
Dnešní díl vychází nepředpokládaně o týden později kvůli mému přílišnému zatížení ve škole. Během dvou týdnů by se snad situace měla stabilizovat a vše zase vycházet pravidelně.
Problematika výkonnosti je v grafických aplikacích často kritická. Během vývoje aplikace roste, roste i scéna, přidávají se různé efekty,… a po nějaké době jsou téměř vždy dosaženy limity i toho nejvýkonnějšího hardware.
Téměř vždy je jedním z limitujících faktorů propustnost grafického subsystému, kde velmi často narážíme na horní limit trojúhelníkové propustnosti. Do tohoto tématu spadají i dnešní příklady. První z nich jsme už nakousli minule. Dnes tedy tuto problematiku dotáhneme až do konce.
| 2.4 – Wire Box (cont.) | Drátěná krabice (pokračování) |
| 2.5 – Performance meter | Měřič výkonnosti |
V prvním příkladu vyřešíme vše, co se týká rendrování trojúhelníků, a na to navážeme měřením výkonnosti na různých grafických kartách a za různých podmínek, které se v naší aplikaci mohou vyskytnout.
Příklad 2.4: Wire Box (Drátěná krabice) – pokračování
Minule jsme nakousli téma, jak rendrovat obyčejné trojúhelníky v Open Inventoru. Pro připomenutí uvádím screenshot:
Dnes si toto téma rozebereme detailněji. Ale předně, abych předešel veškerému zmatení, že to, co vidíme na obrázku – ten drátěný model – bychom snad ani za něco složeného z trojúhelníků neměli považovat. Není tomu tak. V OpenGL můžeme totiž funkcí glPolygonMode měnit styl rendrování. Můžeme volit ze třech hodnot: GL_FILL pro vyplněné trojúhelníky, GL_LINE pro trojúhelník složený pouze z čar a GL_POINT, kdy se rendrují pouze body ve vrcholech. Tento model chování samozřejmě přebírá i Inventor a ve třídě SoDrawStyle zapouzdřuje tuto funkcionalitu. Proto nastavením SoDrawStyle::style na hodnotu SoDrawStyle::LINES se místo rendrování klasické geometrie začne rendrovat její drátěný model.
Teď už se ale pojďme zahrabat hlouběji do problematiky rendrování trojúhelníků. Nejdřív si vše krátce rozebereme z pohledu OpenGL, a pak, jak je to vše zapouzdřeno v Inventoru. Na závěr podiskutujeme o celkové výkonnosti rendrování trojúhelníků.
Jak mnoho z nás ví, v OpenGL můžeme použít několik způsobů, jak rendrovat trojúhelníky. Nejjednodušší způsob je GL_TRIANGLES, kdy specifikujeme vždy tři body, které budeme nazývat vertexy. Každý z těchto vertexů se skládá ze třech prostorových souřadnic – x,y,z. Tyto tři vertexy tedy pošleme do OpenGL a ono nám vyrendruje jeden trojúhelník. Designéři OpenGL však přemýšleli: Většina trojúhelníků sdílí vrcholy se svými sousedy, nešlo by to tedy nějak optimalizovat? Proto byly vymyšleny věci jako GL_TRIANGLE_STRIP, který vždy z prvních třech vertexů vykreslí první trojúhelník, ale od té chvíle již vykresluje trojúhelník s každým dalším vertexem, přičemž chybějící dva vertexy použije z předchozího trojúhelníku. Vše demonstruje následující obrázek:
1-----3-----5
\ / \ /
\ / \ /
2-----4
Pokud by někdo požadoval více detailů, tak celou problematiku rozebírá rootovský článek Grafická knihovna OpenGL III.
Jaký z toho všeho plyne závěr? Takový, že kromě velmi ojedinělých případů bude použití GL_TRIANGLE_STRIP vždy rychlejší než obyčejné trojúhelníky, neboť se do OpenGL posílá méně dat pro vykonání stejné práce.
