
Obsah
1. Brain Floating Point – nový formát uložení čísel pro strojové učení i chytrá čidla
2. Časté způsoby reprezentace numerických hodnot ve formátu pevné a plovoucí řádové (binární) tečky
3. Uložení numerických hodnot ve formátu pevné řádové binární tečky
4. Uložení čísel ve formátu plovoucí řádové (binární) tečky
5. Formát plovoucí řádové binární tečky a norma IEEE 754
6. Přednosti a zápory formátu plovoucí řádové tečky
11. Proč používat typ half float?
12. Vlastnosti typu half float
13. Na scénu přichází formát bfloat16
14. Příklady reprezentace některých důležitých konstant ve formátu bfloat16
15. Vztah mezi formáty single, half a bfloat16
16. (Ne)přesnost výpočtů při použití formátu bfloat16
17. Možné urychlení výpočtů s formátem bfloat16 a využití kombinace více formátů
18. Rozšíření formátu bfloat16
19. Formáty „minifloat“ použité ve výuce, online nástroje
1. Brain Floating Point – nový formát uložení čísel pro strojové učení i chytrá čidla
„Nobody needed all those bits anyway“
Přibližně od první poloviny roku 2018 se můžeme jak v různých článcích zabývajících se tématem strojového učení, tak i v některých knihovnách a frameworcích pro ML (Machine Learning) i AI (Artifical Intelligence) setkat s numerickým formátem označeným bfloat16 neboli plným jménem Brain Floating Point. Jedná se o jednu z několika používaných variant „zkrácených“ numerických formátů s plovoucí řádovou čárkou (někdy se setkáme se souhrnným označením half float, což ovšem není zcela přesné). Numerická hodnota uložená ve formátu bfloat16 zabere v operační paměti či v registru CPU nebo GPU pouhé dva bajty, což může znít minimálně zvláštně v dnešní době, kdy se používají nejenom již poměrně dlouho zavedené typy single (32 bitů) a double (64 bitů), ale navíc i (i když nutno říci, že méně často) formáty quadruple (128 bitů) a dokonce i octuple (256 bitů). Důvodů, proč se prosazuje právě formát bfloat16 je více. Zejména za to může fakt, že se v oblasti strojového učení používají GPU, jejichž výpočetní výkon spojené s masivní paralelizací výpočtů (a hluboké pipeliny) v důsledku vedou k tomu, že se úzkým hrdlem opět stává rychlost, resp. spíše pomalost operační paměti. A poloviční bitová šířka numerických hodnot používaných například při tréninku neuronových sítí mnohdy může vést k mnohonásobnému urychlení celého procesu.
Nejdříve se ovšem zmiňme o tom, že přestože dnes v mnoha aplikačních oblastech převažuje uložení numerických hodnot v nějakém formátu plovoucí řádové čárky (či tečky – podle konkrétních místních pravidel zápisu), můžeme se setkat i s formátem, v němž je řádová čárka/tečka pevně umístěna na určité binární pozici, což mj. znamená, že se její konkrétní pozice (významem odpovídající exponentu) nemusí explicitně ukládat. S takovými formáty se setkáme v oblasti mikrořadičů, digitálních signálových procesorů (DSP) i programovatelných obvodů FPGA. Výhodou je mj. fakt, že si programátor sám určí požadovaný rozsah hodnot i přesnost, a to na základě analýzy řešeného problému. Aritmetické operace jsou posléze prováděny klasickou aritmeticko-logickou jednotkou (ALU), přičemž součet, rozdíl i porovnání jsou shodné s celými čísly a u součinu a podílu je nutné provádět bitové posuny (což mnohé DSP mohou provádět automaticky v rámci jediné strojové instrukce).
V anglické literatuře se zmíněná forma reprezentace číselných hodnot označuje zkratkou FX nebo (i když asi méně často) FXP (fixed point), zatímco dnes častěji používaná reprezentace v systému plovoucí řádové tečky se všeobecně označuje zkratkou FP (floating point). V jednom článku jsem dokonce místo zkratky FX viděl i zkratku XP (fixed point), ale to bylo před mnoha lety, v době dnes již muzeálních Windows 95 :-). Nejprve si vysvětlíme princip obou metod použitých pro ukládání podmnožiny racionálních čísel a posléze si také řekneme, jaké výhody a nevýhody jednotlivé principy přináší v každodenní programátorské praxi a ve kterých situacích je vhodnější použít pevnou řádovou čárku. V dalším textu budeme formát pevné binární řádové tečky zkracovat na FX formát a formát používající plovoucí řádovou tečku budeme zapisovat jako FP formát.
2. Časté způsoby reprezentace numerických hodnot ve formátu pevné a plovoucí řádové (binární) tečky
Při ukládání číselných hodnot do operační paměti počítače poměrně záhy narazíme na některé problémy, z nichž některé souvisí s konečným počtem bitů, které pro uložení dané hodnoty „obětujeme“ a další vycházejí ze způsobu zpracování numerických hodnot mikroprocesorem či matematickým koprocesorem. V konečném počtu bitů je totiž možné uložit pouze konečné množství různých hodnot (pro n bitů maximálně 2n hodnot, i když u mnohých formátů je to méně) a je plně v rukou programátora a návrháře HW, jak efektivně daný počet bitů využije či naopak promrhá ukládáním nepodstatných informací. Poměrně často se totiž stává, že i program využívající dvojitou či dokonce rozšířenou přesnost čísel při FP operacích (tj. datové typy double a extended/temporary) dává nesprávné výsledky dané nepochopením principu práce FP aritmetiky a přitom je možné se přesnějších výsledků dobrat i při použití pouhých 32 bitů či dokonce šestnácti bitů, ale s pečlivě vyváženými aritmetickými a bitovými operacemi.
Na druhou stranu nejsou dnes používané mikroprocesory tak univerzálními zařízeními, jak by se na první pohled mohlo zdát. Mikroprocesory jsou totiž (většinou) navrženy tak, aby účinně, například v rámci jedné operace či instrukce, zpracovávaly pouze konstantní počet bitů. Příkladem mohou být dnes velmi rozšířené procesory řady x86 a x86–64, které jsou velmi dobré při práci s 32bitovými, resp. 64bitovými hodnotami, ale při požadavku na aritmetické výpočty probíhající na (řekněme) 21 bitech se veškerá jejich efektivita ztrácí a procesor se širokými vnitřními sběrnicemi, matematickým koprocesorem atd. se potýká s prohazováním jednotlivých bitů. Podobně mnohé DSP dokážou velmi efektivně provádět výpočty s operandy o šířce 24 bitů, ovšem operace s jinými typy operandů nejsou prakticky podporovány vůbec. Mnohem lepší situace nastane v případě, že se nějaká operace implementuje na programovatelném poli FPGA – zde je možné vytvořit obvody provádějící matematické a logické operace s libovolným počtem bitů, čímž se oproti univerzálním řešením (např. konstantní bitová šířka sběrnice a/nebo registrů) ušetří mnoho plochy těchto velmi zajímavých obvodů (FPGA mohou mimochodem znamenat i velkou šanci pro hnutí open source – pomocí nich by mohlo vznikat, a někde už vzniká open hardware, které by mohlo odstranit závislost na „uzavřených“ síťových a grafických kartách apod.).
Vraťme se však ke způsobům reprezentace číselných hodnot v operační paměti. Nejprve předpokládejme, že pro reprezentaci vlastností určitého objektu či stavu z reálného světa použijeme N binárních číslic (bitů), tj. základních jednotek informace, která může nabývat pouze jedné ze dvou povolených hodnot (ty se značí například symboly yes/no nebo true/false, ale my se budeme spíše držet označení 0 a 1). Pomocí této uspořádané N-tice je možné popsat celkem:
20×21×22 … 2N-1=2N
jednoznačných, tj. navzájem odlišných, stavů. Množina těchto stavů může reprezentovat prakticky jakýkoliv abstraktní či reálný objekt. Přitom si musíme uvědomit, že u této množiny není implicitně řečeno ani myšleno, že se jedná například o celá kladná čísla, to je pouze jedna z mnoha možných interpretací zvolené N-tice (my programátoři máme tendenci považovat celá kladná čísla za přirozenou interpretaci bitové N-tice, to však vychází pouze z našeho pohledu na svět a z našich zkušeností). Reprezentaci momentálního stavu abstraktního či reálného objektu si můžeme představit jako zobrazení z množiny binárních stavů na elementy vzorové (a obecně neuspořádané) množiny. Nejčastěji používanými zobrazeními jsou zobrazení množiny binárních stavů na interval celých kladných čísel (Unsigned Integers), popřípadě na interval celých čísel (Signed Integers).
