
Obsah
1. Problematika operací pro celočíselný součin a podíl
2. Operace s hodnotami s plovoucí řádovou čárkou
3. Význam prefixů a sufixů u instrukcí
4. Instrukční sady ORFPX32 a ORFPX64
6. Rychlost provedení základních FP operací
7. Základní aritmetické operace: součet, součin, rozdíl, podíl, zbytek po dělení
8. Operace typu multiply-accumulate
10. Instrukce určené pro porovnání dvou hodnot s nastavením příznaku F
11. Stručné porovnání OpenRISCu s architekturou RISC-V v oblasti FP operací
12. FP operace specifikované v ISA v RISC-V
13. Implementace instrukcí SIMD na mikroprocesorech RISC
14. „Vektorové“ operace podporované architekturou OpenRISC
15. Saturace při provádění SIMD operací
16. Podporované typy vektorů a jejich prvků
19. Spojení a rozdělení prvků vektorů
1. Problematika operací pro celočíselný součin a podíl
V úvodní kapitole se budeme zabývat problematikou provádění operací součinu a podílu na RISCových mikroprocesorech, samozřejmě včetně jader OpenRISC, které nás dnes zajímají nejvíce. Připomeňme si, že tyto operace patří – alespoň z pohledu programátora – do skupiny aritmetických operací. Jádra OpenRISC mohou – v závislosti na konkrétní konfiguraci čipu – podporovat následující množinu operací pro násobení a dělení:
| # | Instrukce | Význam |
|---|---|---|
| 1 | l.mul | násobení (se znaménkem) |
| 2 | l.mulu | násobení (bez znaménka) |
| 3 | l.muli | násobení konstantou (se znaménkem) |
| 4 | l.muld | násobení s přesunem výsledku do jednotky MAC |
| 5 | l.muldu | násobení s přesunem výsledku do jednotky MAC |
| 6 | l.div | celočíselné dělení (se znaménkem) |
| 7 | l.divu | celočíselné dělení (bez znaménka) |
Kde tedy spočívá onen zmíněný problém? Všechny ostatní operace vykonávané aritmeticko-logickou jednotkou jsou totiž provedeny v jediném strojovém cyklu, což je ostatně chování, které u RISCových jader očekáváme (připomeňme si jen, že provedení operace odpovídá fázi EX v pipeline). Ovšem operace násobení je složitější a je tedy provedena ve třech cyklech a dělení dokonce v cyklech třiceti dvou! Podívejme se na následující tabulku s většinou operací OpenRISCu spadajících do ISA ORBIS32 (kromě skoků, kde záleží na existenci branch delay slotu):
| Instrukce | Počet cyklů pro výpočet |
|---|---|
| základní aritmetické operace | 1 |
| celočíselné násobení | 3 |
| celočíselné dělení | 32 |
| porovnání, nastavení F | 1 |
| logické operace | 1 |
| rotace a posuny | 1 |
| přenosy dat | 1 |
To, že výpočet některých operací trvá déle, než jeden strojový cyklus, představuje poměrně velký problém, zvláště pro RISCové procesory. Při návrhu různých RISCových architektur se inženýři s tímto problémem vypořádali různými způsoby. Pěkným příkladem může být řešení použité u architektury MIPS-I, v níž byla násobička a dělička zcela oddělena od aritmeticko-logické jednotky a dokonce se v ní využívaly vlastní registry nazvané HI a LO, které byly odděleny od sady pracovních registrů.
Odlišným způsobem bylo násobení a dělení řešeno v instrukční sadě procesorů SPARC-V7. V této ISA je možné najít instrukci nazvanou MULScc, neboli Multiply Step and Modify icc, která dokázala při svém zavolání provést jeden krok násobení dvojice 32bitových celých čísel s 64bitovým mezivýsledkem (polovina mezivýsledku se ukládala do pomocného speciálního registru Y ležícího mimo sadu 32 viditelných pracovních registrů). Optimalizovaný programový kód pro násobení dokázal s využitím instrukce MULScc vynásobit dvě celá čísla bez znaménka za 47 strojových cyklů, popř. dvě celá čísla se znaménkem za 51 strojových cyklů, což sice není zanedbatelná doba, ale operace násobení i dělení trvaly poměrně dlouho i u dalších dobových mikroprocesorů, které je měly implementovány přímo v mikrokódu (například 80×86).
Jednou z nejviditelnějších změn, s níž se setkali programátoři mikroprocesorů s architekturou SPARC-V8, bylo právě přidání nových instrukcí určených pro provedení aritmetické operace celočíselného násobení a dělení. Ukazuje se zde částečný odklon od čistého RISCového procesoru, kde čistota návrhu byla vyvážena praktičtějším používáním. Navíc se díky tomu, že násobení a dělení probíhá v součinnosti s ALU, mohly instrukce pro násobení a dělení nastavovat příznakové bity, podobně jako to dokážou ostatní ALU operace:
| # | Instrukce | Význam |
|---|---|---|
| 1 | MULScc | provedení jednoho kroku násobení (převzato z V7) |
| 2 | UMUL | násobení dvojice celočíselných hodnot bez znaménka |
| 3 | SMUL | násobení dvojice celočíselných hodnot se znaménkem |
| 4 | UDIV | dělení dvojice celočíselných hodnot bez znaménka |
| 5 | SDIV | dělení dvojice celočíselných hodnot se znaménkem |
| 6 | UMULcc | odpovídá instrukci UMUL, ovšem nastaví i příznakové bity |
| 7 | SMULcc | odpovídá instrukci SMUL, ovšem nastaví i příznakové bity |
| 8 | UDIVcc | odpovídá instrukci UDIV, ovšem nastaví i příznakové bity |
| 9 | SDIVcc | odpovídá instrukci SDIV, ovšem nastaví i příznakové bity |
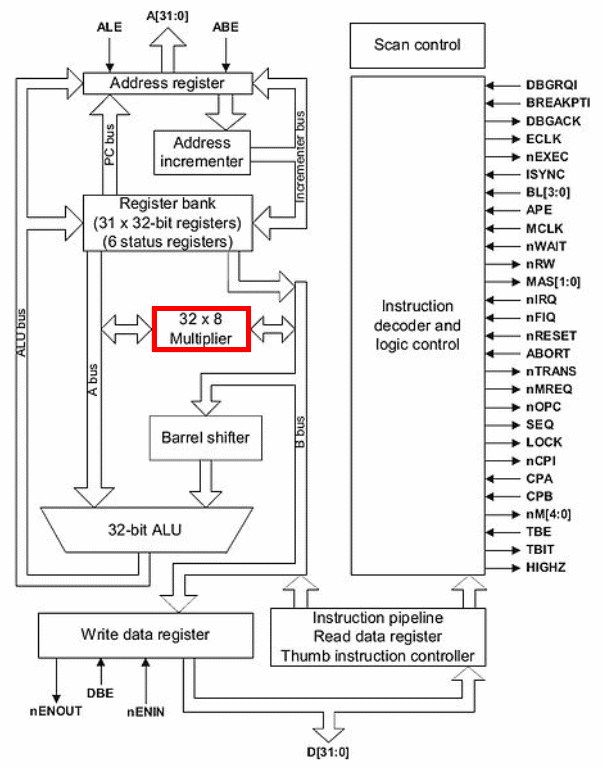
Obrázek 1: I první dvě generace RISCových mikroprocesorů ARM měly násobičku oddělenou od běžného ALU. Násobička navíc prováděla zvolenou operaci delší dobu než tomu bylo v aritmeticko-logické jednotce u kratších a jednodušších operací.
