
Obsah
1. Použití Pythonu pro tvorbu testů: od jednotkových testů až po testy UI
2. Různé podoby testovací pyramidy
4. Jednotkové testy – základ pyramidy, špička kornoutu
5. Testy komponent a integrační testy
6. Systémové testy, akceptační testy
7. Testy aplikačního (programového) rozhraní
8. Testy grafického uživatelského rozhraní a end-to-end testy
10. Test-driven development (TDD)
11. Acceptance test–driven development (ATDD)
12. Použití knihovny unittest.mock (nejenom) při testování
13. Zdrojový soubor s funkcí, kterou budeme nahrazovat mock objektem
14. Test s volanou i s mockovanou funkcí
15. Vytvoření handleru, který se zavolá namísto originální funkce
16. Kombinace handleru s předkonfigurovanou návratovou hodnotou?
17. Obsah následující části seriálu
18. Repositář s demonstračními příklady
19. Předchozí články s tématem testování (nejenom) v Pythonu
1. Použití Pythonu pro tvorbu testů: od jednotkových testů až po testy UI
Testování aplikací, což je téma, do kterého se počítá jak tvorba testů, tak i nástroje a postupy pro jejich spouštění a vyhodnocování, v současnosti tvoří nedílnou součást vývoje aplikací a popř. i součást jejich akceptace zákazníkem. Jedná se o velmi rozsáhlou oblast IT, která se postupně vyvíjela a rozdělovala do několika podoblastí společně s tím, jak se měnil charakter vyvíjených aplikací i jejich celková složitost (původně dávkové úlohy, dále čistě desktopové aplikace s grafickým uživatelským rozhraním, následovaly webové aplikace a webové služby, cloud atd.). S problematikou testů a testování jsme se na stránkách Roota již několikrát setkali (viz odkazy uvedené v devatenácté kapitole), ale možná bude užitečné se na testování podívat i z určitého odstupu – jaké typy testů se používají, proč se vlastně používají, jaké pomocné nástroje máme v dané oblasti k dispozici a jaké jsou případné dobré a naopak špatné praktiky.
Samotný – dnes již samostatný – obor testování v IT se postupně vyvíjel a měnily se i jeho metodiky. U mnoha starších (z dnešního pohledu prastarých) projektů bylo testování prováděno jednorázově, a to na konci vývoje celého systému. Toto mnohdy manuální či jen poloautomatické testování bychom dnes nazvali akceptačními testy. Tento přístup již pro většinu rozsáhlejších projektů není ani praktický ani nejlevnější; dnes je totiž testování úzce svázáno s celým procesem vývoje nového informačního systému a někdy celý vývoj začíná právě vytvořením prvotní sady testů. Důležitější je ovšem průběžné testování v čase vývoje a nasazování aplikace, což nám mj. dává přímou zpětnou vazbu o stavu vyvíjeného systému (pokud jsou pochopitelně testy napsány dobře). V dnes začínajícím (mini)seriálu si nejprve vysvětlíme základní termíny (ty ovšem nejsou plně ustáleny) a postupně budeme proházet „testovací pyramidou“ (viz druhou kapitolu) od její základny až po vrchol.
2. Různé podoby testovací pyramidy
V souvislosti s testy (resp. přesněji řečeno s různými typy testů) se poměrně často můžeme setkat s termínem „testovací pyramida“. O co se vlastně jedná? Jde o rozdělení jednotlivých typů testů do vrstev, přičemž vrstvy na spodních úrovních mají blíže k vlastnímu zdrojovému kódu, zatímco vrstvy na úrovních vyšších již od kódu (a mnohdy i od architektury aplikace) do značné míry abstrahují. Má to pochopitelně svůj velmi dobrý význam, protože jedna úroveň abstrakce nemůže v této oblasti vyhovovat pro všechny oblasti použití. Zajímavé je, že se sice tento termín skutečně používá poměrně často, ale autoři si jednotlivé vrstvy (zejména ty prostřední) rozdělují různým způsobem. Ostatně se můžeme podívat na několik příkladů:
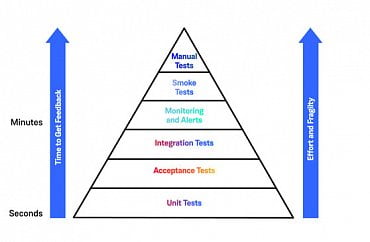
Obrázek 1: Různé podoby testovací pyramidy.
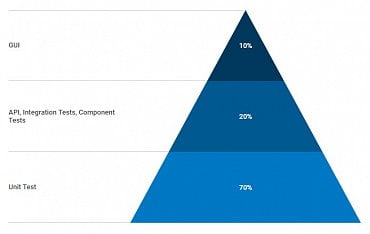
Obrázek 2: Různé podoby testovací pyramidy.
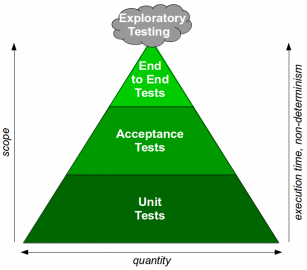
Obrázek 3: Různé podoby testovací pyramidy.
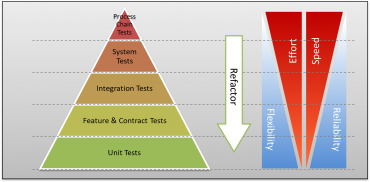
Obrázek 4: Různé podoby testovací pyramidy.
Většina autorů se shodne na tom, že testovací pyramida (ať již jsou její vrstvy blíže k vrcholku pojmenovány různě) tvoří velmi dobrý příklad toho, jak by testy reálné aplikace měly vypadat. Základem pyramidy jsou jednotkové testy a základna by pochopitelně měla být co nejširší. Předností jednotkových testů je jejich rychlé spouštění (může se testovat izolovaně pouze ona jednotka – třída, funkce atd.), stabilita a poměrně snadné a rychlé úpravy. Směrem k vrcholku pyramidy se vrstvy pochopitelně zužují, což v překladu znamená, že by se testům na těchto úrovních mohla (relativně!) věnovat menší pozornost. Testy blíže k vrcholu pyramidy jsou „dražší“, a to jak z hlediska investovaného pracovního času (extrémem jsou manuální testy), tak i času strojového (je nutné sestavit celou aplikaci i se všemi souvisejícími službami atd.).
