
Obsah
1. Malé ohlédnutí za historií Pythonu: Python 0.9.1 na moderním hardware
2. Předchůdce Pythonu – neúspěšný jazyk ABC
3. Od programovacího jazyka ABC k Pythonu
5. Otestování možností Pythonu 0.9.1
6. Příprava na překlad Pythonu 0.9.1
8. Překlad interpretru Pythonu 0.9.1
9. Plnohodnotný interpret Pythonu menší než 200kB?
10. Oprava chyby v implementaci operátoru pro součin dvou hodnot
11. Realizace algoritmu bublinkového řazení pro moderní Python
12. Přepis algoritmu pro Python 0.9.1
13. Vizuální porovnání obou variant: verze pro moderní Python vs. verze pro 34 let starý překladač
14. Porovnání rychlosti moderního interpretru s jeho 34 let starou variantou
15. Základní vlastnosti Pythonu 0.9.1
18. Definice funkcí a základní programové konstrukce
19. Repositář s demonstračními příklady
1. Malé ohlédnutí za historií Pythonu: Python 0.9.1 na moderním hardware
Před několika týdny byla oficiálně vydána nejnovější verze interpretru Pythonu, která nese číslo 3.14. Samotný Python ovšem není v oblasti programovacích jazyků žádným nováčkem, protože jeho první varianty vyšly již na začátku roku 1991, tedy před více než 34 lety! V tomto článku si vyzkoušíme přeložit interpret Pythonu 0.9.1, což je prakticky nejstarší dostupná verze Pythonu vůbec (první verze s číslem 0.9.0 se možná již z internetů ztratila). Zajímavé je, že Python 0.9.1 je stále (i když s malými změnami) přeložitelný a bude pracovat i na moderních 64bitových operačních systémech (což je vzhledem k posunu architektur CPU od 16bitových k 64bitovým registrům atd. poměrně unikátní).
2. Předchůdce Pythonu – neúspěšný jazyk ABC
„I remembered all my experience and some of my frustration with ABC. I decided to try to design a simple scripting language that possessed some of ABC's better properties, but without its problems. So I started typing. I created a simple virtual machine, a simple parser, and a simple runtime. I made my own version of the various ABC parts that I liked. I created a basic syntax, used indentation for statement grouping instead of curly braces or begin-end blocks, and developed a small number of powerful data types: a hash table (or dictionary, as we call it), a list, strings, and numbers.“
Pro většinu čtenářů tohoto článku nebude s velkou pravděpodobností příliš velkým překvapením konstatování, že autorem programovacího jazyka Python je Guido van Rossum. Před popisem vývoje samotného Pythonu se však musíme nejprve zmínit o jeho ideovém předchůdci, jimž je programovací jazyk ABC. Vývoj jazyka ABC začal již v polovině osmdesátých let minulého století v CWI. Pravě na vývoji tohoto jazyka pracoval mj. i Guido; tehdy na juniorské pozici a ve vývojovém týmu společně s Lambertem Meertensem, Leo Geurtsem a Stevenem Pembertonem. Cílem tohoto týmu bylo vytvořit programovací jazyk dobře použitelný i lidmi, kteří sice nejsou profesionálními programátory, ale aplikace potřebují vytvářet a nějakým způsobem udržovat. Jednou z cílových skupin byli pochopitelně vědci (a právě zaměřením mj. i na neprofesionály je známý moderní Python).
Jen pro připomenutí dobových reálií – v polovině osmdesátých let minulého století došlo k obrovskému rozvoji v oblasti osmibitových domácích mikropočítačů i šestnáctibitových osobních mikropočítačů. A především domácím mikropočítačům kraloval jiný programovací jazyk určený pro širokou veřejnost a nikoli pro profesionály – BASIC.

Obrázek 1: Práce s numerickými proměnnými a poli v BASICU. Povšimněte si, že na řádku 50 se do proměnné A vloží hodnota 0 a současně se vytvoří numerické proměnné B a C inicializované na nulu. Dále se na řádku 70 vytvoří desetiprvkové pole, na řádku 80 se nastaví hodnota prvního prvku tohoto pole na 42 a na řádku 100 se vypíše hodnota zdánlivě neinicializovaného prvku číslo 2 (který je ve skutečnosti automaticky nastaven na nulu).
