
Obsah
5. Ukázky vstupního textu pro nástroj noweb
6. Moderní přístupy k literate programmingu
7. Literate programming v podání Jupyter Notebooku
8. Ukázka diáře s popisem všech kroků
10. Nástroje odvozené od utility Docco
12. Příklad použití nástroje Docgo
14. Kde zobrazit výstup programu?
16. Příklad použití nástroje Pycco
18. Repositář s demonstračními příklady
19. Vygenerované soubory s vysvětlením zdrojového kódu i vlastním kódem
1. Literate programming
„„Změňme náš tradiční pohled na tvorbu programů. Místo toho abychom předepsali počítači co má dělat, zkusme vysvětlovat lidským bytostem co chceme, aby počítač dělal. ‚Literární‘ programátor může být srovnáván s esejistou, jehož hlavním cílem je srozumitelné vysvětlení a vybroušený styl. Takový autor vybírá s tezaurem v ruce názvy proměnných a vysvětluje účel každé z nich. Snaží se napsat program, který je srozumitelný, protože jeho principy jsou popsány způsobem, který odpovídá lidskému myšlení a používá k tomu formální i neformální prostředky, které se navzájem doplňují.““
Donald Knuth
V dnešním článku si alespoň ve stručnosti přiblížíme programovací paradigma, pro které slavný Donald E. Knuth vymyslel název „literate programming“ a které použil například při vývoji TeXu. Jedná se o takový styl, ve kterém je průběžně v běžném (lidském) jazyce vysvětlováno, co se má provést a jaký je očekáván výsledek. Mezi tímto slovním popisem se pak nachází jednotlivé kroky programu. Ovšem pozor – nejedná se zde o běžné dokumentační řetězce, v nichž se typicky popisuje, k čemu je určen daný blok programu (typicky třída, metoda či funkce), ale mnohdy spíše o volněji pojatý styl psaní (což částečně uvidíme na příkladech).
Poměrně dobrým příkladem použití tohoto paradigma jsou texty, v nichž se nějaký algoritmus vysvětluje způsobem „shora dolů“ nebo naopak „zdola nahoru“. Oba dva přístupy mají své přednosti a pochopitelně i omezení. Způsob „shora dolů“ se nejdříve zaměřuje na celý řešený problém na nejvyšší (rozumné) úrovni abstrakce, takže může dát čtenáři dobrý vhled do toho, jaký problém se řeší a jakým způsobem. Detaily jsou vysvětleny (a současně i implementovány!) později. Naproti tomu způsob vysvětlování a programování označovaný termínem „zdola nahoru“ je typický při použití jazyků typu Forth, v nichž se nejdříve skládají jednotlivé základní (a značně primitivní) bloky do bloků větších, které provádí činnost na poněkud vyšší úrovni abstrakce. A z těchto bloků se opět skládají další větší celky až k celkové aplikaci. Pochopitelně je možné – a často se to děje – oba styly kombinovat.
2. Systém Web
„Literate programming is not a documentation system per ce, it's a programming paradigm.“
V článku o literate programmingu je prakticky nemožné se nezmínit o systému nazvaném Web (který ovšem nemá nic společného s WWW). Tento systém, který byl vyvinut právě Donaldem Knuthem, byl naprogramován v Pascalu. Samotný Web je z hlediska uživatele složen ze dvou programů – filtrů. První filtr se jmenuje TANGLE (původně skutečně psáno velkými písmeny) a slouží pro vygenerování zdrojového kódu v Pascalu ze vstupního dokumentu. Druhý filtr se jmenuje WEAVE a jeho účelem je vygenerování dokumentace ve formátu připraveném pro tisk („camera ready“); pro vlastní sazbu se přitom používá systém TeX.
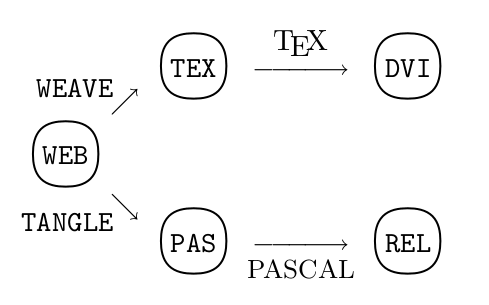
Obrázek 1: Nástroje TANGLE a WEAVE (zdroj: přímo Knuthův dokument o literate programmingu).