3. Zmrzlinový kornout
V souvislosti s prioritami, které se mají věnovat jednotlivým typům testů, se někdy setkáme i s termínem „zmrzlinový kornout“, což je struktura připomínající otočenou pyramidu. V této struktuře se málo času/energie/peněz věnuje jednotkovým testům a testům komponent, o to více času (alespoň relativně) se pak věnuje například testům grafického uživatelského rozhraní nebo dokonce manuálním testům. Takto nastavené priority při tvorbě testů jsou ovšem většinou praktikujících autorů považovány za antipattern, ovšem i s takovým postupem (popř. nějakou jeho variantou) se můžeme v praxi setkat.
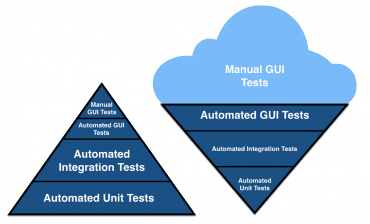
Obrázek 5: Podoba zmrzlinového kornoutu v porovnání s testovací pyramidou.
4. Jednotkové testy – základ pyramidy, špička kornoutu
První fáze testování většinou probíhá na úrovni balíčků, tříd, objektů, metod a funkcí. Jedná se o takzvané jednotkové testy (unit tests), přičemž onou jednotkou bývá jedna funkce, metoda, celá třída nebo (méně často) celý balíček. Tyto testy se v Pythonu tvoří relativně snadno a typicky se vytváří souběžně s programovým kódem nebo (při TDD) dokonce ještě před zahájením prací na programovém kódu. Výhodou jednotkových testů je jejich specifičnost, možnost selektivního spouštění testů pouze pro zvolenou jednotku i snadné plánovaní prací (předpokládá se, že jednotkové testy jsou součástí zdrojových kódů). Vývoj současně s jednotkovými testy může pomoci s vytvářením kvalitnějšího kódu (typicky při omezování stavového prostoru aplikace, globálních proměnných atd.). Ovšem při tvorbě jednotkových testů je nutné počítat i s některými riziky, zejména pak:
- Pokud jednotkové testy vytváří samotný autor testovaného zdrojového kódu, je pravděpodobné, že v testech nemusí pokrýt všechny možné případy, které tak nebudou ani správně odhaleny ve zdrojovém kódu.
- Velké množství procházejících testů může vést k tomu, že se budou zbývající padající testy ignorovat.
- Testy na sobě mohou záviset, což je obecně špatná architektura (testy by mělo být možné spouštět v náhodném pořadí, popř. je filtrovat).
- Změna architektury aplikace může znamenat nutnost přepisu velkého množství jednotkových testů.
V jednotkových testech je nutné některé (zrovna netestované) bloky nahradit za jednodušší objekty nazývané test double. Ty se dále rozdělují do několika kategorií: fake, stub, mock, spy atd. (viz též navazující kapitoly, zejména dvanáctou kapitolu).
Příklad primitivního jednotkového testu:
import pytest
def test_the_answer():
x = 6
y = 7
assert x*y == 42, "test failed"
Příklad testu, který zjišťuje, zda testovaná funkce vyhodila výjimku či nikoli:
import pytest
def raise_expection():
raise Exception("Diamonds are forewer")
def test_exception(self):
with pytest.raises(Exception):
...
...
...
self.assertTrue('This is broken' in context.exception)
Pro programovací jazyk Python v současnosti existuje téměř nepřeberné množství knihoven, frameworků a rozšíření standardních jednotkových testů. Jmenujme například:
| # | Knihovna/framework |
|---|---|
| 1 | unittest |
| 2 | doctest |
| 3 | pytest |
| 4 | nose |
| 5 | testify |
| 6 | Trial |
| 7 | Twisted |
| 8 | subunit |
| 9 | testresources |
| 10 | reahl.tofu |
| 11 | unit testing |
| 12 | testtools |
| 13 | Sancho |
| 14 | zope.testing |
| 15 | pry |
| 16 | pythoscope |
| 17 | testlib |
| 18 | pytest |
| 19 | dutest |
5. Testy komponent a integrační testy
Jak jsme již mohli vidět ve druhé kapitole, tvoří jednotkové testy jen jedinou vrstvu (základnu) takzvané „testovací pyramidy“. Nad nimi se v dalších vrstvách nachází testy komponent, funkční testy, integrační testy, různé formy benchmarků, BDD testy, testy grafického uživatelského rozhraní, manuálně prováděné testy atd. Všechny tyto testy jsou potenciálně důležité, protože samotné jednotkové testy zdaleka nedokáží odhalit všechny možné chyby:

Obrázek 6: Jednotkové testy nedokáží odhalit problémy na vyšších úrovních abstrakce, například problematické sestavení jednotlivých modulů do vyšších celků.
A právě z tohoto důvodu jsou nad samotnými jednotkovými testy postaveny testy komponent a integrační testy. Ty se snaží zjistit, zda je možné menší (a ideálně velmi dobře izolovaně otestované) jednotky (units) sestavit do většího a přitom stále funkčního celku. V některých případech se rozlišuje mezi vnitřní a vnější integrací (testy komponent patří do první kategorie). Testuje se například komunikace mezi jednotlivými moduly, ze kterých se výsledná aplikace skládá. Podobně jako se u jednotkových testů používají mock objekty (resp. obecněji test double), lze u integračních testů používat takzvané fake moduly a mock moduly. Poměrně názorným příkladem takového modulu může být zjednodušená forma databáze uložená v operační paměti, která pro účely testů nahrazuje reálnou databázi (v paměti lze velmi snadno provozovat například SQLite). Relativně snadno se nahrazují i například moduly pro logování apod. Taktéž se zde setkáme s takzvanými špiony (spies), což jsou moduly zaznamenávající všechny požadavky přicházející z jiných modulů.
6. Systémové testy, akceptační testy
U úroveň výše v testovací pyramidě nacházíme celou skupinu testů, zejména pak systémové testy a testy akceptační. Systémové testy se většinou rozdělují do dalších podkategorií. Zejména se často používají takzvané smoke testy, které pouze velmi rychle zjišťují, zda je zajištěna alespoň minimální míra funkčnosti aplikace předtím, než se spustí složitější a časově mnohem náročnější testy. Pokud smoke testy zhavarují, vrací se aplikace zpět k vývojářům a popř. k devops týmu :-)
Po úspěšném provedení smoke testů se mohou spouštět systémové testy, jejichž primárním účelem je ověření, jestli aplikace (služba) sestavená do jednoho celku pracuje korektně. Tyto testy se zaměřují jak na zjištění, zda pro určité vstupy aplikace produkuje určitý výstup (například objedná letenku), ale i to, jak reaguje na nestandardní situace, špatně zadané vstupy, pokusy o průnik do aplikace apod. Tvorbou těchto testů již může být pověřen samostatný tým (na rozdíl od testů jednotkových a popř. testů komponent, což je většinou starostí vývojového týmu).
