
Obsah
1. Programování GPU na Raspberry Pi: použití Quad Processor Unit(s)
2. VideoCore na čipech společnosti Broadcom
4. Využití GPU na Raspberry Pi pro provádění výpočtů
7. Instrukční cache sdílená každou skupinou QPU
8. SFU (Special Functions Unit) sdílená každou skupinou QPU
9. Interní struktura každého QPU
10. Pipeline a její „viditelnost“ při provádění operací
11. Aritmeticko-logické jednotky v QPU
12. Sada pracovních registrů a akumulátorů
13. Formát zpracovávaných hodnot (prvků vektorů)
14. Formát instrukcí posílaných do QPU
15. Celkový teoretický výpočetní výkon grafického čipu na Raspberry Pi
1. Programování GPU na Raspberry Pi: použití Quad Processor Unit(s)
V současnosti existuje nepřeberné množství projektů, v nichž se používají populární jednodeskové mikropočítače Raspberry Pi. Jedná se například o ovládání různých zařízení (robotika), sledování nějakých veličin se zpracováním a odesíláním výsledků, výpočetní „clustery“ (k nim se zakrátko dostaneme), multimediální centra atd. Ve skutečnosti však Raspberry Pi, především pak výkonnější varianty RPi 2 a RPi 3, mohou zastat roli jednoduchého desktopu. Při pohledu na specifikaci RPi by se mohlo zdát, že mikroprocesor tvořící část čipu BCM nabízí poměrně malý výpočetní výkon. Konkrétně se jedná o ARMovská jádra s mikroarchitekturou ARM11 a základní hodinovou frekvencí pouhých 700 MHz (RPi 1), dále pak o čtveřici jader Cortex-A7 s frekvencí 900 MHz (RPi 2) a konečně o čtveřici jader ARM Cortex-A53 s frekvencí 1,2 GHz. Ve skutečnosti jsou však čipy BCM, zejména pak BCM2835 použitý v RPi 1, navrženy pro použití v multimediálních aplikacích, kde ARMovské jádro slouží „pouze“ pro základní ovládání a veškeré složitější výpočty, například kodeky, jsou prováděny v GPU, které je pro tyto účely mnohem výkonnější, než ARMovské CPU.
2. VideoCore na čipech společnosti Broadcom
Všechny tři typy čipů BCM použitých ve všech modelech Raspberry Pi, tj. BCM2835, BCM2836 i BCM2837, jsou postaveny na bázi multimediálních procesorů pojmenovaných VideoCore. Tato architektura byla vyvinuta firmou Alphamosaic a současně je vlastněna společností Broadcom, což je ostatně jeden z důvodů, proč tuto architekturu nenalezneme u dalších výrobců čipů s jádrem ARM (ovšem v této oblasti existuje velká konkurence, takže se setkáme i s dalšími podobnými GPU, například od firem TI, NVidia či Freescale). Architektura VideoCore je plně programovatelná, což je poměrně důležité, protože je pro ni možné vytvářet nové kodeky, používat kodeky, které nemusí být licencovány, využít VideoCore i v těch aplikacích, které nepotřebují vysoký multimediální výkon, ale například provádí mnoho operací s maticemi, výpočty FFT, implementují neuronové sítě atd. Právě poslední možnost, tj. použití VideoCore pro urychlení „běžných“ aplikací, otevírá nové možnosti i pro mikropočítače typu Raspberry Pi, zejména tehdy, pokud má hlavní CPU nedostatečný výkon.