Původní systém Web byl následně přepsán do podoby nástroje CWEB, jenž je použitelný pro použití paradigmatu literate programming v programovacím jazyku C, C++ a částečně i Javy. Tento nástroj se skládá z filtrů CTANGLE a CWEAVE. Příklad výstupu je k dispozici na adrese https://tex.loria.fr/litte/wc.pdf.

Obrázek 2: Příklad výstupu generovaného nástrojem Web.
3. Inspirace Algolem 60?
Některé vlastnosti, které nalezneme v oblasti literate programmingu, jsou s velkou pravděpodobností inspirovány Algolem, přesněji řečeno Algolem 60. ALGOL je totiž poněkud zvláštní a mnohdy i matoucí tím, že jeho syntax existuje ve třech rozdílných variantách, které se nazývají reference syntax, publication syntax a implementation syntax. Referenční syntax je použita především v oficiálním „Reportu“ (de facto standardy), publikační syntax je použita v článcích, při ukázce algoritmů na tabuli (slajdech) atd. A implementační syntax se liší podle použitého počítače a jeho schopností (znaková sada atd.). Kvůli této trojí syntaxi se zápis algoritmů v článcích a knihách mnohdy dosti podstatným způsobem odlišuje od zápisu pro konkrétní počítač. Navíc to umožňuje měnit (v článcích i konkrétní implementaci) klíčová slova a nahrazovat je za národní varianty, používat desetinnou čárku namísto desetinné tečky atd.
4. Nástroj noweb
„The practitioner of literate programming can be regarded as an essayist, whose main concern is with exposition and excellence of style.“
Donald Knuth
Jedním z (relativně) novějších nástrojů inspirovaných původním webem je nástroj nazvaný noweb. Tento nástroj je navržen takovým způsobem, aby byl nezávislý na použitém jazyku – a to jak na programovacím jazyku (C, Python, Perl atd.), tak i do jisté míry na jazyku použitém pro vygenerování dokumentace. Noweb totiž podporuje výstup do formátů TeXu, LaTeXu, HTML a troffu. Ovšem právě kvůli tomu, že je tento nástroj do značné míry nezávislý na použitém programovacím jazyku, není jeho praktické použití příliš uživatelsky přívětivé (už jen z toho důvodu, že většina programátorských textových editorů od sebe nedokáže a tím pádem ani zvýraznit syntaxi jednotlivých částí). O tom, jak vypadá zdrojový text, se přesvědčíme v navazující kapitole.
Podobně jako v případě původního webu se i v nástroji noweb používá dvojí zpracování vstupního textu. O první zpracování se stará filtr pojmenovaný notangle, který vygeneruje zdrojový kód (nezávisle na použitém programovacím jazyku) a o zpracování druhé pak nástroj nazvaný noweave, jenž vygeneruje dokumentaci připravenou pro tisk (resp. přesněji řečeno připravenou například pro zpracování LaTeXem do tiskové podoby).
5. Ukázky vstupního textu pro nástroj noweb
Podívejme se nyní na to, jak vlastně vypadá vstupní text, který má být zpracován nástrojem noweb. Nejprve si uvedeme úplnou podobu textu, poté ho ve stručnosti okomentujeme:
\section{Hello world}
Today I awoke and decided to write
some code, so I started to write Hello World in \textsf C.
<<hello.c>>=
/*
<<license>>
*/
#include <stdio.h>
int main(int argc, char *argv[]) {
printf("Hello World!\n");
return 0;
}
@
\noindent \ldots then I did the same in PHP.
<<hello.php>>=
<?php
/*
<<license>>
*/
echo "Hello world!\n";
?>
@
\section{License}
Later the same day some lawyer reminded me about licenses.
So, here it is:
<<license>>=
This work is placed in the public domain.