3. Uložení numerických hodnot ve formátu pevné řádové binární tečky
Numerické hodnoty zapsané ve formátu pevné řádové binární tečky se chápou jako podmnožina racionálních čísel, což jsou taková čísla, jejichž hodnoty lze vyjádřit vztahem:
xFX=a/b a,b leží v Z, b ≠ 0
Číselné hodnoty z uvažované podmnožiny jsou navíc omezeny podmínkou:
b=2k b leží v Z, k leží v Z+
Protože b je celočíselnou mocninou dvojky (a ne desítky či jiného základu), určuje jeho hodnota n polohu binární tečky v uloženém čísle. Další podmínkou, která má však spíše implementační charakter, je zachování stejného počtu binárních cifer v každém reprezentovaném čísle, což mimo jiné znamená, že všechna čísla mají řádovou binární tečku umístěnou na stejném místě – z této podmínky ostatně plyne i název popisovaného způsobu reprezentace vybrané podmnožiny racionálních čísel. Tak jako i v jiných reprezentacích čísel, jsou nulové číslice před první nenulovou cifrou a za poslední nenulovou cifrou nevýznamné, proto je není zapotřebí uvádět.
Prakticky může být číselná hodnota v systému pevné řádové tečky uložena na osmi bitech například následujícím způsobem (uvažujeme pouze kladné hodnoty):
| Pozice bitu | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| Váha bitu | 24 | 23 | 22 | 21 | 20 | 2-1 | 2-2 | 2-3 |
| Desítková váha bitu | 16 | 8 | 4 | 2 | 1 | 0,5 | 0,25 | 0,125 |
Ve výše uvedeném příkladu je binární řádová tečka umístěna vždy mezi třetím a čtvrtým bitem. Vzhledem k tomu, že je tato skutečnost dopředu známá algoritmu, který provádí zpracování čísel (základní aritmetické operace), není zapotřebí spolu s číslem uchovávat i pozici binární tečky, což výrazně snižuje počet bitů, které je zapotřebí rezervovat pro čísla ze zadaného rozsahu. To je tedy první přednost systému pevné řádové tečky – pokud programátor dopředu zná rozsah všech zpracovávaných hodnot a požadovanou přesnost, může být výhodné tento systém použít. Programátor také díky explicitním určení polohy řádové tečky může určit, ve kterém místě programu se musí přesnost či rozsah zvýšit a kdy naopak snížit. Lépe se tak využije počet bitů, které můžeme pro uložení jednoho čísla obětovat (typicky je tento počet bitů roven délce slova mikroprocesoru, popř. jeho celočíselnému násobku či naopak podílu).
Dále je možné základní matematické operace (sčítání, odčítání, násobení a dělení) poměrně jednoduše implementovat i při použití formátu pevné řádové tečky. V případě, že není k dispozici specializovaný (a současně velmi komplikovaný) matematický koprocesor, je mnohdy mnohem jednodušší a rychlejší implementovat matematické operace v FX formátu. To je případ mnoha jednočipových mikroprocesorů (mikrořadičů), signálových procesorů, ale i specializovaných zařízení obsahujících programovatelné obvody CPLD či FPGA. Dnes sice mají komplikovanější (a dražší) FPGA implementovanou i jednotku FPU, ale mnohdy je výhodnější použít FPGA bez této jednotky a potřebné operace si do tohoto obvodu „vypálit“ po svém.
Obrázek 1: Interní bloky DSP TMS32010, z nichž je patrné, že se násobení a posun dají provádět velmi efektivně (ostatně tento DSP vlastně není nic jiného, než podpůrné obvody postavené okolo rychlé násobičky).
Třetí výhodou je fakt, že u FX formátu může programátor navrhnout a posléze také dodržet požadovanou přesnost všech prováděných výpočtů. To je velký rozdíl oproti FP formátu (resp. jeho podmnožinám, které se nejčastěji používají). Není vzácností narazit na programy, které používají datové typy float či double a přitom jsou výpočty prováděné v těchto programech zatíženy velkou chybou, protože si programátoři plně neuvědomují některé limity FP formátu (příklady si ukážeme níže). Zcela kritické jsou například výpočty s peněžními hodnotami, ale i pouhé sčítání čísel, jež se od sebe o mnoho řádů liší, vede k velkým chybám, které dokonce mohou zapříčinit vznik nekonečných smyček, populární dělení nulou atd.
FX formát má však i mnohé nevýhody. První nevýhoda spočívá v tom, že tento formát není příliš podporován, a to ani po programové stránce (podpora v programovacích jazycích), ani výrobci mikroprocesorů pro počítače PC. Situace je však odlišná v oblasti jednočipových mikropočítačů, signálových procesorů (DSP), řídicích systémů, nebo například u IBM RS 6000, který kromě jednotky FPU obsahuje i FXU – jednotku pro provádění výpočtů v pevné řádové binární čárce. Na platformě x86 je možné pro FX formát použít instrukce MMX a SSE-2 (na rozdíl od původního SSE či AVX orientovaných na typy single a double).
Dále může být použití FX formátu nevýhodné v případě, že se mají zpracovávat numerické hodnoty, které mají velký dynamický rozsah, tj. poměr mezi nejvyšší a nejnižší absolutní hodnotou. V takovém případě by se mohlo stát, že by se při použití FX formátu muselo pro každé číslo alokovat velké množství bitů, které by mohlo dokonce překročit počet bitů nutných pro FP formát. Také v případě, kdy dopředu nevíme, jaké hodnoty se budou zpracovávat, může být výhodnější použití FP formátu. Zde se však nabízí otázka, ve kterých případech nevíme, jaké hodnoty můžeme na vstupu získat: většinou je již z podstaty úlohy dopředu známé, s čím je možné počítat a které hodnoty jsou naprosto nesmyslné. Je však pravdou, že takovou analýzu málokdo dělá a když při výpočtech ve floatech dochází k chybám, tak se bez přemýšlení program přepíše na doubly a problém se tak buď odstraní, nebo alespoň odsune na pozdější dobu, například do chvíle, kdy jsou programu předložena reálná data a ne „pouze“ data testovací.
4. Uložení čísel ve formátu plovoucí řádové (binární) tečky
Uložení racionálních čísel ve formátu plovoucí řádové tečky (FP formát) se od FX formátu odlišuje především v tom, že si každá numerická hodnota sama v sobě nese aktuální polohu řádové tečky. Z tohoto důvodu je kromě bitů, které musí být rezervovány pro uložení významných číslic numerické hodnoty, nutné pro každou numerickou hodnotu rezervovat i další bity, v nichž je určena mocnina o nějakém základu (typicky 2, 8, 10 či 16), kterou musí být významné číslice vynásobeny, resp. vyděleny. První část čísla uloženého v FP formátu se nazývá mantisa, druhá část exponent. Obecný formát uložení a způsob získání původního čísla je následující:
xFP=be×m
kde:
- xFX značí reprezentovanou numerickou hodnotu z podmnožiny reálných čísel
- b je báze, někdy také nazývaná radix
- e je hodnota exponentu (může být i záporná)
- m je mantisa, která může být i záporná
Konkrétní formát numerických hodnot reprezentovaných v systému plovoucí řádové tečky závisí především na volbě báze (radixu) a také na počtu bitů rezervovaných pro uložení mantisy a exponentu. V minulosti existovalo značné množství různých formátů plovoucí řádové tečky (vzpomíná si někdo například na Turbo Pascal s jeho šestibajtovým datovým typem real?), v relativně nedávné minulosti se však ustálilo použití formátů specifikovaných v normě IEEE 754. Ovšem, jak uvidíme dále, se ukazuje, že původní formáty definované v IEEE 754 nedostačují všem požadavkům, a to na obou stranách spektra (někdo požaduje vyšší přesnost/rozsah, jiný zase rychlost výpočtů a malé paměťové nároky). Proto došlo k rozšíření této normy o nové formáty a nezávisle na tom i na vývoji formátu bfloat16.
5. Formát plovoucí řádové binární tečky a norma IEEE 754
V oblasti FP formátů se dnes nejčastěji setkáme s výše zmíněnou normou IEEE 754, popř. jejími rozšířenými variantami. Norma IEEE 754 specifikuje nejenom vlastní formát uložení numerických hodnot v systému plovoucí řádové tečky, ale (a to je celkem neznámá skutečnost) i pravidla implementace operací s těmito hodnotami, včetně konverzí. Konkrétně je v této normě popsáno:
- Základní (basic) a rozšířený (extended) formát uložení numerických hodnot.
- Způsob provádění základních matematických operací:
- součet
- rozdíl
- součin
- podíl
- zbytek po dělení
- druhá odmocnina
- porovnání
- Režimy zaokrouhlování.
- Způsob práce s denormalizovanými hodnotami.
- Pravidla konverze mezi celočíselnými formáty (integer bez a se znaménkem) a formáty s plovoucí řádovou čárkou.
- Způsob konverze mezi různými formáty s plovoucí řádovou čárkou (single → double atd.).
- Způsob konverze základního formátu s plovoucí řádovou čárkou na řetězec číslic (včetně nekonečen a nečíselných hodnot).
- Práce s hodnotami NaN (not a number) a výjimkami, které mohou při výpočtech za určitých předpokladů vzniknout.

Obrázek 2: První čip, který používal formát definovaný v IEEE 754 – Intel 8087.
