Obsah
1. Projekt Numba aneb další přístup k překladu Pythonu do nativního kódu
2. Princip činnosti Numba při překladu
4. Kontrola korektní instalace
5. Označení funkcí, které se mají překládat JITem
6. Testovací benchmark (dnes již naposledy)
7. Výsledky benchmarku při lineárním zvyšování složitosti výpočtu
9. Použití zjednodušené varianty funkce print
10. Vynucení úplného překladu anotací @jit(nopython=True)
11. Porovnání výsledků benchmarků (pouze Numba)
12. Porovnání s benchmarkem naprogramovaným v optimalizovaném Cythonu a ANSI C
13. Graf s výsledky všech benchmarků a zhodnocení výsledků
14. Explicitně zapsané informace o typech (typové signatury)
17. Repositář s demonstračními příklady a výsledky benchmarků
1. Projekt Numba aneb další přístup k překladu Pythonu do nativního kódu
V předchozích třech článcích vydaných na serveru Root [1], [2], [3] jsme se ve stručnosti seznámili s projekty nazvanými RPython a Cython. Oba projekty mají podobné cíle – dokážou ze zdrojového kódu, který je buď podmnožinou (RPython) nebo naopak nadmnožinou (Cython) programovacího jazyka Python vygenerovat nativní (strojový) kód, který ve většině případů běží rychleji, než je tomu při použití klasického interpretu Pythonu, ať již se jedná o CPython (dnes asi nejčastěji používaný), Jython nebo v menší míře o Iron Python. Nástroj RPython je součástí projektu PyPy a jeho použití je do větší míry orientováno na autory interpretrů a překladačů než na běžné vývojáře (na což jsou ostatně programátoři několikrát upozorněni přímo v dokumentaci).
Liší se však způsob vlastní implementace překladu do nativního kódu. Projekt RPython je založený na analýze AST (Abstract Syntax Tree) vytvořeného z bajtkódu samotným interpretrem. Z AST se odvozuje CFG a proto RPython navíc vyžaduje použití podmnožiny Pythonu. Je tomu tak z toho důvodu, aby RPython dokázal správně odvodit datové typy proměnných a argumentů funkcí/metod, a to již v čase překladu, tj. v compile time. Nástroj Cython naproti tomu pracuje poněkud odlišně – transformuje zdrojový kód z Pythonu do programovacího jazyka C a používá přitom informace o typech dodaných přímo vývojářem do zdrojového kódu (ten má tradičně koncovku „.pyx“ a nikoli „.py“). V místech, kde není typ zřejmý, se používá univerzální typ PyObject *, podobně jako v klasickém interpretru. Záleží tedy jen na vývojáři, kterou část kódu bude chtít optimalizovat a které tedy bude věnovat větší péči (při deklaraci typů).
Dnes se zaměříme především na porovnání výsledků benchmarků, ale další článek se bude podrobněji věnovat jak způsobu práce JITu, tak i kooperaci s LLVM (což je velmi pěkný a potenciálně mocný projekt). Taktéž si ukážeme využití AOT, tj. překladu do nativního kódu ještě před spuštěním aplikace, i když tento způsob není tak elegantní jako přímé použití JITu.
2. Princip činnosti Numba při překladu
Princip činnosti nástroje Numba se v několika ohledech odlišuje od RPythonu ale i od Cythonu. Numba totiž umožňuje překlad kódu za běhu aplikace, tj. v runtime. Jedná se tedy o JIT neboli o just-in-time překladač, který má tu výhodu, že dokáže odvodit datové typy proměnných a argumentů funkcí na základě skutečného chování aplikace. To samozřejmě neznamená, že by JIT již při prvním volání funkce přesně věděl, jak má funkci přeložit. Ve skutečnosti se dozví pouze informace o jediné konkrétní větvi, kterou může přeložit. V případě, že bude ta samá funkce později volána s odlišnými typy parametrů, popř. se její chování změní jiným způsobem (Python je velmi dynamický jazyk), provede se just-in-time překlad znovu, takže zde zaplatíme za vyšší výpočetní výkon poněkud většími paměťovými nároky a pomalejším během prvních volání funkce.
Z pohledu běžného vývojáře je největší předností tohoto způsobu překladu fakt, že není zapotřebí samotný zdrojový kód měnit (až na uvedení anotace před funkci). Nepříjemný je přesun času překladu do runtime, což sice nevadí u aplikací, které běží delší dobu, ovšem u jednorázových skriptů může být použití JITu spíše kontraproduktivní. To ostatně uvidíme i na demonstračním příkladu.
Samotný překlad je prováděn na několika úrovních, přičemž Numby na nižších úrovních využívá možností nabízených LLVM. Jedná se o relativně složitou problematiku, které se budeme věnovat v samostatném článku.
Existuje i alternativní způsob překladu, takzvaný AOT (ahead-of-time) překlad, který ovšem vyžaduje informovat Numbu o datových typech parametrů a proměnných, podobně jako je tomu v Cythonu (ovšem syntaxe zápisu je odlišná a pravděpodobně se prozatím nebude sjednocovat). Touto problematikou se budeme zabývat v samostatném článku (a nutno říci, že výhodou Numby je přece jen spíše JIT, než AOT).