Z toho vyšli i designéři Open Inventoru a navrhli dokonce dvě třídy pro rendrování trojúhelníků: SoTriangleStripSet a SoIndexedTriangleStripSet. Nejjednodušší cesta k osvětlení rozdílu mezi nimi bude přímo na našem příkladu. Minule jste si mohli stáhnout verzi se SoTriangleStripSet, dnes se SoIndexedTriangleStripSet – verze pro Linux a Windows.
Jak již možná tušíme, rozdíl je ve způsobu specifikování vertexů. Jednou budeme brát vertexy tak, jak leží v paměti za sebou, a budeme je rendrovat (neindexovaná verze), kdežto u druhé využijeme vlastnosti geometrie, že každý vertex je obyčejně použit několikrát. Proto ho specifikujeme jednou a pak se už na něj jen odkazujeme indexem. Výkonnostně si obě řešení poměříme v následujícím příkladě. Výsledky i mě překvapily. Pojďme se nejprve podívat na realizaci neindexované verze:
#define SIZE2 50 // velikost skyboxu (vydělená dvěma)
// souřadnice jednotlivých vertexů
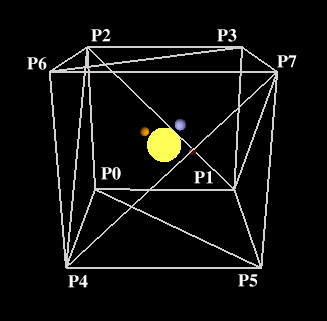
#define P0 { -SIZE2, -SIZE2, -SIZE2 }
#define P1 { SIZE2, -SIZE2, -SIZE2 }
#define P2 { -SIZE2, SIZE2, -SIZE2 }
#define P3 { SIZE2, SIZE2, -SIZE2 }
#define P4 { -SIZE2, -SIZE2, SIZE2 }
#define P5 { SIZE2, -SIZE2, SIZE2 }
#define P6 { -SIZE2, SIZE2, SIZE2 }
#define P7 { SIZE2, SIZE2, SIZE2 }
// předpřipravená geometrie hvězdného pozadí (sky box)
static float skyBoxVertices[6][4][3] =
{
P0, P1, P2, P3 }, // sky00
{ P6, P4, P2, P0 }, // sky06
{ P5, P4, P7, P6 }, // sky12
{ P5, P7, P1, P3 }, // sky18
{ P2, P3, P6, P7 }, // skyN0
{ P4, P5, P0, P1 } // skyS0
}; Vidíme, že vertexy jsou uloženy v poli skyBoxVertices tak, jak jdou za sebou při rendrování. Každý vertex zabírá v paměti 12 byte (3*sizeof(float)) a je jich tam 24. Celkově tedy 288 byte.
Následující obrázek ukazuje rozmístění jednotlivých vrcholů:
Jako statická data nám souřadnice vertexů moc nepomohou. Musíme je nějak načíst do grafu scény. K tomu nám slouží nod SoCoordinate3 (trojka na konci zdůrazňuje, že používáme tři prostorové souřadnice; SoCoordinate4 je dobrá na některé speciality, ale já ji také zatím ještě nepoužil). Souřadnice tedy umístíme do grafu scény takto:
// Souřadnice pro rendrované trojúhelníky jsou předpřipravené
// ve skyBoxVertices.
SoCoordinate3 *coords = new SoCoordinate3;
coords->point.setValues(0, 4*6, skyBoxVertices[0]);
root->addChild(coords); SoCoordinate3::point::setValues má tři parametry: index prvního měněného prvku, počet měněných prvků a ukazatel na pole hodnot. Jen bych upozornil, že Dokumentace k Coin je ke všem fieldům vcelku neúplná. Způsobuje to automatický generátor dokumentace Doxigen, který špatně zpracovává makra. Snad tedy někdy projdu zdrojáky a napíšu alespoň řádku ke každé funkci v některém z dalších pokračování.
SoCoordinate3 nám tedy specifikuje souřadnice, ale vlastní rendrování provádí až SoTriangleStripSet:
// SoTriangleStripSet nám vyrendruje trojúhelníky.
// Každá položka numVertices udává počet vrcholů
// tvořících "triangle strip".