Zdroj: Wikipedia, Autor: Dirk Oppelt
V normě (přesněji řečeno v její rozšířené variantě IEEE 754–2008, resp. její poslední úpravě IEEE 754–2019) nalezneme mj. i tyto FP formáty:
| Označení | Šířka (b) | Báze | Exponent (b) | Mantisa (b) |
|---|---|---|---|---|
| IEEE 754 half | 16 | 2 | 5 | 10+1 |
| IEEE 754 single | 32 | 2 | 8 | 23+1 |
| IEEE 754 double | 64 | 2 | 11 | 52+1 |
| IEEE 754 double extended | 80 | 2 | 15 | 64 |
| IEEE 754 quadruple | 128 | 2 | 15 | 112+1 |
| IEEE 754 octuple | 256 | 2 | 19 | 236+1 |

Obrázek 3: Mikroprocesory Pentium i všechny další čipy řady 80×86 již implicitně obsahují plnohodnotný FPU. Zlé jazyky tvrdí, že u první řady Pentií byl FPU tak rychlý jen proto, že výsledky pouze odhadoval :-)
Typ single (nebo float, popř. float32) vypadá takto:
| bit | 31 | 30 29 … 24 23 | 22 21 … 3 2 1 0 |
|---|---|---|---|
| význam | s | exponent (8 bitů) | mantisa (23 bitů) |
Exponent je přitom posunutý o hodnotu bias, která je nastavena na 127, protože je použit výše uvedený vztah:
bias=2eb-1-1
a po dosazení eb=8 (bitů) dostaneme:
bias=28–1-1=27-1=128–1=127
Vzorec pro vyjádření reálné hodnoty vypadá následovně:
Xsingle=(-1)s × 2exp-127 × m
Rozsah hodnot, které je možné reprezentovat ve formátu jednoduché přesnosti v normalizovaném tvaru je –3,4×1038 až 3,4×1038. Nejnižší reprezentovatelná (normalizovaná) hodnota je rovna 1,17549×10-38, denormalizovaná pak 1,40129×10-45. Jak jsme k těmto hodnotám došli? Zkuste se podívat na následující vztahy:
| hexadecimální hodnota | výpočet FP | dekadický výsledek | normalizováno |
|---|---|---|---|
| 0×00000001 | 2-126×2-23 | 1,40129×10-45 | ne |
| 0×00800000 | 2-126 | 1,17549×10-38 | ano |
| 0×7F7FFFFF | (2–2-23)×2127 | 3,4×1038 | ano |
Formát s dvojitou přesností (double), který je definovaný taktéž normou IEEE 754, se v mnoha ohledech podobá formátu s jednoduchou přesností (single), pouze se zdvojnásobil celkový počet bitů, ve kterých je hodnota uložena, tj. místo 32 bitů se používá 64 bitů:
| bit | 63 | 62 … 52 | 51 … 0 |
|---|---|---|---|
| význam | s | exponent (11 bitů) | mantisa (52 bitů) |
Exponent je v tomto případě posunutý o hodnotu bias=2047 a vzorec pro výpočet reálné hodnoty vypadá takto:
Xdouble=(-1)s × 2exp-2047 × m
Přičemž hodnotu mantisy je možné pro normalizované hodnoty získat pomocí vztahu:
m=1+m51-1+m50-2+m49-3+…+m0-52
(mx představuje x-tý bit mantisy)
Rozsah hodnot ukládaných ve dvojité přesnosti je –1,7×10308..1,7×10308, nejmenší možná nenulová hodnota je rovna 2,2×10-308.
V novější normě IEEE 754–2008 je specifikován nepovinný formát nazvaný binary128, který se ovšem běžně označuje quadruple precision či jen quad precision. Tento formát je založen na slovech širokých 128 bitů (16 bajtů), která jsou rozdělena takto:
| bit | 127 | 126 … 112 | 111 … 0 |
|---|---|---|---|
| význam | s | exponent (15 bitů) | mantisa (112 bitů) |
Exponent je v tomto případě posunutý o hodnotu bias=16383. Dekadická přesnost u tohoto formátu dosahuje 34 cifer!
Jen krátce se zmiňme o poslední variantě FP formátu, který se nazývá binary256 či méně formálně octuple precision. Tento formát využívá slova o šířce plných 256 bitů (32 bajtů) s následujícím rozdělením:
| bit | 255 | 254 … 236 | 235 … 0 |
|---|---|---|---|
| význam | s | exponent (19 bitů) | mantisa (235 bitů) |
Exponent je v tomto případě posunutý o hodnotu bias=262143. Dekadická přesnost u tohoto formátu dosahuje 71 cifer, nejmenší (nenormalizovaná) reprezentovatelná hodnota rozdílná od nuly je přibližně 10−78984, maximální hodnota pak 1.611 ×1078913 (těžko říct, zda je takový rozsah vůbec reálně využitelný).
6. Přednosti a zápory formátu plovoucí řádové tečky
Vzhledem k tomu, že je FP formát v současnosti velmi rozšířený a používaný, musí nutně přinášet některé výhody, jinak by jeho rozšíření nebylo zdaleka tak velké. První předností je podpora FP operací díky hardwarovým FPU jednotkám, které jsou dostupné jak ve formě samostatného matematického koprocesoru (původně Intel 8087, Intel i80287, Intel i80387, Intel i80487, Motorola M68881, Motorola M68882), tak i jako přímá součást moderních mikroprocesorů (řada x86 od „plnohodnotných“ mikroprocesorů i486, Motorola M68040, Power PC, některé typy mikrořadičů a signálových procesorů atd.). Zapomenout nesmíme ani na další rozšíření instrukčních sad, které FP podporují: SSE-x (x86), VFP (ARM), NEON (ARM), rozšíření pro RISC-V (F, D, Q). Další předností je existence normy IEEE 754, ve které je mimo jiné řečeno i to, že každá FPU jednotka by měla podporovat ideálně dva formáty, například basic single a basic double. To je velmi důležité, zejména pro přenos numerických údajů mezi různými zařízeními. Pro mnoho programátorů je také výhodné to, že jeden základní datový typ (například float) je možné použít pro reprezentaci mnoha objektů či vlastností. Všechny tyto skutečnosti vedly k tomu, že FP formát (či možná lépe řečeno formáty) jsou v prakticky všech programovacích jazycích implementovány jako základní datové typy, což představuje velký náskok před FX formátem, který je podporován pouze několika málo jazyky a programovými knihovnami.
FP formát však má i některé zápory, které nás mohou v některých případech „donutit“ k použití nějakého alternativního formátu (FX, rational). První nevýhoda vychází z velké komplexnosti vlastního formátu, tj. způsobu rozdělení údajů na mantisu a exponent. I taková základní matematická operace, jako je součet, je kvůli FP formátu poměrně složitá a výsledek nemusí vždy odpovídat intuitivnímu cítění programátora, který má tendenci FP formát pokládat za ekvivalent reálných čísel („datový typ double je přesný…“). Mnoho programátorů se například chybně spoléhá na to, že i pouhý převod mezi typem int na single/float a zpět na int je bezeztrátový – pravý opak je pravdou a to vzhledem k tomu, že se ztratí hodnoty minimálně osmi nejnižších bitů, které musely být vyhrazeny pro uložení exponentu. FP formát, resp. formát specifikovaný normou IEEE 754, se vůbec nehodí pro práci s peněžními hodnotami; z tohoto důvodu se v některých vyšších programovacích jazycích zavádí speciální datový typ decimal, resp. currency, určený speciálně pro peněžní hodnoty.
Další nedostatek FP formátu souvisí s jeho značnou komplexností. Hardwarové jednotky FPU jsou relativně komplikované, což limituje použití FP operací v některých vestavných – embedded – zařízeních (těch je dnes řádově více než osobních počítačů). Dále se komplikuje a především zpomaluje převod mezi FP formáty a celočíselnými formáty dat (integer, long). Z tohoto důvodu jsou například mnohé signálové procesory zkonstruovány tak, aby podporovaly pouze FX aritmetiku, protože jak na vstupu signálového procesoru, tak i na jeho výstupu jsou prakticky vždy celočíselné hodnoty a pouze převody mezi vstupem, interní reprezentací a výstupem by byly mnohdy komplikovanější než implementace veškerých výpočtů v FX reprezentaci.
Jen pro zajímavost si zkuste vyplnit následující tabulku pro tři proměnné různých typů, jejichž hodnota není rovna NaN:
int x = ...; float f = ...; double d = ...;
Které tvrzení (výraz) je pravdivý a který nepravdivý a proč?:
| Tvrzení | Je pravdivé? |
|---|---|
| x == (int)(float) x | ano/ne |
| x == (int)(double) x | ano/ne |
| f == (float)(double) f | ano/ne |
| d == (float) d | ano/ne |
| f == -(-f); | ano/ne |
| 2/3 == 2/3.0 | ano/ne |
| d < 0.0 ⇒ ((d*2) < 0.0) | ano/ne |
| d > f ⇒ -f > -d | ano/ne |
| d * d >= 0.0 | ano/ne |
| (d+f)-d == f | ano/ne |
7. Datový formát half (half float, half-precision floating-point) a další FP formáty s nižším počtem bitů
Zatímco výše zmíněné formáty single a double jsou určeny pro běžné aritmetické výpočty a při správném použití mohou být využity v mnoha numerických algoritmech, začal být společně s rozšiřováním grafických akcelerátorů vyvíjen tlak na standardizaci formátů s menší bitovou hloubkou. Je tomu tak z toho důvodu, že některé operace (již jsme se zmínili o paměti hloubky, ovšem i operace s barvami pixelů atd.) někdy vyžadují vyšší dynamický rozsah, ovšem přesnost nemusí být vysoká a více nám záleží na rychlosti provádění operací.