Jenže na rozdíl od (většinou) nestrukturovaného BASICu, který navíc nabízel pouze základní datové typy (typicky pouze čísla, řetězce, jednorozměrná pole, matice) byl programovací jazyk ABC navržen odlišným, dnes bychom řekli, že mnohem modernějším způsobem (zdá se, že Meertens dokonce BASIC přímo nesnášel, jeho motto bylo „Stamp out Basic!“). Ostatně podívejme se na jednoduchý příklad programu zapsaného v syntaxi jazyka ABC, který získá všechna slova ze vstupního dokumentu. Můžeme zde vidět velkou podobnost s pozdějším Pythonem – odsazování je součástí syntaxe, používání dvojteček, programová smyčka typu for-each, použití operátoru not.in atd:
HOW TO RETURN words document:
PUT {} IN collection
FOR line IN document:
FOR word IN split line:
IF word not.in collection:
INSERT word IN collection
RETURN collection
3. Od programovacího jazyka ABC k Pythonu
Ovšem už při vývoji jazyka ABC se ukázalo, že svět informatiky nebyl na tento programovací jazyk připraven (někdo by řekl, že se jednalo o špatné načasování vstupu na trh). Na mikropočítačích s relativně malými systémovými zdroji nebylo možné potenciálu ABC využít (navíc mu konkuroval BASIC, o kterém vycházely desítky, možná i stovky knížek a který byl díky uložení v ROM logicky prvním jazykem většiny začátečníků – včetně autora tohoto článku) a na druhé straně výkonnostního spektra, tedy na počítačích s UNIXem, se již používaly odlišné skriptovací jazyky, například Tcl (1988) a Perl (1987); na strojích IBM se naproti tomu používal jazyk Rexx (1979), ze kterého se na Amize vyvinul jazyk ARexx.
Nicméně i přes relativní neúspěch jazyka ABC nebyly základní myšlenky ztraceny, protože je později Guido van Rossum použil právě při implementaci první verze Pythonu, který z jazyka ABC v mnoha ohledech vycházel.
Prvotní verze Pythonu (před oficiální verzí 1.0) jsou vypsány v následující tabulce:
| Verze | Datum vydání |
|---|---|
| 0.9.0 | 20. února 1991 |
| 0.9.1 | konec února 1991 |
| 0.9.2 | podzim 1991 |
| 0.9.4 | 24. prosince 1991 |
| 0.9.5 | 2. ledna 1992 |
| 0.9.6 | 6. dubna 1992 |
| 0.9.8 | 9. ledna 1993 |
| 0.9.9 | 29. července 1993 |
4. Odsazování v ABC a Pythonu
Zkušenější programátoři, kteří se seznamují s programovacím jazykem Python, bývají poměrně často překvapeni tím, že součástí syntaxe tohoto jazyka je i odsazení; navíc se na začátku bloků používá dvojtečka (naopak začátečníci, kteří jiný jazyk neznají, tento fakt většinou zcela přirozeně přijmou, což mám několikrát ověřeno v praxi). Kde se vlastně tento neobvyklý zápis programů objevil? Ještě před samotným jazykem ABC bylo vytvořeno několik jeho předchůdců označovaných písmenem B a číslovkou (B0, B1, …). A již v B0 se objevilo povinné odsazování, které zde mělo význam sdružení operací do bloků. Ovšem samotné bloky tehdy byly uvozeny klíčovými slovy BEGIN a END. Plánovalo se, že díky použití klíčových slov bude odsazování prováděno automaticky ve specializovaném programátorském textovém editoru (a to se stále pohybujeme na začátku devadesátých let minulého století).