SoTriangleStripSet *strip = new SoTriangleStripSet;
for (int i=0; i<6; i++)
strip->numVertices.set1Value(i, 4);
root->addChild(strip); V kódu vidíme, že šestkrát voláme funkci set1Value na field numVertices. Jako parametr uvádíme index měněného prvku a novou hodnotu. Číslo čtyři na nultém indexu říká, že první triangle strip se bude skládat ze čtyřech vertexů. To znamená, že se vezmou vertexy ze SoCoordinate3 na indexech 0–3 a vykreslí se z nich dva trojúhelníky. Počet trojúhelníků je totiž vždy o dva menší než počet vertexů. Nyní už máme vykreslenu jednu stranu krychle. Druhá čtyřka má říká, že druhý triangle strip bude mít opět čtyři vertexy. To odpovídá indexům 4–7 v SoCoordinate3 (index je neustále inkrementován). Poslední čtyřka pak odpovídá indexům 20–23.
Odlišný přístup používá SoIndexedTriangleStripSet. Místo jednoho pole obsahujícího všechny vertexy v pořadí, jak se rendrují za sebou, jsou zde pole dvě. První pole obsahuje osm vertexů odpovídajících vrcholům krychle a druhé je pole indexů:
#define SIZE2 50 // velikost skyboxu (vydělená dvěma)
// souřadnice jednotlivých vertexů
static float skyBoxVertices[8][3] =
{
-SIZE2, -SIZE2, -SIZE2,
SIZE2, -SIZE2, -SIZE2,
-SIZE2, SIZE2, -SIZE2,
SIZE2, SIZE2, -SIZE2,
-SIZE2, -SIZE2, SIZE2,
SIZE2, -SIZE2, SIZE2,
-SIZE2, SIZE2, SIZE2,
SIZE2, SIZE2, SIZE2,
};
// indexy do skyBoxVertices pro jednotlivé vertexy,
// -1 ukončuje vždy jeden triangle-strip
static int32_t skyBoxIndices[5*6] =
{
0, 1, 2, 3, -1, // sky00
6, 4, 2, 0, -1, // sky06
5, 4, 7, 6, -1, // sky12
5, 7, 1, 3, -1, // sky18
2, 3, 6, 7, -1, // skyN0
4, 5, 0, 1, -1, // skyS0
}; Pole indexů se nám odkazuje do pole vertexů a každý triangle strip je ukončen –1. Vidíme nápadnou podobnost mezi poli skyBoxVertices (předchozí případ) a skyBoxIndices (tento případ). Množství spotřebované paměti je 24 floatů (96 bytes) pro první tabulku a 30 integerů (120 bytes) pro druhou. Celkově tedy 216 byte. Takže jsme ušetřili čtvrtinu paměti.
Jiný pohled na věc je, že pokud například děláme editor modelů a chceme v něm implementovat možnost přesunování jednotlivých vertexů například tažením myší, tak v neindexované verzi upadneme do problémů, neboť bychom museli hledat všechny vertexy modelu, které leží v daném bodě, a ty pak posunout. Realizace přes indexovanou verzi je v tomto případě určitě jednodušší, protože změnu stačí provést pouze jednou v poli vertexů.
Poznámka k názvosloví: Množné číslo od index je v angličtině indices, stejně jako od vertex vertices.
Tímto jsme zakončili náš příklad a vrhneme se na otázku výkonnosti.
Příklad 2.5: Performance (Výkonnost)
Zpočátku jsem si říkal, že indexovaná verze potřebuje pár instrukcí pro každý vertex navíc, a tudíž bude o maličký chloupek pomalejší. Ale od časů GeForce256 (první GeForce, rok uvedení 1999) je vše jinak. Ta totiž obsahuje uvnitř vertexovou cache (na 16 prvků), do ní zpracuje našich osm vertexů (transformace, světelné výpočty, …), a pak se už na ně jen odkazuje skrz indexy. Kdežto u neindexované verze musíme všechny výpočty provádět pro všech 24 vertexů. Takže indexovaná verze se pod tímto pohledem jeví jako lepší. Bohužel však zatím Coin nepoužívá k rendrování žádnou funkci, u které je vertex cache podporována. Již však jdou zprávy, že se začalo pracovat na podpoře „vertex arrays“, které toto všechno umožní.
