
Obsah
1. Jupyter Notebook – nástroj pro programátory, výzkumníky i lektory
2. Technologie, na níž je projekt Jupyter Notebook založen
3. Architektura Jupyter Notebooku
4. Podporované programovací jazyky
5. Instalace Jupyter Notebooku
6. Konfigurace a spuštění Jupyter Notebooku
7. Další často používané balíčky
8. Přímé použití Jupyter Notebooku bez instalace
11. Načtení dat uložených ve formátu CSV
13. Zobrazení dat ve formě grafů
15. Zobrazení diáře (notebooku) přímo na GitHubu
1. Jupyter Notebook – nástroj pro programátory, výzkumníky i lektory
V dnešním článku si popíšeme velmi užitečný a přitom snadno ovladatelný nástroj nazvaný Jupyter Notebook, který uživatelům (a zdaleka se nemusí jednat pouze o vývojáře) používajícím programovací jazyk Python (popř. některý další jazyk zmíněný dále) zpřístupňuje interaktivní prostředí založené na použití webového rozhraní. Jupyter Notebook vznikl z neméně známého a používaného projektu IPython Notebook(s). Toto interaktivní prostředí, které se zobrazuje přímo ve webovém prohlížeči, obsahuje klasickou smyčku REPL (Read–Eval–Print–Loop), což mj. znamená, že se jednotlivé výrazy zapsané uživatelem mohou ihned vyhodnocovat s prakticky okamžitou zpětnou vazbou. Navíc však nástroj Jupyter Notebook dokáže do okna prohlížeče vykreslovat tabulky, grafy či různé obrázky, a to jak s přímým využitím předaných dat (vektory či sekvence čísel), tak i při specifikaci funkce, jejíž průběh se má vykreslit (existují zde ovšem některá omezení, kterými se budu zabývat v navazujících kapitolách). Třešničkou na dortu je podpora pro práci se vzorci psanými v TeXu či LaTeXu, tvorba slajdů, sdílení „živého“ zdrojového kódu atd.
Obrázek 1: Klasický IPython notebook – jedná se o nástroj, který umožňoval interaktivní ovládání interpretru Pythonu z GUI, nabízel všechny možnosti konzolového IPythonu a navíc i podporoval práci s grafickými objekty (rastrové obrázky, grafy, diagramy atd.).
Celé grafické uživatelské rozhraní Jupyter Notebooku napodobuje diář (notebook), do kterého se zapisují jak poznámky, tak i případný programový kód a jeho výsledek, takže se tento systém může hodit i pro tvorbu (interaktivních) prezentací, použití sdílené pracovní plochy, zápis postupů, na nichž jsou jednotlivé výpočty založeny atd. Ostatně v tomto ohledu není přístup zvolený autory nijak nový ani přelomový, protože například i populární Matlab používá podobnou technologii (i když založenou na jiném programovacím jazyku).
 D
D
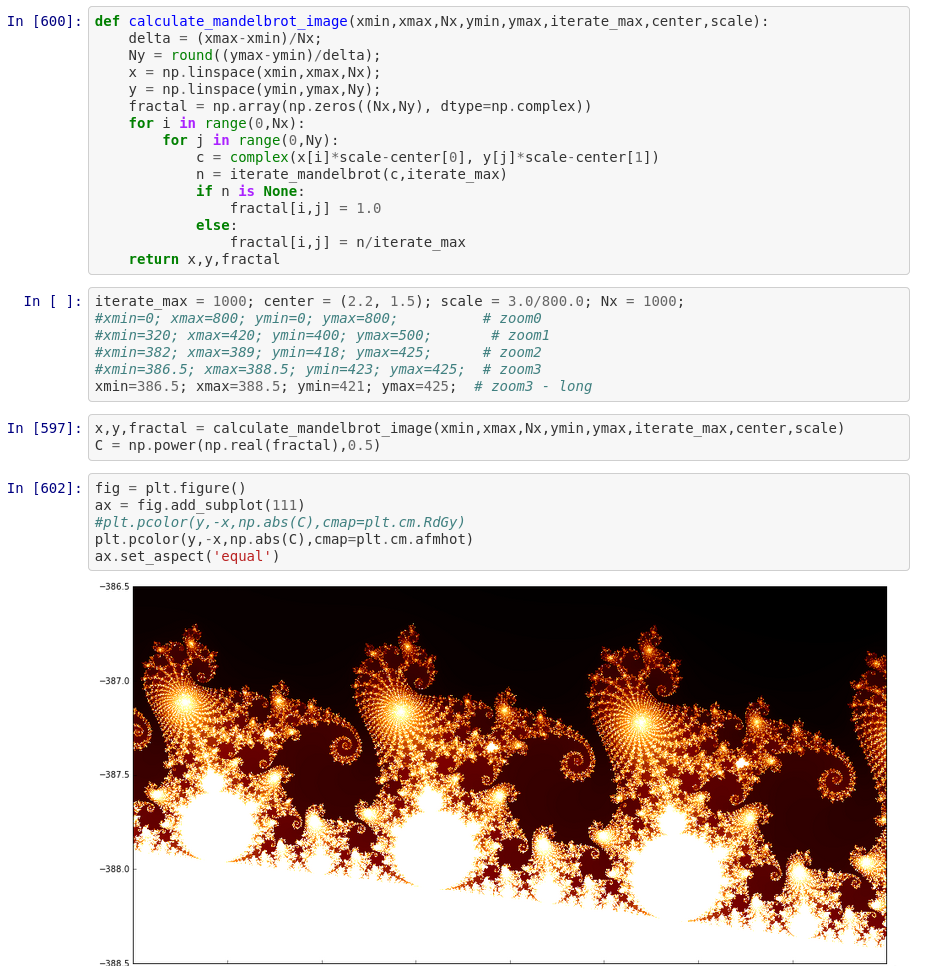
Obrázek 2: Použití Pythonu v Jupyteru při výpočtu fraktálů. Složitější numerické výpočty jsou jednou z oblastí, v níž by bylo výhodnější použít jiný programovací jazyk, resp. přesněji jeho jádro propojené s Jupyterem (Julia, Go, C/C++).
