
Obsah
1. Technologie mezijazyků (mezikódů) a bajtkódů v moderních interpretrech a překladačích
2. Typická sekvence transformací prováděných při překladu zdrojového kódu
4. Příklad zobrazení struktury výsledného CST
5. Význam mezijazyka v oblasti moderních překladačů
7. Historie vývoje bajtkódu a jeho využití
8. Bajtkód pro zásobníkové vs. registrové virtuální stroje
9. Praktická ukázka rozdílu mezi bajtkódem určeným pro zásobníkový a registrový virtuální stroj
10. Bajtkód virtuálního stroje jazyka Java (JVM)
11. Příklady metod přeložených do bajtkódu JVM
12. Bajtkód využívaný interpretrem jazyka Lua
13. Příklady funkcí přeložených do bajtkódu jazyka Lua
14. Bajtkód využívaný jazykem Python
16. Překlad výpočtu do mezikódu GIMPLE a RTL
18. Překlad výpočtu do LLVM IR
1. Technologie mezijazyků (mezikódů) a bajtkódů v moderních interpretrech a překladačích
V dnešním článku se budeme zabývat technologiemi mezijazyků (někdy se nazývají mezikódy, anglicky pak intermediate representation) a bajtkódů (bytecode). Tyto technologie jsou používány ve většině moderních interpretrů a překladačů, protože v mezijazycích popř. s využitím bajtkódů jsou ukládány výsledky jedné či hned několika fází překladu. Jedná se sice o poněkud skrytou vlastnost překladačů a interpretrů, ovšem může být užitečné ji znát, protože nám umožňuje pochopit, jak vlastně překladače pracují, jaké dokážou provádět optimalizace, zda jsou korektně detekovány ty části zdrojového kódu, které mohou vést k nedefinovanému chování atd. Na tento článek budou navazovat další články, ve kterých se budeme podrobněji zabývat mezijazykem nazvaným LLVM IR (použitý je v rodině překlačů LLVM) a taktéž mezijazyky GIMPLE a RTL, které naopak nalezneme v rodině překladačů GCC (GNU Compiler Collection).
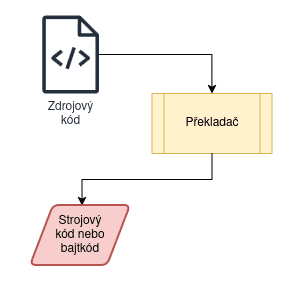
Obrázek 1: Pohled na činnost překladače, který je zde chápán jako černá skříňka, jež transformuje zdrojový kód na strojový kód nebo bajtkód.
2. Typická sekvence transformací prováděných při překladu zdrojového kódu
Při zpracování zdrojových kódů se postupně provádí jednotlivé dílčí kroky, a to jak v klasických překladačích (C, C++, C3, Go, Rust), tak i v těch programovacích jazycích, které provádí překlad „jen“ do bajtkódu s jeho pozdější interpretací (Python, Lua). Díky rozdělení celého zpracování do několika konfigurovatelných a relativně samostatných kroků je zajištěna velká flexibilita a možnost případného relativně snadného rozšiřování o další syntaktické prvky, existuje možnost použití jediné sady nástrojů více programovacími jazyky (GCC, LLVM), lze přidat podporu pro různé výstupní formáty (typický je překlad do nativního kódu pro různé platformy nebo do WebAssembly atd.), podporu pro speciální filtry apod. (nehledě na to, že každá činnost je založena na odlišné teorii). Celý průběh zpracování vypadá při určitém zjednodušení následovně:
- U jazyků typu C a C++ se nejdříve zdrojové kódy transformují s využitím preprocesoru, který expanduje makra, řeší podmínky preprocesoru, vkládání obsahu dalších souborů, expanzi jmen funkcí atd.
- Většinou se však na samotném začátku zpracování nachází takzvanýlexer, který postupně načítá jednotlivé znaky ze vstupního řetězce (resp. většinou ze vstupního souboru) a vytváří z nich lexikální tokeny. Teoreticky se pro každý programovací jazyk používá odlišný lexer a samozřejmě je možné v případě potřeby si napsat lexer vlastní. V případě Pythonu můžeme použít standardní modul tokenizer, nebo lze alternativně použít například projekt Pygments, jenž obsahuje lexery pro mnoho dalších programovacích jazyků a navíc je snadno rozšiřitelný pro přidání dalších jazyků.
- Výstup z lexeru může procházet libovolným počtem filtrů sloužících pro odstranění nebo (častěji) modifikaci jednotlivých tokenů; ať již jejich typů či přímo textu, který tvoří hodnotu tokenu. Díky existenci filtrů je například možné nechat si zvýraznit vybrané bílé znaky, slova se speciálním významem v komentářích (TODO:, FIX:) apod. Některé lexery obsahují filtr přímo ve svém modulu. V běžných překladačích bývá filtrace omezena na odstranění komentářů atd.
- Sekvence tokenů tvoří základ pro syntaktickou analýzu. Nástroj, který syntaktickou analýzu provádí, se většinou nazývá parser a proto se taktéž někdy setkáme s pojmem parsing (tento termín je ovšem chybně používán i v těch případech, kdy se provádí „pouze“ lexikální analýza). Výsledkem činnosti parseru je vhodně zvolená datová struktura, typicky abstraktní syntaktický strom (AST); někdy též strom derivační nebo CST. V případě interpretru jazyka Python vypadá postupné zpracování vstupního zdrojového textu takto: lexer → derivační strom (parse tree) → AST.
- Z AST nebo CST se další transformací typicky vytváří buď přímo bajtkód (Lua, Python) nebo struktura v mezikódu nebo mezijazyku. Záleží na konkrétním překladači nebo interpretru, jakou sémantiku bude tento mezijazyk mít. Moderní překladače navíc mají hned několik mezijazyků popř. se provádí několik transformací mezi různými fázemi překladu. Pokud je výsledkem bajtkód, bude použit interpretrem nebo JITem, pokud se jedná o mezikód, pokračuje se dalším krokem.
- Mezikód/mezijazyk je přeložen backend překladačem do finálního spustitelného kódu určeného pro konkrétní platformu. Touto fází překladu se ovšem dnes zabývat nebudeme.
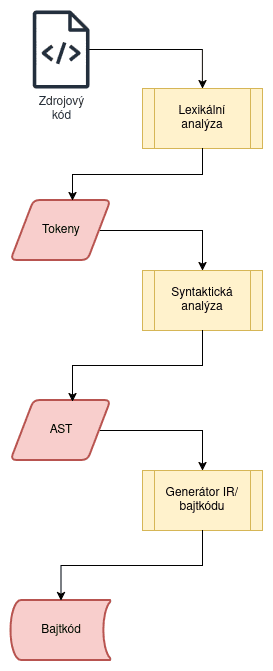
Obrázek 2: Jak překladače, tak i interpretry ve skutečnosti provádí několik transformací. Ze zdrojového kódu vzniká AST a následně bajtkód nebo mezikód.
3. AST a CST
Standardní abstraktní syntaktický strom (AST), o kterém jsme se několikrát zmínili v předchozí kapitole, má ovšem jednu poměrně zásadní nevýhodu – v případě, že AST upravíme a necháme si z něho zpětně vygenerovat zdrojový kód, ztratíme veškeré původní formátování, tedy například mezery zapsané ve výrazech, přesné umístění komentářů, v některých případech i dekorátorů atd. Z tohoto důvodu se pro ty nástroje, které musí modifikovat zdrojový kód (nepřímo – přes strom) používají nepatrně odlišné typy stromů, které se nazývají Concrete Syntax Tree neboli zkráceně CST (popř. derivační stromy nebo parse tree).
Tyto stromové datové struktury, jak již ostatně jejich název napovídá, reprezentují syntaktickou strukturu daného bloku programového kódu (což může být konstanta, výraz, příkaz, složený blok, funkce, třída, či celý modul). Díky tomu, že si CST pamatuje původní zápis syntaktických prvků, je umožněna relativně snadná tvorba nástrojů pro refaktoring kódu. Příkladem může být knihovna LibCST, která slouží pro manipulaci s CST v Pythonu.
4. Příklad zobrazení struktury výsledného CST
Ukažme si na několika jednoduchých příkladech, jaké informace jsou vlastně v CST uloženy. Začneme výrazem, který obsahuje dva operandy, jeden operátor a mezery:
6 * 7
Výsledný CST lze reprezentovat například následujícím způsobem:
BinaryOperation(
left=Integer(
value='6',
lpar=[],
rpar=[],
),
operator=Multiply(
whitespace_before=SimpleWhitespace(
value=' ',
),
whitespace_after=SimpleWhitespace(
value=' ',
),
),
right=Integer(
value='7',
lpar=[],
rpar=[],
),
lpar=[],
rpar=[],
)
Výraz bez mezer, ovšem uložený do kulatých závorek:
(6*7)
Výsledný CST:
BinaryOperation(
left=Integer(
value='6',
lpar=[],
rpar=[],
),
operator=Multiply(
whitespace_before=SimpleWhitespace(
value='',
),
whitespace_after=SimpleWhitespace(
value='',
),
),
right=Integer(
value='7',
lpar=[],
rpar=[],
),
lpar=[
LeftParen(
whitespace_after=SimpleWhitespace(
value='',
),
),
],
rpar=[
RightParen(
whitespace_before=SimpleWhitespace(
value='',
),
),
],
)
Složitější výraz s několika operátory s různou prioritou (** je v Pythonu operátorem umocnění):
(1+2)*3/2**4
Výsledný CST:
BinaryOperation(
left=BinaryOperation(
left=BinaryOperation(
left=Integer(
value='1',
lpar=[],
rpar=[],
),
operator=Add(
whitespace_before=SimpleWhitespace(
value='',
),
whitespace_after=SimpleWhitespace(
value='',
),
),
right=Integer(
value='2',
lpar=[],
rpar=[],
),
lpar=[
LeftParen(
whitespace_after=SimpleWhitespace(
value='',
),
),
],
rpar=[
RightParen(
whitespace_before=SimpleWhitespace(
value='',
),
),
],
),
operator=Multiply(
whitespace_before=SimpleWhitespace(
value='',
),
whitespace_after=SimpleWhitespace(
value='',
),
),
right=Integer(
value='3',
lpar=[],
rpar=[],
),
lpar=[],
rpar=[],
),
operator=Divide(
whitespace_before=SimpleWhitespace(
value='',
),
whitespace_after=SimpleWhitespace(
value='',
),
),
right=BinaryOperation(
left=Integer(
value='2',
lpar=[],
rpar=[],
),
operator=Power(
whitespace_before=SimpleWhitespace(
value='',
),
whitespace_after=SimpleWhitespace(
value='',
),
),
right=Integer(
value='4',
lpar=[],
rpar=[],
),
lpar=[],
rpar=[],
),
lpar=[],
rpar=[],
)
5. Význam mezijazyka v oblasti moderních překladačů
Moderní překladače se v některých ohledech liší od překladačů, které byly používány v šedesátých, sedmdesátých či osmdesátých letech minulého století. Původně byly překladače do značné míry specializované, protože podporovaly pouze jediný programovací jazyk a současně (většinou) produkovaly strojový kód určený pro jedinou platformu (CPU+operační systém). Taktéž optimalizace, pokud byly vůbec prováděny, byly z dnešního pohledu poměrně primitivní (výjimkou jsou ovšem překladače FORTRANu pro superpočítače). V současnosti je ovšem situace mnohem komplikovanější, protože se od překladačů očekává podpora většího množství programovacích jazyků nebo jeho dialektů, podpora pro více architektur CPU, ale například i to, že překladač bude provádět agresivní optimalizace, autovektorizaci kódu atd.
Ukazuje se, že tyto požadavky lze splnit rozdělením překladu na „přední“ a „zadní“ fázi. V první fázi je použit překladač konkrétního programovacího jazyka/jazyků (například Clang). Tento překladač vyprodukuje univerzální mezikód. Ten je následně optimalizován (mnohdy v několika průchodech) a výsledek je poslán do zadního překladače, který provede překlad na konkrétní platformu (CPU+operační systém) s provedením optimalizací použitelných právě pro tuto platformu. Mezijazyk, i když je pro mnoho vývojářů skrytý, je tak ústředním prvkem celého procesu. Mezikód resp. mezijazyk ovšem do značné míry ovlivňuje vlastnosti překladače (například to, do jaké míry dokáže pracovat s nedefinovaným chováním).