3. Instalace nástroje Numba
V současnosti existuje hned několik možností, jak projekt Numba nainstalovat. Pravděpodobně nejjednodušší je použití pip neboli Python installeru a instalace Numby pouze pro lokálního (přihlášeného) uživatele:
$ pip3 install --user numba
Collecting numba
Downloading https://files.pythonhosted.org/packages/1e/74/bcf00816aa212e1439709f88b4e62519b60c89e18eb9f9f67e7d02ab4461/numba-0.38.1-cp36-cp36m-manylinux1_x86_64.whl (1.9MB)
100% |████████████████████████████████| 1.9MB 700kB/s
Collecting llvmlite>=0.23.0dev0 (from numba)
Downloading https://files.pythonhosted.org/packages/21/c7/eb581bbbdf731f24a72eba505cf42668231c595ba61997a6fa186b7f0413/llvmlite-0.23.2-cp36-cp36m-manylinux1_x86_64.whl (15.8MB)
100% |████████████████████████████████| 15.8MB 103kB/s
Requirement already satisfied: numpy in ./.local/lib/python3.6/site-packages (from numba)
Installing collected packages: llvmlite, numba
Successfully installed llvmlite-0.23.2 numba-0.38.1
Kromě výše uvedeného postupu je možné pro instalaci Numby použít platformu Anaconda (nejedná se však o stejně pojmenovaný instalátor Fedory), samozřejmě za předpokladu, že ji již máte na svém počítači nakonfigurovanou:
$ conda install numba
popř. pro přechod na vyšší verzi:
$ conda update numba
Další varianta spočívá v překladu projektu ze zdrojových kódů. V tomto případě potřebujete mít nainstalován jak LLVM tak i llvmlite, což je knihovna zajišťující rozhraní mezi LLVM a Pythonem:
$ git clone https://github.com/numba/llvmlite $ cd llvmlite $ python setup.py install
Po tomto přípravném kroku již následuje naklonování repositáře s Numbou a její překlad s instalací:
$ git clone https://github.com/numba/numba.git $ cd numba $ pip install -r requirements.txt $ python setup.py build_ext --inplace $ python setup.py install
4. Kontrola korektní instalace
Dalším krokem ihned po instalaci bude zjištění, zda se Numba nainstalovala korektně. Prvním pokusem bude pokus o spuštění příkazu numba, tj. především test, jestli tento příkaz leží na PATH:
$ numba --help
usage: numba [-h] [--annotate] [--dump-llvm] [--dump-optimized]
[--dump-assembly] [--dump-cfg] [--dump-ast]
[--annotate-html ANNOTATE_HTML] [-s]
[filename]
positional arguments:
filename Python source filename
optional arguments:
-h, --help show this help message and exit
--annotate Annotate source
--dump-llvm Print generated llvm assembly
--dump-optimized Dump the optimized llvm assembly
--dump-assembly Dump the LLVM generated assembly
--dump-cfg [Deprecated] Dump the control flow graph
--dump-ast [Deprecated] Dump the AST
--annotate-html ANNOTATE_HTML
Output source annotation as html
-s, --sysinfo Output system information for bug reporting
V případě, že se tento příkaz nepodaří spustit, většinou to znamená, že do PATH není zahrnuta cesta ~/.local/bin, což lze snadno napravit (.bashrc atd.).
Druhý krok spočívá v pokusu o spuštění dalšího nástroje, který se jmenuje pycc (varování „DEPRECADED“ si nyní nemusíme všímat :-):
$ pycc --help
usage: pycc [-h] [-o OUTPUT] [-c | --llvm] [--header] [--python] [-d]
inputs [inputs ...]
DEPRECATED - Compile Python modules to a single shared library
positional arguments:
inputs Input file(s)
optional arguments:
-h, --help show this help message and exit
-o OUTPUT Output file (default is name of first input -- with new ending)
-c Create object file from each input instead of shared-library
--llvm Emit llvm instead of native code
--header Emit C header file with function signatures
--python Emit additionally generated Python wrapper and extension module
code in output
-d, --debug Print extra debug information
Třetí krok bude ve skutečnosti nejdůležitější, protože zjistíme, jestli je vůbec možné do běžící smyčky REPL naimportovat modul numba. Korektní instalace bude reagovat takto:
$ python3 Python 3.6.3 (default, Oct 9 2017, 12:11:29) [GCC 7.2.1 20170915 (Red Hat 7.2.1-2)] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import numba >>> numba.sys.version '3.6.3 (default, Oct 9 2017, 12:11:29) \n[GCC 7.2.1 20170915 (Red Hat 7.2.1-2)]'
V případě, že se instalace z nějakého důvodu nepovedla, získáme běžné chybové hlášení o neexistujícím modulu:
>>> import numba Traceback (most recent call last): File "<stdin>", line 1, in <module> ImportError: No module named numba
5. Označení funkcí, které se mají překládat JITem
Použití just-in-time překladače Numba může být ve skutečnosti velmi jednoduché. Pokud totiž o nějaké funkci naprogramované v Pythonu víme, například na základě použití profileru, že je vhodné jí optimalizovat, umístíme před její hlavičku anotaci @jit. Tuto anotaci lze naimportovat z modulu numba (a o existenci tohoto modulu jsme se přesvědčili v předchozí kapitole). Příklad označení funkce vypadá takto:
from numba import jit
@jit
def funkce1():
pass
Celá aplikace se spouští obvyklým způsobem, což znamená, že – na rozdíl od RPythonu nebo Cythonu – použijeme přímo interpret python/python2/python3 přesně stejným způsobem, jako bez použití Numby.
6. Testovací benchmark (dnes již naposledy)
V dnešním článku se snad již naposledy setkáme s benchmarkem, v němž se vykresluje Mandelbrotova množina se zadaným rozlišením a s předem nastaveným maximálním počtem iterací. Výsledek výpočtu se vypíše na standardní výstup, který bude přesměrován do souboru, protože výsledkem výpočtů budou bitmapy ve formátu Portable Pixel Map (viz [1]). Na tomto místě si musíme uvědomit, že benchmark kromě rychlosti vlastního výpočtu bude měřit i kumulativní čas výpisu hodnot na standardní výstup, který mj. znamená nutnost volání knihovních funkcí. Následuje výpis zdrojového kódu benchmarku, přičemž kód je napsán tak, aby byl kompatibilní s Pythonem 2.x, Pythonem 3.x i Jythonem (a také s Numbou):
#!/usr/bin/env python
# vim: set fileencoding=utf-8
import palette_mandmap
from sys import argv, exit
def calc_mandelbrot(width, height, maxiter, palette):
print("P3")
print("{w} {h}".format(w=width, h=height))
print("255")
cy = -1.5
for y in range(0, height):
cx = -2.0
for x in range(0, width):
zx = 0.0
zy = 0.0
i = 0
while i < maxiter:
zx2 = zx * zx
zy2 = zy * zy
if zx2 + zy2 > 4.0:
break
zy = 2.0 * zx * zy + cy
zx = zx2 - zy2 + cx
i += 1
r = palette[i][0]
g = palette[i][1]
b = palette[i][2]
print("{r} {g} {b}".format(r=r, g=g, b=b))
cx += 3.0/width
cy += 3.0/height
if __name__ == "__main__":
if len(argv) < 4:
width = 512
height = 512
maxiter = 255
else:
width = int(argv[1])
height = int(argv[2])
maxiter = int(argv[3])
calc_mandelbrot(width, height, maxiter, palette_mandmap.palette)

Obrázek 1: Mandelbrotova množina o rozlišení 512×512 pixelů vykreslená předchozím příkladem.