Zdroj
2. Technologie, na níž je projekt Jupyter Notebook založen
Nástroj Jupyter Notebook je založen na klasické technologii klient-server, kde klientem je webový prohlížeč spuštěný u uživatele (či uživatelů) a serverem je Jupyter s přidaným modulem (takzvaným kernelem) pro zvolený programovací jazyk nebo jazyky (my dnes budeme používat Python) – celá architektura je zmíněna v navazující kapitole). Výraz, popř. blok výrazů představujících programový kód napsaný ve zvoleném programovacím jazyce, je po stlačení klávesové zkratky Shift+Enter přenesen na server, kde je zpracován a výsledek je poslán zpět do prohlížeče.
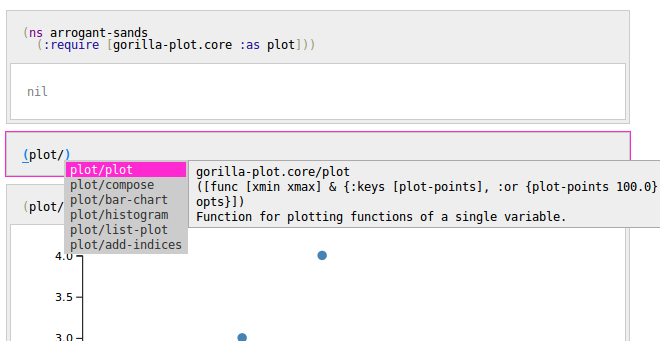
Obrázek 3: Nástroj Gorilla REPL obsahuje podporu pro doplňování názvů funkcí a maker společně se zobrazením nápovědy (programové dokumentace). Jedná se o nástroj založený na stejném paradigmatu jako dnes popisovaný Jupyter Notebook, ovšem Gorilla REPL je primárně určen pro jazyk Clojure zatímco Jupyter Notebook je více univerzální.
JavaScriptový kód na straně prohlížeče zajistí interpretaci získaných výsledků a jejich zařazení na správné místo do dynamické webové stránky (jedná se vlastně o variantu na dnes tak populární SPA – Single-Page Application se všemi přednostmi a pochopitelně i zápory, které toto řešení přináší). Výsledky poslané serverem na klienta mohou být ve skutečnosti různého typu; typicky se jedná o fragment HTML (tabulky atd.), obrázek typu SVG (graf, histogram), rastrový obrázek (graf získaný například ze systému R), vzorec vykreslený z TeXového či LaTeXového zdrojového kódu, animace či video (různé formáty) apod. Samotná architektura nástroje Jupyter je otevřená a poměrně snadno rozšiřitelná, což znamená, že je v případě potřeby možné přidat například další typy grafů apod.
Existují i podobně koncipované projekty. Na stránkách Rootu již vyšel článek o projektu Gorilla REPL, který je určen pro programovací jazyk Clojure – s tímto projektem se ve stručnosti seznámíme v sedmnácté kapitole.
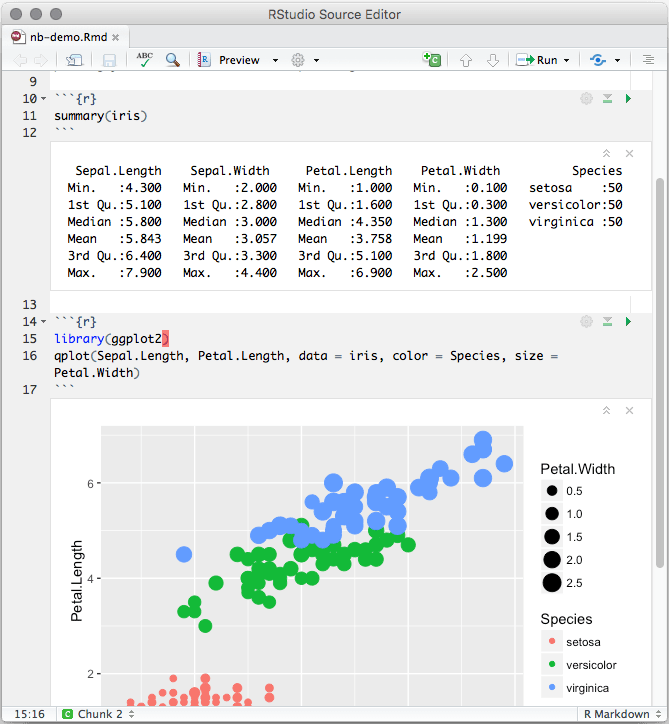
Obrázek 4: Dalším podobným projektem je R Markdown notebook.
Zdroj: dokumentace k projektu dostupná na https://bookdown.org/yihui/rmarkdown/notebook.html
3. Architektura Jupyter Notebooku
Jak jsme si již řekli v úvodní kapitole, vznikl projekt Jupyter Notebook rozšířením původního projektu nazvaného IPython Notebooks. V případě Jupyter Notebooku musely být provedeny některé změny v celé architektuře, a to především z toho důvodu, aby bylo možné podporovat různé programovací jazyky, další typy specializovaných kernelů apod. Základem je IPython Kernel, který přijímá zprávy (příkazy, které se mají vykonat) přes ØMQ, vykonává tyto příkazy a výsledky posílá zpět přes ØMQ (povšimněte si, že v tomto případě samotný kernel vůbec nezajímá, kdo příkazy posílal):
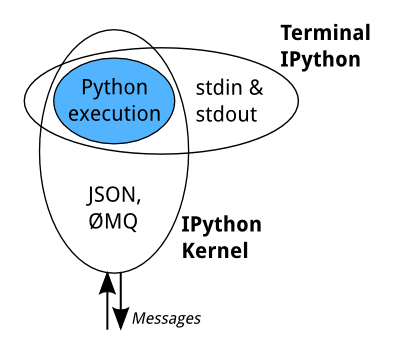
Obrázek 5: IPython Kernel a jeho navázání na ØMQ (popř. alternativní přístup přes standardní vstupně-výstupní operace přístupné přes terminál).
Zdroj: How IPython and Jupyter Notebook work
IPython Kernel podporuje – což asi není při přečtení jeho jména velkým překvapením – programovací jazyk Python. Ovšem přidat lze i další kernely (takzvané nativní kernely), které mohou podporovat další programovací jazyky. Alternativně není nutné vytvářet celý nový kernel (což může být komplikované kvůli nutnosti napojení na ØMQ atd.), ale lze použít přímo IPython Kernel tak, aby volal příkazy interpretru jiného programovacího jazyka. Teoreticky se sice nejedná o nejefektivnější řešení, ovšem musíme si uvědomit, že spouštěny budou příkazy zapisované přímo uživatelem a že tedy uživatel je „úzkým hrdlem“, ne výkonnost jednoho interpretru volaného z interpretru jiného:
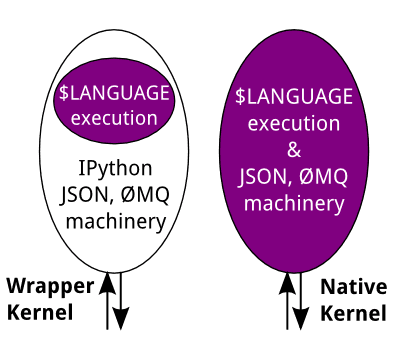
Obrázek 6: Dva způsoby, jakými je možné Jupyter rozšířit o další jazyky: nepřímo přes IPython a přímo nativním kernelem.