3. Generace jader VideoCore
V současnosti existují minimálně čtyři generace grafických procesorů založených na VideoCore. Tyto procesory jsou většinou umístěny na jednom čipu s hlavním procesorem a řadičem periferních zařízení, takže vzniká SoC (System on a Chip), což je ostatně i případ mikropočítače Raspberry Pi. Podívejme se na některé čipy obsahující VideoCore a popř. i hlavní procesor a další pomocné obvody:
| # | Čip | GPU | CPU |
|---|---|---|---|
| 1 | VC01 | VideoCore 1 | × |
| 2 | BCM2702 (VC02) | VideoCore 2 | × |
| 3 | BCM2705 (VC05) | VideoCore 2 | × |
| 4 | BCM2091 | VideoCore 4 | ? |
| 5 | BCM2722 | VideoCore 2 | × |
| 6 | BCM2724 | VideoCore 2 | × |
| 7 | BCM2727 | VideoCore 3 | × |
| 8 | BCM11181 | VideoCore 3 | × |
| 9 | BCM2763 | VideoCore 4 | × |
| 10 | BCM2820 | VideoCore 4 | ARM1176 |
| 11 | BCM2835 | VideoCore 4 | ARM1176 (standardně 700 MHz) |
| 12 | BCM2836 | VideoCore 4 | Quad-core Cortex-A7 (standardně 900 MHz) |
| 13 | BCM2837 | VideoCore 4 | Quad-core Cortex-A53 (standardně 1200 MHz) |
| 14 | BCM11182 | VideoCore 4 | × |
| 15 | BCM11311 | VideoCore 4 | Dual-core Cortex-A9 |
| 16 | BCM21654 | VideoCore 4 | Cortex-A9 + Cortex-R4 |
| 17 | BCM21654G | VideoCore 4 | Cortex-A9 (až do 1 GHz) |
| 18 | BCM21663 | VideoCore 4 | Cortex-A9 (až do 1.2 GHz) |
| 19 | BCM21664 | VideoCore 4 | Cortex-A9 (až do 1 GHz) |
| 20 | BCM21664T | VideoCore 4 | Cortex-A9 (až do 1.2 GHz) |
| 21 | BCM28150 | VideoCore 4 | Dual-core Cortex-A9 |
| 22 | BCM21553 | VideoCore 4 | ARM11 |
| 23 | BCM28145/28155 | VideoCore 4 | Dual-core Cortex-A9 (až do 1.2 GHz) |
| 24 | BCM23550 | VideoCore 4 | Quad-core Cortex-A7 (až do 1.2 GHz) |
4. Využití GPU na Raspberry Pi pro provádění výpočtů
V dnešním článku si stručně popíšeme tu část GPU použitou na čipech BCM, kterou je možné naprogramovat a použít tak pro mnohdy razantní urychlení výpočtů. Teoretický maximální výpočetní výkon programovatelné části GPU dosahuje 24 GFLOPS u čipů BCM2835 a BCM2836 resp. 28,8 GFLOPS u čipu BCM2837, musíme si však uvědomit, že tohoto stavu se v reálných programech nemůže dosáhnout a navíc je tento výkon spočítán pro případ, že se zpracovávají čtyřprvkové vektory obsahující osmibitové hodnoty (barvy atd.) a to navíc pouze omezeným repertoárem operací (součet, součin, konverze). Pokud se výpočty mají provádět se 16bitovými či 32bitovými hodnotami a s použitím dalších operací (druhá odmocnina, podíl), bude reálný výpočetní výkon mnohem nižší, i tak se však dá dosáhnout zajímavých hodnot. 10 GFLOPS nemusí být výjimkou, což je pro mikropočítač s cenou 20 (35) dolarů a příkonem mezi jedním až čtyřmi watty velmi zajímavá hodnota umožňující efektivně použít RPi ve výpočetních clusterech (záleží samozřejmě na konkrétní aplikaci, neboť RPi se na druhou stranu může „pochlubit“ pomalou implementací Ethernetu, takže lokalita dat hraje významnou roli při rozhodování).