V předchozím zdrojovém textu byly použity tři jazyky – LaTeX, C a PHP, přičemž LaTeX byl (pochopitelně) použit pro dokumentační část. Jednotlivé bloky psané v programovacích jazycích začínají jednoznačným označením (chunk), což je identifikátor, který je zapsán ve dvojitých lomených závorkách. Příkladem je:
<<hello.c>>=
Naproti tomu bloky s dokumentací jméno nemají (neodkazuje se na ně). Začínají řádkem obsahujícím pouze znak @, za nímž následuje vlastní dokumentace, v našem případě založená na TeXu a v případě druhého bloku LaTeXu (jako nadmnožině TeXu z pohledu uživatele):
@ \noindent \ldots then I did the same in PHP.
Typickou ukázkou toho, jak vypadá vstupní text pro nástroj noweb, je zdrojový kód unixové utility wc, který byl upravený do výstupu, jehož HTML varianta je dostupná na adrese https://www.cs.tufts.edu/~nr/noweb/examples/wc.html. Na tomto výstupu je patrné stáří nowebu, který nedokáže dobře využít všech možností nabízených moderním HTML a kaskádovými styly. Část upraveného zdrojového kódu utility wc vypadá následovně:
The present chunk, which does the counting, was actually one of
the simplest to write. We look at each character and change state if it begins or ends
a word.
<<Scan file>>=
while (1) {
<<Fill buffer if it is empty; break at end of file>>
c = *ptr++;
if (c > ' ' && c < 0177) {
/* visible ASCII codes */
if (!in_word) {
word_count++;
in_word = 1;
}
continue;
}
if (c == '\n') line_count++;
else if (c != ' ' && c != '\t') continue;
in_word = 0;
/* c is newline, space, or tab */
}
@
Na závěr se podívejme na ještě složitější kód, který tentokrát kombinuje dokumentaci se zdrojovým kódem napsaným v Perlu. Začátky jednotlivých chunků jsou pro větší přehlednost zvýrazněny:
\documentclass[10pt]{article}
\usepackage{noweb}
\noweboptions{smallcode,longchunks}
\begin{document}
\pagestyle{noweb}
@
\paragraph{Introduction}
This is [[autodefs.perl]]\footnote{Copyright 1997, Andrew L.
Johnson and Brad C. Johnson, All rights reserved.},
a Perl script to be used as an [[autodefs]] filter
in the [[noweb]] pipeline to identify and index
some common Perl definitions. Since this
file is also meant to show off some of the
features of [[noweb]] it is purposely verbose
and contorted.
Perl does not require the formal declaration or typing of
variables which makes it difficult to
differentiate between declarations and usages of
variables. We may however find definitions of [[sub]]’s and
[[package]]’s with little difficulty and that is the purpose of
this module. Before we begin we need to know
some facts about [[noweb]]’s pipeline structure.\footnote{Noweb’s
pipeline structure is described in the \textit{Noweb Hackers
Guide} which is included in the [[noweb]] distribution.}
Actual code in the pipeline lie between lines
of the form [[@begin code]] and [[@end code]].
In Perl these are easily recognized by the following regular
expressions.
<<Global variables>>=
$begin_code_pat = "^\@begin code";
$end_code_pat = "^\@end code";
@ %def $begin_code_pat $end_code_pat
@ \paragraph{autodefs.perl}
Our actual Perl script has the following simple shape:
<<autodefs.perl>>=
#!/usr/bin/perl
<<Global variables>>
<<[[process_code_chunk]] subroutine>>
while ( <> ) {
print $_;
if (/$begin_code_pat/o) {
process_code_chunk;
}
}
@
6. Moderní přístupy k literate programmingu
Dnes můžeme vidět poněkud odlišný způsob zpracování a zobrazení aplikací vyvinutých na bázi literate programmingu. Musíme si totiž uvědomit, že celé paradigma literate programmingu vzniklo v době, kdy největším problémem programátorů bylo vůbec realizovat nějaký algoritmus (vznikaly například nové řadicí algoritmy, alfa-beta ořezávání atd.). Mnoho aplikací – a to včetně zde zmiňovaného TeXu – byla vytvořena buď jako filtr nebo tak, aby se daly spouštět jako dávková úloha na jednom počítači s již připravenými daty (zde pro jednoduchost vynechávám řídicí úlohy a procesy). V současnosti je situace značně odlišná, protože se většinou namísto řešení konkrétního algoritmu vývojáři spíše zaměřují na realizaci celého „workflow“, a to včetně asynchronně vykonávaných operací; spojováním mnoha služeb a modulů do funkčního celku apod. Některé úlohy, typicky z oblasti umělé inteligence, strojového učení, zpracování dat apod. se navíc vyvíjí interaktivně, například s využitím Jupyter Notebooku, s jehož některými možnostmi jsme se již na stránkách Rootu seznámili (viz odkazy na konci článku).
