in DSP applications? Why not?!
https://community.arm.com/processors/b/blog/posts/cortex-m-processors-in-dsp-applications-why-not - Cortex-M23
https://www.arm.com/products/processors/cortex-m/cortex-m23-processor.php - Cortex-M33
https://www.arm.com/products/processors/cortex-m/cortex-m33-processor.php - White Paper – DSP capabilities of Cortex-M4 and Cortex-M7
https://community.arm.com/processors/b/blog/posts/white-paper-dsp-capabilities-of-cortex-m4-and-cortex-m7 - Q (number format)
https://en.wikipedia.org/wiki/Q_%28number_format%29 - TriCore Architecture & Core
http://www.infineon.com/cms/en/product/microcontroller/32-bit-tricore-tm-microcontroller/tricore-tm-architecture-and-core/channel.html?channel=ff80808112ab681d0112ab6b73d40837 - TriCoreTM V1.6 Instruction Set: 32-bit Unified Processor Core
http://www.infineon.com/dgdl/tc_v131_instructionset_v138.pdf?fileId=db3a304412b407950112b409b6dd0352 - TriCore v2.2 C Compiler, Assembler, Linker Reference Manual
http://tasking.com/support/tricore/tc_reference_guide_v2.2.pdf - Infineon TriCore (Wikipedia)
https://en.wikipedia.org/wiki/Infineon_TriCore - C166®S V2 Architecture & Core
http://www.infineon.com/cms/en/product/microcontroller/16-bit-c166-microcontroller/c166-s-v2-architecture-and-core/channel.html?channel=db3a304312bef5660112c3011c7d01ae - Memory segmentation
https://en.wikipedia.org/wiki/Memory_segmentation - Bus mastering
https://en.wikipedia.org/wiki/Bus_mastering - ST10 16-bit MCUs
http://www.st.com/en/microcontrollers/st10–16-bit-mcus.html?querycriteria=productId=LN1111 - XC800 family
https://en.wikipedia.org/wiki/XC800_family - C166 (stránky společnosti Infineon)
https://www.infineon.com/cms/en/product/microcontroller/16-bit-c166-microcontroller/channel.html?channel=ff80808112ab681d0112ab6b2eaf0759#ispnTab3 - C166 Family
https://en.wikipedia.org/wiki/C166_family - Permanent Magnet Synchronous Motor
https://en.wikipedia.org/wiki/Synchronous_motor#Permanent_magnet_motors - Implementing field oriented control of a brushless DC motor
http://www.eetimes.com/document.asp?doc_id=1279321 - Vector control (motor)
https://en.wikipedia.org/wiki/Vector_control_(motor) - Motorola DSP56k
https://www.rockbox.org/wiki/MotorolaDSP56k - Motorola 56000 (Wikipedia)
http://en.wikipedia.org/wiki/Motorola_56000 - Using the Motorola DSP56002EVM for Amateur Radio DSP Projects
http://www.johanforrer.net/EVM/article.html - The Atari Falcon030 „Personal Integrated Media System“
http://www.atarimuseum.com/computers/16bits/falcon030.html - Turtle Beach Corporation (stránky společnosti)
http://www.turtlebeach.com/ - Turtle Beach Corporation (Wikipedia)
https://en.wikipedia.org/wiki/Turtle_Beach_Corporation - Atari Falcon 030 DSP 3D engine test
http://www.digiti.info/video/WHQwMjNRaExfLWs=/atari_falcon030_dsp_3d_engine_test - Atari Falcon030 (německy)
http://www.maedicke.de/atari/hardware/falcon.htm - Old-computers.com: Atari Falcon030
http://www.old-computers.com/museum/computer.asp?c=125&st=1 - Atari Falcon030 (Wikipedia)
http://en.wikipedia.org/wiki/Atari_Falcon - Past and current projects (including Falcon stuff)
http://os.inf.tu-dresden.de/~nf2/projects/projects.html - Atari Falcon 030: The Case For The Defence
http://www.soundonsound.com/sos/1994_articles/sep94/atarifalcon.html - DaVinci processor family
http://www.ti.com/general/docs/datasheetdiagram.tsp?genericPartNumber=TMS320DM365&diagramId=64193 - Texas Instruments DaVinci
https://en.wikipedia.org/wiki/Texas_Instruments_DaVinci - TMS320DM6446 (DaVinci)
http://www.ti.com/product/tms320dm6446 - Digital Media Video Processors (TI)
http://www.ti.com/lsds/ti/processors/dsp/media_processors/davinci/products.page# - TI Wiki
http://processors.wiki.ti.com/index.php/Main_Page - C5000 ultra-low-power DSP
http://www.ti.com/lsds/ti/processors/dsp/c5000_dsp/overview.page - OMAP (Wikipedia)
https://en.wikipedia.org/wiki/OMAP - OMAP – TI Wiki
http://processors.wiki.ti.com/index.php/OMAP - Why OMAP can't compete in smartphones
http://www.eetimes.com/author.asp?section_id=40&doc_id=1286602 - Applications Processors – The Heart of the Smartphone