Zdroj: How IPython and Jupyter Notebook work
Máme tedy dva moduly – webové rozhraní (webový prohlížeč s JSA) a kernel či kernely. Tyto dva moduly nejsou propojeny přímo, protože mezi nimi leží Notebook server. Ten z jedné strany komunikuje s webovým rozhraním přes HTTP a WebSockety a ze strany druhé s kernelem/kernely přes ØMQ. Navíc server udržuje stav vlastního diáře. Toto řešení je snadno rozšiřitelné, může být provozováno na jednom stroji (což si ukážeme dále) či v „cloudu“ atd. Taktéž umožňuje spolupráci na jednom diáři, prezentaci živých výsledků apod.:
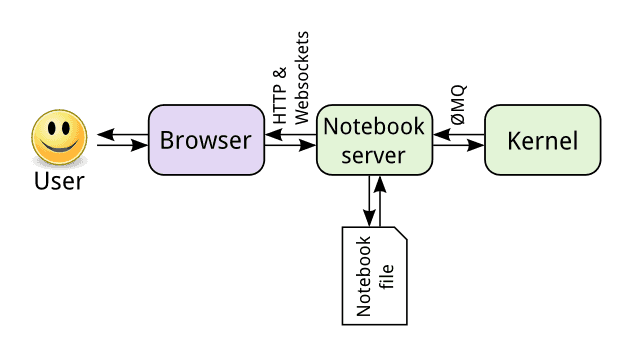
Obrázek 7: Připojení vlastního uživatelského rozhraní (založeného na webovém klientu) k serveru a propojení serveru s kernelem (kernely).
Zdroj: How IPython and Jupyter Notebook work
4. Podporované programovací jazyky
Pro projekt Jupyter vznikla celá řada kernelů, z nichž mnohé podporují další programovací jazyky (i když Python bude pravděpodobně stále nejpoužívanějším jazykem). Jedná se například o následující jazyky:
| # | Kernel | Jazyk |
|---|---|---|
| 1 | Dyalog Jupyter Kernel | APL (Dyalog) |
| 2 | Coarray-Fortran | Fortran 2008/2015 |
| 3 | IJulia | Julia |
| 4 | IHaskell | ghc >= 7.6 |
| 5 | IRuby | ruby >= 2.3 |
| 6 | tslab | Typescript 3.7.2, JavaScript ESNext |
| 7 | IJavascript | nodejs >= 0.10 |
| 8 | ITypeScript | Typescript >= 2.0 |
| 9 | jpCoffeescript | coffeescript >= 1.7 |
| 10 | jp-LiveScript | livescript >= 1.5 |
| 11 | ICSharp | C# 4.0+ |
| 12 | IFSharp | F# |
| 13 | lgo | Go >= 1.8 |
| 14 | iGalileo | Galileo >= 0.1.3 |
| 15 | gopherlab | Go >= 1.6 |
| 16 | Gophernotes | Go >= 1.9 |
| 17 | IScala | Scala |
| 18 | IErlang | Erlang |
| 19 | ITorch | Torch 7 (LuaJIT) |
| 20 | IElixir | Elixir >= 1.5 |
| 21 | ierl | Erlang >= 19, Elixir >= 1.4, LFE 1.2 |
| 22 | OCaml-Jupyter | OCaml >= 4.02 |
| 23 | IForth | Forth |
| 24 | peforth | Forth |
| 25 | IPerl | Perl 5 |
| 26 | Perl6 | Perl 6.c |
| 27 | IPerl6 | Perl 6 |
| 28 | Jupyter-Perl6 | Perl 6.C |
| 29 | IPHP | PHP >= 5.4 |
| 30 | Jupyter-PHP | PHP >= 7.0.0 |
| 31 | IOctave | Octave |
| 32 | IScilab | Scilab |
| 33 | MATLAB Kernel | Matlab |
| 34 | Bash | bash |
| 35 | Z shell | zsh >= 5.3 |
| 36 | PowerShell | PowerShell |
| 37 | CloJupyter | Clojure >= 1.7 |
| 38 | jupyter-kernel-jsr223 | Clojure 1.8 |
| 39 | Hy Kernel | Hy |
| 40 | Calysto Hy | Hy |
| 41 | jp-babel | Babel |
| 42 | Lua Kernel | Lua |
| 43 | IPurescript | Purescript |
| 44 | IPyLua | Lua |
| 45 | ILua | Lua |
| 46 | Calysto Scheme | Scheme |
| 47 | Calysto Processing | Processing.js >= 2 |
| 48 | idl_kernel | IDL |
| 49 | Mochi Kernel | Mochi |
| 50 | Lua (used in Splash) | Lua |
| 51 | Calysto Bash | bash |
| 52 | IBrainfuck | Brainfuck |
| 53 | cling | C++ |
| 54 | xeus-cling | C++ |
| 55 | Prolog | Prolog |
| 56 | SWI-Prolog | SWI-Prolog |
| 57 | cl-jupyter | Common Lisp |
| 58 | common-lisp-jupyter | Common Lisp |
| 59 | IJython | Jython 2.7 |
| 60 | ROOT | C++/python |
| 61 | Tcl | Tcl 8.5 |
| 62 | J | J 805–807 (J901beta) |
| 63 | Jython | Jython>=2.7.0 |
| 64 | C | C |
| 65 | Coconut | Coconut |
| 66 | Pike | Pike >= 7.8 |
| 67 | jupyter-kotlin | Kotlin 1.1-M04 EAP |
| 68 | mit-scheme-kernel | MIT Scheme 9.2 |
| 69 | elm-kernel | elm |
| 70 | SciJava Jupyter Kernel | Java + 9 scripting languages |
| 71 | BeakerX | Groovy, Java, Scala, Clojure, Kotlin, SQL |
| 72 | IJava | Java 9 |
| 73 | Guile | Guile 2.0.12 |
| 74 | IRacket | Racket >= 6.10 |
| 75 | EvCxR Jupyter Kernel | Rust >= 1.29.2 |
| 76 | SSH Kernel | Bash |
| 77 | Emu86 Kernel | Intel Assembly Language |
5. Instalace Jupyter Notebooku
Jupyter Notebook je možné nainstalovat hned několika způsoby, podle toho, zda se využijí balíčky dostupné přímo v repositáři dané linuxové distribuce nebo se použijí jiní správci balíčků (conda, pip). Prakticky všechny oficiálně podporované postupy instalace jsou zmíněny v diagramu umístěném na stránce https://jupyter.readthedocs.io/en/latest/projects/content-projects.html.