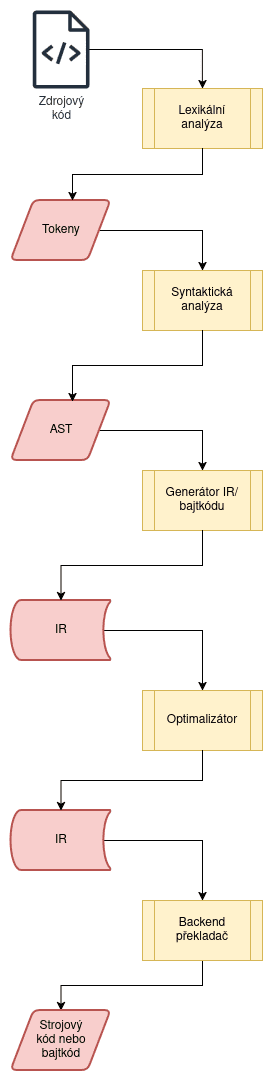
Obrázek 3: Některé moderní překladače provádí hned několik fází transformace mezikódu.
6. Mezijazyk vs bajtkód
Pojem mezijazyk nebo též mezikód je většinou používán v souvislosti se sofistikovanými překladači, které překlad provádí v několika fázích zmíněných v předchozím textu. Naproti tomu mnohé interpretry sice taktéž provádí překlad, ale výsledek se namísto mezijazyk/mezikód nazývá bajtkód. Po technologické stránce se mezijazyky a bajtkódy mohou do značné míry podobat, takže mnohdy význam obou termínů splývá. Typicky obě technologie musí dokázat reprezentovat sekvenci více či méně abstraktních instrukcí a navíc je nutné ukládat i metainformace (jména souborů, čísla řádků, přístupová práva k funkcím a metodám atd.). V operační paměti se v obou případech jedná o „netextové“ struktury. Samotný bajtkód je uložen do binárních souborů (mezikód se naproti tomu většinou na disk neukládá).
Nejprve se ve stručnosti seznámíme s historií používání bajtkódu, která je poměrně dlouhá a přitom i z programátorského hlediska zajímavá, protože úspěch mnoha programovacích jazyků vycházel mj. i z toho, že se díky použití bajtkódů (a s nimi souvisejících virtuálních strojů) mohly jejich překladače snadno a relativně rychle rozšiřovat na různé platformy a architektury počítačů (a to se v žádném případě netýká pouze Javy, jejíž bajtkód se rozšířil na prakticky všechny architektury, ale dříve například i Pascalu či BPCL, což je pradávný předchůdce rodiny jazyků C a C++).
Bajtkód je využíván především dvěma nástroji. Na jedné straně se jedná o překladač (například v případě Javy to může být překladač javac, API tohoto překladače dostupné v moderních JDK či interní překladač využívaný nějakým integrovaným vývojovým prostředím), který překládá zdrojový kód napsaný programátorem (či poloautomaticky vygenerovaný v IDE :-) do bajtkódu; což mj. znamená, že je překlad zcela nezávislý na použité platformě. Na straně druhé již jednou přeložený bajtkód využívá interpret či dnes již v mnoha případech spíše JIT (just in time) překladač. Ve skutečnosti však s bajtkódem může pracovat i mnoho dalších nástrojů. Příkladem ve světě Javy a bajtkódu JVM mohou být například nástroje typu Cobertura a EMMA sloužící pro zjištění, které části zdrojového kódu aplikací jsou pokryty (jednotkovými) testy. Tyto nástroje musí umět dobře kooperovat s virtuálním strojem Javy, proto nejprve modifikují bajtkódy testovaných tříd, aby bylo možné při běhu testů dynamicky zjistit, které řádky kódu jsou skutečně z testů volány.
Podobným způsobem je bajtkód modifikován nástroji podporujícími aspektově orientované programování (aspect oriented programming), které taktéž mohou zasahovat do bajtkódu vygenerovaného překladačem. Teoreticky je sice možné při použití aspektově orientovaného programování transformovat přímo zdrojové kódy programů (což je použito především v jiných programovacích jazycích), ale transformace bajtkódu je v případě Javy mnohem snazší. Ze stejného důvodu (analýza bajtkódu je jednodušší než analýza zdrojového textu) je bajtkód použit pro statickou analýzu a hledání potenciálních chyb nástrojem FindBugs.
7. Historie vývoje bajtkódu a jeho využití
Myšlenka na využití bajtkódu pro překlad a následnou interpretaci programů je v informatice úspěšně realizována a využívána již poměrně dlouhou dobu. Jedním z prvních známých a rozšířených bajtkódů byl bajtkód nazvaný OPCODE, který byl vyvinut pro potřeby programovacího jazyka BCPL. Jazyk BPCL (Basic Combined Programming Language), jenž byl vytvořen Martinem Richardsem již v roce 1966, je z hlediska historie výpočetní techniky důležitý především proto, že z něho Ken Thompson odvodil nový programovací jazyk nazvaný jednoduše B a z jazyka B se postupně vyvinulo klasické Céčko (nejdříve K&R C, posléze dodnes používané ANSI/ISO C následované C99, C11, C17, C23 a C2Y).
Výše zmíněný bajtkód OPCODE byl založen na instrukcích pracujících se zásobníkem operandů (operand stack, viz další kapitoly) a v práci s daty dostupnými přes indexové registry. Například výraz x / y + z se pro proměnné x, y a z uložené na pozicích 1, 2 a 10 přeložil do bajtkódu OPCODE následujícím způsobem, který se nápadně podobá bajtkódu JVM (což ostatně není náhoda, jak si řekneme dále):
LP 1 LP 2 DIV LP 10 PLUS
Popularita používání bajtkódu byla úzce spojena i s úspěšností takzvaného p-code, což byl (a ostatně stále ještě je) bajtkód využívaný některými překladači programovacího jazyka Pascal (to se ovšem netýká Turbo Pascalu, který se vydal vlastní značně odlišnou cestou). Díky využití p-code bylo snadnější portovat jak překladač Pascalu na různé platformy, tak i interpret vlastního p-kódu. Tento bajtkód je v současnosti ještě využíván na některých školách při výuce IT; mj. i z tohoto důvodu se jedná o stále živý projekt, o čemž ostatně mohou svědčit i stránky projektu UCSD p-system Virtual Machine dostupné na adrese http://ucsd-psystem-vm.sourceforge.net/.
Dále je na tomto místě vhodné zmínit bajtkód využívaný v ekosystému programovacího jazyka Smalltalk. Jedná se o poměrně vysokoúrovňový bajtkód, který se v některých ohledech přibližuje bajtkódu používaném Pythonem (posílání zpráv je v tomto případě velmi podobné volání virtuálních metod apod.). Mimochodem – velká část bajtkódu Smalltalku je reflexivně dostupná i z vlastního jazyka, viz například http://marianopeck.files.wordpress.com/2011/05/screen-shot-2011–05–21-at-6–51–24-pm.png.
8. Bajtkód pro zásobníkové vs. registrové virtuální stroje
Využívání bajtkódů má v současnosti za sebou zhruba čtyřicet let postupného vývoje, takže pravděpodobně nebude příliš překvapující, že za tuto (na IT) poměrně dlouhou dobu bylo navrženo a implementováno mnoho různých řešení virtuálního stroje+bajtkódu, která se od sebe v mnoha ohledech odlišovala, a to jak úrovní abstrakce bajtkódu (nízkoúrovňové instrukce dobře transformovatelné na strojový kód vs. vysokoúrovňové instrukce podporující například polymorfismus využívaný například virtuálním strojem Pythonu), tak i způsobem, jakým jednotlivé instrukce pracovaly s argumenty (resp. s operandy).
Naprostou většinu existujících a v současnosti používaných bajtkódů je možné rozdělit do dvou skupin. V první skupině se nachází bajtkódy zpracovávané virtuálními stroji založenými na zásobníku operandů (operand stack) a ve druhé skupině se nachází bajtkódy využívající sadu registrů (register set) nabízených virtuálním strojem (počet registrů může být buď omezen na několik jednotek až desítek registrů nebo naopak prakticky neomezen, takže se spíše jedná o paměť s izolovanými buňkami). Oba zmíněné přístupy mají své přednosti i zápory a taktéž skalní zastánce i odpůrce, jak je tomu ostatně v IT dobrým zvykem :-)
Bajtkódy a virtuální stroje využívající zásobník operandů a instrukce pro práci s argumenty uloženými na tomto zásobníku většinou obsahují mnoho bezparametrických instrukcí, jejichž operační kódy tak mohou být velmi krátké a typicky bývají uloženy v jediném bajtu (z toho také ostatně označení „bajtkód“ vychází). Interpretace takového bajtkódu bývá velmi jednoduchá a lze ji efektivně provádět i na těch mikroprocesorech, které obsahují velmi malé množství pracovních registrů, z čehož ostatně vyplývá i oblíbenost takto navržených bajtkódů v době osmibitových mikroprocesorů a mikrořadičů (poněkud speciálním případem je jazyk Forth).
Před přibližně dvaceti lety, kdy se ve větší míře začaly rozšiřovat JIT překladače, se předpokládalo, že nové JIT překladače budou mít problémy s překladem instrukcí založených na použití zásobníku operandů do strojového kódu moderních mikroprocesorů (ty mají většinou velkou sadu pracovních registrů), ovšem ukázalo se, že JIT dokáží bez větších problémů pracovat jak se zásobníkovými instrukcemi, tak i s instrukcemi využívajícími sadu pracovních registrů VM (viz například JIT v JVM).
Tím se pomalu dostáváme ke druhému rozšířenému typu bajtkódů. Jedná se o bajtkódy, jejichž instrukce dokážou pracovat s obsahem množiny pracovních registrů zvoleného virtuálního stroje. Délka instrukčního slova i možnosti takto navržených bajtkódů závisí především na počtu těchto pracovních registrů; v moderních VM se setkáme minimálně s použitím šestnácti či 32 registry, což znamená, že mnoho instrukcí má délku minimálně dva bajty, mnohdy i tři či čtyři bajty.
Liší se taktéž počet operandů instrukcí – některé bajtkódy využívají takzvaný dvouadresový kód (používají dva registry – jeden registr zdrojový a druhý registr současně zdrojový i cílový), jiné se zaměřují na tříadresový kód (dva zdrojové registry a jeden registr cílový). Způsob interpretace takto navržených bajtkódů může být problematičtější v případě, že mikroprocesor, na němž interpret běží, obsahuje menší množství fyzických pracovních registrů, ovšem (jak již bylo řečeno v předchozím odstavci), při použití JIT se rozdíly mezi oběma způsoby práce s operandy do značné míry rozostřují.
9. Praktická ukázka rozdílu mezi bajtkódem určeným pro zásobníkový a registrový virtuální stroj
Podívejme se nyní na dvě ukázky, ze kterých bude patrné, jak se může lišit bajtkód založený na zásobníkovém virtuálním stroji od bajtkódu, který je určen pro registrový virtuální stroj. V obou příkladech se má vyhodnotit jednoduchý výraz result = a+b*c-d; pro jednoduchost předpokládejme, že všech pět proměnných je lokálních a současně mají typ celé číslo (integer). Způsob překladu do bajtkódu využívajícího zásobník operandů (konkrétně je v tomto případě použit bajtkód JVM) může vypadat následovně:
; 0 je index proměnné a
; 1 je index proměnné b
; 2 je index proměnné c
; 3 je index proměnné d
; 4 je index proměnné result
0: iload 0 ; uložení obsahu proměnné a na zásobník
1: iload 1 ; uložení obsahu proměnné b na zásobník
2: iload 2 ; uložení obsahu proměnné c na zásobník
3: imul ; provedení operace b*c, výsledek je ponechán na zásobníku
4: iadd ; provedení operace a+(b*c)
5: iload 3 ; uložení obsahu proměnné d na zásobník
6: isub ; dokončit příkaz a+(b*c)+d
7: istore 4 ; uložení výsledku z TOS (obsah zásobníku operandů) do proměnné result
Příklad kompilace téhož příkazu result = a+b*c-d do bajtkódu využívajícího pracovní registry, konkrétně do bajtkódu využívaného programovacím jazykem Lua:
; 0 je index proměnné a
; 1 je index proměnné b
; 2 je index proměnné c
; 3 je index proměnné d
; 4 je index proměnné result
1 [101] MUL 4 1 2 ; přímé vynásobení obsahu proměnných b a c
2 [101] ADD 4 0 4 ; přičíst k obsahu proměnné a mezivýsledek, výsledek uložit do proměnné result
3 [101] SUB 4 4 3 ; odečíst od mezivýsledku obsah proměnné b, výsledek uložit do proměnné result
Ve druhém případě se nemusely vůbec použít instrukce pro uložení proměnných na zásobník ani pro načtení hodnoty zpět ze zásobníku operandů do proměnné, ovšem na druhou stranu musely mít všechny aritmetické instrukce v instrukčním slovu uloženy i indexy operandů.