2. Operace s hodnotami s plovoucí řádovou čárkou
Připomeňme si, že čipy s jádry OpenRISC jsou široce konfigurovatelné a jejich tvůrci dokonce mají možnost volby, které instrukční sady budou podporovány. Seznam instrukčních sad jsme si již uvedli minule, takže jen ve stručnosti:
| # | Zkratka | Celé jméno | Stručný popis |
|---|---|---|---|
| 1 | ORBIS32 | OpenRISC Basic Instruction Set | zpracování 32bitových operandů, skoky, podmínky, bitové operace |
| 2 | ORBIS64 | OpenRISC Basic Instruction Set | rozšíření na 64bitové operandy |
| 3 | ORFPX32 | OpenRISC Floating Point eXtension | operace s numerickými hodnotami typu float/single (jednoduchá přesnost) |
| 4 | ORFPX64 | OpenRISC Floating Point eXtension | operace s numerickými hodnotami typu double (dvojitá přesnost) |
| 5 | ORVDX64 | OpenRISC Vector/DSP eXtension | zpracování hodnot uložených v 64bitových vektorech |
Instrukční sadu ORBIS32 jsme si již poměrně podrobně popsali minule. Dnes nás budou zajímat především ISA ORFPX32 a ORFPX64, což jsou instrukční sady realizující operace s hodnotami reprezentovanými ve formátu s plovoucí řádovou čárkou. Tyto dvě instrukční sady si popíšeme společně, protože většina instrukcí je totožných a liší se jen typem operandů.
3. Význam prefixů a sufixů u instrukcí
V úvodním článku o architektuře OpenRISC byly popsány instrukce, které začínaly prefixem „l.“. Tímto prefixem se označují instrukce z ISA ORBIS32, popř. ORBIS64. Všechny operace s hodnotami s plovoucí řádovou čárkou používají prefix „lf.“ a „vektorové“ operace pak prefix „lv.“:
| Prefix | Význam |
|---|---|
| l. | celočíselné operace, řídicí instrukce, load & store atd. |
| lf. | operace s FP hodnotami |
| lv. | „vektorové“ (SIMD) operace |
U některých instrukcí se navíc používá i sufix, tj. znak zapsaný za jméno instrukce a oddělený od mnemotechnického kódu tečkou. V současné variantě specifikace OpenRISC se setkáme s těmito sufixy:
| Sufix | Význam | Použito |
|---|---|---|
| s | single (float) | ORFPX32 |
| d | double | ORFPX64 |
| b | byte (8 bitů) | ORVDX64 |
| h | half word (16 bitů) | ORVDX64 |
Podívejme se nyní na příklady. Bude se jednat o instrukci součtu, ovšem pokaždé provedeného odlišným způsobem:
| Instrukce | Význam |
|---|---|
| l.add | součet dvou celočíselných operandů uložených v pracovních registrech |
| lf.add.s | součet dvou FP operandů typu single uložených v pracovních registrech |
| lf.add.d | součet dvou FP operandů typu double uložených v pracovních registrech |
| lv.add.b | součet osmi operandů typu byte uložených v 64bitových pracovních registrech |
| lv.add.h | součet čtyř operandů typu half word uložených v 64bitových pracovních registrech |
4. Instrukční sady ORFPX32 a ORFPX64
Ve specifikaci OpenRISC jsou (prozatím) popsány dvě instrukční sady určené pro práci s hodnotami s plovoucí řádovou čárkou. První sada se jmenuje ORFPX32 a slouží pro zpracování hodnot typu float/single podle normy IEEE 754. Další sada se jmenuje ORFPX64. Tato sada je určena pro 64bitové čipy (!) a umožňuje zpracování hodnot typu double, opět podle IEEE 754. Ve skutečnosti obsahuje poslední úprava normy IEEE 754 i další formáty, ovšem široce podporované jsou právě float/single a double:
| Norma/systém | Šířka (b) | Báze | Exponent (b) | Mantisa (b) |
|---|---|---|---|---|
| IEEE 754 half | 16 | 2 | 5 | 10+1 |
| IEEE 754 single | 32 | 2 | 8 | 23+1 |
| IEEE 754 double | 64 | 2 | 11 | 52+1 |
| IEEE 754 double extended | 80 | 2 | 15 | 64 |
| IEEE 754 quadruple | 128 | 2 | 15 | 112+1 |
| IEEE 754 octuple | 256 | 2 | 19 | 236+1 |
Instrukční sada s instrukcemi pro FP operace je pojata přísně minimalisticky. Nalezneme zde především instrukce určené pro provádění základních aritmetických operací, dále instrukce pro konverzi dat a taktéž instrukce pro porovnání dvou hodnot s nastavením příznaku F. Instrukční sada je malá i z toho důvodu, že všechny operace jsou prováděny s hodnotami, které již musí být uloženy v běžných pracovních registrech (general purpose registers), což je dosti zvláštní řešení. Všech třicet v současnosti podporovaných instrukcí je vypsáno v další tabulce:
| Instrukce | Instrukce | Instrukce | Instrukce | Instrukce |
|---|---|---|---|---|
| lf.add.s | lf.div.s | lf.sfeq.s | lf.sfgt.s | lf.ftoi.d |
| lf.add.d | lf.div.d | lf.sfeq.d | lf.sfgt.d | lf.ftoi.s |
| lf.sub.s | lf.rem.s | lf.sfne.s | lf.sfle.s | lf.itof.d |
| lf.sub.d | lf.rem.d | lf.sfne.d | lf.sfle.d | lf.itof.s |
| lf.mul.s | lf.madd.s | lf.sfge.s | lf.sflt.s | lf.cust1.s |
| lf.mul.d | lf.madd.d | lf.sfge.d | lf.sflt.d | lf.cust1.d |
5. Registr FPSCR
Všechny FP operace sice probíhají nad běžnými pracovními registry a výsledky porovnávacích operací nastavují příznak F, ovšem jádra OpenRISC, které FP operace podporují, ještě obsahují další specializovaný registr nazvaný FPSCR neboli Floating Point Control Status Register (prakticky totožné jméno mají tyto registry i na dalších architekturách s výjimkou x86–64 :-). V tomto registru jsou umístěny bity řídicí způsob provádění FP operací a další bity (vlastně příznaky) jsou nastavovány po všech FP operacích, takže je lze použít pro zjištění, proč například nastala při výpočtech výjimka atd.:
