Obsah
1. Jupyter Notebook – operace s rastrovými obrázky a UML diagramy, literate programming
2. Konverze diáře do zdrojového kódu Pythonu
5. Vykreslování na úrovni pixelů
6. Načtení obrázku z externího souboru
7. Vykreslování základních 2D primitiv
8. Aplikace jednoduchých konvolučních filtrů
9. Integrace Jupyter Notebooku s PlantUML
13. Hierarchické členění stavových diagramů
14. Tvorba sekvenčních diagramů v PlantUML
16. Jupyter Notebook a literate programming
17. Ukázka diáře s popisem všech kroků
18. Export diáře do dalších formátů
19. Repositář s demonstračními příklady
1. Jupyter Notebook – operace s rastrovými obrázky a UML diagramy, literate programming
Již v perexu dnešního článku jsme se zmínili o jedné velké přednosti Jupyter Notebooku – o jeho schopnosti integrace textů, popř. speciálních textů (zdrojových kódů, MathML, Markdownu) s rastrovými obrázky (typicky PNG a JPEG), s vektorovými kresbami (SVG) a v případě potřeby dokonce i s animacemi. Tuto schopnost jsme si ukázali v dvojici článků [1][2] o knihovně Matplotlib, ovšem ve skutečnosti jsou možnosti Jupyter Notebooku v této oblasti mnohem rozsáhlejší a neomezené na „pouhé grafy funkcí“. Dnes si ukážeme, jakým způsobem lze pracovat s rastrovými obrázky, provádět přímo jejich úpravy (interaktivně) atd. Navíc lze s vhodnými moduly do diářů integrovat i UML diagramy, které jsou vykreslovány nástrojem PlantUML. Právě na příkladu integrace PlantUML je patrné, že do diářů lze vkládat i vektorové kresby ve formátu SVG.
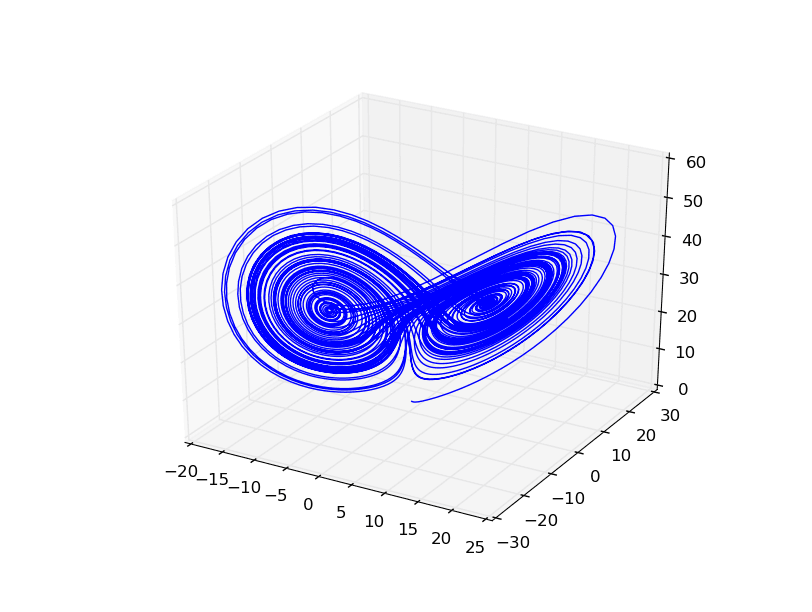
Obrázek 1: Lorenzův atraktor vykreslený demonstračním příkladem popsaným v předchozím článku, v němž jsme se zabývali převážně popisem možností Matplotlibu.
V závěru článku se – prozatím ovšem jen ve stručnosti a nepříliš přesně – seznámíme s termínem „literate programming“ i s tím, jak tento koncept souvisí s vlastním Jupyter Notebookem.
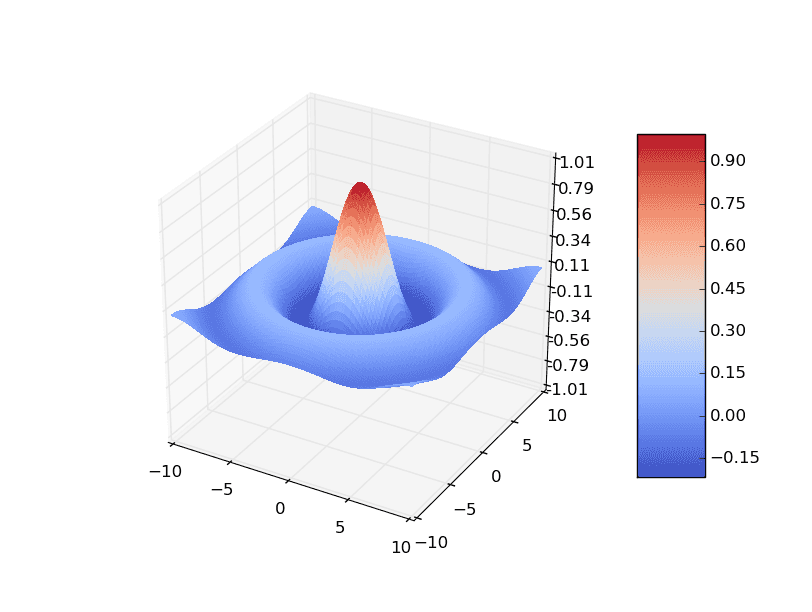
Obrázek 2: Plocha funkce z=f(x,y) používající barvovou mapu pojmenovanou „coolwarm“. Opět se jedná o příklad vysvětlený minule.
2. Konverze diáře do zdrojového kódu Pythonu
Před popisem použití rastrových obrázků a UML diagramů si však ještě ukažme, jakým způsobem je možné vyexportovat obsah diáře do formy zdrojového kódu (skriptu) v Pythonu. Takový skript lze v některých případech přímo spustit z příkazové řádky (v závislosti na obsahu diáře – ne vždy je to možné), popř. ho otevřít v IPythonu. Konverze do Pythonu se provádí buď přímo z grafického uživatelského rozhraní Jupyter Notebooku nebo – což bývá při práci na více diářích lepší – z příkazové řádky:
$ jupyter nbconvert --to script raster_image.ipynb
Výsledek může pro tento diář vypadat následovně:
# coding: utf-8 # In[36]: import numpy as np from matplotlib import pyplot as plt # In[37]: raster = np.zeros(shape=(450, 450, 3), dtype=np.uint8) # In[38]: plt.imshow(raster) # In[39]: plt.show()
Pro porovnání si ukažme obsah původního diáře:
Obrázek 3: Obsah původního diáře.
Můžeme vidět, že se samotné příkazy Pythonu převedly korektně a ostatní informace (například názvy buňek) jsou zapsány v poznámkách.
3. Práce s rastrovými obrázky
Jak jsme si již řekli v úvodní kapitole, je možné v Jupyter Notebooku zobrazit rastrové obrázky a to nejenom statické obrázky uložené na lokálním disku (i to je však užitečné), ale především obrázky, které se získají nějakým algoritmem. Ve skutečnosti existuje hned několik způsobů, jak toho dosáhnout. Pravděpodobně nejjednodušší (i když nikoli nejrychlejší) je použití knihovny Numpy v kombinaci s Matplotlibem. V Numpy totiž můžeme vytvořit trojrozměrné pole reprezentující jednotlivé pixely obrázku. Prvky tohoto pole mají typ uint8 a samotné pole má formát výškaךířka×3, kde 3 představuje tři barvové složky barvového prostoru RGB. Zdroj pro prázdný (černý) obrázek o velikosti 450×450 pixelů se tedy vytvoří takto:
raster = np.zeros(shape=(450, 450, 3), dtype=np.uint8)
Barvové složky RGB mají hodnoty od 0 (nejnižší intenzita) do 255 (nejvyšší intenzita).
O zobrazení obsahu tohoto pole se postará knihovna Matplotlib, a to například takto:
plt.imshow(raster) plt.show()
Obrázek 4: Toto je obrázek vložený do diáře.
Celý skript (obsah diáře) může vypadat takto:
import numpy as np from matplotlib import pyplot as plt raster = np.zeros(shape=(450, 450, 3), dtype=np.uint8) plt.imshow(raster) plt.show()
Výsledný diář i s obrázkem je na adrese https://github.com/tisnik/jupyter-notebook-examples/blob/master/raster_image.ipynb.
4. Změna velikosti obrázku
Rastrový obrázek je možné na ploše Jupyter Notebooku do jisté míry zvětšit. Trik spočívá v použití příkazu plt.figure (dokumentace), kterému se kromě ID grafu předají rozměry v palcích a popř. i očekávané rozlišení výstupu (což pro obrazovku nebude přesné). Následně se na ploše notebooku vytvoří potřebné místo a do něj se graf zobrazí:
plt.figure(1, figsize=(8,6), dpi=100) plt.imshow(raster)
Na výsledném diáři bude mít zobrazený obrázek velikost přibližně 500×500 pixelů.
Obrázek 5: Zvětšený obrázek vložený do diáře.
Celý skript, který je možné vložit do diáře:
import numpy as np from matplotlib import pyplot as plt raster = np.zeros(shape=(450, 450, 3), dtype=np.uint8) plt.figure(1, figsize=(8,6), dpi=100) plt.imshow(raster) plt.show()
5. Vykreslování na úrovni pixelů
Hlavním důvodem, proč je rastrový obrázek reprezentován trojrozměrným polem spravovaným knihovnou Numpy je fakt, že je v tomto případě velmi snadné měnit barvy pixelů takového obrázku. Může se například jednat o výsledky simulací apod. Ostatně podívejme se na jednoduchý příklad, v němž se do obrázku vykreslí barevné přechody mezi zelenou a bílou barvou, přičemž se v horizontální ose mění červená barvová složka a ve směru vertikální složky barva modrá. Složka zelená je nastavena na nejvyšší intenzitu 255:
for y in range(HEIGHT):
for x in range(WIDTH):
raster[y][x][0] = x
raster[y][x][1] = 255
raster[y][x][2] = y