5. Základní architektura GPU
Podívejme se nejdříve na celkové schéma GPU VideoCore:
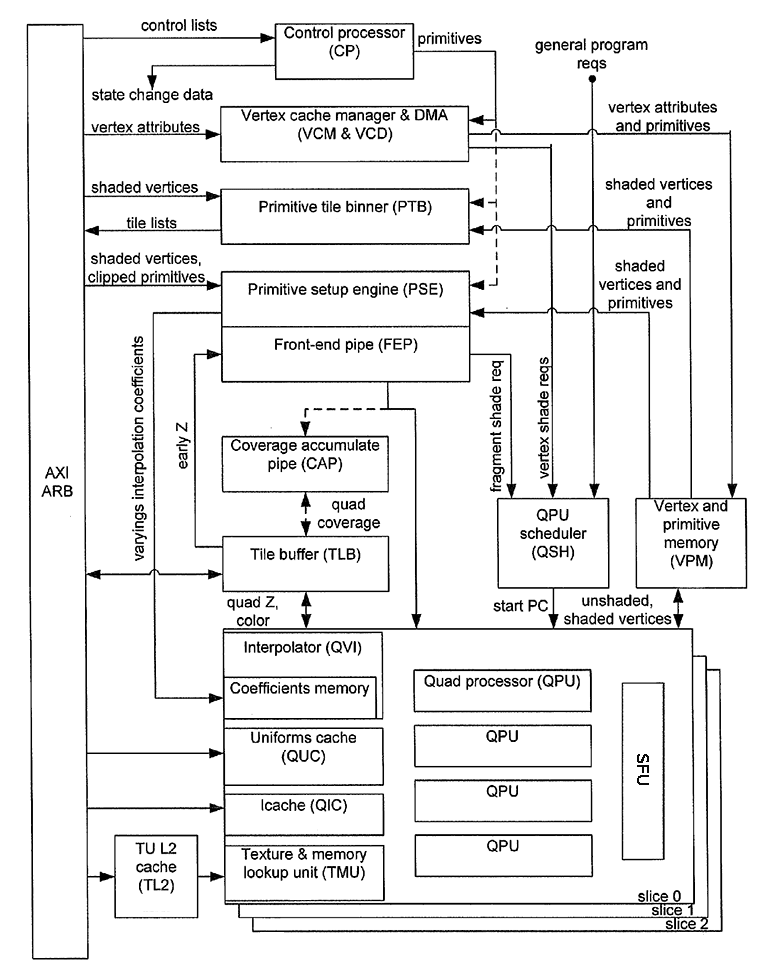
Obrázek 1: Schéma GPU VideoCore.
Na tomto obrázku můžeme vidět koncepci VideoCore. Na jednu stranu se nejedná ani o univerzálně programovatelný čip s maticí nezávisle pracujících CPU, na stranu druhou to ale není pevně nakonfigurovaný 3D akcelerátor. Některé moduly, které VideoCore obsahuje, jsou určeny čistě pro provádění 2D a 3D grafických operací a je možné je pouze překonfigurovat, nikoli přeprogramovat (Front-End Pipe, Interpolator, celý koncept Z-bufferu atd.). Některé moduly pracují s vertexy (vrcholy) zpracovávaných grafických primitiv, další moduly naopak zpracovávají fragmenty, tj. data popisující jeden pixel, který se má zapsat do framebufferu. Zajímavostí je použití TLB (Tile Bufferu), který zde z důvodů lepší škálovatelnosti nahrazuje přímý přístup do klasického framebufferu. Ovšem z hlediska programování obecných algoritmů nejsou tyto bloky většinou podstatné; důležitější jsou programovatelné QPU neboli Quad Processor Unit(s) a k nim přidružené pomocné moduly popsané v dalších kapitolách (QPU je název používaný společností Broadcom, obecný název pro tento typ programovatelných modulů je shader).
6. Skupiny QPU (slices)
Na GPU je implementováno dvanáct QPU. Ty jsou sdruženy po čtveřicích, přičemž vždy jedna čtveřice QPU tvoří společně s instrukční cache a SFU skupinu neboli slice (na tomto místě nechci slice překládat jako řez, protože stejné slovo bude použito při popisu pipeline):

Obrázek 2: Skupiny QPU.
Proč jsou QPU sdruženy do čtveřic? Samotný QPU interně obsahuje dvě aritmeticko-logické jednotky, které ovšem dokážou provádět jen jednodušší operace (navíc každá ALU jinou skupinu operací). Pro specializované výpočty, které se při 2D a 3D renderingu používají, například pro výpočet druhé odmocniny, se však minimalisticky pojatý QPU vůbec nehodí. Pro tyto výpočty je vytvořen modul SFU popsaný dále, který je složitější a tudíž zabere větší plochu čipu. Pravděpodobně by nebylo ekonomické implementovat pro každý QPU vlastní SFU, proto je tento modul vždy sdílen mezi čtyřmi QPU a počítá se s tím, že výpočet odmocniny nebude probíhat tak často, jako například součet či součin (už zde můžete vidět určitou problematičnost výpočtu GFLOPS, protože ne všechny FP operace jsou si zde rovny).
