
Jak známo nic na tomto světě není osamocené a naprosto všechno má nějaké vazby na své okolí a své okolí také nějak ovlivňuje. Při tvorbě databází nás většinou zajímá určitý problém, určitá skutečnost, kterou vyjadřujeme daty, která následně vkládáme do tabulek.
Bohužel dost lidí okolo OpenSource projektů je opojeno možnostmi téměř neomezeného prostoru pro nápady a jejich implementaci a často jsou přehlíženy záležitosti, které by měly vlastnímu programování předcházet nebo naopak po zdárné implementaci následovat. Jedná se o věci, jako je analýza, kreslení schémat systému, psaní dokumentace, systematické testování software (QA – quality assurance) a celkově záležitosti shrnutelné pod pojem project management. Nechť tento článek alespoň částečně pomůže v tom, jak efektivně pojímat práci s SQL.
Začněme tím nejdůležitějším. Každý tvůrce databáze by si měl na počátku odpovědět na otázku, čím je pro jeho aplikaci databáze. Jedná se o základní stavební kámen aplikace, nebo je databáze jen vedlejším produktem, nebo bude databáze sloužit jako datový sklad? Zvláště u některých jednoduchých aplikací je dobré se zamyslet nad tím, co nám přinese využívání relačních databází a jsou-li relace potřebné. Občas může i trošinku chytrý soubor odvést dobrou práci v místech, kde by někdo možná chtěl použít databázový server. Pro úplnost mimo relačního modelu existují ještě:
- hierarchický model, je vyjádřen vazbou rodič-potomek a výsledkem je tedy stromová struktura. Výhodou tohoto modelu je rychlost, nevýhodou omezení na výše uvedenou vazbu. Mezi hodně používané implementace patří například LDAP.
- síťový model je podobný předchozímu, ale umožňuje záznamu mít více než jednoho rodiče.
Jen tak pro zopakování si řekněme základní pojmy o relačních DB, které budeme potřebovat. Základem relačních databází jsou dvourozměrné tabulky, kterým říkáme entity. Tabulka je složena ze sloupečků a řádek. Sloupečkům říkáme atributy a řádkům většinou prostě řádky (rows) nebo také n-tice. Průsečíkem sloupce a řádky je pole (field). Shrneme-li to, každá entita má jeden a více atributů a řádek. Jak si ale dále ukážeme, tabulka s pouze jedním sloupcem postrádá smysl.
My se budeme zabývat případem, kdy je DB v aplikaci základní vrstvou pro práci s daty a jejich ukládání. V tomto případě by měl být datový model (DB) svébytný, to znamená sám o sobě zaručuje konzistenci dat a sám o sobě vypovídá o jednotlivých vztazích mezi daty (prosím tuto větu zapamatovat!:-). Bude-li vám někdo tvrdit, že jeho návrh DB je dobrý, ačkoli mu konzistenci (integritu) dat zajišťuje vrstva nad DB (například uživatelské rozhraní), mějte se na pozoru.
Abychom se zde o integritě DB jen nezmínili, zopakujme si, že rozlišujeme doménovou, entitní a referenční integritu dat.
Doménová integrita znamená, že na úrovni sloupců definujeme omezení na určitý datový typ, případně omezení rozsahu hodnot. V databázové hantýrce se tomu celému říká doména atributu. Více viz vaše oblíbená SQL a například CHECK(…) v definici sloupců.
Entitní integrita je záležitostí jednoznačné identifikace řádky v rámci tabulky. Sloupec, který obsahuje tento identifikátor, je pak nazýván primárním klíčem (PRIMARY KEY).
Referenční integrita (RI) je již mezitabulkovou záležitostí. Definuje vztah dvou tabulek, a to pomocí cizích klíčů (FOREIGN KEY).
Základní pojmy jsem si již vyjasnili (zopakovali, chcete-li) a nyní se podívejme na modelování DB.
Jak již bylo řečeno, základem je tabulka. Jméno atributu i jméno tabulky by mělo být v jednotném čísle. Tabulka by měla být nazvána podstatným jménem. Doporučuji myslet při tvorbě aplikace i na to, že svět nezačíná a nekončí na českých hranicích a že čeština není světový jazyk. Platí to hlavně tam, kde je licence typu OpenSource.
Při návrhu tabulky se snažíme o takzvanou normalizaci. Normalizace by měla vést k vzniku tabulek, které lze snadno a efektivně udržovat. Normalizace má několik stupňů a snahou je dosáhnout stupně co nejvyššího.