Navíc se změnil i význam médií používaných programátory. Cílem již není (a pro mnohé vývojáře mimo výzkumné ústavy a vysoké školy ani nebylo) vytištěný dokument, ale spíše jeho elektronická forma, ideálně automaticky generovaná a automaticky aktualizovaná v synchronizaci se zdrojovým kódem. Novým médiem se tak stává displej, dnes širokoúhlý – což nabízí zcela odlišné možnosti v porovnání s běžnou tištěnou dokumentací, kde typicky existuje omezení na formát A4 nebo US Letter (navíc pouze v černobílé variantě).
Z výše zmíněných důvodů se dnes setkáme s poněkud odlišnými přístupy:
- Používá se systém diářů, v němž jsou komentáře odděleny od kódu, protože vstupní text je rozdělen do buněk (cells). Předností tohoto přístupu je fakt, že lze využít mnoho značkovacích jazyků, dokonce je možné v rámci jednoho diáře tyto jazyky střídat.
- Alternativně se používá přístup, v němž je dokument popisující algoritmus či sekvenci kroků vložen do zdrojového kódu jako běžný komentář daného programovacího jazyka. Nástroj, který takové soubory zpracovává, tedy musí znát syntaxi daného programovacího jazyka. Nevýhodou je, že komentáře, přesněji řečeno jejich obsah, většinou nebývá dále nijak zvýrazňován v programátorských editorech.
7. Literate programming v podání Jupyter Notebooku
Jupyter Notebook a podobné nástroje jsou pro použití paradigmatu literate programování velmi dobře připraveny, protože jsou založeny na použití diáře. Díky tomu, že v Jupyter Notebooku lze kombinovat buňky s textem s buňkami obsahujícími kód a jeho výsledky, je možné i v běžných diářích tento styl používat, což se ostatně poměrně často používá při přípravě materiálů pro výuku (takových diářů existuje celá řada a jsou z různých oborů – od IT přes zpracování signálů až po chemii). Výhodné je, že je (mj.) plně podporován jazyk Markdown, takže dokumentace není jen čistým textem, ale lze používat i základní formátovací příkazy, a to včetně tvorby tabulek.
Obrázek 3: Grafické uživatelské rozhraní projektu JupyterLab se zobrazeným vzorovým příkladem. JupyterLab je nástupcem Jupyter Notebooku.
8. Ukázka diáře s popisem všech kroků
Diář, který kromě vlastních kroků pro s analýzami a výpočty obsahuje i okomentovaný postup, lze nalézt na adrese https://github.com/tisnik/jupyter-notebook-examples/blob/master/consumer_benchmarks.ipynb. Na základě tohoto diáře byl vytvořen jeden z demonstračních příkladů zmíněných v další kapitole.
Obrázek 4: Část diáře zmíněného v předchozím odstavci.
9. Nástroje typu Docco
Poněkud jiným směrem se vydaly nástroje typu Docco (viz též http://ashkenas.com/docco/). Tyto nástroje jsou založeny na tom, že dokumentace s popisem algoritmů, postupů, tříd atd. je uložena v běžných komentářích platných v rámci použitého programovacího jazyka; typicky je navíc možné použít některý značkovací jazyk, například Markdown. Díky tomu je možné s takto připravenými zdrojovými kódy pracovat přímo v integrovaných vývojových prostředích i programátorských editorech. Navíc je změněn i výstup produkovaný Doccem, který je přizpůsoben moderním širokoúhlým displejům (a nikoli klasickým tiskovým stranám). V praxi to znamená, že tyto nástroje dokáží výsledek zpracovat a zobrazit takovým způsobem, že v jednom sloupci je zobrazena dokumentace a ve sloupci druhém pak vlastní zdrojový kód, většinou s plným zvýrazněním syntaxe.