7. Instrukční cache sdílená každou skupinou QPU
Z vnějšího pohledu je každý QPU vektorovým (nebo možná přesněji řečeno SIMD) procesorem zpracovávajícím vektory se šestnácti prvky s latencí čtyři cykly. Z vnitřního pohledu je situace jiná, protože SIMD operace se zde provádí „pouze“ se čtyřprvkovými vektory (odtud ostatně pochází význam názvu Quad Processor Unit), ovšem postupně se do pipeline vloží instrukce čtyřikrát pro různé vstupní vektory. Instrukce se do skupiny QPU přenáší přes instrukční cache, která je na schématu pojmenována QIC. Samotné řízení QPU má na starost blok QSH (scheduler). Pokud je GPU naprogramován pro 2D či 3D rendering, používá scheduler relativně jednoduchý postup pro nalezení prvního volného QPU, kterému dodá data (vertexy, fragmenty), protože v tomto případě QPU zpracovávají stejný algoritmus:
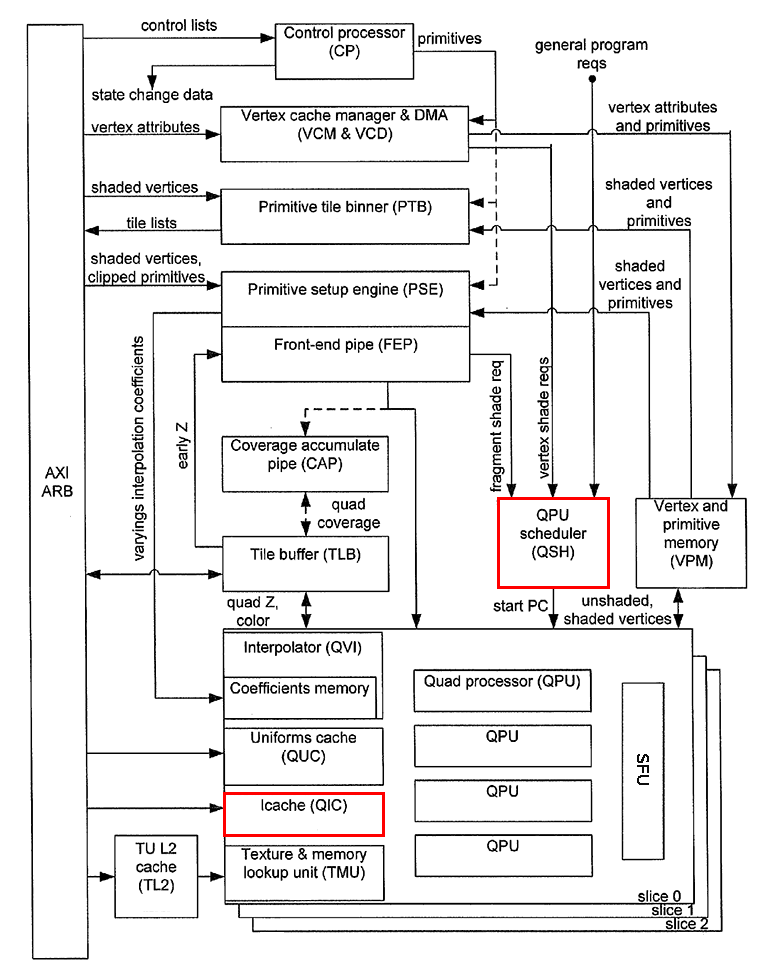
Obrázek 3: Instrukční cache a scheduler.
Proč se SIMD operace provádí právě nad čtyřprvkovými vektory? Typickým algoritmem je práce s fragmenty, tj. mj. i s barvami pixelů, což jsou čtveřice A, R, G, B. Jak uvidíme dále, je barva (color) reprezentována ve formátu vhodném pro provádění všech důležitých operací s fragmenty – změnu barvy, aplikaci průhlednosti, interpolaci atd.

Obrázek 4: Skupina QPU sdílející společné moduly.