1. normální forma (1NF)
Relace (tabulka) je v první normální formě, pokud každý její atribut (sloupec) obsahuje jen atomické hodnoty. Tedy hodnoty z pohledu databáze již dále nedělitelné. Tato podmínka není splněna například u tabulky, kde je jméno a příjmení v jednom sloupci a přitom aplikace pracuje s těmito položkami jako samostatnými.
2. normální forma (2NF)
Relace se nachází v druhé normální formě, pokud splňuje podmínky první normální formy a každý neklíčový atribut je plně závislý na primárním klíči, a to na celém klíči a nejen na nějaké jeho podmnožině.
3. normální forma (3NF)
V této formě se nachází tabulka, splňuje-li předchází dvě formy a všechny její neklíčové atributy jsou vzájemně nezávislé.
Tabulka by měla mít alespoň dva atributy. Naopak má-li více jak osm atributů, je vhodné ji blíže prozkoumat a zjistit, zda by nešlo některé atributy vyčlenit do samostatné tabulky. Rozhodujeme-li se o tom, zda vyčlenit nějaký atribut do samostatné tabulky, učiníme tak tehdy, najdeme-li alespoň dva takové atributy, které spolu mohou založit tabulku.
Existují datové modely, které se záměrně dělají tak, že ne zcela vyhovují nárokům na normalizaci tabulek. Jedná se především o oblast datových skladů (data warehouse – DW) a tzv. multidimenzionální databáze (je-li vůbec použito relací). Tato oblast je ale již značně nad rámec tohoto článku a nebudeme se jí tedy zabývat.
Výše uvedená pravidla normálních forem lze jen doporučit pro zapamatování a používání. Ušetříte si tak mnoho problémů s vaší DB. Zvláště začátečníci mají sklon data celé své aplikace vtlačit do jedné nebo několika málo tabulek a připravují se tak o základní vlastnosti, které jim solidní SQL server dává. Je dobré si uvědomit, že moderní SQL severy jsou více než jen víceuživatelské síťové soubory.
Nyní již jsme schopni vytvořit tabulku a můžeme přistoupit pospojování tabulek v logický celek. Dvě tabulky jsou vždy spojeny tak, že jedna poskytuje primární klíč a druhá tabulka vytváří na tento klíč referenci, tedy sloupec (nebo sloupce), který obsahuje hodnoty primárního klíče první tabulky. Této referenci říkáme cizí klíč. Nemusí jít nutně o dvě různé tabulky, ale i pouze o jednu tabulku, v níž definujeme určité vztahy mezi záznamy (například hierarchii). Taktéž primární a cizí klíč nemusí nutně být tvořeny jedním sloupcem, ale i více sloupci najednou, například:
CREATE TABLE prim
(
id int,
num int,
data text,
PRIMARY KEY(id, num)
);
CREATE TABLE fk
(
id serial PRIMARY KEY,
p_id int,
p_num int,
name vharchar(10),
FOREIGN KEY(p_id, p_num) REFERENCES prim(id, num)
);
CREATE TABLE hier
(
id serial PRIMARY KEY,
parent int REFERENCES hier (id),
name varchar(32)
);
Vztahy (relationship) mezi tabulkami jsou:
Vazba one-to-one (1:1)
Vyjadřuje vztah, kdy právě jeden záznam má vztah k právě jednomu jinému unikátní záznamu. Například každý jeden unikátní občan ČR má jedno unikátní rodné číslo. Tato vazba není často využívána, protože se většinou daří data s touto vazbou ukládat v rámci jedné tabulky.
Vazba one-to-many (1:N)
Jedná se o nejčastěji používanou vazbu. Atribut v tabulce může v tomto případě nabývat právě jedné hodnoty z množiny hodnot definovaných v tabulce druhé. Příkladem je třeba vztah člověka a jeho rodného města. Měst je mnoho, ale každý z nás se narodil pouze v jednom z nich. Stejnou vazbou, ale opačně, je vazba many-to-one (N:1).