Dobrým příkladem je dnes již pochopitelně dávno překonaný, ovšem z hlediska vývoje IT velmi důležitý grafický akcelerátor Voodoo I, resp. přesněji řečeno způsob implementace jeho paměti hloubky. Do paměti hloubky (Z-bufferu) je možné ukládat vzdálenosti fragmentů od pozorovatele (kamery) ve dvou formátech, v obou případech je však každý údaj vždy uložen na šestnácti bitech. Při použití prvního způsobu se do Z-bufferu skutečně ukládají vzdálenosti fragmentů, přesněji řečeno celočíselná část vzdálenosti (výpočty vzdálenosti se provádí přesněji, ale výsledek je při ukládání zaokrouhlen). Tento formát není příliš výhodný, protože po projekci 3D scény ze světových souřadnic do prostoru obrazovky není krok mezi jednotlivými vzdálenostmi konstantní, což vede k vizuálním chybám při vykreslování (rozlišení pouze 216 vzdáleností je v tomto případě nedostatečné). Z tohoto důvodu se preferuje druhý způsob (nazývaný také w-buffer), při němž se do Z-bufferu ukládají převrácené hodnoty vzdálenosti, a to ve speciálním formátu čísel s pohyblivou řádovou tečkou (čárkou), který má následující strukturu připomínající formát definovaný v IEEE 754 (viz předchozí kapitoly):
1.mantissa × 2exponent
V tomto formátu je pro mantisu vyhrazeno dvanáct bitů a pro exponent čtyři bity. Povšimněte si implicitní jedničky před desetinnou tečkou i toho, že žádný bit není vyhrazen pro uložení znaménka – vzdálenosti (a samozřejmě i jejich převrácené hodnoty) jsou vždy kladné. Minimální hodnota, kterou lze tímto způsobem uložit, je rovna jedničce (0×0000 ~ 1.0000000000002×20), maximální hodnota 65528.0 (0×ffff ~ 1.1111111111112×215). Podobné „krátké“ formáty čísel s plovoucí řádovou tečkou jsou v oblasti grafických akcelerátorů velmi oblíbené. NVidia a firma Microsoft zavedla typ half do jazyka Cg (v roce 2002), ILM podporuje tento formát pro operace vyžadující velkou dynamiku (rozsah) hodnot atd.
Tento formát používá pro ukládání FP hodnot pouhých šestnáct bitů, tj. dva byty. Maximální hodnota je rovna 65504 (FFE016=11111111111000002), minimální hodnota (větší než nula) přibližně 5,9×10-8. Předností tohoto formátu je malá bitová šířka (umožňuje paralelní přenos po interních sběrnicích GPU) a také větší rychlost zpracování základních operací, protože pro tak malou bitovou šířku mantisy je možné některé operace „zadrátovat“ a nepočítat pomocí ALU. Také některé iterativní výpočty (sin, cos, sqrt) mohou být provedeny rychleji, než v případě plnohodnotných typů float a single.
| Celkový počet bitů (bytů): | 16 (2) |
| Bitů pro znaménko: | 1 |
| Bitů pro exponent: | 5 |
| Bitů pro mantisu: | 10 |
| BIAS (offset exponentu): | 15 |
| Přesnost: | 5–6 číslic |
| Maximální hodnota: | 65504 |
| Minimální hodnota: | –65504 |
| Nejmenší kladná nenulová hodnota: | 5,96×10-8 |
| Nejmenší kladná normalizovaná hodnota: | 6,104×10-5 |
| Podpora +∞: | ano |
| Podpora -∞: | ano |
| Podpora NaN: | ano |
8. Podpora datového typu half
Datový typ s poloviční přesností nalezneme v mnoha GPU. Příkladem mohou být čipy s jádrem VideoCore, které nalezneme v populárních jednodeskových mikropočítačích Raspberry Pi:
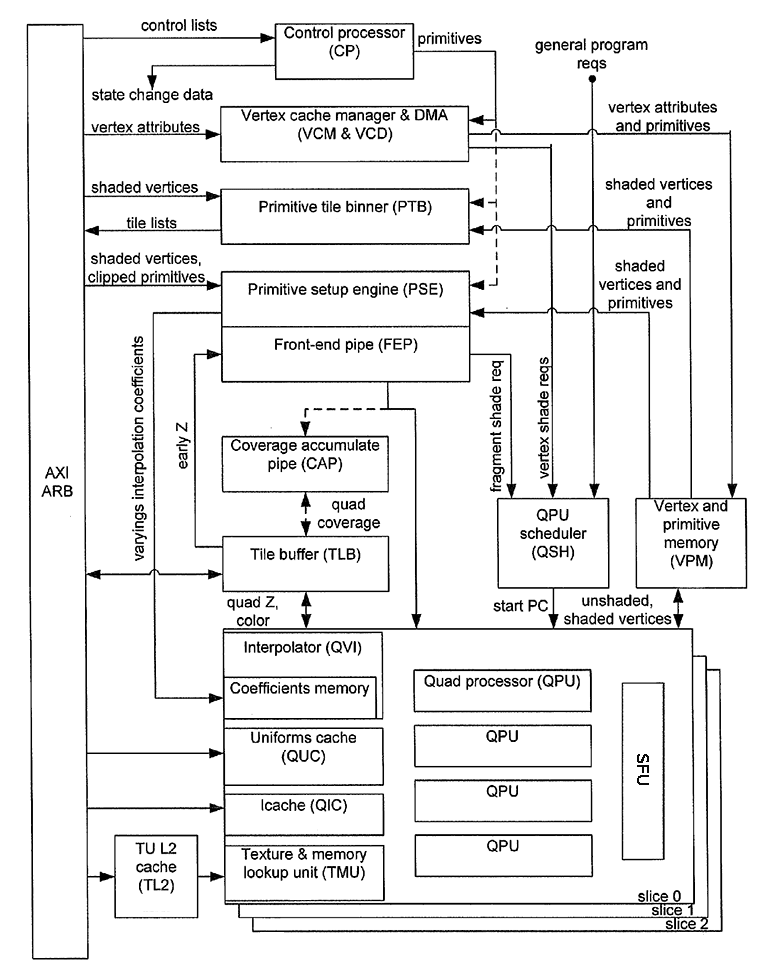
Obrázek 4: Schéma GPU VideoCore.
Na předchozím obrázku můžeme vidět koncepci VideoCore. Na jednu stranu se nejedná ani o univerzálně programovatelný čip s maticí nezávisle pracujících CPU, na stranu druhou to ale není pevně nakonfigurovaný 3D akcelerátor. Některé moduly, které VideoCore obsahuje, jsou určeny čistě pro provádění 2D a 3D grafických operací a je možné je pouze překonfigurovat, nikoli přeprogramovat (Front-End Pipe, Interpolator, celý koncept Z-bufferu atd.). Některé moduly pracují s vertexy (vrcholy) zpracovávaných grafických primitiv, další moduly naopak zpracovávají fragmenty, tj. data popisující jeden pixel, který se má zapsat do framebufferu. Zajímavostí je použití TLB (Tile Bufferu), který zde z důvodů lepší škálovatelnosti nahrazuje přímý přístup do klasického framebufferu. Ovšem z hlediska programování obecných algoritmů nejsou tyto bloky většinou podstatné; důležitější jsou programovatelné QPU neboli Quad Processor Unit(s) a k nim přidružené pomocné moduly (QPU je název používaný společností Broadcom, obecný název pro tento typ programovatelných modulů je shader).
Všechny QPU mají stejnou interní strukturu a skládají se z několika bloků:
- Banky A s 32 pracovními registry. Každý registr má šířku 32 bitů.
- Banky B, taktéž s 32 pracovními registry. Každý registr má šířku 32 bitů.
- Sady šesti akumulátorů (na schématu chybí šestý akumulátor r5, ten je z pohledu QPU určen jen pro čtení, z pohledu programátora naopak představuje možnost, jak do QPU přenést data)
- První ALU orientovanou na operaci násobení (+ na operace hledání minima, maxima atd.).
- První ALU orientovanou na operaci sčítání (+ na bitové posuny, logické operace, součty a rozdíly se saturací).
- Několik multiplexorů, které vybírají ty vstupní registry, jenž se mají použít jako operandy v ALU.
- Moduly označené packer a unpacker zajišťují základní konverze dat (32bitový registr totiž může obsahovat skalární hodnotu či vektor).