| Bity | Označení | Význam |
|---|---|---|
| 0 | FPEE | povolení či zákaz výjimek při FP operacích |
| 1–2 | RM | zaokrouhlovací režim: k nejbližšímu číslu, k 0, k -∞, k +∞ |
| 3 | OVF | příznak přetečení |
| 4 | UNF | příznak podtečení |
| 5 | SNF | příznak „signalling“ NaN |
| 6 | QNF | příznak „quiet“ NaN |
| 7 | ZF | operace skončila s nulovým výsledkem |
| 8 | IXF | nepřesný výsledek (bez normalizace) |
| 9 | IVF | neplatný výsledek |
| 10 | INF | výsledkem je nekonečno |
| 11 | DZF | došlo k dělení nulou |
| 12–31 | reserved | rezervováno pro další rozšíření |
6. Rychlost základních FP operací
Podívejme se nyní, jak rychlé (nebo pomalé) je vykonání základních operací s operandy reprezentovanými v systému plovoucí řádové čárky. Počet strojových cyklů, který si můžete přečíst v následující tabulce, je převzat ze specifikace referenční architektury, takže je možné, že v budoucnu může dojít k vylepšení, většinou ovšem za cenu komplikovanějšího čipu:
| Instrukce | Počet cyklů pro výpočet |
|---|---|
| součet, rozdíl | 10 |
| součin | 38 |
| podíl | 37 |
| porovnání, nastavení příznaku F | 2 |
| konverze hodnot | 7 |
7. Základní aritmetické operace: součet, součin, rozdíl, podíl, zbytek po dělení
V této kapitole jsou popsány všechny základní aritmetické operace, tj. součet, rozdíl, součin, podíl a zbytek po dělení (tj. všechny FP operace, s nimiž se setkáme například v jazyku C):
| # | Instrukce | Datový typ | Význam |
|---|---|---|---|
| 1 | lf.add.s | single | součet dvou operandů |
| 2 | lf.add.d | double | součet dvou operandů |
| 3 | lf.sub.s | single | rozdíl dvou operandů |
| 4 | lf.sub.d | double | rozdíl dvou operandů |
| 5 | lf.mul.s | single | součin dvou operandů |
| 6 | lf.mul.d | double | součin dvou operandů |
| 7 | lf.div.s | single | podíl dvou operandů |
| 8 | lf.div.d | double | podíl dvou operandů |
| 9 | lf.rem.s | single | zbytek po dělení dvou operandů |
| 10 | lf.rem.d | double | zbytek po dělení dvou operandů |
Všechny tyto operace používají standardní formát R, který je nepatrně upraven, protože bity 8 až 10 jsou rezervovány pro další případná rozšíření instrukční sady:
+-----+------+--------+--------+--------+-------+------------------+ |31 30|29 26| 25 21 | 20 16 | 15 11 | 10 8 | 7 0 | +-----+------+--------+--------+--------+-------+------------------+ |třída|opcode| rD (5) | rA (5) | rB (5) |rezerva| druhá část opcode| +-----+------+--------+--------+--------+-------+------------------+
8. Operace typu multiply-accumulate
K aritmetickým instrukcím můžeme přiřadit i instrukce typu multiply-accumulate neboli MAC. Již minule jsme se setkali s několika instrukcemi tohoto typu, ovšem to se jednalo o instrukce celočíselné. Zajímavé a užitečné je, že i v instrukčních sadách ORFPX32 a ORFPX64 podobné instrukce nalezneme, což je patrné z následující tabulky:
| # | Instrukce | Typ dat | Význam |
|---|---|---|---|
| 1 | lf.madd.s | single | součin dvou registrů obsahujících hodnoty typu single |
| 2 | lf.madd.d | double | součin dvou registrů obsahujících hodnoty typu double |
Tyto instrukce se od běžného součinu liší především v tom ohledu, že se výsledek součin neuloží do třetího pracovního registru, ale přičte se k obsahu speciálních registrů FPMADDLO a FPMADDHI (patřících do skupiny 11).
9. Konverzní operace
První dvě instrukce, s nimiž se seznámíme v této kapitole, slouží pro zaokrouhlení hodnoty typu float, popř. double na celé číslo (pokud je to samozřejmě možné). Další dvě instrukce jsou určeny pro konverzi hodnot mezi celočíselným typem int (long) na typ float popř. na typ double. V tomto případě dochází ke ztrátě přesnosti, protože několik bitů u FP hodnot je vždy použito pro uložení exponentu:
| # | Instrukce | Význam |
|---|---|---|
| 1 | lf.ftoi.d | převod hodnoty typu double na 64bitové celé číslo |
| 2 | lf.ftoi.s | převod hodnoty typu single/float na 32bitové celé číslo |
| 3 | lf.itof.d | převod 64bitového celého čísla na double |
| 4 | lf.itof.s | převod 32bitového celého čísla na single/float |
10. Instrukce určené pro porovnání dvou hodnot s nastavením příznaku F
Další skupina instrukcí slouží pro porovnání dvou hodnot, ať již typu single/float či double. Výsledkem porovnání je pravdivostní hodnota reprezentovaná jediným bitem, který je uložen do příznaku F, s nímž jsme se seznámili minule. Povšimněte si, že se toto chování odlišuje od mnoha dalších architektur, a to včetně ARMů či RISCu-V atd. U většiny architektur je k dispozici méně instrukcí pro porovnání, ovšem tyto instrukce nastavují větší množství příznaků (například současně příznak nulovosti a zápornosti). U OpenRISCu máme k dispozici všechny základní relační operace, které ovšem nastavují příznak jediný (podobné chování mají velmi elegantně navržená jádra SH-2A).