LOAD_FAST_BORROW_LOAD_FAST_BORROW 1 (a, b) ; uložení dvou proměnných a a b na zásobník LOAD_FAST_BORROW 2 (c) ; uložení proměnné c na zásobník BINARY_OP 5 (*) ; provedení výpočtu b*c s uložením výsledku BINARY_OP 0 (+) ; provedení výpočtu a+b*c s uložením výsledku LOAD_FAST_BORROW 3 (d) ; uložení proměnné d na zásobník BINARY_OP 10 (-) ; provedení výpočtu a+b*c-d s uložením výsledku STORE_FAST 4 (result) ; výsledek je ze zásobníku umístěn do proměnné result
10. Bajtkód virtuálního stroje jazyka Java (JVM)
První typ v současnosti používaného bajtkódu, s nímž se v dnešním článku alespoň ve stručnosti seznámíme, je bajtkód využívaný v JVM (Java Virtual Machine). Virtuální stroj jazyka Java samozřejmě využívá jiný soubor „strojových“ instrukcí, než fyzický mikroprocesor, na němž jsou Javovské programy spouštěny. Dokonce ani mikroprocesory určené pro přímé spouštění bajtkódu – dnes již zpola zapomenuté projekty MicroJava a PicoJava, dokonce i ARM procesory s technologií Jazelle – nedokázaly nativně vykonávat všechny instrukce bajtkódu.
V prvních několika letech existence Javy byly instrukce bajtkódu (tvořící těla jednotlivých metod) v naprosté většině případů pouze interpretovány, a to mnohdy velmi jednoduchým způsobem: v programové smyčce se postupně načítaly kódy jednotlivých instrukcí a následně se pro každou instrukci zavolala nativní funkce, která danou instrukci vykonala, většinou s parametry uloženými na zásobníkovém rámci (stack frame) nebo v zásobníku operandů (bližší popis bude uveden v následujících kapitolách).
Naprogramování naivního interpretru pro bajtkód virtuálního stroje Javy ve skutečnosti není příliš složité, protože samotná instrukční sada je poměrně jednoduchá (resp. bývala jednoduchá). Moderní interpretry, například JamVM, jsou navíc naprogramovány takovým způsobem, aby byl jejich přenos na další procesorové architektury snadný a přitom se bajtkód interpretoval co nejefektivnějším způsobem, ideálně s ručně optimalizovanou vnitřní smyčkou (naprogramovanou v případě ručně prováděných optimalizací většinou v assembleru).
Ovšem i přes veškerou snahu programátorů interpretrů nemůže běh programů napsaných v Javě a spouštěných v JVM s interpretovaným bajtkódem v rychlosti soutěžit s nativními aplikacemi. Právě z tohoto důvodu vznikly takzvané just-in-time (JIT) překladače, které dokážou přeložit buď jen určitou sekvenci instrukcí JVM nebo i celý bajtkód do nativního strojového kódu, který je následně spuštěn. Některé JIT překladače, například stále populární HotSpot původně vyvinutý společností Sun Microsystems, používají adaptivní překlad, v němž je bajtkód analyzován v době běhu, takže má JIT překladač k dispozici mnohem více informací, než při statickém překladu. HotSpot navíc umožňuje pomocí takzvaný sond (probes sledovat, který kód je překládán a jaký typ překladu je přitom použit, to je však již poměrně pokročilá a nepříliš často používaná technologie. Ovšem nezávisle na tom, zda jsou instrukce JVM „pouze“ interpretovány, nebo je nejdříve použit JIT, musí být vždy dodrženy všechny vlastnosti jazyka Java i JVM. JIT například může odstranit kontrolu mezí při indexování polí, ale jen tehdy, když je zřejmé, že nedojde k překročení těchto mezí.
V této kapitole si ve stručnosti připomeneme základní vlastnosti bajtkódu virtuálního stroje Javy. Struktura i vlastnosti JVM jsou přesně popsány ve specifikaci JVM, včetně přesného formátu všech datových typů (znaků, celých čísel, čísel s plovoucí řádovou tečkou). Díky dodržování této specifikace různými výrobci virtuálního stroje Javy je zaručeno, že programy napsané v Javě jsou přenositelné na počítače s mnohdy velmi rozdílnou architekturou: od smartphonů s jednojádrovými mikroprocesory až po superpočítače s velkým množstvím výpočetních uzlů a mnohdy s několika desítkami tisíc procesorových jader. Různé nekompatibility, s nimiž programátoři bojovali především v minulosti (ale samozřejmě i dnes, i když v mnohem menší míře), bývají způsobeny buď chybami v implementaci některého virtuálního stroje (a nedodržení specifikace lze považovat za chybu) či nekompatibilitami ve standardních knihovnách, popř. chybami v nativních knihovnách, které lze z JVM volat.
Specifikace virtuálního stroje Javy popisuje některé jeho části velmi precizně (například se jedná o již zmíněné datové typy či o formát instrukcí nebo o strukturu zásobníkového rámce), ovšem u některých dalších částí jsou popsány jen základní vlastnosti a zůstává pouze na tvůrci konkrétní JVM, jakým způsobem se bude daná část virtuálního stroje ve skutečnosti implementovat. Asi nejtypičtějším příkladem je specifikace haldy (heap), u níž se sice předpokládá využití automatické správy paměti, ale nikde již není řečeno, jaký konkrétní algoritmus správy paměti se má použít (v současnosti se využívá hned několik algoritmů) ani jaký formát má být použit pro ukládání referencí na objekty. Díky tomu bylo možné Javu jednoduše přenést z původní 32bitové architektury jak na 16bitové procesory, tak i na procesory pracující s 64bitovými ukazateli (u nichž lze navíc v případě potřeby využít i komprimované ukazatele na objekty) – to vše bez nutnosti zásahu do zdrojových kódů Javovských programů i bez nutnosti jejich rekompilace.
Virtuální stroj jazyka Java obsahuje instrukce, které pracují s operandy několika datových typů. Na rozdíl od mnoha fyzických procesorů se v případě JVM provádí kontroly, zda jsou operace skutečně aplikovány na správné operandy. Není například možné, aby se operace součtu prováděla s jedním operandem typu int a druhým operandem typu long – takový bajtkód by byl při svém načítání odmítnut a vůbec by nebyl spuštěn (to však jinými slovy znamená, že bajtkód je zbytečně redundantní, zejména v porovnání s bajtkódy jazyků Lua a Python, v tomto ohledu se spíše blíží dále zmíněnému LLVM IR). Zajímavé je, že jen velmi málo instrukcí JVM podporuje práci s datovými typy boolean, byte, short a char. Proměnné a parametry metod těchto typů musí být například před provedením některé aritmetické operace nejprve převedeny na typ int pomocí konverzních instrukcí (těch existuje celkem patnáct).
Většina instrukcí virtuálního stroje Javy pracuje s operandy uloženými na takzvaném zásobníku operandů (operand stack). Zásobník operandů (v tomto případě se již jedná o skutečný zásobník typu LIFO – Last In, First Out) je vytvářen v čase běhu aplikace pro každou zavolanou metodu, což mj. znamená, že je při spuštění metody vždy prázdný (zásobník operandů je podle specifikace součástí zásobníkového rámce, jeho konkrétní umístění však je libovolné). Již v čase překladu zdrojového kódu je pro každou metodu zjištěno, jak velká oblast paměti má být pro zásobník operandů vyhrazena a samozřejmě je prováděna kontrola, zda se v době běhu aplikace tato velikost nepřekročí (to by se nemělo u validního bajtkódu stát).
Virtuální stroj Javy kontroluje typy operandů uložených na zásobník operandů a zajišťuje, že se nad těmito operandy budou provádět pouze typově bezpečné operace. V praxi to například znamená, že není možné na zásobník uložit dvě hodnoty typu float a následně provést instrukci iadd, protože tato instrukce vyžaduje, aby na zásobníku byly uloženy dvě hodnoty typu int (i když float i int mají shodnou bitovou šířku).
11. Příklady metod přeložených do bajtkódu JVM
Základní vlastnosti bajtkódu virtuálního stroje Javy si ukážeme na způsobu překladu testovací třídy obsahující několik statických metod. Tím, že jsou všechny testované metody statické, je zajištěno, že se jim nebude předávat další (ve zdrojovém kódu skrytý) parametr this, jiný významnější rozdíl mezi statickými a nestatickými metodami v bajtkódu nenajdeme.
První dvě metody nop1() a nop2() jsou bezparametrické, mají prázdné tělo a nevrací žádnou hodnotu, takže lze předpokládat, že jejich bajtkód bude velmi jednoduchý:
/**
* Prazdna metoda bez parametru.
*/
public static void nop1() {
}
/**
* Taktez prazdna metoda bez parametru.
*/
public static void nop2() {
return;
}
Další metoda, která se jmenuje answer(), je taktéž bezparametrická, ale vrací konstantní celočíselnou hodnotu 42:
/**
* Metoda bez parametru vracejici konstantu.
*/
public static int answer() {
return 42;
}
Následuje přetížená metoda add(), jejíž jednotlivé varianty akceptují různé celočíselné i reálné hodnoty; poslední varianta této metody spojuje řetězce (a to stejným operátorem +). Na příkladu metod add() si povšimněte toho, že operace + není pro datové typy byte a short uzavřena (výsledkem je hodnota typu int), což vychází z vlastností bajtkódu. Ostatně ani další aritmetické operace pro tyto datové typy taktéž nejsou uzavřeny:
/**
* Soucet dvou celych cisel typu short.
*/
public static short add(short x, short y) {
return (short)(x+y);
}
/**
* Soucet dvou celych cisel typu int.
*/
public static int add(int x, int y) {
return x+y;
}
/**
* Soucet dvou celych cisel typu long.
*/
public static long add(long x, long y) {
return x+y;
}
/**
* Soucet dvou celych cisel typu float.
*/
public static float add(float x, float y) {
return x+y;
}
/**
* Soucet dvou celych cisel typu double.
*/
public static double add(double x, double y) {
return x+y;
}
/**
* Spojeni dvou retezcu.
*/
public static String add(String x, String y) {
return x+y;
}
Následuje další testovací metoda pojmenovaná isNegative() obsahující podmíněný příkaz. Ten by zde ve skutečnosti nemusel být uveden, neboť celé tělo metody lze zkrátit do jediného výrazu, jehož výsledek by byl vracen příkazem return, ovšem my potřebujeme zjistit, jakým způsobem se do bajtkódu JVM překládají konstrukce typu if-then-else. Ve zdrojovém kódu metody fibonacciIter() jsou použity jak podmínky, tak i počítaná programová smyčka typu for a v poslední testované metodě fibonacciRecursive() je použita rekurze, tj. metoda přímo volá samu sebe. Podívejme se nyní na celý zdrojový kód testovací třídy::
/**
* Trida s nekolika jednoduchymi statickymi metodami
* pro otestovani zakladnich vlastnosti bajtkodu JVM.
*/
public class Test {
/**
* Prazdna metoda bez parametru.
*/
public static void nop1() {
}
/**
* Taktez prazdna metoda bez parametru.
*/
public static void nop2() {
return;
}
/**
* Metoda bez parametru vracejici konstantu.
*/
public static int answer() {
return 42;
}
/**
* Soucet dvou celych cisel typu byte.
*/
public static byte add(byte x, byte y) {
return (byte)(x+y);
}
/**
* Soucet dvou celych cisel typu short.
*/
public static short add(short x, short y) {
return (short)(x+y);
}
/**
* Soucet dvou celych cisel typu int.
*/
public static int add(int x, int y) {
return x+y;
}
/**
* Soucet dvou celych cisel typu long.
*/
public static long add(long x, long y) {
return x+y;
}
/**
* Soucet dvou celych cisel typu float.
*/
public static float add(float x, float y) {
return x+y;
}
/**
* Soucet dvou celych cisel typu double.
*/
public static double add(double x, double y) {
return x+y;
}
/**
* Spojeni dvou retezcu.
*/
public static String add(String x, String y) {
return x+y;
}
/**
* Metoda s podminkou.
*/
public static boolean isNegative(int x) {
if (x < 0) {
return true;
}
return false;
}
/**
* Metoda s podminkou a se smyckou.