Obrázek 6: Vykreslený obrázek vložený do diáře.
Pro větší přehlednost je možné nadefinovat i indexy barvových složek:
RED = 0
GREEN = 1
BLUE = 2
for y in range(HEIGHT):
for x in range(WIDTH):
raster[y][x][RED] = x
raster[y][x][GREEN] = 255
raster[y][x][BLUE] = y
Celý skript vložený do tohoto diáře vypadá následovně:
import numpy as np
from matplotlib import pyplot as plt
WIDTH = 256
HEIGHT = 256
raster = np.zeros(shape=(HEIGHT, WIDTH, 3), dtype=np.uint8)
for y in range(HEIGHT):
for x in range(WIDTH):
raster[y][x][0] = x
raster[y][x][1] = 255
raster[y][x][2] = y
plt.figure(1, figsize=(8,6), dpi=100)
plt.imshow(raster)
plt.show()
6. Načtení obrázku z externího souboru
Pro načtení obrázku z externího souboru je možné použít například knihovnu PIL/Pillow, která umožňuje práci s rastrovými obrázky uloženými v mnoha podporovaných formátech, aplikaci různých filtrů na obrázky, manipulaci s jednotlivými pixely, kreslení základních geometrických tvarů i textů do obrázků apod. Pro načtení rastrového obrázku slouží funkce Image.open(), které je nutné předat jméno souboru s rastrovým obrázkem a volitelně taktéž režim přístupu k souboru (implicitně „r“ – značící režim čtení). Ze jména souboru a především pak z jeho hlavičky si knihovna Pillow odvodí formát souboru a použije příslušnou specializovanou třídu pro načtení a dekódování obrazových dat. S obrázkem je možné dále pracovat stejným způsobem (alespoň zdánlivě), jako tomu bylo v předchozích příkladech:
import numpy as np from PIL import Image from matplotlib import pyplot as plt filename="house.png" img = Image.open(filename) plt.figure(1, figsize=(6,6), dpi=100) plt.imshow(img) plt.show()