Vazba many-to-many (M:N)
Pěkným příkladem této vazby je vztah čtenářů a novin. Každé noviny mají mnoho čtenářů a každý z těchto čtenářů může být zároveň čtenářem několika různých novin. V praxi nelze v SQL tento vztah vyjádřit přímo a používá se proto „mezi-tabulka“ s vazbami 1:N na požadované tabulky. Například pro tabulky noviny a čtenář vytvoříme tabulku čtenář_novin, kde jeden sloupec bude odkazovat na tabulku čtenářů a druhý na tabulku novin. V každé řádce této tabulky tedy bude identifikátor čtenáře a novin, který bude vyjadřovat, že daný čtenář čte dané noviny. Čtenář může mít v tabulce více záznamů (řádek), pokaždé však s jinými novinami. V rámci této tabulky bude dvojice čtenář a noviny unikátní. Z takto vytvořené tabulky jsem schopni zjistit, jaké noviny čte čtenář a zároveň i množinu čtenářů určitých novin.
Častým problémem SQL databází je definování a hlavně práce s hierarchickými vztahy (vztah vyjadřující podřízenost a nadřízenost). V těchto případech mají záznamy často podobu stromů a efektivně s nimi pracovat znamená používat rekurzi, která je pro SQL věcí cizí. Například pokud chcete popsat rozsáhlou organizační strukturu nějaké organizace, musíte v rámci jedné tabulky definovat vztahy mezi záznamy. To se provede například tak, že vedle sloupce, který jednoznačně identifikuje řádky, definujeme další uvádějící nadřízený záznam. V praxi to znamená definovat REFERENCES ukazující do téže tabulky (viz již uvedený příklad).
Vlastní tvorba datového modelu
Chcete-li dosáhnout optimálního návrhu DB, je vhodné držet se určitého postupu. Je vhodné rozdělit jej na tyto základní části:
- shromažďování dat a požadavků od uživatelů a zadavatelů systému. Jedná se často o práci s lidmi, takže je vhodné se ozbrojit úsměvem a nekonečnou trpělivostí. Dobré je myslet na to, že většina lidí vám řekne jen to, na co se jich zeptáte, proto je nutné zeptat se na vše. Z vlastní zkušenosti mohu říct, že není chvíle, kdy by uživatel riskoval svůj život více, než když řekne tvůrci aplikace podstatnou informaci až ve chvíli, kdy je aplikace napsána a testována. Je vhodné provádět i určitou selekci informací. Většina lidí má pocit, že jim dáte program, který vyřeší všechny jejich problémy. Takové programy ale mají jen politické strany.
- dalším krokem je definice nezávislých entit
- definice vztahů a typů těchto vztahů
- definice závislých entit a vyhledání kandidátů na klíčové atributy
Výše uvedené se v cyklu opakuje tak dlouho, až se podaří vyřešit všechny vztahy. Po této fázi návrhu DB by již měla existovat rámcová představa o tom, jak bude vypadat výsledná DB. Tato fáze návrhu je ještě značně obecná, takže například u vztahů mezi entitami můžeme pracovat s vazbami M:N, které až později transformujeme do vazeb 1:N a „mezitabulek“.
V další fázi se formulují a definují jednotlivé atributy a tabulky se normalizují tak, aby bylo dosaženo 3NF (třetí normální forma). Jedná se hlavně o finální upřesnění primárních klíčů a vztahů ostatních sloupců k nim.
Výsledkem této fáze vývoje by měl být nějaký diagram (ERD nebo UML). Tento diagram se vám bude později hodit při tvorbě složitějších SQL dotazů. Dobré je, i když se to vždy nedělá, vztahy v diagramech pojmenovávat.
Až ve finále by měla být dělána optimalizace datových typů, a to většinou s přihlédnutí k již určitému SQL serveru.
Oblíbeným tématem mnoha debat je výběr SQL serveru. Ten by měl být vždy prováděn až dle vymyšleného datového modelu, a to tak, aby bylo možné datový model v SQL implementovat.
Většina používaných SQL serverů (Interbase, PostgreSQL, DB2, Sybase, Oracle, Informix) vám asi poskytne dostatečné zázemí pro implementaci obvyklých datových modelů. Avšak například MySQL v případě cizích klíčů a referenční integrity dat asi nebude splňovat základní poučku o samostatnosti datového modelu a bude do návrhu nutné zahrnout i nutnost implementovat některé věci ve vrstvě na touto DB.
Až v této chvíli je smysluplné transformovat navržené schéma do SQL příkazů. V případě, že používáte nějaký CASE nástroj, se může jednat o značně jednoduchý úkon.
Popsaný postup se zabývá tím, jak existující informace transformovat do SQL schématu, ale nic neříká o tom, jak se v moři informací neutopit a jak je analyzovat. V případě opravdu rozsáhlejších schémat je vhodné se rozhodnout pro nějakou strategii, jak se se zadáním ve zdraví vypořádat.