Ve Fedoře (27 a výše) lze instalaci provést příkazem (podobné to bude i v distribucích založených na debianních balíčcích, akorát se pochopitelně použije jiný nástroj než dnf):
$ sudo dnf install python3-notebook
Využít je možné i správce balíčků Conda. V případě, že tento nástroj používáte, bude instalace vypadat následovně:
$ conda install -c conda-forge notebook
A konečně lze použít i klasický pip nebo pip3 (v závislosti na tom, jaký je stav Pythonu 3 na daném operačním systému):
$ pip install notebook
V případě, že pip instaluje balíčky pro Python 2 a nikoli pro Python 3, použijeme:
$ pip3 install notebook
Použít je možné i spuštění v kontejneru. Konkrétně pro Docker je k dispozici hned několik obrazů Jupyter Notebooku, každý s rozdílnými kernely a dalšími moduly. Viz https://hub.docker.com/u/jupyter/#!.
6. Konfigurace a spuštění Jupyter Notebooku
Před prvním spuštěním Jupyter Notebooku je vhodné si nastavit heslo, které se bude zadávat pro přístup do UI:
$ jupyter notebook password Enter password: Verify password: [NotebookPasswordApp] Wrote hashed password to /home/ptisnovs/.jupyter/jupyter_notebook_config.json
Dále se již může Jupyter Notebook spustit, a to jednoduše příkazem jupyter notebook:
$ jupyter notebook [I 11:26:39.019 NotebookApp] Writing notebook server cookie secret to /run/user/1000/jupyter/notebook_cookie_secret [W 11:26:39.615 NotebookApp] WARNING: The notebook server is listening on all IP addresses and not using encryption. This is not recommended. [I 11:26:39.629 NotebookApp] Serving notebooks from local directory: /home/ptisnovs [I 11:26:39.629 NotebookApp] 0 active kernels [I 11:26:39.629 NotebookApp] The Jupyter Notebook is running at: [I 11:26:39.629 NotebookApp] http://[all ip addresses on your system]:8888/ [I 11:26:39.629 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation). [I 11:26:39.983 NotebookApp] 302 GET /tree (::1) 1.91ms
Pokud se zobrazí i řádky zvýrazněné kurzivou, znamená to, že server Jupyter Notebooku bude přístupný i ostatním počítačům na síti. Toto chování (někdy ho vyžadujeme) lze zakázat editací souboru ~/.jupyter/jupyter_notebook_config.json, konkrétně úpravou řádku s klíčem „ip“:
{
"NotebookApp": {
"password": "sha1:neco-tay-je",
"ip": "localhost"
}
}
Nové spuštění již nebude výše zvýrazněné varování psát:
$ jupyter notebook [I 11:26:39.019 NotebookApp] Writing notebook server cookie secret to /run/user/1000/jupyter/notebook_cookie_secret [I 11:26:39.629 NotebookApp] Serving notebooks from local directory: /home/ptisnovs [I 11:26:39.629 NotebookApp] 0 active kernels [I 11:26:39.629 NotebookApp] The Jupyter Notebook is running at: [I 11:26:39.629 NotebookApp] http://localhost:8888/ [I 11:26:39.629 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation). [I 11:26:39.983 NotebookApp] 302 GET /tree (::1) 1.91ms
Obrázek 8: Přihlašovací obrazovka.
7. Další často používané balíčky
Programovací jazyk Python je dnes oblíben mj. i proto, že nabízí celou sadu nástrojů použitelných v oblasti zpracování velkých dat, analýzu nestrukturovaných dat, strojové učení, umělé inteligence atd. Proto se v souvislosti s použitím Jupyter Notebooku ve výzkumu většinou ještě instalují další balíčky, zejména pak:
- Numpy je balíček zpřístupňující rychlé výpočty s vektory a maticemi. Viz například přednáška na LinuxDays 2019
- Pandas lze použít pro přípravu, čtení, zpracování strukturovaných dat získávaných z různých zdrojů
- Matplotlib je knihovna pro tvorbu konfigurovatelných grafů různých typů
- Seaborn je postavena nad Matplotlibem a zpřístupňuje statistické funkce (regresní křivky atd.)
- StatsModels nabízí lineární i logistickou regresi, i další skupinu algoritmů ARIMA
- Scikit-learn různé metody používané v oblasti strojového učení
- Imbalanced Learn používaná například pro detekci podvrhnutých dat (pokud je tato sada menší, než celá sada dat).
- NLTK neboli Natural Language toolkit pro zpracování méně strukturovaných textových dat, analýzu získávanou web crawlingem atd.
- Keras je (mj. ) vysokoúrovňové API pro deep learning
- TensorFlow pro práci s neuronovými sítěmi
- PyTorch framework pro strojové učení (podobné projektu Torch, který jsme si zde již představili)
Samotná instalace tedy může vypadat například následovně:
$ sudo dnf install python3-seaborn python3-lxml python3-basemap python3-scikit-image python3-scikit-learn python3-sympy python3-dask+dataframe python3-nltk
8. Přímé použití Jupyter Notebooku bez instalace
Ve skutečnosti není nutné ve všech případech provádět vlastní instalaci Jupyter Notebooku. Lze totiž využít již běžící server dostupný na adrese https://jupyter.org/try. V současnosti je k dispozici několik typů diářů, a to včetně diáře nazvaného „Classic Notebook“, který lze použít i pro příklad, s nímž se dnes seznámíme v rámci dalších kapitol.

Obrázek 9: Úvodní stránka zobrazená při přístupu na https://jupyter.org/try.

Obrázek 10: V některých okamžicích se diář nespustí z důvodu velkého zájmu dalších uživatelů o použití této služby.