7. Výsledky benchmarku při lineárním zvyšování složitosti výpočtu
Na rozdíl od předchozích článků nyní budeme benchmark spouštět odlišným skriptem, který zajistí (přibližně) lineární zvyšování složitosti. Budeme totiž měnit pouze vertikální rozlišení obrázku (výšku) od 0 do 3500 pixelů s pevně daným krokem 100 pixelů. Postupné volání benchmarku zajistí tento skript (podobný skript bude použit i pro všechny další benchmarky):
width="2048"
OUTFILE="numba1_linear_scale.times"
PREFIX="numba1_linear_scale"
rm $OUTFILE
for height in $(seq 0 100 3500)
do
echo "${width} x ${height}"
echo -n "${height} " >> $OUTFILE
/usr/bin/time --output $OUTFILE --append --format "%e %M" python3 mandelbrot_python.py $width $height 255 > "${PREFIX}_${width}_${height}.ppm"
done
Podívejme se nyní na výsledky. Jen pro zopakování – prozatím získáme výsledky rychlosti výpočtu běžného interpretru Pythonu. Důvod, proč tento benchmark vlastně spouštíme, spočívá v tom, aby se ukázaly rozdíly mezi časy zahájení výpočtu (rozdíl interpretr versus JIT):
| Šířka | Výška | Čas běhu |
|---|---|---|
| 2048 | 0 | 0,03 |
| 2048 | 100 | 1,84 |
| 2048 | 200 | 3,59 |
| 2048 | 300 | 5,56 |
| 2048 | 400 | 7,16 |
| 2048 | 500 | 9,63 |
| 2048 | 600 | 11,62 |
| 2048 | 700 | 12,56 |
| 2048 | 800 | 14,20 |
| 2048 | 900 | 16,23 |
| 2048 | 1000 | 17,91 |
| 2048 | 1100 | 19,58 |
| 2048 | 1200 | 23,49 |
| 2048 | 1300 | 23,08 |
| 2048 | 1400 | 25,22 |
| 2048 | 1500 | 26,88 |
| 2048 | 1600 | 28,87 |
| 2048 | 1700 | 30,80 |
| 2048 | 1800 | 33,12 |
| 2048 | 1900 | 33,82 |
| 2048 | 2000 | 37,45 |
| 2048 | 2100 | 37,80 |
| 2048 | 2200 | 39,46 |
| 2048 | 2300 | 42,15 |
| 2048 | 2400 | 44,28 |
| 2048 | 2500 | 46,78 |
| 2048 | 2600 | 46,53 |
| 2048 | 2700 | 48,47 |
| 2048 | 2800 | 50,65 |
| 2048 | 2900 | 54,63 |
| 2048 | 3000 | 53,87 |
| 2048 | 3100 | 55,37 |
| 2048 | 3200 | 58,27 |
| 2048 | 3300 | 59,18 |
| 2048 | 3400 | 61,80 |
| 2048 | 3500 | 66,23 |
O tom, že se složitost (a čas výpočtu) skutečně zvětšuje lineárně, se můžeme přesvědčit pohledem na následující graf:
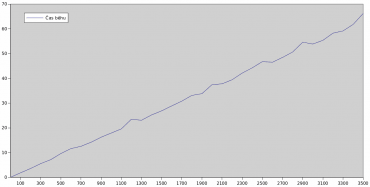
Obrázek 2: Závislost celkové doby výpočtu na vertikálním rozlišení obrázku.
8. Přidání anotace @jit
Prvním krokem při praktickém použití nástroje Numba je zápis anotace @jit před funkcí, u které potřebujeme, aby ji překladač optimalizoval v čase běhu. Nejdříve musíme do příslušného modulu anotaci naimportovat, což je snadné:
from numba import jit
Následně tuto anotaci použijeme – žádné další kroky není zapotřebí provést:
@jit
def calc_mandelbrot(width, height, maxiter, palette):
...
...
...
9. Použití zjednodušené varianty funkce print
Jedním z potenciálně problematických prvků našeho benchmarku je použití pythonovské funkce print. Při JIT překladu totiž může Numba použít dvě varianty této funkce – původní „univerzální“ pythonovskou variantu s téměř nepřebernými možnostmi formátování a volitelnými parametry nebo zjednodušenou variantu umožňující tisk číselných hodnot nebo řetězců (více info o nativních funkcích Numby je uvedeno na stránce https://numba.pydata.org/numba-doc/dev/reference/pysupported.html). Obecně platí, že pokud použijeme zjednodušenou variantu funkce print, bude JIT schopen přeložit celou JITovanou funkci do strojového kódu.
Náš kód tedy na dvou místech nepatrně upravíme a využijeme tak velké flexibility formátu PNM, v němž je možné použít jako oddělovač buď konec řádku nebo libovolný bílý znak (jednou z nepříjemných vlastností nativní varianty printu je to, že se vždy tiskne konec řádku).