8. SFU (Special Functions Unit) sdílená každou skupinou QPU
Jak jsme si již řekli v předchozích kapitolách, sdílí skupina QPU ještě blok nazvaný SFU určený pro provádění sice důležitých, ale přece jen méně častých operací. Jedná se o výpočet druhé odmocniny, výpočet převrácené hodnoty druhé odmocniny, výpočet logaritmu a exponenciální funkce. První dvě operace nalezneme v mnoha grafických algoritmech, například při normalizaci vektorů, druhé dvě operace při některých operacích s fragmenty (například mlha ve scéně). Zajímavý je způsob volání těchto operací – pro každou operaci je v QPU vyhrazen speciální registr. Zápisem hodnoty do tohoto registru se výpočet spustí a po třech cyklech je výsledek uložen do akumulátoru r4. Záleží jen na programátorovi, aby sám zajistil, že se nespustí větší množství operací v QPU, a to v rámci celé skupiny (slice). Navíc se po spuštění výpočtu nesmí po dobu dvou cyklů přistupovat k akumulátoru r4 (jeho hodnota je platná až třetí cyklus po spuštění výpočtu).
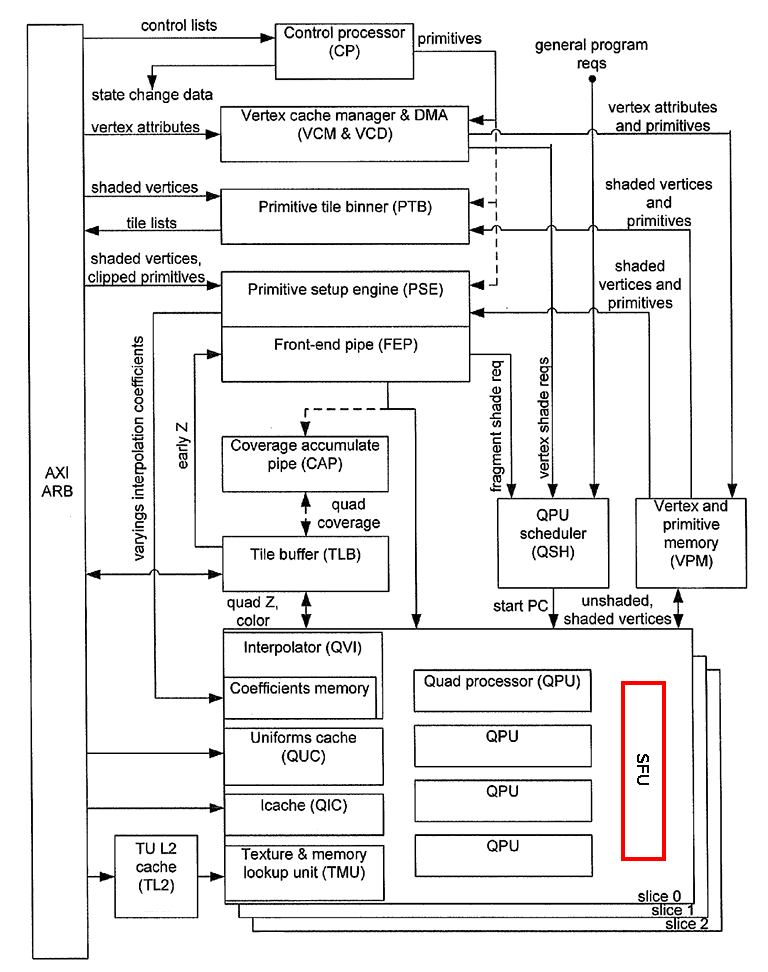
Obrázek 5: Special Functions Unit sdílená každou skupinou QPU.
9. Interní struktura každého QPU
Všechny QPU mají stejnou interní strukturu a skládají se z několika bloků:
- Banky A s 32 pracovními registry. Každý registr má šířku 32 bitů.
- Banky B, taktéž s 32 pracovními registry. Každý registr má šířku 32 bitů.
- Sady šesti akumulátorů (na schématu chybí šestý akumulátor r5, ten je z pohledu QPU určen jen pro čtení, z pohledu programátora naopak představuje možnost, jak do QPU přenést data)
- První ALU orientovanou na operaci násobení (+ na operace hledání minima, maxima atd.).
- První ALU orientovanou na operaci sčítání (+ na bitové posuny, logické operace, součty a rozdíly se saturací).