9. Použití Markdownu
Vzhledem k tomu, že je možné projekt Jupyter použít i pro tvorbu prezentací, asi nás nepřekvapí, že je podporována tvorba poznámek, které mohou být naformátovány. Podporován je především známý a široce používaný formátovací jazyk Markdown. Podívejme se na následující příklad, v němž je Markdown použit pro zobrazení textu neproporcionálním písmem, tučným písmem a kurzivou:

Obrázek 11: Programové zobrazení textu v Markdownu přímým zavoláním funkce display.
Pro víceřádkový text lze změnit typ buňky, tj. typ vstupního řádku (In), který ve skutečnosti může obsahovat několikařádkový vstup:

Obrázek 12: Několikařádková buňka obsahující text zapsaný v Markdownu.
10. Matematická sazba
Podporována je i matematická sazba odvozená od možností TeXu a LaTeXu. Příkladem může být zápis vzorce s integrálem a zlomkem:
F(x) &= \int^a_b \frac{1}{3}x^3
Další dva příklady ukazují použití horních indexů (mocnin), zlomku a zápisu druhé odmocniny:
display(Math(r'x^2+y^2'))
display(Math(r'\frac{1}{\sqrt{x}}'))
Matematické vzorce lze do HTML stránky (a rozhraní Jupyter Notebooku je tvořeno dynamicky generovanou HTML stránkou) vkládat různými způsoby – jen s využitím možností samotného HTML (ovšem s ne zcela dobrým výsledkem), přes MathML až po vyrendrování obrázku se vzorcem:
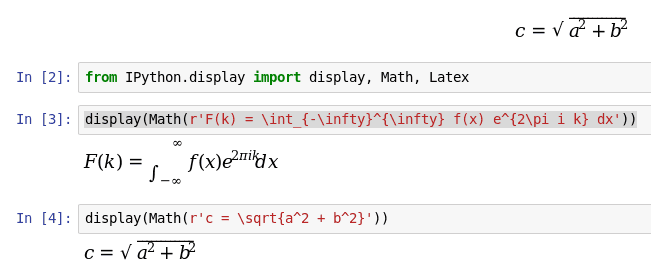
Obrázek 13: Vykreslení vzorců pomocí značek HTML není vždy optimální.
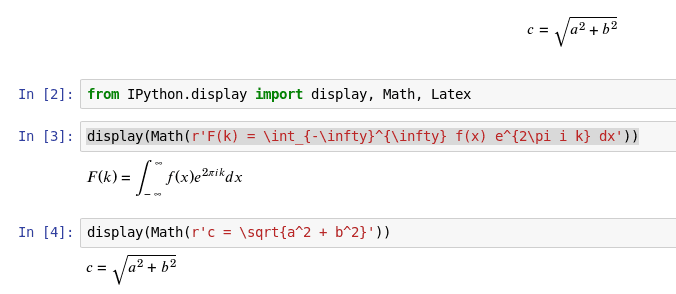
Obrázek 14: Použití MathML již vede k mnohem lepším výsledkům.

Obrázek 15: Nebo lze rendering (vykreslení) ponechat na LaTeXu.
11. Načtení dat uložených ve formátu CSV
V dalším textu si ukážeme jednoduchý diář s analýzou dat pro službu, která zpracovává data posílaná na vstup (a meziuložená v databázi), která je nutné analyzovat a poslat na výstup (opět například do databáze). Jedná se tedy o jednu z možných implementací „pipeline“. Diář je dostupný na adrese https://github.com/tisnik/jupyter-notebook-examples/blob/master/processing1.ipynb a můžete si ho otevřít ve vlastním Jupyter Notebooku (ideální je repositář naklonovat, protože obsahuje i datové soubory).
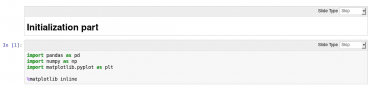
Obrázek 16: Import všech balíčků.
Načtení CSV souborů provedeme přes knihovnu Pandas zmíněnou výše. Jeden screenshot prý nahradí stovky (tisíce?) slov, takže jen krátce:
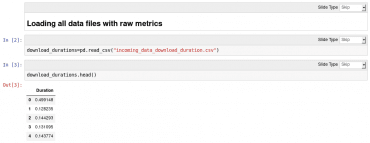
Obrázek 17: Načtení jednoho datového souboru ve formátu CSV.
12. Základní analýza dat
S využitím knihovny Pandas lze v případě potřeby provést i základní analýzu dat, resp. přesněji řečeno zjištění některých statistických informací, převzorkování dat apod. Obě zmíněné operace jsou ukázány na dalším screenshotu, v němž se sloupce obsahující časy získání/vytvoření dat převzorkují po jedné minutě, získá se četnost dat (po minutách) a následně se zobrazí základní statistické údaje o takto vzniklé sadě nových dat:
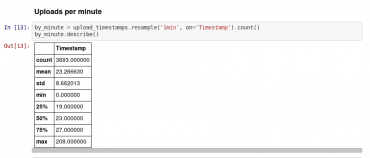
Obrázek 18: Použití knihovny Pandas pro manipulaci s daty.
13. Zobrazení dat ve formě grafů
V rámci inicializace diáře jsme načetli i knihovnu Matplotlib sloužící k tvorbě různých grafů. Ukažme si tedy, alespoň ve stručnosti, dva základní typy grafů, které je možné použít a přímo zobrazit na stránce s diářem. Prvním grafem je sloupcový graf, jehož základní verze vypadá následovně:
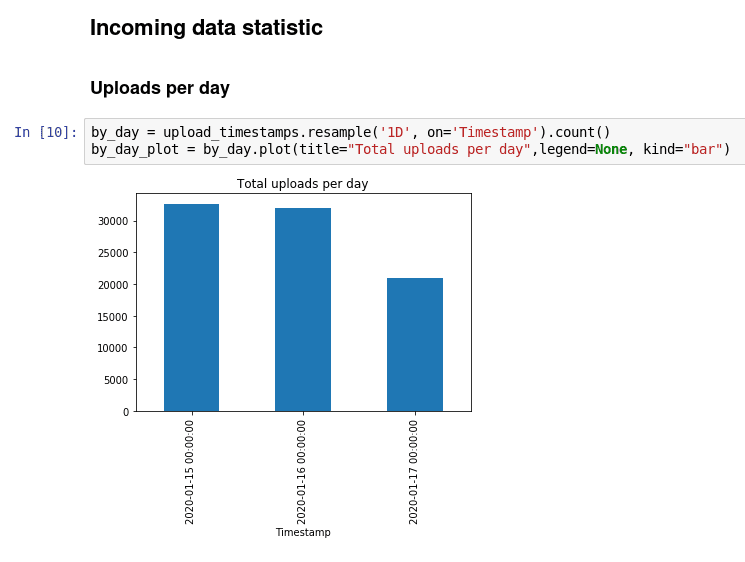
Obrázek 19: Sloupcový graf.