Obrázek 5: Příklad výstupu generovaném systémem Docco.
Celou ukázku naleznete na http://facebook.github.io/rebound-js/docs/rebound.html
10. Nástroje odvozené od utility Docco
Utilita Docco podporuje velké množství programovacích jazyků; jejich aktuální seznam naleznete přímo ve zdrojovém kódu https://github.com/jashkenas/docco/blob/master/resources/languages.json. Ovšem kromě Docco vznikly i další podobně koncipované nástroje, které jsou mnohdy specializovány na určitý programovací jazyk nebo skupinu jazyků. Mezi tyto nástroje patří například:
| # | Nástroj | Jazyk |
|---|---|---|
| 1 | Rocco | vytvořeno v Ruby, dostupné jako Ruby gem |
| 2 | Shocco | pro POSIX shell |
| 3 | Pycco | pro Python, bude zmíněn v dalších kapitolách |
| 4 | Gocco | pro Go |
| 5 | Locco | pro jazyk Lua |
| 6 | Docgo | pro Go, bude zmíněn v dalších kapitolách |
11. Nástroj Docgo
Prvním moderním nástrojem typu Docco, který si dnes popíšeme, je nástroj nazvaný Docgo, jenž je určený pro použití stylu literate programming společně s programovacím jazykem Go. Tento nástroj je jednoduše použitelný a pro daný zdrojový soubor (s poznámkami) generuje jedinou HTML stránku obsahující jak dokumentaci, tak i zdrojový kód i všechny styly.
Instalace tohoto nástroje je triviální, ovšem pochopitelně se počítá s tím, že již máte korektně nainstalovány základní vývojové nástroje programovacího jazyka Go:
$ go get github.com/dhconnelly/docgo
Po dokončení předchozího příkazu by se v podadresáři ~/go (přesněji řečeno v adresáři, na který ukazuje proměnná prostředí GOPATH) měl objevit nový spustitelný soubor nazvaný docgo. Ten lze spustit a předat mu jméno zdrojového souboru či souborů vytvořených v programovacím jazyce Go.
Příklad použití:
$ docgo gonum.go
12. Příklad použití nástroje Docgo
Jako příklad použití nástroje Docgo v praxi jsem přepsal jeden článek vydaný na tomto serveru do podoby okomentovaného zdrojového kódu. Konkrétně se jednalo o článek pojednávající o knihovně gonum určené pro programovací jazyk Go. Samotný text článku je umístěn do závorek uvozených znaky //, které mohou obsahovat značky jazyka Markdown. Naproti tomu komentáře v závorkách /* */ nejsou převedeny do dokumentu, ale zůstávají součástí zdrojového kódu.
Úplný kód takto pojatého článku naleznete na adrese https://github.com/tisnik/literate-programming-examples/blob/master/gonum.go.
// excerpt big identity matrix: Dims(100, 100) // ⎡1 0 0 ... ... 0 0 0⎤ // ⎢0 1 0 0 0 0⎥ // ⎢0 0 1 0 0 0⎥ // . // . // . // ⎢0 0 0 1 0 0⎥ // ⎢0 0 0 0 1 0⎥ // ⎣0 0 0 ... ... 0 0 1⎦
Výsledný článek i s ukázkami kódu můžete vidět zde.
13. Změna šířky sloupců
Styl zobrazení výsledného dokumentu je uveden přímo ve vygenerovaném HTML souboru, což ovšem přináší určité problémy. Pokud například budete chtít, aby se ve výsledném dokumentu použila větší plocha pro zobrazení textu, je nutné vygenerovaný HTML ručně upravit, a to konkrétně na dvou místech:
@@ -22,7 +22,7 @@
#docgo #background {
position: fixed;
- top: 0; left: 525px; right: 0; bottom: 0;
+ top: 0; left: 725px; right: 0; bottom: 0;
background: rgb(47, 47, 47);
border-left: 1px solid #e5e5ee;
z-index: -1;
@@ -65,8 +65,8 @@
font-size: 15px;
line-height: 22px;
color: black;
- min-width: 450px;
- max-width: 450px;
+ min-width: 650px;
+ max-width: 650px;
padding-top: 10px;
padding-right: 25px;
padding-bottom: 1px;
Upravenou podobu článku i s ukázkami kódu můžete vidět zde.