- Několik multiplexorů, které vybírají ty vstupní registry, jenž se mají použít jako operandy v ALU.
- Moduly označené packer a unpacker zajišťují základní konverze dat (32bitový registr totiž může obsahovat skalární hodnotu či vektor).
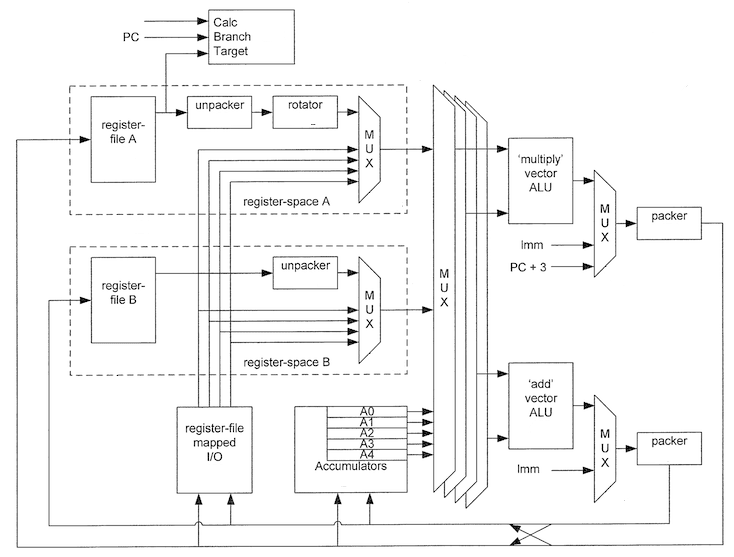
Obrázek 6: Interní struktura každého QPU (zjednodušená, nejsou zde naznačeny řezy pipeline atd.).
10. Pipeline a její „viditelnost“ při provádění operací
QPU jsou interně koncipovány skutečně minimalisticky, což mj. znamená, že se programátor musí seznámit s principem pipeline, protože jednotlivé fáze pipeline jsou pro programátora „viditelné“. Na běžných CPU je naproti tomu většinou programátor od pipeline odstíněn, takže například nemusí řešit konflikty při přístupu k registrům, které se „magicky“ vyřeší samy za cenu pozdržení další instrukce či použitím zkratky (forward paths). Co to znamená v praxi při programování QPU? Například je nutné čekat minimálně jeden takt mezi zápisem výsledku do registru a použitím (čtením) tohoto registru v jiné operaci; dále programátor musí explicitně používat branch delay sloty (délka tři takty) atd. QPU se většinou programují v assembleru (existuje jich více a bohužel nejsou mezi sebou kompatibilní), ale tyto assemblery většinou nevypisují žádné varování, pokud se použije nekorektní operace (dva za sebou jdoucí ALU instrukce nad jedním registrem jsou typickým příkladem).
Pipeline má osm řezů, výpočty se samozřejmě překrývají:
| # | Zkratka | Operace |
|---|---|---|
| 1 | SP | synchronizace atd. |
| 2 | RA | zápis předchozích výsledků do registrů |
| 3 | RR | čtení z registrů a přenos do latchů |
| 4 | MS | výběr operandů pro sčítačku a násobičku, přečtení/zápis hodnot do akumulátorů |
| 5 | A0 | první fáze výpočtu |
| 6 | A1 | druhá fáze výpočtu |
| 7 | A2 | třetí fáze výpočtu |
| 8 | WB | přenos výsledků zpět do pracovních registrů |
Poznámka: pokud hledáte operaci IF (instruction fetch), vězte, že tato operace je provedena pro všechny čtyři QPU v již zmíněné instrukční cache. Každému QPU se instrukční slovo předává postupně, takže QPU nejsou synchronizovány, což je opraveno v prvním řezu.