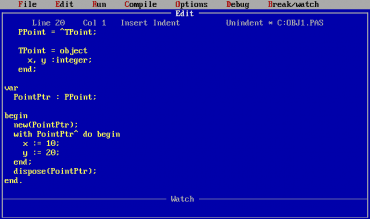
Obrázek 2: Nepovinné, ovšem pochopitelně doporučené odsazování v Pascalu, resp. zde konkrétně ve slavném Turbo Pascalu.
Ovšem poté si tvůrci jazyka B0 uvědomili, že vyžadovat odsazení a současně navíc i použití klíčových slov BEGIN a END je vlastně nadbytečné a proto v jazyce B1 (tedy ve druhé generaci jazyka B) již chybělo klíčové slovo BEGIN. Namísto END se používalo spojení END IF, END FOR atd. (to tedy znamená, že podmínky a smyčky automaticky vytvářely bloky, což je podle mého skromného názoru poměrně dobrý způsob strukturování programů). A nakonec se v jazyce B2 programátoři „museli“ zcela obejít bez zápisu začátků a konců bloků pomocí klíčových slov – vše bylo vyřešeno pouhým odsazením.
Dalším typickým prvkem programovacího jazyka B (a posléze ABC a Pythonu) je dvojtečka zapisovaná před začátkem bloku. Myšlenka použít dvojtečku vznikla v roce 1978, kdy Robert Dewar, Peter King, Jack Schwartz a náš starý známý Lambert Meertens navrhovali syntaxi jazyka B a porovnávali různě zápisy bubble sortu. Nakonec zavolali manželku Roberta Dewara a zeptali se jí, zda se jí navržená varianta líbí. Ta odpověděla, že má pocit, že se zápis „FOR i …“ vztahuje pouze k jednomu řádku a nikoli k celému bloku pod tímto řádkem. A právě na základě tohoto alfa testingu návrhu jazyka bylo rozhodnuto před začátkem bloku používat dvojtečku, což Pythonu vydrželo až do dneška.
5. Otestování možností Pythonu 0.9.1
Tento článek není zaměřen pouze na popis historie vývoje programovacího jazyka Python. Ukážeme si i použití dnes již značně historického interpretru Python 0.9.1 na moderním hardware. Zajímavé je, že i tak starý zdrojový kód (má již 34 let), který byl určen pro šestnáctibitové a 32bitové systémy a překládán byl relativně jednoduchými překladači jazyka C, je možné přeložit moderním překladačem céčka pro 64bitový operační systém – a výsledek bude stále funkční a dokonce do značné míry kompatibilní s moderními variantami programovacího jazyka Python.
V rámci dalších kapitol si popíšeme způsob překladu Pythonu 0.9.1 a opravu jedné chyby v interpretru. Dále si ukážeme jednoduchý benchmark, kterým porovnáme rychlost interpretace kódu v Pythonu 0.9.1 v porovnání s moderním Pythonem 3.13 (resp. dnes vlastně 3.14). A nakonec si ukážeme některé rozdíly v syntaxi Pythonu.
6. Příprava na překlad Pythonu 0.9.1
Nejprve je nutné získat zdrojové kódy Pythonu 0.9.1, které se pokusíme přeložit moderním překladačem jazyka C. Tyto zdrojové kódy lze nalézt na adrese https://www.python.org/ftp/python/src/Python-0.9.1.tar.gz, i když existuje i několik repositářů, které je ve více či méně původní podobě obsahují taktéž.