Existují čtyři základní strategie:
- shora dolů
Zadání se postupně rozmělňuje na menší a menší detaily. Analytik musí být vybaven schopností abstraktního myšlení a musí být schopen opravdu dobře rozpitvávat jednotlivé stupně a na nic nezapomenout. - zdola nahoru
Berou se jednotlivosti na nejnižší úrovni a skládají se do celku. Výhodou je možnost lépe zadání rozdělit mezi více členů týmu. Nevýhodou je, že při sestavování do celku se pravděpodobně nepodaří vyhnout se častějším změnám, protože některé věci „vyplavou“ na povrch při finálním sestavování schématu. Na počátku také možná budete v datech plavat, je tedy vhodné je rozdělit mezi více lidí. - zevnitř ven
Podobné jako předchozí. Nalezne se nějaký zásadní a důležitý bod a postupně se od něho dostáváme k jiným takovým bodům. Hezkým přirovnáním je šíření olejových skvrn. Nejdříve se nachází několik samostatných skvrnek, které se postupně zvětšují, až se všechny spojí v jeden celek. - smíšená
V první fázi se zadání rozdělí na více částí (tzv. skeletální schéma) a v druhé fázi se pak části analyzují metodou shora dolů. Nakonec se schémata integrují v celek.
Kreslení schémat databází
Popsat něco slovy může být hodně náročně (hlavně jste-li rodu mužského), proto už od databázového pravěku existují způsoby, jak názorně zakreslovat DB. V případě větších DB by měl být diagram právě tím, s čím se při analýze pracuje. Pokud jste nuceni vytvářet SQL dotazy pro rozsáhlejší DB, tak mít možnost nahlédnout do nějakého schématu také není úplně k zahození.
Souhrnně se diagramy databází schovávají pod zkratku ERD (entity relationship diagram). Protože nic nemůže být úplně jednoduché, existuje několik notací (OMG, ORM, UML, IDEF1X, Crow's Foot, Bachman, Chen, James Martin) těchto schémat a nutno říct, že v různých programech se mohou používané značky mírně lišit nebo i kombinovat. Vzhledem k tomu, že na kreslení těchto diagramů asi budete používat nějaký software, považuji za zbytečné se zde na tomto místě rozepisovat o jednotlivých notacích ERD a raději ponechám na vás prozkoumání dokumentace vámi používaného programu. Bohužel ty opravdu dobré programy na ERD a generování SQL příkazů pro tvorbu DB jsou většinou komerční.
ERD diagramy popisují statickou strukturu databáze. Pro popis toku dat a podobné věci slouží například některé podmnožiny UML.
Původním typem ERD je Chenova notace (Peter Chen 1976). Pro svou názornost je většinou používána ve studijních materiálech nebo dokumentech popisující nějaký úkaz apod. Tento styl diagramů je poměrně náročný na prostor, takže k popisu rozsáhlejších DB není moc vhodný a většina schémat, která uvidíte, bude asi v některé z úspornějších a novějších notací. Tuto původní notaci ovládá například program dia nebo tcm a asi i řada jiných programů (většinou komerčních). Ukázky a popis této notace naleznete například na adrese http://panoramix.univ-paris1.fr/CRINFO/dmrg/MEE/misop003/miso5.html.
Další používanou Crow's Foot notace (je akceptovaná v Information Engineering Methodology (IEM) – bohužel žádný kompletní dokument o IEM se mi najít nepodařilo) a dále pak notace IDEF1X. Tyto notace používá i český program XTG. Z jeho dokumentace je i ukázka této notace:
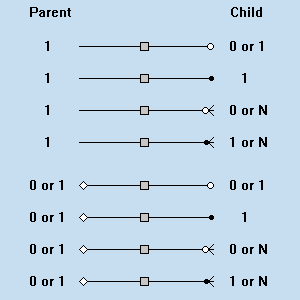
ERD je vhodné kreslit horizontálně (zleva doprava), bez šikmých čar. Jednotlivé spojnice kreslit dostatečně daleko od sebe, aby nedošlo k jejich záměně. Každý diagram by měl být identifikovatelný, to znamená obsahovat nějakou popisku.

Ukázka je z programu XTG Data Modeller.
Odkazy o ERD:
How to Draw Entity Relationship Diagrams (ERD)
The Entity-Relationship Diagram Technique
Software na ERD:
Entity Relationship using Linux and Dia