11. Aritmeticko-logické jednotky v QPU
Z obrázku 6 je patrné, že každý QPU obsahuje dvě samostatně pracující aritmeticko-logické jednotky, přičemž první jednotka provádí operace součtu a druhá jednotka především operaci součinu. ALU tedy nejsou zcela symetrické. Kromě operace součtu dvou vektorů (32bitová FP operace) může první ALU provádět bitové posuny, logické operace a v neposlední řadě taktéž vektorové součty a rozdíly se saturací (myšleny jsou zde součty a rozdíly prováděné prvek po prvku, výpočty se saturací jsou obzvlášť výhodné při zpracování signálů). Druhá aritmeticko-logická jednotka dokáže kromě násobení dvou 32bitových FP hodnot provést součet prvků dvou vektorů, rozdíl prvků, výpočet minima (prvek po prvku), výpočet maxima a taktéž násobení vektorů prvek po prvku. Konkrétní popis zpracovávaných instrukcí si uvedeme příště.
12. Sada pracovních registrů a akumulátorů
Dále v každém QPU nalezneme dvě banky registrů A a B. V první bance se nachází 32 registrů pojmenovaných ra0 až ra31, ve druhé bance pochopitelně nalezneme registry se jmény rb1 až rb31. Typicky se registry z banky A používají v první ALU a registry z banky B ve druhé ALU, ovšem jedním bitem v instrukci lze banky při zápisu výsledků prohodit (na schématu je to naznačeno „angličanem“ v pravé dolní části). Kromě těchto registrů v QPU najdeme i šest akumulátorů r0 až r5. Akumulátory nabízejí rychlejší přístup, protože výsledky se do akumulátorů zapisují už ve fázi MS (o jeden takt dříve), navíc zde neexistuje omezení, která aritmeticko-logická jednotka může do akumulátoru(ů) zapisovat výsledek (samozřejmě nesmí dojít k souběžnému zápisu, což je opět věc, která musí být zajištěna programátorem). Akumulátory r4 a především pak r5 mají další speciální funkci, protože jsou využity pro přenos dat z dalších modulů čipu.
13. Formát zpracovávaných hodnot (prvků vektorů)
QPU mohou zpracovávat data v několika různých formátech. Vždy však platí, že do první i druhé aritmeticko-logické jednotky vstupují hodnoty přečtené z 32 bitových registrů či z akumulátorů (tyto hodnoty se označují termínem vektor, i když se ve skutečnosti může jednat o skalární hodnotu). Každou 32bitovou hodnotu je možné interpretovat jako:
- 32bitová hodnota typu celé číslo (integer)
- 32bitová FP hodnota (single/float)
- 16bitová celočíselná hodnota se znaménkem
- 16bitová FP hodnota (má poněkud omezený repertoár operací)
- 8bitová celočíselná hodnota bez znaménka (čtyři hodnoty/prvky mohou tvořit vektor)
- 8bitová hodnota reprezentující barvovou složku v rozsahu 0,0 až 1,0 (čtyři složky tvoří barvu)
14. Formát instrukcí posílaných do QPU
QPU zpracovává instrukce se šířkou 64 bitů. Formát těchto instrukcí do určité míry připomíná klasické VLIW procesory, protože v každé instrukci nalezneme bitová pole s odlišnou funkcí (výběr operace pro první aritmeticko-logickou jednotku, výběr operace pro druhou ALU, aplikace funkce pack či unpack v první či druhé cestě do ALU, signalizace skoku, výběr podmínky pro provedení operace atd.). Ovšem na rozdíl od VLIW zde není rozdělení bitových polí pro všechny instrukce zcela totožné, takže se rozeznává celkem sedm formátů, které se od sebe mohou rozlišit na základě prvních bitů instrukčního slova. Podrobnější informace si uvedeme v případě zájmu příště.