*/
public static long fibonacciIter(int n) {
if (n <= 1) {
return n;
}
long result = 0;
long n1 = 0;
long n2 = 1;
for(n--; n > 0; n--) {
result = n1 + n2;
n1 = n2;
n2 = result;
}
return result;
}
/**
* Metoda s rekurzi.
*/
public static long fibonacciRecursive(int n) {
if (n <= 1) {
return n;
}
else {
return fibonacciRecursive(n-1) + fibonacciRecursive(n-2);
}
}
/**
* Vse je nutne otestovat.
*/
public static void main(String[] args) {
nop1();
nop2();
System.out.println(answer());
System.out.println(add((byte)1, (byte)2));
System.out.println(add((short)1, (short)2));
System.out.println(add(1, 2));
System.out.println(add(1L, 2L));
System.out.println(add(1f, 2f));
System.out.println(add(1., 2.));
System.out.println(add("Hello ", "world!"));
System.out.println(isNegative(-10));
for (int n=0; n <= 10; n++) {
System.out.println(n + "\t" + fibonacciIter(n) + "\t" + fibonacciRecursive(n));
}
}
}
Bajtkód přeložených metod je vypsán pod tímto odstavcem.
V metodě nop1() je použita pouze jediná instrukce return pro návrat z těla metody:
public static void nop1(); Code: 0: return ; pouze návrat z metody
Totéž platí pro metodu nop2():
public static void nop2(); Code: 0: return ; pouze návrat z metody
V metodě answer() je s využitím instrukce ireturn vrácena hodnota uložená na vrcholu zásobníku operandů (TOS):
public static int answer(); Code: 0: bipush 42 ; uložit na zásobník konstantu 42 2: ireturn ; výskok z metody s předáním návratové hodnoty
Metoda add() využívá pro typ byte automatický převod hodnotu argumentu či lokální proměnné na typ int, ovšem výsledek se musí zpětně konvertovat:
public static byte add(byte, byte); Code: 0: iload_0 ; uložit první parametr na zásobník (+ provést konverzi na int) 1: iload_1 ; uložit druhý parametr na zásobník (+ provést konverzi na int) 2: iadd ; provést součet 3: i2b ; zpětná konverze na byte 4: ireturn ; výskok z metody s předáním návratové hodnoty
Totéž platí v případě použití celočíselného datového typu short:
public static short add(short, short); Code: 0: iload_0 ; uložit první parametr na zásobník (+ provést konverzi na int) 1: iload_1 ; uložit druhý parametr na zásobník (+ provést konverzi na int) 2: iadd ; provést součet 3: i2s ; zpětná konverze na short 4: ireturn ; výskok z metody s předáním návratové hodnoty
Součet dvou čísel typu int s využitím zásobníku operandů je podporován přímo instrukcí bajtkódu:
public static int add(int, int); Code: 0: iload_0 ; uložit první parametr na zásobník 1: iload_1 ; uložit druhý parametr na zásobník 2: iadd ; provést součet 3: ireturn ; výskok z metody s předáním návratové hodnoty
Součet dvou čísel typu long s využitím zásobníku operandů je taktéž podporován přímo instrukcí bajtkódu:
public static long add(long, long); Code: 0: lload_0 ; uložit první parametr na zásobník 1: lload_2 ; uložit druhý parametr na zásobník 2: ladd ; provést součet 3: lreturn ; výskok z metody s předáním návratové hodnoty
Totéž platí pro argumenty či proměnné typu float:
public static float add(float, float); Code: 0: fload_0 ; uložit první parametr na zásobník 1: fload_1 ; uložit druhý parametr na zásobník 2: fadd ; provést součet 3: freturn ; výskok z metody s předáním návratové hodnoty
Totéž platí pro argumenty či proměnné typu double:
public static double add(double, double); Code: 0: dload_0 ; uložit první parametr na zásobník 1: dload_2 2: dadd ; provést součet 3: dreturn ; výskok z metody s předáním návratové hodnoty
Spojení dvou řetězců je naproti tomu realizováno přes instanci třídy StringBuilder a metody append(). Výsledek je nutné převést na řetězec metodou toString():
public static java.lang.String add(java.lang.String, java.lang.String);
Code:
; tato lokální proměnná se použije při spojování řetězců
0: new #2; //class java/lang/StringBuilder
3: dup
; zavolat konstruktor třídy StringBuilder
4: invokespecial #3; //Method java/lang/StringBuilder."init":()V
; zavolat metodu append() třídy StringBuilder pro první parametr
7: aload_0
8: invokevirtual #4; //Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
; zavolat metodu append() třídy StringBuilder pro druhý parametr
11: aload_1
12: invokevirtual #4; //Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
; zpětný převod na řetězec
15: invokevirtual #5; //Method java/lang/StringBuilder.toString:()Ljava/lang/String;
18: areturn ; výskok z metody s předáním návratové hodnoty
V metodě isNegative() je použita instrukce pro podmíněný skok ifge. Povšimněte si toho, že pravdivostní hodnoty jsou v bajtkódu reprezentovány celočíselnými konstantami 0 a 1:
public static boolean isNegative(int); Code: 0: iload_0 ; uložit parametr na zásobník 1: ifge 6 ; podmíněný skok na lokální adresu 6 při splnění podmínky 4: iconst_1 ; 1==true 5: ireturn ; výskok z metody s předáním návratové hodnoty true 6: iconst_0 ; 0==false 7: ireturn ; výskok z metody s předáním návratové hodnoty false
Nejsložitější je (podle očekávání) bajtkód metody fibonacciIter(), v níž je použito několika podmíněných skoků i jednoho skoku nepodmíněného:
public static long fibonacciIter(int); Code: 0: iload_0 ; uložit první parametr na zásobník 1: iconst_1 ; n se bude porovnávat s hodnotou 1 2: if_icmpgt 8; podmíněný skok na instrukci na indexu 8 5: iload_0 ; pro n menší nebo rovno 1 se vrátí přímo n 6: i2l ; konverze n na long 7: lreturn ; výskok z metody s předáním návratové hodnoty false 8: lconst_0 ; příprava pro zahájení počítané programové smyčky 9: lstore_1 10: lconst_0 11: lstore_3 12: lconst_1 13: lstore 5 15: iinc 0, -1 18: iload_0 ; zde začíná programová smyčka 19: ifle 39 ; test na ukončení programové smyčky 22: lload_3 23: lload 5 25: ladd 26: lstore_1 27: lload 5 29: lstore_3 30: lload_1 31: lstore 5 33: iinc 0, -1 36: goto 18 ; skok na začátek programové smyčky 39: lload_1 40: lreturn ; výskok z metody s předáním návratové hodnoty false
Bajtkód metody fibonacciRecursive() poměrně přesně odpovídá své zdrojové předloze:
public static long fibonacciRecursive(int);
Code:
0: iload_0 ; uložit první parametr na zásobník
1: iconst_1 ; n se bude porovnávat s hodnotou 1
2: if_icmpgt 8; podmíněný skok na instrukci na indexu 8
5: iload_0 ; pro n menší nebo rovno 1 se vrátí přímo n
6: i2l ; konverze n na long
7: lreturn ; výskok z metody s předáním návratové hodnoty false
8: iload_0
9: iconst_1
10: isub ; provedení operace n-1
; rekurzivní volání metody
11: invokestatic #6; //Method fibonacciRecursive:(I)J
14: iload_0
15: iconst_2
16: isub ; provedení operace n-2
; rekurzivní volání metody
17: invokestatic #6; //Method fibonacciRecursive:(I)J
20: ladd ; sečíst výsledek (návratovou hodnotu) obou rekurzivně volaných metod
21: lreturn ; výskok z metody s předáním návratové hodnoty false
12. Bajtkód využívaný interpretrem jazykem Lua
Dalším bajtkódem, s nímž se v dnešním článku alespoň ve stručnosti seznámíme, je bajtkód využívaný programovacím jazykem Lua. Bajtkód tohoto jazyka se v mnoha ohledech odlišuje od bajtkódu JVM. Pravděpodobně nejnápadnějším rozdílem mezi bajtkódem JVM a bajtkódem jazyka Lua je fakt, že se v Lua VM nepoužívá zásobník operandů, protože indexy operandů jsou přímo součástí instrukčního slova.
I formát instrukčních kódů je od JVM velmi odlišný, protože zatímco v případě bajtkódu JVM je kód instrukce uložen v celém bajtu (s několika málo výjimkami), je u Lua VM kód instrukce uložen v pouhých šesti bitech, zatímco zbylých 26 bitů instrukčního slova je rezervováno pro uložení indexů operandů či konstant. Bytekód Lua VM taktéž obsahuje spíše vysokoúrovňové instrukce, které dobře reflektují vlastnosti tohoto programovacího jazyka. Existují například instrukce pro implementaci programové smyčky for, instrukce pro práci s (asociativními) poli tvořícími nejdůležitější strukturovaný datový typ jazyka Lua a dokonce se v bajtkódu nachází instrukce pro vytvoření uzávěru (closure) a pro tail call.
Instrukce mohou mít jeden z následujících formátů:
iABC
| # | Označení | Délka bitového pole | Význam |
|---|---|---|---|
| 1 | i | 6 | kód instrukce |
| 2 | A | 8 | index či hodnota prvního operandu |
| 3 | B | 9 | index či hodnota druhého operandu |
| 4 | C | 9 | index či hodnota třetího operandu |
iABx
| # | Označení | Délka bitového pole | Význam |
|---|---|---|---|
| 1 | i | 6 | kód instrukce |
| 2 | A | 8 | index či hodnota prvního operandu |
| 3 | Bx | 18 | index či hodnota druhého operandu |
iAsBx
| # | Označení | Délka bitového pole | Význam |
|---|---|---|---|
| 1 | i | 6 | kód instrukce |
| 2 | A | 8 | index či hodnota prvního operandu |
| 3 | sBx | 18 | index či hodnota druhého operandu (zde se znaménkem) |
iAx
| # | Označení | Délka bitového pole | Význam |
|---|---|---|---|
| 1 | i | 6 | kód instrukce |
| 2 | Ax | 26 | index či hodnota prvního (jediného) operandu |
isJ
| # | Označení | Délka bitového pole | Význam |
|---|---|---|---|
| 1 | i | 5 | kód instrukce |
| 2 | sJ | 26 | cíl skoku |
| 3 | k | 1 | registr nebo konstanta |
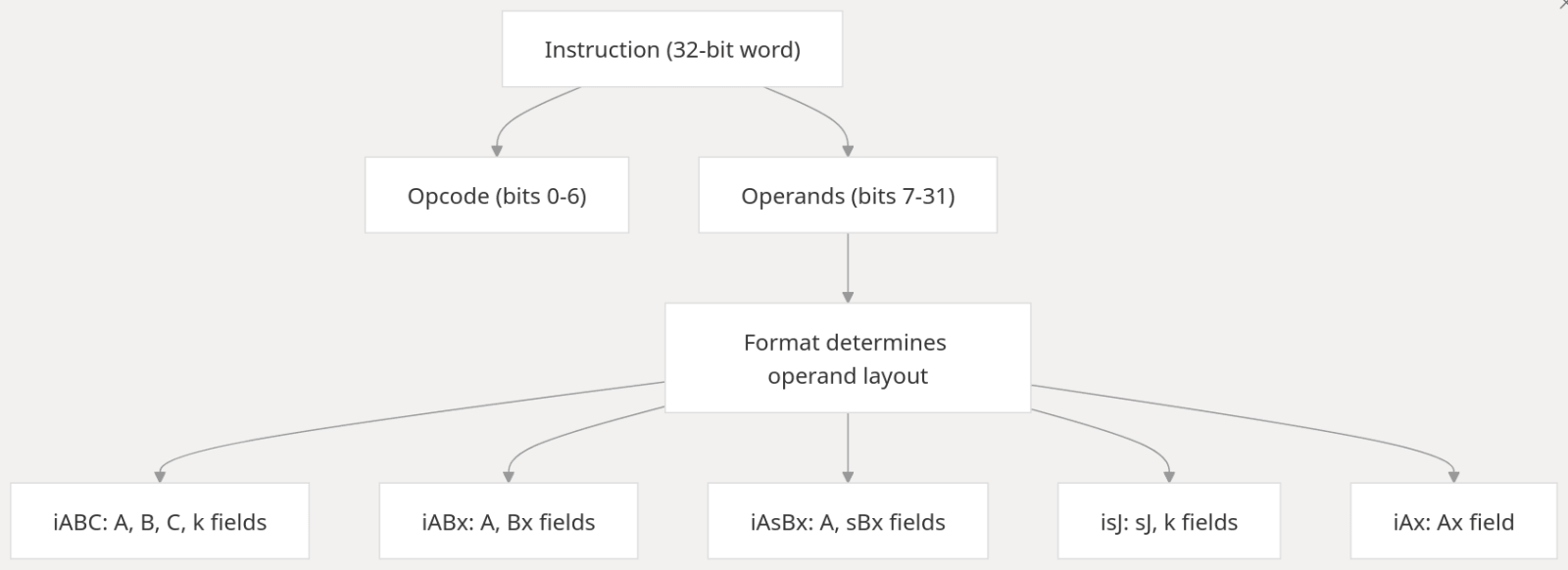
Obrázek 4: Různé instrukce podporované v bajtkódu jazyka Lua.