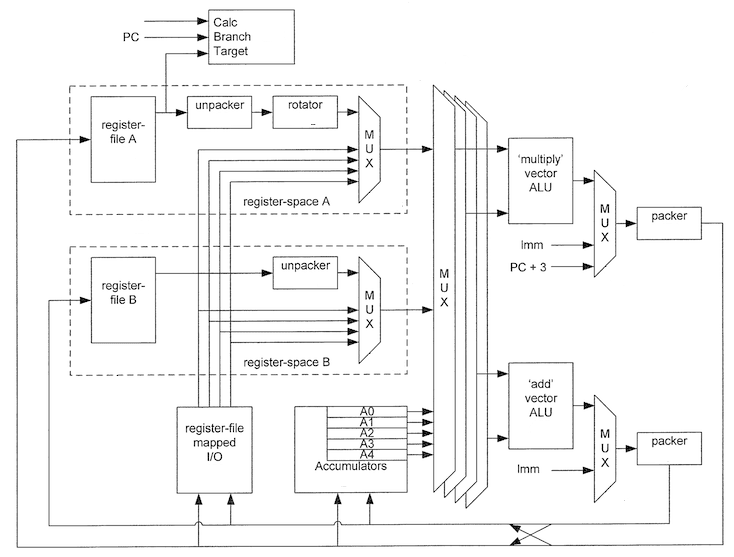
Obrázek 5: Interní struktura každého QPU (zjednodušená, nejsou zde naznačeny řezy pipeline atd.).
Z obrázku číslo 5 je patrné, že každý QPU obsahuje dvě samostatně pracující aritmeticko-logické jednotky, přičemž první jednotka provádí operace součtu a druhá jednotka především operaci součinu. ALU tedy nejsou zcela symetrické. Kromě operace součtu dvou vektorů (32bitová FP operace) může první ALU provádět bitové posuny, logické operace a v neposlední řadě taktéž vektorové součty a rozdíly se saturací (myšleny jsou zde součty a rozdíly prováděné prvek po prvku, výpočty se saturací jsou obzvlášť výhodné při zpracování signálů). Druhá aritmeticko-logická jednotka dokáže kromě násobení dvou 32bitových FP hodnot provést součet prvků dvou vektorů, rozdíl prvků, výpočet minima (prvek po prvku), výpočet maxima a taktéž násobení vektorů prvek po prvku.
Co je ovšem v kontextu tohoto článku důležité: QPU mohou zpracovávat data v několika různých formátech. Vždy však platí, že do první i druhé aritmeticko-logické jednotky vstupují hodnoty přečtené z 32 bitových registrů či z akumulátorů (tyto hodnoty se označují termínem vektor, i když se ve skutečnosti může jednat o skalární hodnotu). Každou 32bitovou hodnotu je možné interpretovat jako:
- 32bitová hodnota typu celé číslo (integer)
- 32bitová FP hodnota (single/float)
- 16bitová celočíselná hodnota se znaménkem
- 16bitová FP hodnota (má poněkud omezený repertoár operací)
- 8bitová celočíselná hodnota bez znaménka (čtyři hodnoty/prvky mohou tvořit vektor)
- 8bitová hodnota reprezentující barvovou složku v rozsahu 0,0 až 1,0 (čtyři složky tvoří barvu)
Práce s 16bitovými FP hodnotami je obecně rychlejší, než u 32bitových hodnot typu single, takže lze překonat i udávanou výkonnost čipů v GFLOPS.
9. Knihovna NumPy
Formát half je podporován i v knihovně NumPy, kde se s ním setkáme pod jménem float16. V následující tabulce jsou vypsány základní datové formáty podporované touto knihovnou:
| Formát | Popis | Rozsah |
|---|---|---|
| bool | uloženo po bajtech | True/False |
| int8 | celočíselný se znaménkem | –128..127 |
| int16 | celočíselný se znaménkem | –32768..32767 |
| int32 | celočíselný se znaménkem | –2147483648..2147483647 |
| int64 | celočíselný se znaménkem | –9223372036854775808..9223372036854775807 |
| uint8 | celočíselný bez znaménka | 0..255 |
| uint16 | celočíselný bez znaménka | 0..65535 |
| uint32 | celočíselný bez znaménka | 0..4294967295 |
| uint64 | celočíselný bez znaménka | 0..18446744073709551615 |
| float16 | plovoucí řádová čárka | poloviční přesnost (half) |
| float32 | plovoucí řádová čárka | jednoduchá přesnost (single) |
| float64 | plovoucí řádová čárka | dvojitá přesnost (double) |
| complex64 | komplexní číslo (dvojice) | 2×float32 |
| complex128 | komplexní číslo (dvojice) | 2×float64 |
10. Programovací jazyk Julia
Formát plovoucí řádové čárky s poloviční přesností se používá i v některých programovacích jazycích. Příkladem je programovací jazyk Julia, mezi jehož základními datovými typy nalezneme i typ nazvaný float16. Všechny primitivní datové typy tohoto jazyka jsou vypsány v následující tabulce, typ s poloviční přesností na prvním řádku:
primitive type Float16 <: AbstractFloat 16 end primitive type Float32 <: AbstractFloat 32 end primitive type Float64 <: AbstractFloat 64 end primitive type Bool <: Integer 8 end primitive type Char <: AbstractChar 32 end primitive type Int8 <: Signed 8 end primitive type UInt8 <: Unsigned 8 end primitive type Int16 <: Signed 16 end primitive type UInt16 <: Unsigned 16 end primitive type Int32 <: Signed 32 end primitive type UInt32 <: Unsigned 32 end primitive type Int64 <: Signed 64 end primitive type UInt64 <: Unsigned 64 end primitive type Int128 <: Signed 128 end primitive type UInt128 <: Unsigned 128 end

Obrázek 6: Logo programovacího jazyka Julia.
11. Proč používat typ half float?
V předchozím textu jsme se dozvěděli, že se formát s poloviční přesností používá na některých GPU a nalezneme ho v programovacím jazyku Julia i v knihovně NumPy. Všechny tyto tři technologie mají jednu věc společnou – používají se (či mohou používat) pro numerické výpočty, a to mnohdy vysoce výpočetně náročné výpočty, u nichž je nutné zajistit co nejvyšší výpočetní výkon. A právě na GPU, popř. na specializovaném hardware (superpočítače) se datový typ half float poměrně dobře prosadil, pochopitelně u některých typů výpočtů, popř. jen v některé části celé „pipeline“.
Výkon se nezvyšuje pouze tím, že operace mohou být provedeny rychleji, ale taktéž vyšším využitím cache, omezením přístupu k pomalé operační paměti či dokonce k ještě pomalejším diskům.
Příkladem může být jeden z nejvýkonnějších superpočítačů na světě – stroj SUMMIT. Při použití standardního benchmarku založeného na LINPACKu a tedy i formátu double, dosahuje výpočetní výkon přibližně 148 petaFLOPS, tedy číselně 148×1015 FLOPS. Ovšem pokud se provádí výpočty s typem half float, je výpočetní výkon o několik řádů vyšší, konkrétně 3,3×1018 FLOPS, tedy v řádu exaFLOPS!
12. Vlastnosti typu half float
Při návrhu formátu half float se jeho tvůrci snažili o vyvážení dvou protichůdných požadavků – zajistit relativně slušnou přesnost výpočtů a současně i umožnit velký dynamický rozsah hodnot. V případě formátů double či quadruple je zajištění obou požadavků poměrně snadné, protože je k dispozici velký počet bitů, které lze rozdělit mezi mantisu a exponent, ovšem u formátu half float s pouhými šestnácti dostupnými bity (jeden z nich je navíc rezervován pro uložení znaménka) nutně muselo dojít ke kompromisům. Tvůrci formátu half float v tomto případě upřednostnili spíše přesnost výpočtů, resp. přesnost ukládaných hodnot, a proto bylo pro mantisu rezervováno celých deset bitů a pro exponent pouze bitů pět. Vyzkoušejme si nyní základní vlastnosti tohoto formátu na jednoduchém testu – výpočtu součtu harmonické řady. Ta je divergentní, což bylo ostatně dokázáno již ve čtrnáctém století. Ovšem při naivním výpočtu této řady se ukazují některé nepříjemné vlastnosti hodnot s plovoucí řádovou čárkou. Ostatně to bude patrné na výpočtu této řady, kterou lze realizovat jak s hodnotami typu double, tak i s hodnotami typu float a pochopitelně i half float.