Obrázek 7: Testovací bitmapa použitá i v dalších příkladech.
Příslušný diář je dostupný na adrese https://github.com/tisnik/jupyter-notebook-examples/blob/master/raster_image_load.ipynb.
Ve chvíli, kdy je obrázek úspěšně načten a dekódován, je ve skriptu reprezentován objektem typu Image. To mj. znamená, že máme přístup ke všem metodám tohoto objektu, resp. přesněji řečeno k metodám deklarovaným přímo ve třídě Image.. Kromě toho lze přistupovat i k atributům objektu typu Image, přičemž tyto atributy nesou základní informace o zpracovávaném obrázku.
Atribut format obsahuje formát souboru, ze kterého byl obrázek načten, popř. hodnotu None pro obrázky vzniklé programově. V atributu size jsou uloženy rozměry obrázku a jelikož jsou rastrové obrázky dvourozměrné, je hodnotou atributu size dvojice (tuple) obsahující horizontální rozlišení (tj. počet pixelů na obrazovém řádku) a rozlišení vertikální (tj. počet obrazových řádků). A konečně atribut mode obsahuje informaci o tom, jaký barvový prostor je použit („L“, „RGB“ atd.).
7. Vykreslování základních 2D primitiv
Po popisu nízkoúrovňových kreslicích operací se podívejme na způsob vykreslování základních dvourozměrných entit, tj. především úseček, kružnic, oblouků, ale například i textu. Tyto operace jsou realizovány přes objekt získaný zavoláním konstruktoru ImageDraw.Draw(), kterému předáme referenci na již existující rastrový obrázek. Obrázek nejprve načteme tak, jak jsme již zvyklí:
filename="house.png" img = Image.open(filename)
Následně zavoláme konstruktor ImageDraw.Draw():
draw = ImageDraw.Draw(img)
Po tomto řádku je již možné vykreslovat všechny podporované 2D entity. A po vykreslení je vhodné (i když nikoli nutné) objekt explicitně uvolnit z paměti:
# explicitní vymazání objektu umožňujícího kreslení del draw
Základní vysokoúrovňovou kreslicí operací je operace určená pro nakreslení obyčejné úsečky. Tato operace je realizována metodou line, které se typicky předává n-tice obsahující koncové prvky úsečky, tedy body [x1, y1] a [x2, y2]:
(x1, y1, x2, y2)
Dále se typicky této metodě předává barva úsečky, a to přes nepovinný (pojmenovaný) parametr fill. Hodnotou tohoto parametru je trojice představující barvu v RGB prostoru:
draw.line((x1, y1, x2, y2), fill=(255, 255, 255))
Pro nakreslení úsečky se používá klasický Bresenhamův algoritmus, který ovšem (ve své původní podobě) nedokáže využít antialiasing. To nám ovšem nebude vadit protože budeme vykreslovat mřížku složenou pouze z vodorovných a svislých úseček. Nejprve vytvoříme objekt typu Draw a následně zjistíme rozměry obrázku přečtením atributu Image.size. Následuje vykreslení svislých a posléze vodorovných úseček:
import numpy as np
from PIL import Image, ImageDraw
from matplotlib import pyplot as plt
filename="house.png"
img = Image.open(filename)
draw = ImageDraw.Draw(img)
width, height = img.size[0], img.size[1]
for x in range(0, width, 16):
draw.line((x, 0, x, height-1), fill=(255, 255, 255))
for y in range(0, height, 16):
draw.line((0, y, width-1, y), fill=(255, 255, 255))
size = 2*width/72
plt.figure(1, figsize=(size,size), dpi=100)
plt.imshow(img, interpolation="none")
plt.show()
Viz též příslušný diář.

Obrázek 8: Výsledný rastrový obrázek.
8. Aplikace jednoduchých konvolučních filtrů
Knihovna Pillow obsahuje poměrně velké množství (konvolučních) filtrů, které je možné aplikovat na upravované rastrové obrázky. Popišme si nyní ten nejjednodušší filtr: při úpravách fotografií nebo naskenovaných obrázků se poměrně často můžeme setkat s požadavkem na odstranění šumu z obrazu nebo z jeho vybrané části. Nejjednodušším a taktéž nejrychlejším filtrem, který dokáže odstranit vysoké frekvence v obrazu a tím i šum (bohužel spolu s ostrými hranami) je filtr nazvaný příznačně Blur. Tento filtr pracuje velmi jednoduše – spočítá průměrnou hodnotu sousedních pixelů tvořících pravidelný blok a tuto hodnotu uloží do pixelu ležícího přesně uprostřed bloku (operace je samozřejmě provedena pro všechny pixely v obrazu). Výsledkem je sice obraz s odstraněným vysokofrekvenčním šumem, ale současně s potlačením šumu došlo k rozmazání všech jednopixelových hran na přechody široké minimálně tři pixely.
Filtr typu Blur zmíněný v předchozím textu, se na již načtený obrázek aplikuje velmi jednoduše s tím, že výsledkem aplikace filtru bude nový (rozmazaný) obrázek:
blurred_image = test_image.filter(ImageFilter.BLUR)

Obrázek 9: Rozmazání obrázku.
První skript použitelný v diáři:
import numpy as np from PIL import Image, ImageFilter from matplotlib import pyplot as plt filename="house.png" img = Image.open(filename) blurred = img.filter(ImageFilter.BLUR) plt.figure(1, figsize=(8,6), dpi=100) plt.imshow(blurred) plt.show()
Ve druhém příkladu, který se liší pouze parametrem metody img.filter, jsou v obrázku nalezeny a zvýrazněny hrany, opět pomocí obyčejného konvolučního filtru:

Obrázek 10: Nalezení hran konvolučním filtrem.
Druhý skript použitelný v dalším diáři:
import numpy as np from PIL import Image, ImageFilter from matplotlib import pyplot as plt filename="house.png" img = Image.open(filename) edges = img.filter(ImageFilter.FIND_EDGES) plt.figure(1, figsize=(6,6), dpi=100) plt.imshow(edges) plt.show()
9. Integrace Jupyter Notebooku s PlantUML
Ve druhém článku si ukážeme integraci nástroje PlantUML s Jupyter Notebookem.
Nástroj PlantUML (http://plantuml.sourceforge.net/) dokáže na základě textového popisu UML diagramu vytvořit bitmapový obrázek či SVG s tímto diagramem, přičemž uživatel může do jisté míry ovlivnit způsob jeho vykreslení, přidat popis hran apod. V současné verzi PlantUML je podporováno mnoho typů UML diagramů, zejména: diagram aktivit, stavový diagram, diagram tříd, diagram objektů, diagram komponent, diagram užití a sekvenční diagram. Ve skutečnosti sice UML popisuje i další typy diagramů, ovšem PlantUML s velkou pravděpodobností dokáže pokrýt většinu potřeb analytiků i programátorů, protože v nabídce podporovaných diagramů jsou zastoupeny všechny tři kategorie: popis struktury informačního systému, popis chování informačního systému a popis interakce či komunikace. PlantUML je naprogramovaný v Javě, ovšem jedná se o relativně malý program, který pro svůj běh nevyžaduje enormní množství zdrojů (diskový prostor, RAM atd.). Pro uživatele PlantUML je na adrese http://sourceforge.net/projects/plantuml/files/plantuml.jar/download k dispozici spustitelný Java archiv, dále je vhodné si stáhnout referenční příručku k jazyku z adresy http://plantuml.sourceforge.net/PlantUML_Language_Reference_Guide.pdf.
Jediný balíček, který je nutné nainstalovat, je podpora pro volání serveru PlantUML z Jupyter Notebooku. Tato instalace je triviální:
$ pip3 install --user iplantuml
10. Diagram aktivit
Klasické vývojové diagramy sice nejsou v UML přímo podporovány, ale existuje zde velmi podobný typ diagramu nazvaný diagram aktivit. Tímto diagramem je možné do jisté míry nahradit vývojové diagramy s větvením i programovými smyčkami. Diagram aktivit lze v PlantUML vytvořit velmi jednoduchým způsobem, což si ostatně ukážeme na několika demonstračních příkladech (diářích).
První příklad obsahuje definici diagramu aktivit, který obsahuje jen jedinou akci, tj. uzel představující většinou dále nedělený krok, který se v systému provádí. Diagram obsahuje symbol inicializace (černá tečka), koncový bod (kružnice s černou tečkou uprostřed) a uzel s prováděným krokem. Mezi symbolem inicializace a uzlem je nakreslena šipka, podobná šipka je pak nakreslena mezi uzlem a koncovým bodem. V PlantUML je tento diagram představován následujícím kódem (textovým souborem). Povšimněte si použití symbolů (*) jak pro symbol inicializace, tak i pro koncový bod:
@startuml (*) --> "Aktivita" "Aktivita" --> (*) @enduml
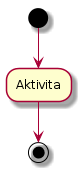
Obrázek 11: Diagram aktivit vygenerovaný z předchozího zdrojového kódu.
Deklarace začíná řádkem @startuml a končí řádkem @enduml. Zajímavé je, že není nutné uvádět typ diagramu – ten je odvozen z kontextu.
Jak již bylo řečeno v předchozí kapitole, je možné při tvorbě diagramů s využitím nástroje PlantUML ovlivnit způsob vykreslení diagramu. V mnoha případech se nevyhneme přidání popisu k jednotlivým šipkám diagramu aktivit, což lze zajistit zápisem poznámky do hranatých závorek:
@startuml (*) --> [začátek procesu] "Aktivita1" --> [zpracování požadavku] "Aktivita2" --> [konec procesu] (*) @enduml

Obrázek 12: Diagram aktivit. Uzly jsou v tomto diagramu umístěny pod sebe.
Taktéž je možné změnit uspořádání uzlů (a tím pádem i směr šipek). Namísto symbolu → představujícího šipku je možné alternativně použít:
- -down→ odpovídá běžné šipce směřující (šikmo) dolů
- -right→ šipka orientovaná doprava
- → stejný význam jako má předchozí symbol
- -left→ šipka orientovaná doleva
- -up→ šipka orientovaná nahoru
Zkusme si nyní předchozí diagram změnit takovým způsobem, aby byly všechny uzly umístěné v jedné horizontální rovině. Úprava je ve skutečnosti velmi jednoduchá:
@startuml (*) -right-> [začátek procesu] "Aktivita1" -right-> [zpracování požadavku] "Aktivita2" -right-> [konec procesu] (*) @enduml

Obrázek 13: Diagram aktivit vygenerovaný ze zdrojového kódu pátého příkladu. Nyní jsou všechny uzly zobrazeny v jedné horizontální rovině.
Velmi důležitou součástí naprosté většiny diagramů aktivit je rozvětvení. To je reprezentováno malým kosočtvercem, takže se tento prvek diagramu podobá rozvětvení používaného v klasickém vývojovém diagramu, ovšem s tím rozdílem, že se podmínka pro rozvětvení může (ale nemusí) psát do předchozího kroku (zde si dovolím sémantiku diagramu aktivit nepatrně pozměnit, protože samotné rozvětvení není v diagramu aktivit chápáno jako samostatný krok). Pojďme si nyní ukázat, jak by se postupovalo při vytváření diagramu analogickému známému vtípku o univerzálním návodu na opravu všeho: http://joyreactor.com/post/287235. Zde se již setkáme s potřebou větvení, které se do diagramu aktivit zapisuje – což mnoho programátorů patrně potěší – pomocí slov if, then, else a endif. Jednoduché rozvětvení může být zapsáno následovně:
@startuml (*) --> "Does it move?" if "" then --> [yes] "WD-40" else --> [no] "Duct Tape" endif "WD-40" --> (*) "Duct Tape" --> (*) @enduml
Pro lepší názornost je možné jednotlivé podvětve zvýraznit odsazením, které je samozřejmě taktéž podporováno:
@startuml
(*) --> "Does it move?"
if "" then
--> [yes] "Should it?" as s1
if "" then
--> [yes] "No problem" as np1
np1 --> (*)
else
--> [no] "Use duct tape" as tape
tape --> (*)
endif
else
--> [no] "Should it?" as s2
if "" then
--> [yes] "Use WD-40" as wd40
wd40 --> (*)
else
--> [no] "No problem" as np2
np2 --> (*)
endif
endif
@enduml