15. Celkový teoretický výpočetní výkon grafického čipu na Raspberry Pi
Na závěr si ještě přibližme, jakým způsobem se vlastně výrobce čipů Broadcom dopracoval k tvrzení, že teoretický maximální výpočetní výkon programovatelné části GPU dosahuje 24 GFLOPS u čipů BCM2835 a BCM2836 resp. 28,8 GFLOPS u čipu BCM2837. Jak je u těchto čísel zvykem – a v tom není Broadcom sám – vypočetla se ta nejlepší teoretická hodnota, které je možné dosáhnout. Pokud máme k dispozici celkem 12 QPU, z nichž každý bude zpracovávat teoreticky nejrychlejší program (což například znamená, že se musí správně střídat registry, nedochází k synchronizaci, nejsou použity skoky atd.), tak každé QPU dokáže dokončit dvě instrukce v každém taktu, protože je použita ALU se sčítačkou a navíc samostatná ALU s násobičkou. Pokud se v každé instrukci zpracuje čtyřprvkový vektor (4×bajt nebo 4×8bit float), dostaneme jednoduchým výpočtem:
12×2×4=96 FP operací (FLOP) v jednom taktu
QPU používají na BCM2835 a BCM2836 hodinovou frekvenci 250 MHz, takže:
250×106 × 96 = 24×109 FLOPS = 24 GFLOPS
QPU u BCP2837 má poněkud vyšší hodinovou frekvenci 300 MHz:
300×106 × 96 = 28,8×109 FLOPS = 28,8 GFLOPS

Při ceně RPi tedy (teoreticky) zaplatíme za každý GFLOPS jeden dolar, se všemi výše zmíněnými omezeními. U Tegry K1 je výpočetní výkon 365 GFLOPS se 192 jádry, takže při sumě přibližně 180 dolarů za desku se dostáváme k výhodnější ceně přibližně 50 centů za GFLOPS. Naproti tomu u šestnácti jádrového „high performance“ Parallela boardu je cena více než 3 dolary za GFLOPS (spočtení ceny u desek s čipy Atom atd. ponechám na váženém čtenáři).
Poznámka: programování QPU je mnohem pracnější a časově náročnější, než u běžného CPU, navíc každé použití SFU snižuje počet reálně dokončených operací.
16. Odkazy na Internetu
- Hacking The GPU For Fun And Profit (Pt. 1)
https://rpiplayground.wordpress.com/2014/05/03/hacking-the-gpu-for-fun-and-profit-pt-1/ - A birthday present from Broadcom
https://www.raspberrypi.org/blog/a-birthday-present-from-broadcom/ - VideoCoreIV-QPU
https://github.com/hermanhermitage/videocoreiv-qpu - VC4ASM – macro assembler for Broadcom VideoCore IV aka Raspberry Pi GPU
http://maazl.de/project/vc4asm/doc/index.html - BCM2835: High Definition 1080p Embedded Multimedia Applications Processor
https://web.archive.org/web/20120513032855/http://www.broadcom.com/products/BCM2835 - MoeASM released – VideoCore IV support to be added
https://wk3.org/posts/588911 - VideoCore (Wikipedia)
https://en.wikipedia.org/wiki/VideoCore - More QPU magic from Pete Warden (RPi blog)
https://www.raspberrypi.org/blog/more-qpu-magic-from-pete-warden/ - New QPU macro assembler (RPi blog)
https://www.raspberrypi.org/blog/new-qpu-macro-assembler/ - Raspberry Pi VideoCore APIs
http://elinux.org/Raspberry_Pi_VideoCore_APIs - Programming AudioVideo on the Raspberry Pi GPU
https://jan.newmarch.name/RPi/index.html - The Standard for Vector Graphics Acceleration
https://www.khronos.org/openvg/ - Raspberry Pi pages
https://www.raspberrypi.org/ - BCM2835 registers
http://elinux.org/BCM2835_registers - VideoCore (archiv stránek společnosti Alphamosaic)
http://web.archive.org/web/20030209213838/www.alphamosaic.com/videocore/ - RPi lessons: Lesson 6 Screen01
http://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen01.html - Raspberry Pi forum: Bare metal
https://www.raspberrypi.org/forums/viewforum.php?f=72 - C library for Broadcom BCM 2835 as used in Raspberry Pi
http://www.airspayce.com/mikem/bcm2835/ - Raspberry Pi Hardware Components
http://elinux.org/RPi_Hardware#Components - RPi Framebuffer
http://elinux.org/RPi_Framebuffer - HOWTO: Boot your Raspberry Pi into a fullscreen browser kiosk
http://blogs.wcode.org/2013/09/howto-boot-your-raspberry-pi-into-a-fullscreen-browser-kiosk/ - Zdrojový kód fb.c pro RPI
https://github.com/jncronin/rpi-boot/blob/master/fb.c - RPiconfig
http://elinux.org/RPi_config.txt - Mailbox framebuffer interface
https://github.com/raspberrypi/firmware/wiki/Mailbox-framebuffer-interface


