Testy akceptační jsou ještě zajímavější, protože se na jejich vytváření může podílet i zákazník. Jak již název těchto testů napovídá, je jejich úspěšné provedení (většinou) vyžadováno proto, aby byla akceptována funkčnost aplikace. Pro akceptační testy lze v Pythonu použít různé knihovny a frameworky, například dále zmíněnou knihovnu Behave nebo – a to pravděpodobně častěji – nástroj nazvaný Robot Framework. V tomto nástroji lze testy zapisovat formou tabulek, například následujícím způsobem (nejedná se o jediný možný způsob):
| *** Settings *** | | | | Library | Test16.py | | | | | | | *** Test Cases *** | | | | Adder #1 | | | | | Add | 1 | 2 | | Result should be | 3 | | | | | | Adder #2 | | | | | Add | 0 | 0 | | Result should be | 0 | | | | | | Adder #3 | | | | | Add | 1 | -1 | | Result should be | 0 |
Ve webovém prohlížeči si můžeme prohlédnout vygenerované soubory s výsledky:
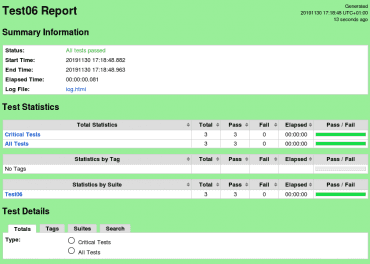
Obrázek 7: Přehled s výsledky testovacího scénáře. Zelená barva naznačuje, že všechny testy skončily korektně.
Alternativně:
| *** Settings *** | | | | Library | Test16.py | | | *** Test Cases *** | | | | Adder #1 | | | | | Add | 1 | 2 | | Result should be | 3 | | | Add | 2 | 3 | | Result should be | 5 | | | Add | 4 | 5 | | Result should be | 9 | | Adder #2 | | | | | Add | 0 | 0 | | Result should be | 0 | | Adder #3 | | | | | Add | 1 | -1 | | Result should be | 0 |

Obrázek 8: Podrobnější pohled na jednotlivé kroky testu.
Jiný způsob zápisu testu, opět v tabulkové podobě:
| *** Settings *** | | | |
| Library | Accumulator6.py | | |
| Test template | Accumulate | | |
| Test setup | Setup method | 0 | |
| Test teardown | Teardown method | | |
| | | | |
| *** Test Cases *** | Value | Expected | |
| Test1 | 0 | 0 | |
| | 1 | 1 | |
| | 10 | 11 | |
| | -10 | 1 | |
| | 1 | 2 | |
| | 1 | 3 | |
| | | | |
| *** Keywords *** | | | |
| Accumulate | | | |
| | [Arguments] | ${value} | ${expected} |
| | Add value | ${value} | |
| | Accumulator value should be | ${expected} | |

Obrázek 9: Podrobnější pohled na jednotlivé kroky testu, informace z logovacího souboru.

Obrázek 10: Přehled s výsledky testovacího scénáře. Červená barva naznačuje pád alespoň jednoho testu.
7. Testy aplikačního (programového) rozhraní
Dalším typem testů jsou testy aplikačního programového rozhraní, dnes typicky (ale nejenom) REST API. Tyto testy mohou být vyvinuty a spouštěny samostatně (například vůči jedné izolované komponentě), nebo mohou být součástí end-to-end testů zmíněných dále. Součástí API testů bývají i kontroly autentizace a autorizace, stejně jako kontroly, jak API reaguje na pokusy o průnik, popř. „pouze“ na vadná data. Jak jsme si již řekli na začátku tohoto odstavce, dnes se velmi často používá REST API, takže testy pro ně lze vytvořit různými způsoby (například automaticky ze specifikace OpenAPI), ovšem používají se i další protokoly (MQTT, SOAP, RMI, SMTP atd.). Pro některé typy webových aplikací (resp. přesněji řečeno jejich REST API) mi vyhovovala kombinace knihovny Behave se známou knihovnou requests, ovšem existují i mnohé další více či méně komplexní nástroje.
Dnes můžeme sledovat poměrně rychlou adaptaci fuzzy systémů (fuzzerů) při testování webových služeb či celých webových aplikací. Je to ostatně logické, zejména když si uvědomíme, že právě webové služby a aplikace poskytují svá rozhraní mnohdy všem uživatelům Internetu a tedy i mnoha potenciálním útočníkům. Snaha o co nejlepší zabezpečení je tedy v této oblasti IT zcela pochopitelná. Testovat je možné například REST API. V tomto případě mohou fuzzery použít popis API (OpenAPI/Swagger atd.) a na základě něho začít generovat různé potenciálně problematické vstupy se snahou o obejití vnitřních kontrolních mechanismů aplikace či služby. Některé nástroje, například https://github.com/dubzzz/fuzz-rest-api/, se navíc snaží o různé specifické typy útoků, například do dat přidávají řetězce s příklady SQL Injection apod. Dále lze pochopitelně posílat pseudonáhodná data v tělech požadavků, měnit parametry URL i hlavičky požadavků.
Příklady nástrojů určených pro Python:
| # | Nástroj |
|---|---|
| 1 | Hypothesis |
| 2 | Pester |
| 3 | Peach Fuzzer Framework |
| 4 | antiparser |
| 5 | Fusil (Fusil the fuzzer) |
| 6 | PyFuzzer |
8. Testy grafického uživatelského rozhraní a end-to-end testy
Následují relativně vysokoúrovňové testy, zejména testy grafického uživatelského rozhraní, kterým bude později věnováno hned několik článků v tomto seriálu. Mnohé dnešní aplikace jsou založeny na webovém prohlížeči (ať již klasickém, či „schovaném“ ve frameworcích typu Electron), takže existuje hned několik nástrojů pro Python, které umožňují testování GUI takových aplikací. Většinou se setkáme se dvěma způsoby testování:
- Simulace chování webového prohlížeče, typicky na úrovni protokolu HTTP a parsování HTML, které posílá aplikace prohlížeči. Mnohdy jsou tyto testy zredukovány na testy REST API. Sem spadají nástroje jako webunit, zope.testbrowser, webtest nebo FunkLoad.
- Automatizace přímo v rámci webového prohlížeče, kdy testy (resp. framework pod nimi) přímo používá možnosti webového prohlížeče. V této kategorii je pravděpodobně nejznámějším nástrojem Selenium, které obsahuje podporu i pro Python. Existují však i další nástroje, například Windmill či Splinter.