13. Příklady funkcí přeložených do bajtkódu jazyka Lua
Pro porovnání bajtkódů JVM a Lua VM vytvoříme sadu funkcí, které se do co největší míry podobají metodám použitým ve třídě Test1.java z předchozích kapitol. Jedním z velkých rozdílů mezi jazyky Java a Lua je dynamická povaha datových typů v Lue, což například znamená, že se původní přetížená metoda add() musí implementovat funkcí add() pro čísla a funkcí addStr() pro řetězce:
--
-- Modul s nekolika jednoduchymi funkcemi
-- pro otestovani zakladnich vlastnosti bajtkodu jazyka Lua
--
--
-- Prazdna funkce bez parametru.
--
function nop1()
end
--
-- Taktez prazdna funkce bez parametru.
--
function nop2()
return
end
--
-- Funkce bez parametru vracejici konstantu.
--
function answer()
return 42
end
--
-- Soucet dvou cisel.
--
function add(x, y)
return x+y
end
--
-- Spojeni dvou retezcu.
--
function addStr(x, y)
return x..y
end
--
-- Funkce s podminkou.
--
function isNegative(x)
if x < 0 then
return true
end
return false
end
--
-- Funkce s podminkou a se smyckou.
--
function fibonacciIter(n)
if n <= 1 then
return n
end
local result = 0
local n1 = 0
local n2 = 1
for i = n-1, 1, -1 do
result = n1 + n2
n1 = n2
n2 = result
end
return result
end
--
-- Funkce s rekurzi.
--
function fibonacciRecursive(n)
if n <= 1 then
return n
else
return fibonacciRecursive(n-1) + fibonacciRecursive(n-2)
end
end
--
-- Vse je nutne otestovat.
--
function main()
nop1()
nop2()
print(answer())
print(add(1, 2))
print(addStr("Hello ", "world!"))
print(isNegative(-10))
for n = 0, 10 do
print(n .. "\t" .. fibonacciIter(n) .. "\t" .. fibonacciRecursive(n))
end
end
main()
Podívejme se nyní na vygenerovaný bajtkód:
Funkce nop1() obsahuje pouze jedinou instrukci pro návrat z funkce. První a druhý parametr instrukce RETURN určuje, které registry budou použity pro návratové hodnoty (může jich být více):
function <Test.lua:9,10> (1 instruction at 0x90a7c88)
0 params, 2 slots, 0 upvalues, 0 locals, 0 constants, 0 functions
1 [10] RETURN 0 1
U funkce nop2() poněkud překvapivě narazíme na dvojici instrukcí RETURN, protože překladač provádí překlad bez optimalizací (což oceníme při ladění):
function <Test.lua:15,17> (2 instructions at 0x90a7de0)
0 params, 2 slots, 0 upvalues, 0 locals, 0 constants, 0 functions
1 [16] RETURN 0 1
2 [17] RETURN 0 1
Ve funkci answer() se vrací konstanta 42 a opět zde můžeme vidět automaticky vytvořenou koncovou instrukci RETURN (ve skutečnosti RETURN nil):
function <Test.lua:22,24> (3 instructions at 0x90a7f08)
0 params, 2 slots, 0 upvalues, 0 locals, 1 constant, 0 functions
1 [23] LOADK 0 -1 ; 42
2 [23] RETURN 0 2
3 [24] RETURN 0 1
Součet dvou parametrů předaných funkci add() je velmi jednoduchý – sečtou se hodnoty parametru číslo 0 s hodnotou parametru číslo 1, výsledek se uloží do registru 2, který je následně vrácen první instrukcí RETURN:
function <Test.lua:29,31> (3 instructions at 0x90a7d88)
2 params, 3 slots, 0 upvalues, 2 locals, 0 constants, 0 functions
1 [30] ADD 2 0 1
2 [30] RETURN 2 2
3 [31] RETURN 0 1
V bajtkódu nalezneme i instrukci pro konkatenaci řetězců:
function <Test.lua:36,38> (5 instructions at 0x90a8308)
2 params, 4 slots, 0 upvalues, 2 locals, 0 constants, 0 functions
1 [37] MOVE 2 0
2 [37] MOVE 3 1
3 [37] CONCAT 2 2 3
4 [37] RETURN 2 2
5 [38] RETURN 0 1
V bajtkódu funkce isNegative() si povšimněte způsobu načtení pravdivostních konstant do registru 1 i způsobu provedení podmíněného skoku:
function <Test.lua:43,48> (7 instructions at 0x90a8500)
1 param, 2 slots, 0 upvalues, 1 local, 1 constant, 0 functions
1 [44] LT 0 0 -1 ; - 0
2 [44] JMP 0 2 ; to 5
3 [45] LOADBOOL 1 1 0
4 [45] RETURN 1 2
5 [47] LOADBOOL 1 0 0
6 [47] RETURN 1 2
7 [48] RETURN 0 1
Bajtkód funkce fibonacciIter() je relativně krátký (zejména v porovnání s jeho variantou pro JVM), protože se zde využívají speciální instrukce FORPREP a FORLOOP, jimiž je implementována programová smyčka typu for:
function <Test.lua:53,69> (16 instructions at 0x90a7fa0)
1 param, 8 slots, 0 upvalues, 8 locals, 3 constants, 0 functions
1 [54] LE 0 0 -1 ; - 1
2 [54] JMP 0 1 ; to 4
3 [55] RETURN 0 2
4 [58] LOADK 1 -2 ; 0
5 [59] LOADK 2 -2 ; 0
6 [60] LOADK 3 -1 ; 1
7 [62] SUB 4 0 -1 ; - 1
8 [62] LOADK 5 -1 ; 1
9 [62] LOADK 6 -3 ; -1
10 [62] FORPREP 4 3 ; to 14
11 [63] ADD 1 2 3
12 [64] MOVE 2 3
13 [65] MOVE 3 1
14 [62] FORLOOP 4 -4 ; to 11
15 [68] RETURN 1 2
16 [69] RETURN 0 1
Způsob rekurzivního volání funkce si vyžádá podrobnější vysvětlení, které bude uvedeno příště:
function <Test.lua:74,80> (13 instructions at 0x90a87d8)
1 param, 4 slots, 1 upvalue, 1 local, 3 constants, 0 functions
1 [75] LE 0 0 -1 ; - 1
2 [75] JMP 0 2 ; to 5
3 [76] RETURN 0 2
4 [76] JMP 0 8 ; to 13
5 [78] GETTABUP 1 0 -2 ; _ENV "fibonacciRecursive"
6 [78] SUB 2 0 -1 ; - 1
7 [78] CALL 1 2 2
8 [78] GETTABUP 2 0 -2 ; _ENV "fibonacciRecursive"
9 [78] SUB 3 0 -3 ; - 2
10 [78] CALL 2 2 2
11 [78] ADD 1 1 2
12 [78] RETURN 1 2
13 [80] RETURN 0 1
Bajtkód používaný Lua VM je (alespoň podle mého názoru) nejenom čitelnější, ale i kratší, a to mj. i kvůli existenci specializovaných instrukcí pro implementaci programové smyčky for i díky existenci aritmetických a logických instrukcí využívajících tříadresový kód (není potřeba složitě manipulovat s hodnotami ukládanými na zásobník operandů).
14. Bajtkód využívaný jazykem Python
Posledním v současnosti používaným bajtkódem, o němž se v dnešním článku zmíníme, je bajtkód využívaný programovacím jazykem Python, konkrétně jeho původní verzí CPython (kromě tohoto bajtkódu lze najít i další bajtkódy Pythonu určené pro jiné VM, například Mamba atd.). Již v předchozích kapitolách jsme si řekli, že bajtkód JVM je poměrně nízkoúrovňový, zejména v porovnání s bajtkódem používaným v programovacím jazyku Lua (resp. přesněji řečeno virtuálním strojem tohoto jazyka). Totéž platí, a to dokonce ještě ve větší míře, i pro bajtkód jazyka Python. Ten je opět založen na zásobníku operandů, ovšem mnohé instrukce pracující s jedním či dvěma operandy (samozřejmě uloženými na zásobníku) ve skutečnosti mohou volat metody objektů a nikoli pouze provádět operace nad primitivními datovými typy. Platí to především pro všechny „aritmetické“ operace, například i pro operátor +, který se překládá do instrukce BINARY_ADD.
To například znamená, že se jednoduchá funkce add() se dvěma operandy:
def add(x, y):
return x+y
přeloží do následující čtveřice instrukcí bajtkódu:
add:
28 0 LOAD_FAST 0 (x)
3 LOAD_FAST 1 (y)
6 BINARY_ADD
7 RETURN_VALUE
Tuto funkci lze ovšem volat jak s číselnými parametry, tak i s řetězci, n-ticemi, seznamy či objekty s implementovanou metodou __add__, takže instrukce BINARY_ADD není zcela porovnatelná například s JVM instrukcemi iadd, ladd atd. operujícími pouze nad konkrétním primitivním datovým typem.:
print(add(1, 2))
print(add(1., 2))
print(add("Hello ", "world!"))
print(add([1,2,3], [4,5,6]))
print(add((1,2,3), (4,5,6)))
Kromě toho může bajtkód Pythonu obsahovat i instrukce pro snazší tvorbu smyček (BREAK_LOOP, CONTINUE_LOOP) i pro práci s kolekcemi (LIST_APPEND, MAP_ADD, BUILD_SLICE apod).
Podobně jako tomu bylo v případě Javy i programovacího jazyka Lua, i pro Python byla vytvořena demonstrační aplikace s funkcemi, které se snaží co nejvíce přiblížit původním zdrojovým kódům v Javě a Lue (právě proto zde nejsou použity některé pro Python typické idiomy). Podívejme se nejdříve na zdrojový kód tohoto příkladu, který ve své závěrečné části obsahuje funkci pro disassembling bajtkódu:
#
# Modul s nekolika jednoduchymi funkcemi
# pro otestovani zakladnich vlastnosti bajtkodu jazyka Python
#
#
# Prazdna funkce bez parametru.
#
def nop1():
pass
#
# Taktez prazdna funkce bez parametru.
#
def nop2():
return
#
# Funkce bez parametru vracejici konstantu.
#
def answer():
return 42
#
# Soucet dvou cisel.
#
def add(x, y):
return x+y
#
# Funkce s podminkou.
#
def isNegative(x):
if x < 0:
return True
return False
#
# Funkce s podminkou a se smyckou.
#
def fibonacciIter(n):
if n <= 1:
return n
result = 0
n1 = 0
n2 = 1
for i in xrange(n-1, 0, -1):
result = n1 + n2
n1 = n2
n2 = result
return result
#
# Funkce s rekurzi.
#
def fibonacciRecursive(n):
if n <= 1:
return n
else:
return fibonacciRecursive(n-1) + fibonacciRecursive(n-2)
#
# Vse je nutne otestovat.
#
def main():
nop1()
nop2()
print(answer())
print(add(1, 2))
print(add("Hello ", "world!"))