Jen tak pro zajímavost jsem provedl měření výkonnosti na velmi rozsáhlém modelu o 87000 trojúhelnících na své GeForce FX5200 a procesoru P3 933MHz. Výsledky mě oproti teorii poněkud zaskočily. Na GeForce FX5200 jsem naměřil 22 FPS pro indexovanou verzi a 18,5 pro neindexovanou. Protože výsledky neodpovídaly mým odhadům, tj. že neindexovaná verze by spíše měla být rychlejší, neboť Coin vertex cache zatím nevyužívá, tak jsem si v duchu říkal: „To může být nějaká fíčůrka této velmi nové grafikárny. Bude třeba vyzkoušet klasiku, tedy GeForce2 MX400.“ Ta mě ale úplně vyvedla z míry, neboť ukázala pouhých 1,3 FPS. Pátral jsem po vysvětlení, neboť podobného záhadného propadu výkonu na některých počítačích jsem si už všiml při jiných příležitostech. Po chvíli se věc vysvětlila: Pokud ve scéně používáme materiály a světla (jako že jsme to dělali až doposud), tak grafický subsystém musí řešit mnoho matematických výpočtů při zobrazování scény, které, pokud nejsou realizovány v hardware grafického akcelerátoru, značně snižují výkon celého systému.
Jak se tedy vyhnout těmto výpočtům? Většina lidí řekne: „Proč bych já měl do scény dávat nějaká světla a podobně. Prostě specifikuju barvu a ono se mi to v té barvě vykreslí.“ A mají pravdu. Přesně tomuto se říká předsvětlená scéna. To znamená, že můžeme mít model města, které dopředu osvětlíme, abychom ušetřili čas během rendrování. Nevýhoda tohoto přístupu je například v tom, že pak nemůžeme modelovat různé směry slunečního svitu během dne. Problematické by také byly například exploze z dnešních her – jsme zvyklí, že výbuch nám osvětlí okolní objekty, což je u předsvětlené scény problém. V praxi se to řeší například tak, že objekty v těsné blízkosti exploze se dočasně rendrují jako osvětlovaná scéna.
K přepínání mezi předsvětleným barevným modelem scény a osvětlovacím modelem nám slouží nod SoLightModel. Jeho field model můžeme nastavit buď na PHONG, nebo BASE_COLOR, přičemž BASE_COLOR je to, co potřebujeme pro naši předsvětlenou scénu:
SoLightModel *lmodel = new SoLightModel;
lmodel->model.setValue(SoLightModel::BASE_COLOR);
root->addChild(lmodel); Od této chvíle bude mít veškerá geometrie barvu rovnu přesně hodnotě difúzní složky jejího materiálu. A abychom nemuseli používat tak robustní věc jako SoMaterial k nastavování pouze difúzní složky, je zde SoBaseColor, který je podstatně úspornější a nastavuje pouze tuto difúzní složku:
SoBaseColor *baseColor = new SoBaseColor;
baseColor->rgb.setValue(1.f, 1.f, 1.f);
root->addChild(baseColor); Nyní už můžeme upřít pozornost na samotné výsledky, které byly naměřeny na několika kartách, jež se mi během dvou uplynulých dnů dostaly pod ruku. Pro každou kartu jsem provedl čtyři měření pro kombinace z osvětlená/předsvětlená (lit/pre-lit) scéna a indexovaný/neindexovaný model. Výsledky nepovažujte za naprosto přesné, protože FPS neustále kolísá o zhruba +/- 5% v závislosti na postranních aktivitách CPU a podobně.