Na ještě vyšší úrovni, prakticky na vrcholku pyramidy, jsou end-to-end testy. Ty slouží k otestování aplikace jako celku, od začátku do konce. Může se například provádět následující testování:
- Přihlášení do aplikace
- Zahájení konkrétní operace
- Vytvoření reportu
- Poslání tohoto reportu na tiskárnu
- Odhlášení z aplikace
9. Testy chování (BDD)
Velmi důležité jsou testy chování (behaviour-driven), protože ty nám mohou odhalit nelogičnosti ve zdánlivě funkčním systému (například se očekává neintuitivní ovládání). Tyto typy testů do určité míry kombinují přístupy TDD a ATDD (viz následující dvě kapitoly); používají se zde nástroje Behave či Robot Framework. Zajímavé je, že se v této oblasti můžeme setkat s určitou standardizací (procházející dokonce přes více programovacích jazyků), kterou představuje doménově specifický jazyk (DSL) nazvaný Gherkin.
Ve dvou článcích [1] [2] o programovacím jazyku Clojure jsme se věnovali popisu integrace výše zmíněného doménově specifického jazyka Gherkin určeného pro popis testovacích scénářů přímo v programovacím jazyku Clojure. Ve skutečnosti ovšem není Gherkin v žádném případě určen pouze pro použití společně s Clojure, ale jedná se o DSL integrovatelný i do mnoha dalších programovacích jazyků. Dnes si ve stručnosti představíme knihovnu Behave, s jejíž pomocí se Gherkin integruje do jazyka Python. Ve skutečnosti se bude jednat o téměř ideální spojení, protože Gherkin i Python používají podobný způsob zápisu, v němž i odsazení jednotlivých programových řádků je součástí syntaxe (naproti tomu se Gherkin a Clojure ze syntaktického hlediska zcela odlišují).
Jazyk Gherkin je navržen takovým způsobem, aby ho uživatelé (nemusí se totiž nutně jednat pouze o programátory) mohli začít používat prakticky okamžitě, tj. bez nutnosti studia sáhodlouhých manuálů.
Tento doménově specifický jazyk odstiňuje autora testů od vlastní implementace systému i od programovacího jazyka (či jazyků), v nichž je systém vytvořen. Ostatně v Gherkinu lze popsat očekávané chování prakticky jakéhokoli systému, který dokonce nemusí mít nic společného s IT.
Obrázek 11: Ukázka scénářů napsaných v doménově specifickém jazyce Gherkin.
Na předchozím screenshotu jsou zvýrazněna klíčová slova uvozující jednotlivé kroky testu. Ostatní slova a číslice ve větách jsou buď pevně daná (svázaná s konkrétním krokem), nebo se jedná o proměnné. Ve scénáři je zapsána i tabulka, jejíž obsah se řádek po řádku postupně stává obsahem jednotlivých kroků testu (obsahem tabulky se nahrazují slova umístěná do ostrých závorek).
Druhým důležitým souborem je vlastní testovací scénář nazvaný adder.feature, který je (př použití knihovny Behave) typicky uložen v podadresáři features. Tento testovací scénář je naprogramován v jazyku Gherkin, konkrétně v jeho výchozí anglické „mutaci“. V následujícím výpisu jsou klíčová slova rozeznávaná interpretrem označena tučně:
Feature: Adder test
Scenario: Check the function add()
Given The function add is callable
When I call function add with arguments 1 and 2
Then I should get 3 as a result
Tento přístup je možné napodobit i při použití Robot Frameworku, v němž může zápis testu vypadat například následovně:
*** Settings ***
Library Accumulator6.py
Test setup Setup method 0
Test teardown Teardown method
Test template Accumulator operation
*** Keywords ***
Accumulator operation
[Arguments] ${value} ${expected}
Given accumulator has been zeroed
When I add ${value} to accumulator
Then the accumulated value Should Be ${expected}
*** Test Cases *** Value Expected
Accumulator operation 1 1
Accumulator operation 10 10
*** Keywords ***
Accumulator has been zeroed
log accumulator init
I add ${value} to accumulator
Add value ${value}
Then the accumulated value should be ${expected}
Accumulator value should be ${expected}
10. Test-driven development (TDD)
Zkratkou TDD se označuje poměrně populární metodika vývoje softwaru, v němž jsou jednotlivé kroky (typicky malé operace) definovány s využitím testů, a to většinou jednotkových testů, ovšem může se jednat i o testy komponent či dokonce o testy UI (to je ovšem méně flexibilní). Nejprve jsou napsány tyto testy, které pochopitelně musí zhavarovat, protože vyžadovaná funkcionalita neexistuje. Posléze vývojáři postupně doplní programový kód, který se neustále testuje – tento proces je nedílnou součástí celého vývoje a provádí se prakticky neustále, a to pochopitelně i před a po refaktoringu. Touto metodikou se opět budeme podrobněji zabývat v samostatném článku.
11. Acceptance test–driven development (ATDD)
Podobně znějící zkratka ATDD znamená Acceptance test–driven development. Opět se jedná o metodiku vývoje softwaru, tentokrát ovšem postavenou na poměrně úzké spolupráci mezi vývojáři, zákazníky a testery (což bývá velmi problematické :-). Využívá se zde například BDD a cílem je získat přesnější informace o požadavcích zákazníka ještě předtím, než se začne ztrácet drahý čas vývojem – mnoho problémů by se mělo objevit již při psaní akceptačních testů, popř. BDD. Teoreticky by se mělo jednat o ideální postup, který ovšem nemusí být některou z participujících stran dobře pochopen.
12. Použití knihovny unittest.mock (nejenom) při testování
Při testování aplikací, zejména při psaní jednotkových testů (což je, jak již ostatně víme, základ testovací pyramidy), se poměrně často dostaneme do situace, kdy potřebujeme nahradit nějakou funkci, metodu nebo dokonce celou třídu používanou v reálné aplikaci za „falešnou“ funkci/metodu/třídu vytvořenou pouze pro účely jednotkových testů. V programovacím jazyku Python je možné pro tvorbu a použití takových „falešných“ bloků kódu použít hned několik různých knihoven, které se od sebe odlišují jak svými možnostmi, tak i způsobem zápisu či deklarace očekávaného chování testované aplikace. Určitým standardem v této oblasti je v současnosti knihovna unittest.mock. Dnes si ukážeme některé základní techniky, které nám tato knihovna poskytuje.