print(isNegative(-10))
for n in xrange(0,11):
print(str(n) + "\t" + str(fibonacciIter(n)) + "\t" + str(fibonacciRecursive(n)))
#main()
def disassemble():
from dis import dis
print("\nnop1:")
dis(nop1)
print("\nnop2:")
dis(nop2)
print("\nanswer:")
dis(answer)
print("\nadd:")
dis(add)
print("\nisNegative:")
dis(isNegative)
print("\nfibonacciIter:")
dis(fibonacciIter)
print("\nfibonacciRecursive:")
dis(fibonacciRecursive)
disassemble()
Opět se podívejme, jak bude vypadat bajtkód vygenerovaný překladačem Pythonu, resp. přesněji řečeno CPythonu:
Na překladu funkce nop1() pravděpodobně nenajdeme nic překvapivého:
nop1:
10 0 LOAD_CONST 0 (None)
3 RETURN_VALUE
Novější Python (3.13 a 3.14) ovšem provede překlad odlišně – bajtkód totiž obecně nemusí být přenositelný mezi různými verzemi Pythonu:
nop1: 9 RESUME 0 10 RETURN_CONST 0 (None)
Stejným způsobem je přeložena i funkce nop2(), což je pochopitelné:
nop2:
16 0 LOAD_CONST 0 (None)
3 RETURN_VALUE
V bajtkódu funkce answer() se na zásobník nejdříve uloží číselná konstanta 42, která je následně instrukcí RETURN_VALUE vrácena volající funkci:
answer:
22 0 LOAD_CONST 1 (42)
3 RETURN_VALUE
Bajtkód pro novější Python:
answer: 21 RESUME 0 22 RETURN_CONST 1 (42)
Ve funkci add() se používá instrukce BINARY_ADD, která však ve skutečnosti může pracovat nejenom s čísly, ale i s řetězci, n-ticemi apod., což je velký rozdíl oproti bajtkódu JVM, což jsme ostatně mohli vidět v předchozích kapitolách:
add:
28 0 LOAD_FAST 0 (x)
3 LOAD_FAST 1 (y)
6 BINARY_ADD
7 RETURN_VALUE
Novější verze bajtkódu obsahuje specifičtější instrukce:
add:
27 RESUME 0
28 LOAD_FAST_LOAD_FAST 1 (x, y)
BINARY_OP 0 (+)
RETURN_VALUE
V bajtkódu funkce isNegative() je zajímavá především kombinace instrukcí COMPARE_OP (s operandem <) a JUMP_IF_FALSE. Instrukce bajtkódu Pythonu evidentně nejsou pojmenovány s ohledem na jejich ruční zápis :-):
isNegative:
34 0 LOAD_FAST 0 (x)
3 LOAD_CONST 1 (0)
6 COMPARE_OP 0 (<)
9 JUMP_IF_FALSE 5 (to 17)
12 POP_TOP
35 13 LOAD_GLOBAL 0 (True)
16 RETURN_VALUE
>> 17 POP_TOP
36 18 LOAD_GLOBAL 1 (False)
21 RETURN_VALUE
I v bajtkódu funkce fibonacciIter() nalezneme dvojici instrukcí COMPARE_OP s JUMP_IF_FALSE. Kromě toho si povšimněte instrukce FOR_ITER, která pro zadaný iterátor uložený na zásobníku vytvoří základ pro programovou smyčku for:
fibonacciIter:
42 0 LOAD_FAST 0 (n)
3 LOAD_CONST 1 (1)
6 COMPARE_OP 1 (<=)
9 JUMP_IF_FALSE 5 (to 17)
12 POP_TOP
43 13 LOAD_FAST 0 (n)
16 RETURN_VALUE
>> 17 POP_TOP
45 18 LOAD_CONST 2 (0)
21 STORE_FAST 1 (result)
46 24 LOAD_CONST 2 (0)
27 STORE_FAST 2 (n1)
47 30 LOAD_CONST 1 (1)
33 STORE_FAST 3 (n2)
49 36 SETUP_LOOP 52 (to 91)
39 LOAD_GLOBAL 0 (xrange)
42 LOAD_FAST 0 (n)
45 LOAD_CONST 1 (1)
48 BINARY_SUBTRACT
49 LOAD_CONST 2 (0)
52 LOAD_CONST 3 (-1)
55 CALL_FUNCTION 3
58 GET_ITER
>> 59 FOR_ITER 28 (to 90)
62 STORE_FAST 4 (i)
50 65 LOAD_FAST 2 (n1)
68 LOAD_FAST 3 (n2)
71 BINARY_ADD
72 STORE_FAST 1 (result)
51 75 LOAD_FAST 3 (n2)
78 STORE_FAST 2 (n1)
52 81 LOAD_FAST 1 (result)
84 STORE_FAST 3 (n2)
87 JUMP_ABSOLUTE 59
>> 90 POP_BLOCK
54 >> 91 LOAD_FAST 1 (result)
94 RETURN_VALUE
Bajtkód vygenerovaný novější verzí Pythonu (3.13 a 3.14):
fibonacciIter:
41 RESUME 0
42 LOAD_FAST 0 (n)
LOAD_CONST 1 (1)
COMPARE_OP 58 (bool(<=))
POP_JUMP_IF_FALSE 2 (to L1)
43 LOAD_FAST 0 (n)
RETURN_VALUE
45 L1: LOAD_CONST 2 (0)
STORE_FAST 1 (result)
46 LOAD_CONST 2 (0)
STORE_FAST 2 (n1)
47 LOAD_CONST 1 (1)
STORE_FAST 3 (n2)
49 LOAD_GLOBAL 1 (xrange + NULL)
LOAD_FAST 0 (n)
LOAD_CONST 1 (1)
BINARY_OP 10 (-)
LOAD_CONST 2 (0)
LOAD_CONST 3 (-1)
CALL 3
GET_ITER
L2: FOR_ITER 11 (to L3)
STORE_FAST 4 (i)
50 LOAD_FAST_LOAD_FAST 35 (n1, n2)
BINARY_OP 0 (+)
STORE_FAST 1 (result)
51 LOAD_FAST 3 (n2)
STORE_FAST 2 (n1)
52 LOAD_FAST 1 (result)
STORE_FAST 3 (n2)
JUMP_BACKWARD 13 (to L2)
49 L3: END_FOR
POP_TOP
54 LOAD_FAST 1 (result)
RETURN_VALUE
V bajtkódu funkce fibonacciRecursive() si povšimněte zejména instrukce pojmenované LOAD_GLOBAL, kterou je možné využít pro uložení hodnoty globálního symbolu na zásobník:
fibonacciRecursive:
60 0 LOAD_FAST 0 (n)
3 LOAD_CONST 1 (1)
6 COMPARE_OP 1 (<=)
9 JUMP_IF_FALSE 5 (to 17)
12 POP_TOP
61 13 LOAD_FAST 0 (n)
16 RETURN_VALUE
>> 17 POP_TOP
63 18 LOAD_GLOBAL 0 (fibonacciRecursive)
21 LOAD_FAST 0 (n)
24 LOAD_CONST 1 (1)
27 BINARY_SUBTRACT
28 CALL_FUNCTION 1
31 LOAD_GLOBAL 0 (fibonacciRecursive)
34 LOAD_FAST 0 (n)
37 LOAD_CONST 2 (2)
40 BINARY_SUBTRACT
41 CALL_FUNCTION 1
44 BINARY_ADD
45 RETURN_VALUE
46 LOAD_CONST 0 (None)
49 RETURN_VALUE
15. Mezikódy používané v GCC
V ekosystému překladačů GCC se můžeme setkat s několika typy mezijazyků resp. mezikódu. Celý proces překladu je totiž rozdělen do mnoha fází a v každé fázi je možné si výsledek příslušné transformace prohlédnout, i když je nutné na tomto místě poznamenat, že (na rozdíl od dále zmíněného LLVM IR) jsou mezijazyky GCC považovány za interní záležitost překladače a nemusí tak být příliš stabilní (je tomu tak naschvál – aby se zamezilo využití/zneužití části GCC v komerčních překladačích). V každém případě se v moderním GCC setkáme s mezijazyky GIMPLE (GNU IMPLEmentation) a RTL (Register Transfer Language). Těmto mezijazykům bude věnován celý samostatný článek, ovšem v navazující kapitole si alespoň ve stručnosti ukážeme, jak mohou výsledky jednotlivých fází překladu vypadat v případě, že si vyžádáme jejich výpis (jedná se o operaci typu dump, ostatně přesně tak se jmenují i přepínače GCC, které výpis zajistí).
16. Překlad výpočtu do mezikódu GIMPLE a RTL
Překládat budeme dvojici funkcí, které provádí součet, součin a rozdíl celočíselných hodnot. První z těchto funkcí zpracovává hodnoty bez znaménka:
unsigned int addX(unsigned int a, unsigned int b, unsigned int c, unsigned int d) {
return a+b*c-d;
}
Druhá funkce zpracovává hodnoty se znaménkem (a přitom neřešení přetečení, což je nedefinovaná operace):
signed int addX(signed int a, signed int b, signed int c, signed int d) {
return a+b*c-d;
}
Výsledek transformace přes AST do mezijazyka GIMPLE dopadne takto:
unsigned int addX (unsigned int a, unsigned int b, unsigned int c, unsigned int d)
{
unsigned int D.2838;
_1 = b * c;
_2 = a + _1;
D.2838 = _2 - d;
return D.2838;
}
a:
int addX (int a, int b, int c, int d)
{
int D.2838;
_1 = b * c;
_2 = a + _1;
D.2838 = _2 - d;
return D.2838;
}
Překlad v pozdější fázi už vypadá odlišně:
unsigned int addX (unsigned int a, unsigned int b, unsigned int c, unsigned int d)
{
unsigned int D.2838;
unsigned int _1;
unsigned int _2;
unsigned int _7;
<bb 2> :
_1 = b_3(D) * c_4(D);
_2 = a_5(D) + _1;
_7 = _2 - d_6(D);
<bb 3> :
<L0>:
return _7;
}
Dtto pro druhou funkci:
int addX (int a, int b, int c, int d)
{
int D.2838;
int _1;
int _2;
int _7;
<bb 2> :
_1 = b_3(D) * c_4(D);
_2 = a_5(D) + _1;
_7 = _2 - d_6(D);
<bb 3> :
<L0>:
return _7;
}
Výstup do RTL používá LISPovskou notaci (RMS se nezapře):
(note 1 0 7 NOTE_INSN_DELETED)
(note 7 1 26 2 [bb 2] NOTE_INSN_BASIC_BLOCK)
(insn/f 26 7 27 2 (set (mem:DI (pre_dec:DI (reg/f:DI 7 sp)) [0 S8 A8])
(reg/f:DI 6 bp)) "add_unsigned.c":1:82 69 {*pushdi2_rex64}
(nil))
(insn/f 27 26 28 2 (set (reg/f:DI 6 bp)
(reg/f:DI 7 sp)) "add_unsigned.c":1:82 95 {*movdi_internal}
(nil))
(insn 28 27 29 2 (set (mem/v:BLK (scratch:DI) [0 A8])
(unspec:BLK [
(mem/v:BLK (scratch:DI) [0 A8])
] UNSPEC_MEMORY_BLOCKAGE)) "add_unsigned.c":1:82 1487 {*memory_blockage}
(nil))
(note 29 28 2 2 NOTE_INSN_PROLOGUE_END)
(insn 2 29 3 2 (set (mem/c:SI (plus:DI (reg/f:DI 6 bp)
(const_int -4 [0xfffffffffffffffc])) [1 a+0 S4 A32])
(reg:SI 5 di [ a ])) "add_unsigned.c":1:82 96 {*movsi_internal}
(nil))
(insn 3 2 4 2 (set (mem/c:SI (plus:DI (reg/f:DI 6 bp)
(const_int -8 [0xfffffffffffffff8])) [1 b+0 S4 A32])
(reg:SI 4 si [ b ])) "add_unsigned.c":1:82 96 {*movsi_internal}
(nil))
(insn 4 3 5 2 (set (mem/c:SI (plus:DI (reg/f:DI 6 bp)
(const_int -12 [0xfffffffffffffff4])) [1 c+0 S4 A32])
(reg:SI 1 dx [ c ])) "add_unsigned.c":1:82 96 {*movsi_internal}
(nil))
(insn 5 4 6 2 (set (mem/c:SI (plus:DI (reg/f:DI 6 bp)
(const_int -16 [0xfffffffffffffff0])) [1 d+0 S4 A32])
(reg:SI 2 cx [ d ])) "add_unsigned.c":1:82 96 {*movsi_internal}
(nil))
(note 6 5 9 2 NOTE_INSN_FUNCTION_BEG)
(insn 9 6 10 2 (set (reg:SI 0 ax [102])
(mem/c:SI (plus:DI (reg/f:DI 6 bp)
(const_int -8 [0xfffffffffffffff8])) [1 b+0 S4 A32])) "add_unsigned.c":2:15 96 {*movsi_internal}
(nil))
(insn 10 9 25 2 (parallel [
(set (reg:SI 0 ax [102])
(mult:SI (reg:SI 0 ax [102])
(mem/c:SI (plus:DI (reg/f:DI 6 bp)
(const_int -12 [0xfffffffffffffff4])) [1 c+0 S4 A32])))
(clobber (reg:CC 17 flags))
]) "add_unsigned.c":2:15 593 {*mulsi3_1}
(nil))
(insn 25 10 11 2 (set (reg:SI 1 dx [orig:98 _1 ] [98])
(reg:SI 0 ax [102])) "add_unsigned.c":2:15 96 {*movsi_internal}
(nil))
(insn 11 25 12 2 (set (reg:SI 0 ax [103])
(mem/c:SI (plus:DI (reg/f:DI 6 bp)
(const_int -4 [0xfffffffffffffffc])) [1 a+0 S4 A32])) "add_unsigned.c":2:13 96 {*movsi_internal}
(nil))
(insn 12 11 13 2 (parallel [
(set (reg:SI 0 ax [orig:99 _2 ] [99])
(plus:SI (reg:SI 0 ax [103])
(reg:SI 1 dx [orig:98 _1 ] [98])))
(clobber (reg:CC 17 flags))
]) "add_unsigned.c":2:13 283 {*addsi_1}
(expr_list:REG_EQUAL (plus:SI (reg:SI 1 dx [orig:98 _1 ] [98])
(mem/c:SI (plus:DI (reg/f:DI 19 frame)
(const_int -4 [0xfffffffffffffffc])) [1 a+0 S4 A32]))
(nil)))
(insn 13 12 21 2 (parallel [
(set (reg:SI 0 ax [orig:100 _7 ] [100])
(minus:SI (reg:SI 0 ax [orig:99 _2 ] [99])
(mem/c:SI (plus:DI (reg/f:DI 6 bp)
(const_int -16 [0xfffffffffffffff0])) [1 d+0 S4 A32])))
(clobber (reg:CC 17 flags))
]) "add_unsigned.c":2:17 389 {*subsi_1}
(nil))
(insn 21 13 30 2 (use (reg/i:SI 0 ax)) "add_unsigned.c":3:1 -1
(nil))
(note 30 21 31 2 NOTE_INSN_EPILOGUE_BEG)
(insn 31 30 32 2 (set (mem/v:BLK (scratch:DI) [0 A8])
(unspec:BLK [
(mem/v:BLK (scratch:DI) [0 A8])
] UNSPEC_MEMORY_BLOCKAGE)) "add_unsigned.c":3:1 1487 {*memory_blockage}
(nil))
(insn/f 32 31 33 2 (set (reg/f:DI 6 bp)
(mem:DI (post_inc:DI (reg/f:DI 7 sp)) [0 S8 A8])) "add_unsigned.c":3:1 77 {*popdi1}
(expr_list:REG_CFA_DEF_CFA (plus:DI (reg/f:DI 7 sp)
(const_int 8 [0x8]))
(nil)))
(jump_insn 33 32 34 2 (simple_return) "add_unsigned.c":3:1 1489 {simple_return_internal}
(nil)
-> simple_return)
(barrier 34 33 23)
(note 23 34 0 NOTE_INSN_DELETED)
Ještě si pokusme přeložit funkci pro výpočet Fibonacciho posloupnosti.