| # | Instrukce | Datový typ | Význam |
|---|---|---|---|
| 1 | lf.sfeq.s | single | porovnání dvou hodnot na rovnost |
| 2 | lf.sfeq.d | double | porovnání dvou hodnot na rovnost |
| 3 | lf.sfne.s | single | porovnání dvou hodnot na nerovnost |
| 4 | lf.sfne.d | double | porovnání dvou hodnot na nerovnost |
| 5 | lf.sfge.s | single | porovnání dvou hodnot na relaci „větší nebo rovno“ |
| 6 | lf.sfge.d | double | porovnání dvou hodnot na relaci „větší nebo rovno“ |
| 7 | lf.sfgt.s | single | porovnání dvou hodnot na relaci „větší než“ |
| 8 | lf.sfgt.d | double | porovnání dvou hodnot na relaci „větší než“ |
| 9 | lf.sfle.s | single | porovnání dvou hodnot na relaci „menší nebo rovno“ |
| 10 | lf.sfle.d | double | porovnání dvou hodnot na relaci „menší nebo rovno“ |
| 11 | lf.sflt.s | single | porovnání dvou hodnot na relaci „menší než“ |
| 12 | lf.sflt.d | double | porovnání dvou hodnot na relaci „menší než“ |
Tyto instrukce používají instrukční slova, v nichž je několik bitů nevyužitých:
+-----+------+---------+--------+--------+-------+------------------+ |31 30|29 26| 25 21 | 20 16 | 15 11 | 10 8 | 7 0 | +-----+------+---------+--------+--------+-------+------------------+ |třída|opcode|nevyužito| rA (5) | rB (5) |rezerva| druhá část opcode| +-----+------+---------+--------+--------+-------+------------------+
11. Stručné porovnání OpenRISCu s architekturou RISC-V v oblasti FP operací
Jen pro zajímavost se ve stručnosti podívejme, jakým způsobem jsou výpočty s hodnotami v pohyblivé řádové čárce realizovány v konkurenčním projektu RISC-V. I tato zajímavá (a úspěšnější) architektura totiž umožňuje – pokud je to samozřejmě s ohledem na řešený problém nutné – FPU do čipu přidat. Ve skutečnosti existují dokonce dvě rozšíření původní ISA. První rozšíření se jmenuje jednoduše „F“, protože specifikuje instrukce s hodnotami typu single/float, tj. s čísly s jednoduchou přesností podle normy IEEE 754–2008 (jedná se o zpřesnění původní slavné normy IEEE 754). Instrukce, které v tomto rozšíření ISA nalezneme, zhruba odpovídají výše popsané instrukční sadě ORFPX32.
Druhé rozšíření se podle očekávání jmenuje „D“, protože předepisuje operace s hodnotami typu double, tj. s čísly s přesností dvojitou. To zhruba odpovídá instrukční sadě ORFPX64. Proč však došlo k rozdělení funkcí matematického koprocesoru na dvě části? Existují totiž aplikace, v nichž postačuje pracovat s typem single/float, takže by v tomto případě podpora dvojnásobné přesnosti pouze přinášela komplikace v realizaci mikroprocesoru (ostatně i tak jsou obecně operace s plovoucí řádovou čárkou pomalejší, než celočíselné operace RISCové aritmeticko-logické jednotky). Dokonce existují i aplikace vyžadující malý a rychlý mikroprocesor s nativní podporou typu half-float, což jsou 16bitová čísla se znaménkem, mantisou i exponentem (zavedeny byly například v dnes již zapomenutém jazyce Cg).
Dalším rozšířením instrukčních sad je rozšíření označené písmenem „Q“. To přidává možnost práce s numerickými hodnotami s plovoucí řádovou čárkou se čtyřnásobnou přesností. Formát uložení těchto hodnot je specifikován v již několikrát zmíněné normě IEEE 754–2008. Ostatně podívejme se na následující tabulku, v níž jsou vypsány vybrané formáty numerických hodnot, které jsou v této normě specifikovány (vynechávám takzvané „decimální“ formáty) a jak se tyto formáty mapují na rozšířené instrukční sady mikroprocesorů RISC-V:
| Oficiální jméno | Známo též jako | Znaménko | Exponent | Mantisa | Celkem | Decimálních číslic | RISV-5 |
|---|---|---|---|---|---|---|---|
| binary16 | half | 1 | 5b | 10b | 16b | cca 3,3 | není |
| binary32 | single/float | 1 | 8b | 23b | 32b | cca 7,2 | „F“ |
| binary64 | double | 1 | 11b | 52b | 64b | cca 15,9 | „D“ |
| binary128 | quadruple | 1 | 15b | 112b | 128b | cca 34,0 | „Q“ |
Pro rozšíření se jménem „F“ se používá nová sada pracovních registrů. Tyto registry jsou pojmenovány f0 až f31 a každý z těchto registrů má šířku 32 bitů. Podobně je tomu u rozšíření „D“, ovšem s tím rozdílem, že registry budou mít šířku celých 64 bitů. Navíc se u většiny operací používá i stavový a řídicí registr nazvaný fcrs.
12. FP operace specifikované v ISA v RISC-V
Následuje tabulka se všemi instrukcemi, které nalezneme v instrukční sadě „F“ čipů s jádrem RISC-V:
| # | Instrukce | Význam |
|---|---|---|
| 1 | FLW | načtení FP hodnoty z paměti (adresa rs+offset) |
| 2 | FSW | uložení FP hodnoty do paměti (adresa rs+offset) |
| 3 | FADD.S | součet dvou FP hodnot (tříadresový kód) |
| 4 | FSUB.S | rozdíl dvou FP hodnot |
| 5 | FMUL.S | součin dvou FP hodnot |
| 6 | FDIV.S | podíl dvou FP hodnot |
| 7 | FMIN.S | vrací menší z obou FP hodnot |
| 8 | FMAX.S | vrací větší z obou FP hodnot |
| 9 | FSQRT.S | druhá odmocnina (použity jsou jen dva registry) |
| 10 | FMADD.S | rs1×rs2+rs3 (multiply-add, čtyřadresový kód!) |
| 11 | FMSUB.S | rs1×rs2-rs3 |
| 12 | FNMADD.S | -(rs1×rs2+rs3) |
| 13 | FNMSUB.S | -(rs1×rs2-rs3) |
| 14 | FCVT.W.S | převod FP na integer |
| 15 | FCVT.S.W | převod integer na FP |
| 16 | FCVT.WU.S | převod FP na unsigned integer |
| 17 | FCVT.S.WU | převod unsigned integer na FP |
| 18 | FMV.X.S | pouze přesun mezi integer registrem a FP registrem (nikoli konverze) |
| 19 | FMV.S.X | pouze přesun mezi FP registrem a integer registrem (nikoli konverze) |
| 20 | FLT.S | porovnání dvou FP hodnot, zápis 0 či 1 do integer registru |
| 21 | FLE.S | porovnání dvou FP hodnot, zápis 0 či 1 do integer registru |
| 22 | FEQ.S | porovnání dvou FP hodnot, zápis 0 či 1 do integer registru |
| 21 | FCLASS | zjistí „třídu“ FP hodnoty a nastaví deset bitů podle následující tabulky |
Výsledek instrukce FCLASS zapsaný do vybraného integer registru:
| Index bitu | Význam |
|---|---|
| 0 | záporné nekonečno |
| 1 | záporné číslo (normalizovaná hodnota) |
| 2 | záporné číslo (nelze normalizovat) |
| 3 | záporná nula |
| 4 | kladná nula |
| 5 | kladné číslo (nelze normalizovat) |
| 6 | kladné číslo (normalizovaná hodnota) |
| 7 | kladné nekonečno |
| 8 | NaN (signaling) |
| 9 | NaN (quiet, lze je předat do mnoha instrukcí) |
Základní aritmetické operace v rozšíření „D“ jsou prakticky stejné, pouze mají odlišný postfix:
| # | Instrukce | Význam |
|---|---|---|
| 1 | FADD.D | součet dvou FP hodnot (tříadresový kód) |
| 2 | FSUB.D | rozdíl dvou FP hodnot |
| 3 | FMUL.D | součin dvou FP hodnot |
| 4 | FDIV.D | podíl dvou FP hodnot |
| 5 | FMIN.D | vrací menší z obou FP hodnot |
| 6 | FMAX.D | vrací větší z obou FP hodnot |
| 7 | FSQRT.D | druhá odmocnina (použity jsou jen dva registry) |
Dále jsou definovány konverzní operace mezi hodnotami s jednoduchou přesností a přesností dvojitou:
| # | Instrukce | Význam |
|---|---|---|
| 1 | FCVT.S.D | double na single (provádí se zaokrouhlení) |
| 2 | FCVT.D.S | single na double (hodnota se nezmění) |
Zapomenout nesmíme ani na konverzi mezi hodnotami typu integer a double, ovšem některé konverze lze provádět pouze na 64bitových procesorech s instrukční sadou RV64I (už jen z toho důvodu, že na 32bitových procesorech nejsou k dispozici dostatečně široké pracovní registry):
| # | Instrukce | Význam |
|---|---|---|
| 1 | FCVT.W.D | double → 32bit signed integer |
| 2 | FCVT.L.D | double → 64bit signed integer |
| 3 | FCVT.WU.D | double → 32bit unsigned integer |
| 4 | FCVT.LU.D | double → 64bit unsigned integer |
| 5 | FCVT.D.W | 32bit signed integer → double |
| 6 | FCVT.D.L | 64bit signed integer → double |
| 7 | FCVT.D.WU | 32bit unsigned integer → double |
| 8 | FCVT.D.LU | 64bit unsigned integer → double |
I instrukce pro práci se znaménky mají svoji 64bitovou obdobu:
| # | Instrukce | Význam |
|---|---|---|
| 1 | FSGNJ.D | kopie z registru src1 do dest, ovšem kromě znaménka; to je přečteno ze src2 |
| 2 | FSGNJN.D | kopie z registru src1 do dest, ovšem kromě znaménka; to je přečteno ze src2 a znegováno |
| 3 | FSGNJX.D | kopie z registru src1 do dest, ovšem kromě znaménka; to je získáno ze src1 i src2 s využitím operace XOR |
Stejně jako přesuny bitové kopie mezi celočíselným registrem a FP registrem (opět platí pouze pro 64bitovou instrukční sadu):
| # | Instrukce | Význam |
|---|---|---|
| 1 | FMV.X.D | pouze přesun mezi integer registrem a FP registrem (nikoli konverze) |
| 1 | FMV.D.X | pouze přesun mezi FP registrem a integer registrem (nikoli konverze) |
13. Implementace instrukcí SIMD na mikroprocesorech RISC
Prakticky u všech RISCových architektur došlo (dříve či později) k rozšíření jejich ISA o SIMD operace, což si samozřejmě vyžádalo modifikace ALU. Ve skutečnosti se dokonce tento typ instrukcí poprvé objevil právě na mikroprocesorech RISC a teprve se zhruba dvouletým zpožděním byl převzat i na původně čistě CISCovou architekturu x86 (ostatně se zdaleka nejedná o první ani o poslední technologii, která byla na x86 převzata právě z RISCových procesorů).

Obrázek 2: Superpočítač Cray-1 byl jedním ze superpočítačů s velmi dobrou podporou vektorových operací, ať se to týkalo instrukční sady, tak i podpory v překladači Fortranu. Ve skutečnosti se však dnešní „vektorové“ instrukce odlišují od implementace provedené Seymourem Crayem.
Důvodů, proč se vlastně instrukce typu SIMD na RISCových procesorech vůbec objevily, je větší množství. Jedním z nich je to, že se tyto procesory začaly používat v grafických pracovních stanicích, mj. i pro zpracování videa, provádění rastrových operací i 3D operací (před masivním příchodem grafických akcelerátorů a GPU), což je přesně ta oblast, v níž je možné informace zpracovávat nikoli jen ve formě skalárních dat, ale i jako vektory pevné délky. Dalším důvodem byla snaha výrobců RISCových procesorů o průnik na trh s počítači určenými pro náročné výpočty (jedná se o určitý mezistupeň mezi výkonnými pracovními stanicemi a superpočítači). V tomto oboru se mnoho algoritmů provádí nad maticemi a vektory obsahujícími numerické hodnoty reprezentované v systému plovoucí řádové čárky (FP: Floating Point). Třetím důvodem je samozřejmě snaha o zvýšení výpočetního výkonu a právě SIMD instrukce k němu mohou vést, aniž by bylo nutné radikálně měnit používanou výrobní technologii čipů (zvyšovat úroveň integrace, snižovat napěťové úrovně či zvyšovat frekvenci, popř. přidávat vyrovnávací paměti/cache).

Obrázek 3: Superpočítač CDC 7600 je předchůdcem superpočítačů Cray. Dnes se samozřejmě jedná o historický stroj z počítačového pravěku.
Prakticky každá významnější společnost (v případě PowerPC pak dokonce aliance) navrhující mikroprocesory s architekturou RISC přišla dříve či později na trh s instrukční sadou obsahující „vektorové“ instrukce, které jsou dnes souhrnně označovány zkratkou SIMD (původní vektorové instrukce používané na superpočítačích jsou v některých ohledech flexibilnější, proto budeme používat spíše zkratku SIMD). Rozšiřující instrukční sady byly pojmenovávány nejrůznějšími názvy a zkratkami a nikdy vlastně nedošlo – na rozdíl od platformy x86 – ke sjednocení těchto instrukcí do jediné skupiny „SIMD pro RISC“, což je vlastně logické, protože procesory RISC jsou mnohdy určeny pro specializované oblasti použití, od vestavných (embedded) systémů přes smartphony a tablety až po superpočítače.

Obrázek 4: Mikroprocesor HP PA-RISC 7300LC (PA=Precision Architecture). Jedná se moderní variantu procesorů RISC se zabudovaným matematickým koprocesorem a sadou 32bitových celočíselných registrů a taktéž 64bitových registrů pro FPU operace.