http://www.engineering.com/ElectronicsDesign/ElectronicsDesignArticles/ArticleID/5791/Applications-Processors-The-Heart-of-the-Smartphone.aspx - TI cuts 1,700 jobs in OMAP shift
http://www.eetimes.com/document.asp?doc_id=1262782 - VLIW: Very Long Instruction Word: Texas Instruments TMS320C6×
http://www.ecs.umass.edu/ece/koren/architecture/VLIW/2/ti1.html - An Introduction To Very-Long Instruction Word (VLIW) Computer Architecture
Philips Semiconductors - VLIW Architectures for DSP: A Two-Part Lecture (PDF, slajdy)
http://www.bdti.com/MyBDTI/pubs/vliw_icspat99.pdf - Very long instruction word (Wikipedia)
https://en.wikipedia.org/wiki/Very_long_instruction_word - A VLIW Approach to Architecture, Compilers and Tools
http://www.vliw.org/book/ - VEX Toolchain (VEX = VLIW Example)
http://www.hpl.hp.com/downloads/vex/ - Elbrus (computer)
https://en.wikipedia.org/wiki/Elbrus_%28computer%29 - Super Harvard Architecture Single-Chip Computer
https://en.wikipedia.org/wiki/Super_Harvard_Architecture_Single-Chip_Computer - Digital Signal Processors (stránky TI)
http://www.ti.com/lsds/ti/processors/dsp/overview.page - C674× Low Power DSP (stránky TI)
http://www.ti.com/lsds/ti/processors/dsp/c6000_dsp/c674×/overview.page - TMS320C30 (stránky TI)
http://www.ti.com/product/tms320c30 - TMS320C6722B
http://www.ti.com/product/tms320c6722b/description - Introduction to DSP
http://www.ti.com/lit/wp/spry281/spry281.pdf - The Evolution of TMS (Family of DSPs)
http://www.slideshare.net/moto_modx/theevo1 - Datasheet k TMS32010
http://www.datasheetarchive.com/dlmain/49326c32a52050140abffe6f0ac4894aa09889/M/TMS32010 - 1979: Single Chip Digital Signal Processor Introduced
http://www.computerhistory.org/siliconengine/single-chip-digital-signal-processor-introduced/ - The TMS32010. The DSP chip that changed the destiny of a semiconductor giant
http://www.tihaa.org/historian/TMS32010–12.pdf - Texas Instruments TMS320 (Wikipedia)
https://en.wikipedia.org/wiki/Texas_Instruments_TMS320 - Great Microprocessors of the Past and Present: Part IX: Signetics 8×300, Early cambrian DSP ancestor (1978):
http://www.cpushack.com/CPU/cpu2.html#Sec2Part9 - Great Microprocessors of the Past and Present (V 13.4.0)
http://jbayko.sasktelwebsite.net/cpu.html - Introduction to DSP – DSP processors:
http://www.bores.com/courses/intro/chips/index.htm - The Scientist and Engineer's Guide to Digital Signal Processing:
http://www.dspguide.com/ - Digital signal processor (Wikipedia EN)
http://en.wikipedia.org/wiki/Digital_signal_processor - Digitální signálový procesor (Wikipedia CZ)
http://cs.wikipedia.org/wiki/Digitální_signálový_procesor - Digital Signal Processing FAQs
http://dspguru.com/dsp/faqs - Reprezentace numerických hodnot ve formátech FX a FP
http://www.root.cz/clanky/fixed-point-arithmetic/ - IEEE 754 a její příbuzenstvo: FP formáty
http://www.root.cz/clanky/norma-ieee-754-a-pribuzni-formaty-plovouci-radove-tecky/ - Čtyři základní způsoby uložení čísel pomocí FX formátů
http://www.root.cz/clanky/binarni-reprezentace-numerickych-hodnot-v-fx-formatu/ - Základní aritmetické operace prováděné v FX formátu
http://www.root.cz/clanky/zakladni-aritmeticke-operace-provadene-ve-formatu-fx/ - Aritmetické operace s hodnotami uloženými ve formátu FP
http://www.root.cz/clanky/aritmeticke-operace-s-hodnotami-ve-formatu-plovouci-radove-carky/ - FIR Filter FAQ
http://dspguru.com/dsp/faqs/fir - Finite impulse response (Wikipedia)
http://en.wikipedia.org/wiki/Finite_impulse_response - DSPRelated
http://www.dsprelated.com/ - Addressing mode (Wikipedia)
https://en.wikipedia.org/wiki/Addressing_mode - Orthogonal instruction set
https://en.wikipedia.org/wiki/Orthogonal_instruction_set - TI 16-bit and 32-bit microcontrollers
http://www.ti.com/lsds/ti/microcontrollers16-bit32-bit/overview.page - TMS 32010 Assembly Language Programmer's Guide (kniha na Amazonu)
https://www.amazon.com/32010-Assembly-Language-Programmers-Guide/dp/0904047423 - COSC2425: PC Architecture and Machine Language, PC Assembly Language
http://www.austincc.edu/rblack/courses/COSC2425/index.html