Obrázek 14: Návod jak opravit vše.
11. Diagram tříd
Druhým velmi často používaným diagramem definovaným ve standardu UML je diagram tříd (class diagram). V tomto typu diagramu je možné zobrazit jednoduché i složitější vztahy mezi třídami, například fakt, že třída Boolean je potomkem třídy Object (příklad je převzatý z Javy):
@startuml Object <|-- Boolean @enduml

Obrázek 15: Vztah mezi třídami Object a Boolean zobrazený v diagramu tříd.
Můžeme samozřejmě zobrazit i vazby mezi větším počtem tříd. Povšimněte si, že nikde není zapotřebí specifikovat, že se má zobrazit diagram tříd a ne diagram aktivit: toto rozhodnutí provede PlantUML automaticky:
@startuml Object <|-- Boolean Object <|-- String Object <|-- Number Number <|-- Integer Number <|-- Double @enduml

Obrázek 16: Vztahy mezi větším počtem tříd.
V případě, že je nutné zvýraznit i přístupová práva k atributům, je vhodnější použít alternativní způsob zápisu metadat o třídě. Ten se podobá zápisu deklarace třídy v C++ či Javě, přičemž znaky se speciálním významem před názvem atributu určují viditelnost i přístupová práva:
@startuml
class TestClass {
-privateField
#protectedField
~packageProtectedField
+publicField
}
@enduml

Obrázek 17: Třída s atributy, které mají různá přístupová práva.
Pro úplnost doplňme třídu i o metody s různými přístupovými právy:
@startuml
class TestClass {
-privateField
#protectedField
~packageProtectedField
+publicField
-privateMethod()
#protectedMethod()
~packageProtectedMethod()
+publicMethod()
}
@enduml

Obrázek 18: Třída s atributy a metodami, které mají různá přístupová práva. Povšimněte si oddělení atributů od metod, to je provedeno automaticky.
Vše je opět ukázáno v diáři, nyní konkrétně na adrese https://github.com/tisnik/jupyter-notebook-examples/blob/master/plantuml_class_diagrams.ipynb.
12. Stavové diagramy
Velmi často používaným typem UML diagramů jsou stavové diagramy neboli state diagrams, které lze využít pro popis konečného počtu stavů popisovaného systému a především pak přechodů mezi jednotlivými stavy (navíc se zde objevuje koncept událostí). Ve své nejjednodušší podobě je možné stavovým diagramem reprezentovat klasický stavový automat, ovšem možnosti UML jsou v tomto případě ještě rozšířeny o takzvané pseudostavy. Příkladem pseudostavu může být rozvětvení (fork) či naopak spojení (join), popř. pseudostav rozhodování (ten však nemá stejný význam, jako rozvětvení používané v případě výše popsaného diagramu aktivit). V následujících kapitolách si ukážeme, jakým způsobem je možné stavové diagramy vykreslovat v nástroji PlantUML i to, jak lze stavové diagramy hierarchicky rozdělovat, což je v případě složitějších systémů nezbytné pro zachování srozumitelnosti a současně i dostatečné podrobnosti stavového diagramu.
V nástroji PlantUML se pro tvorbu stavových diagramů používá především symbol -->, jímž se značí přechod mezi dvěma stavy systému. Na levé i pravé straně tohoto symbolu se může v nejjednodušším případě nacházet jméno stavu, popř. speciální symbol [*] značící buď počáteční pseudostav (initial state) popř. koncový pseudostav (final state). Podívejme se nyní na nejjednodušší možný stavový diagram, který obsahuje jeden normální stav, počáteční pseudostav a koncový pseudostav. Najdeme zde i dvojici přechodů. První přechod je vytvořen mezi počátečním pseudostavem a jediným stavem automatu, další přechod pak mezi tímto stavem a koncovým pseudostavem:
@startuml [*] --> Stav Stav --> [*] @enduml

Obrázek 19: První stavový diagram.
Stavový diagram samozřejmě můžeme dále rozšiřovat. Ve výchozím nastavení se jednotlivé stavy kreslí pod sebe, ovšem ve chvíli, kdy se namísto symbolu --> použije symbol ->, dokáže PlantUML tyto stavy vykreslit vedle sebe:
@startuml [*] --> Stav1 Stav1 --> [*] Stav1 -> Stav2 Stav2 --> [*] @enduml

Obrázek 20: Druhý stavový diagram.
Podívejme se nyní na nepatrně složitější diagram se třemi různými stavy reprezentujícími tři základní skupenství vody (za běžných podmínek). Tento diagram nám bude v dalším textu sloužit jako základ pro další rozšiřování a vylepšování (počáteční a koncový pseudostav je zde uveden pro úplnost a taktéž proto, aby PlantUML korektně rozpoznal, jaký diagram má nakreslit):
@startuml [*] --> Led Led --> Kapalina Kapalina --> Pára Pára --> Led @enduml

Obrázek 21: Třetí stavový diagram.
Diagram vytvořený předchozím příkladem ve skutečnosti není zcela korektní, protože neobsahuje všechny fyzikálně možné přechody mezi třemi skupenstvími vody. Musíme tedy diagram rozšířit i o další tři přechody. To je v našem případě velmi snadné, což je ostatně patrné i při pohledu na následující zdrojový kód. Povšimněte si, že každý stav je zde zmíněn několikrát:
@startuml [*] --> Led Led --> Kapalina Kapalina --> Led Kapalina --> Pára Pára --> Kapalina Pára --> Led Led --> Pára @enduml