Původní kód:
print("P3")
print("{w} {h}".format(w=width, h=height))
print("255")
Nový kód:
print("P3")
print(width)
print(height)
print("255")
Původní kód:
r = palette[i][0]
g = palette[i][1]
b = palette[i][2]
print("{r} {g} {b}".format(r=r, g=g, b=b))
Nový kód:
r = palette[i][0] g = palette[i][1] b = palette[i][2] print(r) print(g) print(b)
Nová podoba benchmarku tedy bude následující:
#!/usr/bin/env python
# vim: set fileencoding=utf-8
import palette_mandmap
from sys import argv, exit
from numba import jit
@jit
def calc_mandelbrot(width, height, maxiter, palette):
print("P3")
print(width)
print(height)
print("255")
cy = -1.5
for y in range(0, height):
cx = -2.0
for x in range(0, width):
zx = 0.0
zy = 0.0
i = 0
while i < maxiter:
zx2 = zx * zx
zy2 = zy * zy
if zx2 + zy2 > 4.0:
break
zy = 2.0 * zx * zy + cy
zx = zx2 - zy2 + cx
i += 1
r = palette[i][0]
g = palette[i][1]
b = palette[i][2]
print(r)
print(g)
print(b)
cx += 3.0/width
cy += 3.0/height
if __name__ == "__main__":
if len(argv) < 4:
width = 512
height = 512
maxiter = 255
else:
width = int(argv[1])
height = int(argv[2])
maxiter = int(argv[3])
calc_mandelbrot(width, height, maxiter, palette_mandmap.palette)
10. Vynucení úplného překladu anotací @jit(nopython=True)
JIT ve skutečnosti může pracovat ve dvou režimech, které se nazývají object mode a nopython mode. V prvním režimu je kód vytvářený JITem schopný zpracovat libovolné objekty (resp. reference na ně) a v případě potřeby se v kódu volá C API Pythonu pro zpracování těchto objektů. Pokud je tento režim použit, nebude se rychlost výsledného programu příliš odlišovat od běhu interpretru. Z tohoto důvodu se většinou budeme chtít tomuto režimu vyhnout – pokud to půjde. Naproti tomu druhý režim (nopython mode) generuje kód, v němž se C API nevolá a všechny proměnné a argumenty nesou hodnoty nativních typů (int, double atd.). Tento režim si můžeme vynutit anotací @jit(nopython=True), ovšem s několika omezeními, které se týkají například výše zmíněné funkce print (ostatně si zkuste sami vyzkoušet, co se stane, pokud tuto anotaci přidáme do prvního příkladu).
Benchmark upravíme následujícím způsobem:
@jit(nopython=True) def calc_mandelbrot(width, height, maxiter, palette):
Pro jistotu si uveďme celý kód, jak s novou anotací, tak i s použitím zjednodušené nativní funkce print:
#!/usr/bin/env python
# vim: set fileencoding=utf-8
import palette_mandmap
from sys import argv, exit
from numba import jit
@jit(nopython=True)
def calc_mandelbrot(width, height, maxiter, palette):
print("P3")
print(width)
print(height)
print("255")
cy = -1.5
for y in range(0, height):
cx = -2.0
for x in range(0, width):
zx = 0.0
zy = 0.0
i = 0
while i < maxiter:
zx2 = zx * zx
zy2 = zy * zy
if zx2 + zy2 > 4.0:
break
zy = 2.0 * zx * zy + cy
zx = zx2 - zy2 + cx
i += 1
r = palette[i][0]
g = palette[i][1]
b = palette[i][2]
print(r)
print(g)
print(b)
cx += 3.0/width
cy += 3.0/height
if __name__ == "__main__":
if len(argv) < 4:
width = 512
height = 512
maxiter = 255
else:
width = int(argv[1])
height = int(argv[2])
maxiter = int(argv[3])
calc_mandelbrot(width, height, maxiter, palette_mandmap.palette)
11. Porovnání výsledků benchmarků (pouze Numba)
Nyní již máme čtyři verze benchmarků:
- Původní zdrojový kód pro klasický interpret Pythonu
- Kód, do něhož byla pouze přidána anotace @jit
- Varianta s jednodušší (nativní) funkcí print
- Varianta s jednodušší (nativní) funkcí print a anotací @jit(nopython=True)
Podívejme se na výsledky benchmarků, nejdříve pouze v numerické podobě:
| Šířka | Výška | Numba #1/interpret | Numba #2 | Numba #3 | Numba #4 |
|---|---|---|---|---|---|
| 2048 | 0 | 0,03 | 0,76 | 5,92 | 5,89 |
| 2048 | 100 | 1,84 | 2,18 | 6,22 | 6,20 |
| 2048 | 200 | 3,59 | 3,56 | 6,60 | 6,58 |
| 2048 | 300 | 5,56 | 4,92 | 6,94 | 6,93 |
| 2048 | 400 | 7,16 | 6,38 | 7,30 | 7,33 |
| 2048 | 500 | 9,63 | 7,90 | 7,64 | 7,67 |
| 2048 | 600 | 11,62 | 9,27 | 8,01 | 8,04 |
| 2048 | 700 | 12,56 | 10,52 | 8,38 | 8,37 |
| 2048 | 800 | 14,20 | 11,99 | 8,70 | 8,83 |
| 2048 | 900 | 16,23 | 13,58 | 9,09 | 9,19 |
| 2048 | 1000 | 17,91 | 14,89 | 9,41 | 9,41 |
| 2048 | 1100 | 19,58 | 16,68 | 9,90 | 9,77 |
| 2048 | 1200 | 23,49 | 18,01 | 10,19 | 10,15 |
| 2048 | 1300 | 23,08 | 19,33 | 10,47 | 10,57 |
| 2048 | 1400 | 25,22 | 20,30 | 11,11 | 10,91 |
| 2048 | 1500 | 26,88 | 22,10 | 11,24 | 11,47 |
| 2048 | 1600 | 28,87 | 23,56 | 11,64 | 11,55 |
| 2048 | 1700 | 30,80 | 24,73 | 11,98 | 11,92 |
| 2048 | 1800 | 33,12 | 26,90 | 12,51 | 12,71 |
| 2048 | 1900 | 33,82 | 28,46 | 12,67 | 12,84 |
| 2048 | 2000 | 37,45 | 29,40 | 13,44 | 13,01 |
| 2048 | 2100 | 37,80 | 30,15 | 13,52 | 13,39 |
| 2048 | 2200 | 39,46 | 32,09 | 13,75 | 13,81 |
| 2048 | 2300 | 42,15 | 33,15 | 14,07 | 14,21 |
| 2048 | 2400 | 44,28 | 35,19 | 14,31 | 14,38 |
| 2048 | 2500 | 46,78 | 36,94 | 14,85 | 14,84 |
| 2048 | 2600 | 46,53 | 38,30 | 15,12 | 15,39 |
| 2048 | 2700 | 48,47 | 40,44 | 15,56 | 15,40 |
| 2048 | 2800 | 50,65 | 40,87 | 15,70 | 15,96 |
| 2048 | 2900 | 54,63 | 44,21 | 16,49 | 16,23 |
| 2048 | 3000 | 53,87 | 42,86 | 16,78 | 16,46 |
| 2048 | 3100 | 55,37 | 45,98 | 16,88 | 17,18 |
| 2048 | 3200 | 58,27 | 45,04 | 17,12 | 17,49 |
| 2048 | 3300 | 59,18 | 49,68 | 17,68 | 17,79 |
| 2048 | 3400 | 61,80 | 53,67 | 17,99 | 17,84 |
| 2048 | 3500 | 66,23 | 52,20 | 18,99 | 18,69 |
Přehlednější bude pohled na graf s průběhy výsledků všech čtyř benchmarků. Za povšimnutí stojí především to, že pouhým uvedením @jit jsme žádného výrazného urychlení nedosáhli, takže Numba nemusí ve všech případech produkovat nejlepší kód (zde konkrétně z toho důvodu, že JIT používal object mode a nikoli nopython mode). Dále si povšimněte, že při náhradě funkce print za její jednodušší variantu se JIT automaticky přepnul do nopython mode, což se projevilo jak delším časem na začátku (oněch cca 5 sekund i pro ty nejkratší skripty), tak menším sklonem výsledné křivky. Můžeme zde vidět, že pro často volané krátké skripty nemusí být JIT tím nejlepším řešením, zatímco pro náročné výpočty je jednoznačně lepší než interpret.