Nejprve stáhneme tarball se zdrojovými kódy:
$ wget https://www.python.org/ftp/python/src/Python-0.9.1.tar.gz
Saving 'Python-0.9.1.tar.gz'
HTTP response 200 [https://www.python.org/ftp/python/src/Python-0.9.1.tar.gz]
Python-0.9.1.tar.gz 100% [=====================================================================================>] 378.07K --.-KB/s
[Files: 1 Bytes: 378.07K [665.62KB/s] Redirects: 0 Todo: 0 Errors: 0 ]
Tarball běžným způsobem rozbalíme:
$ tar xvfz Python-0.9.1.tar.gz python-0.9.1/ python-0.9.1/demo/ python-0.9.1/demo/README python-0.9.1/demo/scripts/ python-0.9.1/demo/scripts/findlinksto.py python-0.9.1/demo/scripts/mkreal.py ... ... ... python-0.9.1/src/To.do python-0.9.1/src/token.h python-0.9.1/src/tokenizer.c python-0.9.1/src/tokenizer.h python-0.9.1/src/traceback.c python-0.9.1/src/traceback.h python-0.9.1/src/tupleobject.c python-0.9.1/src/tupleobject.h python-0.9.1/src/typeobject.c python-0.9.1/src/xxobject.c
Po rozbalení tarballu by měl vzniknout adresář python-0.9.1 s následující strukturou podadresářů:
├── demo │ ├── scripts │ ├── sgi │ │ ├── audio │ │ ├── audio_stdwin │ │ ├── gl │ │ └── gl_panel │ │ ├── apanel │ │ ├── flying │ │ ├── nurbs │ │ └── twoview │ └── stdwin ├── doc ├── lib └── src
Samotné zdrojové kódy interpretru Pythonu jsou, společně s pomocnými soubory, uloženy do podadresáře src, do kterého se přepneme:
$ cd python-0.9.1/src
7. Úprava souboru Makefile
Aby bylo možné interpret Pythonu 0.9.1 přeložit i moderním překladačem C, který se v mnoha ohledech liší od dobového „céčka“, musíme do souboru Makefile přidat definici několika přepínačů céčka, které umožní překlad kódu s implicitně definovanými funkcemi (tj. funkcemi bez předběžné definice), umožní pracovat s navzájem nekompatibilními ukazateli atd.:
CFLAGS=-Wno-implicit-function-declaration -Wno-incompatible-pointer-types -Wno-implicit-int
Dále je nutné upravit příkaz použitý pro cíl python (odstraní se zavináč atd.):
python: libpython.a $(OBJECTS) $(LIBDEPS) Makefile
$(CC) $(CFLAGS) $(OBJECTS) $(LIBS) -o python
Patch, který je možné aplikovat na původní Makefile (tedy na soubor získaný z tarballu), vypadá následovně:
--- Makefile 2009-03-27 01:23:41.000000000 +0100
+++ /tmp/ramdisk/python-0.9.1-/src/Makefile 2025-10-18 17:33:35.054267113 +0200
@@ -56,6 +56,8 @@
#RANLIB = true # For System V
RANLIB = ranlib # For BSD
+CFLAGS=-Wno-implicit-function-declaration -Wno-incompatible-pointer-types -Wno-implicit-int
+
# If your system doesn't have symbolic links, uncomment the following
# line.
@@ -380,8 +382,7 @@
# ============
python: libpython.a $(OBJECTS) $(LIBDEPS) Makefile
- $(CC) $(CFLAGS) $(OBJECTS) $(LIBS) -o @python
- mv @python python
+ $(CC) $(CFLAGS) $(OBJECTS) $(LIBS) -o python
libpython.a: $(LIBOBJECTS)
-rm -f @lib
8. Překlad interpretru Pythonu 0.9.1
Nyní se již můžeme pokusit o překlad interpretru Pythonu 0.9.1. Postačuje zadat příkaz make (nepoužívá se ./configure; život vývojáře býval jednodušší a dobrodružnější):
$ make
Moderní překladač céčka si sice bude na mnoha místech stěžovat, že se volají funkce bez předběžné definice, používají se nesprávné datové typy při volání funkcí atd., ovšem překlad by se měl nakonec dokončit bez chyby:
cc -Wno-implicit-function-declaration -Wno-incompatible-pointer-types -Wno-implicit-int -c -o acceler.o acceler.c
In file included from pgenheaders.h:48,
from acceler.c:36:
malloc.h:59:13: warning: conflicting types for built-in function ‘malloc’; expected ‘void *(long unsigned int)’ [-Wbuiltin-declaration-mismatch]
59 | extern ANY *malloc PROTO((unsigned int));
| ^~~~~~
malloc.h:1:1: note: ‘malloc’ is declared in header ‘<stdlib.h>’
+++ |+#include <stdlib.h>
1 | /***********************************************************
malloc.h:60:13: warning: conflicting types for built-in function ‘calloc’; expected ‘void *(long unsigned int, long unsigned int)’ [-Wbuiltin-declaration-mismatch]
...