Obrázek 22: Čtvrtý stavový diagram s přechody oběma směry.
K jednotlivým přechodům je možné přidat i popis, což je v praxi velmi důležité. U našeho demonstračního příkladu je popis jednoduchý – stavy představují skupenství vody, přechody pak proces vedoucí ke změně skupenství – vypařování, zkapalnění, tání, tuhnutí, sublimace a desublimace:
@startuml [*] --> Led Led --> Kapalina :tání Kapalina --> Led :tuhnutí Kapalina --> Pára :vypařování Pára --> Kapalina :zkapalnění Pára --> Led :desublimace Led --> Pára :sublimace @enduml

Obrázek 23: Pátý stavový diagram s popisem přechodů.
Vizuálně nepěkné vzájemné posunutí jednotlivých uzlů diagramu lze snadno (i když ne zcela přesně) „usměrnit“ pomocí symbolu ->, kterým se vedle sebe umístí uzly s názvy „Led“ a „Kapalina“:
@startuml [*] --> Led Kapalina -> Led :tuhnutí Led -> Kapalina :tání Kapalina --> Pára :vypařování Pára --> Kapalina :zkapalnění Pára --> Led :desublimace Led --> Pára :sublimace @enduml

Obrázek 24: Šestý stavový diagram – dva uzly se nachází na stejné horizontální úrovni.
Pro doplnění lze k jednotlivým uzlům (tedy stavům, skupenstvím) přiřadit i další text. Nejjednodušeji to lze provést tak, jak je naznačeno v dalším příkladu – uvedou se jména uzlů, dvojtečka a libovolný text, který je do uzlů přidán:
@startuml [*] --> Led Kapalina -> Led :tuhnutí Led -> Kapalina :tání Kapalina --> Pára :vypařování Pára --> Kapalina :zkapalnění Pára --> Led :desublimace Led --> Pára :sublimace Kapalina: 0°C až 100°C Led: < 0°C Pára: > 100°C @enduml

Obrázek 27: Sedmý stavový diagram. Ke všem uzlům byl přidán další text.
Vše je možné si interaktivně vyzkoušet v diáři umístěném na adrese https://github.com/tisnik/jupyter-notebook-examples/blob/master/plantuml_state_diagrams.ipynb.
13. Hierarchické členění stavových diagramů
Mnoho systémů je tak složitých, že jejich popis s využitím pouze jediného „plochého“ stavového diagramu by byl značně nepřehledný. V tuto chvíli se však dá využít další vlastnost UML podporovaná i nástrojem PlantUML. Jedná se o hierarchické rozčlenění stavového diagramu na podcelky. Podívejme se na další demonstrační příklad, v němž je první i druhý stav rozdělen na dva stavové poddiagramy. Ty jsou popsány v samostatné sekci uzavřené do bloku začínajícího klíčovým slovem state, za nímž následuje jméno stavu, který se má rozložit:
@startuml
[*] --> Stav1
Stav1 --> Stav2
Stav2 --> Stav1
state Stav1 {
[*] --> Podstav11
Podstav11 -> Podstav12
Podstav12 --> Podstav13
Podstav13 --> [*]
}
state Stav2 {
[*] -> Podstav21
Podstav21 -> Podstav22
Podstav22 -> [*]
}
@enduml

Obrázek 28: Stavový diagram, v němž jsou oba dva hlavní stavy rozčleněny do několika podstavů.
Uveďme si ještě jeden příklad hierarchicky rozčleněného stavového diagramu. Některé uzly hlavního diagramu i jeho podcelků jsou umístěny pod sebou, další uzly pak vedle sebe. Toho lze dosáhnout, jak jsme si již řekli výše, vhodnou kombinací symbolů -> a -->:
@startuml
[*] --> Stav1
Stav1 --> Stav2
Stav1 --> Stav3
Stav2 -> Stav3
Stav2 --> Stav4
Stav3 --> Stav4
Stav4 --> [*]
state Stav1 {
[*] --> Podstav11
Podstav11 -> Podstav12
Podstav12 --> Podstav13
Podstav13 -left> [*]
}
state Stav2 {
[*] --> Podstav21
Podstav21 --> Podstav22
Podstav22 --> [*]
}
state Stav3 {
[*] --> Podstav31
Podstav31 --> Podstav32
Podstav32 --> [*]
}
state Stav4 {
[*] -> Podstav41
Podstav41 -> Podstav42
Podstav42 -> [*]
}
@enduml

Obrázek 29: Poslední stavový diagram. Vzájemné umístění uzlů je řízeno uživatelem.
14. Tvorba sekvenčních diagramů v PlantUML
Stavové diagramy popsané v předchozích kapitolách sice dokážou názorně popsat stavy systému i možné přechody mezi jednotlivými stavy, ovšem v mnoha případech vzniká potřeba podrobněji popsat i interakci mezi popisovaným systémem a jeho okolím, interakci mezi dvěma nebo více moduly systému či (na té nejpodrobnější úrovni) interakci probíhající mezi jednotlivými objekty, z nichž se systém skládá. Pro tento účel slouží v jazyku UML sekvenční diagramy (sequence diagrams), v nichž lze velmi názorným způsobem naznačit časovou posloupnost posílání zpráv mezi různými typy objektů, popř. k zobrazené posloupnosti zpráv přidat další komentáře a značky. Jeden z typických a poměrně často v praxi používaných příkladů použití sekvenčních diagramů je popis komunikace s využitím síťových i jiných protokolů. Ostatně právě na síťovém protokolu (navázání spojení a zrušení spojení) si sekvenční diagramy ukážeme prakticky v navazujícím textu.
Nejjednodušší sekvenční diagram je možné v nástroji PlantUML deklarovat následujícím způsobem. Pomocí symbolu -> je naznačeno poslání zprávy mezi dvojicí objektů, v tomto případě mezi klientem a serverem. Sekvenční diagram neobsahuje žádné počáteční ani koncové pseudostavy, což je jeden z rozpoznávacích znaků mezi sekvenčním diagramem a stavovým diagramem. Proto také při odstranění pseudostavů může PlantUML automaticky změnit stavový diagram za diagram sekvenční, což je samozřejmě chyba:
@startuml Client -> Server: SYN @enduml