S následující situací se již setkal pravděpodobně každý vývojář vytvářející jednotkové testy – je nutné otestovat funkcionalitu části aplikace, v této části se však volá nějaká funkce nebo metoda provádějící potenciálně destruktivní činnost (změna filesystému, vzdálené volání procedur, programování zařízení připojeného přes USB atd.). Popř. se volá funkce/metoda, která v závislosti na různých okolnostech vrací (minimálně z pohledu testů) pseudonáhodná data. Takovou funkci/metodu by bylo vhodné pro účely testování nahradit jednodušším kódem, jenž bude provádět předem známou činnost, například bude za každých okolností pouze vracet určitou hodnotu. Taková náhrada skutečných funkcí či metod za funkce/metody „falešné“ se (poněkud nepřesně) nazývá „mockování“ (mocking), a příslušný náhradní kód pak test double, popř. podle funkce fake, stub, spy nebo mock. V druhé části dnešního článku si ukážeme, jakým způsobem se může tato technika použít v Pythonu, konkrétně v Pythonu řady 3.x.
V současnosti existuje relativně velké množství různých knihoven, které mockování v Pythonu umožňují. Z nich jmenujme například velmi zajímavý projekt Flexmock, který naleznete na adrese https://pypi.python.org/pypi/flexmock. Ovšem v Pythonu 3.x se standardem v této oblasti stala knihovna nazvaná unittest.mock. V případě, že ještě z nějakého důvodu musíte používat Python 2.x, použijte namísto knihovny unittest.mock knihovnu nazvanou jednoduše mock. Tato knihovna nabízí prakticky stejné možnosti jako unittest.mock (je ostatně založena na stejném kódu, který pouze byl pro potřeby Pythonu 2.x upraven), ovšem lze ji použít jak v Pythonu 2.x, tak i v Pythonu 3.x, a to bez toho, abyste museli upravovat zdrojové kódy vašich testů (samozřejmě za předpokladu, že se v nich nevyskytují konstrukce, které nejsou v Pythonu 2.x podporovány). Další knihovny, které stojí za zmínku a které jsou potenciálně užitečné, jsou zmíněny v další tabulce:
| # | Nástroj |
|---|---|
| 1 | Ludibrio |
| 2 | Python Mock |
| 3 | PyMock |
| 4 | mock |
| 5 | pMock |
| 6 | minimock |
| 7 | svnmock |
| 8 | Mocker |
| 9 | Stubble |
| 10 | Mox |
| 11 | MockTest |
| 12 | Fudge |
| 13 | Mockito for Python |
| 14 | CaptureMock |
| 15 | flexmock |
| 16 | doublex |
| 17 | aspectlib |
Vraťme se však k základům jednotkových testů a mockování. Zmíněný falešný blok kódu je možné podle jeho vlastností rozdělit do několika kategorií:
- fake – vrací jedinou programátorem zvolenou hodnotu. Příkladem může být funkce nahrazující čtení z databáze, která vždy vrátí jediný záznam.
- stub – již obsahuje jednoduchou logiku, například dokáže reagovat na špatný vstup podobně, jako nahrazovaný blok.
- spy – dokáže zaznamenat předávané parametry či dokonce celý stav (nebo podstav) aplikace.
- mock – mnohdy se jedná o blok s vlastnostmi, které se přibližují reálnému (nahrazovanému) kódu. Vylepšená verze stub.
13. Zdrojový soubor s funkcí, kterou budeme nahrazovat mock objektem
Popis možností knihovny unittest.mock začneme na tom nejjednodušším možném příkladu. Bude se jednat o aplikaci (či spíše minimalistickou „aplikaci“) tvořenou pouhými dvěma zdrojovými soubory application.py a main.py. První zmíněný soubor obsahuje jedinou funkci pojmenovanou function1, která po svém zavolání nejprve vypíše na standardní výstup text „function1 called“ a následně vrátí do volajícího kódu řetězec s obsahem „tested function“, jenž může být v případě potřeby dále zpracován. Celý soubor se zdrojovým kódem má tedy pouze několik řádků (funkce je volána ze skriptu main.py):
"""Implementace logiky aplikace, kterou budeme testovat."""
def function1():
"""Funkce, kterou v testech nahradíme mockem."""
print("function1 called")
return "tested function"
Zavolání této aplikace je snadné a provede se, jak již víme, přes skript main.py:
#!/usr/bin/env python3
"""Vstupní bod do testované aplikace."""
from application import *
if __name__ == '__main__':
# pouze zavoláme funkci, která se bude v testech mockovat
print(function1())
Následovně:
$ python3 main.py
14. Test s volanou i s mockovanou funkcí
Nyní se podívejme na to, jakým způsobem se může funkce nazvaná function1 volat a testovat v jednotkových testech. Pro jednoduchost prozatím nepoužijeme žádný framework určený pro psaní jednotkových testů (to bude téma pro samostatný článek), ale vytvoříme si jednoduchý pomocný soubor nazvaný test.py, v němž se pokusíme zavolat jak původní funkci, tak i její tzv. mock („falešnou“ variantu původní funkce). Na začátku je nutné provést import modulu unittest.mock a samozřejmě taktéž import testovaného modulu application:
from unittest.mock import * import application
První pseudotest bude jednoduchý – pouze v něm zavoláme původní funkci a vypíšeme hodnotu, kterou tato funkce vrátí volajícímu kódu (zde se žádné mockování neprování):
def test1():
print(application.function1())
Druhý pseudotest je již mnohem zajímavější, protože v něm namísto původní funkce function1 z modulu application použijeme mock. Deklarace testovací funkce je doplněna o anotaci @patch, v níž specifikujeme jméno mockované funkce (ve formě řetězce, jehož obsah je kontrolován) a současně i návratovou hodnotu. To je nutné, protože se původní funkce ve skutečnosti vůbec nezavolá, ale návratovou hodnotu použijeme ve funkci print:
@patch('application.function1', return_value=42)
def test2(mocked_function_object):
print(application.function1())
Povšimněte si, že jméno mockované funkce je zapsáno i s uvedením jmenného prostoru („application.function1“), který ovšem musí odpovídat kontextu, v němž se funkce volá! Právě uvedení správného kontextu je pravděpodobně nejdůležitější část, kterou je nutné při mockování pochopit (více viz navazující část tohoto miniseriálu). Navíc stojí za povšimnutí, že se testovací funkci test2 předává parametr mocked_function_object, který představuje objekt udržující informace o mocku. Tento objekt využijeme v dalších demonstračních příkladech, nyní je však nutné si uvědomit, že se tento parametr plní automaticky (při volání test2 ho explicitně nebudeme uvádět – ostatně v reálných jednotkových testech se bude tato funkce volat automaticky).