...
...
pythonmain.c: In function ‘fatal’:
pythonmain.c:349:8: warning: incompatible implicit declaration of built-in function ‘abort’ [-Wbuiltin-declaration-mismatch]
349 | abort();
| ^~~~~
pythonmain.c:349:8: note: include ‘<stdlib.h>’ or provide a declaration of ‘abort’
pythonmain.c: In function ‘goaway’:
pythonmain.c:385:8: warning: incompatible implicit declaration of built-in function ‘exit’ [-Wbuiltin-declaration-mismatch]
385 | exit(sts);
| ^~~~
pythonmain.c:385:8: note: include ‘<stdlib.h>’ or provide a declaration of ‘exit’
cc -c -Wno-implicit-function-declaration -Wno-incompatible-pointer-types -Wno-implicit-int '-DPYTHONPATH=".:/usr/local/lib/python:/ufs/guido/lib/python:../lib"' config.c
cc -Wno-implicit-function-declaration -Wno-incompatible-pointer-types -Wno-implicit-int pythonmain.o config.o libpython.a -lm -o python
9. Plnohodnotný interpret Pythonu menší než 200kB?
Výsledkem překladu, který mimochodem na moderním HW trvá jen několik sekund, je spustitelný soubor python; v mém konkrétním případě soubor pro 64bitovou (!) platformu x86–64:
$ file python python: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=494acb46ee8b972e65311ff0b8aa63e519422456, for GNU/Linux 3.2.0, not stripped
Tento soubor má velikost necelých 200kB, což je v ostrém kontrastu s moderními interpretry Pythonu, v nichž velikost interpretru (binární soubor s ladicími informacemi) dosahuje 39MB, což je více než 200× více:
-rwxr-xr-x. 1 ptisnovs ptisnovs 185504 Oct 21 18:15 python
Pokud se z binárního souboru moderního interpretru odstraní ladicí symboly, bude mít velikost přibližně 7MB, zatímco u Pythonu 0.9.1 klesne velikost na 150 kB. Rozdíl ve velikosti je stále více než čtyřicetinásobný.
Interpret Pythonu, který jsme získali, je pojat velmi minimalisticky a například neakceptuje prakticky žádné přepínače (jen -s a -display) a pochopitelně neobsahuje ani nápovědu:
$ ./python --help python: can't open file '--help'
Otestujeme, zda interpret skutečně pracuje:
$ ./python >>>
Výrazy se ihned interaktivně vyhodnocují, naprosto stejně, jako je tomu i dnes:
>>> 1+2 3 >>>
10. Oprava chyby v implementaci operátoru pro součin dvou hodnot
Pokusme se v interpretru Pythonu 0.9.1 vypočítat součin 6×7:
$ ./python >>> 6*7 Unhandled exception: run-time error: integer overflow Stack backtrace (innermost last): File "<stdin>", line 1 >>>
Zajímavé je, že tento jednoduchý výpočet nebyl dokončen, protože skončil běhovou chybou. Je tomu tak z toho důvodu, že se ve zdrojovém kódu interpretru špatně detekuje přetečení výsledku operace součinu. Používá se zde přetypování vypočtené hodnoty na long, ovšem tento typ nemá přesně definovánu bitovou šířku a tudíž se zde projevuje vliv moderních překladačů jazyka C. Oprava je snadná – v souboru intobject.c je nutné namísto long použít například přenositelný int32_t:
static object *
int_mul(v, w)
intobject *v;
register object *w;
{
register long a, b;
double x;
if (!is_intobject(w)) {
err_badarg();
return NULL;
}
a = v->ob_ival;
b = ((intobject *)w) -> ob_ival;
x = (double)a * (double)b;
if (x > 0x7fffffff || x < (double) (int32_t) 0x80000000)
return err_ovf();
return newintobject(a * b);
}
Příslušný patch vypadá následovně:
--- intobject.c 2009-03-27 00:59:41.000000000 +0100