Realizace výpočtu s hodnotami typu double, což je typ, který v implementačním jazyce (Go) má odlišné jméno float64. Ve výpočtu zjišťujeme, kdy je již další přičítaný člen z důvodu velkého dynamického rozsahu (mezisoučet versus hodnota n-tého prvku) považován za tak malou hodnotu (relativně k prvnímu operandu) že již může být výpočet ukončen:
package main
import "fmt"
func main() {
var n uint64 = 1
var h1 float64 = 0.0
var h2 float64 = 0.0
for true {
h2 = h1 + 1.0/float64(n)
if n%10000000 == 0 {
fmt.Printf("%f %f %20.18f %d\n", h1, h2, h2-h1, n)
}
if h1 == h2 {
break
}
h1 = h2
n++
}
fmt.Printf("Done:\n%f %f %d\n", h1, h2, n)
}
Tento program po několika dnech skončí s těmito (pochopitelně nesprávnými) hodnotami:
34.122 34.122 cca 281000000000000
Při použití typu single (v Go float32) je výpočet ukončen po pár sekundách, pochopitelně opět s nesprávným výsledkem:
package main
import "fmt"
func main() {
var n uint64 = 1
var h1 float32 = 0.0
var h2 float32 = 0.0
for true {
h2 = h1 + 1.0/float32(n)
if n%1000 == 0 {
fmt.Printf("%f %f %10.8f %d\n", h1, h2, h2-h1, n)
}
if h1 == h2 {
break
}
h1 = h2
n++
}
fmt.Printf("Done:\n%f %f %d\n", h1, h2, n)
}
Z výsledků je patrné, že se iterační výpočet ukončí již po přibližně dvou milionech iterací, protože přesnost i rozsah typu single je menší, než u typu double:
7.484478 7.485478 0.00099993 1000 8.177869 8.178369 0.00049973 2000 8.583423 8.583756 0.00033379 3000 ... ... ... 15.401630 15.401631 0.00000095 2095000 15.402584 15.402585 0.00000095 2096000 15.403538 15.403539 0.00000095 2097000 Done: 15.403683 15.403683 2097152
A konečně se dostáváme k typu half float. Sice se nejedná o základní datový typ programovacího jazyka Go, ale převody na typ half float (v Go označované float16) zajišťuje knihovna github.com/x448/float16:
package main
import (
"fmt"
"github.com/x448/float16"
)
func main() {
var n uint64 = 1
h1 := float16.Fromfloat32(0.0)
h2 := float16.Fromfloat32(0.0)
for true {
h2 = float16.Fromfloat32(h1.Float32() + 1.0/float32(n))
fmt.Printf("%-11s %-11s %10.8f %d\n", h1.String(), h2.String(), h2.Float32()-h1.Float32(), n)
if h1 == h2 {
break
}
h1 = h2
n++
}
fmt.Printf("Done:\n%s %s %d\n", h1.String(), h2.String(), n)
}
Výsledky běhu tohoto demonstračního příkladu ukazují, že malá přesnost i rozsah se projeví velmi negativně na celém výpočtu. Ten je ukončen již po pouhých 513 iteracích, což znamená, že v kontextu výpočtu je již 1/512 považováno za nulovou hodnotu:
0 1 1.00000000 1 1 1.5 0.50000000 2 1.5 1.8330078 0.33300781 3 1.8330078 2.0820312 0.24902344 4 2.0820312 2.28125 0.19921875 5 2.28125 2.4472656 0.16601562 6 2.4472656 2.5898438 0.14257812 7 2.5898438 2.7148438 0.12500000 8 2.7148438 2.8261719 0.11132812 9 2.8261719 2.9257812 0.09960938 10 ... ... ... 7.0585938 7.0625 0.00390625 506 7.0625 7.0664062 0.00390625 507 7.0664062 7.0703125 0.00390625 508 7.0703125 7.0742188 0.00390625 509 7.0742188 7.078125 0.00390625 510 7.078125 7.0820312 0.00390625 511 7.0820312 7.0859375 0.00390625 512 7.0859375 7.0859375 0.00000000 513 Done: 7.0859375 7.0859375 513
import numpy as np
h1 = np.float64(0)
h2 = np.float64(0)
n = 1
while True:
h2 = h1 + np.float64(1)/np.float64(n)
if n%1000000 == 0:
print(h1, h2, h2-h1, n)
if h1 == h2:
break
h1 = h2
n += 1
print(h1, h2, n)
import numpy as np
h1 = np.float32(0)
h2 = np.float32(0)
n = 1
while True:
h2 = h1 + np.float32(1)/np.float32(n)
if n%1000 == 0:
print(h1, h2, h2-h1, n)
if h1 == h2:
break
h1 = h2
n += 1
print(h1, h2, n)
import numpy as np
h1 = np.float16(0)
h2 = np.float16(0)
n = 1
while True:
h2 = h1 + np.float16(1)/np.float16(n)
print(h1, h2, h2-h1, n)
if h1 == h2:
break
h1 = h2
n += 1
print(h1, h2, n)
13. Na scénu přichází formát bfloat16
Konečně se dostáváme k popisu formátu nazvaného bfloat16. Jak jsme se již zmínili v úvodní kapitole, byl tento dosti nový formát navržen zejména s ohledem na jeho použití v oblasti strojového učení a taktéž pro použití v takzvaných „chytrých“ senzorech (popravdě: jedná se o módní výraz používaný pro senzor, jehož hodnota je zpracovávána mikrořadičem umístěným poblíž senzoru; posléze bývá takto zpracovaná hodnota poslána do dalších prvků systému). U senzorů je význam formátu patrný – umožňuje v relativně malém množství bitů ukládat hodnoty v poměrně velkém rozsahu a mnohdy s požadovanou přesností (když uvážíme chyby měření, chyby při A/D převodu atd. atd.). V případě strojového učení si musíme uvědomit, že trénovací a ověřovací množiny dat bývají obrovské, takže se zde může projevit úzké hrdlo ve formě paměti, rychlosti disku apod. Snížení počtu bitů na polovinu (oproti formátu single) se tedy ve výpočtech, zejména při tréninku může projevit mnohonásobně, což ostatně uvidíme dále na grafu.
Jak tedy formát bfloat16 interně vypadá? Jedná se o formát, v němž jsou numerické hodnoty ukládány do slov o šířce pouhých šestnácti bitů, což je stejná šířka, jakou jsme již měli možnost vidět u formátu half float. Liší se ovšem způsob alokace bitů. Nejvyšší bit je stále používán pro uložení znaménka (signum), následuje osm bitů pro reprezentaci exponentu (posunutého o bias, jak je tomu ostatně u dalších FP formátů) a zbývajících (pouhých!) sedm bitů je použito pro uložení mantisy.
Vlastnosti bfloat16 z pohledu programátora jsou ukázány v další tabulce:
| Celkový počet bitů (bytů): | 16 (2) |
| Bitů pro znaménko: | 1 |
| Bitů pro exponent: | 8 |
| Bitů pro mantisu: | 7 |
| BIAS (offset exponentu): | 127 |
| Přesnost: | 3–4 číslice |
| Maximální hodnota: | 3.38953139 × 1038 (nepatrně méně, než u single) |
| Minimální hodnota: | –3.38953139 × 1038 |
| Nejmenší kladná nenulová hodnota: | 9.2 × 10−41 |
| Nejmenší kladná normalizovaná hodnota: | 1.18 × 10-38 |
| Podpora +∞: | ano |
| Podpora -∞: | ano |
| Podpora NaN: | ano |
14. Příklady reprezentace některých důležitých konstant ve formátu bfloat16
Příklady některých důležitých konstant:
| S | Exponent | Mantisa | Dekadicky |
|---|---|---|---|
| 0 | 00000000 | 00000000 | +0 |
| 1 | 00000000 | 00000000 | −0 |
| 0 | 11111111 | 0000000 | +∞ |
| 1 | 11111111 | 0000000 | −∞ |
| 0 | 11111111 | ne nuly | +NaN (1000001 – quiet NaN, jinak signalling NaN) |
| 1 | 11111111 | ne nuly | −NaN |
| 0 | 11111110 | 1111111 | 3.38953139 × 1038 (největší číslo, které ještě není nekonečno) |
| 0 | 00000001 | 0000000 | 1.18 × 10-38 (nejmenší normalizované číslo, které ještě není nula) |
| 0 | 01111111 | 0000000 | 1,0 (přesně) |
| 0 | 10000000 | 0000000 | 2,0 (přesně) |
| 0 | 10001000 | 1111010 | 1000 |
| 0 | 01111011 | 1001101 | 0,1 (pochopitelně nepřesně – zde nám ovšem nepomůže ani double) |
| 0 | 10000000 | 1001001 | π (přibližně 3,140625) |
15. Vztah mezi formáty single, half a bfloat16
Zajímavé je porovnání tří formátů bfloat16, half float a single, a to z toho důvodu, že bfloat16 přebírá své vlastnosti z obou dvou zmíněných formátů. Podívejme se na následující tabulku:
| Formát | single | half | bfloat16 |
|---|---|---|---|
| znaménko | 1 bit | 1 bit | 1 bit |
| exponent | 8 bitů | 5 bitů | 8 bitů |
| mantisa | 23 bitů | 10 bitů | 7 bitů |
| celkem | 32 bitů | 16 bitů | 16 bitů |
| bias | 127 | 15 | 127 |
Z tabulky je patrné, že formát bfloat16 vlastně vznikl z formátu single pouhým odstraněním druhého šestnáctibitového slova s nižšími bity mantisy. Co to ovšem znamená v praxi? Rozsah hodnot reprezentovaných formátem bfloat16 je vyšší, než je tomu u formátu half float (kde maximální hodnota dosahovala pouze 65504 a minimální denormalizovaná hodnota rozdílná od nuly 5.96 × 10-8), ovšem přesnost je zcela zásadním způsobem snížená. Pro běžné numerické výpočty se tedy nemusí jednat o ideální řešení, protože chyby při výpočtu budou mnohem větší, než je tomu u ostatních dnes popisovaných formátů. Na druhou stranu v situaci, kdy nám na přesnosti výpočtů příliš nezáleží a především potřebujeme větší rozsah hodnot a navíc je hodnot obrovské množství, může být tento formát dobrou volbou (některé hodnoty v neuronových sítích zdaleka nemusí mít obrovskou přesnost – viz například obrázek z tohoto článku). Dokonce se v oblasti ML ukazuje, že nepřesnosti vzniklé malým počtem bitů mantisy mohou učení sítí vylepšit, protože přidávají určitou „náhodnost“.