Nyní již můžeme skript doplnit o kód, který všechny testy spustí. Povšimněte si, že první test naschvál spouštíme dvakrát (na začátku a na konci), aby bylo patrné, že mockovaná funkce se volá pouze v testu test2 (mockování je v tomto případě přísně lokální):
if __name__ == '__main__':
test1()
print()
test2()
print()
test1()
print()
Výsledek vypsaný po provedení skriptu potvrzuje, že při každém spuštění testu test1 se zavolá původní funkce, kdežto při spuštění testu test2 funkce mockovaná:
$ python3 test.py function1 called tested function 42 function1 called tested function
15. Vytvoření handleru, který se zavolá namísto originální funkce
Prozatím jsme se dozvěděli, jakým způsobem je možné nahradit volání skutečné funkce vrácením nějaké předem nastavené hodnoty. Tato hodnota sice může být prakticky jakákoli (číslo, pravdivostní hodnota, řetězec, pole, n-tice, slovník, objekt, klidně i None), ovšem někdy si s tímto chováním nevystačíme a budeme potřebovat, aby se namísto původní funkce zavolala funkce odlišná; typicky mnohem jednodušší, s předvídatelnějšími výsledky atd. Příkladem může být „falešná“ funkce nahrazující čtení záznamů z databáze za výběr hodnoty z předem známé datové struktury. S využitím knihovny unittest.mock je nahrazení původní funkce za její (ne)plnohodnotný mock snadné. Nejprve tuto funkci deklarujeme (měla by akceptovat stejné parametry, jako funkce původní) a následně použijeme v anotaci @patch nepovinný parametr side_effect, kterému předáme referenci na mock:
def side_effect_handler():
print("side_effect function called")
return -1
@patch('application.function1', side_effect=side_effect_handler)
def test3(mocked_function_object):
print(application.function1())
Pokud spustíme třetí test představovaný výše vypsanou funkcí test3 (a to opět BEZ parametrů):
test3()
zavolá se z něj ve skutečnosti funkce side_effect_handler a nikoli application.function1:
side_effect function called -1
16. Kombinace handleru s předkonfigurovanou návratovou hodnotou?
Podívejme se ještě, co se stane ve chvíli, kdy v anotaci @patch současně použijeme parametr return_value i side_effect. Zápis bude vypadat následovně:
def side_effect_handler():
print("side_effect function called")
return -1
@patch('application.function1', return_value=42, side_effect=side_effect_handler)
def test4(mocked_function_object):
print(application.function1())
V případě, že zavoláme výše vypsanou testovací funkci test4, vypíšou se na standardní výstup následující dva řádky, z nichž je patrné, že se hodnota specifikovaná parametrem return_value ignorovala a namísto ní se použila návratová hodnota „falešné“ funkce side_effect_handler:
side_effect function called -1
Toto chování se ale změní ve chvíli, kdy mock vrátí speciální hodnotu unittest.mock.DEFAULT (přesněji řečeno sentinel.DEFAULT). V takovém případě se skutečně využije hodnota zapsaná v parametru return_value v anotaci @patch, o čemž se lze ostatně velmi snadno přesvědčit:
def side_effect_handler_2():
print("side_effect function called")
return DEFAULT
@patch('application.function1', return_value=42, side_effect=side_effect_handler_2)
def test5(mocked_function_object):
print(application.function1())
Výsledek zavolání výše vypsané testovací funkce test5:
side_effect function called 42
Díky tomuto chování je možné použít „falešnou“ funkci ve větším množství testů, což je téma, kterým se budeme podrobněji zabývat příště.
Pro přehlednost je v této kapitole vypsán úplný zdrojový kód dnešního druhého demonstračního příkladu rozděleného do dvou modulů.
Soubor application.py s testovanou funkcí
"""Implementace logiky aplikace, kterou budeme testovat."""
def function1():
"""Funkce, kterou v testech nahradíme mockem."""
print("function1 called")
return "tested function"
Soubor test.py s testy
"""Implementace (umělých) jednotkových testů."""
from unittest.mock import *
import application
def test1():
"""První test neprovádí prakticky žádné reálné kontroly, jen zavolá testovanou funkci."""
print(application.function1())
@patch('application.function1', return_value=42)
def test2(mocked_function):
"""Druhý test používá fake test double - náhradu volané funkce."""
print(application.function1())
def side_effect_handler():
"""Implementace handleru - stub funkce nahrazované mockem."""
print("side_effect function called")
return -1
@patch('application.function1', side_effect=side_effect_handler)
def test3(mocked_function):
"""Druhý test používá stub test double - náhradu volané funkce."""
print(application.function1())
@patch('application.function1', return_value=42, side_effect=side_effect_handler)
def test4(mocked_function):
"""Čtvrtý test se snaží zkombinovat fake a stub."""
print(application.function1())
def side_effect_handler_2():
"""Implementace handleru - stub funkce nahrazované mockem, který ovšem ovlivňuje chování testu."""
print("side_effect function called")
return DEFAULT
@patch('application.function1', return_value=42, side_effect=side_effect_handler_2)
def test5(mocked_function):
"""Čtvrtý test se opět snaží zkombinovat fake a stub."""
print(application.function1())
if __name__ == '__main__':
print("*** test1 ***")
test1()
print()
print("*** test2 ***")
test2()
print()
print("*** test3 ***")
test3()
print()
print("*** test4 ***")
test4()
print()
print("*** test5 ***")
test5()
print()
print("*** test1 ***")
test1()
print()
17. Obsah následující části seriálu
V navazujícím článku si ukážeme některé další možnosti, které nám Python a jeho knihovny a frameworky nabízí v oblasti jednotkových testů (včetně možnosti selektivního spouštění benchmarků). Podíváme se i na způsob spouštění jednotkových testů v k tomu určených prostředích (Jenkins, Travis CI) apod.