+++ /tmp/ramdisk/python-0.9.1/src/intobject.c 2025-10-21 18:22:17.740699911 +0200
@@ -22,6 +22,8 @@
******************************************************************/
+#include <stdint.h>
+
/* Integer object implementation */
#include "allobjects.h"
@@ -197,7 +199,7 @@
a = v->ob_ival;
b = ((intobject *)w) -> ob_ival;
x = (double)a * (double)b;
- if (x > 0x7fffffff || x < (double) (long) 0x80000000)
+ if (x > 0x7fffffff || x < (double) (int32_t) 0x80000000)
return err_ovf();
return newintobject(a * b);
}
Po aplikaci patche je nutné interpret znovu přeložit. Nyní již bude vše plně funkční:
$ ./python >>> 6*7 42 >>>
11. Realizace algoritmu bublinkového řazení pro moderní Python
V další části článku se pokusíme o zjištění, jak rychlé jsou moderní interpretry Pythonu oproti jeho nejstarší dostupné verzi, tj. 0.9.1. Připravíme si jednoduchý benchmark, ve kterém je realizován algoritmus bublinkového řazení. Tento algoritmus (a vlastně i celý program) jsem schválně napsal takovým způsobem, aby byl snadno transformovatelný do podoby kompatibilní s Pythonem 0.9.1:
import random
import time
def bubble_sort(size):
a = []
for i in range(size):
a.append(random.randint(0, 2**15))
for i in range(size - 1, 0, -1):
for j in range(i):
if a[j] > a[j + 1]:
a[j], a[j + 1] = a[j + 1], a[j]
for i in range(size-1):
if a[i] > a[i+1]:
print("FAIL")
t1 = time.time()
bubble_sort(30000)
t2 = time.time()
print("Total time:", t2-t1)
12. Přepis algoritmu pro Python 0.9.1
Pokusme se tento benchmark přepsat do podoby kompatibilní s Pythonem 0.9.1. Je nutné provést několik změn:
- namísto modulu random se použije modul nazvaný rand (náhodná čísla schválně generujeme v rozsahu 0..32767), abychom dostali stejný rozsah hodnot.
- print se zapisuje jako příkaz, nikoli jako volání funkce.
- řetězce musí být uzavřeny do apostrofů, nikoli do uvozovek.
Výsledný program bude vypadat následovně:
import rand
import time
def bubble_sort(size):
a = []
for i in range(size):
a.append(rand.rand())
for i in range(size - 1, 0, -1):
for j in range(i):
if a[j] > a[j + 1]:
a[j], a[j + 1] = a[j + 1], a[j]
for i in range(size-1):
if a[i] > a[i+1]:
print 'FAIL'
t1 = time.time()
bubble_sort(30000)
t2 = time.time()
print 'Total time:', t2-t1
13. Vizuální porovnání obou variant: verze pro moderní Python vs. verze pro 34 let starý překladač
Pro zajímavost se podívejme, jak málo změn je vlastně nutné provést ve výpočtu tak, aby byl zdrojový kód kompatibilní s více než 34 let starým interpretrem. Liší se způsob výpočtu pseudonáhodných čísel, print byl původně příkazem a nikoli funkcí, řetězce musí být zapisovány do apostrofů – a to je vlastně vše:
import random import rand
import time import time
def bubble_sort(size): def bubble_sort(size):
a = [] a = []
for i in range(size): for i in range(size):
a.append(random.randint(0, 2**15)) a.append(rand.rand())
for i in range(size - 1, 0, -1): for i in range(size - 1, 0, -1):
for j in range(i): for j in range(i):
if a[j] > a[j + 1]: if a[j] > a[j + 1]:
a[j], a[j + 1] = a[j + 1], a[j] a[j], a[j + 1] = a[j + 1], a[j]
for i in range(size-1): for i in range(size-1):
if a[i] > a[i+1]: if a[i] > a[i+1]:
print("FAIL") print 'FAIL'
t1 = time.time() t1 = time.time()
bubble_sort(30000) bubble_sort(30000)