Původní zdrojový kód:
long fibonacciIter(int n) {
if (n <= 1) {
return n;
}
long result = 0;
long n1 = 0;
long n2 = 1;
for(n--; n > 0; n--) {
result = n1 + n2;
n1 = n2;
n2 = result;
}
return result;
}
Překlad do GIMPLE:
long int fibonacciIter(int n)
{
long int D.2844;
long int result;
long int n1;
long int n2;
if (n <= 1) goto <D.2842>; else goto <D.2843>;
<D.2842>:
D.2844 = (long int) n;
// predicted unlikely by early return (on trees) predictor.
return D.2844;
<D.2843>:
result = 0;
n1 = 0;
n2 = 1;
n = n + -1;
goto <D.2840>;
<D.2839>:
result = n1 + n2;
n1 = n2;
n2 = result;
n = n + -1;
<D.2840>:
if (n > 0) goto <D.2839>; else goto <D.2837>;
<D.2837>:
D.2844 = result;
return D.2844;
}
Po provedení optimalizací:
;; Function fibonacciIter (fibonacciIter, funcdef_no=0, decl_uid=2832, cgraph_uid=1, symbol_order=0)
long int fibonacciIter(int n)
{
long int n2;
long int n1;
long int result;
long int D.2844;
long int _5;
long int _11;
long int _16;
<bb 2> :
if (n_6(D) <= 1)
goto <bb 3>; [INV]
else
goto <bb 4>; [INV]
<bb 3> :
_16 = (long int) n_6(D);
// predicted unlikely by early return (on trees) predictor.
goto <bb 8>; [INV]
<bb 4> :
result_7 = 0;
n1_8 = 0;
n2_9 = 1;
n_10 = n_6(D) + -1;
goto <bb 6>; [INV]
<bb 5> :
result_12 = n1_3 + n2_4;
n1_13 = n2_4;
n2_14 = result_12;
n_15 = n_1 + -1;
<bb 6> :
# n_1 = PHI <n_10(4), n_15(5)>
# result_2 = PHI <result_7(4), result_12(5)>
# n1_3 = PHI <n1_8(4), n1_13(5)>
# n2_4 = PHI <n2_9(4), n2_14(5)>
if (n_1 > 0)
goto <bb 5>; [INV]
else
goto <bb 7>; [INV]
<bb 7> :
_11 = result_2;
<bb 8> :
# _5 = PHI <_16(3), _11(7)>
<L5>:
return _5;
}
17. LLVM IR
V závěru dnešního článku se ještě musíme zmínit o pravděpodobně největší konkurenci ke GCC. Je jím ekosystém postavený okolo projektu LLVM, kterému se budeme podrobněji věnovat v navazujícím článku. V LLVM je překlad rozdělen do většího množství fází. První fáze překladu jsou provedeny frontend překladači, mezi něž patří například Clang. A naopak závěrečné fáze překladu (cílené pro konkrétní operační systém a architekturu mikroprocesorů) jsou prováděny v backend překladači. Mezi těmito fázemi je překládaný program reprezentován v mezikódu/mezijazyku nazývaném LLVM IR (IR=Intermediate Representation). Ten se do určité míry podobá assemblerům RISCových mikroprocesorů, ovšem veškeré argumenty předávané do funkcí, lokální proměnné atd. jsou silně typované. Navíc je LLVM IR navržen takovým způsobem, aby umožňoval překlad pro všechny moderní typy mikroprocesorů a mikrořadičů.
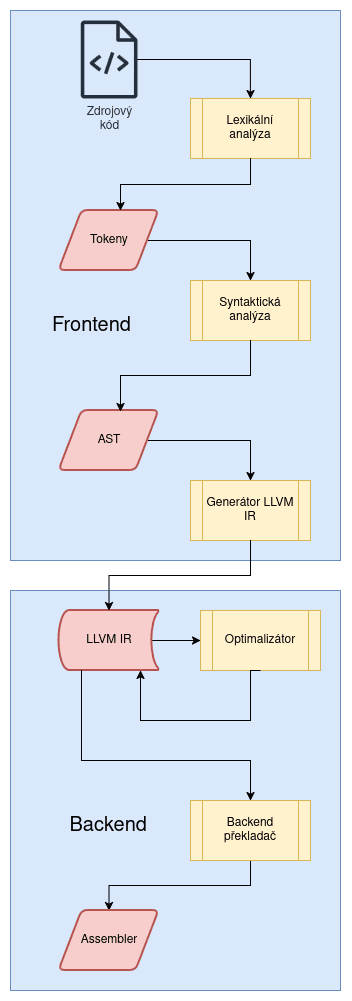
Obrázek 5: Fáze překladu v rodině Clang+LLVM s rozdělením na frontend a backend fáze. Uprostřed se nachází reprezentace založená na LLVM IR.
18. Překlad výpočtu do LLVM IR
Abychom si alespoň ve stručnosti přiblížili, jak LLVM IR vypadá, necháme si do něj přeložit funkci pro součet, součin a rozdíl celočíselných hodnot bez znaménka:
unsigned int addX(unsigned int a, unsigned int b, unsigned int c, unsigned int d) {
return a+b*c-d;
}
Příslušný soubor s výsledkem překladu do LLVM IR (pro architekturu x86–64 a se zapnutými optimalizacemi) bude mít tvar:
; ModuleID = 'add_unsigned.c'
source_filename = "add_unsigned.c"
target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-i128:128-f80:128-n8:16:32:64-S128"
target triple = "x86_64-redhat-linux-gnu"
; Function Attrs: mustprogress nofree norecurse nosync nounwind optsize willreturn memory(none) uwtable
define dso_local noundef i32 @addX(i32 noundef %0, i32 noundef %1, i32 noundef %2, i32 noundef %3) local_unnamed_addr #0 {
%5 = mul i32 %2, %1
%6 = add i32 %5, %0
%7 = sub i32 %6, %3
ret i32 %7
}
attributes #0 = { mustprogress nofree norecurse nosync nounwind optsize willreturn memory(none) uwtable "min-legal-vector-width"="0" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cmov,+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu"="generic" }
!llvm.module.flags = !{!0, !1}
!llvm.ident = !{!2}
!0 = !{i32 1, !"wchar_size", i32 4}
!1 = !{i32 7, !"uwtable", i32 2}
!2 = !{!"clang version 20.1.8 (Fedora 20.1.8-4.fc42)"}
Kromě mnoha dalších (meta)informací zde nalezneme i funkci přeloženou do mezikódu. Povšimněte si, že se jedná o kód, ve kterém zůstaly informace o datových typech parametrů i návratové hodnoty funkce:
define dso_local noundef i32 @addX(i32 noundef %0, i32 noundef %1, i32 noundef %2, i32 noundef %3) local_unnamed_addr #0 {
%5 = mul i32 %2, %1
%6 = add i32 %5, %0
%7 = sub i32 %6, %3
ret i32 %7
}
Zajímavěji dopadne překlad podobné funkce, ovšem zpracovávající celočíselné hodnoty se znaménkem:
signed int addX(signed int a, signed int b, signed int c, signed int d) {
return a+b*c-d;
}
Výsledek překladu do LLVM IR:
; ModuleID = 'add_signed.c'
source_filename = "add_signed.c"
target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-i128:128-f80:128-n8:16:32:64-S128"
target triple = "x86_64-redhat-linux-gnu"
; Function Attrs: mustprogress nofree norecurse nosync nounwind optsize willreturn memory(none) uwtable
define dso_local i32 @addX(i32 noundef %0, i32 noundef %1, i32 noundef %2, i32 noundef %3) local_unnamed_addr #0 {
%5 = mul nsw i32 %2, %1
%6 = add nsw i32 %5, %0
%7 = sub i32 %6, %3
ret i32 %7
}
attributes #0 = { mustprogress nofree norecurse nosync nounwind optsize willreturn memory(none) uwtable "min-legal-vector-width"="0" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cmov,+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu"="generic" }
!llvm.module.flags = !{!0, !1}
!llvm.ident = !{!2}
!0 = !{i32 1, !"wchar_size", i32 4}
!1 = !{i32 7, !"uwtable", i32 2}
!2 = !{!"clang version 20.1.8 (Fedora 20.1.8-4.fc42)"}
Mohlo by se zdát, že výsledné pseudoinstrukce jsou prakticky totožné, ale povšimněte si slov nsw. V tomto konkrétním případě to znamená, že pokud dojde k přetečení výsledku operace, je výsledek obecně nedefinovaný (undefined behaviour) a tudíž má backend překladač velkou volnost při optimalizacích a generování výsledného strojového kódu:

define dso_local i32 @add(i32 noundef %0, i32 noundef %1, i32 noundef %2, i32 noundef %3) local_unnamed_addr #0 {
%5 = mul nsw i32 %2, %1
%6 = add nsw i32 %5, %0
%7 = sub i32 %6, %3
ret i32 %7
}
Překlad funkce pro výpočet Fibonacciho posloupnosti do LLVM IR:
; ModuleID = 'fibonacci.c'
source_filename = "fibonacci.c"
target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-i128:128-f80:128-n8:16:32:64-S128"
target triple = "x86_64-redhat-linux-gnu"
; Function Attrs: nofree norecurse nosync nounwind optsize memory(none) uwtable
define dso_local i64 @fibonacciIter(i32 noundef %0) local_unnamed_addr #0 {
%2 = icmp slt i32 %0, 2
br i1 %2, label %3, label %5
3: ; preds = %1
%4 = sext i32 %0 to i64
br label %12
5: ; preds = %1, %5
%6 = phi i64 [ %10, %5 ], [ 1, %1 ]
%7 = phi i64 [ %6, %5 ], [ 0, %1 ]
%8 = phi i32 [ %9, %5 ], [ %0, %1 ]
%9 = add nsw i32 %8, -1
%10 = add nsw i64 %6, %7
%11 = icmp samesign ugt i32 %8, 2
br i1 %11, label %5, label %12, !llvm.loop !3
12: ; preds = %5, %3
%13 = phi i64 [ %4, %3 ], [ %10, %5 ]
ret i64 %13
}
attributes #0 = { nofree norecurse nosync nounwind optsize memory(none) uwtable "min-legal-vector-width"="0" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cmov,+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu"="generic" }
!llvm.module.flags = !{!0, !1}
!llvm.ident = !{!2}
!0 = !{i32 1, !"wchar_size", i32 4}
!1 = !{i32 7, !"uwtable", i32 2}
!2 = !{!"clang version 20.1.8 (Fedora 20.1.8-4.fc42)"}
!3 = distinct !{!3, !4}
!4 = !{!"llvm.loop.mustprogress"}
19. Obsah navazujícího článku
V dnešním článku byly popsány různé technologie a postupy, které jsou využívané různými typy překladačů a interpretrů. Jelikož se jednotlivé technologie od sebe mnohdy značně odlišují, nebylo je možné popsat podrobněji. Z tohoto důvodu se v navazujícím článku zaměříme pouze na jediný překladač, a to konkrétně na Clang a LLVM. Popíšeme si zejména mezijazyk LLVM IR, který je navržen takovým způsobem, aby na jedné straně dokázal s rozumnou úrovní abstrakce popsat zdrojové kódy zapisované v různých programovacích jazycích a na straně druhé aby ho bylo možné použít pro vygenerování spustitelného strojového kódu pro různé platformy, a to včetně těch platforem, které podporují pokročilé SIMD operace a popř. i souběh různých částí kódu běžících v odlišných vláknech. Jak v článku uvidíme, je LLVM IR sice zpočátku poměrně nečitelný, ale po krátkém zaučení umožňuje sledovat fáze překladu, použité optimalizační metody atd.