18. Repositář s demonstračními příklady
Zdrojové kódy všech dnes použitých demonstračních příkladů byly uloženy do nového Git repositáře, který je dostupný na adrese https://github.com/tisnik/testing-in-python. V případě, že nebudete chtít klonovat celý repositář (ten je ovšem – alespoň prozatím – velmi malý, dnes má přibližně deseti kilobajtů), můžete namísto toho použít odkazy na jednotlivé demonstrační příklady a jejich části, které naleznete v následující tabulce:

https://github.com/tisnik/testing-in-python/blob/master/
19. Předchozí články s tématem testování (nejenom) v Pythonu
Tématem testování jsme se již na stránkách Rootu několikrát zabývali. Jedná se mj. o následující články:
- Behavior-driven development v Pythonu s využitím knihovny Behave
https://www.root.cz/clanky/behavior-driven-development-v-pythonu-s-vyuzitim-knihovny-behave/ - Behavior-driven development v Pythonu s využitím knihovny Behave (druhá část)
https://www.root.cz/clanky/behavior-driven-development-v-pythonu-s-vyuzitim-knihovny-behave-druha-cast/ - Behavior-driven development v Pythonu s využitím knihovny Behave (závěrečná část)
https://www.root.cz/clanky/behavior-driven-development-v-pythonu-s-vyuzitim-knihovny-behave-zaverecna-cast/ - Validace datových struktur v Pythonu pomocí knihoven Schemagic a Schema
https://www.root.cz/clanky/validace-datovych-struktur-v-pythonu-pomoci-knihoven-schemagic-a-schema/ - Validace datových struktur v Pythonu (2. část)
https://www.root.cz/clanky/validace-datovych-struktur-v-pythonu-2-cast/ - Validace datových struktur v Pythonu (dokončení)
https://www.root.cz/clanky/validace-datovych-struktur-v-pythonu-dokonceni/ - Univerzální testovací nástroj Robot Framework
https://www.root.cz/clanky/univerzalni-testovaci-nastroj-robot-framework/ - Univerzální testovací nástroj Robot Framework a BDD testy
https://www.root.cz/clanky/univerzalni-testovaci-nastroj-robot-framework-a-bdd-testy/ - Úvod do problematiky fuzzingu a fuzz testování
https://www.root.cz/clanky/uvod-do-problematiky-fuzzingu-a-fuzz-testovani/ - Úvod do problematiky fuzzingu a fuzz testování – složení vlastního fuzzeru
https://www.root.cz/clanky/uvod-do-problematiky-fuzzingu-a-fuzz-testovani-slozeni-vlastniho-fuzzeru/ - Knihovny a moduly usnadňující testování aplikací naprogramovaných v jazyce Clojure
https://www.root.cz/clanky/knihovny-a-moduly-usnadnujici-testovani-aplikaci-naprogramovanych-v-jazyce-clojure/ - Validace dat s využitím knihovny spec v Clojure 1.9.0
https://www.root.cz/clanky/validace-dat-s-vyuzitim-knihovny-spec-v-clojure-1–9–0/ - Testování aplikací naprogramovaných v jazyce Go
https://www.root.cz/clanky/testovani-aplikaci-naprogramovanych-v-jazyce-go/ - Knihovny určené pro tvorbu testů v programovacím jazyce Go
https://www.root.cz/clanky/knihovny-urcene-pro-tvorbu-testu-v-programovacim-jazyce-go/ - Testování aplikací psaných v Go s využitím knihoven Goblin a Frisby
https://www.root.cz/clanky/testovani-aplikaci-psanych-v-go-s-vyuzitim-knihoven-goblin-a-frisby/ - Testování Go aplikací s využitím knihovny GΩmega a frameworku Ginkgo
https://www.root.cz/clanky/testovani-go-aplikaci-s-vyuzitim-knihovny-gomega-mega-a-frameworku-ginkgo/ - Tvorba BDD testů s využitím jazyka Go a nástroje godog
https://www.root.cz/clanky/tvorba-bdd-testu-s-vyuzitim-jazyka-go-a-nastroje-godog/ - Použití Go pro automatizaci práce s aplikacemi s interaktivním příkazovým řádkem
https://www.root.cz/clanky/pouziti-go-pro-automatizaci-prace-s-aplikacemi-s-interaktivnim-prikazovym-radkem/ - Použití Go pro automatizaci práce s aplikacemi s interaktivním příkazovým řádkem (dokončení)
https://www.root.cz/clanky/pouziti-go-pro-automatizaci-prace-s-aplikacemi-s-interaktivnim-prikazovym-radkem-dokonceni/ - Použití jazyka Gherkin při tvorbě testovacích scénářů pro aplikace psané v Clojure
https://www.root.cz/clanky/pouziti-jazyka-gherkin-pri-tvorbe-testovacich-scenaru-pro-aplikace-psane-v-nbsp-clojure/ - Použití jazyka Gherkin při tvorbě testovacích scénářů pro aplikace psané v Clojure (2)
https://www.root.cz/clanky/pouziti-jazyka-gherkin-pri-tvorbe-testovacich-scenaru-pro-aplikace-psane-v-nbsp-clojure-2/
20. Odkazy na Internetu
- Awesome Python – testing
https://github.com/vinta/awesome-python#testing - Selenium (pro Python)
https://pypi.org/project/selenium/ - Getting Started With Testing in Python
https://realpython.com/python-testing/ - unittest.mock — mock object library
https://docs.python.org/3.5/library/unittest.mock.html - mock 2.0.0
https://pypi.python.org/pypi/mock - An Introduction to Mocking in Python
https://www.toptal.com/python/an-introduction-to-mocking-in-python - Mock – Mocking and Testing Library
http://mock.readthedocs.io/en/stable/ - Python Mocking 101: Fake It Before You Make It
https://blog.fugue.co/2016–02–11-python-mocking-101.html - Nauč se Python! – Testování
http://naucse.python.cz/lessons/intro/testing/ - Flexmock (dokumentace)
https://flexmock.readthedocs.io/en/latest/ - Test Fixture (Wikipedia)
https://en.wikipedia.org/wiki/Test_fixture - Mock object (Wikipedia)
https://en.wikipedia.org/wiki/Mock_object - Extrémní programování
https://cs.wikipedia.org/wiki/Extr%C3%A9mn%C3%AD_programov%C3%A1n%C3%AD - Programování řízené testy
https://cs.wikipedia.org/wiki/Programov%C3%A1n%C3%AD_%C5%99%C3%ADzen%C3%A9_testy - Pip (dokumentace)
https://pip.pypa.io/en/stable/ - Tox
https://tox.readthedocs.io/en/latest/ - pytest: helps you write better programs
https://docs.pytest.org/en/latest/ - doctest — Test interactive Python examples
https://docs.python.org/dev/library/doctest.html#module-doctest - unittest — Unit testing framework
https://docs.python.org/dev/library/unittest.html - Python namespaces
https://bytebaker.com/2008/07/30/python-namespaces/ - Namespaces and Scopes
https://www.python-course.eu/namespaces.php - Stránka projektu Robot Framework
https://robotframework.org/ - GitHub repositář Robot Frameworku