t2 = time.time() t2 = time.time()
print("Total time:", t2-t1) print 'Total time:', t2-t1
14. Porovnání rychlosti moderního interpretru s jeho 34 let starou variantou
V deváté kapitole jsme si řekli, že interpret Pythonu 0.9.1 je cca 200× menší, než interpret moderního Pythonu (což ovšem ani zdaleka není férové srovnání). Ovšem zajímavé bude porovnat i rychlosti obou variant interpretrů. Použijeme benchmarky s realizací algoritmu bublinkového řazení s těmito výsledky:
| Python 0.9.1 | Python 3.13 | Zrychlení |
|---|---|---|
| 189 | 54 | 3,5× |
| 188 | 53 | 3,5× |
| 189 | 54 | 3,5× |
| 189 | 55 | 3,4× |
| 188 | 54 | 3,4× |
| 187 | 53 | 3,5× |
| 187 | 56 | 3,3× |
| 193 | 58 | 3,3× |
| 187 | 57 | 3,2× |

Obrázek 3: Porovnání rychlosti Pythonu 0.9.1 s Pythonem 3.13
Z naměřených výsledků je patrné, že došlo k přibližně 3,5 násobnému zrychlení (popravdě bych očekával ještě větší zrychlení, resp. přesněji řečeno konkurenční technologie, například JVM, se zrychlily mnohem více).
15. Základní vlastnosti Pythonu 0.9.1
Pro čtenáře tohoto článku pravděpodobně nebude velkým překvapením, když napíšeme, že se programovací jazyk Python postupně vyvíjí a že některé jeho verze mezi sebou nejsou (resp. nemusí být) plně kompatibilní. Mohlo by se tedy zdát, že Python 0.9.1 bude v porovnání s moderními Pythony již na první pohled zcela odlišný programovací jazyk. Samozřejmě k několika změnám v syntaxi a sémantice došlo, ale kupodivu jich není příliš mnoho, což si ostatně ukážeme v několika demonstračních příkladech popsaných v navazujících třech kapitolách.
16. Numerické konstanty
V moderním Pythonu lze používat celočíselné hodnoty s neomezeným rozsahem, hodnoty s plovoucí řádovou čárkou i komplexní čísla:
# int/long print(42) print(100000000000000000000000000000000000000000000000000000) # float print(3.1415) print(1.2e10) print(3e-3) print(-3e-3) # complex print(2 + 3j) print(1.5 + 2.8j) print(1e10 + 3e-5j)
Python 0.9.1 podporuje jen celočíselné typy s omezeným rozsahem a typ s plovoucí řádovou čárkou:
# int/long print(42) print(100000000000000000000000000000000000000000000000000000) # float print(3.1415) print(1.2e10) print(3e-3) print(-3e-3)
Povšimněte si, že je sice možné načíst „neomezené“ celé číslo, ale interně dojde k jeho omezení na long (což vlastně máme štěstí – původně se totiž jednalo jen o 32bitový rozsah):
42 9223372036854775807 3.1415 12000000000.0 0.003 -0.003
17. Definice třídy
Definice třídy v moderním Pythonu vypadá následovně:
class Employee:
def __init__(self, first_name, surname, salary):
self._first_name = first_name
self._surname = surname
self._salary = salary
e = Employee()
V Pythonu 0.9.1 se musí explicitně zapisovat předek Object a taktéž se v definici třídy nesmí objevit prázdné řádky (to ovšem ani v definici funkce):
class Employee(Object):
def __init__(self, first_name, surname, salary):
self._first_name = first_name
self._surname = surname
self._salary = salary
e = Employee()
18. Definice funkcí a základní programové konstrukce
Nepatrně složitější program slouží k výpočtu BMI na základě interaktivně zadaných vstupů. Verze pro moderní verze Pythonu může vypadat následovně:

#!/usr/bin/env python
# encoding=utf-8
"""Body Mass Index calculator."""