Podporovány jsou i další typy grafů, například klasický liniový graf:
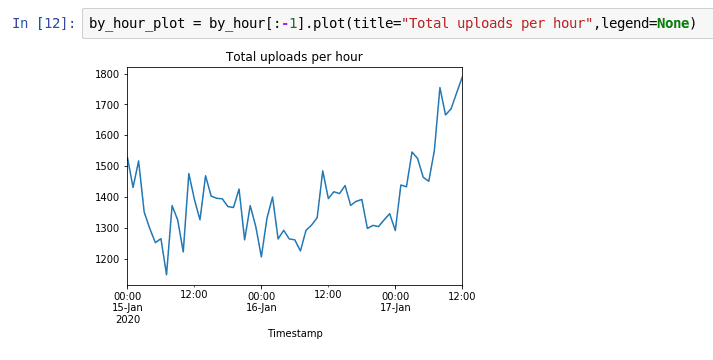
Obrázek 20: Četnost nových dat připravených pro analýzu zobrazená na grafu.
14. Vytvoření slajdů
Z diáře je v případě potřeby možné vytvořit slajdy. Nejprve je však nutné určit, jaké role mají jednotlivé příkazy (In) a jejich výstup (Out). Pro tento účel slouží příkaz View → Cell Toolbar → Slideshow, který nad každý vstupní řádek přidá šedé políčko s výběrovým boxem, v němž je možné určit, zda se má jednat o začátek dalšího slajdu, obsah slajdu či zda se má výstup ignorovat, popř. zobrazit ve formě poznámek. Vzhledem k tomu, že se jedná o velmi důležitou součást celého Jupyter Notebooku (pro někoho zcela nejdůležitější vlastnost), budeme se přípravou slajdů podrobněji zabývat příště.
15. Zobrazení diáře (notebooku) přímo na GitHubu
Užitečné je, že pokud se samotný notebook uloží do repositáře hostovaného na GitHubu, může se celý diář zobrazit přímo při procházení daným repositářem – ovšem jen pasivně (změny apod. nejsou povoleny). Na diář se tedy můžeme dívat jako na glorifikovaný dokument s možností zobrazení tabulek, obrázků a především grafů. Ostatně se o tom sami můžete velmi snadno přesvědčit na adrese https://github.com/tisnik/jupyter-notebook-examples/blob/master/processing1.ipynb, kde lze nalézt náš testovací diář:
Obrázek 21: Repositář s Jupyter notebookem a datovými soubory.
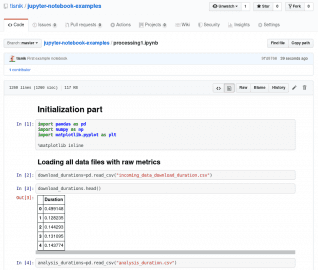
Obrázek 22: Zobrazení Jupyter Notebooku přímo na stránkách GitHubu.
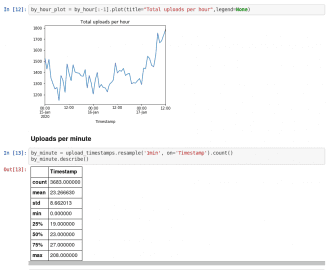
Obrázek 23: Na GitHubu lze zobrazit i grafy, což je pro prezentace velmi dobrá vlastnost.
16. Příbuzné projekty
Existuje několik projektů, které jsou nějakým způsobem příbuzné s Jupyter Notebookem. S některými z nich se ve stručnosti seznámíme v následujícím textu.
Předchůdcem projektu Jupyter Notebook je, jak již ostatně dobře víme, IPython Notebooks, jenž je založený na projektu IPython. Jedná se o v mnoha ohledech vylepšený interpret Pythonu – IPython je ve skutečnosti jedním z nejpropracovanějších REPL, se kterým jsem měl možnost pracovat. Architektura nástroje IPython je navržena takovým způsobem, že je do značné míry modulární, což mj. znamená, že uživatelé mohou s IPythonem komunikovat hned několika možnými způsoby. My se v této kapitole zaměříme zejména na použití interaktivního shellu (což je vlastně v mnoha ohledech vylepšená varianta smyčky REPL), ovšem modulární architektura umožnila vytvořit i zmíněný IPython Notebook, což je naopak implementace konceptu diáře (notebooku). Další množnosti komunikace s IPythonem spočívají v použití 0MQ (Zero MQ), což je zjednodušeně řečeno řešení postavené na bázi socketů (viz též článek o této knihovně); tato architektura byla převzata Jupyterem.
Obrázek 24: Start interaktivního prostředí IPythonu.
Možnosti IPythonu jsou však ve skutečnosti mnohem větší, než „pouhé“ vylepšené rozhraní mezi uživatelem a interpretrem. Architektura IPythonu například umožňuje, aby se komplikované výpočty neprováděly přímo na tom počítači, kde je spuštěn interaktivní shell (klient), ale aby se pouze předaly dalším strojům tvořícím výpočetní farmu. Díky tomu – a taktéž díky propojení IPythonu s knihovnami NumPy a SciPy i s nástrojem matplotlib – se IPython používá i v těch oblastech, kde se provádí mnoho složitých a/nebo časově náročných výpočtů, což může znít poněkud paradoxně, když si uvědomíme, že samotný Python je v těchto ohledech dosti pomalý jazyk (ve skutečnosti NumPy předává výpočty nativnímu kódu psanému v C, popř. ve Fortranu, které obsahují optimalizované algoritmy různých výpočtů).
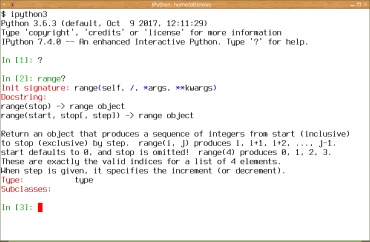
Obrázek 25: Zobrazení nápovědy k funkci range.