Zdroj obrázku: Wikipedia
Nejvýznamnější implementace instrukcí SIMD na mikroprocesorech s architekturou RISC, ať již se jedná o instrukce určené pro operace s celými čísly či s čísly reálnými (přesněji řečeno s plovoucí řádovou čárkou), jsou vypsány v následující tabulce:
| # | Zkratka/název | Plný název | Rodina procesorů |
|---|---|---|---|
| 1 | MAX-1 | Multimedia Acceleration eXtensions v1 | HP-PA RISC |
| 2 | MAX-2 | Multimedia Acceleration eXtensions v2 | HP-PA RISC |
| 3 | VIS 1 | Visual Instruction v1 | Set SPARC V9 |
| 4 | VIS 2 | Visual Instruction v2 | Set SPARC V9 |
| 5 | AltiVec | (obchodní názvy Velocity Engine, VMX) | PowerPC |
| 6 | MDMX | MIPS Digital Media eXtension (MaDMaX) | MIPS |
| 7 | MIPS-3D | MIPS-3D | MIPS |
| 8 | MVI | Motion Video Instructions | DEC Alpha |
| 9 | NEON | Advanced SIMD | Cortex (ARMv7) |
| 10 | ORVDX64 | OpenRISC Vector/DSP eXtension | OpenRISC |
14. „Vektorové“ operace podporované architekturou OpenRISC
Skupina vektorových instrukcí u čipů s architekturou OpenRISC je sice poměrně rozsáhlá, ovšem je tomu tak z toho důvodu, že prakticky každá instrukce existuje ve dvou variantách podle toho, zda se zpracovávají vektory s prvky typu bajt (8 bitů) či půlslovo (16 bitů). V prvním případě obsahuje každý vektor osm prvků, ve druhém případě pak čtyři prvky. U mnoha instrukcí se taktéž rozlišuje, zda se má operace provést se saturací nebo bez saturace. A konečně nejvíce instrukcí je určeno pro porovnání korespondujících prvků dvou vektorů – buď musí být podmínka splněna pro všechny prvky, alespoň pro jeden prvek, popř. je možné výsledek uložit ve formě bitového pole do cílového registru.
15. Saturace při provádění SIMD operací
Zatímco při provádění aritmetických operací s využitím klasické aritmeticko-logické jednotky může docházet k přetečení či podtečení hodnot při provádění instrukcí typu ADD či SUB (součet, rozdíl), je chování instrukcí ORVDX64 odlišné, protože operace podporují takzvanou saturaci, což znamená, že v případě přetečení se do výsledku uloží maximální reprezentovatelná hodnota a naopak při podtečení minimální hodnota, což je například při zpracování signálu (většinou) žádoucí chování. Ostatně podívejme se na následující obrázky, kde je význam saturace popsán:

Obrázek 5: Zdrojový rastrový obrázek (známá fotografie Lenny), který tvoří zdroj pro jednoduchý konvoluční (FIR) filtr, jenž zvyšuje hodnoty pixelů o pevně zadanou konstantu (offset).

Obrázek 6: Pokud je pro přičtení offsetu použita operace součtu se zanedbáním přenosu (carry), tj. když se počítá systémem „modulo N“, dochází při překročení maximální hodnoty pixelu (čistě bílá barva) k jasně viditelným chybám.

Obrázek 7: Při použití operace součtu se saturací sice taktéž dojde ke ztrátě informace (vzniknou oblasti s pixely majícími hodnotu 255), ovšem viditelná chyba je mnohem menší, než na předchozím obrázku.
16. Podporované typy vektorů a jejich prvků
Většina nových instrukcí přidaných v rámci instrukční sady ORVDX64 je určena pro provádění aritmetických a bitových operací s celočíselnými operandy o šířce 8 a 16 bitů, což pokrývá poměrně širokou oblast multimediálních dat – osmibitových i šestnáctibitových zvukových vzorků (samplů), barev pixelů (RGB, RGBA) atd. V následující tabulce jsou vypsány nově podporované datové typy i způsob jejich uložení ve slovech o šířce 64 bitů, které jsou zpracovávány:
| Datový typ | Suffix instrukce | Bitová šířka operandu | Počet prvků vektoru |
|---|---|---|---|
| byte | .b | 8 bitů | 8 |
| half word | .h | 16 bitů | 4 |
17. Aritmetické a logické operace
Skupina aritmetických operací je velmi rozsáhlá, zejména protože velké množství instrukcí existuje ve více variacích (různé datové typy, se saturací/bez saturace, atd.). Navíc do této skupiny řadíme i instrukce pro výpočet minima, maxima a průměru:
| # | Instrukce | Datový typ | Význam |
|---|---|---|---|
| 1 | lv.add.b | signed byte | součet dvou osmiprvkových vektorů s přetečením |
| 2 | lv.add.h | signed half word | součet dvou čtyřprvkových vektorů s přetečením |
| 3 | lv.adds.b | signed byte | součet dvou osmiprvkových vektorů se saturací |
| 4 | lv.adds.h | signed half word | součet dvou čtyřprvkových vektorů se saturací |
| 5 | lv.addu.b | unsigned byte | součet dvou osmiprvkových vektorů s přetečením |
| 6 | lv.addu.h | unsigned half word | součet dvou čtyřprvkových vektorů s přetečením |
| 7 | lv.addus.b | unsigned byte | součet dvou osmiprvkových vektorů se saturací |
| 8 | lv.addus.h | unsigned half word | součet dvou čtyřprvkových vektorů se saturací |
| 9 | lv.sub.b | signed byte | rozdíl dvou osmiprvkových vektorů s přetečením |
| 10 | lv.sub.h | signed half word | rozdíl dvou čtyřprvkových vektorů s přetečením |
| 11 | lv.subs.b | signed byte | rozdíl dvou osmiprvkových vektorů se saturací |
| 12 | lv.subs.h | signed half word | rozdíl dvou čtyřprvkových vektorů se saturací |
| 13 | lv.subu.b | unsigned byte | rozdíl dvou osmiprvkových vektorů s přetečením |
| 14 | lv.subu.h | unsigned half word | rozdíl dvou čtyřprvkových vektorů s přetečením |
| 15 | lv.subus.b | unsigned byte | rozdíl dvou osmiprvkových vektorů se saturací |
| 16 | lv.subus.h | unsigned half word | rozdíl dvou čtyřprvkových vektorů se saturací |
| 17 | lv.avg.b | unsigned byte | průměr korespondujících prvků |
| 18 | lv.avg.h | unsigned half word | průměr korespondujících prvků |
| 19 | lv.madds.h | signed half word | operace multiply-accumulate |
| 20 | lv.subss.h | signed half word | operace multiply-accumulate |
| 21 | lv.muls.h | signed half word | násobení se saturací |
| 22 | lv.max.b | byte | zjištění, který korespondující prvek vektorů je větší |
| 23 | lv.max.h | half word | zjištění, který korespondující prvek vektorů je větší |
| 24 | lv.min.b | byte | zjištění, který korespondující prvek vektorů je menší |