import sys
def compute_bmi(mass, height):
"""Vlastní výpočet BMI za základě hmotnosti a výšky."""
height = height / 100.0
bmi = mass / (height * height)
return bmi
print("Mass (kg): ")
mass = int(input())
# kontrola na špatný vstup
if mass < 0:
print("Invalid input")
sys.exit(1)
print("Height (cm): ")
height = int(input())
# kontrola na špatný vstup
if height < 0:
print("Invalid input")
sys.exit(1)
# výpočet výsledku a výpis na obrazovku
print("BMI = ", compute_bmi(mass, height))
Verze stejného programu, nyní ovšem pro Python 0.9.1 se v několika ohledech liší. Nepoužíváme dokumentační řetězce, ostatní řetězce jsou zapisovány do apostrofů, namísto funkce print se používá příkaz print a navíc není povoleno v jednom výrazu použít celočíselnou proměnnou a hodnotou či proměnnou typu double, takže je konverze provedena explicitně přímo ve zdrojovém kódu. A opět – žádné další změny nejsou nutné!:
#!/usr/bin/env python
# encoding=utf-8
import sys
def compute_bmi(mass, height):
height = float(height)
height = height / 100.0
bmi = float(mass) / (height * height)
return bmi
print 'Mass (kg): '
mass = int(input())
# kontrola na špatný vstup
if mass < 0:
print 'Invalid input'
sys.exit(1)
print 'Height (cm): '
height = int(input())
# kontrola na špatný vstup
if height < 0:
print 'Invalid input'
sys.exit(1)
# výpočet výsledku a výpis na obrazovku
print 'BMI = ', compute_bmi(mass, height)
19. Repositář s demonstračními příklady
Všechny dnes popsané demonstrační příklady jsou vypsány v následující tabulce:
20. Odkazy na Internetu
- Python history: from None to AI
https://python3.info/about/history.html - The History of the Python Language: A Journey Through Time
https://coderivers.org/blog/history-of-python-language/ - Python – History and Versions
https://www.tutorialspoint.com/python/python_history.htm - The Evolution of Python: A Detailed History and Major Achievements
https://www.backendmesh.com/the-evolution-of-python/ - History of Python
https://en.wikipedia.org/wiki/History_of_Python - History of Python
https://www.geeksforgeeks.org/python/history-of-python/ - Old Python releases
https://www.python.org/download/releases/ - Interactive: The Top Programming Languages 2016 (starší data, pěkný způsob filtrace atd.)
https://spectrum.ieee.org/static/interactive-the-top-programming-languages-2016 - Generational list of programming languages
https://en.wikipedia.org/wiki/Generational_list_of_programming_languages - Most Popular Programming Languages on Stack Overflow Bar Chart Race
https://www.youtube.com/watch?v=cKzP61Gjf00 - Další kulaté výročí v IT: dvacet let existence Pythonu 2
https://www.root.cz/clanky/dalsi-kulate-vyroci-v-it-dvacet-let-existence-pythonu-2/ - Zdrojové kódy starých verzí Pythonu
https://legacy.python.org/download/releases/src/ - Python 1.5.2
https://www.python.org/download/releases/1.5/ - Python 1.6.1
https://www.python.org/download/releases/1.6.1/ - Python 3.14.0
https://test.python.org/downloads/release/python-3140/ - What’s new in Python 3.14 (official)
https://docs.python.org/3/whatsnew/3.14.html - What’s New In Python 3.13 (official)
https://docs.python.org/3/whatsnew/3.13.html - What’s New In Python 3.12 (official)
https://docs.python.org/3/whatsnew/3.12.html - What’s New In Python 3.11 (official)
https://docs.python.org/3/whatsnew/3.11.html - What’s New In Python 3.12
https://dev.to/mahiuddindev/python-312–4n43 - Python: The Documentary | An origin story
https://www.youtube.com/watch?v=GfH4QL4VqJ0