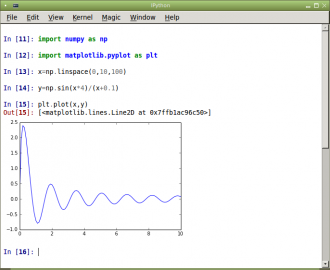
Obrázek 26: Grafické rozhraní IPythonu.
17. Gorilla REPL
Jedná se o projekt inspirovaný IPython Notebookem, ovšem v případě Gorilla REPL zaměřený primárně na použití programovacího jazyka Clojure, kterému jsme se již na stránkách Rootu poměrně podrobně věnovali. V Gorilla REPL lze pochopitelně použít všechny moduly dostupné pro Clojure a díky Java interop i prakticky libovolnou knihovnu dostupnou pro programovací jazyk Java, resp. přesněji řečeno pro jakýkoli jazyk postavený nad JVM.
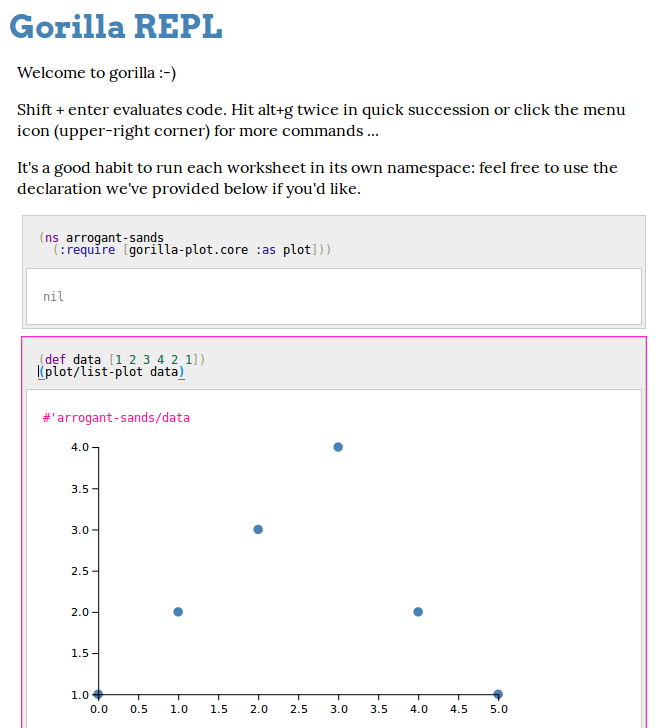
Obrázek 27: Interaktivní prostředí nástroje Gorilla REPL spuštěné v běžném webovém prohlížeči (zde konkrétně ve Firefoxu).
| # | Kernel | |
|---|---|---|
| 1 | CloJupyter | Clojure >= 1.7 |
| 2 | jupyter-kernel-jsr223 | Clojure 1.8 |
| 3 | BeakerX | Groovy, Java, Scala, Clojure, Kotlin, SQL |
Obrázek 28: Standardní grafy jsou v Gorilla REPL do stránky vkládány ve formátu SVG.
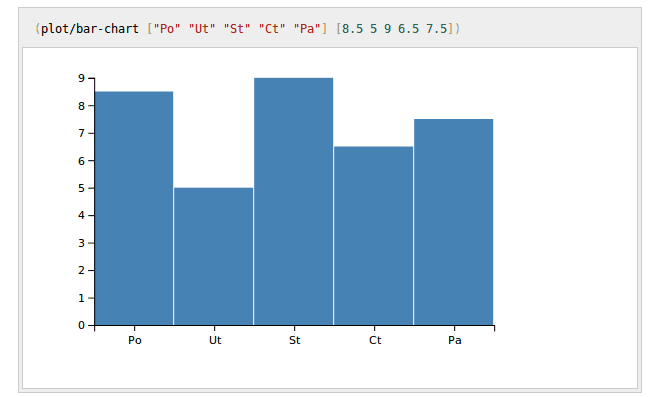
Obrázek 29: Ukázka použití jednoduchého sloupcového grafu.
18. Gophernotes
„There is a tension, especially in scientific computing, between ease and simplicity“
Gophernotes je projekt používající programovací jazyk Go, který z Go zpřístupňuje interaktivní prostředí založené na dnes popisovaném projektu Jupyter. Nástroj Gophernotes dokáže do okna prohlížeče vykreslovat základní grafy, a to jak s přímým využitím předaných dat (vektory či sekvence čísel), tak i při specifikaci funkce, jejíž průběh se má vykreslit (existují zde ovšem mnohá omezení, kterými se budu zabývat v navazujících kapitolách). Třešničkou na dortu je podpora pro práci se vzorci psanými v TeXu či LaTeXu (zde není oproti klasickému Jupyteru žádný podstatný rozdíl).
Již v úvodním odstavci jsme si řekli, že Gophernotes je založen na projektu Jupyter. Ve skutečnosti Gophernotes do Jupyteru doplňuje modul (takzvaný kernel, jak již víme z úvodních kapitol) zajišťující interakci s jazykem Go, podobně jako existují další podobné moduly určené pro programovací jazyky Python, Julia, Lua, jazyk Hy atd. V případě jazyka Go je ovšem situace poněkud složitější, protože Go je primárně překladačem. Aby bylo možné zkombinovat možnosti interpretru a klasického překladače, vznikl projekt pojmenovaný Gomacro.
Nejjednodušší způsob, jakým lze spustit Gophernotes i se všemi potřebnými závislostmi, spočívá v použití Dockeru, protože již existuje připravený obraz obsahující Gophernotes, Jupyter, gomacro i další knihovny pro numerické výpočty a zpracování dat. Následující příkaz zajistí stažení obrazů, spuštění Gophernotesu a namapování HTTP serveru (Jupyter) na port 8888:
$ docker run -it -p 8888:8888 gopherdata/gophernotes:latest-ds
Unable to find image 'gopherdata/gophernotes:latest-ds' locally
Trying to pull repository docker.io/gopherdata/gophernotes ...
sha256:e2ef4a5b318604b8e5116fcf470e11fecbb2c18631cb73bdbed46ed026e862a6: Pulling from docker.io/gopherdata/gophernotes
a44d943737e8: Pull complete
0bbfb29b138b: Pull complete
ef49c0fa046c: Pull complete
Digest: sha256:e2ef4a5b318604b8e5116fcf470e11fecbb2c18631cb73bdbed46ed026e862a6
Status: Downloaded newer image for docker.io/gopherdata/gophernotes:latest-ds
[I 15:14:32.110 NotebookApp] Writing notebook server cookie secret to /root/.local/share/jupyter/runtime/notebook_cookie_secret
[I 15:14:32.998 NotebookApp] Serving notebooks from local directory: /
[I 15:14:32.999 NotebookApp] The Jupyter Notebook is running at:
[I 15:14:33.000 NotebookApp] http://(6c7428d3f7f9 or 127.0.0.1):8888/?token=f4d754332b4be755cfb351018840af76767e80829d7dfc61
[I 15:14:33.000 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 15:14:33.006 NotebookApp]
To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-1-open.html
Or copy and paste one of these URLs:
http://(6c7428d3f7f9 or 127.0.0.1):8888/?token=f4d754332b4be755cfb351018840af76767e80829d7dfc61
Do adresního řádku webového browseru napíšeme adresu: http://127.0.0.1:8888.