14. Kde zobrazit výstup programu?
Nástroj docgo v současnosti neřeší zobrazení ukázkového výstupu z jednotlivých příkazů. Ty je možné umístit buď do dokumentové části (levý sloupec) nebo do části se zdrojovým kódem (sloupec pravý). V předchozích dvou kapitolách jsme viděli první možnost (stačí zascrollovat například na výpis rozsáhlejších matic), ovšem relativně snadnou úpravou (jediným makrem ve Vimu) lze docílit i toho, že výstup bude zobrazen v části společné se zdrojovým kódem. Upravený zdrojový kód naleznete na adrese https://github.com/tisnik/literate-programming-examples/blob/master/gonum_output_as_comments.go.
Výsledky:
15. Nástroj Pycco
Druhým nástrojem, o kterém se dnes konkrétně zmíníme, je nástroj nazvaný Pycco. Jak již název tohoto nástroje napovídá, jedná se o alternativu k nástroji Docco určený pro použití společně s programovacím jazykem Python, který pro psaní dokumentové části podporuje značkovací jazyk Markdown. Pycco se instaluje běžným způsobem, například pomocí pip:
$ pip3 install --user pycco
Tento nástroj dokáže vygenerovat dokumentaci k libovolnému množství skriptů; výsledek se ve výchozím nastavení uloží do podadresáře docs, a to jak HTML stránka, tak i soubor s kaskádovými styly.
16. Příklad použití nástroje Pycco
Jako příklad použití nástroje Pycco byl vybrán a náležitě upraven diář, s nímž jsme se seznámili v rámci osmé kapitoly. Diář byl převeden do kódu v Pythonu, upraven do čitelné podoby a byly do něj přidány komentáře. Výsledný zdrojový kód je dostupný na adrese https://github.com/tisnik/literate-programming-examples/blob/master/consumer_benchmarks.py a vygenerovaná dokumentace společně se zdrojovými kódy na adrese https://tisnik.github.io/literate-programming-examples/consumer_benchmarks.html.
17. Možnosti dalšího vývoje
Ukázané nástroje (pycco a docgo) by bylo vhodné dále rozšířit, například o možnost zobrazení třetího sloupce s výsledky, a to jak textovými (standardní a chybový výstup), tak i grafickými (diagramy, grafy, tabulky). Prozatím sice takové nástroje k dispozici nejsou, ovšem jejich vývoj by mohl být relativně snadný. Ostatně i Jupyter Notebook nyní prochází úpravami, které umožňují zobrazení dvou či více sloupců, což je vlastně velmi podobný mechanismus.

18. Repositář s demonstračními příklady
Všechny demonstrační příklady s nimiž jsme se seznámili v předchozích kapitolách, byly uloženy do Git repositáře umístěného na GitHubu (https://github.com/tisnik/literate-programming-examples). Poslední verze souborů s diáři naleznete pod odkazy uvedenými v tabulce pod tímto odstavcem.