| 25 | lv.min.h | half word | zjištění, který korespondující prvek vektorů je menší |
Další instrukce provádí bitové operace popř. bitové posuny:
| # | Instrukce | Datový typ | Význam |
|---|---|---|---|
| 1 | lv.and | long word | bitová operace logického součinu |
| 2 | lv.or | long word | bitová operace logického součtu |
| 3 | lv.nand | bitová operace negace logického součinu | |
| 4 | lv.nor | bitová operace negace logického součtu | |
| 5 | lv.xor | long word | bitová operace logické nonekvivalence |
| 6 | lv.rl.b | byte | bitové rotace doleva |
| 7 | lv.rl.h | half word | bitové rotace doleva |
| 8 | lv.sll.b | byte | bitové posuny doleva |
| 9 | lv.sll.h | half word | bitové posuny doleva |
| 10 | lv.sra.b | byte | aritmetické posuny doprava |
| 11 | lv.sra.h | half word | aritmetické posuny doprava |
| 12 | lv.srl.b | byte | bitové posuny doprava |
| 13 | lv.sll.h | half word | bitové posuny doprava |
18. Porovnání dvou vektorů
Následují instrukce, které porovnávají příslušné prvky dvou osmiprvkových vektorů typu byte či vektorů čtyřprvkových typu half word. Pokud jsou všechny podmínky (4 nebo 8) splněny, je nastaven příznak F a současně se nastaví třetí (cílový) registr na samé jedničky. Pokud naopak podmínka není splněna pro všechny porovnávané dvojice, je příznak F vynulován a cílový registr je vynulován taktéž:
| # | Instrukce | Datový typ | Význam |
|---|---|---|---|
| 1 | lv.all_eq.b | byte | porovnání dvou osmiprvkových vektorů na rovnost |
| 2 | lv.all_eq.h | half word | porovnání dvou čtyřprvkových vektorů na rovnost |
| 3 | lv.all_ne.b | byte | porovnání dvou osmiprvkových vektorů na nerovnost |
| 4 | lv.all_ne.h | half word | porovnání dvou čtyřprvkových vektorů na nerovnost |
| 5 | lv.all_ge.b | byte | zjištění relace „větší nebo rovno“ |
| 6 | lv.all_ge.h | half word | zjištění relace „větší nebo rovno“ |
| 7 | lv.all_gt.b | byte | zjištění relace „větší než“ |
| 8 | lv.all_gt.h | half word | zjištění relace „větší než“ |
| 9 | lv.all_le.b | byte | zjištění relace „menší nebo rovno“ |
| 10 | lv.all_le.h | half word | zjištění relace „menší nebo rovno“ |
| 11 | lv.all_lt.b | byte | zjištění relace „menší než“ |
| 12 | lv.all_lt.h | half word | zjištění relace „menší než“ |
Další instrukce jsou taktéž určeny pro porovnání, ovšem zjišťují, zda podmínka není splněna alespoň pro jednu porovnávanou dvojici prvků (provádí tedy or mezi prvky):

| # | Instrukce | Datový typ | Význam |
|---|---|---|---|
| 1 | lv.any_eq.b | byte | porovnání dvou osmiprvkových vektorů na rovnost |
| 2 | lv.any_eq.h | half word | porovnání dvou čtyřprvkových vektorů na rovnost |
| 3 | lv.any_ne.b | byte | porovnání dvou osmiprvkových vektorů na nerovnost |
| 4 | lv.any_ne.h | half word | porovnání dvou čtyřprvkových vektorů na nerovnost |
| 5 | lv.any_ge.b | byte | zjištění relace „větší nebo rovno“ |
| 6 | lv.any_ge.h | half word | zjištění relace „větší nebo rovno“ |
| 7 | lv.any_gt.b | byte | zjištění relace „větší než“ |
| 8 | lv.any_gt.h | half word | zjištění relace „větší než“ |
| 9 | lv.any_le.b | byte | zjištění relace „menší nebo rovno“ |
| 10 | lv.any_le.h | half word | zjištění relace „menší nebo rovno“ |
| 11 | lv.any_lt.b | byte | zjištění relace „menší než“ |
| 12 | lv.any_lt.h | half word | zjištění relace „menší než“ |
Třetí sada instrukcí opět slouží pro porovnání dvou vektorů, ovšem u těchto instrukcí je výsledek porovnání uložen do registru cílového (vždy do všech osmi či čtyř bitů). Skupina jedniček znamená splněnou podmínku, skupina nul podmínku nesplněnou:
| # | Instrukce | Datový typ | Význam |
|---|---|---|---|
| 1 | lv.cmp_eq.b | byte | porovnání dvou osmiprvkových vektorů na rovnost |
| 2 | lv.cmp_eq.h | half word | porovnání dvou čtyřprvkových vektorů na rovnost |
| 3 | lv.cmp_ne.b | byte | porovnání dvou osmiprvkových vektorů na nerovnost |
| 4 | lv.cmp_ne.h | half word | porovnání dvou čtyřprvkových vektorů na nerovnost |
| 5 | lv.cmp_ge.b | byte | zjištění relace „větší nebo rovno“ |
| 6 | lv.cmp_ge.h | half word | zjištění relace „větší nebo rovno“ |
| 7 | lv.cmp_gt.b | byte | zjištění relace „větší než“ |
| 8 | lv.cmp_gt.h | half word | zjištění relace „větší než“ |
| 9 | lv.cmp_le.b | byte | zjištění relace „menší nebo rovno“ |
| 10 | lv.cmp_le.h | half word | zjištění relace „menší nebo rovno“ |
| 11 | lv.cmp_lt.b | byte | zjištění relace „menší než“ |
| 12 | lv.cmp_lt.h | half word | zjištění relace „menší než“ |
19. Spojení a rozdělení prvků vektorů
Zbylé instrukce jsou určeny pro spojení popř. pro rozdělení prvků vektorů. Tyto operace jsou velmi užitečné, protože nám například umožňují rozložit rastrový obrázek ve formátu RGB na jednotlivé barvové složky apod.:
| # | Instrukce | Význam |
|---|---|---|
| 1 | lv.merge.b | spojení dvou vektorů (promíchání systémem sudá-lichá), pracuje s polovinou prvků |
| 2 | lv.merge.h | spojení dvou vektorů (promíchání systémem sudá-lichá), pracuje s polovinou prvků |
| 3 | lv.pack.b | spojení spodních polovin dvou vektorů (4 prvky vektoru prvního + 4 prvky vektoru druhého) |
| 4 | lv.pack.h | spojení spodních polovin dvou vektorů (2 prvky vektoru prvního + 2 prvky vektoru druhého) |
| 5 | lv.packs.b | spodní polovina bitů (4 bity) dvou vektorů se převedou na výsledný vektor |
| 6 | lv.packs.h | spodní polovina bitů (8 bitů) dvou vektorů se převedou na výsledný vektor |
| 7 | lv.packus.b | spodní polovina bitů (4 bity) dvou vektorů se převedou na výsledný vektor |
| 8 | lv.packus.h | spodní polovina bitů (8 bitů) dvou vektorů se převedou na výsledný vektor |
| 9 | lv.unpack.b | opak operace packs |
| 10 | lv.unpack.h | opak operace packs |
20. Odkazy na Internetu
- OpenRISC (oficiální stránky)
http://openrisc.io/ - OpenRISC architecture
http://openrisc.io/architecture.html - Emulátor OpenRISC CPU v JavaScriptu
http://s-macke.github.io/jor1k/demos/main.html - Why Not Build on OpenRISC?