https://github.com/robotframework/robotframework - Robot Framework (Wikipedia)
https://en.wikipedia.org/wiki/Robot_Framework - Tutoriál Robot Frameworku
http://www.robotframeworktutorial.com/ - Robot Framework Documentation
https://robotframework.org/robotframework/ - Robot Framework Introduction
https://blog.testproject.io/2016/11/22/robot-framework-introduction/ - robotframework 3.1.2 na PyPi
https://pypi.org/project/robotframework/ - Robot Framework demo (GitHub)
https://github.com/robotframework/RobotDemo - Robot Framework web testing demo using SeleniumLibrary
https://github.com/robotframework/WebDemo - Robot Framework for Mobile Test Automation Demo
https://www.youtube.com/watch?v=06LsU08slP8 - Gherkin
https://cucumber.io/docs/gherkin/ - Selenium
https://selenium.dev/ - SeleniumLibrary
https://robotframework.org/ - The Practical Test Pyramid
https://martinfowler.com/articles/practical-test-pyramid.html - Acceptance Tests and the Testing Pyramid
http://www.blog.acceptancetestdrivendevelopment.com/acceptance-tests-and-the-testing-pyramid/ - Tab-separated values
https://en.wikipedia.org/wiki/Tab-separated_values - A quick guide about Python implementations
https://blog.rmotr.com/a-quick-guide-about-python-implementations-aa224109f321 - radamsa
https://gitlab.com/akihe/radamsa - Fuzzing (Wikipedia)
https://en.wikipedia.org/wiki/Fuzzing - american fuzzy lop
http://lcamtuf.coredump.cx/afl/ - Fuzzing: the new unit testing
https://go-talks.appspot.com/github.com/dvyukov/go-fuzz/slides/fuzzing.slide#1 - Corpus for github.com/dvyukov/go-fuzz examples
https://github.com/dvyukov/go-fuzz-corpus - AFL – QuickStartGuide.txt
https://github.com/google/AFL/blob/master/docs/QuickStartGuide.txt - Introduction to Fuzzing in Python with AFL
https://alexgaynor.net/2015/apr/13/introduction-to-fuzzing-in-python-with-afl/ - Writing a Simple Fuzzer in Python
https://jmcph4.github.io/2018/01/19/writing-a-simple-fuzzer-in-python/ - How to Fuzz Go Code with go-fuzz (Continuously)
https://fuzzit.dev/2019/10/02/how-to-fuzz-go-code-with-go-fuzz-continuously/ - Golang Fuzzing: A go-fuzz Tutorial and Example
http://networkbit.ch/golang-fuzzing/ - Fuzzing Python Modules
https://stackoverflow.com/questions/20749026/fuzzing-python-modules - 0×3 Python Tutorial: Fuzzer
http://www.primalsecurity.net/0×3-python-tutorial-fuzzer/ - fuzzing na PyPi
https://pypi.org/project/fuzzing/ - Fuzzing 0.3.2 documentation
https://fuzzing.readthedocs.io/en/latest/ - Randomized testing for Go
https://github.com/dvyukov/go-fuzz - HTTP/2 fuzzer written in Golang
https://github.com/c0nrad/http2fuzz - Ffuf (Fuzz Faster U Fool) – An Open Source Fast Web Fuzzing Tool
https://hacknews.co/hacking-tools/20191208/ffuf-fuzz-faster-u-fool-an-open-source-fast-web-fuzzing-tool.html - Continuous Fuzzing Made Simple
https://fuzzit.dev/ - Halt and Catch Fire
https://en.wikipedia.org/wiki/Halt_and_Catch_Fire#Intel_x86 - Random testing
https://en.wikipedia.org/wiki/Random_testing - Monkey testing
https://en.wikipedia.org/wiki/Monkey_testing - Fuzzing for Software Security Testing and Quality Assurance, Second Edition
https://books.google.at/books?id=tKN5DwAAQBAJ&pg=PR15&lpg=PR15&q=%22I+settled+on+the+term+fuzz%22&redir_esc=y&hl=de#v=onepage&q=%22I%20settled%20on%20the%20term%20fuzz%22&f=false - libFuzzer – a library for coverage-guided fuzz testing
https://llvm.org/docs/LibFuzzer.html - fuzzy-swagger na PyPi
https://pypi.org/project/fuzzy-swagger/ - fuzzy-swagger na GitHubu
https://github.com/namuan/fuzzy-swagger - Fuzz testing tools for Python
https://wiki.python.org/moin/PythonTestingToolsTaxonomy#Fuzz_Testing_Tools - A curated list of awesome Go frameworks, libraries and software
https://github.com/avelino/awesome-go - gofuzz: a library for populating go objects with random values
https://github.com/google/gofuzz - tavor: A generic fuzzing and delta-debugging framework
https://github.com/zimmski/tavor - hypothesis na GitHubu
https://github.com/HypothesisWorks/hypothesis - Hypothesis: Test faster, fix more
https://hypothesis.works/ - Hypothesis
https://hypothesis.works/articles/intro/ - What is Hypothesis?
https://hypothesis.works/articles/what-is-hypothesis/ - Databáze CVE
https://www.cvedetails.com/ - Fuzz test Python modules with libFuzzer
https://github.com/eerimoq/pyfuzzer - Taof – The art of fuzzing
https://sourceforge.net/projects/taof/ - JQF + Zest: Coverage-guided semantic fuzzing for Java
https://github.com/rohanpadhye/jqf - http2fuzz
https://github.com/c0nrad/http2fuzz - Demystifying hypothesis testing with simple Python examples
https://towardsdatascience.com/demystifying-hypothesis-testing-with-simple-python-examples-4997ad3c5294 - Testování
http://voho.eu/wiki/testovani/ - Unit testing (Wikipedia.en)
https://en.wikipedia.org/wiki/Unit_testing - Unit testing (Wikipedia.cz)
https://cs.wikipedia.org/wiki/Unit_testing - Unit Test vs Integration Test
https://www.youtube.com/watch?v=0GypdsJulKE - TestDouble
https://martinfowler.com/bliki/TestDouble.html - Test Double
http://xunitpatterns.com/Test%20Double.html - Test-driven development (Wikipedia)
https://en.wikipedia.org/wiki/Test-driven_development - Acceptance test–driven development
https://en.wikipedia.org/wiki/Acceptance_test%E2%80%93driven_development - Gauge
https://gauge.org/ - Gauge (software)
https://en.wikipedia.org/wiki/Gauge_(software) - PYPL PopularitY of Programming Language
https://pypl.github.io/PYPL.html - Testing is Good. Pyramids are Bad. Ice Cream Cones are the Worst
https://medium.com/@fistsOfReason/testing-is-good-pyramids-are-bad-ice-cream-cones-are-the-worst-ad94b9b2f05f - Články a zprávičky věnující se Pythonu
https://www.root.cz/n/python/ - PythonTestingToolsTaxonomy
https://wiki.python.org/moin/PythonTestingToolsTaxonomy - Top 6 BEST Python Testing Frameworks [Updated 2020 List]
https://www.softwaretestinghelp.com/python-testing-frameworks/