16. (Ne)přesnost výpočtů při použití formátu bfloat16
V předchozím textu jsme si řekli, že přesnost (tedy počet reprezentovatelných cifer) je u formátu bfloat16 dosti drastickým způsobem snížena. To má vliv na všechny výpočty. Pro ilustraci se pokusme přepsat již výše uvedený výpočet součtu harmonické řady do algoritmu, který do určité míry simuluje chování formátu bfloat16 (ovšem ne zcela přesně). V tomto konkrétním případě výpočet převedeme do programovacího jazyka C, v němž se dobře pracuje s uniemi (union):
#include <stdio.h>
#include <inttypes.h>
typedef union {
float f;
uint32_t i;
} bfloat16mock;
int main(void) {
long n = 1;
bfloat16mock h1;
bfloat16mock h2;
h1.f = 0.0;
h2.f = 0.0;
while (1) {
h2.f = h1.f + 1.0 / (float)n;
h2.i &= 0xffff8000;
printf("%f %f %10.8lf %ld\n", h1.f, h2.f, h2.f-h1.f, n);
if (h1.f == h2.f) break;
h1 = h2;
n++;
}
printf("%f %f %ld\n", h1.f, h2.f, n);
return 0;
}
Na průběhu výpočtu, který je tak krátký, že si ho uvedeme celý, je patrné, že hodnoty 1/n se poměrně brzy začnou zaokrouhlovat na tak malou hodnotu, že výpočet bude v této chvíli ukončen (protože se při přičtení tak malé hodnoty k mezisoučtu nový mezisoučet nezmění):
0.000000 1.000000 1.00000000 1 1.000000 1.500000 0.50000000 2 1.500000 1.832031 0.33203125 3 1.832031 2.078125 0.24609375 4 2.078125 2.273438 0.19531250 5 2.273438 2.437500 0.16406250 6 2.437500 2.578125 0.14062500 7 2.578125 2.703125 0.12500000 8 2.703125 2.812500 0.10937500 9 2.812500 2.906250 0.09375000 10 2.906250 2.992188 0.08593750 11 2.992188 3.070312 0.07812500 12 3.070312 3.140625 0.07031250 13 3.140625 3.210938 0.07031250 14 3.210938 3.273438 0.06250000 15 3.273438 3.335938 0.06250000 16 3.335938 3.390625 0.05468750 17 3.390625 3.445312 0.05468750 18 3.445312 3.492188 0.04687500 19 3.492188 3.539062 0.04687500 20 3.539062 3.585938 0.04687500 21 3.585938 3.625000 0.03906250 22 3.625000 3.664062 0.03906250 23 3.664062 3.703125 0.03906250 24 3.703125 3.742188 0.03906250 25 3.742188 3.773438 0.03125000 26 3.773438 3.804688 0.03125000 27 3.804688 3.835938 0.03125000 28 3.835938 3.867188 0.03125000 29 3.867188 3.898438 0.03125000 30 3.898438 3.929688 0.03125000 31 3.929688 3.960938 0.03125000 32 3.960938 3.984375 0.02343750 33 3.984375 4.000000 0.01562500 34 4.000000 4.015625 0.01562500 35 4.015625 4.031250 0.01562500 36 4.031250 4.046875 0.01562500 37 4.046875 4.062500 0.01562500 38 4.062500 4.078125 0.01562500 39 4.078125 4.093750 0.01562500 40 4.093750 4.109375 0.01562500 41 4.109375 4.125000 0.01562500 42 4.125000 4.140625 0.01562500 43 4.140625 4.156250 0.01562500 44 4.156250 4.171875 0.01562500 45 4.171875 4.187500 0.01562500 46 4.187500 4.203125 0.01562500 47 4.203125 4.218750 0.01562500 48 4.218750 4.234375 0.01562500 49 4.234375 4.250000 0.01562500 50 4.250000 4.265625 0.01562500 51 4.265625 4.281250 0.01562500 52 4.281250 4.296875 0.01562500 53 4.296875 4.312500 0.01562500 54 4.312500 4.328125 0.01562500 55 4.328125 4.343750 0.01562500 56 4.343750 4.359375 0.01562500 57 4.359375 4.375000 0.01562500 58 4.375000 4.390625 0.01562500 59 4.390625 4.406250 0.01562500 60 4.406250 4.421875 0.01562500 61 4.421875 4.437500 0.01562500 62 4.437500 4.453125 0.01562500 63 4.453125 4.468750 0.01562500 64 4.468750 4.468750 0.00000000 65 4.468750 4.468750 65
0.000000 1.000000 1.00000000 1 1.000000 1.500000 0.50000000 2 1.500000 1.828125 0.32812500 3 1.828125 2.078125 0.25000000 4 2.078125 2.265625 0.18750000 5 2.265625 2.421875 0.15625000 6 2.421875 2.562500 0.14062500 7 2.562500 2.687500 0.12500000 8 2.687500 2.796875 0.10937500 9 2.796875 2.890625 0.09375000 10 2.890625 2.968750 0.07812500 11 2.968750 3.046875 0.07812500 12 3.046875 3.109375 0.06250000 13 3.109375 3.171875 0.06250000 14 3.171875 3.234375 0.06250000 15 3.234375 3.296875 0.06250000 16 3.296875 3.343750 0.04687500 17 3.343750 3.390625 0.04687500 18 3.390625 3.437500 0.04687500 19 3.437500 3.484375 0.04687500 20 3.484375 3.531250 0.04687500 21 3.531250 3.562500 0.03125000 22 3.562500 3.593750 0.03125000 23 3.593750 3.625000 0.03125000 24 3.625000 3.656250 0.03125000 25 3.656250 3.687500 0.03125000 26 3.687500 3.718750 0.03125000 27 3.718750 3.750000 0.03125000 28 3.750000 3.781250 0.03125000 29 3.781250 3.812500 0.03125000 30 3.812500 3.843750 0.03125000 31 3.843750 3.875000 0.03125000 32 3.875000 3.890625 0.01562500 33 3.890625 3.906250 0.01562500 34 3.906250 3.921875 0.01562500 35 3.921875 3.937500 0.01562500 36 3.937500 3.953125 0.01562500 37 3.953125 3.968750 0.01562500 38 3.968750 3.984375 0.01562500 39 3.984375 4.000000 0.01562500 40 4.000000 4.000000 0.00000000 41 4.000000 4.000000 41
17. Možné urychlení výpočtů s formátem bfloat16 a využití kombinace více formátů
V případě, že se ML algoritmy provozují na hardware (dnes nejspíše na specializovaném GPU), který formát bfloat16 podporuje, mohou být výpočty skutečně mnohdy významným způsobem urychleny, což je ostatně patrné i na dalším grafu:
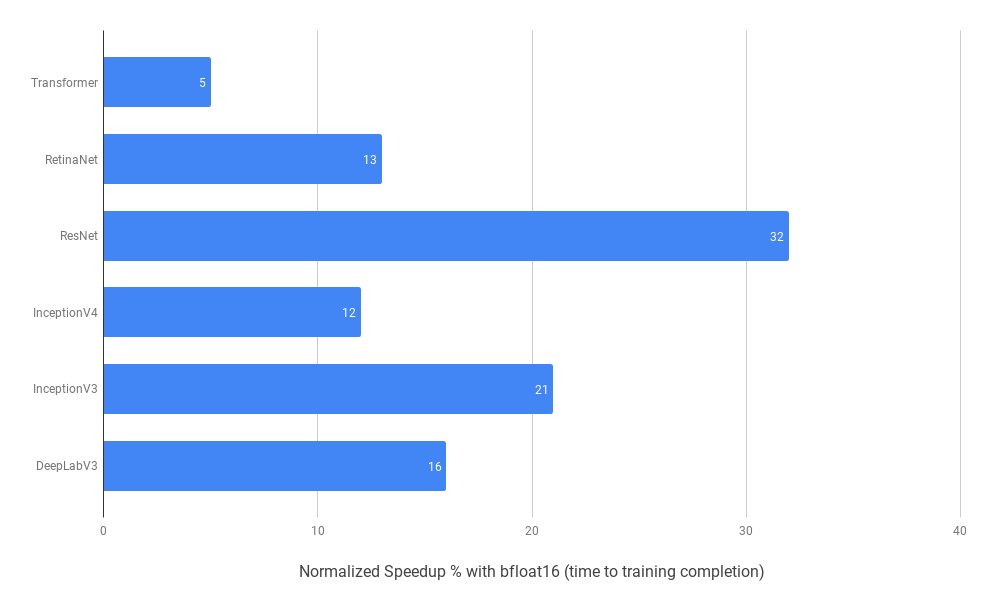
Obrázek 7: Urychlení aplikací ML, konkrétně průběhu tréninku.