https://riscv.org/2014/10/why-not-build-on-openrisc/ - OpenRISC (Wikipedia)
https://en.wikipedia.org/wiki/OpenRISC - OpenRISC – instrukce
http://sourceware.org/cgen/gen-doc/openrisc-insn.html - OpenRISC – slajdy z přednášky
https://iis.ee.ethz.ch/~gmichi/asocd/lecturenotes/Lecture6.pdf - OpenRISC System-on-Chip Design Emulation
https://arxiv.org/pdf/1602.03095.pdf - Cortex-M4 Devices Generic User Guide: Multiply and divide instructions
http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dui0553a/BABFADHJ.html - Open cores
https://opencores.org/ - Projekt OpenRISC 2000
https://opencores.org/project/or2k - OpenRISC na GitHubu
https://github.com/openrisc - OpenRISC 1200
https://en.wikipedia.org/wiki/OpenRISC_1200 - OpenRISC 1200 IP Core Specification (Preliminary Draft)
https://opencores.org/ocsvn/openrisc/openrisc/trunk/or1200/doc/openrisc1200_spec.pdf - mor1kx – an OpenRISC processor IP core
https://www.librecores.org/openrisc/mor1kx - Multiply Without a Multiply Instruction
http://www.robelle.com/smugbook/multiply.html - MULT in a RISC – should instructions take the same amount of time in a RISC system
https://cs.stackexchange.com/questions/77010/mult-in-a-risc-should-instructions-take-the-same-amount-of-time-in-a-risc-syst - Would removing the branch delay slots change the instructions set architecture?
https://cs.stackexchange.com/questions/59565/would-removing-the-branch-delay-slots-change-the-instructions-set-architecture?rq=1 - CRU: RISC-V, OpenRISC, LoRaWAN, and More
https://abopen.com/news/cru-risc-v-openrisc-lorawan/ - Comparing four 32-bit soft processor cores
http://www.eetimes.com/author.asp?section_id=14&doc_id=1286116 - RISC-V Instruction Set
http://riscv.org/download.html#spec_compressed_isa - RISC-V Spike (ISA Simulator)
http://riscv.org/download.html#isa-sim - RISC-V (Wikipedia)
https://en.wikipedia.org/wiki/RISC-V - David Patterson (Wikipedia)
https://en.wikipedia.org/wiki/David_Patterson_(computer_scientist) - Maska mikroprocesoru RISC 1
http://www.cs.berkeley.edu/~pattrsn/Arch/RISC1.jpg - Maska mikroprocesoru RISC 2
http://www.cs.berkeley.edu/~pattrsn/Arch/RISC2.jpg - C.E. Sequin and D.A.Patterson: Design and Implementation of RISC I
http://www.eecs.berkeley.edu/Pubs/TechRpts/1982/CSD-82–106.pdf - Berkeley RISC
http://en.wikipedia.org/wiki/Berkeley_RISC - Great moments in microprocessor history
http://www.ibm.com/developerworks/library/pa-microhist.html - Microprogram-Based Processors
http://research.microsoft.com/en-us/um/people/gbell/Computer_Structures_Principles_and_Examples/csp0167.htm - Great Microprocessors of the Past and Present
http://www.cpushack.com/CPU/cpu1.html - A Brief History of Microprogramming
http://www.cs.clemson.edu/~mark/uprog.html - What is RISC?
http://www-cs-faculty.stanford.edu/~eroberts/courses/soco/projects/2000–01/risc/whatis/ - RISC vs. CISC
http://www-cs-faculty.stanford.edu/~eroberts/courses/soco/projects/2000–01/risc/risccisc/ - RISC and CISC definitions:
http://www.cpushack.com/CPU/cpuAppendA.html - FPGA
https://cs.wikipedia.org/wiki/Programovateln%C3%A9_hradlov%C3%A9_pole - The Evolution of RISC
http://www.ibm.com/developerworks/library/pa-microhist.html#sidebar1 - SPARC Processor Family Photo
http://thenetworkisthecomputer.com/site/?p=243 - SPARC: Decades of Continuous Technical Innovation
http://blogs.oracle.com/ontherecord/entry/sparc_decades_of_continuous_technical - The SPARC processors
http://www.top500.org/2007_overview_recent_supercomputers/sparc_processors - Reduced instruction set computing (Wikipedia)
http://en.wikipedia.org/wiki/Reduced_instruction_set_computer - MIPS architecture (Wikipedia)
http://en.wikipedia.org/wiki/MIPS_architecture - Very long instruction word (Wikipedia)
http://en.wikipedia.org/wiki/Very_long_instruction_word - Classic RISC pipeline (Wikipedia)
http://en.wikipedia.org/wiki/Classic_RISC_pipeline - R2000 Microprocessor (Wikipedia)
http://en.wikipedia.org/wiki/R2000_(microprocessor) - R3000 Microprocessor (Wikipedia)
http://en.wikipedia.org/wiki/R3000 - R4400 Microprocessor (Wikipedia)
http://en.wikipedia.org/wiki/R4400 - R8000 Microprocessor (Wikipedia)
http://en.wikipedia.org/wiki/R8000 - R10000 Microprocessor (Wikipedia)
http://en.wikipedia.org/wiki/R10000 - SPARC (Wikipedia)
http://en.wikipedia.org/wiki/Sparc - CPU design (Wikipedia)
http://en.wikipedia.org/wiki/CPU_design - Control unit (Wikipedia)
http://en.wikipedia.org/wiki/Control_unit - CPUID na x86–64
http://www.felixcloutier.com/x86/CPUID.html - Endianness
https://en.wikipedia.org/wiki/Endianness - Otevřené RISCové architektury OpenRISC a RISC-V
https://www.root.cz/clanky/otevrene-riscove-architektury-openrisc-a-risc-v/ - Instrukční sada procesorových jader s otevřenou architekturou RISC-V
https://www.root.cz/clanky/instrukcni-sada-procesorovych-jader-s-otevrenou-architekturou-risc-v/ - Rozšíření instrukční sady procesorových jader s otevřenou architekturou RISC-V
https://www.root.cz/clanky/rozsireni-instrukcni-sady-procesorovych-jader-s-otevrenou-architekturou-risc-v/ - Instrukční sady procesorových jader s otevřenou architekturou RISC-V (dokončení)
https://www.root.cz/clanky/instrukcni-sady-procesorovych-jader-s-otevrenou-architekturou-risc-v-dokonceni/ - RISCové mikroprocesory s komprimovanými instrukčními sadami
https://www.root.cz/clanky/riscove-mikroprocesory-s-komprimovanymi-instrukcnimi-sadami/ - RISCové mikroprocesory s komprimovanými instrukčními sadami (2)
https://www.root.cz/clanky/riscove-mikroprocesory-s-komprimovanymi-instrukcnimi-sadami-2/



{kind=link}
{kind=link}