| GF FX5200 |
GF4 Ti4200 |
GF3 Ti200 |
GF4 MX440 |
GF2 MX400 |
TNT2 Ultra |
sw rendr. |
|
| pre-lit, indexed | 29,0 | 26,2 | 26,3 | 27,2 | 26,0 | 7,6 | 5,4 |
| pre-lit, non-ind. | 24,0 | 23,3 | 23,4 | 22,5 | 23,3 | 7,1 | 5,6 |
| lit, indexed | 22,0 | 20,1 | 19,6 | 1,5 | 1,5 | 1,1 | 3,7 |
| lit, non-ind. | 18,5 | 17,8 | 17,3 | 1,5 | 1,5 | 1,1 | 3,9 |
Červená barva nám ukazuje výkonnostní propad, pokud osvětlování scény není realizováno v hardware. Modrá barva značí oblast malých výkonů způsobených „zastaralými technologiemi“, tedy TNT2, která přišla v roce 1998, a software rendering testovaný na microsoftí implementaci. Největším překvapením pro mnohé bude GeForce4 MX440, která potvrzuje svůj rodokmen, tj. že je to vylepšená GeForce2. Její pojmenování je tedy pouze marketingový tah NVidie.
Z tabulky můžeme snadno odvodit trojúhelníkovou propustnost. Stačí vždy vynásobit FPS počtem trojúhelníků modelu, tj. 87000. Výsledky se pohybují od 2,6 milionů trojúhelníků za sekundu při FPS kolem 30 až po 100 tisíc pro 1,1 FPS. Starší programátoři možná budou pamatovat doby TNT2, ATI Rage, Voodoo3, Intel740 a podobně, kdy jsme museli počítat s maximální propustností kolem 300 tisíc trojúhelníků. Z toho vyplýval limit 10000 trojúhelníků na scénu pro tehdy obvyklých 30 FPS. Boom začal s příchodem GeForce256 (rok 1999) a prvními Radeony, které obsahovaly jednotku T&L (Transform and Lighting), a ta umožnila posunout výkon o řád výše. Uvidíme, kam nás posunou vývojáři Coin s výkonem, až dokončí implementaci rendrování přes VAR (Vertex Arrays), což je technika používaná v dnešních hrách.
Myslím, že je čas pustit se do našeho vlastního měření, které by si každý sám mohl zkusit. Výsledky, aby nepřišly nazmar, mi můžete poslat na mou adresu peciva(zavináč)fit(tečka)vutbr(tečka)cz, jako subjekt uveďte ivperf. Já pak vše zpracuju a vyhodnotím výsledky. Hodně totiž chybí porovnání s Radeony, ale například i GeForce2 (ne MX) by mě zajímala, jestli má také výkonnostní propad pro osvětlovanou scénu, nebo jestli jsou to jenom MX-ka, která jsou o to ochudobněna.
Jak tedy změřit náš výkon? K tomu použijeme kód velmi podobný příkladu 2–1 ModelViewer s několika vychytávkami. Můžete si ho stáhnout (1,3MB). Je trochu větší, protože obsahuje dva velké modely s našimi 87000 trojúhelníky.
Po zkompilování můžeme program spustit s parametrem jména souboru obsahujícího scénu, v našem případě AztecCityI.iv nebo AztecCityNI.iv. Zkratka I a NI na konci souboru značí indexovanou a neindexovanou verzi modelu. Volitelně také můžeme zadat parametr -b nebo –base-color, který zařídí, že se se scénou bude jednat, jako by byla předsvětlená. Zde je screenshot:
Možná si také všimnete, že některé plošky modelu jako by blikaly, když se s modelem točí. To je chyba v modelu – dva trojúhelníky přes sebe. Záleží pouze na jejich štěstí v z-bufferu, který z nich bude kdy vyrendrován. Já neumím modelovat, takže to ani nemohu opravit.
První záhada: Kde se nám vzalo to počítadlo FPS? Odpověď je velmi jednoduchá, stačí nastavit proměnnou prostředí COIN_SHOW_FPS_COUNTER na jedničku. Vůbec, Coin má mnoho takovýchto vychytávek v debug verzi. První číslo FPS counteru je odvozeno od času rendrování scény (pro odborníky: až těsně před glFinish()), druhé číslo reflektuje to, co uživatel opravdu vidí, tedy včetně doby, než OpenGL provede všechnu zbývající práci ze své fronty příkazů a včetně čekání na swapbuffers, které se synchronizuje na frekvenci obrazovky.