| # | Příklad | Stručný popis | Zdrojový kód |
|---|---|---|---|
| 1 | consumer_benchmarks.py | zkonvertovaný diář s benchmarky | https://github.com/tisnik/literate-programming-examples/blob/master/consumer_benchmarks.py |
| 2 | gonum.go | úvodní informace o knihovně Gonumúvodní informace o knihovně Gonum | https://github.com/tisnik/literate-programming-examples/blob/master/gonum.go |
| 3 | gonum_output_as_comments.go | úvodní informace o knihovně Gonum, výstup ve formě komentářů | https://github.com/tisnik/literate-programming-examples/blob/master/gonum_output_as_comments.go |
19. Vygenerované soubory s vysvětlením zdrojového kódu i vlastním kódem
S využitím nástrojů zmíněných v předchozích kapitolách (pycco, docgo) byly vygenerovány následující soubory (z nichž dva prošly nepatrnými ručními úpravami), které v jednom sloupci obsahují popis algoritmu a ve sloupci druhém vlastní zdrojový kód:
| # | Příklad | Stručný popis | Lze si prohlédnout na adrese |
|---|---|---|---|
| 1 | consumer_benchmarks.html | zkonvertovaný diář s benchmarky | https://tisnik.github.io/literate-programming-examples/consumer_benchmarks.html |
| 2 | gonum_std.html | úvodní informace o knihovně Gonum, nezměněná varianta | https://tisnik.github.io/literate-programming-examples/gonum_std.html |
| 3 | gonum_changed_width.html | úvodní informace o knihovně Gonum, změna šířky sloupců | https://tisnik.github.io/literate-programming-examples/gonum_changed_width.html |
| 4 | gonum_output_as_comments.html | úvodní informace o knihovně Gonum, výstup ve formě komentářů | https://tisnik.github.io/literate-programming-examples/gonum_output_as_comments.html |
| 5 | gonum_output_as_comments_changed_width.html | předchozí příklad s upravenou šířkou sloupců | https://tisnik.github.io/literate-programming-examples/gonum_output_as_comments_changed_width.html |
20. Odkazy na Internetu
- Literate Programming (Knuth)
http://www.literateprogramming.com/knuthweb.pdf - literateprogramming
http://www.literateprogramming.com/ - Literate programing: Kolokviální práce Pavla Starého
https://www.fi.muni.cz/usr/jkucera/pv109/starylp.htm - Ladislav Kašpárek: Literate Programming na střední škole
http://www.ceskaskola.cz/2006/05/ladislav-kasparek-literate-programming.html - anansi: A NoWeb-inspired literate programming preprocessor
https://john-millikin.com/software/anansi - Literate programming
https://en.wikipedia.org/wiki/Literate_programming - Noweb — A Simple, Extensible Tool for Literate Programming
https://www.cs.tufts.edu/~nr/noweb/ - Literate Programming using noweb
https://www.cs.tufts.edu/~nr/noweb/johnson-lj.pdf - An Example of noweb
https://www.cs.tufts.edu/~nr/noweb/examples/wc.html - PyWeb
https://github.com/slott56/py-web-tool - Noweb (Wikipedia)
https://en.wikipedia.org/wiki/Noweb - Notangle
https://archive.is/20151215221108/http://dev.man-online.org/man1/notangle/ - noweb.py
https://github.com/JonathanAquino/noweb.py - literate-programming-style documentation for golang, modeled on docco
https://github.com/dhconnelly/docgo - docgo documentation
https://dhconnelly.com/docgo/ - Docco
http://ashkenas.com/docco/ - Literate CoffeeScript
http://coffeescript.org/#literate - UWTB: Responsive, Two Column Documentation Layout With Markdown and CSS
https://blog.mattbierner.com/responsive-two-column-documentation-layout-with-markdown-and-css/ - Jupyter Notebook – nástroj pro programátory, výzkumníky i lektory
https://www.root.cz/clanky/jupyter-notebook-nastroj-pro-programatory-vyzkumniky-i-lektory/ - Tvorba grafů v Jupyter Notebooku s využitím knihovny Matplotlib
https://www.root.cz/clanky/tvorba-grafu-v-jupyter-notebooku-s-vyuzitim-knihovny-matplotlib/ - Tvorba grafů v Jupyter Notebooku s využitím knihovny Matplotlib (dokončení)
https://www.root.cz/clanky/tvorba-grafu-v-jupyter-notebooku-s-vyuzitim-knihovny-matplotlib-dokonceni/ - Jupyter Notebook – operace s rastrovými obrázky a UML diagramy, literate programming
https://www.root.cz/clanky/jupyter-notebook-operace-s-rastrovymi-obrazky-a-uml-diagramy-literate-programming/ - Šedesátiny převratného programovacího jazyka ALGOL-60
https://www.root.cz/clanky/sedesatiny-prevratneho-programovaciho-jazyka-algol-60/ - shocco
https://rtomayko.github.io/shocco/ - rocco.rb
https://rtomayko.github.io/rocco/rocco.html - gocco
https://nikhilm.github.io/gocco/ - locco
https://rgieseke.github.io/locco/ - web – The original literate programming system
https://www.ctan.org/pkg/web - The CWEB System of Structured Documentation
https://www-cs-faculty.stanford.edu/~knuth/cweb.html