Obrázek 30: Sekvenční diagram vytvořený na základě předchozího demonstračního příkladu.
Druhý příklad je nepatrně složitější a ukazuje způsob navázání komunikace v protokolu TCP (tzv. three-way handshake):
@startuml Client -> Server: SYN Server -> Client: SYN-ACK Client -> Server: ACK @enduml

Obrázek 31: Sekvenční diagram vytvořený na základě dalšího demonstračního příkladu.
U sekvenčních diagramů se velmi často objevuje potřeba okomentovat jednotlivé zprávy. To zajistí klíčové slovo note doplněné o informaci, na které straně diagramu se má komentář objevit (left, right).
@startuml autonumber title TCP: Connection termination Client -[#red]> Server: FIN note left: endpoint wishes to stop its half of the connection Client <[#green]- Server: ACK note right: other end acknowledges with an ACK Client <[#red]- Server: FIN Client -[#green]> Server: ACK @enduml

Obrázek 32: Upravený sekvenční diagram.
Tento diagram (i s příslušnými popiskami) naleznete na diáři dostupném na adrese https://github.com/tisnik/jupyter-notebook-examples/blob/master/plantuml_sequence_diagram.ipynb.
15. Složitější příklady
V dalším notebooku je definován složitější sekvenční diagram popisující relativně jednoduchý systém (pipeline) pro analýzu dat získávaných z Kafky a S3 bucketů:
@startuml
hide footbox
title Data pipeline flow
entity "Kafka\ninput" as kafka1 #99ff99
database S3
box "Data pipeline" #LightBlue
control Consumer
control Downloader
control Executor
control Producer
end box
entity "Kafka\nresults" as kafka2 #ccccff
kafka1 --> Consumer : Notification about new data
Consumer --> Downloader : Download data
Downloader --> S3 : Read data from S3 bucket
S3 --> Downloader : Here's required data
Downloader --> Consumer : Here's required data
Consumer --> Executor : Run executor
Executor --> Consumer : Return report
Consumer --> Producer : Results\nin JSON format
Producer --> kafka2 : Publish\nresults\nin JSON format
@enduml
A konečně poslední příklad, tentokrát s diagramem modulárního systému (jedná se o umělý příklad získaný z reálného UML, ovšem značně zjednodušeného):
@startuml
[Projected service] as service #99ff99
[Microservice2] as microservice2 #ccccff
[Microservice1] as microservice1
[Amazon S3] as s3
package "UI" {
[Displayed data]
}
interface "REST API" as service_http
service -- service_http
interface "REST API" as microservice1_api
microservice1 -- microservice1_api
interface "Go SDK" as go_sdk
go_sdk -> s3
service_http - microservice2
microservice2 - microservice1_api
microservice2 --> go_sdk
note right of microservice1
Provide credentials
needed to access AWS S3
end note
note right of s3
Store data into specified
bucket under
selected file name
end note
s3 --> UI
@enduml
16. Jupyter Notebook a literate programming
„„Změňme náš tradiční pohled na tvorbu programů. Místo toho abychom předepsali počítači co má dělat, zkusme vysvětlovat lidským bytostem co chceme, aby počítač dělal. ‚Literární‘ programátor může být srovnáván s esejistou, jehož hlavním cílem je srozumitelné vysvětlení a vybroušený styl. Takový autor vybírá s tezaurem v ruce názvy proměnných a vysvětluje účel každé z nich. Snaží se napsat program, který je srozumitelný, protože jeho principy jsou popsány způsobem, který odpovídá lidskému myšlení a používá k tomu formální i neformální prostředky, které se navzájem doplňují.““
Donald Knuth
Jupyter Notebook a podobné nástroje jsou velmi dobře připraveny i na styl zápisu programů, pro který slavný Donald Knuth vymyslel název „literate programming“ a který použil například při vývoji TeXu. Jedná se o takový styl, ve kterém je průběžně v běžném jazyce vysvětlováno, co se má provést a jaký je očekáván výsledek. Mezi tímto slovním popisem se pak nachází jednotlivé kroky programu. Ovšem pozor – nejedná se zde o běžné dokumentační řetězce, v nichž se typicky popisuje, co provádí daný blok programu (typicky třída, metoda či funkce). Díky tomu, že v Jupyter Notebooku lze kombinovat buňky s textem s buňkami obsahujícími kód a jeho výsledky, je možné i v běžných diářích tento styl používat.
17. Ukázka diáře s popisem všech kroků
Diář, který kromě vlastních kroků pro s analýzami a výpočty obsahuje i okomentovaný postup, lze nalézt na adrese https://github.com/tisnik/jupyter-notebook-examples/blob/master/consumer_benchmarks.ipynb. V žádném případě se však nejedná o finální verzi – tu dopracujeme příště.
18. Export diáře do dalších formátů
Diář, například ten zmíněný v předchozí kapitole, lze z Jupyter Notebooku v případě potřeby vyexportovat do dalších formátů. Můžeme se například pokusit o export do Markdownu, což ovšem bude úspěšné jen částečně, a to z toho důvodu, že standardní Markdown neobsahuje podporu pro tabulky. Ty tedy musí být vloženy pomocí HTML. Grafy jsou vyexportovány do rastrových obrázků uložených v samostatném podadresáři:
$ jupyter nbconvert --to markdown consumer_benchmarks.ipynb
Podobně lze vygenerovat slajdy (pokud jsou správně definovány v diáři), a to příkazem:

$ jupyter nbconvert --to slides consumer_benchmarks.ipynb
19. Repositář s demonstračními příklady
Všechny demonstrační příklady (resp. přesněji řečeno diáře), s nimiž jsme se seznámili v předchozích kapitolách, byly uloženy do Git repositáře umístěného na GitHubu (https://github.com/tisnik/jupyter-notebook-examples/). Poslední verze souborů s diáři naleznete pod odkazy uvedenými v tabulce pod tímto odstavcem. Diář by se měl otevřít přímo v rámci stránky GitHubu:
Skripty naprogramované v Pythonu pro přímé použití (spuštění):
20. Odkazy na Internetu
- Notebook interface
https://en.wikipedia.org/wiki/Notebook_interface - Jypyter: open source, interactive data science and scientific computing across over 40 programming languages
https://jupyter.org/ - Matplotlib Home Page
http://matplotlib.org/ - Matplotlib (Wikipedia)
https://en.wikipedia.org/wiki/Matplotlib - Popis barvových map modulu matplotlib.cm
https://gist.github.com/endolith/2719900#id7 - Ukázky (palety) barvových map modulu matplotlib.cm
http://matplotlib.org/examples/color/colormaps_reference.html - Galerie grafů vytvořených v Matplotlibu
https://matplotlib.org/3.2.1/gallery/ - showcase example code: xkcd.py
https://matplotlib.org/xkcd/examples/showcase/xkcd.html - Customising contour plots in matplotlib
https://philbull.wordpress.com/2012/12/27/customising-contour-plots-in-matplotlib/ - Graphics with Matplotlib
http://kestrel.nmt.edu/~raymond/software/python_notes/paper004.html - The IPython Notebook
http://ipython.org/notebook.html - nbviewer: a simple way to share Jupyter Notebooks
https://nbviewer.jupyter.org/ - Back to the Future: Lisp as a Base for a Statistical Computing System
https://www.stat.auckland.ac.nz/~ihaka/downloads/Compstat-2008.pdf - gg4clj: a simple wrapper for using R's ggplot2 in Clojure and Gorilla REPL
https://github.com/JonyEpsilon/gg4clj - Analemma: a Clojure-based SVG DSL and charting library
http://liebke.github.io/analemma/ - Clojupyter: a Jupyter kernel for Clojure
https://github.com/roryk/clojupyter - Incanter is a Clojure-based, R-like platform for statistical computing and graphics.
http://incanter.org/ - Evolution of incanter (Gource Visualization)
https://www.youtube.com/watch?v=TVfL5nPELr4 - Questions tagged [incanter] (na Stack Overflow)
https://stackoverflow.com/questions/tagged/incanter?sort=active - Data Sorcery with Clojure
https://data-sorcery.org/contents/ - What is REPL?
https://pythonprogramminglanguage.com/repl/ - What is a REPL?
https://codewith.mu/en/tutorials/1.0/repl - Programming at the REPL: Introduction
https://clojure.org/guides/repl/introduction - What is REPL? (Quora)
https://www.quora.com/What-is-REPL - Gorilla REPL: interaktivní prostředí pro programovací jazyk Clojure
https://www.root.cz/clanky/gorilla-repl-interaktivni-prostredi-pro-programovaci-jazyk-clojure/ - R Markdown: The Definitive Guide
https://bookdown.org/yihui/rmarkdown/ - Single-page application
https://en.wikipedia.org/wiki/Single-page_application - Video streaming in the Jupyter Notebook
https://towardsdatascience.com/video-streaming-in-the-jupyter-notebook-635bc5809e85 - How IPython and Jupyter Notebook work
https://jupyter.readthedocs.io/en/latest/architecture/how_jupyter_ipython_work.html - Jupyter kernels
https://github.com/jupyter/jupyter/wiki/Jupyter-kernels - Keras: The Python Deep Learning library
https://keras.io/ - TensorFlow
https://www.tensorflow.org/ - PyTorch
https://pytorch.org/ - Seriál Torch: framework pro strojové učení
https://www.root.cz/serialy/torch-framework-pro-strojove-uceni/ - Scikit-learn
https://scikit-learn.org/stable/ - Java Interop (Clojure)
https://clojure.org/reference/java_interop - Obrazy s balíčky Jupyter Notebooku pro Docker
https://hub.docker.com/u/jupyter/#! - Správce balíčků Conda (dokumentace)
https://docs.conda.io/en/latest/ - Lorenzův atraktor
https://www.root.cz/clanky/fraktaly-v-pocitacove-grafice-vi/#k02 - Lorenzův atraktor
https://www.root.cz/clanky/fraktaly-v-pocitacove-grafice-iii/#k03 - Graphics with Matplotlib
http://kestrel.nmt.edu/~raymond/software/python_notes/paper004.html - Embedding Matplotlib Animations in Jupyter Notebooks
http://louistiao.me/posts/notebooks/embedding-matplotlib-animations-in-jupyter-notebooks/ - Literate programing, Kolokviální práce Pavla Starého
https://www.fi.muni.cz/usr/jkucera/pv109/starylp.htm - PlantUML (home page)
http://plantuml.sourceforge.net/ - PlantUML (download page)
http://sourceforge.net/projects/plantuml/files/plantuml.jar/download - PlantUML (Language Reference Guide)
http://plantuml.sourceforge.net/PlantUML_Language_Reference_Guide.pdf - Plain-text diagrams take shape in Asciidoctor!
http://asciidoctor.org/news/2014/02/18/plain-text-diagrams-in-asciidoctor/ - Graphviz – Graph Visualization Software
http://www.graphviz.org/ - graphviz (Manual Page)
http://www.root.cz/man/7/graphviz/ - PIL: The friendly PIL fork (home page)
https://python-pillow.org/ - Python Imaging Library (PIL), (home page)
http://www.pythonware.com/products/pil/ - PIL 1.1.6 na PyPi
https://pypi.org/project/PIL/ - Pillow 5.2.0 na PyPi
https://pypi.org/project/Pillow/ - Python Imaging Library na Wikipedii
https://en.wikipedia.org/wiki/Python_Imaging_Library - Pillow na GitHubu
https://github.com/python-pillow/Pillow - Pillow – dokumentace na readthedocs.io
http://pillow.readthedocs.io/en/5.2.x/ - How to use Pillow, a fork of PIL
https://www.pythonforbeginners.com/gui/how-to-use-pillow