20. Odkazy na Internetu
- Is intermediate representation (such as bytecodes or .net IL) still an advantage?
https://stackoverflow.com/questions/35061333/is-intermediate-representation-such-as-bytecodes-or-net-il-still-an-advantage - Intermediate Representation vs Byte Code
https://cs.stackexchange.com/questions/163398/intermediate-representation-vs-byte-code - Getting the intermediate representation in gcc
https://forum.osdev.org/viewtopic.php?t=22845&sid=11f6e77d24bda7fcc2c9ef6a5be4e6b2 - Intermediate Representations
https://www.cs.cornell.edu/courses/cs4120/2023sp/notes/ir/ - Why do we use intermediate representations / languages?
https://mortoray.com/why-we-use-intermediate-representations/ - Unwrapping intermediate representations
https://mortoray.com/unwrapping-intermediate-representations/ - Understanding Python Code Flow From Source to Execution
https://medium.com/@azan96593/understanding-python-code-flow-from-source-to-execution-ebeea870ef83 - Why most compilers use AST, instead generate IR directly?
https://stackoverflow.com/questions/60870622/why-most-compilers-use-ast-instead-generate-ir-directly#60902159 - A Gentle Introduction to LLVM IR
https://mcyoung.xyz/2023/08/01/llvm-ir/ - Why does the compiler need the intermediate representations for link time optimization?
https://stackoverflow.com/questions/75586563/why-does-the-compiler-need-the-intermediate-representations-for-link-time-optimi - pyrefact na PyPi
https://pypi.org/project/pyrefact/ - Repositář projektu pyrefact
https://github.com/OlleLindgren/pyrefact - pyrefact jako plugin do VSCode
https://marketplace.visualstudio.com/items?itemName=olleln.pyrefact - pyrefact-vscode-extension (repositář)
https://github.com/OlleLindgren/pyrefact-vscode-extension - Best Python Refactoring Tools for 2023
https://www.developer.com/languages/python/best-python-refactoring-tools/ - Python Refactoring: Techniques, Tools, and Best Practices
https://www.codesee.io/learning-center/python-refactoring - Lexikální a syntaktická analýza zdrojových kódů programovacího jazyka Python
https://www.root.cz/clanky/lexikalni-a-syntakticka-analyza-zdrojovych-kodu-programovaciho-jazyka-python/ - Lexikální a syntaktická analýza zdrojových kódů programovacího jazyka Python (2.část)
https://www.root.cz/clanky/lexikalni-a-syntakticka-analyza-zdrojovych-kodu-programovaciho-jazyka-python-2-cast/ - Lexikální a syntaktická analýza zdrojových kódů programovacího jazyka Python (3.část)
https://www.root.cz/clanky/lexikalni-a-syntakticka-analyza-zdrojovych-kodu-programovaciho-jazyka-python-3-cast/ - Lexikální a syntaktická analýza zdrojových kódů jazyka Python (4.část)
https://www.root.cz/clanky/lexikalni-a-syntakticka-analyza-zdrojovych-kodu-jazyka-python-4-cast/ - Knihovna LibCST umožňující snadnou modifikaci zdrojových kódů Pythonu
https://www.root.cz/clanky/knihovna-libcst-umoznujici-snadnou-modifikaci-zdrojovych-kodu-pythonu/ - LibCST – dokumentace
https://libcst.readthedocs.io/en/latest/index.html - libCST na PyPi
https://pypi.org/project/libcst/ - libCST na GitHubu
https://github.com/Instagram/LibCST - Inside The Python Virtual Machine
https://leanpub.com/insidethepythonvirtualmachine - module-py_compile
https://docs.python.org/3.8/library/py_compile.html - Given a python .pyc file, is there a tool that let me view the bytecode?
https://stackoverflow.com/questions/11141387/given-a-python-pyc-file-is-there-a-tool-that-let-me-view-the-bytecode - The structure of .pyc files
https://nedbatchelder.com/blog/200804/the_structure_of_pyc_files.html - Python Bytecode: Fun With Dis
http://akaptur.github.io/blog/2013/08/14/python-bytecode-fun-with-dis/ - Python's Innards: Hello, ceval.c!
http://tech.blog.aknin.name/category/my-projects/pythons-innards/ - Golang Compilation and Execution
https://golangtutorial.com/golang-compilation-and-execution/ - Mezijazyk (Wikipedie)
https://cs.wikipedia.org/wiki/Mezijazyk - The LLVM Compiler Infrastructure
https://www.llvm.org/ - GCC internals
https://gcc.gnu.org/onlinedocs/gccint/index.html - GCC Developer Options
https://gcc.gnu.org/onlinedocs/gcc/Developer-Options.html - What is Gimple?
https://mschiralli1.wordpress.com/2024/12/01/what-is-gimple/ - The Conceptual Structure of GCC
https://www.cse.iitb.ac.in/grc/intdocs/gcc-conceptual-structure.html - Open Source ByteCode Libraries in Java
http://java-source.net/open-source/bytecode-libraries - ASM Home page
http://asm.ow2.org/ - Seznam nástrojů využívajících projekt ASM
http://asm.ow2.org/users.html - ObjectWeb ASM (Wikipedia)
http://en.wikipedia.org/wiki/ObjectWeb_ASM - Java Bytecode BCEL vs ASM
http://james.onegoodcookie.com/2005/10/26/java-bytecode-bcel-vs-asm/ - BCEL Home page
http://commons.apache.org/bcel/ - Byte Code Engineering Library (před verzí 5.0)
http://bcel.sourceforge.net/ - Byte Code Engineering Library (verze >= 5.0)
http://commons.apache.org/proper/commons-bcel/ - BCEL Manual
http://commons.apache.org/bcel/manual.html - Byte Code Engineering Library (Wikipedia)
http://en.wikipedia.org/wiki/BCEL - BCEL Tutorial
http://www.smfsupport.com/support/java/bcel-tutorial!/ - Bytecode Engineering
http://book.chinaunix.net/special/ebook/Core_Java2_Volume2AF/0131118269/ch13lev1sec6.html - Bytecode Outline plugin for Eclipse (screenshoty + info)
http://asm.ow2.org/eclipse/index.html - Javassist
http://www.jboss.org/javassist/ - Byteman
http://www.jboss.org/byteman - Java programming dynamics, Part 7: Bytecode engineering with BCEL
http://www.ibm.com/developerworks/java/library/j-dyn0414/ - The JavaTM Virtual Machine Specification, Second Edition
http://java.sun.com/docs/books/jvms/second_edition/html/VMSpecTOC.doc.html - The class File Format
http://java.sun.com/docs/books/jvms/second_edition/html/ClassFile.doc.html - javap – The Java Class File Disassembler
http://docs.oracle.com/javase/1.4.2/docs/tooldocs/windows/javap.html - javap-java-1.6.0-openjdk(1) – Linux man page
http://linux.die.net/man/1/javap-java-1.6.0-openjdk - Using javap
http://www.idevelopment.info/data/Programming/java/miscellaneous_java/Using_javap.html - Examine class files with the javap command
http://www.techrepublic.com/article/examine-class-files-with-the-javap-command/5815354 - Abstract syntax tree
https://en.wikipedia.org/wiki/Abstract_syntax_tree - Lexical analysis
https://en.wikipedia.org/wiki/Lexical_analysis - Parser
https://en.wikipedia.org/wiki/Parsing#Parser - Parse tree
https://en.wikipedia.org/wiki/Parse_tree - Derivační strom
https://cs.wikipedia.org/wiki/Deriva%C4%8Dn%C3%AD_strom - Python doc: ast — Abstract Syntax Trees
https://docs.python.org/3/library/ast.html - Python doc: tokenize — Tokenizer for Python source
https://docs.python.org/3/library/tokenize.html - SymbolTable
https://docs.python.org/3.8/library/symtable.html - 5 Amazing Python AST Module Examples
https://www.pythonpool.com/python-ast/ - Intro to Python ast Module
https://medium.com/@wshanshan/intro-to-python-ast-module-bbd22cd505f7 - Golang AST Package
https://golangdocs.com/golang-ast-package - AP8, IN8 Regulární jazyky
http://statnice.dqd.cz/home:inf:ap8 - AP9, IN9 Konečné automaty
http://statnice.dqd.cz/home:inf:ap9 - AP10, IN10 Bezkontextové jazyky
http://statnice.dqd.cz/home:inf:ap10 - AP11, IN11 Zásobníkové automaty, Syntaktická analýza
http://statnice.dqd.cz/home:inf:ap11 - Introduction to YACC
https://www.geeksforgeeks.org/introduction-to-yacc/ - Introduction of Lexical Analysis
https://www.geeksforgeeks.org/introduction-of-lexical-analysis/?ref=lbp - Write your own filter
http://pygments.org/docs/filterdevelopment/ - Write your own lexer
http://pygments.org/docs/lexerdevelopment/ - Write your own formatter
http://pygments.org/docs/formatterdevelopment/ - Compiler Construction/Lexical analysis
https://en.wikibooks.org/wiki/Compiler_Construction/Lexical_analysis - Compiler Design – Lexical Analysis
https://www.tutorialspoint.com/compiler_design/compiler_design_lexical_analysis.htm - Lexical Analysis – An Intro
https://www.scribd.com/document/383765692/Lexical-Analysis - Python AST Visualizer
https://github.com/pombredanne/python-ast-visualizer - What is an Abstract Syntax Tree
https://blog.bitsrc.io/what-is-an-abstract-syntax-tree-7502b71bde27 - Why is AST so important
https://medium.com/@obernardovieira/why-is-ast-so-important-b1e7d6c29260 - Emily Morehouse-Valcarcel – The AST and Me – PyCon 2018
https://www.youtube.com/watch?v=XhWvz4dK4ng - Python AST Parsing and Custom Linting
https://www.youtube.com/watch?v=OjPT15y2EpE - Chase Stevens – Exploring the Python AST Ecosystem
https://www.youtube.com/watch?v=Yq3wTWkoaYY - Full Grammar specification
https://docs.python.org/3/reference/grammar.html - Playing with GCC’s GIMPLE: How to Generate, Save, and Modify Intermediate Code (Tutorial + Examples)
https://www.tutorialpedia.org/blog/playing-with-gcc-s-intermediate-gimple-format/

































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU
{kind=link}