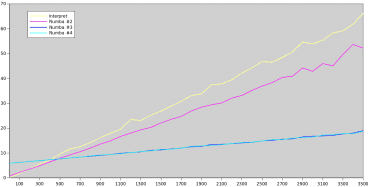
Obrázek 3: Výsledky všech čtyř benchmarků.
12. Porovnání s benchmarkem naprogramovaným v optimalizovaném Cythonu a ANSI C
Nyní již máme výsledky pro oba dva režimy JITu z nástroje Numba. Jak ale tento nepochybně užitečný nástroj obstojí v porovnání s Cythonem a benchmarkem naprogramovaným v čistém céčku? Odpověď získáme při pohledu na následující tabulku, protože i původní benchmarky byly spuštěny novým skriptem (s lineárně rostoucí složitostí):
| Šířka | Výška | ANSI C | Cython #1 | Cython #2 | Cython #3 | Numba #1/interpret | Numba #2 | Numba #3 | Numba #4 |
|---|---|---|---|---|---|---|---|---|---|
| 2048 | 0 | 0,00 | 0,03 | 0,02 | 0,03 | 0,03 | 0,76 | 5,92 | 5,89 |
| 2048 | 100 | 0,06 | 1,03 | 0,22 | 0,08 | 1,84 | 2,18 | 6,22 | 6,20 |
| 2048 | 200 | 0,11 | 2,10 | 0,42 | 0,14 | 3,59 | 3,56 | 6,60 | 6,58 |
| 2048 | 300 | 0,17 | 3,17 | 0,61 | 0,21 | 5,56 | 4,92 | 6,94 | 6,93 |
| 2048 | 400 | 0,23 | 4,04 | 0,81 | 0,26 | 7,16 | 6,38 | 7,30 | 7,33 |
| 2048 | 500 | 0,29 | 5,05 | 0,99 | 0,31 | 9,63 | 7,90 | 7,64 | 7,67 |
| 2048 | 600 | 0,34 | 6,16 | 1,19 | 0,37 | 11,62 | 9,27 | 8,01 | 8,04 |
| 2048 | 700 | 0,40 | 7,04 | 1,38 | 0,43 | 12,56 | 10,52 | 8,38 | 8,37 |
| 2048 | 800 | 0,46 | 8,17 | 1,56 | 0,48 | 14,20 | 11,99 | 8,70 | 8,83 |
| 2048 | 900 | 0,52 | 9,51 | 1,81 | 0,56 | 16,23 | 13,58 | 9,09 | 9,19 |
| 2048 | 1000 | 0,58 | 10,63 | 2,18 | 0,60 | 17,91 | 14,89 | 9,41 | 9,41 |
| 2048 | 1100 | 0,64 | 11,11 | 2,24 | 0,66 | 19,58 | 16,68 | 9,90 | 9,77 |
| 2048 | 1200 | 0,70 | 12,48 | 2,36 | 0,72 | 23,49 | 18,01 | 10,19 | 10,15 |
| 2048 | 1300 | 0,75 | 13,09 | 2,67 | 0,78 | 23,08 | 19,33 | 10,47 | 10,57 |
| 2048 | 1400 | 0,81 | 14,26 | 2,75 | 0,83 | 25,22 | 20,30 | 11,11 | 10,91 |
| 2048 | 1500 | 0,87 | 16,19 | 3,01 | 0,89 | 26,88 | 22,10 | 11,24 | 11,47 |
| 2048 | 1600 | 0,92 | 16,83 | 3,13 | 0,96 | 28,87 | 23,56 | 11,64 | 11,55 |
| 2048 | 1700 | 0,98 | 17,41 | 3,33 | 1,01 | 30,80 | 24,73 | 11,98 | 11,92 |
| 2048 | 1800 | 1,04 | 18,25 | 3,52 | 1,07 | 33,12 | 26,90 | 12,51 | 12,71 |
| 2048 | 1900 | 1,10 | 20,10 | 3,71 | 1,13 | 33,82 | 28,46 | 12,67 | 12,84 |
| 2048 | 2000 | 1,16 | 20,80 | 3,97 | 1,18 | 37,45 | 29,40 | 13,44 | 13,01 |
| 2048 | 2100 | 1,21 | 22,08 | 4,13 | 1,24 | 37,80 | 30,15 | 13,52 | 13,39 |
| 2048 | 2200 | 1,27 | 23,65 | 4,49 | 1,30 | 39,46 | 32,09 | 13,75 | 13,81 |
| 2048 | 2300 | 1,33 | 23,51 | 4,48 | 1,36 | 42,15 | 33,15 | 14,07 | 14,21 |
| 2048 | 2400 | 1,39 | 25,66 | 4,70 | 1,42 | 44,28 | 35,19 | 14,31 | 14,38 |
| 2048 | 2500 | 1,45 | 25,77 | 5,07 | 1,50 | 46,78 | 36,94 | 14,85 | 14,84 |
| 2048 | 2600 | 1,51 | 26,98 | 5,28 | 1,53 | 46,53 | 38,30 | 15,12 | 15,39 |
| 2048 | 2700 | 1,58 | 27,82 | 5,52 | 1,60 | 48,47 | 40,44 | 15,56 | 15,40 |
| 2048 | 2800 | 1,63 | 28,56 | 5,48 | 1,66 | 50,65 | 40,87 | 15,70 | 15,96 |
| 2048 | 2900 | 1,68 | 29,92 | 5,74 | 1,73 | 54,63 | 44,21 | 16,49 | 16,23 |
| 2048 | 3000 | 1,85 | 30,59 | 6,04 | 1,77 | 53,87 | 42,86 | 16,78 | 16,46 |
| 2048 | 3100 | 1,80 | 31,48 | 6,11 | 1,87 | 55,37 | 45,98 | 16,88 | 17,18 |
| 2048 | 3200 | 1,85 | 33,32 | 6,37 | 1,89 | 58,27 | 45,04 | 17,12 | 17,49 |
| 2048 | 3300 | 1,92 | 37,60 | 6,55 | 1,94 | 59,18 | 49,68 | 17,68 | 17,79 |
| 2048 | 3400 | 1,97 | 36,76 | 6,72 | 2,35 | 61,80 | 53,67 | 17,99 | 17,84 |
| 2048 | 3500 | 2,03 | 35,78 | 6,89 | 2,06 | 66,23 | 52,20 | 18,99 | 18,69 |
13. Graf s výsledky všech benchmarků a zhodnocení výsledků
Zkusme si nyní vynést výsledky z předchozí tabulky do grafu. Můžeme v něm vidět, že průběh pro benchmark naprogramovaný v ANSI C je prakticky shodný s Cythonem při volbě nejlepších optimalizací (kterých jsme byli schopni). Současně se jedná o nejrychlejší/nejlepší výsledky. Podle očekávání je většinou nejpomalejší výpočet provedený interpretrem (CPython), ovšem zajímavá je situace na začátku grafu (malá výška obrázků), kde interpret překonává Numbu při zapnutí plného JITování. Průběhy Numba #2 a Numba #3 jsou opět prakticky shodné, což jsme již diskutovali v předchozích kapitolách:
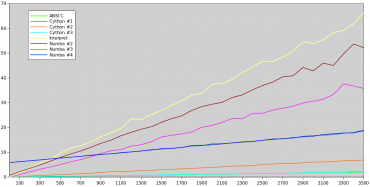
Obrázek 4: Výsledky všech benchmarků z předchozí tabulky.
Stručné zhodnocení pro tento konkrétní benchmark (které ovšem platí i pro další programy s převahou výpočtů):
- S Cythonem je možné dosáhnout nejlepších výsledků, ovšem za cenu nutnosti zásahů do kódu (množství cdef). Bez těchto zásahů bude zrychlení poměrně nevýrazné (hnědý průběh pod žlutým průběhem platným pro interpret).
- Numba sice nedosahuje tak dobrých výsledků jako optimalizovaný (!) Cython, ovšem i při naprosto minimálních zásazích do kódu dokážeme získat rozumné výsledky (modrý průběh). Platíme za to prvotní pauzou nutnou pro JITování (v našem případě cca pět sekund). Záleží na povaze aplikace, jestli je toto zpomalení významné či nikoli (malé skripty versus serverové aplikace například).
14. Explicitně zapsané informace o typech (typové signatury)
I při použití Numby je možné (a to zcela volitelně) informovat just-in-time překladač o typech proměnných, argumentů funkcí či návratových typech funkcí. Z primitivních datových typů se jedná především o různé typy numerických hodnot (+ pravdivostní hodnota). Ty jsou shrnuty v následující tabulce:
| Kanonické jméno | Zkratka | Datový typ |
|---|---|---|
| numba.boolean | numba.b1 | byte |
| numba.uint8, numba.byte | numba.u1 | 8-bit unsigned byte |
| numba.uint16 | numba.u2 | 16-bit unsigned integer |
| numba.uint32 | numba.u4 | 32-bit unsigned integer |
| numba.uint64 | numba.u8 | 64-bit unsigned integer |
| numba.int8, numba.char | numba.i1 | 8-bit signed byte |
| numba.int16 | numba.i2 | 16-bit signed integer |
| numba.int32 | numba.i4 | 32-bit signed integer |
| numba.int64 | numba.i8 | 64-bit signed integer |
| numba.intc | × | C int-sized integer |
| numba.uintc | × | C int-sized unsigned integer |
| numba.intp | × | pointer-sized integer |
| numba.uintp | × | pointer-sized unsigned integer |
| numba.float32 | numba.f4 | single-precision floating-point number |
| numba.float64, numba.double | numba.f8 | double-precision floating-point number |
| numba.complex64 | numba.c8 | single-precision complex number |
| numba.complex128 | numba.c16 | double-precision complex number |
Tyto typy použijeme ve chvíli, kdy se namísto JIT používá AOT (viz druhou kapitolu), popř. je uvidíme při ladění aplikací. Příklad použití (převzatý přímo z dokumentace a mírně upravený) ukazuje, že signaturu lze použít i vícekrát, protože funkce mohou akceptovat více typů parametrů (přeloží se potom několikrát, což ostatně odpovídá i způsobu překladu JITem):
@cc.export('addf', 'f8(f8, f8)')
@cc.export('addi', 'i4(i4, i4)')
@cc.export('addl', 'i8(i8, i8)')
def add(a, b):
return a * b
@cc.export('square', 'f8(f8)')
def square(a):
return a ** 2
15. Specifikace typů polí
Specifikovat je možné i typy polí resp. přesněji řečeno typy prvků ukládaných do pole. Pole jsou totiž po překladu do strojového kódu homogenní datovou strukturou, na rozdíl od běžných Pythonovských seznamů. Příklady deklarace polí různých typů jsou uvedeny v následující tabulce:
| Deklarace | Vrátí se | Význam |
|---|---|---|
| numba.byte[:] | array(uint8, 1d, A) | jednorozměrné pole bajtů |
| numba.byte[::1] | array(uint8, 1d, C) | souvislé jednorozměrné pole bajtů |
| numba.float32[:] | array(float32, 1d, A) | jednorozměrné pole s prvky typu float (jednoduchá přesnost) |
| numba.int16[:, :] | array(int16, 2d, A) | dvourozměrné pole 16bitových celých čísel |
| numba.uintp[:, :, :] | array(uint64, 3d, A) | trojrozměrné pole ukazatelů |
| numba.float32[:, :, ::1] | array(float32, 3d, C) | souvislé trojrozměrné pole (céčková organizace) |
| numba.float32[::1, :, :] | array(float32, 3d, F) | souvislé trojrozměrné pole (organizace podle Fortranu) |
| numba.float32[:, ::1, :] | array(float32, 3d, A) | trojrozměrné pole |
Souvislá pole odpovídají céčkovým polím – prvky jsou v nich uloženy v kontinuálním bloku paměti.