Druhou proměnnou, kterou nastavujeme, je IV_SEPARATOR_MAX_CACHES. Když ji nastavíme na nulu, zakážeme tím caching scény do display-listů. To by nám totiž ovlivňovalo výsledky. Navíc, NVidia má zřejmě trochu nedooptimalizované display-listy. Rendrování z display-listů je totiž u mě pomalejší než klasické rendrování. Víceméně má vždy 17 FPS bez ohledu na přesný typ GeForce. A navíc vytváření display-listu z celé scény (87000tri) trvá zhruba tři sekundy. Takže je to trochu zklamání.
Třetí věcí je volání metody setOverride(TRUE) na nod SoLightModel, který vkládáme do scény za účelem vynucení si, že scéna bude předsvětlená. Override na nodu značí, že žádný jiný nod, který by následoval dále v grafu scény, nebude moci lightmodel změnit, ani kdyby měl také nastaveno override. Stejným způsobem můžeme například také scéně vnutit, aby se celá bez jakékoliv výjimky rendrovala jako drátěný model a podobně.
A přichází poslední věc v podobě čtyřech backdoorů – tedy zadních vrátek, které nám mohou značně ulehčit debugovací práce. Upozorňuji, že tyto backdoory jsou k dispozici pouze u debug verze, nikoliv v release, což je pochopitelné. Jak tedy tyto backdoory aktivovat? Stačí v běžící aplikaci vyťukat správnou sekvenci písmen a máme to. Zkratky jsou následující:
| dumpiv | uloží celou aktuální scénu do souboru (včetně skryté scény interně přítomné v potomcích SoQtViewer) |
| glinfo | v dialogovém okně zobrazí informace o OpenGL |
| soinfo | zobrazí informace o okenním systému |
| ivinfo | zobrazí verzi inventorské implementace a rozlišení funkce vracející aktuální čas (toto je důležitá informace při portování, protože na všech platformách požadujeme přesnost času řádově v mikrosekundách) |
Nejdůležitější informace nám v tuto chvíli poskytuje glinfo. Z něj snadno zjistíme téměř všechny podstatné vlastnosti OpenGL na našem systému. My zde především můžeme zjistit, skrz co probíhá rendering, zda skrz hardware, či je aktivní pouze softwarová emulace. Také můžeme zde vyčíst název čipu grafické karty a verzi ovladače. Pokud jsou v položkách vendor nebo renderer slova jako Mesa či Microsoft Corporation, tak rendrujeme určitě přes software. Více detailů k jednotlivým položkám výpisu je v OpenGL dokumentaci (především funkce glGetString a glGetIntegerv).
Pokud mi chcete poslat vaše výsledky, proveďte všechna čtyři měření:

$ ./perf -b AztecCityI.iv $ ./perf -b AztecCityNI.iv $ ./perf AztecCityI.iv $ ./perf AztecCityNI.iv
Při měření je ale nutné model roztočit, protože statickou scénu Inventor nepřekresluje a zobrazené číslo by odpovídalo výsledkům z rendrování prvního frame. Jako výsledek mi stačí vždy jen první číslo z FPS counteru, přičemž vezměte hodnotu, kolem které to bude nejvíce kolísat. Dále připojte typ a frekvenci procesoru a název grafické karty. Z názvu karty by mělo být patrné, jaký je tam čip a který je to jeho derivát – Ultra, MX200, Ti400 a podobně. Vše by mělo být zjistitelné po zadání sekvence kláves glinfo. Také připojte typ OS. Vše pošlete na peciva(zavináč)fit(tečka)vutbr(tečka)cz s předmětem ivperf. Výsledky posílejte jen následující dva týdny. Já vše vyhodnotím, a pokud bude něco zajímavého, zmíním se o tom v některém z dalších dílů. Všem zúčastněným předem děkuji.
Závěr
Minule jsem přislíbil i textury na dnešek. Bohužel se nestihly. Příští pokračování tedy bude věnováno především jim. Kvůli mým povinnostem na začátku semestru bude pravděpodobně i příští díl opožděn o týden, tak se nezlobte ;-) .