Obrázek 30: Prohlížeč se zeptá na token, který zkopírujeme ze zprávy vypsané po spuštění Dockeru s gophernotesem.

Obrázek 31: Grafické uživatelské rozhraní Jupyteru s Gophernotesem.
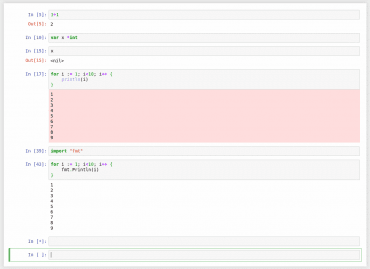
Obrázek 32: Zprávy zapisované na chybový výstup jsou podbarveny červeně, zprávy zapisované na výstup standardní nemají podbarvení žádné (implicitní barvou je bílé pozadí).
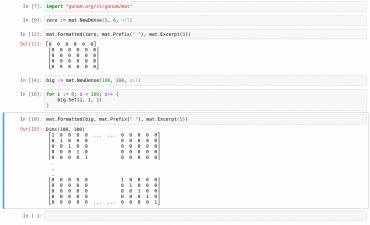
Obrázek 33: Formátování matic zpracovaných kernelem Gophernotes.

19. JupyterLab
JupyterLab je relativně nový projekt nabízející upravené a vylepšené grafické uživatelské rozhraní pro projekt Jupyter; jedná se tedy o alternativu k celému výše popsanému Jupyter Notebooku (od kterého se sice odlišuje, ale základ práce zůstává stejný). I JupyterLab lze použít přímo na webu (bez nutnosti instalace), popř. provést jeho lokální instalaci (server+kernely na jednom počítači). Podrobnosti o tomto zajímavém projektu budou uvedeny v samostatném článku. Mimochodem: sympatické je, že vzorový příklad, na kterém jsou některé možnosti JupyterLabu ukázány, je založen na Lorenzových diferenciálních rovnicích, jejichž řešením vznikne slavný Lorenzův atraktor (jehož objevení mělo velký vliv na rozvinutí teorie chaosu, revize možností predikce chování systémů citlivých na počáteční podmínky aj.).
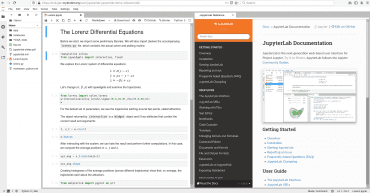
Obrázek 34: Grafické uživatelské rozhraní projektu JupyterLab se zobrazeným vzorovým příkladem.
20. Odkazy na Internetu
- Notebook interface
https://en.wikipedia.org/wiki/Notebook_interface - Jypyter: open source, interactive data science and scientific computing across over 40 programming languages
https://jupyter.org/ - The IPython Notebook
http://ipython.org/notebook.html - nbviewer: a simple way to share Jupyter Notebooks
https://nbviewer.jupyter.org/ - Back to the Future: Lisp as a Base for a Statistical Computing System
https://www.stat.auckland.ac.nz/~ihaka/downloads/Compstat-2008.pdf - gg4clj: a simple wrapper for using R's ggplot2 in Clojure and Gorilla REPL
https://github.com/JonyEpsilon/gg4clj - Analemma: a Clojure-based SVG DSL and charting library
http://liebke.github.io/analemma/ - Clojupyter: a Jupyter kernel for Clojure
https://github.com/roryk/clojupyter - Incanter is a Clojure-based, R-like platform for statistical computing and graphics.
http://incanter.org/ - Evolution of incanter (Gource Visualization)
https://www.youtube.com/watch?v=TVfL5nPELr4 - Questions tagged [incanter] (na Stack Overflow)
https://stackoverflow.com/questions/tagged/incanter?sort=active - Data Sorcery with Clojure
https://data-sorcery.org/contents/ - What is REPL?
https://pythonprogramminglanguage.com/repl/ - What is a REPL?
https://codewith.mu/en/tutorials/1.0/repl - Programming at the REPL: Introduction
https://clojure.org/guides/repl/introduction - What is REPL? (Quora)
https://www.quora.com/What-is-REPL - Gorilla REPL: interaktivní prostředí pro programovací jazyk Clojure
https://www.root.cz/clanky/gorilla-repl-interaktivni-prostredi-pro-programovaci-jazyk-clojure/ - R Markdown: The Definitive Guide
https://bookdown.org/yihui/rmarkdown/ - Single-page application
https://en.wikipedia.org/wiki/Single-page_application - Video streaming in the Jupyter Notebook
https://towardsdatascience.com/video-streaming-in-the-jupyter-notebook-635bc5809e85 - How IPython and Jupyter Notebook work
https://jupyter.readthedocs.io/en/latest/architecture/how_jupyter_ipython_work.html - Jupyter kernels
https://github.com/jupyter/jupyter/wiki/Jupyter-kernels - Keras: The Python Deep Learning library
https://keras.io/ - TensorFlow
https://www.tensorflow.org/ - PyTorch
https://pytorch.org/ - Seriál Torch: framework pro strojové učení
https://www.root.cz/serialy/torch-framework-pro-strojove-uceni/ - Scikit-learn
https://scikit-learn.org/stable/ - Java Interop (Clojure)
https://clojure.org/reference/java_interop - Obrazy s balíčky Jupyter Notebooku pro Docker
https://hub.docker.com/u/jupyter/#! - Správce balíčků Conda (dokumentace)
https://docs.conda.io/en/latest/ - Lorenzův atraktor
https://www.root.cz/clanky/fraktaly-v-pocitacove-grafice-vi/#k02 - Lorenzův atraktor
https://www.root.cz/clanky/fraktaly-v-pocitacove-grafice-iii/#k03