Význam posledního znaku v předchozím zápisu určuje uspořádání prvků pole v operační paměti:
| Order | Význam |
|---|---|
| ‚C‘ | prvky jsou uspořádány jako v jazyku C |
| ‚F‘ | prvky jsou uspořádány jako v jazyku Fortran |
| ‚A‘ | ponecháme na implementaci, který způsob uspořádání zvolit |
Jaký je tedy vlastně rozdíl mezi uspořádáním prvků podle ‚C‘ a ‚F‘? Předpokládejme matici 3×3 prvky:
| 1 2 3 | | 4 5 6 | | 7 8 9 |
Tato matice může být v paměti uložena následujícím způsobem:
1 2 3 4 5 6 7 8 9 - 'C'
Alternativně je však možné prohodit řádky a sloupce (což více odpovídá matematickému zápisu matice):
1 4 7 2 5 8 3 6 9 - 'F'
V dalších dílech si ukážeme, jak lze v Numba používat pole odpovídající konvencím známé knihovny Numpy.
16. Obsah druhé části článku
Ve druhé části článku si ukážeme především interní procesy, které Numba provádí při JITování kódu. Setkáme se tedy s projektem LLVM, který je velmi populární, a to v mnoha oblastech (stačí jen připomenout zajímavý projekt Emscripten atd.).

17. Repositář s demonstračními příklady a výsledky benchmarků
Všechny skripty, které jsme si v dnešním článku ukázali, naleznete na adrese https://github.com/tisnik/numba-examples. Následují odkazy na jednotlivé příklady (pro jejich spuštění je nutné mít nainstalovánu knihovnu a jeho závislosti – viz třetí kapitolu):
| # | Příklad | Adresa |
|---|---|---|
| 1 | mandelbrot-v1 | https://github.com/tisnik/numba-examples/tree/master/mandelbrot-v1 |
| 2 | mandelbrot-v2 | https://github.com/tisnik/numba-examples/tree/master/mandelbrot-v2 |
| 3 | mandelbrot-v3 | https://github.com/tisnik/numba-examples/tree/master/mandelbrot-v3 |
| 4 | mandelbrot-v4 | https://github.com/tisnik/numba-examples/tree/master/mandelbrot-v4 |
Výsledky benchmarků (prosté textové soubory určené pro další zpracování) jsou „rozházeny“ mezi tři repositáře, což je ale pochopitelné, protože jsme benchmarky spouštěli s využitím rozdílných nástrojů:
| # | Výsledek pro | Adresa |
|---|---|---|
| 1 | ANSI C | https://github.com/tisnik/rpython-examples/blob/master/benchmarks/mandelbrot/c/ansi_c_linear_scale.times |
| 2 | Cython bez optimalizací | https://github.com/tisnik/cython-examples/blob/master/mandelbrot/v1/cython_linear_scale.times |
| 3 | Cython s type hinty | https://github.com/tisnik/cython-examples/blob/master/mandelbrot/v2/cython_linear_scale.times |
| 4 | Cython plně optimalizovaný | https://github.com/tisnik/cython-examples/blob/master/mandelbrot/v3/cython_linear_scale.times |
| 5 | Numba základní varianta | https://github.com/tisnik/numba-examples/blob/master/mandelbrot-v2/numba2_linear_scale.times |
| 6 | Numba s vylepšeným print | https://github.com/tisnik/numba-examples/blob/master/mandelbrot-v3/numba3_linear_scale.times |
| 7 | Numba s plným JITem | https://github.com/tisnik/numba-examples/blob/master/mandelbrot-v4/numba4_linear_scale.times |
18. Odkazy na Internetu
- Numba
http://numba.pydata.org/ - numba 0.38.1
https://pypi.org/project/numba/ - Numba documentation
http://numba.pydata.org/numba-doc/latest/index.html - Numba na GitHubu
https://github.com/numba/numba - First Steps with numba
https://numba.pydata.org/numba-doc/0.12.2/tutorial_firststeps.html - Numba and types
https://numba.pydata.org/numba-doc/0.12.2/tutorial_types.html - Just-in-time compilation
https://en.wikipedia.org/wiki/Just-in-time_compilation - Cython (home page)
http://cython.org/ - Cython (wiki)
https://github.com/cython/cython/wiki - Cython (Wikipedia)
https://en.wikipedia.org/wiki/Cython - Cython (GitHub)
https://github.com/cython/cython - Python Implementations: Compilers
https://wiki.python.org/moin/PythonImplementations#Compilers - EmbeddingCython
https://github.com/cython/cython/wiki/EmbeddingCython - The Basics of Cython
http://docs.cython.org/en/latest/src/tutorial/cython_tutorial.html - Overcoming Python's GIL with Cython
https://lbolla.info/python-threads-cython-gil - GlobalInterpreterLock
https://wiki.python.org/moin/GlobalInterpreterLock - The Magic of RPython
https://refi64.com/posts/the-magic-of-rpython.html - RPython: Frequently Asked Questions
http://rpython.readthedocs.io/en/latest/faq.html - RPython’s documentation
http://rpython.readthedocs.io/en/latest/index.html - RPython (Wikipedia)
https://en.wikipedia.org/wiki/PyPy#RPython - Getting Started with RPython
http://rpython.readthedocs.io/en/latest/getting-started.html - PyPy (home page)