Zdroj: https://cloud.google.com/tpu/docs/bfloat16
18. Rozšíření formátu bfloat16
Na závěr se ještě zmiňme o podpoře formátu bfloat16. Nejdříve se zaměříme na hardware, tedy na mikroprocesory a GPU, které tento formát nativně podporují. Samotný formát bfloat16 je poměrně nový, takže si teprve postupně hledá cestu pro začlenění jak do samotného hardware (mikroprocesorů a GPU), tak i do širší množiny programovacích jazyků, knihoven a frameworků. Formát bfloat je již začleněn do nových „AI procesorů“ společnosti Intel. Mezi ně patří například Nervana NNP-L1000 atd. Dále se s tímto typem setkáme u výkonných procesorů Xeon, protože do rozšíření instrukční sady AVX-512 byly přidány tři instrukce označované souhrnně AVX-512_BF16. Jedná se konkrétně o instrukce s nezapamatovatelnými názvy VCVTNE2PS2BF16, VCVTNEPS2BF16 a VDPBF16PS (časy, kdy jsme si v assembleru vystačili s třípísmennými zkratkami, jsou u platformy x86 dávnou minulostí). Důležitější je pravděpodobně podpora v TPU (tensor processing unit) a tím pádem i v knihovně TensorFlow. To ovšem není vše, protože se bfloat objevuje/objeví i v čipech s architekturou ARMv8.6-A atd.
Důležitá je samozřejmě i podpora formátu bfloat16 v programovacích jazycích, knihovnách a frameworcích. Zde se situace postupně zlepšuje, zejména pokud si uvědomíme, že se jedná o poměrně nový formát. Některé knihovny, například knihovna half-rs určená pro programovací jazyk Rust, jsou určeny pouze pro převod numerických dat z a do bfloat16 s tím, že se zkonvertované hodnoty použijí především při ukládání vstupních dat (trénovací množiny, …), samotných neuronových sítí atd. Samotné výpočty s bfloat16 však nejsou podporovány. Ovšem pochopitelně nalezneme i knihovny a frameworky, které začínají bfloat16 plně podporovat. Jedná se mnohdy o ty knihovny, které slouží pro spuštění výpočtů na GPU. Již jsme se zmínili o podpoře v TensorFlow, ale například i v balíčku BFloat16s určeném pro jazyk Julia.

19. Formáty „minifloat“ použité ve výuce, online nástroje
Jen pro úplnost se zmiňme o tom, že existují i formáty s plovoucí řádovou čárkou, které používají pro uložení numerických hodnot pouhý jeden bajt. V těchto případech je razantně sníženo jak rozlišení, tak přesnost. Tyto formáty sice mohou mít svůj význam (některá čidla), ovšem setkáme se s nimi zejména při výuce vlastností FP formátů, protože právě na hodnotách uložených v jediném bajtu, tedy při maximálním počtu 256 kombinací, je možné snadno ukázat všechny důležité vlastnosti FP formátů, zejména pak:
- Existenci kladné a záporné nuly
- Nerovnoměrného rozložení reprezentovatelných hodnot na číselné ose
- Denormalizovaných hodnot
- Kladného a záporného nekonečna
- Hodnot typu NaN (Not a Number)
- Zaokrouhlovacích algoritmů
Mezi zajímavé online nástroje pro studium FP formátů patří:
- Mediump float calculator (volba šířky mantisy a exponentu)
- Float Exposed (lze si vybrat i BFloat16)
20. Odkazy na Internetu
- Why Intel is betting on BFLOAT16 to be a game changer for deep learning training? Hint: Range trumps Precision
https://hub.packtpub.com/why-intel-is-betting-on-bfloat16-to-be-a-game-changer-for-deep-learning-training-hint-range-trumps-precision/ - half-rs (pro Rust)
https://github.com/starkat99/half-rs - float16 (pro Go)
https://github.com/x448/float16 - bfloat16 – Hardware Numerics Definition
https://software.intel.com/en-us/download/bfloat16-hardware-numerics-definition - Intel Prepares To Graft Google’s Bfloat16 Onto Processors
https://www.nextplatform.com/2019/07/15/intel-prepares-to-graft-googles-bfloat16-onto-processors/ - A Study of BFLOAT16 for Deep Learning Training
https://arxiv.org/pdf/1905.12322.pdf - BFloat16s.jl
https://github.com/JuliaComputing/BFloat16s.jl - Half Precision Arithmetic: fp16 Versus bfloat16
https://nhigham.com/2018/12/03/half-precision-arithmetic-fp16-versus-bfloat16/ - bfloat16 floating-point format (Wikipedia)
https://en.wikipedia.org/wiki/Bfloat16_floating-point_format - Unum (number format)
https://en.wikipedia.org/wiki/Unum_(number_format)#Posit - Performance Benefits of Half Precision Floats
https://software.intel.com/en-us/articles/performance-benefits-of-half-precision-floats - Norma IEEE 754 a příbuzní: formáty plovoucí řádové tečky
https://www.root.cz/clanky/norma-ieee-754-a-pribuzni-formaty-plovouci-radove-tecky/ - IEEE-754 Floating-Point Conversion
http://babbage.cs.qc.cuny.edu/IEEE-754.old/32bit.html - Small Float Formats
https://www.khronos.org/opengl/wiki/Small_Float_Formats - Binary-coded decimal
https://en.wikipedia.org/wiki/Binary-coded_decimal - Chen–Ho encoding
https://en.wikipedia.org/wiki/Chen%E2%80%93Ho_encoding - Densely packed decimal
https://en.wikipedia.org/wiki/Densely_packed_decimal - A Summary of Chen-Ho Decimal Data encoding
http://speleotrove.com/decimal/chen-ho.html - Art of Assembly language programming: The 80×87 Floating Point Coprocessors
https://courses.engr.illinois.edu/ece390/books/artofasm/CH14/CH14–3.html - Art of Assembly language programming: The FPU Instruction Set
https://courses.engr.illinois.edu/ece390/books/artofasm/CH14/CH14–4.html - INTEL 80387 PROGRAMMER'S REFERENCE MANUAL
http://www.ragestorm.net/downloads/387intel.txt - Floating-Point Formats
http://www.quadibloc.com/comp/cp0201.htm - Data types (SciPy)
https://docs.scipy.org/doc/numpy-1.13.0/user/basics.types.html - New 16-bit floating point type – NumPy 1.6.0 Release Notes
https://github.com/numpy/numpy/blob/7cfec2403486456b52b525eccf7541e1562d9ab3/doc/release/1.6.0-notes.rst#new-16-bit-floating-point-type - RFC pro Rust
https://github.com/joshtriplett/rfcs/blob/f16b/text/0000-f16b.md - IEEE-754 Floating Point Converter
https://www.h-schmidt.net/FloatConverter/IEEE754.html - Mediump float calculator
https://oletus.github.io/float16-simulator.js/ - IEEE 754 Calculator
http://weitz.de/ieee/ - BFloat16 (Swift for TensorFlow)
https://www.tensorflow.org/swift/api_docs/Structs/BFloat16 - Using bfloat16 with TensorFlow models
https://cloud.google.com/tpu/docs/bfloat16 - What is tf.bfloat16 “truncated 16-bit floating point”?
https://stackoverflow.com/questions/44873802/what-is-tf-bfloat16-truncated-16-bit-floating-point - BFloat16 processing for Neural Networks on Armv8-A
https://community.arm.com/developer/ip-products/processors/b/ml-ip-blog/posts/bfloat16-processing-for-neural-networks-on-armv8_2d00_a - Mixed precision training
https://arxiv.org/pdf/1710.03740.pdf - [R] Mixed Precision Training
https://www.reddit.com/r/MachineLearning/comments/75phd2/r_mixed_precision_training/ - Floating Point Numbers
https://floating-point-gui.de/formats/fp/ - Float exposed
https://float.exposed/0×40490000 - Float Toy
http://evanw.github.io/float-toy/ - IEEE-754 visualization
https://bartaz.github.io/ieee754-visualization/ - Advantages Of BFloat16 For AI Inference
https://semiengineering.com/advantages-of-bfloat16-for-ai-inference/ - ARMv8-A bude podporovat nový formát čísel BFloat16
https://www.root.cz/zpravicky/armv8-a-bude-podporovat-novy-format-cisle-bfloat16/ - Intel oznámil nový formát BFloat16 pro budoucí procesory
https://www.root.cz/zpravicky/intel-oznamil-novy-format-bfloat16-pro-budouci-procesory/ - Nový formát čísel Intelu BFloat16 bude v GCC 10 a Clang 9
https://www.root.cz/zpravicky/novy-format-cisel-intelu-bfloat16-bude-v-gcc-10-a-clang-9/ - Mixed precision
https://www.tensorflow.org/guide/keras/mixed_precision - Training Performance: A user’s guide to converge faster (TensorFlow Dev Summit 2018)
https://www.youtube.com/watch?v=SxOsJPaxHME - Programování GPU na Raspberry Pi: použití Quad Processor Unit(s)
https://www.root.cz/clanky/programovani-gpu-na-raspberry-pi-pouziti-quad-processor-unit-s/ - “Half Precision” 16-bit Floating Point Arithmetic
https://blogs.mathworks.com/cleve/2017/05/08/half-precision-16-bit-floating-point-arithmetic/ - Half Precision Arithmetic in Numerical Linear Algebra
https://nla-group.org/2018/10/03/half-precision-arithmetic-in-numerical-linear-algebra/ - Enable BF16 support
https://gcc.gnu.org/ml/gcc-patches/2019–04/msg00477.html - Survey of Floating-Point Formats
https://mrob.com/pub/math/floatformats.html