https://pypy.org/ - PyPy (dokumentace)
http://doc.pypy.org/en/latest/ - Localized Type Inference of Atomic Types in Python (2005)
http://citeseer.ist.psu.edu/viewdoc/summary?doi=10.1.1.90.3231 - Tutorial: Writing an Interpreter with PyPy, Part 1
https://morepypy.blogspot.com/2011/04/tutorial-writing-interpreter-with-pypy.html - List of numerical analysis software
https://en.wikipedia.org/wiki/List_of_numerical_analysis_software - Pixie: lehký skriptovací jazyk s „kouzelnými“ schopnostmi
https://www.root.cz/clanky/pixie-lehky-skriptovaci-jazyk-s-kouzelnymi-schopnostmi/ - Programovací jazyk Pixie: funkce ze základní knihovny a použití FFI
https://www.root.cz/clanky/programovaci-jazyk-pixie-funkce-ze-zakladni-knihovny-a-pouziti-ffi/ - The future can be written in RPython now (článek z roku 2010)
http://blog.christianperone.com/2010/05/the-future-can-be-written-in-rpython-now/ - PyPy is the Future of Python (článek z roku 2010)
https://alexgaynor.net/2010/may/15/pypy-future-python/ - Portal:Python programming
https://en.wikipedia.org/wiki/Portal:Python_programming - RPython Frontend and C Wrapper Generator
http://www.codeforge.com/article/383293 - PyPy’s Approach to Virtual Machine Construction
https://bitbucket.org/pypy/extradoc/raw/tip/talk/dls2006/pypy-vm-construction.pdf - Tutorial: Writing an Interpreter with PyPy, Part 1
https://morepypy.blogspot.com/2011/04/tutorial-writing-interpreter-with-pypy.html - A simple interpreter from scratch in Python (part 1)
http://www.jayconrod.com/posts/37/a-simple-interpreter-from-scratch-in-python-part-1 - Brainfuck Interpreter in Python
https://helloacm.com/brainfuck-interpreter-in-python/ - Interpretry, překladače, JIT překladače a transpřekladače programovacího jazyka Lua
https://www.root.cz/clanky/interpretry-prekladace-jit-prekladace-a-transprekladace-programovaciho-jazyka-lua/ - LuaJIT – Just in Time překladač pro programovací jazyk Lua
https://www.root.cz/clanky/luajit-just-in-time-prekladac-pro-programovaci-jazyk-lua/ - LuaJIT – Just in Time překladač pro programovací jazyk Lua (2)
https://www.root.cz/clanky/luajit-just-in-time-prekladac-pro-programovaci-jazyk-lua-2/ - LuaJIT – Just in Time překladač pro programovací jazyk Lua (3)
https://www.root.cz/clanky/luajit-just-in-time-prekladac-pro-programovaci-jazyk-lua-3/ - LuaJIT – Just in Time překladač pro programovací jazyk Lua (4)
https://www.root.cz/clanky/luajit-just-in-time-prekladac-pro-programovaci-jazyk-lua-4/ - LuaJIT – Just in Time překladač pro programovací jazyk Lua (5 – tabulky a pole)
https://www.root.cz/clanky/luajit-just-in-time-prekladac-pro-programovaci-jazyk-lua-5-tabulky-a-pole/ - LuaJIT – Just in Time překladač pro programovací jazyk Lua (6 – překlad programových smyček do mezijazyka LuaJITu)
https://www.root.cz/clanky/luajit-just-in-time-prekladac-pro-programovaci-jazyk-lua-6-preklad-programovych-smycek-do-mezijazyka-luajitu/ - LuaJIT – Just in Time překladač pro programovací jazyk Lua (7 – dokončení popisu mezijazyka LuaJITu)
https://www.root.cz/clanky/luajit-just-in-time-prekladac-pro-programovaci-jazyk-lua-7-dokonceni-popisu-mezijazyka-luajitu/ - LuaJIT – Just in Time překladač pro programovací jazyk Lua (8 – základní vlastnosti trasovacího JITu)
https://www.root.cz/clanky/luajit-just-in-time-prekladac-pro-programovaci-jazyk-lua-8-zakladni-vlastnosti-trasovaciho-jitu/ - LuaJIT – Just in Time překladač pro programovací jazyk Lua (9 – další vlastnosti trasovacího JITu)
https://www.root.cz/clanky/luajit-just-in-time-prekladac-pro-programovaci-jazyk-lua-9-dalsi-vlastnosti-trasovaciho-jitu/ - LuaJIT – Just in Time překladač pro programovací jazyk Lua (10 – JIT překlad do nativního kódu)
https://www.root.cz/clanky/luajit-just-in-time-prekladac-pro-programovaci-jazyk-lua-10-jit-preklad-do-nativniho-kodu/ - LuaJIT – Just in Time překladač pro programovací jazyk Lua (11 – JIT překlad do nativního kódu procesorů s architekturami x86 a ARM)
https://www.root.cz/clanky/luajit-just-in-time-prekladac-pro-programovaci-jazyk-lua-11-jit-preklad-do-nativniho-kodu-procesoru-s-architekturami-x86-a-arm/ - LuaJIT – Just in Time překladač pro programovací jazyk Lua (12 – překlad operací s reálnými čísly)
https://www.root.cz/clanky/luajit-just-in-time-prekladac-pro-programovaci-jazyk-lua-12-preklad-operaci-s-realnymi-cisly/





























 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU